基于UV位置图与CGAN的单图像大姿态三维彩色人脸重建方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于计算机视觉领域,尤其是一种基于UV位置图与CGAN的单图像大姿态三维彩色人脸重建方法
背景技术
生物特征是近来被广泛关注和使用的一种信息特征,相应模型的重构的技术也随之社会需求的变化在不断发展。人脸所含有的丰富的特征信息,使其成为对人身份识别、表情识别、年龄性别判断等的重要载体,所以对于人脸信息的处理一直是计算机视觉领域一个重要研究课题。但是二维图像中所能保留的人脸信息很有限,而且会受拍摄角度、物体遮挡和光照角度等影响。而最近流行的三维重建技术随着机器学习技术的发展也得到了很大提升,所以运用此技术从二维图像中重建出完整的三维人脸模型可以减轻上述问题的影响,并且赋予模型更多的信息。
发明内容
现有三维人脸重建技术能使用单图像得到的三维模型,但是受到图像中人脸角度大导致重建结果误差较大,并且模型缺乏完整的表面纹理导致真实度降低。本发明提供一种基于UV位置图与CGAN的单图像大姿态三维彩色人脸重建方法,针对单图像中,大姿态人脸自遮挡导致的大量人脸不可见,导致三维人脸重建精度下降和最终结果缺少大量面部彩色纹理。本发明主要使用UV位置记录生成三维点云模型,再使用基于CGAN设计的网络补全残缺的人脸,最终获得完整彩色三维人脸模型。
为了解决上述技术问题本发明采用如下的技术方案:
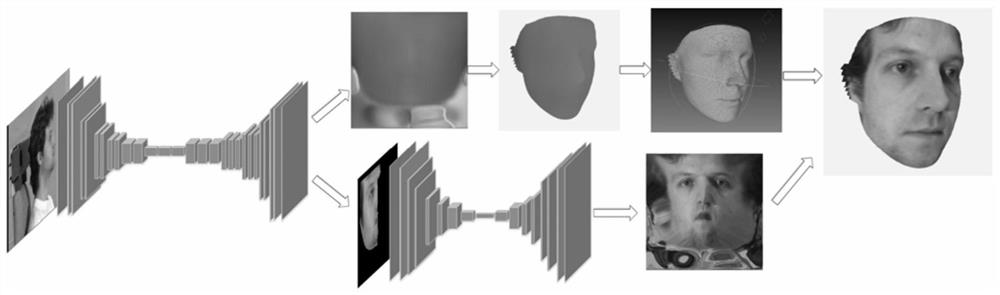
一种基于UV位置图与CGAN的单图像大姿态三维彩色人脸重建方法,包括以下步骤:
S1:采集数据
利用主动视觉法获取大量人脸的三维模型,同时拍摄下以正面人脸为0°,以5°为步长旋转范围为[-90°,-90°]的照片,分类并按照设定格式命名保存;
S2:生成UV位置图
UV图是从三维表面参数转换而来的二维图像平面,一个三维模型使用的是(X,Y,Z)坐标系统,其结构是一个点云坐标作为顶点的多边形模型,UV坐标系统的工作就是把多边形的顶点与二维图像上的像素对应起来,这样UV坐标就定义了图片上每个点的位置信息,这些点与三维模型是相互联系的,在点与点之间的间隙进行图像光滑插值处理,从而UV纹理图就可以影设到三维模型上,根据这一原理通过构建UV位置图将三维点云数据记录到二维的图像中;
S3:生成UV纹理图
在获得了UV位置图之后再使用双线性采用器,重新采样三维模型的顶点及其相关的UV坐标,将照片中的彩色纹理信息渲染到位置图中就可以获得需要的UV纹理图;但是由于自遮挡的存在,存在大面积的人脸是不可见的,造成了输出的纹理图的残缺,其中残缺部分采用黑色进行填充;
S4:构造编码-解码器网络
在编码器部分输入的256*256*3图像先通过一个核为4的卷积层,然后使用10个残差块获得其8*8*512的特征,此处不直接压缩到一维的特征向量,因为对于三维的人脸模型来说各点之间在空间中相对位置的信息,虽然这样做会导致训练难度的上升,但是保留空间位置的信息会提高重建结果的精确度;在解码器部分采用17个反卷积预测生成256*256*3的UV位置图;
S5:构造损失函数
使用均方误差计算由3DMM-STN得到的位置图P(u,v)与网络输出的UV位置
其中,(u,v)表示UV坐标系下点,P(u,v)表示真实目标图中点的位置,
