一种基于双深度时序差分神经网络的紧密协作型供应链任务调度方法
文献发布时间:2023-06-19 12:25:57
技术领域
本发明涉及供应链调度领域,更具体地,涉及一种基于双深度时序差分神经网络的紧密协作型供应链任务调度方法。
背景技术
供应链调度,其目的是能够找到一条优化的方案与策略,从而使整条供应链利益最优化,无论是对于供应商还是生产商,供应链调度都是至关重要的。与传统供应链系统相比,开放式供应链系统在任务、服务、资源、优化目标、不确定性等方面都存在较大差异。从制造任务的角度,开放式供应链系统中的任务具有个性化、大规模以及供应商协作更加紧密的特点;从制造服务的角度,开放式供应链是一种面向服务的制造模式,开放式供应链调度问题不再是简单的任务与资源的匹配,而要考虑制造服务的柔性、关联性、可组合性以及任务与服务的映射关系。开放式供应链系统中的动态性、不确定性更加凸显,干扰事件更加普遍,导致解决开放式供应链环境下的调度问题更加困难。就目前而言,我国制造业在生产能力利用效率方面仍然处于比较低的水平,这主要是因为传统制造业的调度模式已无法适应开放式供应链任务的快速变化,制造企业所使用的供应链任务调度系统,同生产实际情况相差甚远,在复杂的动态开放式场合很难应用,通常需要人工对调度方案进行适应性调整。但是人工调整的优劣取决于调度员的经验和知识水平,而且往往需要耗费大量的时间和劳动力,调度方案的稳定性及供应链任务调度效率难以保证。
因此,要对紧密协作型供应链任务调度模式进行深入研究,将传统的供应链任务调度模式向智能化和高效化的方向发展。目前,使用运筹学、强化学习等优化方法的车间调度系统在生产中有所应用,例如采用神经网络拟合车间调度方案近优解,将Q学习等强化学习方法用于车间调度任务的组合分配规则选取等,这些方法一定程度上缓解了车间调度任务对人工调整的依赖,但是尚未见这些方法应用于供应链任务的调度中。
基于运筹学的优化方法求解效率低,尤其是在大规模问题的应用中,而且运筹学在应用过程中往往对调度问题进行了简化,得到的求解方案难以直接运用于实际生产调度中。以Q学习为代表的强化学习方法采用的是表格型强化学习模型,其在解决调度问题上具有一定的优势。但实际的紧密协作型供应链任务调度过程十分复杂,具有很多扰动,单一的Q学习方法并不能描述实际复杂加工过程。
作为深度神经网络与Q学习算法相结合的DQN算法,解决了传统Q学习算法中的维数灾难问题,但是DQN算法又会存在过估计问题,在实际应用过程中,过估计问题会导致系统输出的Q值不断增大,从而导致模型所获得的奖励值并非最优,直接影响了最优动作策略组的选择。
公日为2020年07月10日,公开号为CN111401616A的中国专利公开了一种供应链环境下预制混凝土构件的双层调度方法,采集生产数据并建立调度问题对应的数学规划模型;将所有的订单进行实数编码随机产生Size个初始解;从初始种群的解中选出目标函数值最大的解作为初始解;对初始解进行订单子集选择;局部搜索初始解,更新局部最优解;满足终止条件后,对当前最优解进行判断和检查检查并更新当前最优解及其对应的目标值;计算得到最优解的总完工时间,重新安排所有已接受的订单,在不影响TNRI值的情况下,对TCT值进行最小化得到最优解;对最优解进行解码,获得调度方案。但是上述方法不能用于紧密协作型供应链任务调度。
发明内容
本发明提供一种基于双深度时序差分神经网络的紧密协作型供应链任务调度方法,优化紧密协作型供应链任务调度过程,并最终得到最优动作策略组。
为解决上述技术问题,本发明的技术方案如下:
一种基于双深度时序差分神经网络的紧密协作型供应链任务调度方法,包括以下步骤:
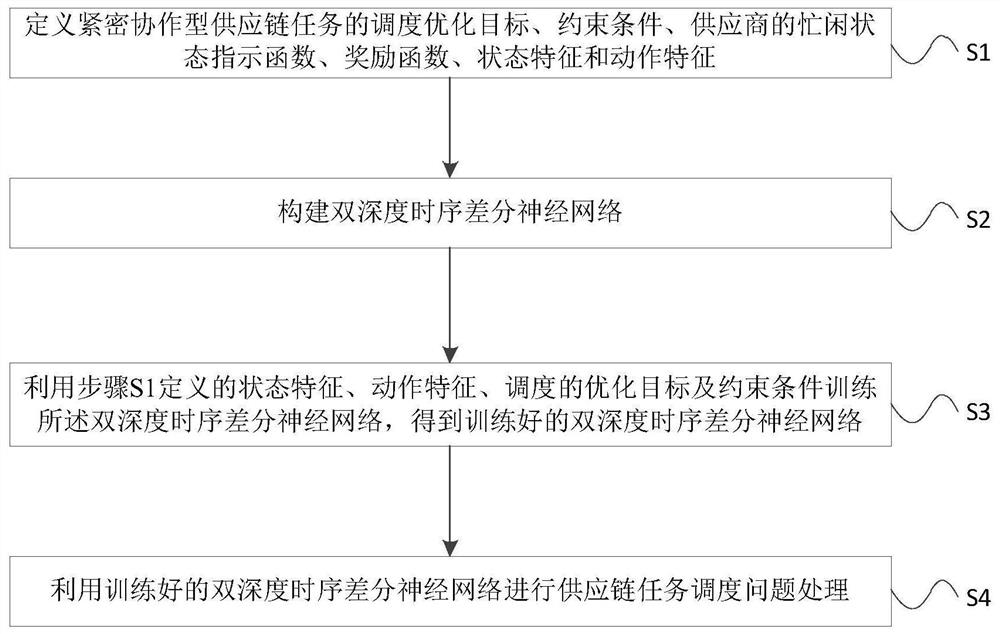
S1:定义紧密协作型供应链任务的调度优化目标、约束条件、供应商的忙闲状态指示函数、奖励函数、状态特征和动作特征;
