进行脸部筛选的全人关联
文献发布时间:2023-06-19 12:14:58
技术领域
本公开一般涉及检测影像中的人。更具体地,本公开涉及可以执行脸部幻构和/或筛选的全人关联系统。
背景技术
通过计算机检测影像(例如,静止帧和/或视频)中的人类对于指导执行大量不同任务可以非常有用。例如,可以基于在摄像头的当前视点中是否存在一个或多个人类来控制摄像头(例如,监控摄像头)的各个方面(例如,位置、图像捕捉行为等)。作为另一个示例,自动驾驶车辆可以包括摄像头,并且可以分析由摄像头捕捉的影像,以确定在其周围环境中存在人类行人并相应地进行操作。作为又一个示例,在图像中检测人类可以是较大过程中的第一阶段,该较大过程包括在检测人类之后执行的多个下游行动,诸如识别人类(例如,解锁移动装置),检测与人类相关联的凝视方向(例如,理解人类发出的口头命令的主题),或者其他活动。
在大多数现有系统中,计算系统通过将脸部检测器或人员检测器应用于影像来检测影像中的人类。脸部检测器可以是计算机实现的组件,其被配置为检测图像中的人脸(例如,特别是脸部而不是其他身体部位)。人员检测器可以是计算机实现的组件,其被配置为检测图像中的人体(例如,整个身体的大部分而不仅仅是脸部)。在最先进的系统中,这些检测器(例如,脸部检测器或人员检测器)是已经过训练以使用机器学习技术执行其检测操作的机器学习模型。但是,这些检测器中的每个检测器都可能由于产生假阳性(falsepositive)(例如,检测到不存在的东西)或假阴性(false negative)(例如,未能检测到影像中描绘的物体)而失败。假阳性和假阴性两者都会对相关系统的功效产生不利影响。
此外,某些系统可以包括并执行分开的脸部检测器和人员检测器。然而,这种方法有很多缺点。首先,包括和使用两个不同检测器需要大量的计算或其他资源的使用(例如,存储器使用、处理器使用、能源消耗等)。其次,两个检测器经常导致冲突的信息(例如,在发现人的地方,但是附近没有人脸检测,反之亦然)。再次,到目前为止,还没有直接的方法将检测到的脸部和人相关联,这使得计算系统无法知道检测是否涉及一个人或两个人员。
发明内容
本公开的实施例的多个方面和优点将在以下描述中部分地阐述,或者可以从描述中获知,或者可以通过实施例的实践获知。
本公开的一个示例方面涉及一种计算机系统,其基于与人员检测的关联筛选脸部检测。计算机系统包括:一个或多个处理器;机器学习人员检测模型,被配置为检测图像中描绘的人体;机器学习脸部检测模型,被配置为检测图像中描绘的人脸;以及一个或多个非暂时性计算机可读介质,其共同存储指令,该指令在由一个或多个计算装置执行时,使得计算机系统执行操作。操作包括获得输入图像。操作包括将输入图像输入到机器学习人员检测模型和机器学习脸部检测模型中。操作包括接收作为机器学习人员检测模型的输出的一个或多个人员检测,其中一个或多个人员检测中的每个人员检测指示在输入图像中相应检测到的人体的相应检测到的身体位置。操作包括接收作为机器学习脸部检测模型的输出的一个或多个脸部检测,其中一个或多个脸部检测中的每个脸部检测指示在输入图像中相应检测到的人脸的相应检测到的脸部位置。对于一个或多个脸部检测中的至少第一脸部检测,操作包括:确定第一脸部检测是否与人员检测之一相关联;以及至少部分地基于第一脸部检测是否与人员检测之一相关联,修改与第一脸部检测相关联的第一置信度得分和与第一脸部检测相关联的第一置信度阈值中的一者或两者。
本公开的另一个示例方面涉及一种幻构图像中的脸部检测的计算机实现方法。该方法包括由一个或多个计算装置获得输入图像。该方法包括由一个或多个计算装置将输入图像输入至机器学习人员检测模型,其被配置为检测图像中描绘的人体。该方法包括由一个或多个计算装置接收作为机器学习人员检测模型的输出的人员检测,其中人员检测指示在输入图像中检测到的人体的检测到的身体位置。该方法包括由一个或多个计算装置至少部分地基于由人员检测器提供的检测到的人体的检测到的身体位置来生成幻构的脸部检测,其中幻构的脸部检测指示与检测到的人体相关联的脸部在输入图像中的幻构的脸部位置。
本公开的另一示例方面涉及一个或多个非暂时性计算机可读介质,其共同存储指令,该指令在由一个或多个处理器执行时,使得一个或多个处理器执行操作。操作包括确定相对于图像的一个或多个脸部检测和一个或多个人员检测,其中每个脸部检测指示被认为包含脸部的图像的相应区域或像素组,并且每个人员检测指示被认为包含人员的相应区域或像素组。操作包括计算与每个脸部检测和每个推定的人员检测相关联的相应置信度得分。操作包括识别与指示身体界标的集合的位置的每个人员检测相关联的相应姿态点的集合。操作包括使用与第一人员检测相关联的相应姿态点的集合来确定至少第一脸部检测与至少第一人员检测之间的关联得分。操作包括将关联得分和相应置信度得分用于第一脸部检测,来产生更新的置信度得分用于第一脸部检测。操作包括基于更新的置信度得分与置信度阈值的比较来确定是否丢弃第一脸部检测。
本公开的其他方面涉及各种系统、设备、非暂时性计算机可读介质、用户界面和电子装置。
参考以下描述和所附权利要求,将更好地理解本公开的各个实施例的这些和其他特征、方面和优点。结合在本说明书中并构成本说明书的一部分的附图示出了本公开的示例实施例,并且附图与描述一起用于解释相关原理。
附图说明
在说明书中参考附图阐述了针对本领域普通技术人员的实施例的详细讨论,在附图中:
图1A描绘了根据本公开的示例实施例的执行全人关联的示例计算系统的框图。
图1B描绘了根据本公开的示例实施例的示例计算装置的框图。
图1C描绘了根据本公开的示例实施例的示例计算装置的框图。
图2描绘了根据本公开的示例实施例的示例处理管线的框图。
图3描绘了示例多头人员和脸部检测模型的框图。
图4A-G描绘了带有检测的示例图像,其示出了图2的示例处理管线的应用。
在多个附图中重复的附图标记旨在识别各种实现中的相同特征。
具体实施方式
概述
本公开的示例方面涉及执行与脸部筛选和/或脸部幻构的全人关联的计算系统和方法。具体地,本公开的一个方面涉及在一个模型中执行脸部和人员检测两者的多头人员检测模型和脸部检测模型。脸部检测和人员检测中的每个检测都可以找到界标或其他姿态信息以及置信度得分。脸部检测和人员检测的姿态信息可用于选择某些脸部检测和人员检测,以作为全人检测关联在一起,其可被称为“外观(appearance)”。本公开的另一方面涉及基于脸部检测与人员检测的关联的脸部筛选。具体地,本公开的系统和方法可以使用脸部检测和人员检测的并置来调整置信度得分和/或相应阈值。例如,整齐地与人员检测对准的低置信度脸部检测反而可以被视为存在脸部的高置信度。然而,如果低置信度脸部检测不能与人员检测对准,则其置信度会降低(或者可选地,不提高)。本公开的又一个方面涉及脸部幻构。具体地,本公开的系统和方法可以使用人员检测界标对脸部检测进行幻构。通过应用本文所述的脸部筛选和幻构技术,可以生成更完整和准确的脸部检测和/或全人检测,从而提高基于脸部检测和/或全人检测执行的任何活动的准确性或其他质量。