S6:训练编码-解码器网络
将UV位置图作为目标值,各个角度的人脸照片作为输入到编码-解码器网络进行训练使用Adam优化器,学习率设置为0.0002,批量设置为16,最终得到的网络输出为UV位置图;接着使用一个结构简单的卷积神经网络从UV位置图中重建出人脸的三维形状,但是此时还未在其表面添加纹理细节;
S7:构造条件生成对抗网络
GAN的主要灵感来自博弈论中零和博弈的思想,应用到深度学习的神经网络上就是通过生成器G和判别器D不断进行博弈,G作为生成网器,输入为一个随机噪声x,通过这个随机噪声生成图像;D作为判别器需要判断图片是否为真实的,其输入为图片;在训练过程中G需要尽量生成真实的图片去欺骗D,而D要辨别出G生成的图片的真假,构成了一个博弈的过程,最终达到纳什均衡点;
其中,x为输入噪声其范围为概率分布p
在搭建的GAN中用残缺的UV纹理图代替噪声输入生成器,其中生成器部分采用编码器解码器结构,编码器部分为8个卷积层,解码器部分为8个反卷积层,它们的卷积核都为4,步长为2;判别器部分采用4层的卷积层,将输入图片与标签相连获取它们的特征。但是在训练GAN时常常会出现不稳定,梯度消失,模式奔溃等问题,所以根据CGAN思想,对GAN其进行一定的改进,使其能获得更好的结果。一种具有一定结果约束的深度卷积神经对抗网络,相对于GAN其生成器使用分数跨步卷积,鉴别器使用跨步卷积来替换掉所有池化层,为更深的架构移除了完全连接的隐藏层,生成器中使用ReLU作为激活函数,鉴别器中使用LeakyReLU作为激活函数;
S8:构造对抗损失函数
为了提升生成UV纹理图的真实感和纹理细节,设置了多个损失函数取加权和,分别为像素层面损失函数L
像素层面的损失函数L1采用均方误差,使在像素级别上生成图像与目标图片接近,并添加面罩P提高眼睛鼻子嘴巴部位的权重,作为提高性能的关键部分会给予高于其他损失函数的权重;
其中,W和H分别为图像的宽与高,j表示宽度上的像素点位置,k表长度上的像素点位置,x和y分别为输入图片与真实图片;
引入deepface模块此处用F表示,获取生成图与标签中人脸的特征并进行对比,从全局角度对人脸轮廓,眼鼻口位置进行确定并保持数据每个人的不同特征,使输出结果不会是一个平均相似的UV纹理图。
其中,N表示获取的特征数量,F表示图片输入deepface模块获得的结果,x和y分布表示输入图片与真实图片。
由于人脸具有对称的特性,所以采用对称损失函数,利用可见部分的先验知识,能有效的解决大姿态导致的自遮挡问题,补全单图像中无法看到的部分;在现实中自遮挡可能导致左侧或者右侧不可见,所以训练时输入的图像左遮挡右遮挡都存在;而采用对称损失函数可能会对光照造成的人脸两侧亮度不同产生误判,所以需要其他调节好与其他损失函数的权重比,不能赋予对称损失函数很大的权重。
其中,W和H分别为图像的宽与高,j表示宽度上的像素点位置,k表长度上的像素点位置,x和y分别为输入图片与真实图片。
使用对抗损失函数计算,从标签中判别生成的人脸图像的损失值,这有利于提高生成图像的真实感,降低模糊程度。
其中,G表示生成器,D表示判别器,W和H分别为图像的宽与高,j表示宽度上的像素点位置,k表长度上的像素点位置,x为输入图片。
最终的生成损失函数取上面的各损失函数的加权和。
L
其中,L
S9:训练条件对抗生成网络
