一种基于Rasa的多渠道应答的智能客服
文献发布时间:2023-06-19 18:29:06
技术领域
本发明涉及计算机软件应用技术领域,特别涉及一种基于Rasa的多渠道应答的智能客服。
背景技术
目前,智能商服服务领域,rasa智能应答能力很大程度地解决了人工客服成本高,无法24小时在线回复的问题。目前市场上的rasa智能应答装置,多使用相对位置编码的transformer模型定义对话模式,使用ALBERT预训练模型分析量化矩阵,Bi-LSTM模型和softmax模型进行语句分析输出实体信息和用户意图。由于RASA系统的数据库需要存储和比对大量信息,故对系统的CPU和GPU要求非常高,易出现系统崩盘现象。
发明内容
本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于Rasa的多渠道应答的智能客服,解决RASA智能服务装置中系统存储量大,高并发的问题,并提供一种对数据库模型简易化维护方式,维护人员不需要学习Rasa也能完成自然语言模型的训练和维护工作。
本发明提供了如下的技术方案:
本发明提供一种基于Rasa的多渠道应答的智能客服,包括以下步骤:
S1、问题库构建,使用DEC文本聚类算法对文本语料数据进行粗聚类:第一步,使用jieba分词算法对文本数据进行分词处理,根据分词结果构建文本的数据空间X;第二步,使用堆叠自编码器来无监督学习数据在特征空间的表示,用来将数据空间X映射至特征空间Z;在获得初始化的特征空间Z后,使用标准的k-means算法聚类来获得k个初始化簇中心;第三步,使用t分布计算特征空间Z中的节点与簇中心的相似度,然后通过辅助分布来进一步使各个簇更加内聚,最终完成文本数据聚类;聚类完成后,由运营人员对每一类的文本数据贴上业务类型标签得到一个较为粗略的问题库;然后,运营人员还需要更进一步地校验聚类算法可能导致的业务类型边界不清晰或聚类错误问题,最终得到一个业务类型边界明确、语料数据归类正确的可用的问题库;
S2、问题库同步与维护,问题库构建完成后,通过http请求将问题库数据以json格式同步传送至Rasa端,在Rasa端进行数据解析;在Rasa侧,以问题库中业务问题标准问作为Rasa中的意图标签,业务问题标准问及其相似问作为对应标签下的训练语料数据,由程序自动生成Rasa训练模型所需要的yaml代码文件;业务人员可以通过增加、删除、修改系统问题库实现对Rasa训练数据的修改;
S3、模型训练,运行服务器通过定时任务和http请求每10分钟向训练服务器发出请求,若训练服务器最新模型与运行服务器一致则不更新模型,反之运行服务器下载最新的模型并重新启动Rasa;
S4、运行分离,运行服务器采用负载均衡策略分发灵犀系统请求,同时每个运行节点使用Sanic异步web框架多进程启动模型;首先创建一个web服务的入口类Sanic;然后使用app.get()方法定义一个用于接收系统访客问题的接口,在接口中解析系统传入的参数;最后将解析得到的访客问题文本和访客id传入Rasa模型做意图判断,得出结果后由接口将用户id和用户意图返还给系统;
S5、问题库订购,访客在登录系统后输入的文本问题通过http请求传入Rasa运行服务器,Rasa模型进行业务意图判断之后将判断结果返回系统;系统结合访客的渠道信息和意图结果,查询该渠道是否订购该业务问题,若订购则按照设置的答案回复访客,若未订购则回复无法理解访客的问题。
与现有技术相比,本发明的有益效果如下:
1、本发明将模型训练和模型运行的服务器进行分离、利用负载均衡策略,降低了系统的高负荷问题;