更具体地,根据本公开的一个方面,计算机系统可以包括人员检测模型和脸部检测模型两者。在一些实现中,人员检测模型和/或脸部检测模型可以是机器学习模型,诸如,例如,诸如卷积神经网络的人工神经网络(以下称为“神经网络”)。
人员检测模型和脸部检测模型中的每一个都可以被配置为处理输入影像。输入影像可以包括二维影像或三维影像。例如,输入影像可以包括由摄像头(例如,可见光谱摄像头、红外摄像头、高光谱摄像头等)捕获的图像。图像可以用任意数量的不同颜色空间(例如,灰度、RGB、CMYK等)表示。作为另一示例,输入影像可以包括由光检测和测距(“LIDAR”)系统或无线电检测和测距(“RADAR”)系统生成的影像。例如,输入影像可以是或包括检测到的数据点的二维或三维点云。
人员检测模型可以被配置(例如,被训练)为检测图像中描绘的人体。例如,人员检测模型可以被配置为寻找人体的大部分(例如,包括躯干、头部和四肢)而不仅仅是脸部。因此,给定输入图像,人员检测模型可以输出一个或多个人员检测,其中每个人员检测指示输入图像中相应检测到的人体的相应检测到的身体位置。
人体的位置可以以多种不同方式被指示。作为一个示例,人员检测可以将检测到的身体的位置指示为边界形状。边界形状可以是二维形状或三维形状(例如,取决于输入图像的尺寸结构)。边界形状可以识别影像中的像素(或体素)组,其与图像内的身体位置相对应。边界形状可以是多边形形状(例如,方框或立方体)、曲线形状(例如,圆形或椭圆形)或任意形状(例如,识别包围检测到的身体的特定像素或体素组的分割掩模)。
作为另一示例,除了边界形状或可选地,人员检测可以通过描述检测到的身体姿态的姿态数据指示相应的检测到的身体的位置。例如,姿态数据可以识别检测到的身体的一个或多个界标的位置。例如,界标可以包括手部界标(例如,手指)、手臂界标(例如,肘、肩膀等)、躯干界标(例如,肩膀、腰部、臀部、胸部等)、腿部界标(例如,脚、膝盖、大腿等)、脖子界标和头部界标(例如,眼睛、鼻子、眉毛、嘴唇、下巴等)。在一些实现中,描述界标的位置的姿态数据仅包括与界标的位置相对应的多个点。在其他实现中,描述界标的位置的姿态数据包括身体的简笔画表示,其中各种界标(例如,手、肘、肩等)经由边缘连接。除了界标位置,身体姿态数据还可以描述检测到的身体的各种其他特点,诸如身体相对于与输入影像相关联的坐标结构的倾斜、偏离和/或滚转角。例如,基于相对于彼此的界标位置可以计算角度。
在一些实现中,人员检测模型可以为每个人员检测提供描述相应的人员检测是准确的可信度的数值(即,图像的已识别的部分实际上描绘了人体)。该数值可以被称为置信度得分。通常,较大的置信度得分指示该模型对预测更有信心。在一些示例中,置信度得分的范围可以从0到1。
如上所述,除了人员检测模型之外,计算系统还可以包括脸部检测模型。脸部检测模型可以被配置(例如,被训练)为检测图像中描绘的人脸。就是说,与人员检测模型相反,脸部检测模型可以被配置为仅在图像中搜索脸部,而不考虑身体的其余部分。因此,给定输入图像,脸部检测模型可以输出一个或多个脸部检测,其中每个脸部检测指示输入图像中的相应检测到的脸部的相应检测到的脸部位置。
脸部的位置可以以多种不同方式被指示。作为一个示例,脸部检测可以将检测到的脸部的位置指示为边界形状。边界形状可以是二维形状或三维形状(例如,取决于输入图像的尺寸结构)。边界形状可以识别影像中的像素(或体素)组,其与图像内的脸部位置相对应。边界形状可以是多边形形状(例如,方框或立方体)、弯曲形状(例如,圆形或椭圆形)或任意形状(例如,识别包围检测到的脸部的特定像素(或体素)组的分割掩模)。
作为另一示例,除了边界形状或可选地,脸部检测可以通过描述脸部姿态的姿态数据指示相应的检测到的脸部的位置。例如,姿态数据可以识别检测到的脸部的一个或多个面部界标的位置。例如,面部界标可以包括眼睛界标、鼻子界标、眉毛界标、嘴唇界标、下巴界标或其他面部界标。在一些实现中,描述界标位置的姿态数据仅包括与界标位置相对应的多个点。在其他实现中,描述界标位置的姿态数据包括脸部的连接表示,其中各种界标(例如,所有嘴唇界标)经由边缘连接。除了界标位置之外,面部姿态数据还可以描述检测到的脸部的各种其他特点,诸如脸部相对于与输入影像相关联的坐标结构的倾斜、偏离和/或滚转角。例如,基于相对于彼此的界标位置可以计算角度。
在一些实现中,脸部检测模型可以为每个脸部检测提供描述相应的脸部检测是准确的可信度的数值(即,图像的已识别的部分实际上描绘了人脸)。该数值可以被称为置信度得分。通常,较大的置信度得分指示该模型对预测更有信心。在一些示例中,置信度得分的范围可以从0到1。
因此,计算系统可以获得输入图像,并且可以将输入图像输入到人员检测模型和脸部检测模型中,以接收一个或多个人员检测和一个或多个脸部检测,以及指示模型在其检测中有多少信心的置信度得分。
根据本公开的一个方面,在一些实现中,人员检测模型和脸部检测模型可以被包括在单个、多头模型中,该模型包括共享特征提取部分、人员检测头部和脸部检测头部。因此,计算系统可以将输入图像输入到共享特征提取部分中。共享特征提取部分可以从输入图像中提取一个或多个特征。共享特征提取部分可以将提取的特征提供至人员检测头部和脸部检测头部中的每一个。人员检测头部和脸部检测头部可以分开处理提取的特征,以分别生成人员检测和脸部检测。
以这样的方式,从影像获得人员检测和脸部检测两者所需的处理量可以被减少。就是说,不像通常执行的那样运行两个分开的模型,而是可以执行单个共享特征提取部分以提取特征,然后两个分开的头部可以针对共享特征操作以执行分开的人员和脸部检测。因此,使用单个、多头模型能够节省诸如存储器使用、处理器使用、计算时间、能源使用和/或网络使用的计算资源。
在一个示例中,共享特征提取部分、人员检测头部和脸部检测头部中的每一个可以是或包括诸如卷积神经网络的神经网络。例如,在一些实现中,共享特征提取部分可以是包括一个或多个卷积的卷积神经网络,并且人员检测头部和脸部检测头部中的每一个可以是包括一个或多个神经元层的前馈神经网络(例如,只有单个最终分类层)。因此,在一些实现中,大部分处理工作由共享特征提取部分执行,从而利用了本文其他地方所述的资源节省优势(例如,更少的浮点运算、更少的参数等),并且实质上提供了“二合一”场景,其中一个模型的资源使用价值可提供两次检测。
根据本公开的另一方面,在接收到人员和脸部检测之后,计算系统可以尝试将每个脸部检测与人员检测之一相关联,反之亦然。例如,当脸部检测与人员检测相关联时,它可以生成全人检测,这可以被称为“外观”。如本文将进一步讨论的,将脸部检测与人员检测相关联以生成外观的能力可以用作筛选(例如,丢弃)某些脸部和/或人员检测(例如,那些被认为是假阳性的)的基础。
