场景文字的轮廓拟合和校正方法、电子设备及存储介质
文献发布时间:2023-06-19 11:35:49
技术领域
本申请涉及场景文字识别领域,尤其是涉及一种场景文字的轮廓拟合和校正方法、电子设备及存储介质。
背景技术
文字在人类生活中被广泛应用,它能准确传达丰富的信息,使得其在许多视觉应用领域发挥重要作用。自然场景文字的识别是地理定位、智能检测、工业自动化、机器人导航等应用的基础。其中,任意形状场景文字的检测和识别是一个富有挑战的问题,由于文字的大小,长宽比,形状等富于变化,要求场景文字检测、识别方法具有表达复杂形状的能力。
近年来基于分割的文字检测方法,因其能输出像素精度的轮廓来表示任意文本形状,而受到广泛研究。基于分割的文字检测方法输出的是由像素点组成的文字区域轮廓,为实现端到端文字识别,当前主流的方法是求取检测文字轮廓的最小旋转矩形,然后用仿射变换采样该矩形区域的图像进行后续的文字识别。
但是发明人认为上述相关技术存在不能实现任意形状文字的高精度识别的问题。
发明内容
为了提高基于分割的文字检测器在实现端到端任意形状文字识别的精度,本申请提供一种场景文字的轮廓拟合和校正方法、电子设备及存储介质。
第一方面,本申请提供的一种场景文字的轮廓拟合和校正方法采用如下的技术方案:
一种场景文字的轮廓拟合和校正方法,包括以下步骤:
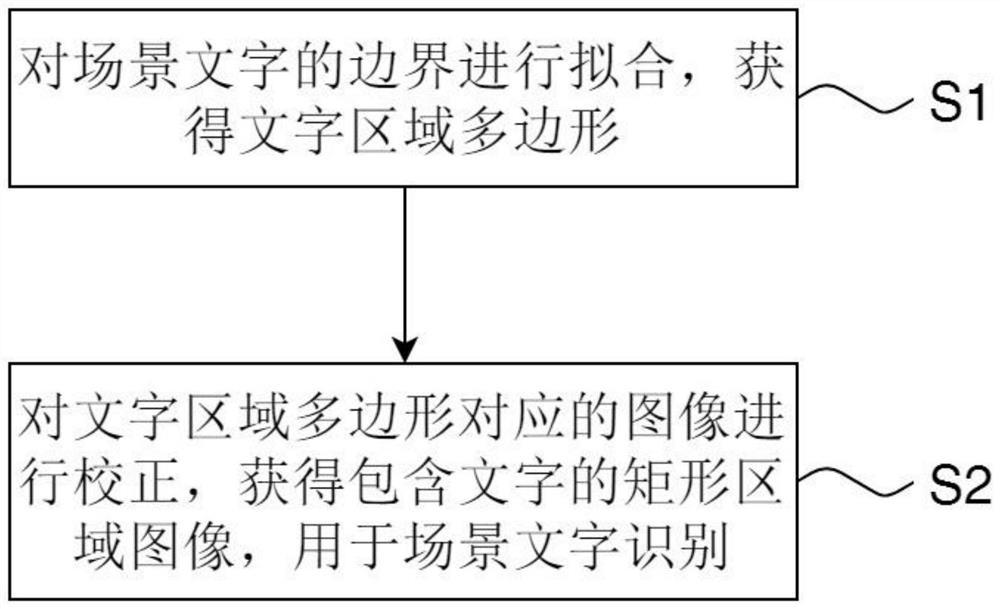
对场景文字的边界进行拟合,获得文字区域多边形;
对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,用于场景文字识别。
本申请通过对场景文字的边界进行拟合,获得文字区域多边形;然后对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,通过以上方法进行处理,从而获得了包含更少背景的文字矩形区域图像,用于场景文字识别时,可以有效提高任意形状场景文字的识别精度。
优选的,所述的对场景文字的边界进行拟合,获得文字区域多边形,包括:
对场景文字的整体轮廓拟合一个最小旋转矩形作为初始矩形;
根据所述的最小旋转矩形,将文字轮廓分为左右两部分,然后通过递归调用分别求取两部分的拟合多边形;
将获得的两个拟合多边形合并为单个多边形,进而得到文字区域多边形。
本申请基于分治法进行文字轮廓拟合,即将轮廓分为左右两部分,递归求取两部分的拟合多边形,然后将递归调用获得的两个拟合多边形合并为单个多边形。这种方法不需要设计额外的结构获取其它信息,从而可直接从分割轮廓中对任意复杂形状的文字边界进行拟合,而且计算量小,易于实现。
优选的,根据所述的最小旋转矩形,将文字轮廓分为左右两部分,然后通过递归调用分别求取两部分的拟合多边形,具体包括:
(a)设初始递归深度T=1,场景文字的整体轮廓点集C
(b)根据当前轮廓C
(c)取L为rbox
(d)对左边部分
(e)同理,对右边部分
通过采用以上方法从文字轮廓中拟合文字边界,该方法不需要训练模型,能够处理任何复杂的文字形状,拟合后对文字区域多边形对应的图像进行校正,然后输入文字识别器,可以有效提升端到端场景文字识别的精度。
优选的,以下任一条件满足则递归拟合过程终止:
当前轮廓的拟合精度超过预设的第一阈值w1;
