新型果糖-4-差向异构酶以及使用其制备塔格糖的方法
文献发布时间:2023-06-19 12:14:58
技术领域
本发明涉及一种果糖-4-差向异构酶变体,其具有改善的转化活性或稳定性,以及使用其制备塔格糖的方法。
背景技术
塔格糖具有很难与蔗糖区分开的天然甜味,并且还具有类似于蔗糖的物理性质。塔格糖是一种天然甜味剂,其少量存在于诸如牛奶、奶酪、可可等食物中,以及诸如苹果和橘子的甜水果中。塔格糖的热量值为1.5kcal/g,是蔗糖的三分之一,其血糖指数(GI)为3,是蔗糖的5%。塔格糖具有类似于蔗糖的甜味,并具有多种有益于健康的功能。鉴于此,在多种产品中,塔格糖可以用作能够满足健康需求和口味的替代甜味剂。
制备塔格糖的常用方法包括使用半乳糖作为主要原料的化学方法(催化反应)或生物方法(异构化酶反应)(参见韩国专利号10-0964091)。为了经济地获得作为上述反应原料的半乳糖,对各种包含半乳糖的基本原料,以及从这些原料中获得半乳糖以制备塔格糖的方法进行了研究。用于获得半乳糖的代表性基础原料是乳糖。然而,乳糖或者包含乳糖的产品的价格不稳定,这取决于全球市场中原料奶和乳糖的产量、供应和需求等。因此,用于制备塔格糖的原料的稳定供应受到限制。因此,亟需能够以普通糖(蔗糖、葡萄糖、果糖等)作为原料制备塔格糖的新方法。
发明内容
本发明人开发了一种新型的变体蛋白,其在氨基酸序列SEQ ID NO:1中包含一个或多个氨基酸取代,并且发现所述变体蛋白具有与野生型SEQ ID NO:1相同的转化活性,或者相比野生型,具有改进的转化活性或稳定性,以及改进的塔格糖产量,从而完成本发明。
技术方案
本发明的一个目的是提供一种果糖-4-差向异构酶变体,其在SEQ ID NO:1的氨基酸序列中包含一个或多个氨基酸取代。
本发明的另一个目的是提供一种编码果糖-4-差向异构酶变体的多核苷酸。
本发明的另一个目的是提供一种载体,其包含所述多核苷酸。
本发明的另一个目的是提供一种微生物,其包含所述变体。
本发明的另一个目的是提供一种用于制备塔格糖的组合物,所述组合物包含果糖-4-差向异构酶变体、表达所述变体的微生物或所述微生物的培养物中的一个或多个。
本发明的另一个目的是提供一种制备塔格糖的方法,所述方法包括在微生物、所述微生物的培养物、或其衍生的果糖-4-差向异构酶的存在下,使果糖进行反应的步骤。
有益效果
本发明的果糖-4-差向异构酶变体使得塔格糖的工业规模的生产具有优异的特点,并将普通糖果糖转化为塔格糖,因此展示出很高的经济效益。
附图说明
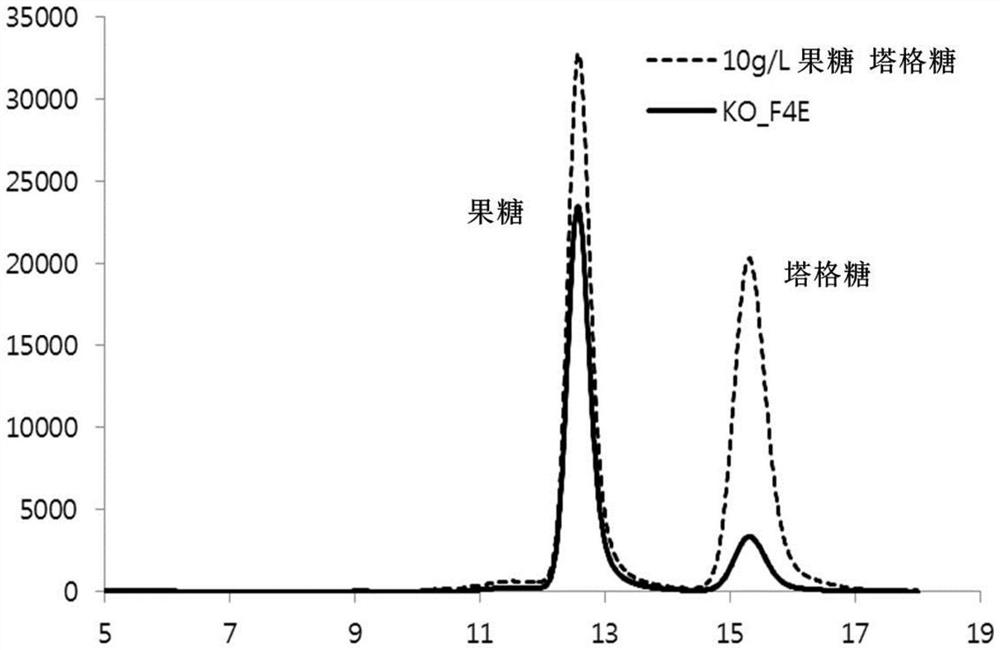
图1示出HPLC色谱结果,示出了本发明的一个实施方案制备的塔格糖-二磷酸醛缩酶(KO_F4E)具有果糖-4-差向异构酶的活性。
图2示出60℃下,变体的热稳定性随时间变化的测量结果,其中,所述变体具有在位置124的苏氨酸的变异,所述变体通过本发明的一个实施方案制备。
图3示出60℃下,活性随时间变化的测量结果,其中,所述活性是变体的果糖-4-差向异构化活性,所述变体通过本发明的一个实施方案制备。
图4示出60℃下,热稳定性随时间变化的测量结果,其中,所述热稳定性是变体的热稳定性,所述变体通过本发明的一个实施方案制备。
具体实施方式
以下将对本发明进行详细地描述。同时,本文公开的每个描述和实施方案都可以应用于其他描述和实施方案。即,本发明公开的各种元素的所有组合都落入本发明的范围内。另外,本发明的范围不受限于以下的具体描述。
为了实现本发明的目的,本发明的一方面提供一种果糖-4-差向异构酶变体,在果糖-4-差向异构酶氨基酸序列中包含一个或多个氨基酸取代。
为了实现本发明的目的,本发明的另一方面提供一种果糖-4-差向异构酶变体,其在SEQ ID NO:1的氨基酸序列中包含一个或多个氨基酸取代。
如本文所用,术语“果糖-4-差向异构酶”是指一种酶,其具有在果糖的第4碳位置通过差向异构化将果糖转化为塔格糖的果糖-4-差向异构化活性。对于本发明的目的,果糖-4-差向异构酶可以包括任何酶,而不受限制,只要其能够以果糖为底物产生塔格糖,并且其可以与“D-果糖C4-差向异构酶”互换使用。例如,果糖-4-差向异构酶可以包括塔格糖-二磷酸醛缩酶或塔格糖-二磷酸醛缩酶II类辅助蛋白(Tagatose-bisphosphate aldolaseor tagatose-bisphosphate class II accessory protein),其属于已知数据库京都基因与基因组百科全书(KEGG,Kyoto Encyclopedia of Genes and Genomes)中的EC4.1.2.40,只要其具有将底物果糖转化为塔格糖的活性。已知塔格糖-二磷酸醛缩酶可以D-塔格糖1,6-二磷酸为底物,产生磷酸甘油酮(glycerone phosphate)和D-甘油醛3-磷酸(D-glyceraldehyde3-phosphate),如下述[反应式1]所示。
[反应式1]
D-塔格糖1,6-二磷酸<=>磷酸甘油酮+D-甘油醛3-磷酸
例如,果糖-4-差向异构酶可以包括塔格糖-6-磷酸激酶(Tagagose 6phosphatekinase;EC 2.7.1.144),只要其具有将底物果糖转化为塔格糖的活性。如下述[反应式2]所示,已知塔格糖-6-磷酸激酶可以ATP和D-塔格糖6-磷酸(D-tagatose 6-phosphate)为底物,产生ADP和D-塔格糖1,6-二磷酸(D-tagatose 1,6-bisphosphate)。
[反应式2]
ATP+D-塔格糖6-磷酸<=>ADP+D-塔格糖1,6-二磷酸
果糖-4-差向异构酶将底物果糖转化为塔格糖的转化率(转化率=塔格糖质量/果糖初始质量*100)可以为0.01%或更高,特别地,0.1%或更高,更特别地,0.3%或更高。更特别地,转化率可以为0.01%至100%,或0.1%至50%。
本发明的果糖-4-差向异构酶、塔格糖-二磷酸醛缩酶、或塔格糖-6-磷酸激酶可以为衍生自耐热微生物或其变体的酶,例如,衍生自Kosmotoga olearia、Thermanaerothrixdaxensis、Rhodothermus profundi、海洋红嗜热盐菌(Rhodothermus marinus)、Limnochorda pilosa、Caldithrix abyssi、Caldilinea aerophila、热产硫化氢热厌氧杆菌(Thermoanaerobacter thermohydrosulfuricus)、酸杆菌细菌(Acidobacterialesbacterium)、Caldicellulosiruptor kronotskyensis、解热嗜热厌氧杆菌(Thermoanaerobacterium thermosaccharolyticum)或假单胞菌H103(Pseudoalteromonassp.H103)的酶或其变体,但不限于此。特别地,为衍生自Kosmotoga olearia(SEQ ID NO:1)、解热嗜热厌氧杆菌(SEQ ID NO:3)、假单胞菌H103(SEQ ID NO:5)、Thermanaerothrixdaxensis(SEQ ID NO:7)、酸杆菌细菌(SEQ ID NO:9)、Rhodothermus profundi(SEQ IDNO:11)、海洋红嗜热盐菌(SEQ ID NO:13)、Limnochorda pilosa(SEQ ID NO:15)、Caldithrix abyssi(SEQ ID NO:17)、Caldicellulosiruptor kronotskyensis(SEQ IDNO:19)、Caldilinea aerophila(SEQ ID NO:21)或热产硫化氢热厌氧杆菌(SEQ ID NO:23)的酶或其变体,但不限于此。
特别地,果糖-4-差向异构酶、塔格糖-二磷酸醛缩酶、或塔格糖-6-磷酸激酶可以包含SEQ ID NO:1、3、5、7、9、11、13、15、17、19、21、或23的氨基酸序列,或与其具有70%或更高的同源性或相同性的氨基酸序列,但不限于此。更特别地,本发明的果糖-4-差向异构酶可以包含与SEQ ID NO:1、3、5、7、9、11、13、15、17、19、21或23的氨基酸序列具有至少60%、70%、80%、85%、90%、95%、96%、97%、98%、99%的同源性或相同性的多肽。此外,具有氨基酸序列以及表现出与上述蛋白相应的效力的辅助蛋白显然也落入本发明的范围内,所述氨基酸序列具有同源性或相同性,尽管氨基酸序列的部分序列存在缺失、修饰、取代或添加。
在本发明中,SEQ ID NO:1是指具有果糖-4-差向异构酶活性的氨基酸序列。SEQID NO:1序列可从已知数据库NCBI的GenBank或KEGG(Kyoto Encyclopedia of Genes andGenomes)获得。例如,所述序列可衍生自Kosmotoga olearia,更特别地,为包含SEQ ID NO:1的氨基酸序列的多肽/蛋白,但不限于此。此外,可以非限制性地包括具有与上述氨基酸序列相同的活性的序列。此外,可以包括SEQ ID NO:1氨基酸序列或与其具有70%或更高的同源性或相同性的氨基酸序列,但不限于此。特别地,所述氨基酸序列可以包含具有SEQ IDNO:1的氨基酸序列以及与SEQ ID NO:1具有至少70%、80%、85%、90%、95%、96%、97%、98%或99%或更高的同源性或相同性的氨基酸序列。此外,虽然氨基酸序列中的部分序列存在缺失、修饰、取代或添加,但是具有氨基酸序列以及表现出与上述蛋白相应的效力的蛋白显然也落入本发明的范围内,所述氨基酸序列具有同源性或相同性。
即,尽管在本发明中描述为“具有特定SEQ ID NO的氨基酸序列的蛋白”,所述蛋白可以具有与由相应的SEQ ID NO的氨基酸序列组成的蛋白相同或相似的活性。在此情况下,明显地,具有部分序列缺失、修饰、取代、保守取代或添加的氨基酸序列的任何蛋白也可以用于本发明。例如,在具有与经修饰的蛋白相同或相应的活性的情况下,不排除在氨基酸序列的上游或下游添加序列(这不会改变蛋白的功能)、可能自然发生的突变、其沉默突变或保守取代,并且即使存在序列添加或突变,其也显然落入本发明的范围内。
如本文所用,术语“塔格糖”是指一种己酮糖,其为一种单糖,与“D-塔格糖”互换使用。
如本文所用,术语“果糖-4-差向异构酶变体”是指包含一个或多个氨基酸取代的果糖-4-差向异构酶变体,所述取代发生在具有果糖-4-差向异构酶活性的多肽的氨基酸序列上。
果糖-4-差向异构酶变体可以包括一种变异,两种变异,三种变异,四种变异,或五种变异,其包括其他氨基酸对SEQ ID NO:1氨基酸序列位置124的氨基酸的取代,但不限于此。
特别地,本发明提供一种果糖-4-差向异构酶变体,其包括i)其他氨基酸对位置124的氨基酸的取代,ii)其他氨基酸对位置124和位置390的氨基酸的取代,iii)其他氨基酸对位置124和位置97的氨基酸的取代,iv)其他氨基酸对位置124和位置97的氨基酸的取代,以及其他氨基酸对位置33、80、102、137、210、318和367中的任意一个的氨基酸的取代,v)其他氨基酸对位置124、97和367的氨基酸的取代,以及其他氨基酸对位置33、80、102、137、210、239和318中的任意一个的氨基酸的取代,vi)其他氨基酸对位置124、97、367和33的氨基酸的取代,以及其他氨基酸对位置80、102、210和318中的任意一个的氨基酸的取代,vii)其他氨基酸对位置124、97、367和80的氨基酸的取代,以及其他氨基酸对位置102、137和210中的任意一个的氨基酸的取代,或者viii)其他氨基酸对位置124、97、367、210和318的氨基酸的取代,但不限于此。
如本文所用,“位置N”可以包括位置N和与位置N对应的氨基酸位置,特别地,为与特定氨基酸序列公开的成熟多肽的任意氨基酸残基对应的氨基酸位置。所述特定氨基酸序列可以是SEQ ID NO:1、3、5、7、9、11、13、15、17、19、21、和23中的任意一个氨基酸序列。
与位置N对应的氨基酸位置或与特定氨基酸序列公开的成熟多肽的任意氨基酸残基对应的氨基酸位置可以使用Needleman-Wunsch算法确定(Needleman and Wunsch,1970,J.Mol.Biol.48:443-453),特别地,为5.0.0或之后的版本,正如EMBOSS软件包(EMBOSS:TheEuropean Molecular Biology Open Software Suite,文献[Rice et al.,2000,TrendsGenet.16:276-277])的Needle程序中所实现的。使用的参数可以是空位开放罚分10、空位扩展罚分0.5和EBLOSUM62(EMBOSS BLOSUM62版本)替换矩阵。
在与位置N对应的氨基酸位置或与特定氨基酸序列公开的成熟多肽的任意氨基酸残基对应的氨基酸位置上,氨基酸残基的识别可以由几个计算机程序对多个多肽序列进行比对来确定,所述计算机程序包括但不限于MUSCLE(multiple sequence comparison bylog-expectation;3.5或之后的版本,文献[Edgar,2004,Nucleic Acids Research32:1792-1797]),MAFFT(6.857或之后的版本;文献[Katoh and Kuma,2002,Nucleic AcidsResearch 30:3059-3066];文献[Katoh et al.,2005,Nucleic Acids Research 33:511-518];文献[Katoh and Toh,2007,Bioinformatics 23:372-374];文献[Katoh et al.,2009,Methods in Molecular Biology 537:39-64];文献[Katoh and Toh,2010,Bioinformatics 26:1899-1900]),和使用ClustalW的EMBOSS EMMA(1.83或之后的版本;文献[Thompson et al.,1994,Nucleic Acids Research 22:4673-4680]),采用他们各自的默认参数。
当另一多肽由特定氨基酸序列的成熟多肽分化而来,以致于传统的基于序列的对比无法检测他们之间的关系时(文献[Lindahl and Elofsson,2000,J.Mol.Biol.295:613-615]),可以使用其他的成对序列比较算法。使用利用多肽家族(图谱)的概率表示的搜索程序搜索数据库,可以在基于序列的搜索中获得更高的灵敏度。例如,经过迭代数据库搜索过程,PSI-BLAST程序生成了图谱,并且能够检测远端同源物(文献[Atschul et al.,1997,Nucleic Acids Res.25:3389-3402])。如果多肽的家族或超家族在蛋白结构数据库中具有一个或多个代表,仍可以获得更高的灵敏度。例如GenTHREADER程序,(文献[Jones,1999,J.Mol.Biol.287:797-815];文献[McGuffin and Jones,2003,Bioinformatics19:874-881])利用源自多种资源的信息(PSI-BLAST,二级结构预测,结构比对图谱和溶剂化势)作为神经网络的输入,所述神经网络预测查询序列的结构折叠。类似地,文献[Gough et al.,2000,J.Mol.Biol.313:903-919]所示的方法可被用于将未知结构的序列与SCOP数据库中的超家族模型进行比对。这些比对又可以用于产生多肽的同源性、相似性、或相同性模型,并且可以使用为评价准确性而开发的工具评估这些模型的准确性。
“其他多肽”并无限制,只要其是与位置对应的氨基酸以外的氨基酸即可。根据其侧链的性质,“氨基酸”分为四类:酸性、碱性、极性(亲水性)、和非极性(疏水性)氨基酸。
特别地,所述变体可以是具有一个或多个选自以下的氨基酸对氨基酸序列SEQ IDNO:1的每一个位置的氨基酸取代的蛋白:非极性氨基酸,包括甘氨酸(G)、丙氨酸(A)、缬氨酸(V)、亮氨酸(L)、异亮氨酸(I)、甲硫氨酸(M)、苯丙氨酸(F)、色氨酸(W)和脯氨酸(P);极性氨基酸,包括丝氨酸(S),苏氨酸(T),半胱氨酸(C),酪氨酸(Y),天冬氨酸(D)和谷氨酰胺(Q);酸性氨基酸,包括天冬酰胺(N)和谷氨酸(E);和碱性氨基酸,包括赖氨酸(K)、精氨酸(R)和组氨酸(H),但不限于此。
特别地,所述变体可以具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,其中,所述极性氨基酸或非极性氨基酸可选自色氨酸(W)、半胱氨酸(C)和酪氨酸(Y),但不限于此。
所述变体可以具有自果糖-4-差向异构酶的N端,其他氨基酸对位置124的苏氨酸(T)残基的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有非极性氨基酸、酸性氨基酸或碱性氨基酸(苏氨酸(T)除外)对位置390的氨基酸的取代,其中,所述非极性氨基酸、酸性氨基酸或碱性氨基酸可选自以赖氨酸(K)、甘氨酸(G)、缬氨酸(V)、亮氨酸(L)、组氨酸(H)、天冬氨酸(D)、异亮氨酸(I)和精氨酸(R),但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,其他氨基酸对位置124的苏氨酸(T)残基的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,其中,所述极性氨基酸可以是酪氨酸(Y),但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,以及极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有其他氨基酸对位置33、80、102、137、210、和318中的任意一个的氨基酸的取代,其中,所述其他氨基酸可选自甘氨酸(G)、丙氨酸(A)、精氨酸(R)、缬氨酸(V)、亮氨酸(L)、异亮氨酸(I)、苏氨酸(T)、脯氨酸(P)、丝氨酸(S)、色氨酸(W)、苯丙氨酸(F)、组氨酸(H)、半胱氨酸(C)、酪氨酸(Y)、赖氨酸(K)、天冬氨酸(D)和谷氨酸(E),但不限于此。特别地,所述变体可以具有丙氨酸(A)、丝氨酸(S)、色氨酸(W)、甘氨酸(G)、苯丙氨酸(F)或酪氨酸(Y)对位置33的氨基酸的取代,苯丙氨酸(F)、酪氨酸(Y)、精氨酸(R)、苯丙氨酸(F)、半胱氨酸(C)、苏氨酸(T)、丝氨酸(S)、亮氨酸(L)、赖氨酸(K)或谷氨酸(E)对位置80的氨基酸的取代,苏氨酸(T)、丙氨酸(A)、脯氨酸(P)、丝氨酸(S)、亮氨酸(L)、异亮氨酸(I)或色氨酸(W)对位置102的氨基酸的取代,半胱氨酸(C)、谷氨酸(E)、甘氨酸(G)、精氨酸(R)或苯丙氨酸(F)对位置137的氨基酸的取代,天冬氨酸(D)、丝氨酸(S)、赖氨酸(K),缬氨酸(V)、亮氨酸(L)或甘氨酸(G)对位置210的氨基酸的取代,组氨酸(H)、甘氨酸(G)、异亮氨酸(I)、丙氨酸(A)或半胱氨酸(C)对位置318的氨基酸的取代,但不限于此。所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,极性氨基酸(苏氨酸(T)除外)对位置210的氨基酸的取代,碱性氨基酸(苏氨酸(T)除外)对位置390的氨基酸的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1氨基酸序列,所述变体还具有非极性氨基酸(脯氨酸(P))对位置318的氨基酸的取代,其中,所述非极性氨基酸可以为甘氨酸(G),但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,以及非极性氨基酸(天冬酰胺(N)除外)对位置367的氨基酸的取代,其中,所述极性氨基酸可以为酪氨酸(Y)并且所述非极性氨基酸可以为缬氨酸(V),但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,以及非极性氨基酸(天冬酰胺(N)除外)对位置367的氨基酸的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1氨基酸序列,所述变体还可以具有非极性氨基酸、极性氨基酸、或碱性氨基酸对位置102、137、210、239和318中的任意一个的氨基酸的取代,其中,所述非极性氨基酸、极性氨基酸、或碱性氨基酸可以选自亮氨酸(L)、半胱氨酸(C)、丝氨酸(S)、赖氨酸(K)和甘氨酸(G),但不限于此。