2、本发明程序自动生成Rasa训练模型所需要的yaml代码文件,业务人员可自行修改问题库,来进行问题库的维护,无须学习rasa基础。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
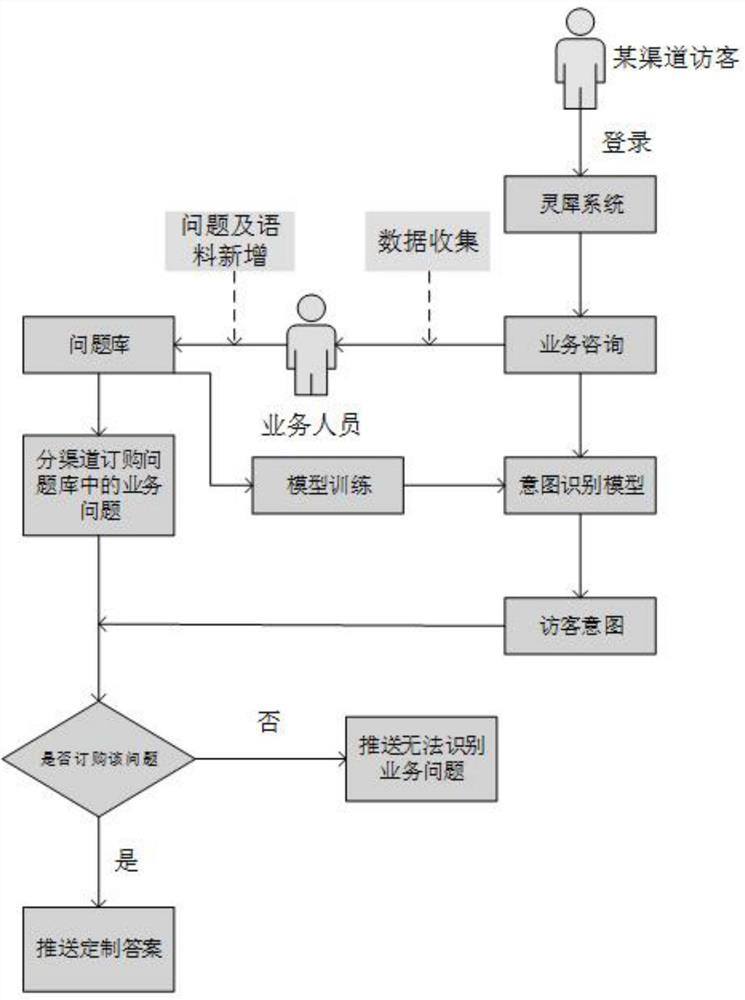
图1是本发明的整体流程示意图;
图2是本发明的问题库构建流程示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
实施例1
如图1-2,本发明提供一种基于Rasa的多渠道应答的智能客服,包括以下步骤:
S1、问题库构建,使用DEC文本聚类算法对文本语料数据进行粗聚类:第一步,使用jieba分词算法对文本数据进行分词处理,根据分词结果构建文本的数据空间X;第二步,使用堆叠自编码器来无监督学习数据在特征空间的表示,用来将数据空间X映射至特征空间Z。在获得初始化的特征空间Z后,使用标准的k-means算法聚类来获得k个初始化簇中心;第三步,使用t分布计算特征空间Z中的节点与簇中心的相似度,然后通过辅助分布来进一步使各个簇更加内聚,最终完成文本数据聚类。聚类完成后,由运营人员对每一类的文本数据贴上业务类型标签得到一个较为粗略的问题库。然后,运营人员还需要更进一步地校验聚类算法可能导致的业务类型边界不清晰或聚类错误问题,最终得到一个业务类型边界明确、语料数据归类正确的可用的问题库;
S2、问题库同步与维护,问题库构建完成后,通过http请求将问题库数据以json格式同步传送至Rasa端,在Rasa端进行数据解析。在Rasa侧,以问题库中业务问题标准问作为Rasa中的意图标签,业务问题标准问及其相似问作为对应标签下的训练语料数据,由程序自动生成Rasa训练模型所需要的yaml代码文件。业务人员可以通过增加、删除、修改系统问题库实现对Rasa训练数据的修改;
S3、模型训练,运行服务器通过定时任务和http请求每10分钟向训练服务器发出请求,若训练服务器最新模型与运行服务器一致则不更新模型,反之运行服务器下载最新的模型并重新启动Rasa;
S4、运行分离,运行服务器采用负载均衡策略分发灵犀系统请求,同时每个运行节点使用Sanic异步web框架多进程启动模型。首先创建一个web服务的入口类Sanic。然后使用app.get()方法定义一个用于接收系统访客问题的接口,在接口中解析系统传入的参数。最后将解析得到的访客问题文本和访客id传入Rasa模型做意图判断,得出结果后由接口将用户id和用户意图返还给系统;
S5、问题库订购,访客在登录系统后输入的文本问题通过http请求传入Rasa运行服务器,Rasa模型进行业务意图判断之后将判断结果返回系统。系统结合访客的渠道信息和意图结果,查询该渠道是否订购该业务问题,若订购则按照设置的答案回复访客,若未订购则回复无法理解访客的问题。
进一步的,目前该发明运用于翼支付的灵犀系统上,对C端客户提供24小时在线的文本应答服务,应答时效在1s内,大量降低了客服人员的工作量。
本发明中其技术要点如下所示:
1、本发明应用DEC文本聚类算法、jieba分词算法、k-means算法聚类相结合的语意解析工具而组成的精准的rasa应答装置;
2、使用Sanic异步web框架多进程启动模型实现多渠道应答,将模型训练和模型运行的服务器进行分离、利用负载均衡策略,降低系统并发性。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种智能客服应答方法、装置、智能客服应答系统及计算机可读存储介质
- 一种基于智能客服业务的应答响应方法及系统