当前轮廓的拟合精度超过预设的第二阈值w2(w2 当前递归的深度达到预设的最大递归深度T_max; 当前轮廓的面积小于预设的最小面积Area_min。 优选的,采用平均合并方法将获得的两个拟合多边形合并为单个多边形,进而得到文字区域多边形。方法实现最简单,从而可以提高任意形状文字轮廓拟合的效率。 优选的,所述的采用平均合并方法将获得的两个拟合多边形合并为单个多边形,包括: 将左边多边形上边最右顶点与右边多边形上边最左顶点合并为二者中点 通过采用以上技术方案,从而可以准确、快速的将获得的两个拟合多边形合并为单个多边形。 优选的,所述的对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,包括:采用三角网划分文字区域多边形,并对每个三角形区域用仿射变换进行插值,得到校正后的包含文字的矩形区域图像。 通过采用上述方法,从而可以简单、快速的获得校正后的文字区域图像,而且可以适应各种密度的图像采样点,校正后的矩形区域图像用于文字识别,可以大大提高识别的精度。 优选的,所述的采用三角网划分文字区域多边形,并对每个三角形区域用仿射变换进行插值,得到校正后的包含文字的矩形区域图像,包括: 估计图像中文字行的文字高度和宽度; 将多边形上边线性映射到校正后矩形的上边,即多边形顶点p
其中Length(:)为计算点序列形成路径长度的函数;S 同样,将多边形下边线性映射到校正后矩形的下边; 得到点对的映射关系后构建三角网,对每个三角形区域分别进行仿射变换,得到目标文字图像I 本申请中,通过将文字区域映射成校正后矩形,具体的,在两个区域中寻找文字区域多边形的顶点在校正后矩形上对应的点,获得所有一一对应的点对后然后构建三角网,对每个三角形区域分别进行仿射变换,得到目标文字图像I 优选的,所述的图像中文字行的文字高度H 因为校正后的文字变成水平排列,所以校正后矩形中所有文字具有相似的高度,从而可以人为设定一个固定值(这个值最好大于图像中文字的高度最大值,否则文字都被缩小了)。相对的,图像中文字可能为各种形状(S形、棱形等),从而每个文字大小可能各不相同,为了更准确描述图像中文字的高度,采用取均值方法(即计算图像中所有文字的高度均值)。文字区域多边形是文字图像的近似最小外接多边形,多边形上(下)边的路径长度表示文字区域的宽度,使用上下边长度的最大值选择文字区域,既能包含完整的文字图像,又不会包含过多的背景。因此,这种方法简单有效,能够更准确的表达文字区域中文字的宽高。 优选的,设定校正后的文字高度为H 通过采用上述方法设置校正后的文字宽度,从而能更准确的表达文字区域中的文字图像,校正效果也更好。 第二方面,本申请提供一种电子设备,采用如下的技术方案: 一种电子设备,包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如前述任一种方法的计算机程序。 第三方面,本申请提供一种计算机可读存储介质,采用如下的技术方案: 一种计算机可读存储介质,存储有能够被处理器加载并执行如前述任一种方法的计算机程序。 综上所述,本申请包括以下至少一种有益技术效果: 1、本申请通过对场景文字的边界进行拟合,获得文字区域多边形;然后对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,通过以上方法进行处理,从而获得了包含更少背景的文字矩形区域图像,用于场景文字识别时,可以有效提高任意形状场景文字的识别精度。 2、本申请采用三角网划分文字区域多边形,并对每个三角形区域用仿射变换进行插值,得到校正后的包含文字的矩形区域图像。通过采用上述方法,从而可以简单、快速的获得校正后的文字区域图像,而且可以适应各种密度的图像采样点,校正后的矩形区域图像用于文字识别,可以大大提高识别的精度。 附图说明 图1是本发明的一种实施例的方法流程图。 图2为拟合左右区域轮廓以及合并拟合多边形示意图。 