一种资源调度方法以及资源调度系统
文献发布时间:2023-06-19 11:54:11
技术领域
本申请涉及计算机技术领域,尤其涉及一种资源调度方法以及资源调度系统。
背景技术
应用一般可以在至少一个节点上执行。应用在执行时产生若干进程/线程。从应用开始执行到执行完毕,在所有节点上的所有进程/线程可能大多数都会对底层的存储系统产生输入输出(input output,IO)操作,这些IO操作所涉及到的数据集合,称之为工作集(work set)。
应用在工作集上的IO操作一般是规律性的。例如,视频播放应用在其工作集上的IO操作一般是顺序读。通过对应用的IO操作规律进行归纳可以得到应用的IO模式(即IOpattern)。业界提供了一种智能缓存技术(Smart Cache,SC)探索IO模式,基于上述IO模式进行资源调度可以提高资源利用率。
具体地,SC提供一个数据智能服务(data intelligence service,DIS)组件以预测IO模式。然而,DIS组件对于IO模式的预测准确性不高。在基于DIS组件预测的IO模式进行资源调度时,一方面降低了缓存命中率,导致存储资源利用率降低以及应用执行效率降低,另一方面浪费了预测使用的算力,降低了计算资源利用率。
发明内容
本申请提供了一种资源调度方法,解决了IO模式预测不准确,进而导致资源利用降低以及应用执行效率降低的问题。
第一方面,本申请提供了一种资源调度方法。该方法可以应用于资源调度系统。资源调度系统可以从较细粒度采集应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息。其中,操作属性信息包括输入输出地址,对象属性信息包括数据对象标识。如此,资源调度系统根据上述操作属性信息和对象属性信息能够对应用进行精准地应用画像,获得应用画像信息。
基于精准的应用画像信息进行资源调度,可以提高缓存命中率,进而提高存储资源利用率以及应用执行效率。并且该方法可以避免预测不精准导致的算力浪费,提高了计算资源利用率。
可选的,资源调度系统可以包括计算节点、分析节点和调度节点。计算节点可以采集应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及数据对象的对象属性信息。分析节点可以根据操作属性信息和对象属性信息进行分析获得应用画像信息。调度节点可以根据应用画像信息调度资源。
可选的,计算节点、分析节点和调度节点中的至少两个可以部署于相同计算机设备,如此,可以减少操作属性信息、数据对象属性信息或者应用画像信息等数据的传输时延,从而提高调度效率。并且,上述部署方式可以减少传输资源开销,提高资源利用率。
可选的,计算节点、分析节点和调度节点也可以分别部署于不同的计算机设备。例如,计算节点可以部署于至少一台第一计算机设备,分析节点可以部署于至少一台第二计算机设备,调度节点可以部署于至少一台第三计算机设备,如此,可以提高整个资源调度系统的健壮性。
在一些可能的实现方式中,资源调度系统可以通过如下方式调度存储资源。具体地,资源调度系统先将应用画像信息转换成信息提示项,然后根据该信息提示项调度存储系统中的存储资源。例如,根据信息提示项提示的连续读或者跳读等信息将数据对象的对应内容添加至缓存,实现数据精确预取,避免预取多余的数据占用缓存,提高存储资源利用率。
在一些可能的实现方式中,资源调度系统采用如下方式将应用画像信息转换成信息提示项。具体地,资源调度系统可以确定与所述应用画像信息对应的信息提示模板,该信息提示模板可以是资源调度系统中内置的模式提示信息转换器提供,该模式提示信息转换器内置至少一种模式提示信息转换框架,如顺序模式提示信息转换框架、随机模式提示信息转换框架等等,每种模式提示信息转换框架可以提供对应模式的信息提示模板。如此,资源调度系统可以根据应用画像信息结合模式提示信息转换器,确定与该应用画像信息对应的信息提示模板,然后根据所述应用画像信息中各字段的字段值结合所述信息提示模板,获得信息提示项。
在一些可能的实现方式中,资源调度系统可以对不同类型存储系统的存储资源进行调度。例如,资源调度系统可以对Burst buffer、蜜蜂谷歌文件系统(bee google filesystem,BeeGFS)或者Lustre等类型的存储系统进行资源调度。每种存储系统可以支持至少一种类型的命令集。
资源调度系统可以根据所述信息提示项从所述存储系统支持的命令集中选择目标命令类型,根据所述目标命令类型和所述信息提示项中与所述目标命令类型关联字段的字段值生成至少一条命令。然后通过所述存储系统的目标接口下发所述命令,以使所述存储系统执行所述命令实现调度存储资源。如此,可以实现兼容不同类型的存储系统,支持不同类型存储系统的存储资源进行调度。
在一些可能的实现方式中,所述应用画像信息包括所述应用的输入输出操作随时间分布情况。其中,输入输出操作随时间分布情况可以通过所述输入输出操作的操作时间段和所述操作时间段内的输入输出大小表征。对应地,资源调度系统在调度资源时,可以根据应用的输入输出操作随时间分布情况调度计算资源,如此,可以均衡不同计算机设备的计算资源。
可选的,输入输出操作随时间分布情况可以通过曲线图或者柱形图形式呈现,曲线图或者柱形图的横坐标为操作时间段,纵坐标为该操作时间段内的输入输出大小。需要说明的是,输入输出操作随时间分布情况呈现的操作时间段和输入输出大小是经合并处理后的操作时间段和输入输出大小。
具体地,针对相同数据对象的输入输出操作可以按照操作时间段进行排序,相邻输入输出操作的操作时间段重叠,则将该相邻操作的操作时间段合并,将相邻输入输出操作的输入输出大小相加作为合并后的操作时间段内输入输出操作的输入输出大小。
在一些可能的实现方式中,资源调度系统可以根据所述对象属性信息确定针对相同数据对象的输入输出操作,然后根据所述针对相同数据对象的输入输出操作的操作属性信息结合至少一种识别模型,例如将所述针对相同数据对象的输入输出操作的操作属性信息输入至少一种识别模型,获取所述识别模型的识别结果作为应用画像信息。
在一些可能的实现方式中,所述至少一种识别模型包括第一模式识别模型,所述第一模式识别模型用于结合所述针对相同数据对象的输入输出操作的输入输出地址,获取所述应用的第一输入输出模式,所述第一输入输出模式包括连续信息、顺序信息、热点信息和序列信息中的任意一种或多种,所述连续信息用于标识所述输入输出操作是否连续,所述顺序信息用于标识所述输入输出操作是顺序或逆序,所述热点信息用于标识所述输入输出操作的热点区域,所述序列信息用于标识所述输入输出操作是否有序。
在一些可能的实现方式中,所述至少一种识别模型包括第二模式识别模型,所述第二模式识别模型用于结合所述针对相同数据对象的输入输出操作中相邻操作的输入输出地址,例如将针对相同数据对象的输入输出操作的输入输出地址输入第二模式识别模型,该第二模式识别模型能够自动确定相邻操作的输入输出地址,根据该相邻操作的输入输出地址获取所述应用的第二输入输出模式,所述第二输入输出模式包括概率信息,所述概率信息用于指示第二访问区域作为第一访问区域的后继访问区域的概率。
在一些可能的实现方式中,所述至少一种识别模型包括第三模式识别模型,所述第三模式识别模型用于第一输入输出模式和第二输入输出模式均未被命中时,获取所述应用的第三输入输出模式,所述第三输入输出模式包括随机信息,所述随机信息用于标识所述输入输出操作是随机输入输出操作。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括冲突域识别模型,所述冲突域识别模型用于所述操作时间段重叠且所述输入输出地址重叠时,将地址重叠区域识别为冲突域。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括时间分布识别模型,所述时间分布识别模型用于按照所述操作时间段对所述输入输出操作排序,当相邻的输入输出操作存在操作时间重叠时,合并所述相邻的输入输出操作的操作时间段,将所述相邻的输入输出操作的输入输出大小相加获得合并后的输入输出操作的输入输出大小,根据所述输入输出操作的时间段和所述输入输出大小获得所述应用的输入输出操作随时间分布情况。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述对象属性信息还包括生存时间段,所述至少一种识别模型包括生命周期识别模型,所述生命周期识别模型用于结合所述生存时间段与所述操作时间段获取所述数据对象的生命周期类型。
在一些可能的实现方式中,所述数据对象包括作业执行时产生的数据对象,所述至少一种识别模型包括重复性识别模型,所述重复性识别模型用于结合所述作业执行多次产生的数据对象的输入输出地址获取所述作业在执行时产生的数据对象是否具有大小重复性。
第二方面,本申请提供了一种资源调度方法。该方法可以应用于计算节点。具体地,计算节点采集应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息。其中,操作属性信息包括输入输出地址,对象属性信息包括数据对象标识。进一步地,计算节点还可以存储所述应用在所述作业周期内的操作属性信息以及所述数据对象的对象属性信息,该操作属性信息以及对象属性信息用于对应用进行应用画像,获得应用画像信息。
在一些可能的实现方式中,所述操作属性信息还包括所述输入输出操作所属线程的线程标识、所述输入输出操作所属进程的进程标识、所述输入输出操作所属节点的节点标识、所述输入输出操作所属任务的任务标识和所述输入输出操作所属作业标识中的任意一种或多种。