S2:构建双深度时序差分神经网络;
S3:利用步骤S1定义的状态特征、动作特征、调度的优化目标及约束条件训练所述双深度时序差分神经网络,得到训练好的双深度时序差分神经网络;
S4:利用训练好的双深度时序差分神经网络进行供应链任务调度问题处理。
优选地,步骤S1中所述调度优化目标为:
将待完成供应链订单j(j=1,2,…,n),合理分配于m个供应商组成的加工序列中,尽量减少每个供应商的等待时间,以期达到最小化总供应链订单完成时间;
所述约束条件为:
每个供应链订单的整体加工流程固定,但每个供应商的订单队列的加工顺序可以改变;
每个供应商在每个时刻只能加工一个供应链子订单且不允许中断;
每个供应链订单j都有对应于供应商i(i=1,2,…,m)的供应链子订单加工时间,准备时间包含在加工时间内或忽略不计;
供应商的忙闲状态指示函数σ
奖励函数定义为:
式中,r表示系统在决策时刻t
优选地,步骤S1中所述状态特征定义如下:
f
优选地,步骤S1所述动作特征:
SPT,为选择供应链子订单加工时间最短的供应链订单;
LPT,为选择供应链子订单加工时间最长的供应链订单;
LWKR,为选择剩余加工时间最短的供应链订单;
MWKR,为选择剩余加工时间最长的供应链订单;
SPT/TWK,为选择供应链子订单加工时间与总加工时间比值最小的供应链订单;
LPT/TWK,为选择供应链子订单加工时间与总加工时间比值最大的供应链订单;
SPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最小的供应链订单;
LPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最大的供应链订单;
SPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最小的供应链订单;
LPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最大的供应链订单;
SPT*TWK,为选择供应链子订单加工时间与总加工时间乘积最小的供应链订单;
LPT*TWK,为选择供应链子订单加工时间与总加工时间乘积最大的供应链订单;
SPT*TWKR,为选择供应链子订单加工时间与剩余加工时间乘积最小的供应链订单;
LPT*TWKR,为选择供应链子订单加工时间与剩余加工时间乘积最大的供应链订单;
SRM,为选择除当前考虑供应链子订单外剩余加工时间最短的供应链订单;
LRM,为选择除当前考虑供应链子订单外剩余加工时间最长的供应链订单;
SSO,为选择后继供应链子订单加工时间最短的供应链订单;
LSO,为选择后继供应链子订单加工时间最长的供应链订单;
FCFS,为在队列中仅有一个供应链订单时,采取先到先加工规则,供应链任务的最优调度仅少数供应链子订单顺序的颠倒,因此FCFS是一种常用规则。
优选地,步骤S2中所述双深度时序差分神经网络具体为:
所述双深度时序差分神经网络分为当前神经网络与目标神经网络,将当前状态值输入至当前神经网络中先找出最大价值函数值对应的动作a
每L步触发一次学习标志位,L为人为设定值,进行学习并更新当前神经网络参数,并在每个完整供应链订单结束时更新目标神经网络参数,当前神经网络与目标神经网络拥有相同的网络结构,包括输入层、5层隐藏层和输出层,其loss 计算方式为方差计算,优化器选用RMSPropOptimizer,双深度时序差分神经网络所求的是与下一状态S
优选地,步骤S3中训练所述双深度时序差分神经网络具体为:
S3.1:初始化记忆体内存,输入数据集;
S3.2:设定episode=0;
S3.3:初始化双深度时序差分神经网络参数;
S3.4:模拟供应链任务调度开始t
S3.5:根据ε-贪婪策略通过当前神经网络选择动作a,执行动作将状态切换为t
