信息处理系统以及信息处理方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明的实施方式涉及信息处理系统以及信息处理方法。本申请基于2018年11月20日在日本申请的日本特愿2018-217271号主张优先权,将其内容援用于此。
背景技术
以往,公开了一种基于通过灵活运用了神经网络的深度学习而生成的共用模型来更新模型或提高模型的精度所用的模型统筹系统相关的技术。
而且,近年来,每天都以开源等形式公开新的学习模型的生成模块、库信息。这些生成模块、库信息等有时在被志愿者组合为准确地发挥功能的状态并封装之后,公开给多数的开发者,由此节省了各个开发者的环境构建的麻烦、实现了开发的效率化。
在现有的技术中,有可能并未充分考虑在采用新的生成模块、库信息的同时实现模型开发技术的标准化。
现有技术文献
专利文献
[专利文献1]日本特开2018-147261号公报
发明内容
发明要解决的技术问题
作为本发明诞生的背景,在开发使用机器学习的服务时,存在开发者间设计不统一且质量不统一的问题点、和因开发手法、开发环境不同而难以被再利用于其他开发者制作的部件等的问题点。为了解决这些问题,希望定义了接口的“开发架构(framework)”、作为软件的部件组的“开发组件”、作为开发物的执行环境的“开发环境”这3个核心资源在开发作业序列中无人工干预而无缝连动地执行机器学习。此时,希望其输出(output)包括变更历史记录在内都被进行构成管理。虽然各资产的概念本身存在于现有技术,但没有使开发者选择想要做的事情、安装以及学习所希望的模型并对输出的模型信息进行蓄积等一气呵成地完成的机制。本发明要解决的技术问题在于,提供一种为了在组织内高质量、高效地开发模型而使与该开发相关的一系列的手工作业一气呵成地完成的模型开发基础框架。而且,提供一种能够谋求实现该模型开发基础框架的模型开发技法的标准化的信息处理系统以及信息处理方法。
用于解决技术问题的手段
本实施方式的一个方式的信息处理系统具有取得部、环境设定部、模型处理部、管理部、接口提供部、以及控制部。取得部取得进行机器学习的设计信息、以及机器学习的对象数据。环境设定部设定对所述取得部所取得的所述设计信息进行执行的架构环境以及库信息、和与所述架构环境以及库信息的版本信息对应的、对所述架构环境下的所述机器学习中的处理的执行进行辅助的软件构成。模型处理部通过使用由所述取得部取得的所述设计信息和由所述环境设定部设定的所述架构环境来执行针对所述对象数据的学习,从而生成或者更新模型。管理部将所述取得部取得的所述设计信息、与所述环境设定部设定的所述架构环境有关的信息、以及与由所述模型处理部生成或者更新的所述模型有关的信息作为开发历史记录信息进行管理。接口提供部受理来自本系统的利用者的、环境设定信息的输出指示,并向所述利用者提示推荐的设定信息,基于由所述利用者选择的设定信息,使所述环境设定部进行环境设定、或者使所述管理部输出所述开发历史记录信息。控制部使所述取得部、所述环境设定部、所述管理部以及所述接口提供部协作。
附图说明
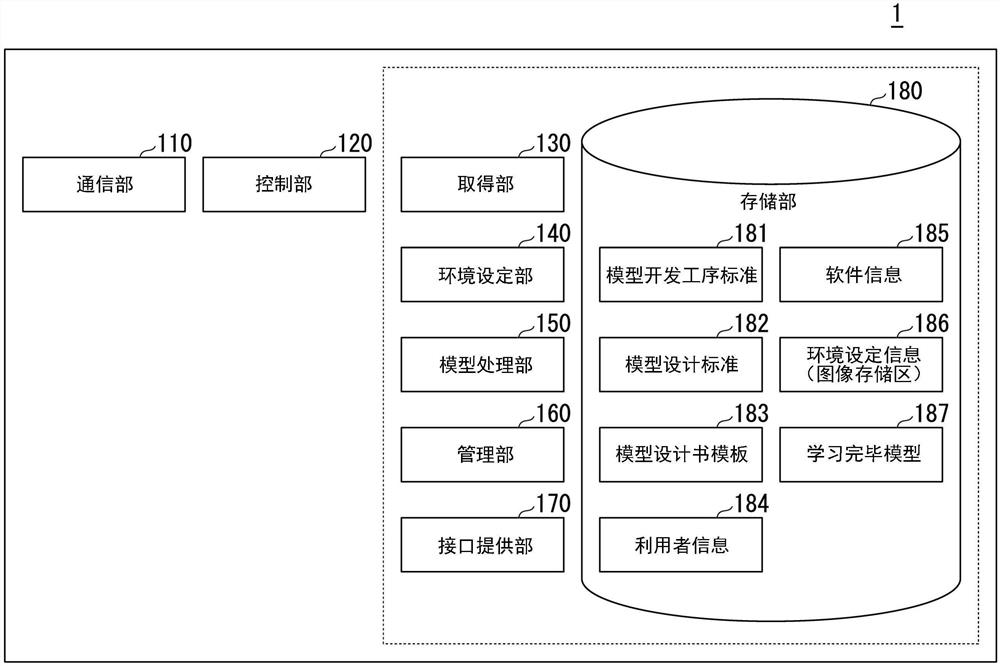
图1是表示实施方式涉及的信息处理系统1的结构的图。
图2是表示在信息处理系统1中实施的模型的学习/推断处理流程的一个例子的图。
图3是对信息处理系统1的处理的概要进行说明的图。
图4是用于对信息处理系统1的利用情形进行说明的图。
图5是表示信息处理系统1的利用情形的具体例的图。
图6是表示模型处理部150涉及的学习处理的流程的一个例子的流程图。
图7是表示虚拟化基础框架C-1的处理的流程的一个例子的流程图。
图8是表示学习完毕模型187的内容的一个例子的图。
图9是表示利用者信息184的内容的一个例子的图。