在一些实现中,计算系统可以针对每个脸部检测试图将脸部检测与人员检测之一迭代地匹配,直到找到认可的关联为止,反之亦然。作为一个示例,对于每个脸部检测,计算系统可以识别在阈值距离内的任何人员检测(例如,基于它们相应位置的比较),并且可以尝试将脸部检测与已识别的人员检测之一相关联(例如,从最靠近的开始)。在其他实现中,针对每个脸部检测仅分析固定数目(例如,一个)的最靠近的人员检测。
在一些实现中,可以基于与检测相关联的位置和/或姿态数据执行关联分析。例如,计算系统可以应用一组规则或条件来确定脸部检测是否应当与人员检测相关联,反之亦然。
作为一个示例,如果脸部检测和人员检测彼此之间在一定距离之内(例如,它们的形心在一定距离之内),则脸部检测可以与人员检测相匹配。作为另一个示例,如果脸部检测与人员检测的相应边界形状(例如,边界框、语义分割等)具有超过阈值的重叠量,则脸部检测可以与人员检测相匹配。例如,重叠量可以被测量为整个脸部边界形状的百分比。
作为另一个示例,可以将用于脸部和人员检测的姿态数据进行比较以确定关联是否合适。例如,如上所述,脸部检测可以指示与一个或多个面部界标(例如,眼睛、嘴唇、耳朵、鼻子、下巴、眉毛等)相关联的一个或多个脸部界标位置。类似地,人员检测还可以指示与一个或多个面部界标相关联的一个或多个面部界标位置。在一些实现中,比较来自脸部和人员检测的相应姿态数据的集合可以包括确定分别由脸部和人员检测提供的每对对应的界标位置之间的相应距离。例如,可以在由脸部检测器提供的“中央上唇”界标位置与由人员检测器提供的“中央上唇”界标位置之间评估距离(例如,归一化距离)。对所有成对的匹配界标可以执行相同的操作(或者如果希望评估某种关系,甚至对不匹配的界标执行)。计算系统可以基于这样计算的距离来确定是否将脸部检测与人员检测相关联。
作为仅出于说明性目的而提供的一个具体且非限制性的示例,可以如下计算对于给定脸部检测(f
其中f
上述规则和条件的各种组合也可以被应用。跨多个关联度量的累积得分可以被计算并将其与阈值进行比较。在一些实现中,计算机系统选择将脸部检测与人员检测相关联,其两者(1)具有超过阈值的得分和(2)具有所有评定的人员检测中的最高得分。但是,也可以应用其他不同的条件组。作为一个示例,匈牙利算法可用于求解最佳总体分配。有时,这种最佳解决方案可能需要分配,例如将脸部分配给不是最高得分的人员,因为另一个脸部可能具有更好的匹配度。在一些实现中,该问题可以作为“线性分配问题”的实例来处理。
根据本公开的一个方面,在试图将每个脸部检测与人员检测之一相关联之后,反之亦然,计算系统可以对面部检测进行筛选,以试图去除假阳性。具体地,计算系统可以基于脸部检测是否能够与人员检测之一相关联来智能地筛选每个脸部检测。
更具体地,作为筛选过程的一部分,可以将与每个脸部检测相关联的相应置信度得分与置信度阈值进行比较,以确定是保留还是丢弃脸部检测。作为一个具体且非限制性的示例,置信度阈值可以设置为0.5,使得如果置信度得分或阈值没有任何变更,则丢弃具有相应置信度得分小于0.5的脸部检测,而保留具有相应置信度得分大于0.5的脸部检测。阈值0.5作为示例提供。任何不同的阈值都可以使用,例如,以在假阳性和假阴性之间进行权衡。
然而,根据本公开的一个方面,可以基于如上所述的关联来修改置信度得分和/或阈值。具体地,在一些实现中,对于与人员检测之一成功地相关联的每个脸部检测,计算系统可以增加与这样的脸部检测相关联的置信度得分和/或可以降低与筛选这样的脸部检测相关联的置信度阈值(例如,从0.5到任何较小的阈值,包括例如零阈值)。可选地或附加地,对于未与人员检测之一成功地相关联的每个脸部检测,计算系统可以降低与这样的脸部检测相关联的置信度得分和/或可以增加与筛选这样的脸部检测相关联的置信度阈值。
有几种不同的方法可以执行置信度值的增加或更新。作为一个示例,可以在相关联的脸部和人员检测之间取最大值。举个示例,脸部检测可以具有0.4置信度,而人员检测可以具有0.8置信度。如果这两个检测相关联,则脸部置信度可以更新为0.8。作为另一个示例,可以使用贝叶斯公式。贝叶斯公式可以考虑两次检测都错误的几率。继续该示例,由于以下公式1.0-(1-0.4)*(1-0.8)=0.88,可以将脸部检测和/或人员检测置信度设置为0.88。在又一个示例中,可以训练附加模型来处理置信度值更新。例如,模型可以取脸部和人员检测置信度值以及相应的关联得分作为输入。如果脸部为真阳性(true positive),则模型的目标输出为1;如果脸部为假阳性,则模型的目标输出为0。脸部的更新的置信度值可以是这样的附加模型的输出。类似的示例也可以用来针对减小置信度值,例如,在没有确证人员检测时。
因此,本公开的系统和方法可以使用脸部和人员检测的并置来调整置信度得分和/或相应的阈值。例如,能够与人员检测相关联的低置信度脸部检测反而可以被视为存在脸部的高置信度。然而,如果低置信度的脸部检测不能与人员检测相关联,则可以降低其置信度(或者可选地,不增加其置信度)。以这样的方式,可以组合图像内的多种检测类型以减少假阳性脸部检测的数量,从而提高脸部检测的精度。
本文所述的应用于筛选脸部检测的筛选技术同样能够应用于筛选人员检测。例如,对于与脸部检测之一成功地相关联的每个人员检测,计算系统可以增加与这样的人员检测相关联的置信度得分和/或可以降低与筛选人员检测相关联的置信度阈值。可选地或附加地,对于未与脸部检测之一成功地相关联的人员检测,计算系统可以降低与这样的人员检测相关联的置信度得分和/或可以增加与筛选这种人员检测相关联的置信度阈值。
根据本公开的另一方面,除筛选检测之外或可选地,计算系统可以基于未关联的人员检测对脸部检测进行幻构,反之亦然。例如,对于特定的人员检测(例如,在执行上述关联过程之后没有与脸部检测相关联的人员检测),计算系统可以至少部分地基于由人员检测提供的检测到的人体的检测到的身体位置来生成幻构的脸部检测。幻构的脸部检测可以指示与检测到的人体相关联的脸部在输入图像中的幻构的脸部位置。
具体地,在一些实现中,由人员检测提供的位置和/或姿态信息可以用于生成幻构的脸部检测。作为示例,如上所述,在一些实现中,人员检测可以描述分别与检测到的人体的一个或多个身体组成部分相关联的一个或多个身体姿态界标。在这样的实现中,至少部分地基于检测到的人体的检测到的身体位置来生成幻构的脸部检测可以包括至少部分地基于一个或多个身体姿态界标来生成一个或多个幻构的脸部姿态界标。例如,人员检测的身体姿态界标可以具体包括面部界标,并且在这种情况下,面部界标可以直接用于生成幻构的脸部姿态界标。在其他实现中,人员检测的身体姿态界标可以仅包括与身体的躯干或四肢相关联的界标,并且生成幻构的脸部姿态界标可以包括将身体图谱(例如,包括关于各种身体界标之间的典型间隔的信息)投射到躯干或肢体界标上,以识别幻构的脸部姿态界标。几何处理可以被执行以确定幻构的脸部的范围或边界和/或诸如面部姿态信息的其他信息。
在一些实现中,计算系统可以选择仅保存满足某些特点或条件的幻构的脸部。作为一个示例,为了保留幻构的脸部检测,在相对狭窄的前窗内可能需要或具有头部姿态。例如,在认可的范围内(例如,与标称值成30度)可能需要与幻构的脸部相关联的偏离、俯仰和/或滚转角,以便保留幻构的脸部。