特别地,位置102的氨基酸可被亮氨酸(L)取代,位置137的氨基酸可被半胱氨酸(C)取代,位置210的氨基酸可被丝氨酸(S)取代,位置239的氨基酸可被赖氨酸(K)取代,或位置318的氨基酸可被甘氨酸(G)取代,但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,以及非极性氨基酸(天冬酰胺(N)除外)对位置367的氨基酸的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有非极性氨基酸对位置33的氨基酸的取代,其中,所述非极性氨基酸可以为精氨酸(R),但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,非极性氨基酸(天冬酰胺(N)除外)对位置367的氨基酸的取代,以及非极性氨基酸对位置33的氨基酸的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有碱性氨基酸、非极性氨基酸、或极性氨基酸对位置80、102、210和318中的任意一个的氨基酸的取代,其中,所述碱性氨基酸、非极性氨基酸或极性氨基酸可选自精氨酸(R)、亮氨酸(L)、丝氨酸(S)和甘氨酸(G),但不限于此。
特别地,位置80的氨基酸可被精氨酸(R)取代,位置102的氨基酸可被亮氨酸(L)取代,位置210的氨基酸可被丝氨酸(S)取代,或位置318的氨基酸可被甘氨酸(G)取代,但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,以及非极性氨基酸(天冬酰胺(N)除外)对位置367的氨基酸的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有碱性氨基酸对位置80的氨基酸的取代,其中,所述碱性氨基酸可以为精氨酸(R),但不限于此。
所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,非极性氨基酸(天冬酰胺(N)除外)对位置367的氨基酸的取代,以及碱性氨基酸对位置80的氨基酸的取代,所述果糖-4-差向异构酶包含SEQ ID NO:1的氨基酸序列,所述变体还可以具有非极性氨基酸或极性氨基酸对位置102、137和210中的任意一个的氨基酸的取代,其中,所述非极性氨基酸或极性氨基酸可选自亮氨酸(L)、半胱氨酸(C)和丝氨酸(S),但不限于此。
特别地,位置102的氨基酸可以被亮氨酸(L)取代,位置137的氨基酸可以被半胱氨酸(C)取代,或位置210的氨基酸可以被丝氨酸(S)取代,但不限于此。所述变体具有自果糖-4-差向异构酶的N端,极性氨基酸或非极性氨基酸(苏氨酸(T)除外)对位置124的苏氨酸(T)残基的取代,极性氨基酸(天冬酰胺(N)除外)对位置97的氨基酸的取代,以及非极性氨基酸(天冬酰胺(N)除外)对位置367的氨基酸的取代,所述果糖-4-差向异构酶位包含SEQ IDNO:1的氨基酸序列,所述变体还可以具有极性氨基酸(苏氨酸(T)除外)对位置210的氨基酸的取代以及非极性氨基酸(脯氨酸(P)除外)对位置318的氨基酸的取代,其中,所述极性氨基酸可以为丝氨酸(S)并且所述非极性氨基酸可以为甘氨酸(G),但不限于此。
果糖-4-差向异构酶变体可包括多肽,多肽的一个或多个氨基酸在保守取代和/或修饰方面与序列本身不同,除了其他氨基酸对特定位置的氨基酸的取代,同时还保留蛋白的功能或性质。
如本文所用,术语“保守取代”是指一个氨基酸被具有相似结构和/或化学性质的另一氨基酸取代。例如,所述变体可以具有一个或多个保守取代,同时保持一个或多个生物学活性。所述保守取代对得到的多肽的活性没有影响或影响很小。
此外,具有一个或多个氨基酸(上述特定位置以外的氨基酸)变异的变体可以包含对多肽的性质和二级结构具有最小影响的氨基酸的缺失或添加。例如,多肽可以与蛋白N端的信号(或先导)序列结合,该所述号(或先导)序列共同翻译或翻译后指导蛋白的转移。所述多肽还可与其他序列或接头缀合以用于鉴定、纯化或合成所述多肽。
此外,所述变体包括上述变异,即SEQ ID NO:1和/或与SEQ ID NO:1具有至少70%、80%、85%、90%、95%、96%、97%、98%或99%或更高的同源性或相同性的氨基酸的变异,而不是SEQ ID NO:1的变异和位置。SEQ ID NO:1的变异如上所述,并且其同源性或相同性可以是上述变异的位置以外的同源性或相同性。
对于本发明的目的,果糖-4-差向异构酶变体的特征是相比野生型,具有改进的转化活性或稳定性。
术语“转化活性”是指在C4位置差向异构化D-果糖从而将其转化为塔格糖。术语“稳定性”是指具有耐热性的酶具有热稳定性。特别地,果糖-4-差向异构酶的变体SEQ IDNO:1的特征是相比野生型的SEQ ID NO:1,其在C4位置差向异构化D-果糖从而将其转化为塔格糖的活性得到提高,和/或热稳定性得到提高。
例如,本发明的果糖-4-差向异构酶变体可以是具有高耐热性的酶。特别地,本发明的果糖-4-差向异构酶变体在50v至70℃下可以表现出其最大活性的50%至100%、60%至100%、70%至100%或75%至100%。更特别地,本发明的果糖-4-差向异构酶变体可以在55℃至60℃、60℃至70℃、55℃、60℃或70℃下表现出其最大活性的80%至100%或85%至100%。
本发明的另一方面提供一种多核苷酸,或包含所述多核苷酸的载体,其中所述多核苷酸用于编码果糖-4-差向异构酶变体。
如本文所用,术语“多核苷酸”是指DNA或RNA链,其具有既定的长度或更长,是一种通过共价键连接核苷酸单体而形成的核苷酸长链聚合物。更特别地,所述多核苷酸是指编码所述变体蛋白的多核苷酸片段。
所述编码本发明的果糖-4-差向异构酶变体的多核苷酸可以非限制性地包括任何多核苷酸序列,只要其为编码本发明的果糖-4-差向异构酶变体的多核苷酸序列。例如,本发明的编码所述果糖-4-差向异构酶变体的多核苷酸可以是一种多核苷酸序列,其编码氨基酸序列,但不限于此。在多核苷酸中,由于密码子简并性或考虑到蛋白表达所在的生物体优选的密码子,只要不改变蛋白的氨基酸序列,就可以在编码区进行各种修饰。因此,由于密码子简并性,本发明显然也可以包括多核苷酸,所述多核苷酸可以被翻译为由所述氨基酸序列组成的多肽或与所述氨基酸序列具有同源性或相同性的多肽。
此外,例如,也可以非限制性地包括由已知的核苷酸序列产生的探针,其在严格条件下与核苷酸序列全长的全部或部分杂交,以编码果糖-4-差向异构酶变体。
术语“严格条件”是指使多核苷酸之间进行特异性杂交的条件。这样的条件在文献(例如,J.Sambrook et al.,如前文所述)中有具体描述。例如,严格条件可以包括,例如具有高同源性或相同性的基因彼此杂交,同源性或相同性为70%或更高、80%或更高、85%或更高,特别地,90%或更高,更特别地,95%或更高,更特别地,97%或更高,更特别地,99%或更高,而同源性或相同性低于上述同源性或相同性的基因彼此不杂交的条件;或者可以包括Southern杂交的常规清洗条件,即在60℃、1×SSC和0.1%SDS,特别地60℃、0.1×SSC和0.1%SDS,并且更特别地68℃、0.1×SSC和0.1%SDS的盐浓度和温度下,清洗一次,特别地,清洗两次或三次的条件。
杂交需要两个核苷酸具有互补的序列,即使由于杂交的紧密性,核苷酸之间可能会出现错配。术语“互补的”用于描述可以彼此杂交的核苷酸碱基之间的关系。例如,对于DNA,腺嘌呤与胸腺嘧啶互补,胞嘧啶与鸟嘌呤互补。因此,本发明不仅可以包括基本上相似的核酸序列,还可以包括与整个序列互补的分离出的核酸片段。
特别地,具有同源性或相同性的多核苷酸可以使用在上述条件下的T
用于杂交多核苷酸的合适的严格性取决于多核苷酸的长度和互补程度,并且这些变量是本领域众所周知的(参见Sambrook等,supra,9.50-9.51,11.7-11.8)。
如本文所用,术语“同源性”或“相同性”是指两个给定的氨基酸序列或核苷酸序列之间的相关程度,并且可以表示为百分比。
术语“同源性”或“相同性”经常可以互换使用。
保守的多核苷酸或多肽序列的同源性或相同性可以通过标准比对算法来确定,并且可以与所使用的程序所建立的默认空位罚分一起使用。基本上,在中等或高度严格条件下,同源或相同的序列可以杂交,以使序列全长的全部或者至少约50%、约60%、约70%、约80%或约90%或以上可以杂交。在杂交中,也考虑包含简并密码子而非密码子的多核苷酸。
可以通过已知的计算机算法,例如使用默认参数的“FASTA”程序(Pearson etal.,(1988)[Proc.Natl.Acad.Sci.USA 85]:2444)确定任何两个多核苷酸或多肽序列是否具有同源性、相似性或相同性。或者,也可以通过Needleman-Wunsch算法(Needleman andWunsch,1970,J.Mol.Biol.48:443-453)来确定,其通过EMBOSS软件包的Needleman程序执行(EMBOSS:The European Molecular Biology Open Software Suite,Rice et al.,2000,Trends Genet.16:276-277)(优选5.0.0版或之后的版本)(GCG程序包(Devereux,J.,et al.,Nucleic Acids Research 12:387(1984)),BLASTP,BLASTN,FASTA(Atschul,[S.][F.,][ET AL.,J MOLEC BIOL 215]:403(1990);Guide to Huge Computers,MartinJ.Bishop,[ED.,]Academic Press,San Diego,1994,以及[CARILLO ETA/.](1988)SIAM JApplied Math 48:1073)。例如,同源性、相似性或相同性可以使用美国国家生物技术信息中心(NCBI)数据库的BLAST和ClustalW来确定。
多核苷酸或多肽的同源性、相似性或相同性可以通过使用例如GAP计算机程序比对序列信息来确定,例如在Smith and Waterman,Adv.Appl.Math(1981)2:482中公开的Needleman et al.(1970),J Mol Biol.48:443。简而言之,GAP程序将相似性定义为比对符号(即核苷酸或氨基酸)的数目除以两个序列中较短者的符号的数值。GAP程序的默认参数可以包括:(1)二进制比较矩阵(其包含的数值对于相同为1,对于不相同为0);以及在Schwartz and Dayhoff,eds.,Atlas of Protein Sequence and Structure,NationalBiomedical Research Foundation,pp.353-358,1979中描述(Gribskov et al.(1986),Nucl.Acids Res.14:6745)的加权比较矩阵;(2)每个空位罚分为3.0,对于每个符号的每个空位另加0.10罚分(或空位开放罚分10和空位扩展罚分0.5);和(3)末端空位不罚分。因此,如本文所用,术语“同源性”或“相同性”是指序列之间的相关性。
如本文所用,术语“载体”是指DNA构建体,包括编码目标变体蛋白的多核苷酸序列,其可操作地连接至合适的调控序列,以使目标变体蛋白在合适的宿主细胞中表达。所述调控序列可以包括能够启动转录的启动子、任何调节所述转录的操作序列、合适的mRNA核糖体结合域的序列以及调节转录和翻译的终止的序列。当表达载体转化到合适的宿主细胞后,他可以独立于宿主基因组进行复制或发挥功能,并可以整合到基因组中。
本发明使用的载体不受特别的限制,只要其可以在宿主细胞中进行复制,并且是本领域已知的任何载体。常用的载体的实例可以包括天然或重组质粒、粘粒、病毒和噬菌体。例如,pWE15、M13、MBL3、MBL4、IXII、ASHII、APII、t10、t11、Charon4A、Charon21A等可用作噬菌体载体或粘粒载体。pBR型、pUC型、pBluescriptII型、pGEM型、pTZ型、pCL型、pET型等可用作质粒载体。特别地,可以使用pDZ、pACYC177、pACYC184、pCL、pECCG117、pUC19、pBR322、pMW118、pCC1BAC等载体。
例如,使用插入细胞内染色体的载体,突变的多核苷酸可以替代染色体中编码目标变体蛋白的多核苷酸。多核苷酸插入染色体的方式可以通过本领域已知的任何方法进行,例如,同源重组,但不限于此。可进一步包括用于确认插入染色体的选择标记。所述选择标记用于选择转入了载体的细胞,即,确认目标核苷酸分子的插入,并且所述选择标记可包括提供可选择表型的标记,如耐药性、缺陷、对细胞毒剂的耐药性或表面修饰蛋白的表达。由于只有表达选择标记的细胞才能在经过选择剂处理的环境下存活或表现出不同的表型,因此可以选择出已转化的细胞。本发明的另一方面提供一种用于制备塔格糖的微生物,所述微生物包括变体蛋白或编码变体蛋白的多核苷酸。特别地,包括变体蛋白和/或编码变体蛋白的多核苷酸的微生物可以是通过转化载体制备的微生物,所述载体包括编码变体蛋白的多核苷酸,但不限于此。
如本文所用,术语“转化”是指将包含编码目标蛋白的多核苷酸的载体导入宿主细胞,使得由所述多核苷酸编码的蛋白在宿主细胞中得到表达。只要转化的多核苷酸能够在宿主细胞中表达,其可以插入并位于宿主细胞的染色体中,或位于染色体外,或者不论插入并位于宿主细胞的染色体内或位于染色体外。此外,所述多核苷酸包括DNA和编码目标蛋白的RNA。可以以任意的方式导入多核苷酸,只要能将其导入宿主细胞并在其中表达。例如,可以以表达盒的形式将多核苷酸导入宿主细胞,所述表达盒为包含自主表达所需的所有元件的基因构建体。通常,所述表达盒包含与多核苷酸可操作地连接的启动子、转录终止信号、核糖体结合域和翻译终止信号。表达盒可为能够自我复制的表达载体的形式。另外,可以将多核苷酸本身导入宿主细胞中,并与在宿主细胞中表达所需的序列可操作地连接,但不限于此。
如本文所用,术语“可操作地连接”是指启动子序列和多核苷酸序列之间的功能性连接,所述启动子序列起始和调节多核苷酸的转录,所述多核苷酸编码本发明的目标变体蛋白及多肽序列。
本发明的另一方面提供一种微生物,其包含果糖-4-差向异构酶变体、编码所述果糖-4-差向异构酶变体的多核苷酸、或包括所述多核苷酸的载体。
所述微生物可以是用于制备果糖-4-差向异构酶变体或塔格糖的微生物。
如本文所用,术语“包含果糖-4-差向异构酶变体的微生物”是指一种重组微生物,其表达本发明的果糖-4-差向异构酶变体。例如,所述微生物是指一种宿主细胞或一种微生物,其通过包含编码果糖-4-差向异构酶变体,或转化包含编码果糖-4-差向异构酶变体的多核苷酸的载体,表达所述变体。为实现本发明的目的,特别地,所述微生物是表达果糖-4-差向异构酶变体的微生物,其包含SEQ ID NO:1的氨基酸序列中的一个或多个氨基酸取代,并且所述微生物可以是表达具有果糖-4-差向异构酶活性的变体蛋白的微生物,其中,所述氨基酸取代是在N端的一个或多个位置的一个或多个氨基酸的取代,但不限于此。
本发明的果糖-4-差向异构酶变体可以通过以下方式获得:用表达本发明的酶或其变体的DNA转化微生物(例如大肠杆菌(E.coli)),培养所述微生物以获得培养物,破坏培养物,然后使用层析柱等进行纯化。除大肠杆菌(Escherichia coli)外,用于转化的微生物还可包括谷氨酸棒杆菌(Corynebacterium glutamicum)、米曲霉菌(Aspergillus oryzae)或枯草芽孢杆菌(Bacillus subtilis),但不限于此。
本发明的微生物可以包括原核或真核微生物,只要其是通过包含本发明的核酸或本发明的重组载体而产生本发明的果糖-4-差向异构酶的微生物即可。例如,所述微生物可以包含属于埃希氏菌(Escherichia)属、欧文氏菌(Erwinia)属、沙雷氏菌(Serratia)属、普罗威登斯菌(Providencia)属、棒状杆菌(Corynebacterium)属和短杆菌(Brevibacterium)属的微生物菌株,但不限于此。
除导入所述核酸或载体以外,本发明的微生物可以包括经由各种已知方法表达本发明的果糖-4-差向异构酶的任何微生物。
本发明的微生物的培养物可以通过在培养基中培养能够表达本发明的果糖-4-差向异构酶的微生物来制备。
在所述方法中,“培养”是指使所述微生物在适当调节的环境条件下生长。培养微生物的步骤可以但不特别限定于通过分批培养、连续培养或补料分批培养等进行。特别是,至于培养条件,可使用碱性化合物(例如,氢氧化钠、氢氧化钾或氨)或酸性化合物(例如,磷酸或硫酸)来将培养物的pH调节到合适的pH(例如,pH 5至9,特别地,pH 6至8,更特别地,pH6.8)。可以向培养物中注入氧气或含氧的气体混合物以保持培养物的有氧状态。培养温度可维持在20℃至45℃,特别地,可维持在25℃至40℃下约10小时至约160小时,但不限于此。
此外,作为用于培养基中的碳源,可以单独或组合使用糖和碳水化合物(例如,葡萄糖、蔗糖、乳糖、果糖、麦芽糖、糖蜜、淀粉和纤维素)、油脂和脂肪(例如,大豆油、葵花籽油、花生油和椰子油)、脂肪酸(例如,棕榈酸、硬脂酸和亚油酸)、醇(例如,甘油和乙醇)和有机酸(例如,乙酸)等,但不限于此。作为氮源,可以单独或组合使用含氮有机化合物(例如,蛋白胨、酵母提取物、肉汁、麦芽提取物、玉米浆、大豆粉和尿素)或无机化合物(例如,硫酸铵、氯化铵、磷酸铵、碳酸铵和硝酸铵),但不限于此。作为用于培养基中的磷源,可以单独或组合使用磷酸二氢钾、磷酸氢二钾、其相应的含钠盐等,但不限于此。此外,培养基中可以包含金属盐(例如,硫酸镁或硫酸铁)、氨基酸、维生素等必需的生长刺激物质。
本发明的另一方面提供一种用于制备塔格糖的组合物,其包含果糖-4-差向异构酶变体、表达所述果糖-4-差向异构酶变体的微生物或所述微生物的培养物。
本发明的用于制备塔格糖的组合物还包括果糖。
另外,本发明的用于制备塔格糖的组合物还可进一步包含在用于制备塔格糖的相应组合物中通常使用的任何合适的赋形剂。赋形剂可包括例如防腐剂、润湿剂、分散剂、悬浮剂、缓冲液、稳定剂、等渗剂等,但不限于此。
本发明的用于制备塔格糖的组合物还可以进一步包含金属离子或金属盐。在一个特定的实施方案中,金属离子或金属盐的金属可以是包含二价阳离子的金属。特别地,本发明的金属可以是镍(Ni)、铁(Fe)、钴(Co)、镁(Mg)或锰(Mn)。更特别地,所述金属盐可为MgSO
本发明的另一方面提供了一种制备塔格糖的方法,所述方法包括以下步骤:使果糖与果糖-4-差向异构酶变体、包含所述果糖-4-差向异构酶变体的微生物或所述微生物的培养物接触,将果糖转化为塔格糖,特别地,所述方法使用果糖-4-差向异构酶变体作为果糖4-差向异构酶,以由果糖制备塔格糖。
在一实施方案中,本发明的接触可以在pH 5.0至pH 9.0的pH,30℃至80℃的温度条件下进行,和/或进行0.5小时至48小时。
特别地,本发明的接触可以在pH 6.0至pH 9.0或pH 7.0至pH 9.0的pH条件下进行。此外,本发明的接触可以在35℃至80℃、40℃至80℃、45℃至80℃、50℃至80℃、55℃至80℃、60℃至80℃、30℃至70℃、35℃至70℃、40℃至70℃、45℃至70℃、50℃至70℃、55℃至70℃、60℃至70℃、30℃至65℃、35℃至65℃、40℃至65℃、45℃至65℃、50℃至65℃、55℃至65℃、30℃至60℃、35℃至60℃、40℃至60℃、45℃至60℃、50℃至60℃或55℃至60℃的温度条件下进行。此外,本发明的所述接触可以进行0.5小时至36小时、0.5小时至24小时、0.5小时至12小时、0.5小时至6小时、1小时至48小时、1小时至36小时、1小时至24小时、1小时至12小时、1小时至6小时、3小时至48小时、3小时至36小时、3小时至24小时、3小时至12小时、3小时至6小时、6小时至48小时、6小时至36小时、6小时至24小时、6小时至12小时、12小时至48小时、12小时至36小时、12小时至24小时、18小时至48小时、18小时至36小时或18小时至30小时。
此外,本发明的所述接触可以在金属离子或金属盐的存在下进行。应用的金属离子或金属盐如上所述。