图10是表示管理部160以及接口提供部170涉及的接口提供处理的流程的一个例子的流程图。
具体实施方式
以下,参照附图对实施方式的信息处理系统以及信息处理方法进行说明。
图1是表示实施方式涉及的信息处理系统1的结构的图。信息处理系统1例如具备通信部110、控制部120、取得部130、环境设定部140、模型处理部150、管理部160、接口提供部170以及存储部180。除了模型处理部150和存储部180以外的这些构成要素的一部分或者全部可以通过CPU(Central Processing Unit)等处理器执行存储于存储部180的程序来实现。而且,控制部120的构成要素的一部分或者全部也可以由LSI(Large ScaleIntegration)、ASIC(Application Specific Integrated Circuit)、FPGA(Field-Programmable Gate Array)等硬件(电路部;包括电路(circuitry))实现,还可以通过软件与硬件的配合来实现。程序可以被预先储存于HDD(Hard Disk Drive)、闪存等存储装置(具备非易失性的存储介质的存储装置),也可以储存于DVD、CD-ROM等能够装卸的存储介质(非易失性的存储介质)并通过将存储介质装配于驱动器装置来进行安装。通过处理器执行存储于存储部180的程序,来实现控制部120的功能。
通信部110经由网络与信息处理系统1的利用者(指一般的系统的开发者,在本申请中同样)的终端装置(例如,个人计算机或平板终端)等外部装置进行通信,来进行信息的收发。网络包括LAN(Local Area Network)、WAN(Wide Area Network)因特网、专用线路、无线基站、供应商(Provider)等中的一部分或者全部。通信部110取得通过利用者的终端装置(未图示)发送的设计信息(例如,由利用者制作的编码程序)、对象数据等。而且,通信部110将由控制部120输出的学习完毕模型等向利用者的终端装置等外部装置输出。
控制部120用于控制各构成要素的信息的输入输出,更具体而言使取得部130、环境设定部140、管理部160以及接口提供部170协作。控制部120例如将由通信部110接收到的信息输出至取得部130、管理部160。而且,控制部120例如将由模型处理部150生成的学习完毕模型、由接口提供部170提供的生成学习完毕模型的开发环境的设定、开发环境的拷贝输出至通信部110,来发送给外部装置。
而且,控制部120将经由通信部110接收到的信息处理系统1的利用者的指示输出给各构成要素。进而,控制部120使定义了接口的“开发架构”、作为软件的部件组的“开发组件”、作为开发物的执行环境的“开发环境”这3个核心资源(各个核心资源的详细内容将后述)协作。控制部120在取得部130、环境设定部140所设定的学习环境的基础上,将取得部130取得的学习数据和评价数据向模型处理部150传递,来执行学习。
取得部130取得由控制部120输出的进行机器学习的设计信息以及对象数据。
此外,取得部130也可以“从其他功能部进行取得”,还可以对所取得的信息进行“自我生成/加工而取得”。取得部130例如调出后述的软件信息185来进行净化对象数据、降噪等加工,取得必要的对象数据。
环境设定部140基于由控制部120输出的与环境设定有关的利用者的指示来进行环境设定。这里,环境设定例如包括所利用的程序言语的种类、进行机器学习的OSS(OpenSource Software,开源软件)、用于进行机器学习的主机OS(Operating System)等的组合(以下,存在称为架构环境的情况)、在架构环境中参照的库信息、参数等的变更内容。环境设定部140将所设定的开发环境例如以容器形式(图像拷贝)作为环境设定信息186存储于存储部。此外,主机OS可以不是必须的。