在一些实现中,对于没有相关联的脸部检测的任何人员检测,脸部可以被幻构。在其他实现中,仅对于(1)没有相关联的脸部检测以及(2)具有大于一些阈值的置信度得分的人员检测,脸部可以被幻构。然后每个幻构的脸部可以与相应的人员检测相关联以生成全人检测或“外观”。
以这种方式,计算系统可以为不相关联的人员检测对脸部进行幻构。这可以减少假阴性脸部检测,其中在图像中描绘了脸部但未被脸部检测器识别(例如,当脸部高度背光或脸部被部分遮挡时可能发生)。因此,通过组合来自相同图像(或跨多个图像)的多种检测类型的证据,由最终脸部检测所展示出的召回(例如,包括幻构的脸部)可以被提高。改善脸部检测的召回还可以提供节省计算资源的好处。换句话说,因为如本文所述的脸部的幻构导致总体上发生更多的脸部检测,所以脸部检测模型可能不需要在尽可能多的帧上运行以取得相同的结果,特别是当跨帧跟踪检测时。因此,较少执行模型总体上会导致节省资源,诸如节省存储器使用、处理器使用等。
在一些实现中,上述的全人检测可以是较大过程中的初始阶段,该较大过程包括在检测人员或脸部之后执行的多个下游行动,诸如识别面部(例如,解锁移动设备,解译命令,在照片管理应用中对照片进行聚类或搜索),检测与人类相关联的凝视方向(例如,理解人类发出的口头命令的主题)或其他活动。
作为一个例子,识别脸部可以包括使用脸部边界形状和/或界标来选择图像的区域(例如,该形状内的区域或已被旋转、缩放等的微调形状);用产生嵌入的网络处理图像区域(参见例如FaceNet模型);以及使用该嵌入与图库(Gallery)中的嵌入的集合进行比较(例如,预先注册),以查看是否存在匹配(例如,基于嵌入空间内的距离)。
因此,在一些示例中,可以裁剪与幻构的脸部检测相对应的图像的一部分,并将其发送到下游模型(例如,面部识别模型和/或凝视检测模型)以进行处理。这样,脸部幻构可以将脸部相关技术应用于图像的特定部分,而不是整个图像,从而节省了处理时间、计算能力、存储器使用等。具体地,示例实验已成功将脸部识别技术应用于这些“幻构的”脸部,并证明了某些总体指标的改善,诸如其中正确识别个体的帧数。
此外,尽管迄今为止将技术描述为应用于单个输入图像,但是所描述的技术还适用于跨多个相关图像帧(诸如在电影中发现)的全人检测并为其带来益处。例如,全人检测或相应的关联可以从第一图像被传送到后续图像,以对多个图像帧执行全人跟踪。关联可以逐帧传播,也可以跨帧直接与人员的脸部关联。除了跨多个帧跟踪全人之外,全人检测或相应的关联可用于将关注信息(attention information)从一帧传送到下一帧。
在一些实现中,为了跨图像执行关联的传播,每个检测可以包括将其与其他检测连结的“锚”(例如,脸部和人员检测两者都具有将其连结到相同人员的锚)。在一些实现中,锚可以与某些界标相关联。可选地或附加地,检测器本身可以被配置(例如,被训练)为产生跨对象匹配的密钥或嵌入。
因此,本公开的方面在一个或多个检测器提供人员检测和脸部检测两者的情况下操作。在这种情况下,情景中的单个人类可以在帧中进行多个相应的检测。本公开的系统可以使用界标估计帧内的脸部与人员检测之间的关联强度,以及跨帧的关联。
本文所述的各种阈值可以手动设置,或者可以基于训练数据学习。本文所述的各种阈值例如可以是固定的,或者可以基于各种特点(诸如图像分辨率、图像照明、用于控制权衡的手动调整(例如,精度与召回)、与脸部检测和/或人员检测相关联的置信度值等)而自适应。
现在将参照附图更详细地讨论本公开的示例实施例。
示例设备和系统
图1A描绘了根据本公开的示例实施例的执行全人关联的示例计算系统100的框图。系统100包括通过网络180通信地耦合的用户计算装置102、服务器计算系统130和训练计算系统150。
用户计算装置102可以是任何类型的计算装置,诸如,例如,个人计算装置(例如,笔记本电脑或台式机)、移动计算装置(例如,智能手机或平板电脑)、游戏控制台或控制器、可穿戴计算装置、嵌入式计算装置或任何其他类型的计算装置。
用户计算装置102包括一个或多个处理器112和存储器114。一个或多个处理器112可以是任何合适的处理装置(例如,处理器核心、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是可操作地连接的一个或多个处理器。存储器114可以包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存装置、磁盘等及其组合。存储器114可以存储数据116和指令118,其由处理器112执行以使用户计算装置102执行操作。
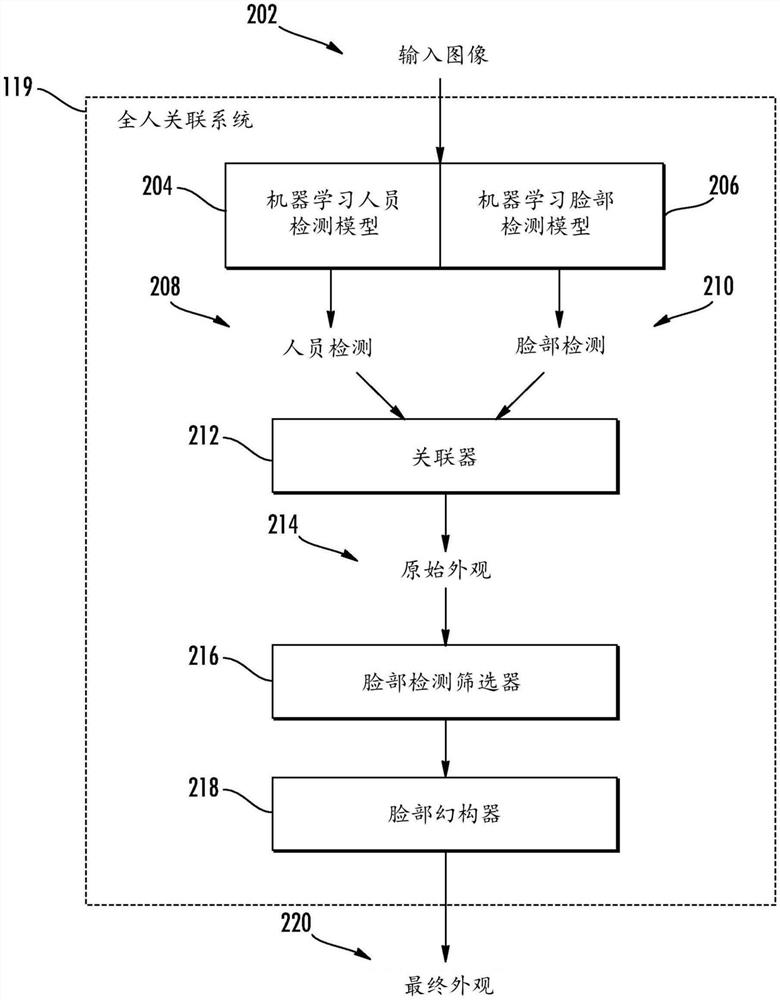
用户计算装置102可以包括全人关联系统119。全人关联系统119可以执行如本文所述的全人检测/关联。图2示出了全人关联系统119的一个示例。然而,也可以使用除了图2所示的示例系统之外的系统。
在一些实现中,全人关联系统119可以存储或包括一个或多个脸部和/或人员检测模型120。例如,脸部和/或人员检测模型120可以是或可以包括各种机器学习模型,诸如神经网络(例如,深度神经网络)或其他类型的机器学习模型,包括非线性模型和/或线性模型。神经网络可以包括前馈神经网络、递归神经网络(例如,长短期记忆递归神经网络)、卷积神经网络或其他形式的神经网络。
参考图3讨论了一个示例多头人员和脸部检测模型240。然而,示例模型240仅作为一个示例提供。模型120可以与示例模型240相似或不同。
在一些实现中,一个或多个脸部和/或人员检测模型120可以通过网络180从服务器计算系统130接收被存储在用户计算装置存储器114中,然后由一个或多个处理器112使用或以其他方式实现。在一些实现中,用户计算装置102可以实现脸部和人员检测模型120的多个并行实例(例如,跨输入影像的多个实例执行并行的脸部和/或人员检测)。
除了全人关联系统119之外或可选地,服务器计算系统130可以包括全人关联系统139。全人关联系统139可以执行本文所述的全人检测/关联。全人关联系统139的一个示例可以与图2所示的系统相同。然而,也可以使用除了图2所示的示例系统以外的系统。
除了模型120之外或可选地,一个或多个脸部和/或人员检测模型140可以被包括在根据客户端-服务器关系与用户计算装置102进行通信的服务器计算系统130中或以其他方式由其存储和实现(例如,作为全人关联系统139的组件)。例如,脸部和/或人员检测模型140可以由服务器计算系统140实现为网络服务的一部分(例如,图像处理服务)。因此,可以在用户计算装置102处存储和实现一个或多个模型120和/或可以在服务器计算系统130处存储和实现一个或多个模型140。一个或多个脸部和/或人员检测模型140可以与模型120相同或相似。