本发明的制备方法还包括分离和/或纯化制备的塔格糖。分离和/或纯化可以通过本领域常用方法来进行。非限制性实例可以包括透析、沉淀、吸附、电泳、离子交换色谱和分级结晶等。纯化方法可仅通过一种方法进行,或者通过组合两种或更多的方法进行。
此外,本发明的制备方法还进一步包括在分离和/或纯化之前或者之后脱色和/或脱盐。通过进行脱色和/或脱盐,可以获得质量更高的塔格糖。
在又一实例中,本发明的制备方法还进一步包括将果糖转化为塔格糖、分离和/或纯化或者脱色和/或脱盐之后,对塔格糖进行结晶的步骤。结晶可通过常用的结晶方法进行。例如,可以通过冷却结晶来进行结晶。
此外,本发明的制备方法还进一步包括在结晶之前浓缩塔格糖的步骤。浓缩可以提高结晶效率。
在又一实例中,本发明的制备方法还进一步包括在分离和/或纯化之后,将未反应的果糖与本发明的酶、表达所述酶的微生物、所述微生物的培养物接触的步骤,或者,在本发明的结晶之后,在分离和/或纯化时重新使用已经从其中分离出晶体的母液,或其组合。所述额外的步骤在经济上有利,因为可以获得较高产量的塔格糖,并且可以减少果糖的丢弃量。
在下文中,将参考以下实施例更详细地描述本发明。然而,仅出于示例性目的给出这些实施例,并且本发明的范围不意图受这些实施例所限制。本发明所涉及的内容对于本领域技术人员来说是显而易见的。
实施例1:包含野生型果糖-4-差向异构酶基因或改进的果糖-4-差向异构酶基因的重组表达载体和转化体的制备
实施例1-1:包含野生型果糖-4-差向异构酶基因的重组表达载体和转化体的制备
为了制备果糖-4-差向异构酶,获得Kosmotoga olearia衍生的氨基酸序列(SEQID NO:1)和基因信息,以制备可在大肠杆菌(E.Coli)中表达的载体和转化的微生物(转化体)。已证实,所述序列可用作果糖-4-差向异构酶以将果糖转化为塔格糖(图1)。
特别地,从登记在京都基因和基因组百科全书(Kyoto Encyclopedia of Genesand Genomes,KEGG)的Kosmotoga olearia核苷酸序列中,选取果糖-4-差向异构酶的核苷酸序列。基于Kosmotoga olearia的氨基酸序列(SEQ ID NO:1)和核苷酸序列(SEQ ID NO:2)信息,将其插入到可以在大肠杆菌中表达的pBT7-C-His,以合成并制备重组表达载体pBT7-C-His-KO(由韩国Bioneer公司进行)。
实施例1-2:改进的果糖-4-差向异构酶库的制备和活性改进的变体的筛选
使用Kosmotoga olearia衍生的果糖-4-差向异构酶基因作为模板,进行随机突变,以构建果糖-4-差向异构酶变体库。具体地,使用多样化随机诱变试剂盒(ClonTech)诱发随机突变,以在果糖-4-差向异构酶基因中,每1000碱基对产生2至3个突变。PCR反应条件如下表1和表2所示。构建编码果糖-4-差向异构酶变体的基因库并将其插入到E.coli BL21(DE3)中。
表1
表2
pBT7-C-His质粒载有果糖-4-差向异构酶变体基因,将含有该质粒的大肠杆菌BL21(DE3)接种到含有0.2mL补充有氨苄青霉素抗生素的LB液体培养基的深孔支架中,然后在37℃的振荡培养箱中进行种培养16小时或更长时间。将通过种培养获得的培养液接种在含有液体培养基的深孔支架中,该液体培养基含有LB和作为蛋白表达调节因子的乳糖,然后进行主培养。种培养和主培养在180rpm的震荡速度和37℃的条件下进行。然后,将培养液在4000rpm和4℃下离心20分钟,随后以回收微生物并将其交付活性测试。
为了从制备好的随机突变库中快速筛选的大量活性改进的变体酶,使用能够特异性定量D-果糖的比色法。具体地,将70%的folin-ciocalteu试剂(sigma-aldrich)与底物反应溶液按照15:1的比例混合,在80℃下反应5分钟,测定900nm处的OD值,通过与野生型酶(SEQ ID NO:1)的相对活性进行比较,筛选出具有活性的变体(D-果糖转化为D-塔格糖)。其中,选出具有最高活性的30个克隆体,并通过测序验证它们的碱基序列。结果显示,位置33、80、97、102、124、137、210、239、318、367和390处出现变异。通过随机突变筛选,获得了具有最优活性的变体T124W和N97Y。
实施例2:变体酶的制备和其活性的比较评估
为了评估实施例1-2中获得的优异变体的相关果糖-4-差向异构化活性,将变体微生物接种到含有5mL补充有氨苄青霉素抗生素的LB液体培养基的培养管中,然后在37℃的振荡培养箱中进行种培养,直至600nm处的吸光度达到2.0。将通过种培养获得的培养液接种到含有液体培养基的培养瓶中,该液体培养基含有LB和作为蛋白表达调节因子的乳糖,然后进行主培养。种培养和主培养在180rpm的震荡速度和37℃的条件下进行。
然后,培养液在8000rpm和4℃下离心20分钟,随后回收微生物。回收的微生物用50mM Tris-HCl(pH 8.0)缓冲液洗涤两次,并重悬于含有10mM咪唑和300mM NaCl的50mMNaH
为了测量获得的纯化的酶的果糖-4-差向异构化活性,将50mM Tris-HCl(pH8.0)、3mM MnSO
实施例3:变体酶的制备和活性改进的变体酶的筛选
为了检测酶的活性,在实施例1-2设计的目标位置中,用苏氨酸以外的非极性或极性侧链取代位置124的苏氨酸(T),构建了单位饱和诱变库,其具有色氨酸(W)、半胱氨酸(C)或酪氨酸(Y)对位置124的苏氨酸(T)的取代,以制备变体酶,并测定了果糖-4-差向异构酶转化的单位活性。
实施例3-1:饱和诱变
制备重组表达载体pBT7-C-His-KO以在大肠杆菌BL21(DE3)中表达野生型的酶基因(表达在野生型的C端具有6XHis-tag的重组酶),该重组表达载体被用作构建变体库饱和诱变的模板。鉴于变异的突变频率和变体产量等,采用基于反转录聚合酶链反应(inversedPCR)的饱和诱变(2014.Anal.Biochem.449:90-98),并且为了最小化构建的变体库的筛选范围(最小化用于饱和诱变的密码子数量),设计并使用一种混合引物NDT/VMA/ATG/TGG(2012.Biotechniques 52:149-158),其中排除了终止密码子并最小化大肠杆菌的稀有密码子。具体地,构建一种总长为33bp的引物,前侧设置15bp、3bp被取代、每个部位后侧设置15bp。PCR重复进行30个循环,94℃下变性2分钟,94℃下变性30秒,60℃下退火30秒,和72℃下延伸10分钟,随后在72℃下延长60分钟。针对所选氨基酸位置构建饱和诱变库后,随机选择每个库中的变体(<11个变体)。分析碱基序列以评估氨基酸突变频率。根据分析的结果,设置好每个库的筛选范围,其中覆盖了90%或更多的序列(2003.Nucleic Acids Res.15;31:e30)。
实施例3-2:活性改进的变体酶的制备
为了评估变体酶的果糖-4-差向异构化相对活性,所述变体酶在单个位置具有改进的单位活性,和所述酶在多个位置改进的具有单位活性的组合,将3-1中制备的饱和诱变库的基因转入大肠杆菌BL21(DE3),并将每个转化的微生物接种到含有5mL含有氨苄青霉素抗生素的LB液体培养基的培养管中,然后在37℃的振荡培养箱中进行种培养,直至在600nm的吸光度达到2.0。将通过种培养获得的培养液接种在含有液体培养基的培养瓶中,该液体培养基含有LB和作为蛋白表达调节因子的乳糖,然后进行主培养。种培养和主培养在180rpm的震荡速度和37℃的条件下进行。然后,培养液在8000rpm和4℃下离心20分钟,随后回收微生物。回收的微生物用50mM Tris-HCl(pH 8.0)缓冲液洗涤两次,然后重悬于含有10mM咪唑和300mM NaCl的50mM NaH
实施例3-3:变体酶特征的比较评估
为了测量实施例3-2中获得的重组变体酶的果糖-4-差向异构化活性,将50mMTris-HCl(pH 8.0)、3mM MnSO
结果显示,制备的所有变体显示出野生型变体的至多2.9倍的转化率。详细的结果如表3所示。此外,热稳定性的检测结果显示60℃下果糖-4-差向异构酶变体的残留活性随着时间推移而降低,但其热稳定性比野生型更好,如图2所示。
表3
实施例4:重组变体酶的制备和活性改良的变体酶的评估
实施例4-1:定点诱变
使用特定的引物进行定点诱变,实施例1-2中选出的变体T124W用于对Kosmotogaolearia衍生的果糖-4-差向异构酶的位置97的天冬酰胺进行酪氨酸的取代。
N端引物(SEQ ID NO:25:GACCATCTTGGCCCATACCCCTGGAAGGGTCAG)和C端引物(SEQID NO:26:CTGACCCTTCCAGGGGTATGGGCCAAGATGGTC),这两个具有突变的互补碱基序列的寡核苷酸用作引物。以质粒形式的DNA为模板,用限制性酶DpnI消化最初的模板DNA,并移除,在试管内扩增并合成具有新变异的质粒。也就是说,被用作模板的实施例1-2中选出的变体DNA,是从大肠杆菌中分离出的DNA,其被可以识别和切割Gm6 ATC的Dpn I的消化,但是在试管中合成的变体DNA并没有因此被切开。其被转化至大肠杆菌DH5alpha以获得变体菌株。进行变体基因的序列分析,以确认发生了合适的变异。也就是说,制备了具有氨基酸序列变异的T124W N97Y变体。转化该变体至表达菌株大肠杆菌BL21(DE3)以制备重组菌株。
实施例4-2:活性改进的变体酶的制备和活性的比较评估
将实施例4-1中制备的变体微生物接种到含有5mL含有氨苄青霉素抗生素的LB液体培养基的培养管中,然后在37℃的振荡培养箱中进行种培养,直至在600nm的吸光度达到2.0。将通过种培养获得的培养液接种在含有液体培养基的培养瓶中,该液体培养基含有LB和作为蛋白表达调节因子的乳糖,然后进行主培养。种培养和主培养在180rpm的震荡速率和37℃的条件下进行。然后,将培养液在8000rpm和4℃下离心20分钟,随后回收微生物。回收的微生物用50mM Tris-HCl(pH 8.0)缓冲液洗涤两次,然后重悬于含有10mM咪唑和300mMNaCl的50mM NaH
用超声仪破坏重悬的微生物,并在13000rpm和4℃下离心20分钟,仅获取上清液。通过His-tag亲和色谱法纯化上清液,并应用10倍填料体积的含有20mM咪唑和300mM NaCl的50mM NaH
为了测量所得的重组变体酶的果糖-4-差向异构化活性,将50mM Tris-HCl(pH8.0)、3mM MnSO
结果显示,制备的所有变体显示出野生型变体的至多4倍的高转化率。详细的结果如表4所示。
表4
实施例4-3:其他重组变体酶的制备和筛选
当加入的是基于位置124变异的各种变异时,为了检测酶的活性,进行如下新增实验。具体地,基于实施例1-2中通过随机突变库筛选的9个活性位置(位置33、80、102、137、210、239、318、367和390),实施例1-2中制备的124W变体和实施例4-1中制备的T124W N97Y变体(分别是,色氨酸(W)取代了位置124的苏氨酸(T),酪氨酸(Y)取代了位置97的天冬酰胺(N))用于构建单点饱和诱变库。通过筛选而选取具有改进的单位活性的变异位置和氨基酸。获得的伴随有其他变异位置的63种变体酶如表5所示。每个位置的变异类型如表6所示。
表5
表6
实施例5:变体酶特征的比较评估
实施例5-1:活性评估
为了测量实施例5中获得的重组变体酶的果糖-4-差向异构化活性,将50mM Tris-HCl(pH 8.0)、3mM MnSO
结果显示,与野生型的转化活性(KO)相比,所有变体显示出增强的果糖-4-差向异构化活性。详细的结果如表7至表9所示。
表7
表8
表9
这些结果表明,与野生型相比,本发明的变体具有增强的果糖-4-差向异构化活性。
实施例5-2:根据变异的数量进行活性的比较评估
为了测量实施例5-1中获得的重组变体酶的果糖-4-差向异构化活性,并由其结果根据变异的数量比较转化率的提高,将50mM Tris-HCl(pH 8.0)、3mM MnSO4和各2mg/mL的酶添加至30重量%的果糖中,并使混合物在50℃或60℃下反应2小时。
结果显示,与野生型相比,本发明的所有变体具有增强的果糖-4-差向异构化活性(图3)。
实施例5-3:热稳定性的比较评估
为了测量获得的重组变体酶的热稳定性,加入各5mg/mL的经纯化的酶,在60℃下放置至少19个小时和至多90个小时,然后在冰上放置5分钟。将每个时间点采样的酶溶液、50mM Tris-HCL(pH 8.0)和3mM MnSO
检测热稳定性的结果显示,60℃下果糖-4-差向异构酶变体的残留活性随着时间推移而降低,但其热稳定性比野生型的更好,如图4所示。
本发明人转化至大肠杆菌BL21(De3)来制备的转化体(转化微生物),其分别命名为大肠杆菌BL21(DE3)/CJ_KO_F4E_M3(T124W)、大肠杆菌BL21(DE3)/CJ_KO_F4E_M8(T124W+N97Y),并于2018年9月19日,按照《布达佩斯条约》,将这些转化体分别以保藏号KCCM12322P(大肠杆菌BL21(DE3)/CJ_KO_F4E_M3)、KCCM12327P(大肠杆菌BL21(DE3)/CJ_KO_F4E_M8)保藏于国际保藏单位韩国微生物保藏中心(KCCM)。
根据本以上描述,本领域技术人员将理解,在不脱离本发明的精神或重要特征的情况下,本发明可以以其他特定形式来体现。因此,应当认为所描述的实施方案在所有方面都仅仅是示例性的而非限制性的。本发明的范围由所附的权利要求而非前文的描述指明。落入权利要求的等同物的含义和范围内的所有变化都将包含在本发明的范围内。
<110> CJ第一制糖株式会社
<120> 新型果糖-4-差向异构酶以及使用其制备塔格糖的方法
<130> OPA19113
<150> KR 10-2018-0116609
<151> 2018-09-28
<150> KR 10-2018-0117237
<151> 2018-10-01
<150> KR 10-2019-0099826
<151> 2019-08-14
<160> 26
<170> KoPatentIn 3.0
<210> 1
<211> 435
<212> PRT
<213> Unknown
<220>
<223> Kosmotoga olearia
<220>
<221> 多肽
<222> (1)..(435)
<223> 塔格糖-二磷酸醛缩酶
<400> 1
Met Lys Lys His Pro Leu Gln Asp Ile Val Ser Leu Gln Lys Gln Gly
1 5 10 15
Ile Pro Lys Gly Val Phe Ser Val Cys Ser Ala Asn Arg Phe Val Ile
20 25 30
Glu Thr Thr Leu Glu Tyr Ala Lys Met Lys Gly Thr Thr Val Leu Ile
35 40 45
Glu Ala Thr Cys Asn Gln Val Asn Gln Phe Gly Gly Tyr Thr Gly Met
50 55 60
Thr Pro Ala Asp Phe Arg Glu Met Val Phe Ser Ile Ala Glu Asp Ile
65 70 75 80
Gly Leu Pro Lys Asn Lys Ile Ile Leu Gly Gly Asp His Leu Gly Pro
85 90 95
Asn Pro Trp Lys Gly Gln Pro Ser Asp Gln Ala Met Arg Asn Ala Ile
100 105 110
Glu Met Ile Arg Glu Tyr Ala Lys Ala Gly Phe Thr Lys Leu His Leu
115 120 125
Asp Ala Ser Met Arg Leu Ala Asp Asp Pro Gly Asn Glu Asn Glu Pro
130 135 140
Leu Asn Pro Glu Val Ile Ala Glu Arg Thr Ala Leu Leu Cys Leu Glu
145 150 155 160
Ala Glu Arg Ala Phe Lys Glu Ser Ala Gly Ser Leu Arg Pro Val Tyr
165 170 175
Val Ile Gly Thr Asp Val Pro Pro Pro Gly Gly Ala Gln Asn Glu Gly
180 185 190
Lys Ser Ile His Val Thr Ser Val Gln Asp Phe Glu Arg Thr Val Glu
195 200 205
Leu Thr Lys Lys Ala Phe Phe Asp His Gly Leu Tyr Glu Ala Trp Gly
210 215 220
Arg Val Ile Ala Val Val Val Gln Pro Gly Val Glu Phe Gly Asn Glu
225 230 235 240
His Ile Phe Glu Tyr Asp Arg Asn Arg Ala Arg Glu Leu Thr Glu Ala
245 250 255
Ile Lys Lys His Pro Asn Ile Val Phe Glu Gly His Ser Thr Asp Tyr
260 265 270
Gln Thr Ala Lys Ala Leu Lys Glu Met Val Glu Asp Gly Val Ala Ile
275 280 285
Leu Lys Val Gly Pro Ala Leu Thr Phe Ala Leu Arg Glu Ala Phe Phe
290 295 300
Ala Leu Ser Ser Ile Glu Lys Glu Leu Phe Tyr Asp Thr Pro Gly Leu
305 310 315 320
Cys Ser Asn Phe Val Glu Val Val Glu Arg Ala Met Leu Asp Asn Pro
325 330 335
Lys His Trp Glu Lys Tyr Tyr Gln Gly Glu Glu Arg Glu Asn Arg Leu
340 345 350
Ala Arg Lys Tyr Ser Phe Leu Asp Arg Leu Arg Tyr Tyr Trp Asn Leu
355 360 365
Pro Glu Val Arg Thr Ala Val Asn Lys Leu Ile Thr Asn Leu Glu Thr
370 375 380
Lys Glu Ile Pro Leu Thr Leu Ile Ser Gln Phe Met Pro Met Gln Tyr
385 390 395 400
Gln Lys Ile Arg Asn Gly Leu Leu Arg Lys Asp Pro Ile Ser Leu Ile
405 410 415
Lys Asp Arg Ile Thr Leu Val Leu Asp Asp Tyr Tyr Phe Ala Thr His
420 425 430
Pro Glu Cys
435
<210> 2
<211> 1308
<212> DNA
<213> Unknown
<220>
<223> Kosmotoga olearia
<220>
<221> 基因
<222> (1)..(1308)
<223> 塔格糖-二磷酸醛缩酶
<400> 2
atgaaaaaac atcctcttca ggacattgtt tcattgcaaa aacagggaat acccaaaggg 60
gttttctctg tatgtagtgc caatagattt gttattgaaa ccactctgga atatgcgaag 120
atgaaaggga caacggttct tatagaggcc acctgcaatc aggtaaacca gttcggtggc 180
tacaccggta tgactcctgc tgatttcaga gaaatggttt tttctatcgc tgaggatatt 240
ggacttccca aaaataaaat catccttggt ggcgaccatc ttggcccaaa tccctggaag 300
ggtcagccgt cagatcaggc tatgcgtaac gccattgaaa tgattcgaga atacgctaaa 360
gctgggttta ccaagcttca tctggatgcc agcatgcgtc ttgcagacga tccggggaac 420
