基于语言模型编码和多任务解码的SQL转换方法及系统
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及自然语言处理语义解析子领域Text to SQL,具体涉及一种基于语言模型编码和多任务解码的SQL转换方法及系统。
背景技术
随着大数据的兴起,现实生活中的数据呈现出爆炸式指数增长趋势。据IDC发布《数据时代2025》的报告显示,全球每年产生的数据将从2018年的33ZB增长到175ZB,相当于每天产生491EB数据。
与此同时,结构化数据和数据库存储规模也越来越大。以往用户想要查询数据库内容时,需要先编写结构化数据库查询语言SQL,再与数据库交互,这给非计算机专业的普通用户带来了不便。SQL 本身功能强大、灵活度高,具备一定的学习门槛。而且对于不同的数据库和应用场景,手工编写准确无误的SQL语言容易出错。如何通过自然语言自由地与数据库交互成为新的研究热点。
Text to SQL(以下简称Text2SQL)是自然语言理解语义解析领域的子任务,旨在将用户的自然语言直接转换成对应的SQL,继而完成后续的查询工作。它的目的可以简单概括为打破人与结构化数据库之间的壁垒,为绝大多数不熟悉SQL语言的用户提供了与大型数据库自由交互的强大工具,也提升了结构化数据的使用效率和价值。同时Text2SQL可以作为人机交互或问答系统的模块之一,当涉及与结构化文档或表格型数据交互时,可以解析用户提问并从海量文本中准确返回用户想要的答案。
例如有表1所示的结构化表格,首行代表表格的列名和属性,其余行是数据库中存储的结构化数据。用户可能会根据表格提问:“周某某和林某某最近的演唱会是什么时候
自从上世纪90年代提出Text2SQL研究方向后,该任务已经在自然语言处理领域被广泛研究多年。早期的语义解析数据集例如ATIS、GeoQuery等,属于受限于特定领域的数据集,并且没有使用SQL作为查询指标。2019年,某公司发布了首个跨领域的中文大规模标注数据集TableQA,内容主要来自金融领域。业内早期的Text2SQL解决方案一般是基于SQL规则的模版方法,对于用户问题进行字符串解析并拼接到模版的对应片段。然而这种方法过于简单,扩展性较差,对于稍复杂一些的查询条件很容易解析错误。另一种基于语法树的SQL解析方案,模型设计复杂,而且可解释性较差。
文本编码方面,传统的词向量属于静态编码,同一个词在不同的上下文语境中具有相同的特征向量,无法满足文本和数据库模式的联合编码需求。
发明内容
为了解决上述中的技术问题,本发明提供了一种基于语言模型编码和多任务解码的SQL转换方法及系统,本发明所实现的方法在文本-SQL解析任务中,能够针对用户问题和给定的结构化数据库进行高效的语义编码和交互;同时在解码部分将SQL拆解为不同片段,采用多任务模型架构分别解码预测,显著提升了SQL生成的准确率和模型的可解释性。
为了实现上述目的,本发明采用的技术方案为:
本发明的其中一个目的在于提供一种基于语言模型编码和多任务解码的SQL转换方法,包括以下步骤:
(1)根据查询数据库的类型,对语言模型编码器进行预训练,所述的语言模型编码器包括Embedding层和Transformer网络,训练后得到预训练语言模型编码器;
(2)将查询数据库根据表名、列名依次展开,把二维表格转换为一维文本序列,结合用户提问语句拼接形成输入序列X,并给定用户提问语句对应的目标SQL序列;
(3)将序列X作为预训练语言模型编码器的Embedding层的输入,获取初始编码向量;再利用Transformer网络对初始编码向量进行深度编码,获取用户提问语句与所述的一维文本序列的上下文语义信息,输出编码结果;
(4)建立由9个不同的神经网络构成的多任务解码器,利用9个神经网络对编码结果进行解码,还原目标SQL序列,并分别计算每一个神经网络的交叉熵损失;
(5)为不同神经网络的损失值设置不同的权重,求和作为预训练语言模型编码器和多任务解码器的总损失,利用梯度下降算法优化目标函数,更新模型参数;
(6)训练完毕,保存模型参数,根据用户提问语句和目标查询数据库,自动生成对应的SQL序列。
本发明的另一个目的在于提供一种基于上述方法的预训练语言模型编码和多任务解码的文本与SQL转换系统,包括:
预训练模块,其用于根据查询数据库的类型,对语言模型编码器进行预训练,训练后得到预训练语言模型编码器;
序列表示模块,其用于将查询数据库根据表名、列名依次展开,把二维表格转换为一维文本序列,结合用户提问语句拼接形成输入序列X;