计算节点还可以根据所述数据对象标识、所述线程标识、所述进程标识、所述节点标识、所述任务标识和所述作业标识中的任意一种或多种所标识的操作属性信息进行聚类,得到数据对象级输入输出操作、线程级输入输出操作、进程级输入输出操作、节点级输入输出操作、任务级输入输出操作和/或作业级输入输出操作的操作属性信息。
在一些可能的实现方式中,所述操作属性信息还包括操作类型和操作时间段中的一种或多种,所述操作时间段通过所述输入输出操作的起始时间和结束时间表征。
在一些可能的实现方式中,所述对象属性信息还包括句柄、生存时间段中的任意一种或多种,所述生存时间段通过所述数据对象的创建时间和删除时间表征。
在一些可能的实现方式中,计算节点还可以根据所述句柄所标识的操作属性信息进行聚类,得到句柄级输入输出操作的操作属性信息。
第三方面,本申请提供了一种资源调度方法。该方法可以应用于分析节点。具体地,分析节点获取应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息。其中,所述操作属性信息包括输入输出地址,所述对象属性信息包括数据对象标识。接着,分析节点可以根据所述操作属性信息和所述对象属性信息生成应用画像信息,然后存储所述应用的应用画像信息,该应用画像信息用于执行相同作业时对调度节点调度资源进行信息提示。
在一些可能的实现方式中,分析节点可以根据对象属性信息确定针对相同数据对象的输入输出操作,然后根据针对相同数据对象的输入输出操作的操作属性信息结合至少一种识别模型,如将针对相同数据对象的输入输出操作的操作属性信息输入至少一种识别模型,获取所述识别模型的识别结果作为应用画像信息。
在一些可能的实现方式中,至少一种识别模型包括第一模式识别模型。分析节点可以根据针对相同数据对象的输入输出操作的输入输出地址结合第一模式识别模型,如将针对相同数据对象的输入输出操作的输入输出地址输入第一模式识别模型,获取第一模式识别模型输出的第一输入输出模式。该第一输入输出模式包括连续信息、顺序信息、热点信息和序列信息中的任意一种或多种,所述连续信息用于标识所述输入输出操作是否连续,所述顺序信息用于标识所述输入输出操作是顺序或逆序,所述热点信息用于标识所述输入输出操作的热点区域,所述序列信息用于标识所述输入输出操作是否有序。
在一些可能的实现方式中,至少一种识别模型包括第二模式识别模型。分析节点可以根据针对相同数据对象的输入输出操作中相邻操作的输入输出地址结合第一模式识别模型,如将针对相同数据对象的输入输出操作中相邻操作的输入输出地址输入第二模式识别模型,获取第二模式识别模型输出的第二输入输出模式。其中,第二输入输出模式包括概率信息,所述概率信息用于指示第二访问区域作为第一访问区域的后继访问区域的概率。
具体地,针对相同数据对象的输入输出操作中第i次输入输出操作,第二输入输出模型可以根据该第i次输入输出操作的输入输出地址确定第一访问区域。针对相同数据对象的输入输出操作中第i+1次输入输出操作,第二模式识别模型根据该第i+1次输入输出操作的输入输出地址确定第二访问区域。其中,i为正整数。
第二模式识别模型可以根据针对相同数据对象的输入输出操作对第一访问区域的后继访问区域进行计数得到第一数量,以及对第一访问区域之后访问第二访问区域的次数进行计数得到第二数量。然后,第二模式识别模型可以根据所述第一数量和所述第二数量确定第二访问区域作为第一访问区域的后继访问区域的概率。当该概率达到预设概率,则第二模式识别模型识别应用的第二输入输出模式为概率模式。
在一些可能的实现方式中,至少一种识别模型包括第三模式识别模型。该第三模式识别模型用于第一输入输出模式和第二输入输出模式均未被命中时,获取所述应用的第三输入输出模式,所述第三输入输出模式包括随机信息,所述随机信息用于标识所述输入输出操作是随机输入输出操作。
在一些可能的实现方式中,操作属性信息还包括操作时间段,所述至少一种识别模型包括冲突域识别模型,所述冲突域识别模型用于所述操作时间段重叠且所述输入输出地址重叠时,将地址重叠区域识别为冲突域。该冲突域可以用于指示应用的开发者更新应用,以解决输入输出操作冲突。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括时间分布识别模型,所述时间分布识别模型用于按照所述操作时间段对所述输入输出操作排序,当相邻的输入输出操作存在操作时间重叠时,合并所述相邻的输入输出操作的操作时间段,将所述相邻的输入输出操作的输入输出大小相加获得合并后的输入输出操作的输入输出大小,根据所述输入输出操作的时间段和所述输入输出大小获得所述应用的输入输出操作随时间分布情况。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述对象属性信息还包括生存时间段,所述至少一种识别模型包括生命周期识别模型,所述生命周期识别模型用于结合所述生存时间段与所述操作时间段获取所述数据对象的生命周期类型。
在一些可能的实现方式中,所述数据对象包括作业执行时产生的数据对象,所述至少一种识别模型包括重复性识别模型,所述重复性识别模型用于结合所述作业执行多次产生的数据对象的输入输出地址获取所述作业在执行时产生的数据对象是否具有大小重复性。当作业在执行时产生的数据对象具有大小重复性时,还可以根据作业在执行时产生的数据对象大小配置条带。
在一些可能的实现方式中,分析节点在对应用进行应用画像获得应用画像信息后,还可以将所述应用画像信息转换成信息提示项,以便调度节点根据所述信息提示项调度所述存储系统中的存储资源。
在一些可能的实现方式中,分析节点可以确定与所述应用画像信息对应的信息提示模板,根据所述应用画像信息中各字段的字段值结合所述信息提示模板,获得信息提示项。
第四方面,本申请提供了一种资源调度方法。该方法可以应用于调度节点。具体地,调度节点可以获取应用画像信息,该应用画像信息根据应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息生成,然后调度节点可以根据所述应用画像信息进行资源调度。
在一些可能的实现方式中,调度节点可以获取应用画像信息经转换所得的信息提示项,该信息提示项具体由分析节点确定与所述应用画像信息对应的信息提示模板,根据所述应用画像信息中各字段的字段值结合所述信息提示模板获得。对应地,调度节点可以根据所述信息提示项调度存储系统中的存储资源。例如调度节点可以根据将信息提示项的提示,将数据对象的相应部分添加至缓存,实现数据精准预取等等。
在一些可能的实现方式中,存储系统可以是不同类型的,为了兼容不同类型存储系统,调度节点可以根据信息提示项从存储系统支持的命令集中选择目标命令类型,根据目标命令类型和信息提示项中与目标命令类型关联字段的字段值生成至少一条命令,通过所述存储系统的目标接口下发所述命令,以使所述存储系统执行所述命令实现调度存储资源。基于此,可以实现分析节点和调度节点的解耦,分析节点仅需根据操作属性信息和对象属性信息获得应用画像信息,无需关注底层的存储系统的类型,调度节点可以通过将信息提示项转换为存储系统可理解的命令,从而适应不同类型存储系统。
在一些可能的实现方式中,所述应用画像信息包括所述应用的输入输出操作随时间分布情况。其中,输入输出操作随时间分布情况通过所述输入输出操作的操作时间段和所述操作时间段内的输入输出大小表征。调度节点在进行资源调度时,可以根据所述应用的输入输出操作随时间分布情况调度计算资源。
第五方面,本申请提供了一种资源调度装置,所述装置包括:
采集模块,用于采集应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息,所述操作属性信息包括输入输出地址,所述对象属性信息包括数据对象标识;
存储模块,用于存储所述操作属性信息和所述对象属性信息,所述操作属性信息和所述对象属性信息用于对所述应用进行画像。
在一些可能的实现方式中,所述操作属性信息还包括所述输入输出操作所属线程的线程标识、所述输入输出操作所属进程的进程标识、所述输入输出操作所属节点的节点标识、所述输入输出操作所属任务的任务标识和所述输入输出操作所属作业标识中的任意一种或多种;
所述装置还包括:
聚类模块,用于根据所述数据对象标识、所述线程标识、所述进程标识、所述节点标识、所述任务标识和所述作业标识中的任意一种或多种所标识的操作属性信息进行聚类,得到数据对象级输入输出操作、线程级输入输出操作、进程级输入输出操作、节点级输入输出操作、任务级输入输出操作和/或作业级输入输出操作的操作属性信息。
在一些可能的实现方式中,所述操作属性信息还包括操作类型和操作时间段中的一种或多种,所述操作时间段通过所述输入输出操作的起始时间和结束时间表征。
在一些可能的实现方式中,所述对象属性信息还包括句柄、生存时间段中的任意一种或多种,所述生存时间段通过所述数据对象的创建时间和删除时间表征。
在一些可能的实现方式中,所述装置还包括:
聚类模块,用于根据所述句柄所标识的操作属性信息进行聚类,得到句柄级输入输出操作的操作属性信息。
第六方面,本申请提供了一种资源调度装置,所述装置包括:
通信模块,用于获取应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息,所述操作属性信息包括输入输出地址,所述对象属性信息包括数据对象标识;
生成模块,用于根据所述操作属性信息和所述对象属性信息获得应用画像信息;
存储模块,用于存储所述应用画像信息,所述应用画像信息用于对调度节点调度资源进行信息提示。
在一些可能的实现方式中,所述生成模块具体用于:
根据所述针对相同数据对象的输入输出操作的操作属性信息结合至少一种识别模型,获取所述识别模型的识别结果作为应用画像信息。
在一些可能的实现方式中,所述至少一种识别模型包括第一模式识别模型,所述第一模式识别模型用于结合所述针对相同数据对象的输入输出操作的输入输出地址,获取所述应用的第一输入输出模式。
所述第一输入输出模式包括连续信息、顺序信息、热点信息和序列信息中的任意一种或多种。其中,所述连续信息用于标识所述输入输出操作是否连续,所述顺序信息用于标识所述输入输出操作是顺序或逆序,所述热点信息用于标识所述输入输出操作的热点区域,所述序列信息用于标识所述输入输出操作是否有序。
在一些可能的实现方式中,所述至少一种识别模型包括第二模式识别模型,所述第二模式识别模型用于结合所述针对相同数据对象的输入输出操作中相邻操作的输入输出地址,获取所述应用的第二输入输出模式。所述第二输入输出模式包括概率信息;其中,所述概率信息用于指示第二访问区域作为第一访问区域的后继访问区域的概率。
在一些可能的实现方式中,所述至少一种识别模型包括第三模式识别模型,所述第三模式识别模型用于第一输入输出模式和第二输入输出模式均未被命中时,获取所述应用的第三输入输出模式。所述第三输入输出模式包括随机信息,所述随机信息用于标识所述输入输出操作是随机输入输出操作。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括冲突域识别模型,所述冲突域识别模型用于所述操作时间段重叠且所述输入输出地址重叠时,将地址重叠区域识别为冲突域。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括时间分布识别模型。所述时间分布识别模型用于按照所述操作时间段对所述输入输出操作排序,当相邻的输入输出操作存在操作时间重叠时,合并所述相邻的输入输出操作的操作时间段,将所述相邻的输入输出操作的输入输出大小相加获得合并后的输入输出操作的输入输出大小,根据所述输入输出操作的时间段和所述输入输出大小获得所述应用的输入输出操作随时间分布情况。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述对象属性信息还包括生存时间段。所述至少一种识别模型包括生命周期识别模型,所述生命周期识别模型用于结合所述生存时间段与所述操作时间段获取所述数据对象的生命周期类型。
在一些可能的实现方式中,所述数据对象包括作业执行时产生的数据对象,所述至少一种识别模型包括重复性识别模型,所述重复性识别模型用于结合所述作业执行多次产生的数据对象的输入输出地址,获取所述作业在执行时产生的数据对象是否具有大小重复性。
第七方面,本申请还提供了一种资源调度装置,所述装置包括:
通信模块,用于获取应用画像信息,所述应用画像信息根据应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息获得,所述操作属性信息包输入输出地址,所述对象属性信息包括数据对象标识;
调度模块,用于根据所述应用画像信息进行资源调度。
在一些可能的实现方式中,所述通信模块具体用于:
获取所述应用画像信息经转换所得的信息提示项;
所述调度模块具体用于:
根据所述信息提示项调度所述存储系统中的存储资源。
在一些可能的实现方式中,所述调度模块具体用于:
根据所述信息提示项从所述存储系统支持的命令集中选择目标命令类型;
根据所述目标命令类型和所述信息提示项中与所述目标命令类型关联字段的字段值生成至少一条命令;
通过所述存储系统的目标接口下发所述命令,以使所述存储系统执行所述命令实现调度存储资源。
在一些可能的实现方式中,所述应用画像信息包括所述应用的输入输出操作随时间分布情况。其中,输入输出操作随时间分布情况通过所述输入输出操作的操作时间段和所述操作时间段内的输入输出大小表征。
对应地,所述调度模块具体用于:
根据所述应用的输入输出操作随时间分布情况调度计算资源。
第八方面,本申请提供了一种资源调度系统,所述资源调度系统包括至少一台第一计算机设备、至少一台第二计算机设备以及至少一台第三计算机设备;
所述至少一台第一计算机设备用于采集应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息,所述操作属性信息包括输入输出地址,所述对象属性信息包括数据对象标识;
所述至少一台第二计算机设备用于根据所述操作属性信息和所述对象属性信息,获得应用画像信息;
所述至少一台第三计算机设备用于根据所述应用画像信息进行资源调度。
可选的,每台计算机设备包括处理器和存储器。其中,所述处理器用于执行所述存储器中的指令,以执行前述资源调度方法中的步骤。
具体地,第一计算机设备的处理器用于执行所述第一计算机设备的存储器中的指令,以执行采集应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息的步骤。第二计算机设备的处理器用于执行所述第二计算机设备的存储器中的指令,以执行根据所述操作属性信息和所述对象属性信息,获得应用画像信息的步骤。第三计算机设备的处理器用于执行所述第二计算机设备的存储器中的指令,以执行根据所述应用画像信息进行资源调度的步骤。
在一些可能的实现方式中,所述至少一台第二计算机设备具体用于:
将所述应用画像信息转换成信息提示项;
所述至少一台第三计算机设备具体用于:
根据所述信息提示项调度所述存储系统中的存储资源。
在一些可能的实现方式中,所述至少一台第二计算机设备具体用于:
确定与所述应用画像信息对应的信息提示模板;
根据所述应用画像信息中各字段的字段值结合所述信息提示模板,获得信息提示项。
在一些可能的实现方式中,所述至少一台第三计算机设备具体用于:
根据所述信息提示项从所述存储系统支持的命令集中选择目标命令类型;
根据所述目标命令类型和所述信息提示项中与所述目标命令类型关联字段的字段值生成至少一条命令;
通过所述存储系统的目标接口下发所述命令,以使所述存储系统执行所述命令实现调度存储资源。
在一些可能的实现方式中,所述应用画像信息包括所述应用的输入输出操作随时间分布情况,所述输入输出操作随时间分布情况通过所述输入输出操作的操作时间段和所述操作时间段内的输入输出大小表征;
所述至少一台第三计算机设备具体用于:
根据所述应用的输入输出操作随时间分布情况调度计算资源。
在一些可能的实现方式中,所述至少一台第三计算机设备具体用于:
根据所述对象属性信息确定针对相同数据对象的输入输出操作;
根据所述针对相同数据对象的输入输出操作的操作属性信息结合至少一种识别模型,获取所述识别模型的识别结果作为应用画像信息。
在一些可能的实现方式中,所述至少一种识别模型包括第一模式识别模型,所述第一模式识别模型用于结合所述针对相同数据对象的输入输出操作的输入输出地址,获取所述应用的第一输入输出模式,所述第一输入输出模式包括连续信息、顺序信息、热点信息和序列信息中的任意一种或多种,所述连续信息用于标识所述输入输出操作是否连续,所述顺序信息用于标识所述输入输出操作是顺序或逆序,所述热点信息用于标识所述输入输出操作的热点区域,所述序列信息用于标识所述输入输出操作是否有序。
在一些可能的实现方式中,所述至少一种识别模型包括第二模式识别模型,所述第二模式识别模型用于结合所述针对相同数据对象的输入输出操作中相邻操作的输入输出地址,获取所述应用的第二输入输出模式,所述第二输入输出模式包括概率信息,所述概率信息用于指示第二访问区域作为第一访问区域的后继访问区域的概率。
在一些可能的实现方式中,所述至少一种识别模型包括第三模式识别模型,所述第三模式识别模型用于第一输入输出模式和第二输入输出模式均未被命中时,获取所述应用的第三输入输出模式,所述第三输入输出模式包括随机信息,所述随机信息用于标识所述输入输出操作是随机输入输出操作。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括冲突域识别模型,所述冲突域识别模型用于所述操作时间段重叠且所述输入输出地址重叠时,将地址重叠区域识别为冲突域。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括时间分布识别模型,所述时间分布识别模型用于按照所述操作时间段对所述输入输出操作排序,当相邻的输入输出操作存在操作时间重叠时,合并所述相邻的输入输出操作的操作时间段,将所述相邻的输入输出操作的输入输出大小相加获得合并后的输入输出操作的输入输出大小,根据所述输入输出操作的时间段和所述输入输出大小获得所述应用的输入输出操作随时间分布情况。
在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述对象属性信息还包括生存时间段,所述至少一种识别模型包括生命周期识别模型,所述生命周期识别模型用于结合所述生存时间段与所述操作时间段获取所述数据对象的生命周期类型。
在一些可能的实现方式中,所述数据对象包括作业执行时产生的数据对象,所述至少一种识别模型包括重复性识别模型,所述重复性识别模型用于结合所述作业执行多次产生的数据对象的输入输出地址获取所述作业在执行时产生的数据对象是否具有大小重复性。
第九方面,本申请提供了一种芯片,所述芯片包括处理器和芯片接口。其中,所述芯片接口用于接收指令,并传输至所述处理器。所述处理器执行上述指令以执行上述第一方面、第二方面、第三方面或第四方面中任一方面所述的资源调度方法。