gaaaacgagc cgctgaaccc ggaagttata gcggaaagaa cagctcttct ctgtcttgaa 480
gccgagaggg cttttaaaga atccgccggt tctctccggc ctgtttacgt tattggtacg 540
gatgttccgc caccgggtgg agcgcaaaac gaaggtaaat cgattcatgt aaccagtgtt 600
caggattttg agcgtaccgt tgagttgacc aaaaaggcat ttttcgacca tggtttgtat 660
gaagcctggg gaagggtgat tgcggttgtt gtgcaaccgg gagtagaatt cgggaatgaa 720
catatattcg aatatgatag aaatcgagcg agagaactta ctgaggcgat aaaaaagcat 780
ccaaatatag tttttgaagg tcactcgaca gattatcaaa cggcaaaagc attgaaagaa 840
atggtagaag acggtgtagc catactcaag gttgggccag ctctaacatt tgcgctcaga 900
gaggcttttt ttgcgttgag cagcattgaa aaagagttat tttatgatac acccgggctt 960
tgttcaaact ttgttgaagt tgtcgagaga gcgatgcttg acaatccaaa acattgggaa 1020
aaatattacc agggagaaga gagagaaaat agattagccc gtaaatacag ctttctcgat 1080
cgcttgaggt attactggaa tcttcctgag gttagaacag cggtgaataa gctgataacc 1140
aaccttgaaa caaaagaaat cccgttaacg cttataagcc agttcatgcc gatgcagtac 1200
caaaaaatca gaaacggttt gctaagaaag gatccaataa gccttataaa agatcgaatt 1260
acccttgttc ttgatgacta ctatttcgca actcaccctg aatgttga 1308
<210> 3
<211> 434
<212> PRT
<213> Unknown
<220>
<223> 解热嗜热厌氧杆菌(Thermoanaerobacterium thermosaccharolyticum)
<220>
<221> 多肽
<222> (1)..(434)
<223> 塔格糖-二磷酸醛缩酶
<400> 3
Met Ala Lys Glu His Pro Leu Lys Glu Leu Val Asn Lys Gln Lys Ser
1 5 10 15
Gly Ile Ser Glu Gly Ile Val Ser Ile Cys Ser Ser Asn Glu Phe Val
20 25 30
Ile Glu Ala Ser Met Glu Arg Ala Leu Thr Asn Gly Asp Tyr Val Leu
35 40 45
Ile Glu Ser Thr Ala Asn Gln Val Asn Gln Tyr Gly Gly Tyr Ile Gly
50 55 60
Met Thr Pro Ile Glu Phe Lys Lys Phe Val Phe Ser Ile Ala Lys Lys
65 70 75 80
Val Asp Phe Pro Leu Asp Lys Leu Ile Leu Gly Gly Asp His Leu Gly
85 90 95
Pro Leu Ile Trp Lys Asn Glu Ser Ser Asn Leu Ala Leu Ala Lys Ala
100 105 110
Ser Glu Leu Ile Lys Glu Tyr Val Leu Ala Gly Tyr Thr Lys Ile His
115 120 125
Ile Asp Thr Ser Met Arg Leu Lys Asp Asp Thr Asp Phe Asn Thr Glu
130 135 140
Ile Ile Ala Gln Arg Ser Ala Val Leu Leu Lys Ala Ala Glu Asn Ala
145 150 155 160
Tyr Met Glu Leu Asn Lys Asn Asn Lys Asn Val Leu His Pro Val Tyr
165 170 175
Val Ile Gly Ser Glu Val Pro Ile Pro Gly Gly Ser Gln Gly Ser Asp
180 185 190
Glu Ser Leu Gln Ile Thr Asp Ala Lys Asp Phe Glu Asn Thr Val Glu
195 200 205
Ile Phe Lys Asp Val Phe Ser Lys Tyr Gly Leu Ile Asn Glu Trp Glu
210 215 220
Asn Ile Val Ala Phe Val Val Gln Pro Gly Val Glu Phe Gly Asn Asp
225 230 235 240
Phe Val His Glu Tyr Lys Arg Asp Glu Ala Lys Glu Leu Thr Asp Ala
245 250 255
Leu Lys Asn Tyr Lys Thr Phe Val Phe Glu Gly His Ser Thr Asp Tyr
260 265 270
Gln Thr Arg Glu Ser Leu Lys Gln Met Val Glu Asp Gly Ile Ala Ile
275 280 285
Leu Lys Val Gly Pro Ala Leu Thr Phe Ala Leu Arg Glu Ala Leu Ile
290 295 300
Ala Leu Asn Asn Ile Glu Asn Glu Leu Leu Asn Asn Val Asp Ser Ile
305 310 315 320
Lys Leu Ser Asn Phe Thr Asn Val Leu Val Ser Glu Met Ile Asn Asn
325 330 335
Pro Glu His Trp Lys Asn His Tyr Phe Gly Asp Asp Ala Arg Lys Lys
340 345 350
Phe Leu Cys Lys Tyr Ser Tyr Ser Asp Arg Cys Arg Tyr Tyr Leu Pro
355 360 365
Thr Arg Asn Val Lys Asn Ser Leu Asn Leu Leu Ile Arg Asn Leu Glu
370 375 380
Asn Val Lys Ile Pro Met Thr Leu Ile Ser Gln Phe Met Pro Leu Gln
385 390 395 400
Tyr Asp Asn Ile Arg Arg Gly Leu Ile Lys Asn Glu Pro Ile Ser Leu
405 410 415
Ile Lys Asn Ala Ile Met Asn Arg Leu Asn Asp Tyr Tyr Tyr Ala Ile
420 425 430
Lys Pro
<210> 4
<211> 1305
<212> DNA
<213> Unknown
<220>
<223> 解热嗜热厌氧杆菌(Thermoanaerobacterium thermosaccharolyticum)
<220>
<221> 基因
<222> (1)..(1305)
<223> 塔格糖-二磷酸醛缩酶
<400> 4
atggctaaag aacatccatt aaaggaatta gtaaataaac aaaaaagtgg tatatccgag 60
ggtatagttt ctatttgtag ttcaaatgaa tttgttattg aagcatctat ggagcgtgca 120
ttaacaaatg gtgattatgt tttaattgaa tcaacagcaa atcaggtgaa tcaatatggt 180
ggatatattg gtatgacacc tattgagttt aaaaaatttg tattttcaat agctaaaaaa 240
gtagattttc cattagataa attgattctt ggtggggatc atttaggccc attaatatgg 300
aaaaatgaat ctagtaattt ggcgttagca aaagcatccg agcttattaa agaatatgta 360
ttagccggat atactaaaat tcatatagac actagtatgc ggctaaaaga tgatactgat 420
tttaatacag aaattattgc tcaaagaagt gcagtattgt taaaggcagc ggaaaatgca 480
tatatggaat tgaataaaaa taataaaaat gttttacatc ctgtctatgt tataggaagt 540
gaagtcccaa tacctggggg cagccaaggc agtgatgaat cgctccaaat tactgatgct 600
aaggattttg aaaatacagt tgaaatattt aaagatgttt tttcaaaata tggattaatt 660
aatgagtggg aaaacatagt agcatttgtt gttcaaccag gagttgagtt tggaaatgat 720
tttgtacatg aatataaacg tgatgaagca aaagaattaa cagatgcact taaaaattat 780
aaaacatttg tttttgaagg acattctact gattatcaaa cacgtgaatc attaaaacaa 840
atggtggaag atggcattgc aattttaaaa gttggacctg cattaacatt tgcactacgt 900
gaagccttaa tagcactaaa taatatagaa aatgagttgc ttaataatgt agatagtata 960
aaattatcaa attttactaa tgtactcgta agtgaaatga tcaataaccc cgaacattgg 1020
aaaaatcatt attttggtga tgatgcaagg aaaaagtttc tatgtaaata tagttattcg 1080
gatagatgta ggtactattt accaactaga aatgtaaaaa actcattaaa tcttcttatt 1140
agaaatctag aaaatgtgaa aataccaatg acattaataa gtcaatttat gcctttgcaa 1200
tatgataata ttagaagagg actcataaaa aatgaaccaa tttctttaat taaaaatgca 1260
ataatgaacc gacttaatga ctattattat gctataaagc cgtaa 1305
<210> 5
<211> 434
<212> PRT
<213> Unknown
<220>
<223> 假单胞菌H103(Pseudoalteromonas sp. H103)
<220>
<221> 多肽
<222> (1)..(434)
<223> 塔格糖-二磷酸醛缩酶
<400> 5
Met Arg Gly Asp Lys Arg Val Thr Thr Asp Phe Leu Lys Glu Ile Val
1 5 10 15
Gln Gln Asn Arg Ala Gly Gly Ser Arg Gly Ile Tyr Ser Val Cys Ser
20 25 30
Ala His Arg Leu Val Ile Glu Ala Ser Met Gln Gln Ala Lys Ser Asp
35 40 45
Gly Ser Pro Leu Leu Val Glu Ala Thr Cys Asn Gln Val Asn His Glu
50 55 60
Gly Gly Tyr Thr Gly Met Thr Pro Ser Asp Phe Cys Lys Tyr Val Leu
65 70 75 80
Asp Ile Ala Lys Glu Val Gly Phe Ser Gln Glu Gln Leu Ile Leu Gly
85 90 95
Gly Asp His Leu Gly Pro Asn Pro Trp Thr Asp Leu Pro Ala Ala Gln
100 105 110
Ala Met Glu Ala Ala Lys Lys Met Val Ala Asp Tyr Val Ser Ala Gly
115 120 125
Phe Ser Lys Ile His Leu Asp Ala Ser Met Ala Cys Ala Asp Asp Val
130 135 140
Glu Pro Leu Ala Asp Glu Val Ile Ala Gln Arg Ala Thr Ile Leu Cys
145 150 155 160
Ala Ala Gly Glu Ala Ala Val Ser Asp Lys Asn Ala Ala Pro Met Tyr
165 170 175
Ile Ile Gly Thr Glu Val Pro Val Pro Gly Gly Ala Gln Glu Asp Leu
180 185 190
His Glu Leu Ala Thr Thr Asn Ile Asp Asp Leu Lys Gln Thr Ile Lys
195 200 205
Thr His Lys Ala Lys Phe Ser Glu Asn Gly Leu Gln Asp Ala Trp Asp
210 215 220
Arg Val Ile Gly Val Val Val Gln Pro Gly Val Glu Phe Asp His Ala
225 230 235 240
Met Val Ile Gly Tyr Gln Ser Glu Lys Ala Gln Thr Leu Ser Lys Thr
245 250 255
Ile Leu Asp Phe Asp Asn Leu Val Tyr Glu Ala His Ser Thr Asp Tyr
260 265 270
Gln Thr Glu Thr Ala Leu Thr Asn Leu Val Asn Asp His Phe Ala Ile
275 280 285
Leu Lys Val Gly Pro Gly Leu Thr Tyr Ala Ala Arg Glu Ala Leu Phe
290 295 300
Ala Leu Ser Tyr Ile Glu Gln Glu Trp Ile Thr Asn Lys Pro Leu Ser
305 310 315 320
Asn Leu Arg Gln Val Leu Glu Glu Arg Met Leu Glu Asn Pro Lys Asn
325 330 335
Trp Ala Lys Tyr Tyr Thr Gly Thr Glu Gln Glu Gln Ala Phe Ala Arg
340 345 350
Lys Tyr Ser Phe Ser Asp Arg Ser Arg Tyr Tyr Trp Ala Asp Pro Ile
355 360 365
Val Asp Gln Ser Val Gln Thr Leu Ile Asn Asn Leu Thr Glu Gln Pro
370 375 380
Ala Pro Met Thr Leu Leu Ser Gln Phe Met Pro Leu Gln Tyr Ala Ala
385 390 395 400
Phe Arg Ala Gly Gln Leu Asn Asn Asp Pro Leu Ser Leu Ile Arg His
405 410 415
Trp Ile Gln Glu Val Val Ser Thr Tyr Ala Arg Ala Ser Gly Leu Ala
420 425 430
Val Lys
<210> 6
<211> 1305
<212> DNA
<213> Unknown
<220>
<223> 假单胞菌H103(Pseudoalteromonas sp. H103)
<220>
<221> 基因
<222> (1)..(1305)
<223> 塔格糖-二磷酸醛缩酶
<400> 6
atcagaggag ataaaagggt gactacagat tttctgaaag aaattgttca acaaaacaga 60
gccggtggta gcagaggtat ttactctgtt tgttctgcgc atcgccttgt tattgaagcg 120
tctatgcagc aagccaaaag cgatggctca ccactgttag tagaggcaac atgtaatcag 180
gttaatcacg aaggtggtta taccggtatg accccaagcg acttttgcaa atacgtgtta 240
gatattgcaa aagaagtggg cttttcccaa gagcaactta ttttaggggg cgaccactta 300
gggcctaacc cgtggactga cctaccagct gcacaggcaa tggaagcggc caaaaaaatg 360
gttgctgatt acgtaagtgc gggcttttca aaaatacatt tagatgcaag catggcatgt 420
gcagatgatg tagagccgct tgctgatgag gttatagcgc agcgcgccac tattttatgt 480
gctgccggcg aagctgctgt tagcgataaa aatgcagccc caatgtatat tattggtacc 540
gaagtgccgg taccaggtgg cgcacaagaa gatttacacg aacttgctac aaccaatatt 600
gatgatttaa aacaaaccat taaaacccat aaagcaaaat ttagcgaaaa cggtttgcaa 660
gacgcatggg atagagtaat tggtgtagta gtgcagcctg gtgttgagtt tgaccacgcg 720
atggtaattg gctatcaaag cgaaaaagca caaacactaa gtaaaactat tttagatttt 780
gataatttgg tttatgaagc gcattcaacc gattatcaaa ccgaaacagc gttaactaac 840
ttggttaacg accactttgc tattttaaaa gtgggcccag ggcttactta tgcagcgcgc 900
gaagcgttgt ttgcacttag ttatattgag caagagtgga taaccaataa gcctctttct 960
aatttgcgcc aagtgcttga agagcgcatg ctcgaaaacc ctaaaaactg ggctaagtat 1020
tacacaggta cagagcaaga gcaggccttt gcacgaaaat atagctttag cgatagatcg 1080
cgttactatt gggccgatcc tattgttgat caaagtgttc aaacactcat taataactta 1140
actgagcagc cagcgccaat gaccttgctg agtcaattta tgccacttca atatgcggca 1200