图3为合并后的边界多边形示意图。 图4为某一个场景文字的最小旋转矩形对应的图像区域。 图5为通过本申请校正后的文字图像。 具体实施方式 以下结合附图1-5对本申请作进一步详细说明。 本申请实施例公开一种场景文字的轮廓拟合和校正方法。参照图1, 一种场景文字的轮廓拟合和校正方法,包括以下步骤: S1,对场景文字的边界进行拟合,获得文字区域多边形; S2,对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,用于场景文字识别。 可选的,所述的对场景文字的边界进行拟合,获得文字区域多边形,包括: 对场景文字的整体轮廓拟合一个最小旋转矩形作为初始矩形; 根据所述的最小旋转矩形,将文字轮廓分为左右两部分,然后通过递归调用分别求取两部分的拟合多边形; 将获得的两个拟合多边形合并为单个多边形,进而得到文字区域多边形。(对任意形状(如S形、棱形、波浪形等)的文字,划分轮廓的原则都是分为左右两部分) 上述方法,具体实施时,也可以对场景文字的整体轮廓拟合一个最小外接矩形。则后续递归过程中先划分后合并轮廓时也以最小外接矩形为出发点。 可选的,根据所述的最小旋转矩形,将文字轮廓分为左右两部分,然后通过递归调用分别求取两部分的拟合多边形,具体包括: (a)设初始递归深度T=1,场景文字的整体轮廓点集C (b)根据当前轮廓C (c)取L为rbox (d)对左边部分 (e)同理,对右边部分 上述方法中,划分当前轮廓时还可以采用任何能够产生两个部分的方法(例如,把轮廓划分为左右两个部分,两个部分包含相同个数的顶点)。 上述方法中,以下任一条件满足则递归拟合过程终止: 当前轮廓的拟合精度超过预设的第一阈值w1; 当前轮廓的拟合精度超过预设的第二阈值w2(w2 当前递归的深度达到预设的最大递归深度T_max; 当前轮廓的面积小于预设的最小面积Area_min。 可选的,采用平均合并方法将获得的两个拟合多边形合并为单个多边形,进而得到文字区域多边形。 具体的,所述的采用平均合并方法将获得的两个拟合多边形合并为单个多边形,包括: 将左边多边形上边最右顶点(如序号为ml)与右边多边形上边最左顶点(如序号为1)合并为二者中点 合并多边形时还可以采用其它任何能够连接左右子轮廓拟合多边形的方法,例如分别计算两个多边形上边及下边交点,并用交点将两个多边形对应边连接起来。 可选的,所述的对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,包括:采用三角网划分文字区域多边形,并对每个三角形区域用仿射变换进行插值,得到校正后的包含文字的矩形区域图像。 可选的,所述的采用三角网划分文字区域多边形,并对每个三角形区域用仿射变换进行插值,得到校正后的包含文字的矩形区域图像,包括: 估计图像中文字行的文字高度和宽度; 将多边形上边线性映射到校正后矩形的上边,即多边形顶点p
其中Length(:)为计算点序列形成路径长度的函数;S 同样,将多边形下边线性映射到校正后矩形的下边; 得到点对的映射关系后构建三角网,对每个三角形区域分别进行仿射变换,得到目标文字图像I 具体实施时,估计文字行高度、宽度还可采用其它方法,例如取上下边对应顶点距离的最大值等。校正前后多边形顶点变换还可采用其它变换形式,例如投影变换等。 可选的,所述的图像中文字行的文字高度H 可选的,设定校正后的文字高度为H 具体实施时,也可以采用其它方案,比如同时人为设定校正后的文字宽度W 本申请实施例还公开一种电子设备。