一种基于GPU加速的2D复杂多边形渲染方法
文献发布时间:2023-06-19 13:46:35
技术领域
本发明涉及计算机图形学领域,特别涉及一种基于GPU加速的2D复杂多边形渲染方法。
背景技术
复杂多边形在绘图类软件(如EDA)中极为常见:用户手绘不够精确,较为容易出现凹多边形,自相交多边形;复杂多边形作为一种矢量图形,其能轻松表达出有洞的多边形;矢量文字天然就是复杂多边。
一般对复杂多边形的渲染有以下三大类型及其缺点:通过CPU使用多边形布尔运算扫描线算法实现全像素的光栅化,比较典型的如浏览器的SVG,对CPU算力要求大,渲染高分辨率场景效率低;通过CPU使用多边形三角化算法,先将多边形拆分成多个三角形,再通过CPU或者GPU光栅化所有三角形,这种方法需要较长的准备时间在CPU侧将多边形三角化;NVIDIA司开发的NV_path_rendering插件,调用NVIDIA显卡专有的功能去实现,不具有通用性。
发明内容
针对现有技术中的上述不足,本发明提供了一种基于GPU加速的2D复杂多边形渲染方法,实现复杂多边形的GPU侧渲染,复杂多边形包括了凹多边形、自相交多边形、含有洞的多边形、多个多边形通过边的方向作为权重规则的复合。
为了达到上述发明目的,本发明采用的技术方案为:
一种基于GPU加速的2D复杂多边形渲染方法,其特征在于,该方法包括以下步骤:
(1)在CPU侧根据多边形的复合规则将多边形顶点简单拆分成多组三角形,并写入GPU数据缓冲区;
(2)根据步骤(1)的分组结果,结合具体的多边形复合规则,控制GPU分多次按相应规则填充模板缓冲;
(3)如果是奇偶规则,直接用模板缓冲的取反规则一次性填充即可;
(4)如果是非0规则,则需要让两组不同法线方向的三角形,使用不同的增长方向填充模板缓冲;
(5)经过步骤(3)、(4),在模板缓冲里非0的像素就是最终需要的渲染结果,可将其直接渲染到屏幕缓冲区,也可以将其渲染到纹理等待进一步处理。
进一步,该渲染方法可以在支持OpenGL ES 2.0的平台实现,不限于台式机、笔记本、服务器、手机、浏览器(WebGL)。
本发明的有益效果为:
可以在支持OpenGL ES 2.0的平台实现,不限于台式机、笔记本、服务器、手机、浏览器(WebGL)等,具有极佳的通用性和性能,实现复杂多边形的GPU侧渲染,复杂多边形包括了凹多边形、自相交多边形、含有洞的多边形、多个多边形通过边的方向作为权重规则的复合。
附图说明
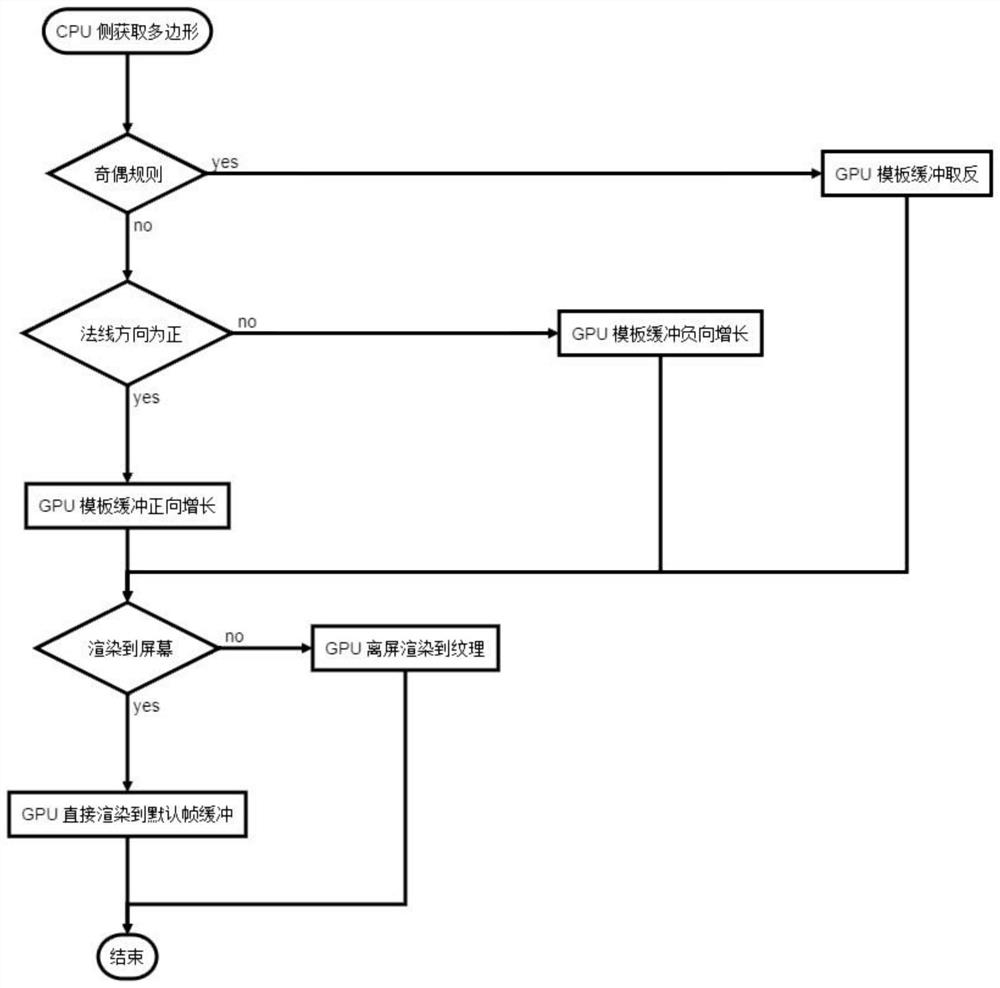
图1为本发明的流程示意图。
具体实施方式
下面结合附图来进一步说明本发明的具体实施方式。其中相同的零部件用相同的附图标记表示。
需要说明的是,下面描述中使用的词语“前”、“后”、“左”、“右”、“上”和“下”指的是附图中的方向,词语“内”和“外”分别指的是朝向或远离特定部件几何中心的方向。
为了使本发明的内容更容易被清楚地理解,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
如图1所示,一种基于GPU加速的2D复杂多边形渲染方法,该方法包括以下步骤:
(1)在CPU侧根据多边形的复合规则将多边形顶点简单拆分成多组三角形,并写入GPU数据缓冲区;
(2)根据步骤(1)的分组结果,结合具体的多边形复合规则,控制GPU分多次按相应规则填充模板缓冲;
(3)如果是奇偶规则,直接用模板缓冲的取反规则一次性填充即可;
(4)如果是非0规则,则需要让两组不同法线方向的三角形,使用不同的增长方向填充模板缓冲;
(5)经过步骤(3)、(4),在模板缓冲里非0的像素就是最终需要的渲染结果,可将其直接渲染到屏幕缓冲区,也可以将其渲染到纹理等待进一步处理。
该渲染方法可以在支持OpenGL ES 2.0的平台实现,不限于台式机、笔记本、服务器、手机、浏览器(WebGL)。
以上所述仅为本发明专利的较佳实施例而已,并不用以限制本发明专利,凡在本发明专利的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明专利的保护范围之内。
- 一种基于GPU加速的2D复杂多边形渲染方法
- 一种基于GPU加速的2D视频转3D视频系统及方法