用户计算装置102还可以包括接收用户输入的一个或多个用户输入组件122。例如,用户输入组件122可以是对用户输入对象(例如,手指或手写笔)的触摸敏感的触敏组件(例如,触敏显示屏或触摸板)。触敏组件可以用来实现虚拟键盘。其他示例用户输入组件包括麦克风、传统键盘或用户可以通过其提供用户输入的其他方式。
服务器计算系统130包括一个或多个处理器132和存储器134。一个或多个处理器132可以是任何合适的处理装置(例如,处理器核心、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是可操作地连接的一个或多个处理器。存储器134可以包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存装置、磁盘等及其组合。存储器134可以存储数据136和指令138,其由处理器132执行以使服务器计算系统130执行操作。
在一些实现中,服务器计算系统130包括一个或多个服务器计算装置或由其以其他方式实现。在服务器计算系统130包括多个服务器计算装置的情况下,这样的服务器计算装置可以根据顺序计算架构、并行计算架构或其一些组合来操作。
如上所述,服务器计算系统130可以存储或以其他方式包括一个或多个机器学习的脸部和/或人员检测模型140。例如,模型140可以是或可以以其他方式包括各种机器学习模型。示例机器学习模型包括神经网络或其他多层非线性模型。示例神经网络包括前馈神经网络、深度神经网络、递归神经网络和卷积神经网络。参考图3讨论了一个示例模型140。
用户计算装置102和/或服务器计算系统130可以经由与通过网络180通信地耦合的训练计算系统150的交互来训练模型120和/或140。训练计算系统150可以与服务器计算系统130分离或者可以是服务器计算系统130的一部分。
训练计算系统150包括一个或多个处理器152和存储器154。一个或多个处理器152可以是任何合适的处理装置(例如,处理器核心、微处理器、ASIC、FPGA、控制器、微控制器等),并且可以是可操作地连接的一个或多个处理器。存储器154可以包括一个或多个非暂时性计算机可读存储介质,诸如RAM、ROM、EEPROM、EPROM、闪存装置、磁盘等及其组合。存储器154可以存储数据156和指令158,其由处理器152执行以使训练计算系统150执行操作。在一些实现中,训练计算系统150包括一个或多个服务器计算装置或由其以其他方式实现。
训练计算系统150可以包括模型训练器160,其使用各种训练或学习技术(诸如,错误的向后传播(backwards propagation))来训练存储在用户计算装置102和/或服务器计算系统130处的机器学习模型120和/或140。在一些实现中,执行错误的向后传播可以包括随着时间的推移执行截断的反向传播(backpropagation)。模型训练器160可以执行多种泛化技术(例如,权重衰减、随机失活(dropout)等),以提高正被训练的模型的泛化能力。
具体地,模型训练器160可以基于训练数据162的集合来训练脸部和/或人员检测模型120和/或140。训练数据162可以包括例如多个训练图像,其中每个训练图像已标有地面实况脸部和/或人员检测。例如,每个训练图像的标签可以描述由训练图像所描绘的脸部和/或人员的位置(例如,以边界形状的形式)和/或姿态(例如,界标位置)。在一些实现中,标签可以由人类手动地应用到训练图像。在一些在实现中,可以使用损失函数来训练模型,该损失函数测量预测的检测与地面实况的检测之间的差异。在包括多头模型的实现中,多头模型可以使用组合了每个头部损失的组合损失函数来训练。例如,组合损失函数可以将来自脸部检测头部的损失与来自人员检测头部的损失相加以形成总损失。总损失可以通过模型反向传播。
在一些实现中,如果用户已经提供了同意,则训练示例可以由用户计算装置102提供。因此,在这样的实现中,提供给用户计算装置102的模型120可以由训练计算系统150从用户计算装置102接收的用户特定数据来训练。在某些情况下,该过程可以被称为个性化模型。
模型训练器160包括用于提供期望功能的计算机逻辑。模型训练器160可以在控制通用处理器的硬件、固件和/或软件中实现。例如,在一些实现中,模型训练器160包括存储在存储装置上、加载到存储器中以及由一个或多个处理器执行的程序文件。在其他实现中,模型训练器160包括一组或多组计算机可执行指令的集合,其存储在有形的计算机可读存储介质中,诸如RAM硬盘或者光学或磁性介质。
网络180可以是任何类型的通信网络,诸如局域网(例如,内部网)、广域网(例如,互联网)或其一些组合,并且可以包括任何数量的有线或无线链路。一般而言,通过网络180的通信可以经由任何类型的有线和/或无线连接来进行,使用多种多样的通讯协议(例如,TCP/IP、HTTP、SMTP、FTP)、编码或格式(例如,HTML、XML)和/或保护方案(例如,VPN、安全HTTP、SSL)。
图1A示出了可用于实现本公开的一个示例计算系统。也可以使用其他计算系统。例如,在一些实现中,用户计算装置102可以包括模型训练器160和训练数据集162。在这样的实现中,在用户计算装置102处可以本地训练并使用模型120。在一些这样的实现种,用户计算装置102可以实现模型训练器160以基于用户特定的数据来个性化模型120。
图1B描绘了根据本公开的示例实施例执行的示例计算装置10的框图。计算装置10可以是用户计算装置或服务器计算装置。
计算装置10包括多个应用(例如,应用1至N)。每个应用都包含自己的机器学习库和机器学习模型。例如,每个应用可以包括机器学习模型。示例应用包括文本消息收发应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。
如图1B所示,每个应用可以与计算装置的多个其他组件通信,诸如一个或多个传感器、上下文管理器、装置状态组件和/或其他组件。在一些实现中,每个应用可以使用API(例如,公共API)与每个装置组件通信。在一些实现中,每个应用使用的API特定于该应用。
图1C描绘了根据本公开的示例实施例执行的示例计算装置50的框图。计算装置50可以是用户计算装置或服务器计算装置。
计算装置50包括多个应用(例如,应用1至N)。每个应用都与中央智能层通信。示例应用程序包括文本消息收发应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。在一些实现中,每个应用可以使用API(例如,跨所有应用的通用API)与中央智能层(和存储在其中的模型)通信。
中央智能层包括多个机器学习的模型。例如,如图1C所示,可以为每个应用提供相应机器学习模型(例如,模型)并由中央智能层进行管理。在其他实现中,两个或更多应用可以共享单个机器学习模型。例如,在一些实现中,中央智能层可以为所有应用提供单个模型(例如,单个模型)。在一些实现中,中央智能层被包括在计算装置50的操作系统内或由其以其他方式实现。