第十方面,本申请提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机设备上运行时,使得计算机设备执行上述各方面所述的方法。
第十一方面,本申请提供了一种包含指令的计算机程序产品,当其在计算机设备上运行时,使得计算机设备执行上述各方面所述的方法。
本申请在上述各方面提供的实现方式的基础上,还可以进行进一步组合以提供更多实现方式。
附图说明
图1为本申请实施例中资源调度方法的系统架构图;
图2为本申请实施例中第一计算机设备的结构示意图;
图3为本申请实施例中第二计算机设备的结构示意图;
图4为本申请实施例中第三计算机设备的结构示意图;
图5为本申请实施例中计算机设备的结构示意图;
图6为本申请实施例中资源调度方法的流程图;
图7为本申请实施例中模式提示信息转换的示意图;
图8为本申请实施例中调度器的结构示意图;
图9为本申请实施例中调度节点进行资源调度的结果示意图;
图10为本申请实施例中调度节点进行资源调度的结果示意图;
图11为本申请实施例中资源调度系统的结构示意图。
具体实施方式
应用可以根据运行环境分为非分布式和分布式两种。非分布式应用也称作集中式应用,运行在集中式环境中,应用所有功能模块集中部署在中心节点,通过中心节点实现应用所有功能。分布式应用即运行在分布式环境中的应用,一般包括运行于分离的运行环境下的多个组件,这些组件可以通过网络进行协作共同实现应用所有功能。在实际应用时,可以将分布式应用部署于多台计算机设备形成的集群,从而使得分布式应用的各个组件可以运行于不同计算机设备形成的分布式环境中。
计算机设备是指任意具有计算能力的设备。在具体实现时,计算机设备可以是手机、平板电脑或者台式机等个人计算机(personal computer,PC),也可以是工作站或者服务器等。计算机设备中包括处理器,例如可以是中央处理器(central process unit,CPU)、现场可编程逻辑门阵列(field programmable gate array,FPGA)或者专用集成电路(application specific integrated circuit,ASIC)。计算机设备可以通过该处理器为用户提供计算资源。
存储系统是用于存放程序和数据的系统,该系统可以包括至少一种存储设备以及控制部件。应用的程序可以存储在存储系统中,计算机设备通过读取存储系统中的程序,运行上述应用。需要说明,存储系统可以集成于计算机设备,也可以独立于计算机设备。当存储系统独立于计算机设备时,可以令集群中的各个计算机设备共享存储系统,形成集群存储系统。
考虑到读写性能、容量以及成本等多方面的要求,存储系统中一般可以配置多级存储设备。具体地,存储系统中可以配置高速缓冲存储器(Cache,简称缓存)、主存储器(Main Memory,也称为内存储器,简称内存)和辅助存储器(Secondary Memory,也称为外存储器,简称外存)。
存储系统通过上述存储器提供不同存储资源。具体地,内存可由计算机设备的处理器直接访问,直接为处理器提供数据和指令,并存入处理器处理后的数据,其读写速度快,但容量相对较小;外存不能由处理器直接访问,因此主要用于存放处理器暂时不用的数据和程序,其读写速度稍逊于内存,但容量相对较大;缓存位于处理器和内存之间,用于解决处理器运算速度和内存读写速度不匹配的问题,具体地,在缓存中存储处理器将访问的数据,该数据属于内存中数据的一部分,当处理器要读取数据时,首先从缓存中进行查找,若查找成功,则立即读取数据并送至处理器进行处理,若查找失败,则再从内存中读取。
为了提高应用执行过程中的资源利用率和应用执行效率,业界提出了一种基于DIS组件对数据访问规律进行预测,然后根据预测结果触发预先加载等手段的方法。然而上述预测过程是建立在一个短期的时间窗上,DIS组件对应用使用数据的规律和模式很容易以偏概权,如此导致预测准确度不高。尤其是在复杂场景下,DIS组件预测准确性大打折扣。在进行资源调度时,如果按照上述规律和模式调度缓存等存储资源,可以导致缓存命中率降低,如此降低了存储资源利用率以及应用执行效率,而且浪费了预测使用的算力,降低了计算资源利用率。
基于此,本申请实施例提供了一种资源调度方法,该方法支持细粒度地采集应用在作业周期对存储系统中数据对象的IO操作的操作属性信息和数据对象的对象属性信息,通过应用在整个作业周期对存储系统中数据对象的IO操作进行应用画像,得到更高层次、更全局的应用画像信息,基于该全局的应用画像信息进行资源调度,可以提高资源利用率和应用执行效率。
具体地,将应用画像信息传递至存储系统,指导存储系统更有效地存储工作集数据,提高缓存命中率,从而提升存储资源利用率以及应用执行效率,并且避免了算力浪费,提升了计算资源利用率。在一些情况下,也可以直接根据应用画像信息调度计算机设备提供的计算资源,提高计算资源的利用率。
下面结合附图,对本申请的实施例进行描述。本申请实施例提供的资源调度方法可以应用于包括但不限于如图1所示的应用环境中。
如图1所示,集群100中包括多个计算节点102,多个计算节点102与存储系统104连接。针对用户端提交的作业(本申请称之为job),调度节点108可以将job划分成多个任务(本申请称之为task),并将多个task分配到多个计算节点102上执行,当所有task执行完毕则表征job执行完毕。
其中,job开始执行至执行完毕的时间段可以称之为一个作业周期。在该作业周期内,运行在计算节点102的应用生成应用进程。应用可以基于应用进程产生对存储系统104中数据对象的IO操作。多个计算节点102可以采集该计算节点上应用在作业周期内对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息。其中一个计算节点102可以作为汇总节点,对多个计算节点102采集的信息进行汇总得到应用在作业周期内对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息,并将其存储至存储系统104中。
需要说明的是,应用产生IO操作所对应的存储系统104与存储操作属性信息和对象属性信息的存储系统104可以是同一存储系统,也可以是不同存储系统。当然,汇总节点也可以是独立于计算集群100的节点。为了便于理解,本申请以计算集群100中的一个计算节点102作为汇总节点进行示例说明。
分析节点106可以从存储系统104获取应用在作业周期对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息,根据操作属性信息和对象属性信息对应用进行应用画像,获得应用画像信息。然后分析节点106可以存储该应用的应用画像信息,例如,分析节点106可以将上述应用画像信息存储至存储系统104。
如此,调度节点108再次接收到作业时,可以根据该作业的作业标识判断该作业是否为上述应用画像过程中所使用作业的相同作业或相似作业,若是,则可以根据作业标识从存储系统104中获取相应的应用画像信息,然后调度节点108根据该应用画像信息进行资源调度。例如,调度节点108可以根据该应用画像信息中应用的IO操作随时间分布情况调度计算节点的计算资源。又例如,调度节点108可以获取根据应用画像信息经转换所得信息提示项(本申请称之为hint entry),根据hint entry调度存储系统104中的存储资源。如此,存储系统104可以精准获取数据,将其加载至缓存,从而实现数据精准预取。
需要说明的是,计算节点102、分析节点106和调度节点108可以通过计算机设备实现。存储系统104可以通过具有存储功能的计算机设备实现,也可以通过机械硬盘(harddisk drive,HDD)和/或固态硬盘(solid state drive,SDD)等存储设备实现。其中,计算节点102、分析节点106和调度节点108可以部署于相同计算机设备,如此,可以减少传输开销,提高调度效率。当然,计算节点102、分析节点106和调度节点108也可以部署于不同计算机设备,如此可以提高整个资源调度系统的健壮性。
图1是以计算节点102、分析节点106和调度节点108分别部署于不同计算机设备进行示例说明的,在实际应用时,上述节点也可以部署在相同计算机设备,或者部分部署在相同计算机设备。此外,图1中计算节点102包括多个,在一些示例中,计算节点102也可以包括一个。
为了方便描述,本申请将部署计算节点102的计算机设备称作第一计算机设备,部署分析节点106的计算机设备称作第二计算机设备,部署调度节点的计算机设备称作第三计算机设备。第一计算机设备具有存储功能,如具有处理器缓存或者能够持久化存储的非易失性存储器时,计算节点102也可以在本地存储操作属性信息和对象属性信息,如此,分析节点106可以直接从计算节点102获取操作属性信息和对象属性信息进行应用画像。同理,第二计算机设备具有存储功能时,分析节点106也可以将应用画像信息存储在本地,如此,调度节点108可以从分析节点106获取应用画像信息,根据该应用画像信息进行资源调度。
图2至图4分别示出了第一计算机设备200、第二计算机设备300和第三计算机设备400的结构示意图。应理解,图2至图4仅仅示出了上述计算机设备中的部分硬件结果和部分软件模块,具体实现时,第一计算机设备200、第二计算机设备300和第三计算机设备400还可以包括更多的硬件结构,如扬声器、显示器等等,以及更多的软件模块,如各种应用程序等。
