一种面对工程应用的机器学习模型可靠性评估方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于土木工程与计算机交叉领域,特别是指一种面对工程应用的机器学习模型可靠性评估方法。
背景技术
随着人工智能的高速发展,作为其核心的机器学习在越来越多的领域展现出独特价值。机器学习是一种从已有数据中学习其内在规律,并利用所学规律去对未知的数据进行预测分析的算法,常用的机器学习算法有随机森林、神经网络、支持向量机、GBDT等。当前,工程技术领域也开始逐渐引入机器学习算法解决问题。操作步骤通常为:首先将已有数据集划分为训练集与测试集,然后利用训练集对机器学习模型进行训练,最后将测试集数据放入训练好的模型中进行测试,进而评价该模型的准确性。不难发现机器学习所用训练集与测试集全是源自具有相似分布的标签数据集,尽管通过测试集得出模型的预测准确率很高,但由于机器学习模型属于黑箱模型,实际工程中,基于训练好的模型对前方环境与测试条件均未知的复杂工程进行预测,其结果可靠性存疑。使得机器学习模型难以真正用于解决现实生活中的工程挑战。
在此背景下本发明重点关注机器学习模型对复杂工程场景中结果未知的样本集进行预测时结果可靠性的量化评估,可有效推动机器学习方法在实际工程中落地应用。
发明内容
本发明针对实际工程现场对机器学习算法预测结果的可靠性存疑,致使机器学习方法无法落地应用的问题,提供一种面对工程应用的机器学习模型可靠性评估方法。
本方法背后的基本原理在于:模型的预测可靠性与训练集的数据空间相关,训练集的数据空间越大,则意味着模型能够学到的数据内在规律越多,将该模型对未知的数据进行预测时,所得结果距离真实值越近。由于机器学习模型需要用于训练的参数数量很大,但训练过程中的目标函数通常只有一个,因而只要这些训练参数的初始值不一样,训练后的机器学习模型也都互不相同。因此当用训练集、超参数相同但随机种子不同的多个模型分别进行预测时,若多个模型的预测结果均十分接近并收敛于某值,则表明预测结果靠近真值,预测结果具有一定的可靠性。反之若预测结果离散,则表明这些机器学习模型并未真正学到相关的规律和知识,该预测结果不具有可靠性。本发明采用如下技术方案:
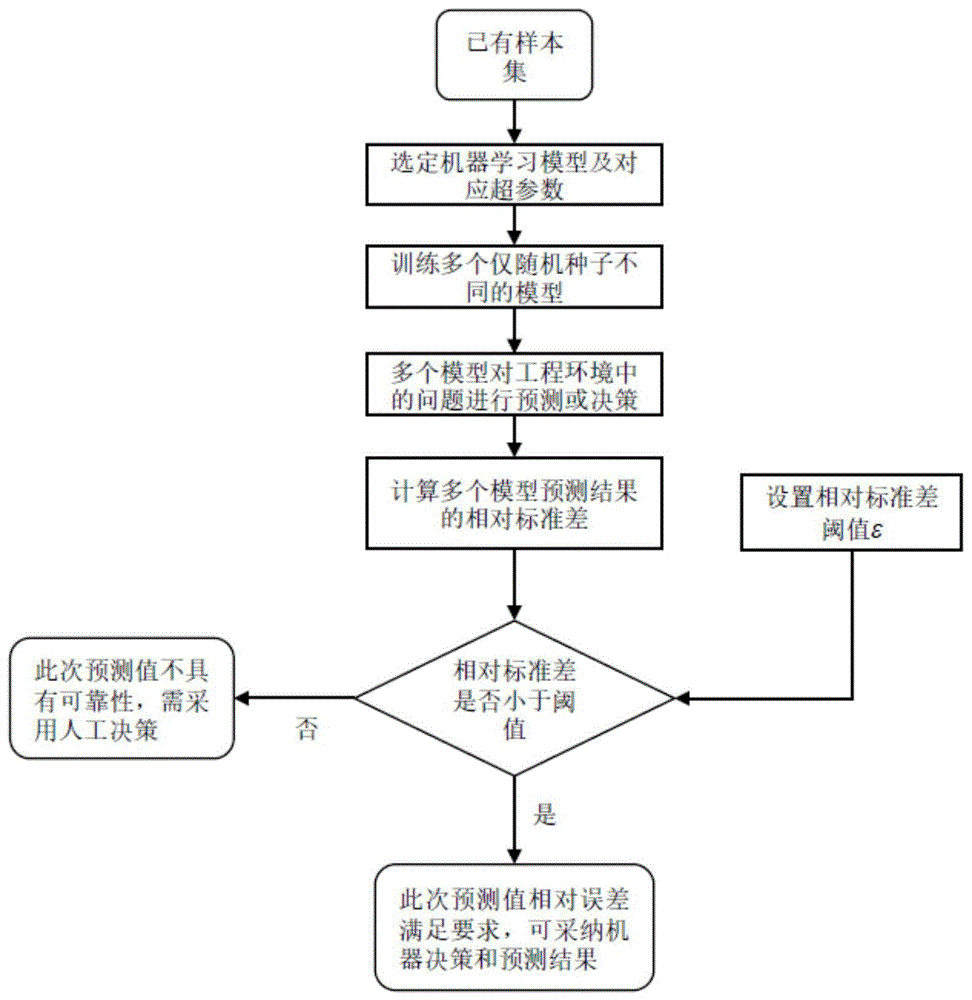
一种面对工程应用的机器学习模型可靠性评估方法,包括:
步骤1,通过已有样本集进行机器学习,选定机器学习模型及对应的超参数,训练多个仅随机种子不同的初始模型;
步骤2,采用步骤1中不同模型分别对复杂工程环境中的问题进行预测或决策;
步骤3,计算步骤2中多个模型预测结果的相对标准差;
步骤4,将阈值设置为ε,当工程场景中预测结果的相对标准差低于设定阈值时,可认为步骤1中模型针对步骤2中工程问题的预测结果具有可靠性,即机器学习模型的预测可信,该问题可相信机器决策;
步骤5,若机器学习模型预测结果的相对标准差高于设定阈值,则认为机器预测结果不具备参考价值,该问题需要人工决策。
进一步地,步骤1中,针对所选择模型对应的超参数,设置每一个超参数的取值范围,随后利用优化模型进行最优超参数组合选择。
进一步地,步骤1中,训练的多个初始模型,应当已经在初始数据集上进行了充分训练,并获得了较高的预测水准。
进一步地,步骤1中,训练的初始模型的数目应不少于3个。
进一步地,步骤1中,在模型训练前需将待训练的参数设置为不同的随机状态,其他所有的模型结构,训练数据和超参数均相同。