以扫描得到的完整UV纹理图作为生成目标,使用残缺的UV纹理图代替噪声输入网络进行训练,使用Adam优化器,学习率设置为0.0002,得到的模型可将UV纹理图中残缺部分补全。
S10:将生成的三维人脸形状模型与UV纹理图拟合,得到最终的完整彩色的三维人脸模型。
本发明的有益效果为:解决了大姿态单人脸图像重建三维人脸模型中常出现的自遮挡问题,实现了直接从单个二维图像中生成完整真实的三维人脸模型。可以解决在人脸识别中遇到的大姿态导致识别精度下降问题,或者可用于单人脸图像生成多角度人脸图像,以增加实验数据减少复杂的数据采集。
附图说明
图1是三维彩色人脸模型生成网络结构总图。
图2是UV位置图记录三维信息原理图。
具体实施方式
下面对本发明做进一步说明。
参照图1和图2,一种基于UV位置图与CGAN的单图像大姿态三维彩色人脸重建方法,包括以下步骤:
S1:采集数据
利用激光扫描仪获取大量人脸的三维模型,同时拍摄下以正面人脸为0°,以5°为步长旋转范围为[-90°,-90°]的照片,分类并按照设定格式命名保存;
S2:生成UV位置图
一个三维模型使用的是(X,Y,Z)坐标系统,其结构是一个点云坐标作为顶点的多边形模型,UV坐标系统的工作就是把多边形的顶点与二维图像上的像素对应起来,这样UV坐标就定义了图片上每个点的位置信息,这些点与三维模型是相互联系的,在点与点之间的间隙进行图像光滑插值处理,从而UV纹理图就可以影设到三维模型上,根据这一原理我们就可以通过构建UV位置图将三维点云数据记录到二维的图像中。
S3:生成UV纹理图
在获得了UV位置图之后再使用双线性采用器,重新采样三维模型的顶点及其相关的UV坐标,将照片中的彩色纹理信息渲染到位置图中就可以获得需要的UV纹理图。
S4:构造编码-解码器网络
在编码器部分输入的256*256*3图像先通过一个核为4的卷积层,然后使用10个残差块获得其8*8*512的特征,此处不直接压缩到一维的特征向量,因为对于三维的人脸模型来说各点之间在空间中相对位置的信息,虽然这样做会导致训练难度的上升,但是保留空间位置的信息会提高重建结果的精确度。在解码器部分采用17个反卷积预测生成256*256*3的UV位置图。
S5:构造损失函数
使用均方误差计算由3DMM-STN得到的位置图P(u,v)与网络输出的UV位置
其中,(u,v)表示UV坐标系下点,P(u,v)表示真实目标图中点的位置,
S6:训练编码-解码器网络
将UV位置图作为目标值,各个角度的人脸照片作为输入到编码-解码器网络进行训练使用Adam优化器,学习率设置为0.0002,批量设置为16,最终得到的网络输出为UV位置图。接着使用一个结构简单的卷积神经网络从UV位置图中重建出人脸的三维形状,但是此时还未在其表面添加纹理细节。
S7:构造条件生成对抗网络
GAN的主要灵感来自博弈论中零和博弈的思想,应用到深度学习的神经网络上就是通过生成器G和判别器D不断进行博弈。G作为生成网器,在原论文中输入为一个随机噪声x,通过这个随机噪声生成图像;D作为判别器需要判断图片是否为真实的,其输入为图片,如y为标签图片,输出为图片为真的概率。在训练过程中G需要尽量生成真实的图片去欺骗D,而D要辨别出G生成的图片的真假,构成了一个博弈的过程,最终达到纳什均衡点。
其中,x为输入噪声其范围为概率分布p