环境设定部140可以在环境设定中基于架构环境以及库信息的版本信息来设定与架构环境以及库信息对应的OSS构成。一般,机器学习的OSS库信息种类多,根据所采用的库和库的版本,所需要的软件构成不同。环境设定部140用于在没有用户干预(或者,省略利用者的操作)的情况下实现这样的软件构成。
在从利用者没有受理到特别的希望的情况下,环境设定部140可以提供由信息处理系统1的管理者推荐的标准化的开发环境。此时,环境设定部140可以受理利用者对设定的变更的请求,并提供对接受到的变更内容进行了反映的环境设定。关于所推荐的开发环境将后述。
模型处理部150在由环境设定部140设定的环境中,生成对由取得部130取得的进行机器学习的设计信息与对象数据加以学习的模型,将所生成的模型作为学习完毕模型187存储于存储部180。以下,存在将由模型处理部150进行的这些处理称为“学习处理”的情况。
而且,模型处理部150实施使用了所生成的学习完毕模型187而得到的推断处理。关于推断处理将后述。
模型处理部150进行的学习处理、推断处理之类的运算例如通过搭载有能够实现高速的学习处理的GPU(Graphic Processing Unit)的服务器(以下,称为GPU服务器)的处理器执行存储于存储部180的程序来实现。
管理部160对设计信息、使设计信息执行的环境设定、在该环境下执行了设定信息的结果即学习完毕模型的对应关系进行管理。例如,在由环境设定部140提供了标准化的开发环境的情况下,管理部160管理利用者对该环境进行了怎样的变更。
接口提供部170基于由控制部120输出的利用者的指示来向利用者提供开发环境。详细内容将后述。
存储部180例如可以由ROM(Read Only Memory)、闪存、HDD(Hard Disk Drive)、SD卡、MRAM(Magnetoresistive Random Access Memory)等非易失性的存储介质、和RAM(Random Access Memory)、寄存器等易失性的存储介质来实现。存储部180除了存储处理器执行的程序以外,还存储控制部120的处理结果等。
存储部180例如存储模型开发工序标准181、模型设计标准182、模型设计书模板183、利用者信息184、软件信息185、环境设定信息186、学习完毕模型187等。存储于存储部180的各种信息、特别是软件信息185例如被信息处理系统1的管理者追加/更新新的OSS、存储向信息处理系统1的利用者提供的专有软件。
此外,在以下的说明中,对模型处理部150的学习处理由多层构造的神经网络实现的情况进行说明,但并不限定于此。多层构造的神经网络例如由输入层、输出层、隐藏层等构成,各层具有多个节点,各层之间通过对节点彼此的连接的强度进行表示的带权重的边缘(edge)连结。
[学习/推断处理的流程]
图2是表示在信息处理系统1中实施的机器学习模型的学习/推断处理流程的一个例子的图。
开发架构中的机器学习的学习/推断处理例如如以下所示那样由(ML1)~(ML5)这5个步骤的处理实现。图2所示的(ML1)、(ML4)以及(ML5)属于对学习处理进行说明的步骤。而且,图2所示的(ML2)以及(ML3)属于对推断处理进行说明的步骤。
(ML1)净化步骤
取得部130针对所取得的对象数据进行净化。净化例如是指实施如下处理,即:对性质不同的数据进行检测并去除的除去处理、用于消除对象数据中的错误的修正处理、不足数据的插值处理等。
(ML2)预处理步骤
取得部130通过进行使对象数据的值归一化的处理等来取得适合于机器学习的对象数据。
(ML3)推断步骤