进一步地,步骤3中,相对标准差的计算公式为:
式中:RSD为样本相对标准差,σ为样本的标准差,μ为样本多个预测值的平均值。
进一步地,步骤4中,设定的阈值应该根据具体工程问题的属性和精度要求来决定。
进一步地,所述的无监督式评估方法适用于训练参数多于目标函数数量的各类机器学习模型。
附图说明
图1为本发明方法的实施流程图;
具体实施方式
为使本发明更易于理解,下面结合本发明的实施例和附图进行详细阐述,以本发明的技术方案为依据,给出了具体的实施过程,对本发明的技术方案作进一步解释说明。
在本实施例中,针对实际工程现场对机器学习算法预测结果存疑,致使机器学习方法无法落地应用的问题,提供一种面对工程应用的机器学习模型可靠性评估方法。
本方法背后的基本原理在于:模型的预测可靠性与训练集的数据空间相关,训练集的数据空间越大,则意味着模型能够学到的数据内在规律越多,将该模型对未知的数据进行预测时,所得结果距离真实值越近。由于机器学习模型需要用于训练的参数数量很大,但训练过程中的目标函数通常只有一个,因而只要这些训练参数的初始值不一样,训练后的机器学习模型也都互不相同。因此当用多个训练集、超参数相同但随机种子不同的模型分别进行预测时,若多个模型的预测结果均十分接近并收敛于某值,则表明预测结果靠近真值,预测结果具有一定的可靠性。反之若预测结果离散,则表明这些机器学习并未真正学到相关的规律和知识,该预测结果不具有可靠性。
图1是本实施例中面对工程应用的机器学习模型可靠性评估方法流程图。
如图1所示,本实施例所涉及的面对工程应用的机器学习模型可靠性评估方法包括以下步骤:
步骤S1:将盾构掘进工程中已有的盾构掘进数据作为已有样本集,机器学习模型选用随机森林,在确定了针对该问题的随机森林最佳超参数后,利用该样本集训练3个仅随机种子不同的随机森林初始模型,分别为模型A,模型B,模型C。
采用面对工程应用的机器学习模型可靠性评估方法,在确定使用随机森林算法后,通过贝叶斯优化算法选出最优超参数组合选择,具体为max_depth=9,min_samples_leaf=1,min_samples_split=3,n_estimators=93。
所训练的初始模型,已经在初始数据集上进行了充分训练,并获得了较高的预测水准。
所训练的初始模型的数目不少于3个。
在模型训练前将三个模型的随机种子random_state分别设置为1、2、3,其他所有的模型结构,训练数据和超参数均相同。
步骤S2:利用模型A、B、C对盾构机下一步操作和控制进行预测和决策,可得预测结果分别为a、b、c。
步骤S3:将a、b、c进行相对标准差计算,得到相对标准差RSD。
相对标准差RSD的计算公式为:
式中:RSD为样本相对标准差,σ为样本的标准差,μ为样本多个预测值的平均值。
步骤S4:设置阈值为0.05,并与步骤S3中相对标准差进行比较,若该相对标准差低于设定阈值时,可认为步骤S1中模型针对步骤S2中盾构机操作与控制的预测结果具有可靠性,即机器学习模型的预测可信,该问题可相信机器决策。
此步骤中所设置阈值满足盾构工程中的属性和精度要求。
步骤S5:若步骤S3中相对标准差高于该阈值,则认为机器预测结果不具备参考价值,该问题需要人工决策。
- 一种面向大规模机器学习系统的机器学习模型训练方法
- 一种专家模型与机器学习模型融合的小商户信用评估方法
- 一种基于XGBoost机器学习的核反应堆内螺栓可靠性评估方法