在搭建的GAN中用残缺的UV纹理图代替噪声输入生成器,其中生成器部分采用编码器解码器结构,编码器部分为8个卷积层,解码器部分为8个反卷积层,它们的卷积核都为4,步长为2。判别器部分采用4层的卷积层,将输入图片与标签相连获取它们的特征。但是在训练GAN时常常会出现不稳定,梯度消失,模式奔溃等问题,所以根据CGAN思想,对GAN其进行一定的改进,使其能获得更好的结果。一种具有一定结果约束的深度卷积神经对抗网络,相对于GAN其生成器使用分数跨步卷积,鉴别器使用跨步卷积来替换掉所有池化层,为更深的架构移除了完全连接的隐藏层,生成器中使用ReLU作为激活函数,鉴别器中使用LeakyReLU作为激活函数。
S8:构造对抗损失函数
为了提升生成UV纹理图的真实感和纹理细节,设置了多个损失函数取加权和,分别为像素层面损失函数L
像素层面的损失函数L1采用均方误差,使在像素级别上生成图像与目标图片接近,并添加面罩P提高眼睛鼻子嘴巴部位的权重,作为提高性能的关键部分会给予高于其他损失函数的权重。
其中,W和H分别为图像的宽与高,j表示宽度上的像素点位置,k表长度上的像素点位置,x和y分别为输入图片与真实图片;
引入deepface模块此处用F表示,获取生成图与标签中人脸的特征并进行对比,从全局角度对人脸轮廓,眼鼻口位置进行确定并保持数据每个人的不同特征,使输出结果不会是一个平均相似的UV纹理图。
其中,N表示获取的特征数量,F表示图片输入deepface模块获得的结果,x和y分布表示输入图片与真实图片。
由于人脸具有对称的特性,所以采用对称损失函数,利用可见部分的先验知识,能有效的解决大姿态导致的自遮挡问题,补全单图像中无法看到的部分。在现实中自遮挡可能导致左侧或者右侧不可见,所以训练时输入的图像左遮挡右遮挡都存在。而采用对称损失函数可能会对光照造成的人脸两侧亮度不同产生误判,所以需要其他调节好与其他损失函数的权重比,不能赋予对称损失函数很大的权重。
其中,W和H分别为图像的宽与高,j表示宽度上的像素点位置,k表长度上的像素点位置,x和y分别为输入图片与真实图片。
使用对抗损失函数计算,从标签中判别生成的人脸图像的损失值,这有利于提高生成图像的真实感,降低模糊程度。
其中,G表示生成器,D表示判别器,W和H分别为图像的宽与高,j表示宽度上的像素点位置,k表长度上的像素点位置,x为输入图片。
最终的生成损失函数取上面的各损失函数的加权和。
L
其中,L
S9:训练条件对抗生成网络
以扫描得到的完整UV纹理图作为生成目标,使用残缺的UV纹理图代替噪声输入网络进行训练,使用Adam优化器,学习率设置为0.0002,得到的模型可将UV纹理图中残缺部分补全。
S10:将生成的三维人脸形状模型与UV纹理图拟合,得到最终的完整彩色的三维人脸模型。
本实施例的基于UV位置图与CGAN的单图像大姿态三维彩色人脸重建方法,解决了大姿态单人脸图像重建三维人脸模型中常出现的自遮挡问题,实现了直接从单个二维图像中生成完整真实的三维人脸模型。克服了单图像大姿态人脸重建时精度下降甚至无法正确识别人脸的不足。从而可以用于解决在人脸识别中遇到的大姿态导致识别精度下降问题,或者可用于单人脸图像生成多角度人脸图像,以增加实验数据减少复杂的数据采集。
- 基于UV位置图与CGAN的单图像大姿态三维彩色人脸重建方法
- 基于RGB单图实时人脸三维图像重建方法、装置及电子设备