中央智能层可以与中央装置数据层通信。中央装置数据层可以是用于计算装置50的数据集中储存库。如图1C所示,中央设备数据层可以与计算装置的多个其他组件通信,诸如一个或多个传感器、上下文管理器、设备状态组件和/或其他组件。在一些实现中,中央设备数据层可以使用API(例如,私有API)与每个设备组件通信。
图2描绘了根据本公开的示例实施例的示例处理管线的框图。处理管线可以由全人关联系统119执行。将参考描绘了示例图像的图4A-G讨论图2的处理管线,其中检测示出了图2的示例处理管线的应用。这些图像仅作为示例提供。
仍然参照图2,全人关联系统119可以包括人员检测模型204和脸部检测模型206两者。在一些实现中,人员检测模型204和/或脸部检测模型206可以是机器学习模型,诸如,例如,诸如卷积神经网络的人工神经网络(以下被称为“神经网络”)。
人员检测模型204和脸部检测模型206中的每一个都可以被配置为处理输入图像202。输入图像202可以包括二维影像或三维影像。例如,输入图像202可以是由摄像头(例如,可见光谱摄像头、红外摄像头、高光谱摄像头等)捕获的图像。输入图像202可以用任意数量的不同颜色空间(例如,灰度、RGB、CMYK等)表示。作为另一示例,输入图像202可以包括由光检测和测距(“LIDAR”)系统或无线电检测和测距(“RADAR”)系统生成的影像。例如,输入图像202可以是或包括检测到的数据点的二维或三维点云。
人员检测模型204可以被配置(例如,被训练)为检测图像中描绘的人体。例如,人员检测模型204可以被配置为寻找人体的大部分(例如,包括躯干、头部和四肢)而不仅仅是脸部。因此,给定输入图像,人员检测模型204可以输出一个或多个人员检测208,其中每个人员检测208指示输入图像202中相应检测到的人体的相应检测到的身体位置。
人体的位置可以以多种不同方式被指示。作为一个示例,人员检测208可以将检测到的身体的位置指示为边界形状。边界形状可以是二维形状或三维形状(例如,取决于输入图像的尺寸结构)。边界形状可以识别影像中的像素(或体素)组,其与图像内的身体位置相对应。边界形状可以是多边形形状(例如,方框或立方体)、曲线形状(例如,圆形或椭圆形)或任意形状(例如,识别包围检测到的身体的特定像素(或体素)组的分割掩模)。
作为另一示例,除了边界形状或可选地,人员检测208可以通过描述检测到的身体姿态的姿态数据指示相应的检测到的身体的位置。例如,姿态数据可以识别检测到的身体的一个或多个界标的位置。例如,界标可以包括手部界标(例如,手指)、手臂界标(例如,肘、肩膀等)、躯干界标(例如,肩膀、腰部、臀部、胸部等)、腿部界标(例如,脚、膝盖、大腿等)、脖子界标和头部界标(例如,眼睛、鼻子、眉毛、嘴唇、下巴等)。在一些实现中,描述界标的位置的姿态数据仅包括与界标的位置相对应的多个点。在其他实现中,描述界标的位置的姿态数据包括身体的简笔画表示,其中各种界标(例如,手、肘、肩等)经由边缘连接。除了界标位置,身体姿态数据还可以描述检测到的身体的各种其他特点,诸如身体相对于与输入图像202相关联的坐标结构的倾斜、偏离和/或滚转角。例如,基于相对于彼此的界标位置可以计算角度。
在一些实现中,人员检测模型204可以为每个人员检测208提供描述相应的人员检测208是准确的可信度的数值(即,图像的识别部分实际上描绘了人体)。该数值可以被称为置信度得分。通常,较大的置信度得分指示该模型对预测更有信心。在一些示例中,置信度得分的范围可以从0到1。
如上所述,除了人员检测模型204之外,全人关联系统119还可以包括脸部检测模型206。脸部检测模型206可以被配置(例如,被训练)为检测图像中描绘的人脸。就是说,与人员检测模型204相反,脸部检测模型206可以被配置为仅在图像中搜索脸部,而不考虑身体的其余部分。因此,给定输入图像,脸部检测模型206可以输出一个或多个脸部检测210,其中每个脸部检测210指示输入图像中的相应检测到的脸部的相应检测到的脸部位置。
脸部的位置可以以多种不同方式被指示。作为一个示例,脸部检测210可以将检测到的脸部的位置指示为边界形状。边界形状可以是二维形状或三维形状(例如,取决于输入图像的尺寸结构)。边界形状可以识别影像中的像素(或体素)组,其与图像内的脸部位置相对应。边界形状可以是多边形形状(例如,方框或立方体)、弯曲形状(例如,圆形或椭圆形)或任意形状(例如,识别包围检测到的脸部的特定像素(或体素)组的分割掩模)。
作为另一示例,除了边界形状或可选地,脸部检测210可以通过描述脸部姿态的姿态数据指示相应的检测到的脸部的位置。例如,姿态数据可以识别检测到的脸部的一个或多个面部界标的位置。例如,面部界标可以包括眼睛界标、鼻子界标、眉毛界标、嘴唇界标、下巴界标或其他面部界标。在一些实现中,描述界标位置的姿态数据仅包括与界标位置相对应的多个点。在其他实现中,描述界标位置的姿态数据包括脸部的连接表示,其中各种界标(例如,所有嘴唇界标)经由边缘连接。除了界标位置之外,面部姿态数据还可以描述检测到的脸部的各种其他特点,诸如脸部相对于与输入影像相关联的坐标结构的倾斜、偏离和/或滚转角。例如,基于相对于彼此的界标位置可以计算角度。
在一些实现中,脸部检测模型206可以为每个脸部检测210提供描述相应的脸部检测是准确的可信度的数值(即,图像的已识别的部分实际上描绘了人脸)。该数值可以被称为置信度得分。通常,较大的置信度得分指示该模型对预测更有信心。在一些示例中,置信度得分的范围可以从0到1。
因此,全人关联系统119可以获得输入图像202,并且可以将输入图像202输入到人员检测模型204和脸部检测模型206中,以接收一个或多个人员检测208和一个或多个脸部检测210,以及指示模型在其检测中有多少信心的置信度得分。
为了提供示例,图4A示出了示例输入图像300。图像300描绘了五个人,分别被标记为301-305。现在参照图4B,已经从输入图像300中生成了多个脸部和人员检测。例如,脸部检测311、312、313、314和315已经生成,以及人员检测321、322、323和324已经生成。脸部检测311-315和人员检测321-324中的每一个都提供边界形状(在此为边界框),并且具有与边界形状相邻提供的相应的置信度得分。可以看出,脸部检测311-315包含一些错误。例如,对于分别描绘时钟和出口标志的图像部分,错误地生成了脸部检测312和313。另一方面,对于人员302和人员305的脸部,错误地错过了脸部检测。
再次参照图2,根据本公开的一个方面,在一些示例实现中,人员检测模型204和脸部检测模型206可以被包括在单个、多头模型中,该模型包括共享特征提取部分、人员检测头部和脸部检测头部。图3描绘了这样的多头人员和脸部检测模型240的示例的框图。模型240可以包括共享特征提取部分250、人员检测头部252和脸部检测头部254。如上下文中所使用的,术语“头部”是指模型架构的一部分,而不是人员的物理头部。