S3.6:依据动作a,通过目标神经网络计算出t
S3.7:将单步样本(
S3.8:判断是否触发学习标志位,若是,进入步骤S3.9,若不是,进入步骤 S3.10;
S3.9:从记忆体中取出batch_size组样本数据输入至双深度时序差分神经网络,学习并更新当前网络参数;
S3.10:判断是否达到终止状态,若是,进入步骤S3.11,若不是,令n=n+1 后返回步骤S3.4;
S3.11:每个供应链订单结束进行状态转移,替换目标神经网络参数;
S3.12:判断episode是否等于设定的Max_episode,若是,进入步骤S3.13,若不是,返回步骤S3.3;
S3.13:输出最优生产周期对应策略组合,并记录当前神经网络参数。
优选地,步骤S3.1中所述数据集包括供应商个数m、待完成供应链订单数量n及待完成供应链子订单处理时间数据,采集企业历史供应数据,面向产品制造的供应需求定义供应链任务:将供应链任务分解为多个供应链订单,每个供应链订单下包含多个子订单,每个子订单由一个供应商完成,从而完成数据集的构建。
优选地,所述数据集采用参照企业历史供应数据随机生成的方法构建仿真数据集,具体为:
首先以均匀分布的方式随机生成多个供应链订单,并在每个供应链订单下再以均匀分布的方式随机生成多个子订单,之后参照企业历史供应数据,以拟合历史待完成供应链子订单处理时间曲线的方式随机生成对应的子订单处理时间数据集。
优选地,步骤S3中训练双深度时序差分神经网络时,参数更新过程使用 RMSProp优化器和squared_difference loss损失函数,初始学习率为0.001,迭代 1000回合,每隔100回合,学习率变为原来的0.1倍,得到已训练的检测模型。
优选地,步骤S4中利用训练好的双深度时序差分神经网络进行供应链任务调度问题处理,具体为:
针对新的、需要调度的供应链任务,首先进行供应链任务的数据标准化处理,即将新到的供应链任务的供应商个数m、待完成供应链订单数量n及待完成供应链子订单处理时间提取出来,完成标准化供应链调度任务数据的构建,并将构建好的标准化数据输入到已训练好的双深度时序差分神经网络中,利用已训练的双深度时序差分神经网络进行动作选择,得出最优动作策略组;并按照最优动作策略,确定每个供应链订单/子订单的完成时间,从而得到整个供应链任务的总供应商等待时间。
与现有技术相比,本发明技术方案的有益效果是:
本发明针对紧密协作型供应链任务调度问题,提出了基于改进的双深度时序差分神经网络(DDTDN),实现对状态特征和动作特征的半马尔科夫决策过程建模,在仅给定的待完成供应链子订单处理时间的情况下,优化紧密协作型供应链任务调度过程,在只给出待完成供应链子订单处理时间的情况下,利用给定的待完成供应链子订单处理时间,优化供应链任务调度过程,并最终得到最优动作策略组。
附图说明
图1为本发明的方法流程示意图。
图2为实施例中双深度时序差分神经网络模型示意图。
图3为实施例中训练所述双深度时序差分神经网络的流程示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
本实施例提供一种基于双深度时序差分神经网络的紧密协作型供应链任务调度方法,如图1,包括以下步骤:
S1:定义紧密协作型供应链任务的调度优化目标、约束条件、供应商的忙闲状态指示函数、奖励函数、状态特征和动作特征;
S2:构建双深度时序差分神经网络;
S3:利用步骤S1定义的状态特征、动作特征、调度的优化目标及约束条件训练所述双深度时序差分神经网络,得到训练好的双深度时序差分神经网络;
S4:利用训练好的双深度时序差分神经网络进行供应链任务调度问题处理。
步骤S1中所述调度优化目标为:
将待完成供应链订单j(j=1,2,…,n),合理分配于m个供应商组成的加工序列中,尽量减少每个供应商的等待时间,以期达到最小化总供应链订单完成时间;
