面向局部视觉建模的图像描述生成方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及图像描述生成方法,尤其是涉及一种基于面向局部视觉建模的图像描述生成方法。
背景技术
图像描述是一项为给定图片生成一个流畅的描述性句子的任务。近年来,图像标注领域在一系列创新性方法以及数据集的支持下得到快速发展。由于自下而上的自注意力机制([1].P.Anderson,X.He,C.Buehler,et al.Bottom-up and top-down attention forimage captioning and visual question answering.Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2018:6077-6086)取得巨大成功,现在大多数的图像描述任务都采用目标检测器提取的区域特征作为视觉表示,比如:Faster R-CNN([2].S.Ren,K.He,R.Girshick,etal.Faster r-cnn:towards real-timeobject detection with region proposal networks.IEEE transactions on patternanalysis and machine intelligence.2016:1137-1149)。由于检测器通常在大规模密集数据集上预训练([3].R.Krishna,Y.Zhu,O.Groth,et al.Visual genome:Connect-inglanguage and vision using crowdsourced dense image annotations.IJCV.2017:32-73.),所以它可以对图像中的显著性区域生成判别表示,描述完整的对象信息。
发展至今,区域特征为图像描述任务的发展做出重要的贡献([4].Y.Pan,T.Yao,Y.Li,et al.X-linear attention networks for image captioning.Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition.2020:10971-10980.)。然而,区域特征仍然存在明显的缺陷。首先,这些特征是同图像中的显著性区域提取处理的,因此通常会忽略上下文信息。此外,预先预先训练好的目标检测器经常存在噪声、交叠或者错误检测的问题,这将会限制图像描述的性能上限。
为了解决上述限制,近期的研究转向网格特征的使用,将网格特征应用到目标检测器提高视觉问答性能([5].M.Cornia,M.Stefanini,L.Baraldi,et al.Meshed-memorytransformer for image captioning.Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition.2020:10578-10587)。RSTNet([6].L.Huang,W.Wang,J.Chen,X.-Y.Wei.Attention on attention for imagecaptioning.Proceedings of the IEEE international conference on computervision,2019:4634-4643.)和DLCT([7].H.Jiang,I.Misra,M.Rohrbach,et al.In defenseof grid features for visual question answering.Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition,2020:10267-10276.)将网格特征引入类Transformer网络中,并且在图像标注中取得不错的表现。但是,这些类Transformer的架构不利于完整的目标识别。最近的研究表明,传统Transformer在局部视觉建模中效率较低([8].X.Zhang,X.Sun,Y.Luo,et al.Rst-net:Captioning withadaptive attention on visual and non-visual words.Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.2021:15465-15474.)。因此,仅仅将自注意引入模型,网格特征的依赖性不足以进行局部视觉识别,由此导致标注性能次优。