模型处理部150从取得部130取得进行了净化以及预处理后的对象数据,进而在环境设定部140中设定了由利用者设定的环境、模型定义等的基础上,进行推断处理。模型处理部150例如根据对象数据的种类(例如,图像、传感器数据等)、分析问题(例如,回归、分类等),来对预先定义的模型定义赋予对象数据,由此输出推断结果。
(ML4)模型评价步骤
模型处理部150计算来自学习完毕模型187的输出数据与针对输入数据的教导数据(正解)之间的误差,设定对学习完毕模型187的准确性进行评价的指标。
(ML5)权重更新步骤
模型处理部150一点点地将各边缘的权重更新为适当的值以使在模型评价步骤中计算出的误差变少。
模型处理部150通过反复实施与上述的(ML3)至(ML5)的步骤相当的处理,来生成最佳的学习完毕模型187。
信息处理系统1通过将上述的(ML1)至(ML5)所示的处理流程、和与该处理流程建立了对应的开发标准(后述)提供给利用者,来实现设计的统一化。而且,信息处理系统1通过对在学习处理和推断处理双方中共同使用的模型定义、预处理等的模块进行共同管理,能够使各种模块的维护性、扩展性提高。
[信息处理系统1的处理概要]
图3是对信息处理系统1的处理的概要进行说明的图。信息处理系统1中的处理例如能够通过图3所示的(A)至(D)的工序来说明。
[开发架构]
图3所示的(A)开发架构定义有对图2所示的机器学习中的学习和推断的各处理进行装配的模块的接口。开发架构例如由学习处理A-1、预处理A-2、推断处理A-3以及模型生成处理A-4构成。利用者使用开发架构来进行模型的安装。开发架构的各处理例如由取得部130、环境设定部140、以及模型处理部150实现。进而,通过控制部120调出存储于存储部180的学习完毕模型187等来在模型处理部150中执行由开发架构生成的学习完毕模型涉及的学习处理A-1。
信息处理系统1通过提供后述的(D)开发标准,来促进开发架构中的典型的处理的设计的统一化。而且,信息处理系统1通过将能够在学习处理A-1和推断处理A-3这两个处理中共同利用的模型定义、预处理的模块从两个处理分离出来并通用,能够使维护性、扩展性提高。
[开发组件]
图3所示的(B)开发组件是在上述的开发架构中进行机器学习的情况下的对象数据的调节(conditioning)、学习方法的设定之类的、在用于生成学习完毕模型的预先准备所对应的工序中提供的功能组。例如,通过由控制部120调出软件信息185的软件来实现开发组件。
在开发组件中,例如,作为针对对象数据的预处理B-1,进行降噪处理(除去噪声的处理)、净化处理(将性质不同的数据除去、错误的修正、不足数据的插补等数据的整理等处理)等处理,作为对象数据的指教/增强处理B-2,进行数据的增加(日语:水増やし)、基于GANs(Generative Adversarial Networks:生成对抗网络)的特征提取、使用了主动学习架构的数据整理等。
而且,在开发组件中,例如受理模型学习的手法B-3(例如,有教导的学习、有半教导的学习、有自己教导的学习等)的选择、模型再利用B-4的条件设定、利用者对模型定义B-5(例如,GoogLeNet模型、ResNet模型、VGG-16模型等)的选择之类的利用者的指示。条件设定例如是指提供如下功能,即:再利用已有的学习完毕模型187的一部分来构建新的模型的手法亦即微调(Fine-tuning)、将预先进行了学习后的学习完毕模型187在其他学习中也加以利用的转移学习、将学习完毕模型187的精度压缩至不降低的程度来加以利用的模型压缩等。
此外,对于开发组件的设定而言,也可以由信息处理系统1的管理者预先设定推荐的组合,将该组合作为学习效率化B-6这一设定信息提供给利用者。例如,在由利用者选择了学习效率化B-6中的“指教数据不足应对”的情况下,提供与分别选择了由管理者设定为在指教数据不足时进行推荐的B-1~B-5的各种处理的状态等同的设定。推荐的组合例如是在迄今为止的信息处理系统1的开发中将在迄今为止的模型开发中具有实际成绩的各学习阶段的核心技术资产化而得到的组合。