tttcgtgcag gacaattaaa taacgatccg ctttctttga tcagacactg gatccaagaa 1260
gttgtatcaa cctacgcccg cgctagcgga cttgcagtaa aatag 1305
<210> 7
<211> 426
<212> PRT
<213> Unknown
<220>
<223> Thermanaerothrix daxensis
<220>
<221> 多肽
<222> (1)..(426)
<223> 塔格糖-二磷酸醛缩酶
<400> 7
Met Val Thr Tyr Leu Asp Phe Val Val Leu Ser His Arg Phe Arg Arg
1 5 10 15
Pro Leu Gly Ile Thr Ser Val Cys Ser Ala His Pro Tyr Val Ile Glu
20 25 30
Ala Ala Leu Arg Asn Gly Met Met Thr His Thr Pro Val Leu Ile Glu
35 40 45
Ala Thr Cys Asn Gln Val Asn Gln Tyr Gly Gly Tyr Thr Gly Met Thr
50 55 60
Pro Ala Asp Phe Val Arg Tyr Val Glu Asn Ile Ala Ala Arg Val Gly
65 70 75 80
Ser Pro Arg Glu Asn Leu Leu Leu Gly Gly Asp His Leu Gly Pro Leu
85 90 95
Val Trp Ala His Glu Pro Ala Glu Ser Ala Met Glu Lys Ala Arg Ala
100 105 110
Leu Val Lys Ala Tyr Val Glu Ala Gly Phe Arg Lys Ile His Leu Asp
115 120 125
Cys Ser Met Pro Cys Ala Asp Asp Arg Asp Phe Ser Pro Lys Val Ile
130 135 140
Ala Glu Arg Ala Ala Glu Leu Ala Gln Val Ala Glu Ser Thr Cys Asp
145 150 155 160
Val Met Gly Leu Pro Leu Pro Asn Tyr Val Ile Gly Thr Glu Val Pro
165 170 175
Pro Ala Gly Gly Ala Lys Ala Glu Ala Glu Thr Leu Arg Val Thr Arg
180 185 190
Pro Glu Asp Ala Ala Glu Thr Ile Ala Leu Thr Arg Ala Ala Phe Phe
195 200 205
Lys Arg Gly Leu Glu Ser Ala Trp Glu Arg Val Val Ala Leu Val Val
210 215 220
Gln Pro Gly Val Glu Phe Gly Asp His Gln Ile His Val Tyr Arg Arg
225 230 235 240
Glu Glu Ala Gln Ala Leu Ser Arg Phe Ile Glu Ser Gln Pro Gly Leu
245 250 255
Val Tyr Glu Ala His Ser Thr Asp Tyr Gln Pro Arg Asp Ala Leu Arg
260 265 270
Ala Leu Val Glu Asp His Phe Ala Ile Leu Lys Val Gly Pro Ala Leu
275 280 285
Thr Phe Ala Phe Arg Glu Ala Val Phe Ala Leu Ala Ser Ile Glu Asp
290 295 300
Trp Val Cys Asp Ser Pro Ser Arg Ile Leu Glu Val Leu Glu Thr Thr
305 310 315 320
Met Leu Ala Asn Pro Val Tyr Trp Gln Lys Tyr Tyr Leu Gly Asp Glu
325 330 335
Arg Ala Arg Arg Ile Ala Arg Gly Tyr Ser Phe Ser Asp Arg Ile Arg
340 345 350
Tyr Tyr Trp Ser Ala Pro Ala Val Glu Gln Ala Phe Glu Arg Leu Arg
355 360 365
Ala Asn Leu Asn Arg Val Ser Ile Pro Leu Val Leu Leu Ser Gln Tyr
370 375 380
Leu Pro Asp Gln Tyr Arg Lys Val Arg Asp Gly Arg Leu Pro Asn Gln
385 390 395 400
Phe Asp Ala Leu Ile Leu Asp Lys Ile Gln Ala Val Leu Glu Asp Tyr
405 410 415
Asn Val Ala Cys Gly Val Arg Ile Gly Glu
420 425
<210> 8
<211> 1281
<212> DNA
<213> Unknown
<220>
<223> Thermanaerothrix daxensis
<220>
<221> 基因
<222> (1)..(1281)
<223> 塔格糖-二磷酸醛缩酶
<400> 8
atggttacct atttggattt tgtggtgctt tctcatcgtt ttaggcgccc cctgggcatt 60
acctcagtgt gttcggcgca tccgtatgtc attgaggcgg cgctgcgtaa tgggatgatg 120
acccatacac cggtcctaat cgaggccact tgcaatcaag tcaatcagta tgggggatat 180
acggggatga ccccggcaga tttcgtgcgg tatgtggaga atattgctgc acgggtaggc 240
tctccacgtg aaaacctcct tttgggtggc gatcatttgg gacccctggt ctgggctcat 300
gaacctgctg agagtgccat ggaaaaagct cgagctctgg tcaaagccta tgtagaggct 360
ggttttcgca aaattcatct ggattgctca atgccctgtg cggatgatcg cgatttttct 420
ccaaaggtca ttgctgagcg ggcagccgaa ttggctcagg tggcagagtc aacttgtgat 480
gttatgggct tgcccttgcc caactacgtc attggaaccg aggtgccccc agcaggtggc 540
gccaaggctg aagccgaaac tttgagggta acccgtccgg aggatgcagc ggagaccatt 600
gcactgacca gagcggcttt tttcaagcga ggtttagagt ctgcctggga acgtgtagtg 660
gcgttagtag tgcaacccgg tgttgaattc ggagatcatc agattcatgt ttaccgccgt 720
gaggaagcgc aggctctttc ccgcttcatt gaaagccagc ccggcttagt ctatgaggct 780
cactccaccg actatcagcc ccgtgatgcg ctgcgggctt tggttgagga tcatttcgca 840
atcctgaagg tgggtccggc gctaaccttt gcttttcgtg aggcagtttt tgccctggcc 900
agtatcgagg attgggtatg cgattcaccc agtcgcatcc tggaagtttt ggaaacaacc 960
atgctggcca acccggtcta ctggcaaaag tattacttgg gcgatgagcg agcgcgtcgg 1020
attgccagag ggtatagttt cagcgatcgc attcgttatt attggagtgc accagcggtt 1080
gaacaggcct ttgaacgctt gcgggcaaat ctgaatcgtg tttcgatccc ccttgtcctt 1140
ctcagtcagt atttgccgga tcaatatcgc aaagtgcggg atggacggct gcctaaccag 1200
tttgatgctt tgattctgga taaaatccaa gccgtactgg aagactacaa tgtggcgtgt 1260
ggtgtgagga taggggagtg a 1281
<210> 9
<211> 431
<212> PRT
<213> Unknown
<220>
<223> 酸杆菌细菌(Acidobacteriales bacterium)
<220>
<221> 多肽
<222> (1)..(431)
<223> 塔格糖-二磷酸醛缩酶
<400> 9
Met Ser Asp Asn Leu Gln Val Phe Leu Arg Glu Ser Arg Gly Arg Arg
1 5 10 15
Gly Ile Tyr Ser Val Cys Ser Ala His Pro Arg Val Ile Glu Ala Ala
20 25 30
Met Arg Gln Ala Gly Ala Asp Gly Thr His Leu Leu Leu Glu Ala Thr
35 40 45
Ser Asn Gln Val Asn Gln Ala Gly Gly Tyr Thr Gly Met Thr Pro Ala
50 55 60
Met Phe Arg Asp Tyr Val Tyr Asp Ile Ala Gln Glu Ile Gly Phe Asp
65 70 75 80
Arg Ser Arg Leu Ile Leu Gly Gly Asp His Leu Gly Pro Asn Pro Trp
85 90 95
Gln Gln Leu Asp Ala Ser Thr Ala Met Gln Tyr Ala Glu Glu Met Val
100 105 110
Arg Leu Tyr Ile Glu Ala Gly Phe Thr Lys Ile His Leu Asp Ala Ser
115 120 125
Met Arg Cys Ala Asp Asp Ala Ala Ile Val Pro Asp Glu Val Met Ala
130 135 140
Gly Arg Ala Ala Ala Leu Cys Ser Ala Ala Glu Ser Ala Arg Ala Arg
145 150 155 160
Leu Gly Leu Ala Pro Val Val Tyr Val Ile Gly Thr Glu Val Pro Thr
165 170 175
Pro Gly Gly Ala Ser His Ala Leu Asn Thr Leu Glu Val Thr Thr Arg
180 185 190
Glu Ala Val Glu His Thr Leu Ser Val His Arg Lys Ala Phe His Asp
195 200 205
Ala Gly Leu Asp Ala Ala Trp Gln Arg Val Ile Ala Val Val Val Gln
210 215 220
Pro Gly Val Glu Phe Asp His Asp Ser Val Val Asp Tyr Asp Ala Ala
225 230 235 240
Lys Ala Gly His Leu Gln Glu Phe Leu Gln Ala His Pro Glu Leu Val
245 250 255
Met Glu Ala His Ser Ser Asp Tyr Gln Lys Pro Gln Ala Tyr Lys Glu
260 265 270
Leu Val Arg Asp Gly Phe Ala Ile Leu Lys Val Gly Pro Ala Leu Thr
275 280 285
Phe Ala Leu Arg Glu Met Leu Tyr Ala Leu Ala Ala Ile Glu Arg Glu
290 295 300
Leu Val Pro Glu Ala Glu Gln Ser His Leu Val Glu Thr Met Glu Glu
305 310 315 320
Ile Met Leu Ala His Pro Glu Asn Trp Gln Lys Tyr Tyr Arg Gly Ser
325 330 335
Ala Glu Gln Gln Arg Leu Leu Arg Val Tyr Ser Tyr Ser Asp Arg Ile
340 345 350
Arg Tyr Tyr Trp Gly Arg Pro Glu Ala Glu Ala Ala Val Thr Arg Leu
355 360 365
Met Arg Asn Leu His Gln Thr Thr Ile Pro Glu Thr Leu Leu Ser Gln
370 375 380
Tyr Cys Pro Arg Glu Tyr Glu Ala Met Arg Glu Gly Arg Leu Arg Asn
385 390 395 400
Asp Pro Ala Glu Leu Thr Ile Ala Ser Ile Arg Thr Val Leu Glu Ser
405 410 415
Tyr Ser Ser Ala Cys Arg Gly Asp Gly Ser Asn Ser Gly Lys Gln
420 425 430
<210> 10
<211> 1296
<212> DNA
<213> Unknown
<220>
<223> 酸杆菌细菌(Acidobacteriales bacterium)
<220>
<221> 基因
<222> (1)..(1296)
<223> 塔格糖-二磷酸醛缩酶
<400> 10
atgtccgaca atttgcaggt gtttcttcgt gagtcccgag gccggcgcgg catctattcg 60
gtatgctccg cgcatccccg ggtgatcgag gccgccatgc ggcaagctgg cgcagacggc 120
acgcatctgc tgctggaagc gacgtcgaat caggtgaacc aagccggagg ctacaccggc 180
atgactcccg cgatgtttcg cgattacgtt tatgacattg cacaggagat cggcttcgac 240
cgcagccgtt tgattcttgg cggagatcat ttgggcccca atccctggca gcagctcgac 300
gccagcacag cgatgcagta tgcagaggag atggttcgac tgtacatcga ggcaggattc 360
accaagattc atctcgacgc cagcatgcgt tgtgccgacg atgcggcaat cgttcccgat 420
gaagtgatgg caggacgcgc cgccgcattg tgcagcgcgg ctgagtcggc gcgagcacgg 480
ctgggactgg cgccggtggt ctacgtgatc ggaaccgagg ttccaacgcc gggtggagca 540
agccatgctc tcaacacgct ggaggtaaca acgcgggagg cagtcgagca tacgctgtcg 600
gttcatcgca aagccttcca cgatgcggga ttggacgctg catggcagcg cgtgatcgcg 660
gtggtcgtgc agccgggcgt ggagttcgat cacgatagcg ttgtcgacta tgacgccgca 720
aaagcgggcc atttgcaaga atttctacaa gcccacccgg aactggtgat ggaggcacac 780
tccagcgatt accagaagcc gcaagcctac aaggaactgg tccgtgatgg cttcgcgatc 840
ctgaaggtcg ggcctgcgtt gacgtttgcg ctgcgggaga tgctctacgc gctggccgcc 900
atcgagcggg aactggtgcc ggaggcggag cagtcccatc tggtagagac gatggaagag 960
atcatgctgg ctcatcccga gaactggcag aagtactatc gcggaagcgc agagcagcag 1020
cgattgctgc gcgtctatag ctacagcgac cgcattcgct attactgggg acgtccggag 1080
gccgaagctg ccgtcacgcg cctgatgcga aatctgcatc agacgacgat tcccgagact 1140
ctcctaagcc agtattgtcc gcgcgaatat gaggcaatgc gcgaaggaag actgcgaaac 1200
gatccggctg agttgacgat cgcgagcatt cgaactgtgc tggagtccta cagcagcgct 1260
tgtcgcggtg acggctcgaa ctccggtaaa cagtaa 1296
<210> 11
<211> 420
<212> PRT
<213> Unknown
<220>
<223> Rhodothermus profundi
<220>
<221> 多肽
<222> (1)..(420)
<223> 塔格糖-二磷酸醛缩酶
<400> 11
Met Gln Ala His Val Leu Leu Ala Pro Ser Phe Glu Gln Leu Ala Asp
1 5 10 15
His Arg His Gly Phe Val Gly Trp Leu Val Asp Leu Leu Arg Gly Pro
20 25 30
Leu Ala Tyr Arg His Thr Leu Leu Ala Val Cys Pro Asn Ser Glu Ala
35 40 45
Val Thr Arg Ala Ala Leu Glu Ala Ala Arg Glu Ala Asn Ala Pro Leu
50 55 60
Phe Phe Ala Ala Thr Leu Asn Gln Val Asp Leu Asp Gly Gly Tyr Thr
65 70 75 80
Gly Trp Thr Pro Ala Thr Leu Ala Arg Phe Val Ala Asp Glu Arg Ile
85 90 95
Arg Leu Gly Leu Arg Ala Pro Val Val Leu Gly Leu Asp His Gly Gly
100 105 110
Pro Trp Lys Lys Asp Trp His Val Arg Asn Arg Leu Pro Tyr Glu Ala
115 120 125
Thr Leu Gln Ala Val Leu Arg Ala Ile Glu Ala Cys Leu Asp Ala Gly
130 135 140
Tyr Gly Leu Leu His Leu Asp Pro Thr Val Asp Leu Glu Leu Pro Pro
145 150 155 160
Gly Thr Pro Val Pro Ile Pro Arg Ile Val Glu Arg Thr Val Ala Leu
165 170 175
Leu Gln His Ala Glu Thr Tyr Arg Gln Gln Arg Arg Leu Pro Pro Val