如图2所示,第一计算机设备200包括总线201、处理器202、通信接口203和存储器204。处理器202、存储器204和通信接口203之间通过总线201通信。总线201可以是外设部件互连标准(peripheral component interconnect,PCI)总线、快捷外设部件互连标准(peripheral component interconnect express,PCIe)或扩展工业标准结构(extendedindustry standard architecture,EISA)总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,图2中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。通信接口203用于与外部通信,例如接收IO操作的操作属性信息和对象属性信息等等。
其中,处理器202可以为中央处理器(central processing unit,CPU)。存储器204可以包括易失性存储器(volatile memory),例如随机存取存储器(random accessmemory,RAM)。存储器204还可以包括非易失性存储器(non-volatile memory),例如只读存储器(read-only memory,ROM),快闪存储器,HDD或SSD。
存储器204中存储有程序或指令,例如实现采集模块功能所需的程序或指令,处理器202执行该程序或指令以执行前述资源调度方法。当然,存储器204中还可以存储数据,例如存储采集模块采集的数据,具体为应用在作业周期对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息。
如图3所示,第二计算机设备300包括总线301、处理器302、通信接口303和存储器304。处理器302、存储器304和通信接口303之间通过总线301通信。存储器304中存储有程序或指令,例如实现分析模块功能所需的程序或指令。分析模块中可以包括至少一个识别模型,对应地,存储器304中存储有至少一个识别模型对应的程序或指令。处理器302执行该程序或指令以执行前述资源调度方法。当然,存储器304中还可以存储数据,例如存储分析模块分析所得数据,具体为分析模块根据操作属性信息和对象属性信息对应用进行应用画像所得应用画像信息。
如图4所示,第三计算机设备400包括总线401、处理器402、通信接口403和存储器404。处理器402、存储器404和通信接口403之间通过总线401通信。存储器404中存储有程序或指令,例如实现调度模块功能所需的程序或指令。处理器402执行该程序或指令以执行前述资源调度方法。
还需要说明的是,本申请实施例还示出了计算节点102、分析节点106和调度节点108部署在相同计算机设备上时,该计算机设备的结构示意图。如图5所示,计算机设备500包括总线501、处理器502、通信接口503和存储器504。处理器502、存储器504和通信接口503之间通过总线501通信。存储器504中存储有程序或指令,例如,实现采集模块、分析模块和调度模块功能所需的程序或指令。处理器502执行该程序或指令以执行前述资源调度方法。
在一些可能的实现方式中,上述计算节点102、分析节点106和调度节点108的功能还可以通过一个或多个芯片实现。每个芯片包括处理器和芯片接口。其中,芯片接口用于接收指令,并传输至处理器。处理器执行上述指令以执行前述资源调度方法的步骤。当然,上述计算节点102、分析节点106和调度节点108的功能采用多个芯片实现时,每个芯片的芯片接口接收部分指令,每个芯片的处理器根据上述部分指令执行前述资源调度方法的部分步骤,如此,多个处理器可以实现执行资源调度方法的全部步骤。
为了使得本申请的技术方案更加清楚、易于理解,下面将以计算节点102部署在上述第一计算机设备200、分析节点106部署在上述第二计算机设备300、调度节点108部署在上述第三计算机设备400为例,从计算节点102、存储系统104、分析节点106和调度节点108交互的角度,对本申请实施例的资源调度方法进行详细说明。
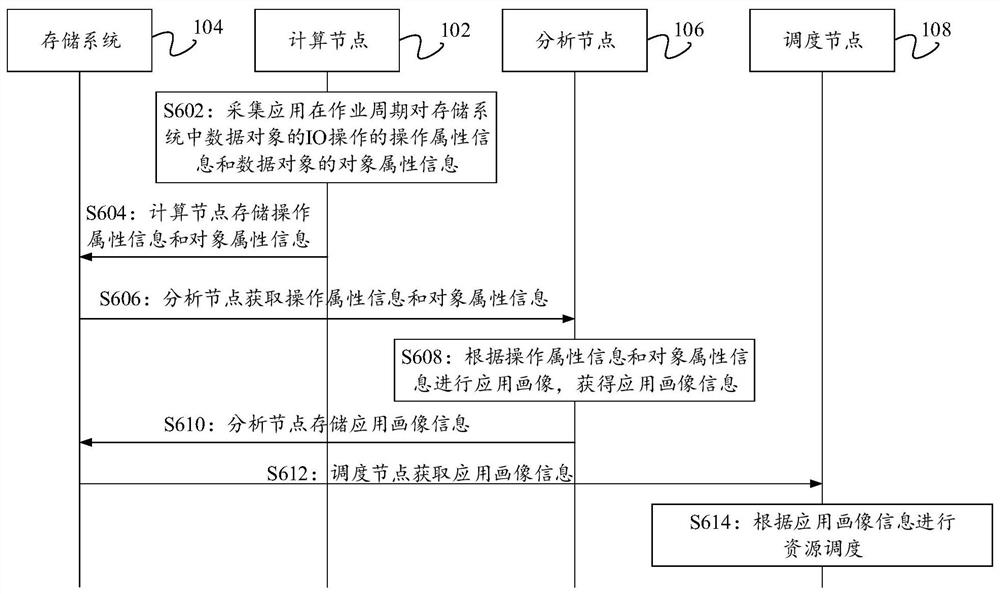
参见图6所示的资源调度方法的流程图,该方法包括:
S602:计算节点102采集应用在作业周期对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息。
数据对象具体是能被计算节点102识别,并输入给计算节点102处理的符号集合。基于不同数据组织形式,数据对象可以是文件(file)、块(block)或者对象(object)等。应用在运行时,常常需要从存储系统104中获取数据对象进行运算,然后输出运算结果,或者向存储系统104写入数据对象,如此产生了对数据对象的输入输出操作,即IO操作。
在具体实现时,计算节点102可以通过驻留在应用层的IO记录器(recorder)采集应用在作业周期对存储系统104中数据对象的IO操作。其中,IO recorder可以通过任意IO跟踪工具实现。计算集群100中的一个计算节点102可以汇总该计算集群100中各计算节点102采集的信息,得到应用在作业周期对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息。
具体地,针对应用在作业周期内的每次IO操作,计算节点102通过IO recorder采集该IO操作的操作属性信息以及该IO操作所针对数据对象的对象属性信息。其中,操作属性信息用于描述操作特征,具体可以包括IO地址。在具体实现时,IO地址可以通过起始地址(即offset)和IO大小(即lens,也称作IO Size)进行标识,在有些情况下,IO地址也可以通过起始地址和结束地址进行标识。对象属性信息用于描述数据对象特征,具体可以包括数据对象标识。数据对象标识可以是数据对象的名称等唯一性标识。
在一个时间段内,一个数据对象可能被多个应用打开,或者被一个应用打开多次。如此可以产生多个打开的句柄(handle)。其中,句柄可以理解为应用引用存储系统104中的数据对象时所使用的指针。为了区分不同句柄的IO行为,IO recorder采集的对象属性信息还可以包括数据对象的句柄。进一步地,计算节点102在汇总计算集群100中多个计算节点102采集的信息后,还可以根据句柄进行行为属性信息聚类,得到句柄级IO行为的行为属性信息。
同理,为了区分不同线程、不同进程、不同节点、不同任务或者不同作业的IO操作,IO recorder采集的操作属性信息还可以包括IO操作所属线程的线程标识、IO操作所属进程的进程标识、IO操作所属节点的节点标识、IO操作所属任务的任务标识和IO操作所属作业的作业标识中的任意一种或多种。
对应地,IO recorder不仅可以按照数据对象标识对IO操作进行聚类,得到数据对象级IO操作;还可以按照线程标识、进程标识、节点标识、任务标识和作业标识中的任意一种进行IO操作聚类得到线程级IO操作、进程级IO操作、节点级IO操作、任务级IO操作和作业级IO操作中的任意一种或多种。
为了便于理解,下面结合具体示例进行说明。例如,应用在作业周期内产生10次IO操作,4次IO操作所属线程的线程标识为0001,3次IO操作所属线程的线程标识为0002,3次IO操作所属线程的线程标识为0003,则可以将线程标识为0001的4次IO操作聚集为一类,线程标识为0002的3次IO操作聚集为一类,线程标识为0003的3次IO操作聚集为一类,从而得到线程级IO操作。
在一些可能的实现方式中,IO recorder采集的操作属性信息还可以包括操作类型和操作时间段中的一种或多种。其中,操作类型具体是指IO操作的类型,例如可以是打开、创建、读、写或者关闭等。操作时间段通过IO操作的起始时间和结束时间表征。操作时间段可以用于对IO操作随时间分布情况进行分析。
IO recorder采集的对象属性信息还可以包括生存时间段。其中,生存时间段通过数据对象的创建时间和删除时间表征。当数据对象包括作业执行时产生的数据对象时,IOrecorder可以采集作业执行多次产生的数据对象的输入输出地址,用于对作业执行时产生的数据对象是否具有大小重复性进行分析。
S604:计算节点102存储所述应用在所述作业周期内的操作属性信息以及所述数据对象的对象属性信息。
计算节点102可以将应用在作业周期内对存储系统104中数据对象的IO操作的操作属性信息和数据对象的对象属性信息存储至存储系统104。进一步地,计算节点102在存储操作属性信息和对象属性信息时,还可以存储操作属性信息和对象属性信息的对应关系。
在具体实现时,计算节点102可以将操作属性信息和对象属性信息写入IO日志文件,将IO日志文件存储至存储系统104中。需要说明,存储操作属性信息和对象属性信息的存储系统104与IO操作所针对的存储系统104可以是同一存储系统,也可以是不同存储系统。
应理解,在一些实施例中,执行资源调度方法也可以不执行S604。
S606:分析节点106获取应用在作业周期对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息。
作业执行完毕时,分析节点106可以从存储系统104中获取应用在作业周期对存储系统104中数据对象的IO操作的操作属性信息以及数据对象的对象属性信息,以便基于该操作属性信息和对象属性信息进行应用画像。
S608:分析节点106根据操作属性信息和对象属性信息对应用进行应用画像,获得应用画像信息。
应用画像是指从至少一个维度描述应用,应用画像信息是指从至少一个维度描述应用的信息。在具体实现时,分析节点106可以从IO维度描述应用,基于此,应用画像信息可以包括应用的IO模式,也即应用访问数据对象的模式。