通过开发组件设定的信息例如作为环境设定信息186被存储于存储部180。
[开发环境]
图3所示的(C)开发环境是由环境设定部140设定的开发环境的具体例。
一般为了执行机器学习的处理,需要在GPU服务器的主机OS上准备安装了GPU驱动器、运行时间环境、统计/机器学习库信息、机器学习所使用的OSS的库信息等的开发环境。为了能够在GPU服务器上执行多种OSS,需要管理大量的OSS库信息,所需要的软件构成根据所采用的OSS库信息、其版本信息而不同。
鉴于此,利用虚拟化基础框架来实现开发环境的标准化。例如,通过信息处理系统1的管理者将有开发实际成绩的软件构成预先设定为标准的虚拟环境图像(image),使得信息处理系统1的利用者能够省略在开发时产生的环境构建所涉及的作业。而且,由于即便例如是不习惯于机器学习、不习惯于特定的OSS的情况,信息处理系统1的利用者也能够参照其他利用者的开发实际成绩、开发环境或进行再利用,所以能够削减直到着手于开发为止的准备时间。
开发环境例如表示将虚拟化基础框架C-1、标准虚拟环境图像存储区C-2以及模型管理存储区C-3合并而得到的环境。
虚拟化基础框架C-1例如由GPU服务器、GPU服务器的主机OS、标准虚拟环境以及模型开发代码构成。标准虚拟环境例如由机器学习用的库信息、数理解析用的库信息、运行环境等构成。关于标准虚拟环境的详细情况将后述。模型开发代码是由信息处理系统1的利用者创建成的程序代码。
标准虚拟环境图像存储区C-2是保存上述的虚拟化基础框架中的标准虚拟图像的存储区。这里,标准虚拟环境图像例如通过使用由Docker(注册商标)等特定的OSS提供的被称为容器的虚拟环境来实现。环境设定部140例如使标准虚拟环境图像存储区C-2作为环境设定信息186存储于存储部180。
模型管理存储区C-3例如是模型开发代码、作为被实际装入了模型开发代码并执行了机器学习的结果而生成的学习完毕模型187、以及虚拟环境图像的组合。虚拟环境图像可以是标准虚拟环境图像存储区C-2,也可以用于存储(保存)信息处理系统1的利用者对于标准虚拟环境图像存储区C-2施加了设定变更后的开发环境的图像。
[开发标准]
图3所示的(D)开发标准是在整个过程中向信息处理系统1的利用者提供的指南、约定。开发标准例如包括模型开发工序标准181、模型设计标准182、模型设计书模板183。
在模型开发工序标准181中例如储存模型的开发步骤、和通过各步骤应该制作的成果物的定义指南。模型的开发步骤例如由作业项目名、目的、开始条件、结束条件、成为输入的成果物、作业内容、成为输出的成果物、所利用的模型设计书模板等定义。
模型设计标准182例如是基于所使用的OSS软件、开发环境的事例对上述的模型开发工序标准的作业项目和其成果物具体进行说明的指南。
模型设计书模板183例如由模型设计书的目录构成、定义了应该记述的内容的文档模板构成。按照开发工序的每个作业,决定应该制作的成果物,并定义了它们的模板。
通过提供这些开发标准,信息处理系统1的利用者能够削减模型开发中的试错所需要的时间、避免设计作业中的脱落、遗漏。而且,通过提供这些开发标准,能够通过进一步定义在机器学习开发基础框架(用于开发机器学习的模型的基础框架)以外的构成要素中应该利用的点,来实现模型开发诀窍的积累、机器学习开发基础框架的利用促进。
[利用情形]
图4是用于对信息处理系统1的利用情形进行说明的图。信息处理系统1的利用情形如图4所示,能够由导入阶段P1、构建阶段P2、运用阶段P3、维护阶段P4这4个阶段表现。
在导入阶段P1中,例如使用由信息处理系统1的利用者收集到的样本数据来进行模型设计。模型处理部150使用该设计结果来实施学习处理,进而进行推断性能评价,由此生成学习完毕模型187。