180 185 190
Ala Tyr Glu Val Gly Thr Glu Glu Val Gly Gly Gly Leu Gln Ala Glu
195 200 205
Ala Arg Met Ala Glu Phe Leu Asp Arg Leu Trp Thr Val Leu Asp Arg
210 215 220
Glu Gly Leu Pro Arg Pro Val Phe Val Val Gly Asp Ile Gly Thr Arg
225 230 235 240
Leu Asp Thr His Thr Phe Asp Phe Glu Arg Ala Arg Arg Leu Asp Ala
245 250 255
Leu Val Arg Arg Tyr Gly Ala Leu Ile Lys Gly His Tyr Thr Asp Gly
260 265 270
Val Asp Arg Leu Asp Leu Tyr Pro Gln Ala Gly Ile Gly Gly Ala Asn
275 280 285
Val Gly Pro Gly Leu Ala Ala Ile Glu Phe Glu Ala Leu Glu Ala Leu
290 295 300
Val Ala Glu Ala His Arg Arg Lys Leu Pro Val Thr Phe Asp Arg Thr
305 310 315 320
Ile Arg Gln Ala Val Ile Glu Ser Gly Arg Trp Gln Lys Trp Leu Arg
325 330 335
Pro Glu Glu Lys Gly Arg Pro Phe Glu Ala Leu Pro Pro Glu Arg Gln
340 345 350
Arg Trp Leu Val Ala Thr Gly Ser Arg Tyr Val Trp Thr His Pro Ala
355 360 365
Val Arg Gln Ala Arg His Gln Leu Tyr Gln Val Leu Ala Pro Trp Leu
370 375 380
Asp Ala Asp Ala Phe Val Arg Ala Arg Ile Lys Ala Arg Leu Met Asp
385 390 395 400
Tyr Phe Arg Ala Phe Asn Leu Ile Gly Phe Asn Glu Arg Leu Gln Ala
405 410 415
Phe Leu Pro Asn
420
<210> 12
<211> 1263
<212> DNA
<213> Unknown
<220>
<223> Rhodothermus profundi
<220>
<221> 基因
<222> (1)..(1263)
<223> 塔格糖-二磷酸醛缩酶
<400> 12
atgcaggcgc acgtcctgct tgccccttcg ttcgagcagc tagcagacca caggcacgga 60
tttgttggct ggttggtcga tttgctgcgc ggaccgctgg cttaccggca cacgctgctg 120
gccgtatgtc ccaattccga agccgtaacg cgcgccgccc tggaagctgc gcgcgaagcc 180
aacgccccgc tattttttgc ggctaccctg aaccaggtcg acctggatgg cggatatacc 240
ggctggaccc cggccacgct ggctcgtttt gttgccgacg agcgcatccg cctgggcctt 300
cgcgcccctg tcgtacttgg tctggatcac ggtggcccct ggaaaaagga ttggcatgtc 360
cgcaaccgtc ttccgtacga ggcaacgctc caggcggtgc ttcgcgcgat tgaggcctgc 420
ctcgacgcag gttatgggct gcttcatctg gacccgacgg tagatctgga attgccgccc 480
ggcacacccg tccccatccc acgtattgtc gaacgaacgg tagcgctttt acaacatgct 540
gaaacgtatc gccaacagcg tcgcctgccc ccggtcgcct acgaggtagg cacggaggag 600
gttggcggcg gcctgcaggc tgaggcgcga atggcagaat ttctggatcg actctggacc 660
gtcctggatc gggaagggct accccgtccg gtgtttgtgg tgggtgacat tggcacccgg 720
cttgacacgc acaccttcga ctttgaacgc gcccgtcgcc tggatgccct ggtgcgccgc 780
tacggtgccc tgatcaaggg gcactacacc gatggagtag accgcctgga tctatatcca 840
caggcgggta tcggtggagc aaacgtgggg cctggcctgg ctgctatcga gtttgaagcg 900
ctggaggccc tggtggccga agcgcaccgc cgcaagctgc ccgttacctt tgaccggacc 960
atccgccagg ctgtcattga aagtggacgc tggcaaaaat ggctgcgccc tgaagagaaa 1020
ggacgtccct ttgaagcatt acctccagaa cgccagcggt ggctggtcgc tacaggcagc 1080
cgctacgtgt ggacgcaccc ggctgtccgg caggcgcgcc atcaattgta tcaggtgctc 1140
gctccctggc tcgatgccga tgcttttgtg cgcgcgcgca tcaaggcccg cctgatggac 1200
tacttccgcg ctttcaacct gataggcttc aatgaacggc tgcaggcctt tttacctaat 1260
tga 1263
<210> 13
<211> 420
<212> PRT
<213> Unknown
<220>
<223> 海洋红嗜热盐菌(Rhodothermus marinus)
<220>
<221> 多肽
<222> (1)..(420)
<223> 塔格糖-二磷酸醛缩酶
<400> 13
Met Gln Ala Gln Ala Leu Leu Thr Val Pro Phe Asp Arg Val Ala Thr
1 5 10 15
His Ala Arg Gly Phe Val Gly Trp Val Ala Glu Leu Leu Gln Gly Pro
20 25 30
Leu Ala Tyr Gln His Thr Leu Leu Ala Val Cys Pro Asn Ser Glu Ala
35 40 45
Val Thr Arg Ala Ala Leu Glu Ala Ala Ala Glu Ala Asn Ala Pro Leu
50 55 60
Leu Phe Ala Ala Thr Leu Asn Gln Val Asp Leu Asp Gly Gly Tyr Thr
65 70 75 80
Gly Trp Thr Pro Ala Thr Leu Ala Arg Phe Val Ala Asp Glu Leu Ala
85 90 95
Arg Leu Asp Leu His Ile Pro Val Val Leu Gly Leu Asp His Gly Gly
100 105 110
Pro Trp Lys Lys Asp Leu His Ala Arg Asn Arg Leu Ser Phe Glu Glu
115 120 125
Thr Phe Gln Ala Val Leu Arg Ala Ile Glu Ala Cys Leu Asp Ala Gly
130 135 140
Tyr Gly Leu Leu His Leu Asp Pro Thr Val Asp Leu Glu Leu Ser Pro
145 150 155 160
Gly Thr Pro Val Pro Ile Pro Arg Ile Val Glu Arg Ser Val Ala Leu
165 170 175
Leu Arg His Ala Glu Thr Tyr Arg Leu Arg Arg Asn Leu Pro Pro Val
180 185 190
Ala Tyr Glu Val Gly Thr Glu Glu Val Gly Gly Gly Leu Gln Ala Glu
195 200 205
Ala Arg Met Ala Glu Phe Leu Asp Arg Leu Trp Thr Ala Leu Asp Arg
210 215 220
Glu Gly Leu Pro His Pro Val Phe Val Val Gly Asp Ile Gly Thr Arg
225 230 235 240
Leu Asp Thr Arg Thr Phe Asp Phe Glu Arg Ala Arg Arg Leu Asp Ala
245 250 255
Leu Val Arg Arg Tyr Gly Ala Leu Ile Lys Gly His Tyr Thr Asp Asp
260 265 270
Val Asp Arg Leu Asp Leu Tyr Pro Lys Ala Gly Ile Gly Gly Ala Asn
275 280 285
Val Gly Pro Gly Leu Ala Ala Ile Glu Phe Glu Ala Leu Glu Ala Leu
290 295 300
Val Glu Glu Ala Arg Arg Arg Gly Leu Ser Val Thr Phe Asp Gln Ala
305 310 315 320
Ile Arg Arg Ala Val Val Glu Ser Gly Arg Trp Thr Lys Trp Leu Gln
325 330 335
Pro Glu Glu Lys Gly Gln Pro Phe Asp Ala Leu Asp Pro Glu Arg Gln
340 345 350
Arg Trp Leu Val Ala Thr Gly Ser Arg Tyr Val Trp Thr His Pro Ala
355 360 365
Val Leu Gln Ala Arg Arg Glu Leu Tyr Glu Ala Leu Ala Pro Trp Leu
370 375 380
Asp Ala Asp Ala Phe Val Arg Thr Arg Ile Lys Ala Arg Leu Met Asp
385 390 395 400
Tyr Phe Arg Ala Phe Asn Leu Ile His Phe Asn Glu Arg Leu Gln Ala
405 410 415
Phe Leu Pro Glu
420
<210> 14
<211> 1263
<212> DNA
<213> Unknown
<220>
<223> 海洋红嗜热盐菌(Rhodothermus marinus)
<220>
<221> 基因
<222> (1)..(1263)
<223> 塔格糖-二磷酸醛缩酶
<400> 14
atgcaggcgc aggccctgct gaccgttcca tttgatcggg tggcgaccca cgcacgcggg 60
tttgtgggct gggtggccga actgctgcag gggcccctgg cctatcagca tacgctgctg 120
gctgtctgtc ccaattcgga agcggtaaca cgggccgcgc tggaggccgc cgccgaggcc 180
aacgccccgc tgctttttgc cgccacgctg aaccaggtgg acctcgacgg cggctacacc 240
ggctggacgc ccgccacgct ggcccggttc gtggcggacg aactggcccg cctggacctg 300
cacatccccg tcgtgctcgg cctggaccac ggcggcccct ggaaaaagga tctgcacgcc 360
cgcaaccgat tgtcctttga ggaaaccttc caggccgtgc tgcgggccat cgaggcctgt 420
ctggatgccg gctacggcct gctgcacctg gatccgacgg tcgatctgga gctatcgccc 480
ggcacgccgg tgcccatccc gcgcattgtc gaacgctcgg tagcgctttt gcgtcatgcc 540
gaaacctatc gacttcgacg taacctgccg ccggtcgcct acgaggtggg caccgaagaa 600
gtcggcggcg gcctgcaggc cgaagcgcgc atggcggagt ttctggatcg cctctggacc 660
gcactggacc gggaaggcct gccccatcca gtcttcgtgg tgggcgacat cggcacccgg 720
ctcgacacgc gcacgttcga cttcgagcgg gcccgacggc tggacgcgct ggtgcgccgc 780
tacggtgccc tcatcaaagg gcactacacc gacgacgtgg atcgcctcga tctgtacccg 840
aaggcgggca tcggcggggc caacgtgggc ccgggcctgg ccgccatcga gtttgaagcg 900
ctggaggcgc tggtggagga agcccgtcgc cgcggtcttt cggtgacgtt cgatcaggcc 960
atccgccggg ccgtcgtcga aagcggacgc tggacgaagt ggctccaacc ggaagagaaa 1020
ggccagccgt tcgatgcgct ggatcccgag cggcaacgct ggctggtggc caccggcagc 1080
cgctacgtgt ggacgcatcc ggccgtcctg caggcccgcc gcgaactcta cgaggcgctc 1140
gccccctggc tcgatgccga cgctttcgtg cgcacgcgca tcaaagcacg cctgatggac 1200
tactttcgtg ccttcaacct gatccatttc aacgagcggc tgcaggcctt tctccccgaa 1260
tga 1263
<210> 15
<211> 448
<212> PRT
<213> Unknown
<220>
<223> Limnochorda pilosa
<220>
<221> 多肽
<222> (1)..(448)
<223> 塔格糖-二磷酸醛缩酶
<400> 15
Met Gln Thr Ser Thr Ala Tyr Val Arg Gln Val Ile Trp Gly Gln Gly
1 5 10 15
Thr Arg Asp Pro Arg Gly Ile Tyr Ser Val Cys Thr Ala Asp Pro Leu
20 25 30
Val Leu Arg Ala Ala Leu Lys Gln Ala Val Glu Asp Gly Ser Pro Ala
35 40 45
Leu Ile Glu Ala Thr Ser Asn Gln Val Asn Gln Phe Gly Gly Tyr Thr
50 55 60
Gly Met Glu Pro Pro Ala Phe Val Glu Phe Val Leu Gly Leu Ala Arg
65 70 75 80
Glu Met Gly Leu Pro Pro Glu Arg Leu Ile Leu Gly Gly Asp His Leu
85 90 95
Gly Pro Asn Pro Trp Gln Arg Leu Ala Ala Glu Glu Ala Met Arg His
100 105 110
Ala Cys Asp Leu Val Glu Ala Phe Val Ala Cys Gly Phe Thr Lys Ile
115 120 125
His Leu Asp Ala Ser Met Pro Leu Gly Glu Glu Arg Ala Gly Gly Ala
130 135 140
Leu Ser Lys Arg Val Val Ala Glu Arg Thr Ala Gln Leu Cys Glu Ala
145 150 155 160
Ala Glu Ala Ala Phe Arg Lys Arg Ser Gln Ala Glu Gly Ala Ser Ala
165 170 175
Pro Pro Leu Tyr Val Ile Gly Ser Asp Val Pro Pro Pro Gly Gly Glu
180 185 190
Thr Ser Gly Ser Gln Gly Pro Lys Val Thr Thr Pro Glu Glu Phe Glu
195 200 205
Glu Thr Val Ala Leu Thr Arg Ala Thr Phe His Asp Arg Gly Leu Asp
210 215 220
Asp Ala Trp Gly Arg Val Ile Ala Val Val Val Gln Pro Gly Val Asp
225 230 235 240
Phe Gly Glu Trp Gln Val His Pro Tyr Asp Arg Ala Ala Ala Ala Ser
245 250 255
Leu Thr Arg Ala Leu Thr Gln His Pro Gly Leu Ala Phe Glu Gly His
260 265 270
Ser Thr Asp Tyr Gln Thr Pro Gly Arg Leu Arg Gln Met Ala Glu Asp
275 280 285
Gly Ile Ala Ile Leu Lys Val Gly Pro Ala Leu Thr Phe Ala Lys Arg
290 295 300
Glu Ala Leu Phe Ala Leu Asn Ala Leu Glu Ser Glu Val Leu Gly Thr
305 310 315 320
Asp Gly Arg Ala Arg Arg Ser Asn Val Glu Ala Ala Leu Glu Glu Ala
325 330 335
Met Leu Ala Asp Pro Arg His Trp Ser Ala Tyr Tyr Ser Gly Asp Glu
340 345 350
His Glu Leu Arg Leu Lys Arg Lys Tyr Gly Leu Ser Asp Arg Cys Arg
355 360 365
Tyr Tyr Trp Pro Val Pro Ser Val Gln Glu Ala Val Gln Arg Leu Leu
370 375 380
Gly Asn Leu Arg Glu Ala Gly Ile Pro Leu Pro Leu Leu Ser Gln Phe
385 390 395 400
Leu Pro Arg Gln Tyr Glu Arg Val Arg Glu Gly Val Leu Arg Asn Asp
405 410 415
Pro Glu Glu Leu Val Leu Asp Arg Ile Arg Asp Val Leu Arg Gly Tyr
420 425 430
Ala Ala Ala Val Gly Thr Gly Ala Arg Arg Ala Glu Pro Ser Pro Ala