所述约束条件为:
每个供应链订单的整体加工流程固定,但每个供应商的订单队列的加工顺序可以改变;
每个供应商在每个时刻只能加工一个供应链子订单且不允许中断;
每个供应链订单j都有对应于供应商i(i=1,2,…,m)的供应链子订单加工时间,准备时间包含在加工时间内或忽略不计;
注意到生产周期与供应商忙闲程度紧密相关,供应商的忙闲状态指示函数σ
奖励函数定义为:
式中,r表示系统在决策时刻t
步骤S1中所述状态特征定义如下:
f
将紧密协作型供应链任务的10种状态特征公式化表示,形成每个供应商繁忙程度的判断依据。采用多种特征可以让机器学习效率更优而具有优势。其中,状态特征f
步骤S1所述动作特征:
SPT,为选择供应链子订单加工时间最短的供应链订单;
LPT,为选择供应链子订单加工时间最长的供应链订单;
LWKR,为选择剩余加工时间最短的供应链订单;
MWKR,为选择剩余加工时间最长的供应链订单;
SPT/TWK,为选择供应链子订单加工时间与总加工时间比值最小的供应链订单;
LPT/TWK,为选择供应链子订单加工时间与总加工时间比值最大的供应链订单;
SPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最小的供应链订单;
LPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最大的供应链订单;
SPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最小的供应链订单;
LPT/TWKR,为选择供应链子订单加工时间与剩余加工时间比值最大的供应链订单;
SPT*TWK,为选择供应链子订单加工时间与总加工时间乘积最小的供应链订单;
LPT*TWK,为选择供应链子订单加工时间与总加工时间乘积最大的供应链订单;
SPT*TWKR,为选择供应链子订单加工时间与剩余加工时间乘积最小的供应链订单;
LPT*TWKR,为选择供应链子订单加工时间与剩余加工时间乘积最大的供应链订单;
SRM,为选择除当前考虑供应链子订单外剩余加工时间最短的供应链订单;
LRM,为选择除当前考虑供应链子订单外剩余加工时间最长的供应链订单;
SSO,为选择后继供应链子订单加工时间最短的供应链订单;
LSO,为选择后继供应链子订单加工时间最长的供应链订单;
FCFS,为在队列中仅有一个供应链订单时,采取先到先加工规则,供应链任务的最优调度仅少数供应链子订单顺序的颠倒,因此FCFS是一种常用规则。
构建19个候选行为作为紧密协作型供应链任务的动作特征,后续DDTDN 工作时即依据每个供应商的状态值输入,选择适合当前供应链子订单的行为,以 对供应链订单进行加工
步骤S2中所述双深度时序差分神经网络如图2,它是基于深度强化学习与 TD算法的神经网络模型,具体为:
所述双深度时序差分神经网络分为当前神经网络与目标神经网络,将当前状态值输入至当前神经网络中先找出最大价值函数值对应的动作a
每L步触发一次学习标志位,L为人为设定值,进行学习并更新当前神经网络参数,并在每个完整供应链订单结束时更新目标神经网络参数,当前神经网络与目标神经网络拥有相同的网络结构,包括输入层、5层隐藏层和输出层,具体参数见表1,其loss计算方式为方差计算,优化器选用RMSPropOptimizer,双深度时序差分神经网络所求的是与下一状态S
表1
步骤S3中训练所述双深度时序差分神经网络如图3,具体为:
S3.1:初始化记忆体内存,输入数据集;
S3.2:设定episode=0;
S3.3:初始化双深度时序差分神经网络参数;
S3.4:模拟供应链任务调度开始t
S3.5:根据ε-贪婪策略通过当前神经网络选择动作a,执行动作将状态切换为t
S3.6:依据动作a,通过目标神经网络计算出t
S3.7:将单步样本(