在构建阶段P2中,例如使用由信息处理系统1的利用者收集到的大规模数据来推进学习处理。模型处理部150通过向在导入阶段P1中生成的学习完毕模型187进一步反映使用了大规模数据的学习处理结果,由此提高学习完毕模型187的学习精度。
在运用阶段P3中,例如信息处理系统1的利用者基于模型数据和观测数据来进行推断处理,并基于推断结果来实施模型评价。模型处理部150根据模型评价的结果来对各边缘进行加权,并将该加权反映为学习完毕模型187的参数,进一步提高学习完毕模型187的学习精度。该时刻的学习完毕模型187例如作为向顾客提交的成果物模型被另外保存。
在维护阶段P4中,例如通过对在运用阶段P3中生成的学习完毕模型187的推断精度进行监视,来判断是否需要更新学习完毕模型187。在信息处理系统1的利用者判断为最好进行学习完毕模型187的更新的情况下,与构建阶段P2、运用阶段P3同样,进行通过模型处理部150来更新学习完毕模型187的处理。
[利用情形的具体例]
以下,按照由信息处理系统1的利用者生成的学习完毕模型187被提供给顾客为止的利用情形,对信息处理系统1的处理的流程的一个例子进行说明。图5是表示信息处理系统1的利用情形的具体例的图。
[导入阶段P1]
信息处理系统1的利用者即案件A的服务开发团队的开发者U1进行适合于案件A的模型设计。取得部130经由通信部110取得开发者U1生成的开发代码(图5(1))。
接下来,环境设定部140进行用于执行开发代码的环境构建。例如作为执行由开发者U1发送的开发代码的开发环境,环境设定部140开始由开发者U1选择的标准虚拟环境的构建(图5(2-1))。
接下来,环境设定部140例如通过受理开发者U1涉及的设定操作来进行环境设定,应用对于标准虚拟环境反映了案件A中的对象数据的特征的开发组件,来在虚拟化基础框架C-1上构建虚拟环境(图5(2―2))。
此外,在图5(2-1)以及(2―2)中,当从开发者U1没有接收到特别的指定的情况、或接收到表示开发者U1对信息处理系统1设定标准的虚拟环境这一意思的操作的情况下,接口提供部170可以输出从标准虚拟环境图像存储区选择的标准虚拟环境。
接下来,模型处理部150对虚拟化基础框架C-1配置案件A的开发代码。接下来,模型处理部150进行案件A的开发代码所对应的学习处理所用的GPU服务器的分配,并使用样本数据来开始学习处理。模型处理部150生成学习完毕模型187作为学习处理的结果(图5(2-3))。该阶段的开发代码、学习完毕模型187、虚拟化基础框架C-1被保存于模型管理存储区C-3。虚拟化基础框架C-1可以被以图像(image)形式保存。
[构建阶段P2]
模型处理部150进而使用大规模数据来进行图5(2-3)所示的学习处理,并且反映推断处理涉及的加权更新等来更新学习完毕模型187(图5(3))。更新后的学习完毕模型187、加权等设定信息可以被依次覆盖保存于模型管理存储区C-3,也可以按各自的更新阶段被保存。
[运用阶段P3]
开发者U1在判断为案件A的学习完毕模型187的学习得到推进、学习完毕模型187的输出精度充分高的情况下,将学习完毕模型187交接给服务构建担当者U2(图5(4-1))。管理部160例如受理表示将阶段移动至开发者U1的运用阶段P3的(将利用者信息184的服务构建担当者U2与案件A相关联、对服务构建担当者U2赋予公开该环境的环境设定信息186的权限等)这一意思的操作。由此,管理部160能够使服务构建担当者U2访问被保存于模型管理存储区C-3的案件A的开发代码、学习完毕模型187以及虚拟化基础框架C-1。
服务构建担当者U2例如将被保存于模型管理存储区C-3的案件A的开发代码、学习完毕模型187、以及虚拟化基础框架C-1应用于案件A的顾客用的专用环境来进行服务构建(图5(4-2)),开始向案件A的顾客提供运用/维护服务(图5(4-3))。