发明内容
本发明的目的是针对传统Transformer在网格特征的局部视觉建模中破坏原始二维空间网格特征的局部关系,并且标注效率较低的缺点,考虑从层内交互跨感受野感知局部信息,并且增强每个网格与其相邻网格之间的交互,层间融合实现跨层级的语义互补,提供一种基于网格特征局部视觉建模的Transformer的图像描述生成方法。
本发明包括以下步骤:
1)模型输入特征在编码器模块通过多头自注意力模块(MSA)细化特征提取;
2)用局部敏感性注意力(LSA)获取到的注意力权重矩阵对多头自注意力模块(MSA)输出的特征重新加权,将相邻网格之间的依赖关系细化;
3)用前馈神经网络(FFN)实现通道域的互动,建立通道域上视觉特征的联系;
4)用空间偏移操作将网格与其相邻的网格对齐,获取偏移后的特征表示;
5)将偏移后的特征表示聚合后使用多层感知机(MLP)实现视觉特征在通道域和空间域的互动;
6)融合后的特征输出加权后与顶层编码器的输出加总,得到输入解码器的融合的视觉特征表示。
本发明具有以下突出优点:
1)本发明克服传统Transformer结构中的Self-Attention在捕捉网格特征的局部细节中效率缺失的缺点,重点研究具有网格特征的局部视觉建模问题,并提出一种新的用于图像标注的LSTNet。LSTNet不仅提高局部视觉信息的标注质量,而且在竞争激烈的MS-COCO基准测试中,它的性能优于最近提出的一系列方法。
2)本发明通过在Transformer的encoder层内加入局部敏感性注意力模块,对多头自注意力输出的特征重新参数化,使得每个网格特征及其相邻网格特征实现交互,在encoder层建立通道域层面的视觉特征联系。
3)本发明解决decoder的输入仅涉及encoder的顶层输出导致的底层特征信息丢失的问题,通过在encoder和decoder之间加入局部敏感性融合模块将所有encoder的输出进行融合,从而达到聚合图像标注层间语义信息,防止模型运行过程中的信息丢失的目的,这有助于层间语义理解。
附图说明
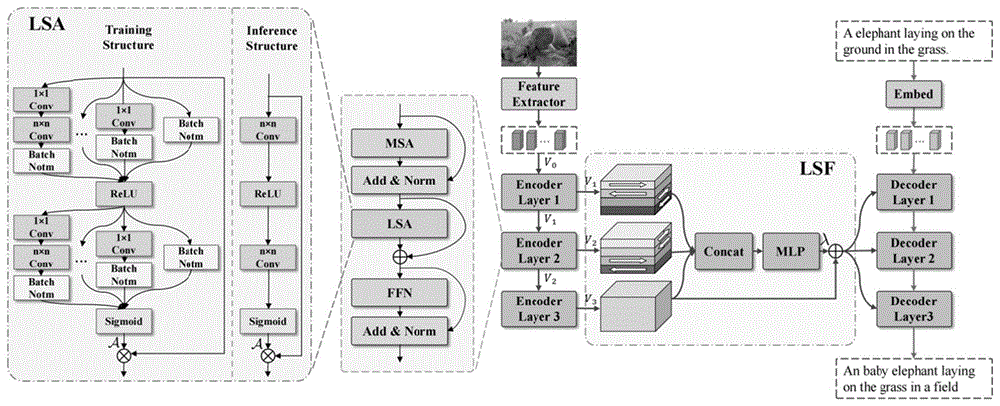
图1为面向局视觉建模的图像描述生成方法的流程图;
图2为空间偏移操作的流程图;
图3为标准Transformer和本发明方法对于输入图片生成描述质量展示;
图4为标准Transformer和本发明方法对于输入图片生成描述的效果展示。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
本发明的目的是针对传统Transformer在网格特征的局部视觉建模中破坏原始二维空间网格特征的局部关系,并且标注效率较低的问题,考虑从层内交互跨感受野感知局部信息,并且增强每个网格与其相邻网格之间的交互,层间融合实现跨层级的语义互补,提出一种基于网格特征局部视觉建模的Transformer的图像标注生成方法。具体的方法流程如图1所示。
具体的每个模块如下:
1、局部敏感性注意力模块LSA
多头注意力模块MSA输出网格序列特征是
其中,σ(·)表示激活函数,MSC
其中i∈{1,2},N是分支数量,BN
模型训练过程使用多分支结构的MSC
MSC
其中,F
使用Sigmoid函数对卷积层的输出正则化,获得每个网格的权重,最后根据LSA得到的权重映射对MSA的输出V重新加权,如下所示:
其中,
2、Encoder模块
LSTNet中的每一个encoder包含三个组成部分,包括:多头自注意力模块MSA、局部敏感性注意力模块LSA以及前馈神经网络FFN。V