其中,应用访问数据对象中一段连续的内容则称之为连续模式,应用访问数据对象中不连续的内容则称之为非连续模式。应用按照地址由小到大的顺序访问数据对象中的内容则称之为顺序模式,应用按照地址由大到小的顺序访问数据对象中的内容则称之为逆序模式。应用访问数据对象中相同内容的频次达到预设频次,则称之为热点模式。应用访问数据对象中内容有序,则称为有序模式。应用访问数据对象中一个区域的内容后访问另一个区域的内容的概率达到预设概率,则称之为概率模式。若以上模式均未命中,则可以将应用访问数据对象的模式确定为随机模式。
在具体实现时,分析节点106可以通过分析模块中的至少一个识别模型对应用进行应用画像。具体地,分析节点106可以根据对象属性信息确定针对相同数据对象的IO操作,然后将针对相同数据对象的IO操作的操作属性信息输入至少一种识别模型,获取识别模型的识别结果作为应用画像信息。
在一些可能的实现方式中,分析节点106可以将针对相同数据对象的IO操作的IO地址输入模式识别模型,例如可以是第一模式识别模型,识别应用的第一IO模式。其中,第一模式识别模型的识别原理是基于针对相同数据对象的IO操作的起始地址和结束地址识别IO模式是否为连续/非连续模式、顺序模式/逆序模式、热点模式和/或有序模式。
对应地,第一IO模式可以包括连续信息、顺序信息、热点信息和序列信息中的任意一种或多种,所述连续信息用于标识所述输入输出操作是否连续,所述顺序信息用于标识所述输入输出操作是顺序或逆序,所述热点信息用于标识所述输入输出操作的热点区域,所述序列信息用于标识所述输入输出操作是否有序。
第一模式识别模型可以基于每次IO操作的结束地址和下一次IO操作的起始地址确定出IO操作是连续或者非连续。具体地,每次IO操作的结束地址等于下一次IO操作的起始地址时,则确定IO操作是连续。至少有一次IO操作的结束地址不等于下一次IO操作的起始地址时,则确定IO操作是非连续。
第一模式识别模型可以基于每次IO操作的起始地址和结束地址确定出IO操作是顺序或逆序。具体地,每次IO操作的起始地址均小于或等于结束地址,且任一次IO操作的结束地址小于或等于下一次IO操作的起始地址,则可以确定出IO操作是顺序。每次IO操作的起始地址均大于或等于结束地址,且任一次IO操作的起始地址小于或等于上一次IO操作的结束地址,则确定出IO操作是逆序。
第一模式识别模型还可以基于每次IO操作的起始地址和结束地址确定出IO操作的热点区域。具体地,针对相同数据对象的IO操作,分析节点106可以根据IO地址(offset)对IO操作进行排序,如按照offset升序排序,若存在IO操作的offset和lens相同,则表明是对相同区域进行IO。分析节点106可以对相同区域去重,并累计该相同区域对应的IO操作次数。进一步地,若存在相同次数的连续区域,还可以对该连续区域进行合并。接着,分析节点106可以将IO操作次数最多或者排序靠前的区域确定为热点区域。
第一模式识别模型还可以基于每次IO操作的起始地址和结束地址确定出IO操作是否有序。具体地,针对相同数据对象的IO操作,第一模式识别模型获取IO操作的起始地址组成的数列,若该数列组成等差数列,且IO操作的结束地址组成的数列也组成等差数列,则确定IO操作有序。
在一些可能的实现方式中,分析节点106以将针对相同数据对象的IO操作的IO地址输入模式识别模型,例如可以是第二模式识别模型,该第二模式识别模型能够对相邻两次IO操作的IO地址进行分析,识别应用的第二IO模式。其中,第二模式识别模型的识别原理是基于针对相同数据对象的IO操作中相邻两次操作的起始地址和结束地址确定相邻两次IO操作是否规律。具体是根据相邻两次操作的起始地址和结束地址确定应用在访问某一区域后是否有较大几率访问另一区域。
对应地,第二输入输出模式包括概率信息,所述概率信息用于指示第二访问区域作为第一访问区域的后继访问区域的概率。其中,第一访问区域是在先IO操作对应于数据对象的一个区域,第二访问区域是在后IO操作对应于数据对象的一个区域。
为了便于理解,下面进行详细说明。针对相同数据对象的IO操作中第i次IO操作,第二模式识别模型根据该第i次IO操作的IO地址确定第一访问区域。类似地,针对相同数据对象的IO操作中第i+1次IO操作,第二模式识别模型根据该第i+1次IO操作的IO地址确定第二访问区域。其中,i为正整数。
第二模式识别模型可以根据相同数据对象的IO操作对第一访问区域的后继访问区域进行计数得到第一数量,以及对第一访问区域之后访问第二访问区域的次数进行计数得到第二数量。然后,第二模式识别模型可以根据所述第一数量和所述第二数量确定第二访问区域作为第一访问区域的后继访问区域的概率。具体地,分析节点106可以将第二数量和第一数量的比值确定为第二访问区域作为第一访问区域的后继访问区域的概率。当该概率达到预设概率,如达到0.8时,则第二模式识别模型识别应用的第二IO模式为概率模式。
当然,第一IO模式和第二IO模式均未被命中时,也即该应用的IO模式不属于顺序连续模式、顺序非连续模式、逆序连续模式、逆序非连续模式、热点模式、有序模式或者概率模式中的任一种模式时,分析节点106可以通过第三模式识别模型识别应用的第三IO模式。其中,第三IO模式包括随机信息,该随机信息用于标识所述IO操作是随机IO操作。
在一些可能的实现方式中,操作属性信息还可以包括操作时间段和/或操作类型等,对象属性信息还可以包括数据对象的生存时间段。对应地,应用画像信息也可以包括冲突域、IO操作随时间分布情况、数据对象的生命周期类型和作业执行时产生数据对象大小中的任意一种或多种。
在一些实现方式中,分析节点106可以将IO地址和操作时间段输入冲突域识别模型,通过冲突域识别模型识别冲突域。所谓冲突域可以理解为IO操作发生冲突的区域。冲突域识别模型的识别原理是,若操作时间段重叠(包括部分重叠或者完全重叠),且IO地址也存在重叠,则有较高的概率发生IO操作冲突。该冲突域识别模型可以将地址重叠部分对应区域即地址重叠区域识别为冲突域。该冲突域可以用于指示应用的开发者对应用进行优化。
在一些实现方式中,分析节点106可以将IO地址和操作时间段输入时间分布识别模型,通过时间分布识别模型识别IO操作随时间分布情况。其中,时间分布识别模型的识别原理是按照操作时间段对所述IO操作排序,当相邻的IO操作存在操作时间重叠时,合并所述相邻的IO操作的操作时间段,将所述相邻的IO操作的IO大小相加获得合并后的IO操作的IO大小,根据所述IO操作的操作时间段和所述IO大小获得所述应用的IO操作随时间分布情况。在另一些实现方式中,分析节点106可以将操作时间段和生存时间段输入生命周期识别模型,通过该生命周期识别模型识别数据对象的生命周期类型,即识别数据对象的生命周期长短,确定数据对象是否为临时数据对象。其中,操作时间段可以通过IO操作的起始时间和结束时间表征。生存时间段可以通过数据对象的创建时间和删除时间表征。生命周期识别模型可以根据应用在作业周期对存储系统104中数据对象的IO操作的操作时间段确定作业起始时间和作业结束时间;根据作业起始时间、作业结束时间和数据对象的创建时间、数据对象的删除时间确定数据对象的生命周期类型。
具体地,作业起始时间可以记作X,作业结束时间可以记作Y,数据对象的创建时间记作N,数据对象的删除时间记作M。当X<=N 在另一些可能的实现方式中,数据对象包括作业执行时产生数据对象,分析节点106可以将作业执行多次产生的数据对象的IO地址输入重复性识别模型,通过该重复性识别模型识别作业执行时产生的数据对象是否具有大小重复性。其中,重复性识别模型的识别原理具体是基于作业执行多次产生的数据对象的IO地址确定作业执行多次产生的数据对象的大小,并基于作业执行多次产生的多个数据对象的大小组成的数列识别作业执行时产生数据对象是否具有大小重复性。 在一些实现方式中,若数列趋于收敛,则可以确定作业执行时产生数据对象具有大小重复性。在此种情形下,重复性识别模型可以输出作业执行时产生数据对象大小作为应用画像信息。其中,重复性识别模型输出的作业执行时产生数据对象大小可以是上述数列的收敛值。在另一些实现方式中,若数列的方差小于预设值,也可以确定作业执行时产生数据对象大小具有大小重复性。在此种情形下,重复性识别模型输出的作业执行时产生数据对象大小可以是上述数列的平均值。需要说明的是,在一些可能的实现方式中,重复性识别模型输出的作业执行时产生数据对象大小可以是上述数列的最大值、最小值或者中位值。 S610:分析节点106存储应用的应用画像信息。 分析节点106可以在存储系统104中存储应用的应用画像信息。当然,在一些实现方式中,分析节点106也可以在本地存储应用的应用画像信息。需要说明的是,分析节点106存储应用画像信息时,还可以存储作业标识和应用画像信息的对应关系,以便后续执行相同作业时,可以直接基于该对应关系获取应用画像信息。 应理解,在一些实施例中,执行资源调度方法也可以不执行S610。 在本申请中,分析节点106分析操作属性信息和对象属性信息是为了对应用画像,以便基于应用画像信息调度资源。为此,分析节点106还可以将应用的应用画像信息转换成信息提示项(hint entry),以便调度节点108通过读取信息提示项进行资源调度。 在具体实现时,分析节点106可以根据应用画像信息确定与该应用画像信息对应的信息提示模板。信息提示模板具体是指信息提示项的模板,通过在模板中填入对应的字段值,例如来自于应用画像信息中各字段的字段值,可以获得信息提示项。 