[维护阶段P4]
服务构建担当者U2例如对提供给案件A的顾客的学习完毕模型187的推断精度进行监视。
[处理流程学习完毕模型187的生成]
图6是表示模型处理部150涉及的学习处理的流程的一个例子的流程图。图6所示的处理例如是在图4所示的各阶段P1~P4中在学习完毕模型187的生成/更新时进行的处理。
通信部110受理信息处理系统1的利用者的学习执行指示(步骤S100)。取得部130例如可以在步骤S100的时刻取得开发代码、对象数据。接下来,模型处理部150确认GPU服务器的资源,对是否有足够的空闲资源进行判断(步骤S102)。模型处理部150在无法判断为有足够的空闲资源的情况下,待机规定时间,再次执行步骤S102。模型处理部150在判断为有足够的空闲资源的情况下,执行用于进行学习的GPU服务器的分配(步骤S104)。接下来,模型处理部150设立作为学习执行环境的虚拟化基础框架C-1(步骤S106),开始学习处理(步骤S108)。接下来,模型处理部150使存储部180存储作为学习处理的结果而被生成或者被更新的学习完毕模型187(步骤S110)。以上,结束本流程图的处理的说明。
[处理流程虚拟化基础框架设立]
图7是表示作为学习执行环境的虚拟化基础框架C-1的处理的流程的一个例子的流程图。图7属于图6的步骤S106的处理明细。
首先,模型处理部150将标准虚拟环境图像存储区C-2展开,来设置虚拟化基础框架C-1(步骤S200)。接下来,模型处理部150将虚拟化基础框架C-1启动(步骤S202)。接下来,环境设定部140通过设定参数等的变更来调整虚拟化基础框架C-1(步骤S204)。接下来,模型处理部150向调整好的虚拟化基础框架C-1装入开发代码(步骤S206)。以上,结束本流程图的处理的说明。
[接口提供]
以下,对接口提供部170涉及的处理进行说明。接口提供部170参照由管理部160输出的信息处理系统1的利用者的访问权限、和对学习完毕模型187设定的公开范围,来输出开发接口以使利用者能够容易地着手于开发。开发接口例如是由环境设定部140设定的架构环境以及库信息、包括开发代码的虚拟化基础框架C-1的图像存储区、学习完毕模型187、各种文档信息的一部分或者全部。
以下,举出具体例来进行说明。假设开发者U1结束图5所示的案件A的开发,正在进行其他的案件B的开发。而且,假设服务构建担当者U2正在实施图5所示的案件A的维护。而且,假设其他利用者U3刚刚开始信息处理系统1的利用,正要参考通过管理部160获得的信息来着手于开发。此外,假设利用者U3不是案件A以及B的相关人员来进行说明。
图8是表示环境设定信息186的内容的一个例子的图。环境设定信息186例如是将用于识别各学习完毕模型的编号与该模型的开发者、案件、模型的公开范围、利用模型、对应的标准虚拟化基础框架C-1、环境设定的变更的有无和变更内容、模型的保存目的地等信息等建立了对应而得到的信息。
图9是表示利用者信息184的内容的一个例子的图。在利用者信息184中例如按每个利用者存储有案件、和对于案件的环境设定信息186等的访问权限等。
管理部160例如受理操作指示以便输出能够由利用者U3参照的接口信息。管理部160参照环境设定信息186和利用者信息184来检索能够对利用者U3提供的接口信息。
管理部160例如将模型No.4的学习完毕模型187的接口信息作为参照图8以及图9而得到的检索信息提供给利用者U3。利用者U3能够参考这些信息、由接口提供部170提供的开发接口、模型开发工序标准181、模型设计标准182、模型设计书模板183等开发标准来着手于开发。