输入图像202可以被输入到共享特征提取部分250中。共享特征提取部分250可以从输入图像中提取一个或多个特征。共享特征提取部分250可以将提取的特征提供给人员检测头部252和脸部检测头部254中的每一个。人员检测头部254和脸部检测头部254可以分开处理提取的特征,以分别生成人员检测208和脸部检测210。
以这种方式,从输入图像202获得人员检测208和脸部检测210两者所需的处理量可以被减少。就是说,不像通常执行的那样运行两个分开的模型,而是可以执行单个共享特征提取部分250以提取特征,然后两个分开的头部252和254可以针对共享特征操作以执行分开的人员和脸部检测。因此,使用单个多头模型240能够节省诸如存储器使用、处理器使用、计算时间、能源使用和/或网络使用的计算资源。
在一个示例中,共享特征提取部分250、人员检测头部252和脸部检测头部254中的每一个可以是或包括诸如卷积神经网络的神经网络。例如,在一些实现中,共享特征提取部分250可以是包括一个或多个卷积的卷积神经网络,并且人员检测头部252和脸部检测头部254中的每一个可以是包括一个或多个神经元层的前馈神经网络(例如,只有单个、最终分类层)。因此,在一些实现中,大部分处理工作由共享特征提取部分250执行,从而利用了本文其他地方所述的资源节省优势(例如,更少的浮点运算、更少的参数等),并且实质上提供了“二合一”场景,其中一个模型的资源使用价值可提供两次检测208和210。
再次参照图2,根据本公开的另一方面,在接收到人员和脸部检测之后,关联器212可以尝试将每个脸部检测210与人员检测208之一相关联,反之亦然。例如,当脸部检测210与人员检测208相关联时,它可以生成全人检测,这可以被称为“外观”214。如本文将进一步讨论的,将脸部检测210与人员检测208相关联以生成外观214的能力可以用作筛选(例如,丢弃)某些脸部检测210(例如,那些被认为是假阳性的)的基础。
在一些实现中,关联器212可以针对每个脸部检测210试图将脸部检测210与人员检测208之一迭代地匹配,直到找到认可的关联为止,反之亦然。作为一个示例,对于每个脸部检测210,关联器212可以识别在阈值距离内的任何人员检测208(例如,基于它们相应位置的比较),并且可以尝试将脸部检测210与已识别的人员检测208之一进行关联(例如,从最靠近的开始)。在其他实现中,针对每个脸部检测210仅分析固定数目(例如,一个)的最靠近的人员检测208。
在一些实现中,基于与检测相关联的位置和/或姿态数据可以执行关联分析。例如,关联器212可以应用一组规则或条件来确定脸部检测210是否应当与人员检测208相关联,反之亦然。
作为一个例子,如果脸部检测210和人员检测208彼此之间在一定距离之内(例如,它们的形心在一定距离之内),则它们可以相匹配。例如,距离可以以像素为单位进行测量,或者以例如脸部宽度的百分比进行测量(例如,进行归一化以使人员的大小(以像素为单位)无关紧要)。
作为另一个示例,如果脸部检测210与人员检测208的相应边界形状(例如,边界框、语义分割等)具有超过阈值的重叠量,则它们可以相匹配。例如,可以将重叠量测量为整个脸部边界形状的百分比。
作为另一个示例,可以将用于脸部和人员检测210、208的姿态数据进行比较以确定关联是否合适。例如,如上所述,脸部检测210可以指示与一个或多个面部界标(例如,眼睛、嘴唇、耳朵、鼻子、下巴、眉毛等)相关联的一个或多个面部界标位置。类似地,人员检测208还可以指示与一个或多个面部界标相关联的一个或多个面部界标位置。在一些实现中,比较来自脸部和人员检测的相应姿态数据的集合可以包括确定分别由脸部和人员检测提供的每对对应的界标位置之间的相应距离。例如,可以在由脸部检测210提供的“中央上唇”界标位置与由人员检测208提供的“中央上唇”界标位置之间评估距离(例如,归一化距离)。对所有成对的匹配界标可以执行相同的操作(或者如果希望评估某种关系,甚至对不匹配的界标执行)。关联器212可以基于这样计算的距离来确定是否将脸部检测210与人员检测208相关联。
作为仅出于说明性目的而提供的一个具体且非限制性的示例,可以如下计算对于给定脸部检测(f
其中f
也可以应用上述规则和条件的各种组合。跨多个关联度量的累积得分可以被计算并将其与阈值进行比较。可以将多个度量相互加权。在一些实现中,关联器212选择将脸部检测与人员检测相关联,其两者(1)具有超过阈值的得分和(2)具有所有评定的人员检测中的最高得分。但是,也可以应用其他不同的条件组。
为了提供示例,图4C提供了一些全人检测或外观的示例。例如,脸部检测314和人员检测322已经相关联以形成外观。类似地,脸部检测315和人员检测323已经相关联以形成不同个体的另一外观。然而,脸部检测311、312和313以及人员检测321和324均未与配对物相关联。
再次参照图2,根据本公开的一个方面,在试图将每个脸部检测与人员检测之一相关联之后,反之亦然,脸部检测筛选器216可以对面部检测进行筛选,以试图去除假阳性。具体地,脸部检测筛选器216可以基于脸部检测是否能够与人员检测之一相关联来智能地筛选每个脸部检测。
更具体地,作为筛选过程的一部分,可以将与每个脸部检测210相关联的相应置信度得分与置信度阈值进行比较,以确定是保留还是丢弃脸部检测210。作为一个具体且非限制性的示例,置信度阈值可以设置为0.5,使得如果置信度得分或阈值没有任何变更,则丢弃具有相应置信度得分小于0.5的脸部检测210,而保留具有相应置信度得分大于0.5的脸部检测210。
然而,根据本公开的一个方面,可以基于如上所述的关联来修改置信度得分和/或阈值。具体地,在一些实现中,对于与人员检测208之一成功地相关联的每个脸部检测210,脸部检测筛选器216可以增加与这样的脸部检测210相关联的置信度得分和/或可以降低与筛选这样的脸部检测210相关联的置信度阈值。可选地或附加地,对于未与人员检测208之一成功地相关联的每个脸部检测210,脸部检测筛选器216可以降低与这样的脸部检测210相关联的置信度得分和/或可以增加与筛选这样的脸部检测210相关联的置信度阈值。
因此,本公开的系统和方法可以使用脸部和人员检测的并置来调整置信度得分和/或相应的阈值。例如,能够与人员检测208相关联的低置信度脸部检测210反而可以被视为存在脸部的高置信度。然而,如果低置信度的脸部检测210不能与人员检测208相关联,则可以降低其置信度(或者可选地,不增加其置信度)。以这样方式,可以组合图像内的多种检测类型以减少假阳性脸部检测的数量,从而提高脸部检测210的精度。