V′
其中,MSA(·)是Transformer中标准的多头自注意力模块,LN(·)表示归一化处理。MSA的输出特征使用LSA捕捉V′
V″
将LSA的输出喂入FFN,实现通道域之间的互动,如下所示:
V
其中FFN的表达式如下所示:
FFN(x)=max(0,xW
与传统的Transformer模型不同,本发明在encoder的输出喂入decoder之前,加入局部敏感性融合模块LSF,通过融合所有的编码器层的视觉特征,避免底层encoder的语义信息和特征信息丢失,从而通过LSF获得了丰富的语义特征:
V
3、局部敏感性融合模块LST
不同层的特征趋向于包含不同层面的语义信息,现存的很多图像标注方法只将encoder最顶层提取的特征喂入decoder,导致底层特征信息丢失,为避免这种信息损失,本发明将encoder中所有层级的特征进行融合,并将融合后的特征喂入decoder。
通过引入简单的空间偏移操作,将每个网格与其相邻的网格对齐,从而使多层感知机不仅可以在通道域互动,而且可以实现在空间域上互动,使用不同的空间偏移操作的第1和第2个encoder层分别由公式(10)、(11)表示:
第l层encoder用V
将来自不同层的偏移特征串联在一起,从而实现多层特征融合,如下所示:
V
通过空间偏移操作将每个网格和他相邻的网格对齐,解决多层感知机不能对邻近网格建立关系的问题,即多层感知机实现通道域和空间域的对话:
σ(·)是ReLU激活函数,
为了进一步增强视觉特征的描述能力,融合后的特征输出加权后与顶层encoder的输出加总,如下所示:
V
具体实验结果如下:
表1总结SOTA模型和本发明在COCO数据集上线上测试的性能比较。本发明在所有方法指标上都显著优于其他SOTA方法,并且与其他方法相比有非常大的性能提升。特别的,使用ResNeXt-101的LSTNet模型比使用ResNeXt-152的RESNet模型以及使用SENet-154的X-Transformer模型表现更好。
表1.本发明和其他SOTA方法二点线上性能对比
表2总结SOTA模型和本发明在COCO数据集上线下测试的性能比较。总体来说,本发明在不使用任何集成技术的情况下报告单个模型的结果,大多数指标表现出比其他模型更好的性能。此外,本发明的CIDEr分数为134.8%,表明本发明达到迄今为止最好的性能,与DLCT相比提高了1.0%。
表2.本发明和其他SOTA方法的线下性能对比
表3.本发明和其他SOTA方法基于同种视觉特征的性能对比
表3总结与在相同的视觉特征上,本发明和其他SOTA方法的性能比较。为了消除不同视觉特征的干扰,在相同的网格特征上进行实验,以比较LSTNet和其他SOTA方法,总体来说,提出的LSTNet在所有指标上仍然取得优越的性能。
图3展示了定性评估LSTNet生成的结果,通过可视化描述生成期间视觉特征的每个网格的贡献。从图中可以看出本发明提出的LSTNet可以在生成像“椅子”和“雨伞”这样的信息性单词时专注于正确的网格,即我们提出的LSA和LSF模块通过本地交互和融合为解码器提供更丰富和更细粒度的视觉特征,帮助模型始终关注图像标注的正确区域。
图4定性地验证LSTNet的有效性,展示了由Transformer和LSTNet在相同网格特征上生成的几个典型标注示例。我们可以观察到,Transformer生成的字幕通常甚至是错误的,而LSTNet生成的字幕更准确和可区分,这表明LSA和LSF有助于通过局部建模识别视觉对象。从图上可以看出Transformer生成的注意力图未能关注图像中的重要视觉对象,而LSTNet能够关注重要的视觉对象。而且Transformer只能关注图像中的一个对象或小区域,而LSTNet将关注更多的对象,从而生成准确和详细的描述。从图四中可以看到我们提出的LSA迫使模型不仅关注图像中的重要信息,而且关注图像中全面的信息。
- 一种面向图像匹配的局部灰度直方图特征描述子建立方法和图像匹配方法
- 基于视觉词汇和局部描述符的胶囊内镜图像检索方法