接口提供部170提供的接口信息例如可以是对利用者U3提供与模型No.4有关的信息的一部分或者全部,也可以使利用者U3参照开发模型No.4的虚拟化基础框架C-1。当接口提供部170例如使利用者U3参照在过去的案件中使用的虚拟化基础框架C-1的情况下,利用者U3能够使用由其他利用者反映了有开发实际成绩的软件构成后得到的虚拟化基础框架C-1,能够容易地进行环境构建操作、或在有实际成绩的开发环境下尝试学习处理。而且,利用者U3能够参照至少适用于虚拟化基础框架C-1的由开发者U1制作出的开发代码来着手于编码。
而且,管理部160例如可以通过信息处理系统1的管理者来设定想要使其他利用者优先参照的虚拟化基础框架C-1、环境设定信息186。
而且,管理部160例如可以从利用者受理对象数据的种类、问题特性作为输入信息,并参照该输入信息来显示适当的虚拟化基础框架C-1、学习完毕模型187作为推荐信息。接口提供部170例如从利用者受理“输入数据是图像数据”、“输入数据是传感器数据”等信息,并显示使用了同样的输入数据的虚拟化基础框架C-1、环境设定信息186作为推荐信息。
[处理流程接口提供]
图10是表示管理部160以及接口提供部170涉及的接口提供处理的流程的一个例子的流程图。
首先,管理部160受理利用者对推荐信息的提供请求(步骤S300)。接下来,管理部160检索利用者信息184和环境设定信息186,取得与利用者的访问权限所对应的可公开范围的开发历史记录信息相应的、环境设定信息186的检索结果(步骤S302)。接下来,管理部160将检索结果的开发历史记录信息提示给利用者(步骤S304)。接下来,接口提供部170受理利用者的接口提供请求(步骤S306)。这里受理的接口提供请求,可以是请求由利用者选择的开发历史记录信息的任意一个的拷贝环境,也可以是请求提供标准虚拟环境。接下来,接口提供部170向利用者提供所请求的开发接口(步骤S308)。以上,结束本流程图的处理的说明。
根据以上说明的至少一个实施方式,通过具有:取得部130,取得进行机器学习的开发代码等的设计信息、以及成为机器学习的对象数据的大规模数据、样本数据;环境设定部140,设定对取得部130所取得的设计信息进行执行的架构环境以及库信息所对应的虚拟化基础框架C-1、和根据架构环境以及库信息的版本信息来对机器学习的处理的执行进行辅助的软件信息185的软件构成;模型处理部150,通过使用反映了由取得部130取得的设计信息和由环境设定部140设定的架构环境的虚拟化基础框架C-1来执行针对对象数据的学习,由此生成或者更新学习完毕模型187;管理部160,作为模型管理存储区C-3等将取得部130取得的设计信息、与环境设定部140设定的架构环境有关的信息、以及与由模型处理部150生成或者更新的学习完毕模型187有关的信息作为开发历史记录信息进行管理;接口提供部170,受理来自信息处理系统1的利用者的、环境设定信息的输出指示,并向利用者提示推荐的设定信息,基于利用者所选择的设定信息来利用成为标准的虚拟化基础框架C-1;以及控制部120,控制取得部130、环境设定部140、管理部160以及接口提供部170的各构成要素的信息的输入输出而使它们协作,由此能够实现信息处理系统1的利用者对模型开发技法的标准化。
对本发明的几个实施方式进行了说明,但这些实施方式只是例示,并不意图限定发明的范围。这些实施方式能够通过其他各种方式实施,在不脱离发明主旨的范围能够进行各种省略、置换、变更。这些实施方式及其变形与包含于发明的范围、主旨同样地包含在技术方案所记载的发明及其等同的范围。
- 细胞观察信息处理系统、细胞观察信息处理方法、细胞观察信息处理程序、细胞观察信息处理系统具有的记录部和细胞观察信息处理系统具有的装置
- 信息处理系统、信息处理装置、信息处理系统的信息处理方法、记录介质和车内部共享系统