435 440 445
<210> 16
<211> 1347
<212> DNA
<213> Unknown
<220>
<223> Limnochorda pilosa
<220>
<221> 基因
<222> (1)..(1347)
<223> 塔格糖-二磷酸醛缩酶
<400> 16
atgcaaacct cgacggcgta cgtgaggcag gtcatttggg gtcaagggac gagggacccc 60
cgcggcatct actcggtctg taccgcagac cccctcgtcc ttcgggccgc cctcaagcag 120
gcggtggagg atggctcccc cgcgctgatc gaggcgacgt ccaaccaggt gaaccagttc 180
ggcgggtata cggggatgga gcccccggcg ttcgtggagt tcgtgctggg acttgcccgc 240
gagatgggac tcccgcccga gcggctgatc ctcgggggcg atcacctcgg ccccaaccca 300
tggcagcggc tggcggccga agaggccatg cggcatgcct gcgacctcgt cgaggccttc 360
gtggcctgcg gcttcaccaa gattcacctg gacgccagca tgcccctggg ggaggaacgg 420
gcaggcggtg cgctttcgaa acgggtggtg gccgaacgga ccgcccagct ctgcgaggcg 480
gccgaggcgg ccttcaggaa gcggtcccag gcggaggggg cgtcggcgcc tccgctctac 540
gtcatcggct ccgacgtgcc tccgcccggc ggcgagacct ccgggagcca ggggcccaag 600
gtgaccacgc cggaggagtt cgaggagacg gtcgcgctga cgcgggcgac ctttcacgat 660
cggggcctgg acgacgcctg gggacgggtg atcgccgtgg tggtccagcc gggggtggac 720
ttcggcgagt ggcaggttca cccctacgat cgggccgccg cggcgagcct tacccgagcc 780
ttgacgcagc atccggggct ggccttcgaa gggcactcca ccgactacca gacgccgggg 840
cggcttcgcc agatggcgga agacggcatc gccatcctga aggtggggcc ggccctcacc 900
ttcgccaagc gggaagcgct cttcgccctg aacgccctgg agtccgaagt gctggggacg 960
gacggccgag cacggcgctc caacgtcgaa gccgccctcg aagaggcgat gctcgccgat 1020
ccccgtcact ggagcgccta ctacagcggg gacgagcacg agctccgtct caagcggaag 1080
tacggcctct ccgaccggtg tcgctactac tggcccgtcc cttcggtgca ggaggccgtc 1140
cagcgcctcc ttggcaacct gcgcgaggcg gggatcccct tgcccctgct gagccagttc 1200
ctgccgcgcc agtacgagcg ggtgcgggag ggcgtcctgc gcaacgaccc ggaggagctg 1260
gtcctggacc ggattcgtga cgtgttgcgg ggatatgcgg cggccgtggg gacgggcgct 1320
aggcgggcgg agccatcacc cgcgtga 1347
<210> 17
<211> 453
<212> PRT
<213> Unknown
<220>
<223> Caldithrix abyssi
<220>
<221> 多肽
<222> (1)..(453)
<223> 塔格糖-二磷酸醛缩酶
<400> 17
Met Ser Leu His Pro Leu Asn Lys Leu Ile Glu Arg His Lys Lys Gly
1 5 10 15
Thr Pro Val Gly Ile Tyr Ser Val Cys Ser Ala Asn Pro Phe Val Leu
20 25 30
Lys Ala Ala Met Leu Gln Ala Gln Lys Asp Gln Ser Leu Leu Leu Ile
35 40 45
Glu Ala Thr Ser Asn Gln Val Asp Gln Phe Gly Gly Tyr Thr Gly Met
50 55 60
Arg Pro Glu Asp Phe Lys Thr Met Thr Leu Glu Leu Ala Ala Glu Asn
65 70 75 80
Asn Tyr Asp Pro Gln Gly Leu Ile Leu Gly Gly Asp His Leu Gly Pro
85 90 95
Asn Arg Trp Thr Lys Leu Ser Ala Ser Arg Ala Met Asp Tyr Ala Arg
100 105 110
Glu Gln Ile Ala Ala Tyr Val Lys Ala Gly Phe Ser Lys Ile His Leu
115 120 125
Asp Ala Thr Met Pro Leu Gln Asn Asp Ala Thr Asp Ser Ala Gly Arg
130 135 140
Leu Pro Val Glu Thr Ile Ala Gln Arg Thr Ala Glu Leu Cys Ala Val
145 150 155 160
Ala Glu Gln Thr Tyr Arg Gln Ser Asp Gln Leu Phe Pro Pro Pro Val
165 170 175
Tyr Ile Val Gly Ser Asp Val Pro Ile Pro Gly Gly Ala Gln Glu Ala
180 185 190
Leu Asn Gln Ile His Ile Thr Glu Val Lys Glu Val Gln Gln Thr Ile
195 200 205
Asp His Val Arg Arg Ala Phe Glu Lys Asn Gly Leu Glu Ala Ala Tyr
210 215 220
Glu Arg Val Cys Ala Val Val Val Gln Pro Gly Val Glu Phe Ala Asp
225 230 235 240
Gln Ile Val Phe Glu Tyr Ala Pro Asp Arg Ala Ala Ala Leu Lys Asp
245 250 255
Phe Ile Glu Ser His Ser Gln Leu Val Tyr Glu Ala His Ser Thr Asp
260 265 270
Tyr Gln Thr Ala Pro Leu Leu Arg Gln Met Val Lys Asp His Phe Ala
275 280 285
Ile Leu Lys Val Gly Pro Ala Leu Thr Phe Ala Leu Arg Glu Ala Ile
290 295 300
Phe Ala Leu Ala Phe Met Glu Lys Glu Leu Leu Pro Leu His Arg Ala
305 310 315 320
Leu Lys Pro Ser Ala Ile Leu Glu Thr Leu Asp Gln Thr Met Asp Lys
325 330 335
Asn Pro Ala Tyr Trp Gln Lys His Tyr Gly Gly Thr Lys Glu Glu Val
340 345 350
Arg Phe Ala Gln Arg Phe Ser Leu Ser Asp Arg Ile Arg Tyr Tyr Trp
355 360 365
Pro Phe Pro Lys Val Gln Lys Ala Leu Arg Gln Leu Leu Lys Asn Leu
370 375 380
Gln Gln Ile Ser Ile Pro Leu Thr Leu Val Ser Gln Phe Met Pro Glu
385 390 395 400
Glu Tyr Gln Arg Ile Arg Gln Gly Thr Leu Thr Asn Asp Pro Gln Ala
405 410 415
Leu Ile Leu Asn Lys Ile Gln Ser Val Leu Lys Gln Tyr Ala Glu Ala
420 425 430
Thr Gln Ile Gln Asn Ser Leu Thr Phe Thr Gln Asn Gln Asn Ser Leu
435 440 445
Ala Met Glu Arg Leu
450
<210> 18
<211> 1362
<212> DNA
<213> Unknown
<220>
<223> Caldithrix abyssi
<220>
<221> 基因
<222> (1)..(1362)
<223> 塔格糖-二磷酸醛缩酶
<400> 18
atgagtctgc atcctttaaa taaattaatc gagcgacaca aaaaaggaac gccggtcggt 60
atttattccg tctgttcggc caatcccttt gttttgaaag cggccatgct acaggcgcaa 120
aaggatcagt ctttgctact tattgaggcc acttccaacc aggtagatca attcggcggt 180
tacaccggca tgcggcccga agattttaaa acaatgacgc ttgaactggc agccgaaaac 240
aattacgatc cacagggatt aatcctgggc ggcgaccatc tggggcccaa ccgctggaca 300
aaactgagcg cctcccgggc catggactac gccagagagc agattgccgc ttatgttaaa 360
gccggctttt ccaaaatcca cttagacgcc accatgccct tgcaaaacga tgccacagat 420
tccgccggcc gccttccagt cgaaacaatc gctcaacgta ccgcagaatt atgcgccgtg 480
gccgaacaaa cttaccggca gagcgaccaa ctctttccgc cgcctgttta cattgtcggc 540
agcgacgtgc ccatcccggg cggcgcgcaa gaagcgctga accagatcca tattacggag 600
gtaaaagagg ttcaacagac cattgatcac gtgcggcggg cctttgaaaa aaacggcctg 660
gaagcggctt acgaaagagt ttgcgccgtt gtcgtgcagc caggcgttga attcgccgat 720
caaatcgttt ttgaatacgc tcccgacaga gcggcggcct taaaagattt tattgaaagc 780
cattcgcagc tggtttatga agcgcactct actgattacc agaccgcacc tcttttgcgc 840
cagatggtaa aagatcactt tgccatttta aaggtcgggc ctgcgctcac ctttgccctg 900
cgcgaagcca tttttgctct ggcctttatg gaaaaagagc ttttgccatt gcacagagcg 960
ctcaaacctt ctgccattct ggaaacgctg gaccaaacga tggacaaaaa ccctgcttac 1020
tggcaaaagc attacggcgg aacaaaggaa gaagtacgct ttgcgcagcg gtttagcctg 1080
agcgaccgca ttcgttacta ctggccgttt ccaaaggttc aaaaggccct gcgccaattg 1140
ctaaaaaact tgcaacaaat ttccattcct ctaactttgg taagccagtt catgccagag 1200
gaataccaac gtattcgcca aggaacgtta accaacgatc cgcaggcgct gattttgaac 1260
aaaattcaaa gcgtattaaa gcaatacgcg gaggcgacgc aaattcaaaa ctctttgaca 1320
ttcacgcaaa atcaaaattc attagcaatg gagcgactat ga 1362
<210> 19
<211> 429
<212> PRT
<213> Unknown
<220>
<223> Caldicellulosiruptor kronotskyensis
<220>
<221> 多肽
<222> (1)..(429)
<223> 塔格糖-二磷酸醛缩酶
<400> 19
Met Ser Pro Gln Asn Pro Leu Ile Gly Leu Phe Lys Asn Arg Glu Lys
1 5 10 15
Glu Phe Lys Gly Ile Ile Ser Val Cys Ser Ser Asn Glu Ile Val Leu
20 25 30
Glu Ala Val Leu Lys Arg Met Lys Asp Thr Asn Leu Pro Ile Ile Ile
35 40 45
Glu Ala Thr Ala Asn Gln Val Asn Gln Phe Gly Gly Tyr Ser Gly Leu
50 55 60
Thr Pro Ser Gln Phe Lys Glu Arg Val Ile Lys Ile Ala Gln Lys Val
65 70 75 80
Asp Phe Pro Leu Glu Arg Ile Ile Leu Gly Gly Asp His Leu Gly Pro
85 90 95
Phe Val Trp Arg Asp Gln Glu Pro Glu Ile Ala Met Glu Tyr Ala Lys
100 105 110
Gln Met Ile Lys Glu Tyr Ile Lys Ala Gly Phe Thr Lys Ile His Ile
115 120 125
Asp Thr Ser Met Pro Leu Lys Gly Glu Asn Ser Ile Asp Asp Glu Ile
130 135 140
Ile Ala Lys Arg Thr Ala Val Leu Cys Arg Ile Ala Glu Glu Cys Phe
145 150 155 160
Glu Lys Ile Ser Ile Asn Asn Pro Tyr Ile Thr Arg Pro Val Tyr Val
165 170 175
Ile Gly Ala Asp Val Pro Pro Pro Gly Gly Glu Ser Ser Ile Cys Gln
180 185 190
Thr Ile Thr Thr Lys Asp Glu Leu Glu Arg Ser Leu Glu Tyr Phe Lys
195 200 205
Glu Ala Phe Lys Lys Glu Gly Ile Glu His Val Phe Asp Tyr Val Val
210 215 220
Ala Val Val Ala Asn Phe Gly Val Glu Phe Gly Ser Asp Glu Ile Val
225 230 235 240
Asp Phe Asp Met Glu Lys Val Lys Pro Leu Lys Glu Leu Leu Ala Lys
245 250 255
Tyr Asn Ile Val Phe Glu Gly His Ser Thr Asp Tyr Gln Thr Lys Glu
260 265 270
Asn Leu Lys Arg Met Val Glu Cys Gly Ile Ala Ile Leu Lys Val Gly
275 280 285
Pro Ala Leu Thr Phe Thr Leu Arg Glu Ala Leu Val Ala Leu Ser His
290 295 300
Ile Glu Glu Glu Ile Tyr Ser Asn Glu Lys Glu Lys Leu Ser Arg Phe
305 310 315 320
Arg Glu Val Leu Leu Asn Thr Met Leu Thr Cys Lys Asp His Trp Ser
325 330 335
Lys Tyr Phe Asp Glu Asn Asp Lys Leu Ile Lys Ser Lys Leu Leu Tyr
340 345 350
Ser Tyr Leu Asp Arg Trp Arg Tyr Tyr Phe Glu Asn Glu Ser Val Lys
355 360 365
Ser Ala Val Tyr Ser Leu Ile Gly Asn Leu Glu Asn Val Lys Ile Pro
370 375 380
Pro Trp Leu Val Ser Gln Tyr Phe Pro Ser Gln Tyr Gln Lys Met Arg
385 390 395 400
Lys Lys Asp Leu Lys Asn Gly Ala Ala Asp Leu Ile Leu Asp Lys Ile
405 410 415
Gly Glu Val Ile Asp His Tyr Val Tyr Ala Val Lys Glu
420 425
<210> 20
<211> 1290
<212> DNA
<213> Unknown
<220>
<223> Caldicellulosiruptor kronotskyensis
<220>
<221> 基因
<222> (1)..(1290)
<223> 塔格糖-二磷酸醛缩酶
<400> 20
atgagtcctc aaaatccatt gattggttta tttaagaata gagaaaaaga gtttaagggt 60
attatttcag tttgttcttc aaatgaaata gtcttagaag cagttttaaa aagaatgaaa 120
gatacaaacc taccaattat tattgaagcc acagcgaacc aggtaaatca atttggcggg 180
tattctgggt tgacaccgtc tcagttcaaa gaacgagtta taaaaattgc tcaaaaagtt 240
gattttccac ttgagagaat aattcttggt ggggaccatc ttggaccatt tgtgtggcgt 300
gaccaggaac cagaaattgc tatggagtat gctaagcaaa tgataaaaga atacataaaa 360
gcaggtttta ccaaaattca catcgacacg agtatgcctt taaaagggga gaacagcata 420
gatgatgaaa taattgctaa aagaactgct gtgctctgca ggattgcgga ggagtgtttt 480
gagaagattt ctataaacaa tccctatatt acaaggccag tttatgtgat aggagctgat 540
gtgccacctc ccggcggaga gtcttctatt tgtcaaacaa ttactactaa agatgaatta 600