S3.8:判断是否触发学习标志位,若是,进入步骤S3.9,若不是,进入步骤 S3.10;
S3.9:从记忆体中取出batch_size组样本数据输入至双深度时序差分神经网络,学习并更新当前网络参数;
S3.10:判断是否达到终止状态,若是,进入步骤S3.11,若不是,令n=n+1 后返回步骤S3.4;
S3.11:每个供应链订单结束进行状态转移,替换目标神经网络参数;
S3.12:判断episode是否等于设定的Max_episode,若是,进入步骤S3.13,若不是,返回步骤S3.3;
S3.13:输出最优生产周期对应策略组合,并记录当前神经网络参数。
主要包含两层循环,内层循环模拟供应链子订单加工过程,将所得单步样本存入记忆体中,并在学习标志位触发时更新当前神经网络参数;外层循环用来重复执行内层循环,并在每个episode结束时更新进行状态转移,替换目标神经网络参数,并在episode达到设定值Max_Episode时输出最优生产周期对应策略组合,并记录其当前神经网络参数。
步骤S3.1中所述数据集包括供应商个数m、待完成供应链订单数量n及待完成供应链子订单处理时间数据,采集企业历史供应数据,面向产品制造的供应需求定义供应链任务:将供应链任务分解为多个供应链订单,每个供应链订单下包含多个子订单,每个子订单由一个供应商完成,从而完成数据集的构建。
所述数据集采用参照企业历史供应数据随机生成的方法构建仿真数据集,具体为:
首先以均匀分布的方式随机生成多个供应链订单,并在每个供应链订单下再以均匀分布的方式随机生成多个子订单,之后参照企业历史供应数据,以拟合历史待完成供应链子订单处理时间曲线的方式随机生成对应的子订单处理时间数据集。
步骤S3中训练双深度时序差分神经网络时,参数更新过程使用RMSProp 优化器和squared_difference loss损失函数,初始学习率为0.001,迭代1000回合,每隔100回合,学习率变为原来的0.1倍,得到已训练的检测模型。根据验证集的生产流程总供应商等待时间长短选取最合适的模型作为紧密协作型供应链任务调度模型。
步骤S4中利用训练好的双深度时序差分神经网络进行供应链任务调度问题处理,具体为:
针对新的、需要调度的供应链任务,首先进行供应链任务的数据标准化处理,即将新到的供应链任务的供应商个数m、待完成供应链订单数量n及待完成供应链子订单处理时间提取出来,完成标准化供应链调度任务数据的构建,并将构建好的标准化数据输入到已训练好的双深度时序差分神经网络中,利用已训练的双深度时序差分神经网络进行动作选择,得出最优动作策略组;并按照最优动作策略,确定每个供应链订单/子订单的完成时间,从而得到整个供应链任务的总供应商等待时间。
采用双深度时序差分神经网络(DDTDN)算法可以很好的解决DQN算法所带来的过估计问题。在实验中,DQN算法的网络模型输出的估计值比真实函数值大,而且对于不同的状态,过估计幅度还会有所不同,这就直接导致了最优动作策略选择发生改变。在DDTDN中,不再是直接从目标神经网络里面找各个动作中最大特征值,而是先在当前神经网络中先找出最大特征值对应的动作,然后利用这个选择出来的动作在目标神经网络中去计算目标的特征值,这样便很好的解决了DQN算法所带来的过估计问题,提升训练效果与模型的稳定性。
同时,采用带有记忆体的神经网络结构,可以在仅给出待完成供应链子订单处理时间的情况下,预先多次模拟供应链任务加工流程,并将所得单步结果存入记忆体中,当记忆体内存达到一定数量,再一次性取出batch_size组数据用于进行网络训练,提高神经网络学习效率。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 一种基于双深度时序差分神经网络的紧密协作型供应链任务调度方法
- 一种基于深度神经网络的协作频谱共享智能契约设计方法