一种电子设备,包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如上述任一种方法的计算机程序。 本申请实施例还公开一种计算机可读存储介质。一种计算机可读存储介质,存储有能够被处理器加载并执行如上述任一种方法的计算机程序。 以上均为本申请的较佳实施例,并非依此限制本申请的保护范围,故:凡依本申请的方法、原理所做的等效变化,均应涵盖于本申请的保护范围之内。 实验例:一种场景文字的轮廓拟合和校正方法,包括对场景文字的边界进行拟合,获得文字区域多边形;对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,用于场景文字识别。 具体的说:进行场景文字边界拟合时,可以输入基于分割的文字检测器输出的文字区域轮廓,比如为一个顺时针排列的有序点集 W(P,C)尽可能接近1,使拟合多边形P尽量贴合轮廓区域; P的四角尽量为直角,使拟合多边形保持文字行的形状。 具体的,如图2所示,首先可以对输入轮廓点集拟合一个最小旋转矩形,记为rbox 边界拟合过程可具体采用以下算法实现:如表1所示: 表1
如上所示,边界拟合为一递归过程,初始递归深度T=1,轮廓点集C 计算当前轮廓C 对左边部分 同理,对右边部分 为了得到目标多边形,将左右两部分拟合的结果 以上的递归拟合,可以在满足以下任一条件后终止递归拟合过程: 当前轮廓的拟合精度超过预设的第一阈值w1。 当前轮廓的拟合精度超过预设的第二阈值w2,w2 当前递归的深度达到预设的最大递归深度T_max。 当前轮廓的面积小于预设的最小面积Area_min。 为了实现端到端文字识别,可以根据拟合获得文字区域多边形;进一步对文字区域多边形对应的图像进行校正,获得包含文字的矩形区域图像,然后输入到文字识别器得到识别文字。具体的,可以采用三角网划分文字区域,并对每个三角形区域用仿射变换进行插值得到校正后的包含文字的矩形区域图像。具体步骤如下: 1)首先估计图像中文字行的文字高度和宽度,高度H 2)多边形上边线性映射到校正后矩形的上边,即多边形顶点p
其中Length(:)为计算点序列形成路径长度的函数。同样的下边映射到校正后矩形的下边。 3)得到点对的映射关系后构建三角网,对每个三角形区域分别进行仿射变换得到目标文字图像I 图4、图5显示了一个采用本申请的技术方案进行场景文字轮廓拟合和校正的例子,图4为最小旋转矩形对应的图像区域,图5为通过本申请的上述方法校正后的文字图像。 为了证明本申请的效果,发明人还做了对比试验: 在任意形状文本数据集TotalText上使用当前热门的基于分割的文字检测器PSENet和DB进行了文字检测得到文字轮廓,将文字轮廓通过本申请校正后的文字图像和直接使用RBOX提取的文字图像分别输入CRNN、STAR-Net、RARE,对最终识别精度进行对比,结果如表2所示。 表2 TotalText数据集识别率
表2中,P表示精确率(precision),R表示召回率(recall),F表示平衡F分数(F-measure)。 使用检测器DB或PSENet进行文字检测得到文字轮廓后,直接使用RBOX提取的文字图像与采用本申请进行文字轮廓拟合及校正后的文字图像,分别输入文字识别器(如STAR-Net、RARE)后,识别效果如表2所示:由表2可知:采用本申请对检测器输出的文字轮廓进一步进行拟合及矫正后,再进行文字识别,文字识别的准确率、召回率、平衡F分数均有所提高;充分说明了本申请的文字轮廓拟合和校正方法有利于文字识别器进行更准确的识别。
- 场景文字的轮廓拟合和校正方法、电子设备及存储介质
- 基于移动端的场景文字检测模型轻量化方法、电子设备及存储介质