gaaagaagtt tagaatattt caaagaagca tttaaaaagg aaggaattga gcatgtattc 660
gattatgtag ttgctgttgt tgcaaatttt ggagttgaat ttgggagcga tgaaattgtt 720
gattttgata tggaaaaagt aaagccgcta aaagaacttt tggcaaagta caatatagta 780
tttgaaggcc attctacaga ttatcaaaca aaagaaaact taaaaagaat ggtcgaatgt 840
ggtattgcaa ttttaaaggt tggtcctgct ctaacattta cattgcgcga agcgttagta 900
gcacttagtc atattgaaga agaaatttat agcaatgaaa aggagaaact gtcaagattt 960
agagaagttt tattgaatac tatgctaaca tgcaaagatc actggagtaa atattttgat 1020
gagaatgata agttaattaa gtcaaagctc ctatatagct atcttgacag atggagatac 1080
tattttgaaa acgagagtgt gaaaagtgct gtttattctc ttattggaaa tttagagaat 1140
gttaaaattc caccttggct tgtaagtcag tattttcctt ctcagtacca aaagatgaga 1200
aaaaaagatt taaaaaacgg tgctgccgac ctaatattgg ataaaatagg ggaagtcatt 1260
gaccattatg tttatgcggt aaaagaataa 1290
<210> 21
<211> 408
<212> PRT
<213> Unknown
<220>
<223> Caldilinea aerophila
<220>
<221> 多肽
<222> (1)..(408)
<223> 塔格糖-二磷酸醛缩酶
<400> 21
Met Ser Thr Leu Arg His Ile Ile Leu Arg Leu Ile Glu Leu Arg Glu
1 5 10 15
Arg Glu Gln Ile His Leu Thr Leu Leu Ala Val Cys Pro Asn Ser Ala
20 25 30
Ala Val Leu Glu Ala Ala Val Lys Val Ala Ala Arg Cys His Thr Pro
35 40 45
Met Leu Phe Ala Ala Thr Leu Asn Gln Val Asp Arg Asp Gly Gly Tyr
50 55 60
Thr Gly Trp Thr Pro Ala Gln Phe Val Ala Glu Met Arg Arg Tyr Ala
65 70 75 80
Val Arg Tyr Gly Cys Thr Thr Pro Leu Tyr Pro Cys Leu Asp His Gly
85 90 95
Gly Pro Trp Leu Lys Asp Arg His Ala Gln Glu Lys Leu Pro Leu Asp
100 105 110
Gln Ala Met His Glu Val Lys Leu Ser Leu Thr Ala Cys Leu Glu Ala
115 120 125
Gly Tyr Ala Leu Leu His Ile Asp Pro Thr Val Asp Arg Thr Leu Pro
130 135 140
Pro Gly Glu Ala Pro Leu Val Pro Ile Val Val Glu Arg Thr Val Glu
145 150 155 160
Leu Ile Glu His Ala Glu Gln Glu Arg Gln Arg Leu Asn Leu Pro Ala
165 170 175
Val Ala Tyr Glu Val Gly Thr Glu Glu Val His Gly Gly Leu Val Asn
180 185 190
Phe Asp Asn Phe Val Ala Phe Leu Asp Leu Leu Lys Ala Arg Leu Glu
195 200 205
Gln Arg Ala Leu Met His Ala Trp Pro Ala Phe Val Val Ala Gln Val
210 215 220
Gly Thr Asp Leu His Thr Thr Tyr Phe Asp Pro Ser Ala Ala Gln Arg
225 230 235 240
Leu Thr Glu Ile Val Arg Pro Thr Gly Ala Leu Leu Lys Gly His Tyr
245 250 255
Thr Asp Trp Val Glu Asn Pro Ala Asp Tyr Pro Arg Val Gly Met Gly
260 265 270
Gly Ala Asn Val Gly Pro Glu Phe Thr Ala Ala Glu Phe Glu Ala Leu
275 280 285
Glu Ala Leu Glu Arg Arg Glu Gln Arg Leu Cys Ala Asn Arg Lys Leu
290 295 300
Gln Pro Ala Cys Phe Leu Ala Ala Leu Glu Glu Ala Val Val Ala Ser
305 310 315 320
Asp Arg Trp Arg Lys Trp Leu Gln Pro Asp Glu Ile Gly Lys Pro Phe
325 330 335
Ala Glu Leu Thr Pro Ala Arg Arg Arg Trp Leu Val Gln Thr Gly Ala
340 345 350
Arg Tyr Val Trp Thr Ala Pro Lys Val Ile Ala Ala Arg Glu Gln Leu
355 360 365
Tyr Ala His Leu Ser Leu Val Gln Ala Asp Pro His Ala Tyr Val Val
370 375 380
Glu Ser Val Ala Arg Ser Ile Glu Arg Tyr Ile Asp Ala Phe Asn Leu
385 390 395 400
Tyr Asp Ala Ala Thr Leu Leu Gly
405
<210> 22
<211> 1227
<212> DNA
<213> Unknown
<220>
<223> Caldilinea aerophila
<220>
<221> 基因
<222> (1)..(1227)
<223> 塔格糖-二磷酸醛缩酶
<400> 22
atgtcaacac ttcgccacat cattttgcga ctgatcgagc tgcgtgaacg agaacagatc 60
catctcacgc tgctggccgt ctgtcccaac tcggcggcgg tgctggaggc agcggtgaag 120
gtcgccgcgc gctgccacac gccgatgctc ttcgctgcca cgctcaatca agtcgatcgc 180
gacggcggct acaccggttg gacgcctgcg caattcgtcg ccgagatgcg tcgctatgcc 240
gtccgctatg gctgcaccac cccgctctat ccttgcctgg atcacggcgg gccgtggctc 300
aaagatcgcc atgcacagga aaagctaccg ctcgaccagg cgatgcatga ggtcaagctg 360
agcctcaccg cctgtctgga ggccggctac gcgctgctgc acatcgaccc cacggtcgat 420
cgcacgctcc cgcccggaga agcgccgctc gtgccgatcg tcgtcgagcg cacggtcgag 480
ctgatcgaac atgccgaaca ggagcgacag cggctgaacc tgccggcggt cgcctatgaa 540
gtcggcaccg aagaagtaca tggcgggctg gtgaatttcg acaattttgt cgccttcttg 600
gatttgctca aggcaaggct tgaacaacgt gccctgatgc acgcctggcc cgccttcgtg 660
gtggcgcagg tcggcactga cctgcataca acgtattttg accccagtgc ggcgcaacgg 720
ctgactgaga tcgtgcgccc taccggtgca ctgttgaagg ggcactacac cgactgggtc 780
gaaaatcccg ccgactatcc gagggtaggc atgggaggcg ccaacgttgg tccagagttt 840
acggcggccg agttcgaggc gctggaagcg ctggaacggc gggaacaacg gctgtgcgcc 900
aaccggaaat tgcagcccgc ctgttttttg gctgcactgg aagaggcagt agtcgcttca 960
gatcgttggc ggaagtggct ccagcccgat gagatcggca agccctttgc agaattaacg 1020
cccgcacgcc ggcgctggct cgtgcagacc ggggcacgct acgtctggac tgcgccgaaa 1080
gttatcgccg cacgcgaaca gctctatgcg cacctctccc ttgtgcaggc ggatccacat 1140
gcctacgtgg tagagtcagt cgcccggtca atcgagcgct atatcgatgc cttcaactta 1200
tacgacgccg ctacattgct tggatga 1227
<210> 23
<211> 446
<212> PRT
<213> Unknown
<220>
<223> 热产硫化氢热厌氧杆菌(Thermoanaerobacter thermohydrosulfuricus)
<220>
<221> 多肽
<222> (1)..(446)
<223> 塔格糖-二磷酸醛缩酶
<400> 23
Met Asn Thr Glu His Pro Leu Lys Asn Val Val Lys Leu Gln Lys Lys
1 5 10 15
Gly Ile Pro Ile Gly Ile Tyr Ser Val Cys Ser Ala Asn Glu Ile Val
20 25 30
Ile Gln Val Ala Met Glu Lys Ala Leu Ser Met Asp Ser Tyr Val Leu
35 40 45
Ile Glu Ala Thr Ala Asn Gln Val Asn Gln Tyr Gly Gly Tyr Thr Asn
50 55 60
Met Lys Pro Ile Asp Phe Arg Asp Phe Val Tyr Ser Ile Ala Lys Arg
65 70 75 80
Ile Asn Phe Pro Glu Asn Arg Ile Ile Leu Gly Gly Asp His Leu Gly
85 90 95
Pro Leu Pro Trp Lys Asn Gln Gln Ala Lys Lys Ala Met Glu Glu Ala
100 105 110
Lys Glu Leu Val Lys Gln Phe Val Met Ala Gly Phe Thr Lys Ile His
115 120 125
Val Asp Thr Ser Met Leu Leu Gly Asp Asp Asn Ile Asn Ile Lys Leu
130 135 140
Asp Thr Glu Thr Ile Ala Glu Arg Gly Ala Ile Leu Val Ser Val Ala
145 150 155 160
Glu Arg Ala Phe Glu Glu Leu Lys Lys Phe Asn Pro Tyr Ala Leu His
165 170 175
Pro Val Tyr Val Ile Gly Ser Glu Val Pro Val Pro Gly Gly Ser Gln
180 185 190
Lys Glu Asn Asn Asn Glu Ile Gln Val Thr Lys Pro Thr Asp Phe Glu
195 200 205
Glu Thr Val Glu Val Tyr Lys Ser Thr Phe Tyr Lys Tyr Gly Leu Gly
210 215 220
Asn Ala Trp Glu Asp Val Val Ala Val Val Val Gln Ala Gly Val Glu
225 230 235 240
Phe Gly Val Glu Asp Ile His Glu Tyr Asp His Gln Gln Ala Glu Asn
245 250 255
Leu Val Ser Ala Leu Lys Lys Tyr Pro Asn Leu Val Phe Glu Ala His
260 265 270
Ser Thr Asp Tyr Gln Pro Ala Lys Leu Leu Lys Glu Met Val Arg Asp
275 280 285
Gly Phe Ala Ile Leu Lys Val Gly Pro Glu Leu Thr Phe Ala Leu Arg
290 295 300
Glu Gly Leu Phe Ala Leu Asn Ile Ile Glu Lys Glu Leu Phe Lys Asp
305 310 315 320
Asn His Asp Ile Glu Met Ser Asn Phe Ile Asp Ile Leu Asp Thr Ala
325 330 335
Met Leu Asn Asn Pro Lys Tyr Trp Glu Gln Tyr Tyr Tyr Gly Asp Asp
340 345 350
Asn Lys Ile Arg Ile Ala Arg Lys Tyr Ser Tyr Ser Asp Arg Cys Arg
355 360 365
Tyr Tyr Leu Ile Glu Asn Glu Val Arg Ala Ser Met Ser Arg Leu Phe
370 375 380
Lys Asn Leu Thr Asn Val Glu Ile Pro Leu Thr Leu Ile Ser Gln Tyr
385 390 395 400
Met Pro Ile Gln Tyr Glu Lys Ile Arg Met Gly Leu Leu Lys Asn Asp
405 410 415
Pro Glu Asn Leu Val Lys Asp Lys Ile Gly Asn Cys Ile Asp Lys Tyr
420 425 430
Leu Tyr Ala Thr Asn Pro Thr Ser Gly Glu Phe Lys Leu Ile
435 440 445
<210> 24
<211> 1341
<212> DNA
<213> Unknown
<220>
<223> 热产硫化氢热厌氧杆菌(Thermoanaerobacter thermohydrosulfuricus)
<220>
<221> 基因
<222> (1)..(1341)
<223> 塔格糖-二磷酸醛缩酶
<400> 24
atgaatacag aacatccttt gaaaaacgtt gttaaactac aaaaaaaggg aattccaata 60
ggtatttatt cagtttgtag tgcaaatgaa atagttattc aagttgcaat ggagaaggca 120
ttgagtatgg atagttatgt tttaattgaa gcaacggcta atcaagtaaa tcaatatggt 180
ggctatacga atatgaaacc tattgatttt agagattttg tgtattctat agccaaaagg 240
ataaacttcc cagaaaatag aataatcctt ggcggggacc acttaggacc tttgccatgg 300
aaaaatcaac aagcgaaaaa agcaatggaa gaagcaaaag aacttgttaa acaatttgtg 360
atggctggct ttacgaaaat tcatgtagat acaagtatgc ttcttggaga tgataacata 420
aatatcaaac tagatactga aactattgcg gagagaggag cgatacttgt atcagtagca 480
gaaagagctt ttgaggagtt aaaaaagttt aatccttatg ctcttcatcc agtttatgta 540
ataggtagtg aagttcctgt tccaggaggt tctcaaaaag aaaataataa tgaaatacaa 600
gtaacaaagc cgacggattt tgaagaaact gtggaagtgt ataaaagcac tttctataaa 660
tatggtttag gaaacgcatg ggaagatgtt gtagcagtgg ttgtgcaggc tggggtggaa 720
tttggagttg aagatattca tgaatatgat caccaacagg ctgaaaattt agtaagtgct 780
ttaaaaaagt atcctaattt agtatttgaa gcccactcta cggattatca acctgcaaaa 840
ctactaaaag aaatggtgag agatggattt gctatactta aagttggacc tgaattgact 900
tttgcattaa gggaaggatt gtttgctctg aatattatag aaaaagaatt atttaaagat 960
aatcatgata ttgagatgtc aaattttatt gatatccttg atacagcaat gttaaataat 1020
ccgaagtatt gggaacagta ttattacggt gatgataata aaattagaat tgctagaaaa 1080
tacagctatt ctgatagatg taggtattat ctaatcgaaa atgaagttag agcatctatg 1140
tctaggttgt ttaaaaattt aacaaatgtt gagataccat taaccttgat aagtcagtat 1200
atgcctattc aatatgaaaa aattagaatg ggactattaa aaaatgatcc tgagaattta 1260
gtaaaagata aaattggaaa ttgcattgat aagtatttgt atgctactaa tccgacaagt 1320
ggagaattta aactaatata a 1341
<210> 25
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> 引物 1
<400> 25
gaccatcttg gcccataccc ctggaagggt cag 33
<210> 26
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> 引物 2
<400> 26
ctgacccttc caggggtatg ggccaagatg gtc 33
- 新型的果糖-4-差向异构酶以及使用其制备塔格糖的方法
- 新型果糖-4-差向异构酶以及使用其制备塔格糖的方法