在一些可能的实现方式中,如应用画像信息包括IO模式时,分析节点106可以通过模式提示信息转换器将应用画像信息转换为对应的hint entry。如图7所示,模式提示信息转换器包括至少一种模式提示信息转换框架。模式提示信息转换框架可以包括顺序模式提示信息转换框架、随机模式提示信息转换框架、共享模式提示信息转换框架、独享模式提示信息转换框架或者临时文件(tmpfile)模式提示信息转换框架中的一种或多种,每种模式提示信息转换框架可以提供一种IO模式对应的信息提示模板。分析节点106可以根据应用画像信息,从至少一种模式提示信息转换框架中确定与该应用画像信息对应的模式提示信息转换框架,进而基于该模式提示信息转换框架提供的信息提示模板,结合应用画像信息中各字段的字段值生成hint entry。 需要说明,一种IO模式可以转换成一个hint entry,也可能转换成多个hintentry。如图7所示,应用的工作集可以包括文件A、文件B和文件C等三个数据对象,每个数据对象可以有至少一种IO模式。例如,对于文件A存在IO模式1和IO模式2种IO模式。将各数据对象的IO模式形成的IO模式集输入模式提示信息转换器,该模式提示信息转换器能够基于模式提示信息转换框架提供的信息提示模板,对应用画像信息进行转换,生成对应的hintentry。例如,针对文件A的2种IO模式可以按照上述方式转换成3个hint entry,即hint1、hint2和hint3,其中,一种IO模式转换成一个hint entry,另一种IO模式转换成2个hintentry。文件B和文件C的转换过程与文件A类似,在此不再赘述。 进一步地,分析节点106还可以在本地或存储系统104存储上述hint entry,以便后续执行相同或相似的作业时,能够根据上述hint entry进行资源调度,提高资源利用率和应用执行效率。 S612:调度节点108获取应用的应用画像信息。 调度节点108可以直接获取应用的应用画像信息。在有些情况下,调度节点108也可以获取应用画像信息转换生成的hint entry。 S614:调度节点108根据应用画像信息进行资源调度。 具体地,应用画像信息包括所述应用的IO操作随时间分布情况时,调度节点108可以直接根据所述应用的IO操作随时间分布情况调度计算节点102的计算资源。通过均衡多个计算节点102的计算资源,可以提高计算资源的利用率。 当然,调度节点108也可以根据hint entry对存储系统104进行信息提示,进而实现存储资源调度。考虑到存储系统104可以包括多种类型,例如可以包括Burst buffer、BeeGFS或者Lustre等多种类型,调度节点108在解析hint entry时,可以根据该hint entry从存储系统104支持的命令集中选择目标命令类型。例如,调度节点108可以选择目标命令类型willread。接着,调度节点108根据所述目标命令类型和所述信息提示项中与所述目标命令类型关联字段的字段值生成至少一条命令。 如信息提示项中提示IO模式为顺序非连续(字段mode),起始地址(字段begin)为0,结束地址(字段end)为77824,步长(字段stride)为4096,IO大小(字段block)为4096,则调度节点108可以根据上述目标命令类型和信息提示项中与目标命令类型关联字段,如mode、begin、end、stride和block的字段值生成多条命令,该多条命令可以表示为xxx---willread-s 0-e 4096---xxx,xxx---willread-s8192-e12288。其中,命令中xxx为省略的字段,第一条命令表示应用将要读取地址范围为0-4096的内容,第二个命令表示应用将要读取地址范围为8192-12288的内容。 调度节点108还通过存储系统104的目标接口下发所述命令,如此实现对存储系统104的信息提示,进而实现存储资源调度。例如,调度节点108可以下发上述命令,以使存储系统104将地址范围为0-4096的内容以及地址范围为8192-12288的内容添加至缓存,以便应用实现数据精确预取,避免预取多余数据占用缓存,提高存储资源利用率。 在实际应用时,调度节点108可以通过调度模块中的调度器实现存储资源调度。具体地,调度器接收到作业时,从作业描述文件(job description files,JD)中获取hintentry,然后通过解析hint entry内容的方式,将hint entry转换为与存储系统104对应的命令,然后通过存储系统104的目标接口下发该命令,从而实现将hint entry传递至底层的存储系统104。如此,存储系统104能够准确预知应用对数据对象的IO操作模式,并基于该IO操作模式执行相应的存储资源调度策略,以提高存储资源利用率和应用执行效率。 为了便于理解,下面以调度器为scheduler对存储资源调度过程进行示例说明。 参见图8,scheduler是一种支持作业回调框架hook framework的调度器。hintentry具体以hook记录的形式存储在scheduler的作业描述文件JD中。根据hint entry的执行顺序,例如应用的作业开始执行前或者执行完毕后,可以将hook记录分为prehook和posthook。每条hook记录指定工作集中的一个数据对象以及针对该数据对象即将发生的IO操作。其中,数据对象可以通过数据对象标识如数据对象名称等进行表征。针对数据对象即将发生的IO操作可以通过包括IO模式在内的信息进行表征,考虑到非连续读写情况,IO操作具体可以通过IO模式、起始地址、结束地址、IO大小、步长等进行表征,进一步地,hook记录中还可以指定IO操作对应的节点。 作业提交至schedule后,scheduler读取作业描述文件JD。当读取到prehook记录时,则根据prehook中的规则在相关节点例如prehook记录指定的节点运行提示信息通知器hint notifier,该hint notifier可以通过内置的提示信息解析器hint parser解析hintentry,然后基于存储系统适配层(storage system adapter)生成与存储系统104对应的指令,通过各存储系统104的目标接口下发至各存储系统104。 其中,hint entry为读操作相关hint entry时,hint notifier可以采用阻塞执行方式,等待存储系统104执行完相关操作后返回;hint entry为写操作相关hint entry时,hint notifier可以采用非阻塞执行方式,hint notifier主动向存储系统104查询操作是否完成。 所有prehook执行完毕后,Schedule开始调度作业在各计算节点上执行,作业执行完毕后,继续读取作业描述文件JD。 当读取到posthook记录时,根据posthook中的规则在相关节点例如posthook记录指定的节点执行hint notifer,以通过指令的方式将hint entry传递至存储系统104。例如,可以在相关节点执行hint notifer,通过淘汰指令,指示存储系统104淘汰cache中的工作集缓存。 为了便于理解,本申请还以数据对象为文件对存储资源调度过程进行示例说明。 在一个示例中,job用户从数据库查询到job的文件test的IO模型为顺序非连续读取模型,其特征值为: 表1
其中,mode表示IO操作类型,例如取值为0时表征读操作。begin和end分别表示IO起始地址和IO结束地址。stride表示步长,count表示IO分片个数,block表示IO分片大小。 调度器可以读取作业描述文件JD,当读取到作业描述文件JD中的prehook时,prehook中即记录有上述表1所包括的各字段的信息,调度器可以根据prehook生成与存储系统对应的命令,然后调度器可以通过存储系统104的目标接口向存储系统下发命令,具体为hint notifier register--id test--mode 0--begin 0--end 77824--stride 4096--count 10--block 4096。存储系统可以通过读取上述命令,调度存储资源。如图9所示,调度器可以指示存储系统104将文件中的A2部分添加到缓存,而不是将A1部分添加至缓存,从而实现精准地确定下一次读操作的位置,并实现精准预取数据,而不会预取多余的数据,提高了存储资源利用率以及应用执行效率。 该示例是以一个数据对象进行示例说明的,下面结合工作集中多个数据对象的预取进行示例说明。 如图10所示,工作集中包括4个数据对象,具体为文件A至文件D,分析节点106基于IO操作的操作属性信息和对象属性信息结合至少一种识别模型,如第一IO模式识别模型、第二IO模式识别模型以及第三IO模式识别模型等,获取应用画像信息,该应用画像信息可以包括应用的IO模式等信息,如针对文件的顺序读模式。此外,操作属性信息中还可以包括节点标识,识别模型还可以结合针对相同文件的IO操作的节点标识,确定应用的IO模式为共享模式或者独享模式。 进一步地,分析节点106还可以根据模式提示信息转换器包括的多种模式提示信息转换框架,如顺序模式提示信息转换框架、共享模式提示信息转换框架以及独享模式提示信息转换框架等,确定与IO模式对应的信息提示模板,根据信息提示模板以及IO模式中各字段的字段值,生成对应的信息提示项。 调度节点108可以读取信息提示项,根据信息提示项从存储系统104支持的命令集中选择目标命令类型,如选择willread这一命令类型,然后根据该目标命令类型和信息提示项中与上述目标命令类型关联字段的字段值,生成至少一条命令。其中,针对willread这一目标命令类型,其关联字段可以包括顺序、共享、起始地址、结束地址等字段。调度节点108可以根据will read这一命令类型以及顺序、共享、起始地址、结束地址等字段的字段值生成至少一条命令。 然后,调度节点108通过存储系统104的目标接口将上述命令传递至存储系统104,存储系统104基于该命令可以确定在节点1上顺序共享读文件A,具体包括文件A中的A2-A4,逆序独享读文件C,具体包括文件C中的C4至C7,在节点2上顺序共享读文件A,具体包括文件A中的A6,以及在节点2上顺序独享跳读文件B,具体包括文件B中的B2、B4、B6和B8,在节点3上顺序共享读文件A,具体包括文件A中的A8-A10,以及随机独享读文件D中的D5。 基于此,存储系统104可以将A2-A4、A6以及A8-A10预加载至全局缓存globalcache,将C7、C6、C5、C4依次加载至节点A的本地缓存local cache,将A6加载至节点2的localcache,将A8、A9和A10依次加载至节点3的local cache,如此可以大大减少cache中的无效数据,提升了cache的利用率和命中率,提高了存储系统104的性能以及应用执行效率。 在另一个示例中,job用户从数据库中查询job具备大小重复性的文件的大小,例如,job具备大小重复性的文件的大小为: 表2