向量嵌入模块,其用于根据预训练语言模型的词嵌入矩阵、位置向量矩阵和文本片段表示矩阵叠加,将原始的输入序列转换为固定长度的向量表示,得到初始编码向量;
Transformer网络模块,其用于对初始编码向量进行深度编码,获取用户提问语句与所述的一维文本序列的上下文语义信息,输出编码结果;
多任务解码模块,由9个不同的神经网络构成,对编码结果进行解码,还原目标SQL序列;
损失函数计算模块,在训练阶段,用于计算每一个神经网络的交叉熵损失,并根据不同神经网络的权重计算总损失;并基于总损失值和目标SQL序列,对预训练语言模型编码器和多任务解码器的参数进行更新。
与现有技术相比,本发明的优势在于:
1、本发明使用基于Transformer模块的预训练语言模型作为编码器,联合编码数据库模式和用户问题,可以捕捉其中隐含的模式链接关系。
2、解码器拆分为9个子网络,结合不同网络的loss权重设计,不仅可以解析“>, <,==, between, in”和嵌套查询等SQL查询条件,还显著提升了SQL解析准确率和模型的可解释性,可以单独优化准确率较低的模块,证明了模型的优越性。
3、预训练语言模型具有强大的特征编码能力和泛化性,本发明可以快速迁移至各个领域的数据库中使用,显著缓解Text2SQL标注数据缺乏的问题。
附图说明
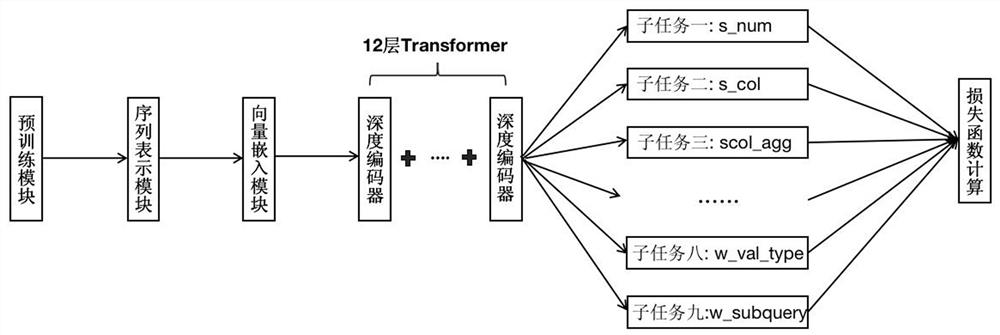
图1为本发明方法的整体框架设计图;
图2为本发明系统的整体流程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
如图1所示,一种基于语言模型编码和多任务解码的SQL转换方法,包括以下步骤:
一、根据查询数据库的类型,对语言模型编码器进行预训练,所述的语言模型编码器包括Embedding层和Transformer网络,训练后得到预训练语言模型编码器;
二、将查询数据库根据表名、列名依次展开,把二维表格转换为一维文本序列,结合用户提问语句拼接形成输入序列X,并给定用户提问语句对应的目标SQL序列;
三、将序列X作为预训练语言模型编码器的Embedding层的输入,获取初始编码向量;再利用Transformer网络对初始编码向量进行深度编码,获取用户提问语句与所述的一维文本序列的上下文语义信息,输出编码结果;
四、建立由9个不同的神经网络构成的多任务解码器,利用9个神经网络对编码结果进行解码,还原目标SQL序列,并分别计算每一个神经网络的交叉熵损失;
五、为不同神经网络的损失值设置不同的权重,求和作为预训练语言模型编码器和多任务解码器的总损失,利用梯度下降算法优化目标函数,更新模型参数;
六、训练完毕,保存模型参数,根据用户提问语句和目标查询数据库,自动生成对应的SQL序列。
根据上述步骤,本发明框架主要分为四部分:(a)序列表示模块,(b)编码器模块,(c)多任务解码器模块,(d)损失函数计算模块。具体步骤分别阐述如下:
(a)序列表示模块。将数据库和问题统一转换为文本序列,基本步骤如下:
1.从数据库中抽取出所有表的表名和列名,依次拼接。
2.加入问题,按“query、table、column”的顺序拼接成长序列X,其中问题、表名、列名片段之间用分隔符“[SEP]”分隔,序列开始位置加入“[CLS]”标记符。
具体的,将查询数据库根据表名、列名依次展开,把二维表格转换为一维文本序列,结合用户提问语句,按“问题(用户提问语句)、表名、列名片段”的顺序拼接成序列X,其中问题、表名、列名片段之间用分隔符“SEP”分隔,序列开始位置加入“CLS”标记符,拼接得到的序列X表示为:
X=[CLS, Q, SEP, T1, SEP, col_11, SEP, col_12,..., col_1i, SEP,T2,..., SEP]
其中,Q表示用户的问题,Ti表示数据库中第i张表的表名,col_ij表示第i张表中第j列的列名。
在训练阶段,还需要给定用户提问语句对应的目标SQL序列。
(b)编码器模块。将序列转换为向量并通过Transformer模块进行深度编码,基本步骤如下:
1.对序列X按字符切割,经预训练语言模型的词向量矩阵获取字符级别的向量编码;同时针对文本中每一个字符的位置和序列号(本发明中query部分的序列号为0,其余部分的序列号均为1,即onehot编码)得到位置嵌入编码和序列嵌入编码;这三部分的向量对应位置求和作为文本的嵌入向量表示。