为了提供示例,图4D和4E示出了脸部检测的示例筛选。具体地,图4D示出了五个脸部检测311、312、313、314和315。每个检测具有对应的置信度得分。使用示例置信度阈值0.5,可以看出脸部检测312、313和315具有低于示例置信度阈值的对应置信度得分,而脸部检测311和314具有大于阈值的置信度得分。因此,在没有任何操纵的情况下,将保留检测311和314,而将丢弃检测312、313和315。然而,由于脸部检测315已经成功地与人员检测323相关联,所以应用于脸部检测315的置信度得分可以被减小(例如,减小到0.1)。由于脸部检测315具有大于减小的阈值(0.1)的置信度得分(0.15),因此可以保留脸部检测315(实际上是正确的)。然而,由于脸部检测312和313均未与人员检测相关联,因此未调整的阈值0.5可以被应用于检测312和313(实际上是不正确的),从而导致这些检测被丢弃。该结果在图4E中示出。因此,可以看出,来自人员检测和相应的关联的线索已用于改善脸部筛选过程。具体地,在所示的示例中,即使脸部检测315所接收的置信度得分低于脸部检测313,也最终保留了脸部检测315,而丢弃了脸部检测313。实际上,这种结果提高了脸部检测的精度。
再次参照图2,本文描述为应用于筛选脸部检测210的筛选技术同样能够应用于筛选人员检测208。例如,对于成功与脸部检测210之一相关联的每个人员检测208,脸部检测筛选器216可以增加与这样的人员检测208相关联的置信度得分和/或可以降低与筛选人员检测208相关联的置信度阈值。可选地或额外地,对于未成功地与脸部检测210之一相关联的每个人员检测208,脸部检测筛选器216可以降低与这样的人员检测208相关联的置信度得分和/或可以增加与筛选这样的人员检测208相关联的置信度阈值。
根据本公开的另一方面,除脸部检测筛选器216之外或可选地,全人关联系统119可以包括基于未关联的人员检测对脸部检测进行幻构的脸部幻构器218,反之亦然。例如,对于特定的人员检测208(例如,在执行上述关联过程之后没有与脸部检测210相关联的人员检测),脸部幻构器218可以至少部分地基于由人员检测208提供的检测到的人体的检测到的身体位置来生成幻构的脸部检测。幻构的脸部检测可以指示与检测到的人体相关联的脸部在输入图像中的幻构的脸部位置。
具体地,在一些实现中,由人员检测208提供的位置和/或姿态信息可以用于生成幻构的脸部检测。作为示例,如上所述,在一些实现中,人员检测208可以描述分别与检测到的人体的一个或多个身体组成部分相关联的一个或多个身体姿态界标。在这样的实现中,至少部分地基于检测到的人体的检测到的身体位置来生成幻构的脸部检测可以包括至少部分地基于一个或多个身体姿态界标来生成一个或多个幻构的脸部姿态界标。例如,人员检测208的身体姿态界标可以具体包括面部界标,并且在这种情况下,面部界标可以直接用于生成幻构的脸部姿态界标。在其他实现中,人员检测的身体姿态界标可以仅包括与身体的躯干或四肢相关联的界标,并且生成幻构的脸部姿态界标可以包括将身体图谱(例如,包括关于各种身体界标和/或面部界标之间的典型间隔的信息)投射到躯干或肢体界标上,以识别幻构的脸部姿态界标。几何处理可以被执行以确定幻构的脸部的范围或边界和/或诸如面部姿态信息的其他信息。
在一些实现中,脸部幻构器218可以选择仅保存满足某些特点或条件的幻构的脸部。作为一个示例,为了保留幻构的脸部检测,在相对狭窄的前窗内可能需要或具有头部姿态。例如,在认可的范围内可能需要与幻构的脸部相关联的偏离、俯仰和/或滚转角,以便保留幻构的脸部。
在一些实现中,对于没有相关联的脸部检测的任何人员检测208,脸部可以被幻构。在其他实现中,仅对于(1)没有相关联的脸部检测以及(2)具有大于一些阈值的置信度得分的人员检测,脸部可以被幻构。然后可以将每个幻构的脸部与相应人员检测相关联以生成全人检测或“外观”。
以这种方式,脸部幻构器218可以为不相关联的人员检测对脸部进行幻构。这可以减少假阴性脸部检测,其中在图像中描绘了脸部但未被脸部检测器识别(例如,当脸部高度背光或脸部被部分遮挡时可能发生)。因此,通过组合来自相同图像(或跨多个图像)的多种检测类型的证据由最终脸部检测所展示出的召回(例如,包括幻构的脸部)可以被提高。改善脸部检测的召回还可以提供节省计算资源的好处。换句话说,因为如本文所述的脸部的幻构导致总体上发生更多的脸部检测,所以脸部检测模型206可能不需要在尽可能多的帧上运行以取得相同的结果,特别是当跨帧跟踪检测时。因此,较少执行模型总体上会导致节省资源,诸如节省存储器使用、处理器使用等。
图4F和4G示出了脸部幻构过程和结果的示例。例如,参照图4E,可以看出,人员检测321和324先前没有与之相关联的脸部检测。参照图4F,可以看出,幻构的脸部检测331和332已经分别针对人员检测321和324进行了幻构。例如,人员检测321和324中包括的相应面部界标信息可以用于分别生成幻构的脸部检测331和332。幻构的脸部检测331和332可以被分析以确定它们是否满足某些接受条件。作为示例,参照图4G,可以看出,幻构的脸部检测331被丢弃,是由于例如幻构的脸部检测331具有-50度的脸部倾斜,这在示例可接受的倾斜角度范围之外。然而,幻构的脸部检测332已被保留。
再次参照图2,在一些实现中,全人关联系统119可以是较大过程中的初始阶段,该较大过程包括在检测人员或脸部之后执行的多个下游行动,诸如识别面部(例如,解锁移动设备,解译命令,在照片管理应用中对照片进行聚类或搜索),检测与人员相关联的凝视方向(例如,理解人类发出的口头命令的主题)或其他活动。因此,在一些示例中,可以裁剪与幻构的脸部检测相对应的输入图像202的一部分,并将其发送到下游模型(例如,面部识别模型和/或凝视检测模型)以进行处理。这样,脸部幻构可以将脸部相关技术应用于图像的特定部分,而不是整个图像,从而节省了处理时间、计算能力、存储器使用等。
关于图2描述的各种阈值可以手动设置,或者可以基于训练数据学习。本文所述的各种阈值例如可以是固定的,或者可以基于各种特点(诸如图像分辨率、图像照明、用于控制权衡的手动调整(例如,精度与召回)、与脸部检测和/或人员检测相关联的置信度值等)而自适应。
附加公开
本文讨论的技术参考了服务器、数据库、软件应用和其他基于计算机的系统,以及对这样的系统采取的行动和发送的信息。基于计算机的系统的固有灵活性允许任务的各种各样的可能配置、组合和划分以及组件之间和组件中的功能。例如,可以使用单个装置或组件或者组合工作的多个装置或组件来实现本文讨论的过程。数据库和应用可以在单个系统上实现,也可以分布在多个系统上。分布式组件可以顺序或并行运行。
尽管已经针对本主题的各种具体示例实施例详细描述了本主题,但是每个示例都是通过说明的方式提供的,而非对本公开的限制。本领域技术人员在理解前述内容后,可以容易地产生对这样的实施例的变更、变化和等同。因此,本领域的公开内容并不排除本主题包括这样的修改、变化和/或添加,这对于本领域的普通技术人员来说是显而易见的。例如,作为一个实施例的一部分示出或描述的特征可以与另一实施例一起使用以产出又一实施例。因此,本公开旨在涵盖这样的变更、变化和等同。
- 进行脸部筛选的全人关联
- 一种在应用/系统间进行关联和筛选数据的方法