调度器可以通过hint notifier register-id NULL--mode 1--size 8192的命令向存储系统104下发文件的大小(即size),存储系统104根据size确定文件的条带大小,具体地,当size较小时,可以设置较小的条带,如此可以减少对齐、校验块浪费的空间等等。 当然,job用户还可以从数据库查询job使用的文件是否为临时文件,对于临时文件,可以选择降低冗余、存储在临时空间等策略。例如,job的test文件是一个临时文件,其特征值为: 表3
通过hint_notifier register-id test--mode 1--tempfile 1的命令告知存储系统104test文件是一个临时文件。存储系统104可将test文件放在临时空间,并取消多副本策略或纠删码(erasure coding,EC)策略。 上文中结合图1至图10,详细描述了本申请所提供的资源调度方法,下面将结合附图,描述根据本申请所提供的资源调度系统。 参见图11所示的资源调度系统的结构示意图,该调度系统包括: 至少一台第一计算机设备200、至少一台第二计算机设备300以及至少一台第三计算机设备400,每台计算机设备包括处理器和存储器; 所述至少一台第一计算机设备200用于采集应用在作业周期对存储系统中数据对象的输入输出操作的操作属性信息以及所述数据对象的对象属性信息,所述操作属性信息包括输入输出地址,所述对象属性信息包括数据对象标识; 所述至少一台第二计算机设备300用于根据所述操作属性信息和所述对象属性信息,获得应用画像信息; 所述至少一台第三计算机设备400用于根据所述应用画像信息进行资源调度。 其中,第一计算机设备200的具体实现可以参见图2所示实施例相关内容描述,第二计算机设备300的具体实现可以参见图3所示实施例相关内容描述,第三计算机设备400的具体实现可以参见图4所示实施例相关内容描述,在此不再赘述。 第一计算机设备200、第二计算机设备300和第四计算机设备400在执行对应的方法步骤时可以参见图6所示实施例相关内容描述,在此不再赘述。 在一些可能的实现方式中,所述至少一台第二计算机设备300用于: 将所述应用画像信息转换成信息提示项; 所述至少一台第三计算机设备用于: 根据所述信息提示项调度所述存储系统中的存储资源。 在一些可能的实现方式中,所述至少一台第二计算机设备300用于: 确定与所述应用画像信息对应的信息提示模板; 根据所述应用画像信息中各字段的字段值结合所述信息提示模板,获得信息提示项。 在一些可能的实现方式中,所述至少一台第三计算机设备400用于: 根据所述信息提示项从所述存储系统支持的命令集中选择目标命令类型; 根据所述目标命令类型和所述信息提示项中与所述目标命令类型关联字段的字段值生成至少一条命令; 通过所述存储系统的目标接口下发所述命令,以使所述存储系统执行所述命令实现调度存储资源。 在一些可能的实现方式中,所述应用画像信息包括所述应用的输入输出操作随时间分布情况,所述输入输出操作随时间分布情况通过所述输入输出操作的操作时间段和所述操作时间段内的输入输出大小表征; 所述至少一台第三计算机设备400用于: 根据所述应用的输入输出操作随时间分布情况调度计算资源。 在一些可能的实现方式中,所述至少一台第三计算机设备用于: 根据所述对象属性信息确定针对相同数据对象的输入输出操作; 将所述针对相同数据对象的输入输出操作的操作属性信息输入至少一种识别模型,获取所述识别模型的识别结果作为应用画像信息。 在一些可能的实现方式中,所述至少一种识别模型包括第一模式识别模型,所述第一模式识别模型用于结合所述针对相同数据对象的输入输出操作的输入输出地址,获取所述应用的第一输入输出模式,所述第一输入输出模式包括连续信息、顺序信息、热点信息和序列信息中的任意一种或多种,所述连续信息用于标识所述输入输出操作是否连续,所述顺序信息用于标识所述输入输出操作是顺序或逆序,所述热点信息用于标识所述输入输出操作的热点区域,所述序列信息用于标识所述输入输出操作是否有序。 在一些可能的实现方式中,所述至少一种识别模型包括第二模式识别模型,所述第二模式识别模型用于结合所述针对相同数据对象的输入输出操作中相邻操作的输入输出地址,获取所述应用的第二输入输出模式,所述第二输入输出模式包括概率信息,所述概率信息用于指示第二访问区域作为第一访问区域的后继访问区域的概率。 在一些可能的实现方式中,所述至少一种识别模型包括第三模式识别模型,所述第三模式识别模型用于第一输入输出模式和第二输入输出模式均未被命中时,获取所述应用的第三输入输出模式,所述第三输入输出模式包括随机信息,所述随机信息用于标识所述输入输出操作是随机输入输出操作。 在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括冲突域识别模型,所述冲突域识别模型用于所述操作时间段重叠且所述输入输出地址重叠时,将地址重叠区域识别为冲突域。 在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述至少一种识别模型包括时间分布识别模型,所述时间分布识别模型用于按照所述操作时间段对所述输入输出操作排序,当相邻的输入输出操作存在操作时间重叠时,合并所述相邻的输入输出操作的操作时间段,将所述相邻的输入输出操作的输入输出大小相加获得合并后的输入输出操作的输入输出大小,根据所述输入输出操作的时间段和所述输入输出大小获得所述应用的输入输出操作随时间分布情况。 在一些可能的实现方式中,所述操作属性信息还包括操作时间段,所述对象属性信息还包括生存时间段,所述至少一种识别模型包括生命周期识别模型,所述生命周期识别模型用于结合所述生存时间段与所述操作时间段获取所述数据对象的生命周期类型。 在一些可能的实现方式中,所述数据对象包括作业执行时产生的数据对象,所述至少一种识别模型包括重复性识别模型,所述重复性识别模型用于结合所述作业执行多次产生的数据对象的输入输出地址获取所述作业在执行时产生的数据对象是否具有大小重复性。 另外需说明的是,以上所描述的实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。另外,本申请提供的装置实施例附图中,模块之间的连接关系表示它们之间具有通信连接,具体可以实现为一条或多条通信总线或信号线。 通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件的方式来实现,当然也可以通过专用硬件包括专用集成电路、专用CPU、专用存储器、专用元器件等来实现。一般情况下,凡由计算机程序完成的功能都可以很容易地用相应的硬件来实现,而且,用来实现同一功能的具体硬件结构也可以是多种多样的,例如模拟电路、数字电路或专用电路等。 但是,对本申请而言更多情况下软件程序实现是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在可读取的存储介质中,如计算机的软盘、U盘、移动硬盘、ROM、RAM、磁碟或者光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,训练设备,或者网络设备等)执行本申请各个实施例所述的方法。 在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。 所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。 所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、训练设备或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、训练设备或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的训练设备、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘(SolidState Disk,SSD))等。
- 一种资源调度装置、资源调度系统和资源调度方法
- 一种资源调度方法和资源调度系统