对于长度为n的输入序列,将被Embedding转换为向量e,计算公式为:
其中,e是字向量嵌入、位置嵌入和段嵌入的总和。
2.将文本的嵌入向量经12层Transformer网络编码,学习上下文语义关联信息,特别是问题和表名、列名间的蕴含关系编码。Transformer模块能避免长距离依赖问题,且可以并行计算,运算效率高。
具体的,使用12层Transformer网络对用户提问语句和表格拼接的一维文本序列逐层进行特征抽取,表示为:
其中,h
在自注意力网络中,Q、K、V三个向量的输入是相同的,在第1层Transformer中为步骤(3)生成的初始编码向量,其余11层的输入均为上一层Transformer的输出;d
前向传播层的公式可表示为:
其中,Z为自注意力层的输出,W
(c)多任务解码器模块。将编码器输出特征输入下游不同子网络,本实施例中设置了9个子网络:
s_num_linear(select部分召回的列的总数)、scol_linear(select部分具体召回列的列名)、scol_agg_linear(召回列添加的聚合函数)、w_num_op_linear(where条件数量)、wcol_linear(where条件中对应的列)、wcol_op_linear(where各条件中对应的操作类型)、wcol_value(where各条件中抽取出的value值)、wcol_value_type(where各条件中value值对应的类型)、w_subquery(where各条件中涉及的子查询操作)。
上述9个子网络分别还原SQL相应片段,基本步骤如下:
1.为了还原select片段,在解码器中设计了s_num、s_col、s_col_agg三个子任务,分别计算select中召回列的数量、召回列的列名以及召回列添加的聚合函数。
2.为了还原where片段,在解码器中设计了w_num_op、w_col、w_col_op、w_col_val、w_val_type五个子任务,分别计算where部分的条件数量、where条件对应的列、条件对应的操作、条件中提取的文本值、条件中提取的文本值的类型。
3.为了实现嵌套查询,在解码器中设计了w_subquery子任务,可以满足超过平均值(> avg)、低于最大值(< max)等子查询需求。
通过设计9个子网络,模型不仅支持预测“>, <, ==, !=”等基础条件,还可以满足“in/not in, between and,嵌套子查询”等更加复杂的SQL语法,最后将还原的SQL片段拼接为完整的SQL。
本实施例中,在设计子网络时,分别将9个预测任务作为每一个神经网络的预测任务,在训练阶段,从目标SQL序列中分别拆解出9个预测任务的真实结果作为标签;结合预测结果和真实标签计算每一个神经网络的交叉熵损失。
(d)损失函数计算模块。计算各个任务的损失函数并加权求和,基本步骤如下:
1.根据各个子任务的输出结果,结合真实标注标签,分别计算交叉熵损失函数值,不同子任务的损失值有不同的权重,并将损失权重作为模型训练参数的一部分。各损失加权求和作为模型训练的总损失。
权重的设计是由于用户对不同SQL片段的错误容忍度并不相同。例如,“Where”条件部分如果预测出错,最终SQL查询结果一定是错误的,容忍度最低;“Select”查找部分如果存在冗余,返回一些不相关信息,用户一般可以接受。所以,需要为不同神经网络的损失值设置不同权重,首先确保“Where”片段尽可能预测正确。
2.使用mini-batch梯度下降法反向传播梯度来更新网络的参数值。其中训练过程中使用链式法则,模型参数计算公式为:
其中,是目标函数,α表示学习率,w
图2是本发明设计的基于语言模型编码和多任务解码的SQL转换系统流程示意图。系统流程与图1的方法流程相似,为了提升语言模型在特定领域内的特征抽取能力,在上述基础上增设了预训练模块,预训练方法为:获取查询数据库所处领域的无监督文本语料,结合用户提问语句,对语言模型做基于字符掩码的迭代预训练。更具体的,本实施中,根据数据集所处的领域,从知乎、百度知道等网站爬取对应垂直领域的无监督文本语料,和数据集中的用户提问一起,对预训练语言模型做基于字符掩码(MLM)的迭代预训练,提升领域内的特征抽取能力。
此外,将编码器模块进一步拆分为向量嵌入模块,深度编码器模块,总共分为六大模块,分别是预训练模块,序列表示模块,向量嵌入模块,深度编码器模块,子任务解码模块,以及损失函数计算模块。
预训练模块,其用于根据查询数据库的类型,对语言模型编码器进行预训练,训练后得到预训练语言模型编码器;
序列表示模块,其用于将查询数据库根据表名、列名依次展开,把二维表格转换为一维文本序列,结合用户提问语句拼接形成输入序列X;
向量嵌入模块,其用于根据预训练语言模型的词嵌入矩阵、位置向量矩阵和文本片段表示矩阵叠加,将原始的输入序列转换为固定长度的向量表示,得到初始编码向量;
Transformer网络模块,其用于对初始编码向量进行深度编码,获取用户提问语句与所述的一维文本序列的上下文语义信息,输出编码结果;
多任务解码模块,由9个不同的神经网络构成,对编码结果进行解码,还原目标SQL序列;
损失函数计算模块,在训练阶段,用于计算每一个神经网络的交叉熵损失,并根据不同神经网络的权重计算总损失;并基于总损失值和目标SQL序列,对预训练语言模型编码器和多任务解码器的参数进行更新。
对于系统实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的系统实施例仅仅是示意性的,其中所述作为多任务解码模块,可以是或者也可以不是物理上分开的。另外,在本发明中的各功能模块可以集成在一个处理单元中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个单元中。上述集成的模块或单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现,以根据实际的需要选择其中的部分或者全部模块来实现本申请方案的目的。
实施例
本发明在大型公开数据集TableQA上进行了对比和消融实验。TableQA是某公司2019年发布的大规模中文标注数据集,一共包含45,918条自然语言问句,表格和问题主要来自金融相关领域。相比此前Text2SQL领域的权威数据集WikiSQL难度更大,例如查找部分的目标列往往大于1,在条件部分增加了“or”判断逻辑,用户的问题表达更加随意多元。此外,数据库模式本身(表名、列名)可能并不包含在问题中,贴近了实际场景下用户的口语化表述。
原始TableQA数据集的SQL条件部分,仅包含“>, <, ==, !=”四种基础操作。为了贴近实际应用,增强语法多样性,通过人工标注与模版扩充相结合的方式,本发明在原有训练集和验证集上额外加入了“between and, in/not in, 嵌套子查询”等操作类型。最终训练的模型,可以支持以上所有操作类别。
所有实验中,文本词汇表均按字分割,个数限制在21128个常见字符。
本发明主要在三大评价指标上进行对比实验,分别是:Logical-form accuracy(LX),Execution accuracy(EX),Mean accuracy(MX)。其中LX表示逻辑形式准确率,评判模型生成SQL序列的各个片段是否和真实标注结果一致;EX表示执行结果准确率,直接执行生成的SQL,查看返回结果是否和预期相同;MX表示平均准确率,是LX和EX的平均值,可以更全面客观地反应模型的精准度。
实验在经过上述改进的TableQA验证集上进行,比较了5个Text2SQL领域公开知名的解决方案:SQLNet、MQAN、SQLova、X-SQL、Coarse2Fine,以及本发明算法MTSQL。为了验证领域预训练、语言模型对最终结果的贡献,本发明保留相同解码器,在编码器部分测试了静态词向量word2vec和3个主流预训练语言模型:BERT、XLNet、RoBERTA。其中领域预训练使用了从知乎平台爬取的金融主题文章,结合数据集本身的用户提问一共包含12MB无监督文本语料。完整对比结果如表2所示:
从表2可以看出,本发明提出的基于语言模型编码和多任务解码的SQL转换方法,在各个评判指标下均获得最优效果,充分展示了本发明算法的优越性。将SQL按照语法结构拆分为不同子片段分别还原预测,可以显著提升生成SQL的质量和模型的可解释性。
另外经过词向量和不同语言模型的对比实验,静态词向量word2vec对文本序列编码能力较弱,导致最终预测结果偏低。而预训练语言模型可以改进特征编码能力,在评判指标上获得了明显的改进。其中,采用动态Mask策略和更大训练语料的RoBERTA模型,效果要略好于BERT和XLNet,提高了模型的最终效果。“Pre”表示预训练,使用领域内的文本语料对语言模型做进一步的预训练,可以继续提升模型最终的预测结果,证明了领域预训练方法的有效性。
- 基于语言模型编码和多任务解码的SQL转换方法及系统
- 基于语言模型编码和多任务解码的SQL转换方法及系统