一种基于合作夏普利值的联邦学习激励方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及一种联邦学习中的激励机制,特别是涉及一种跨设备联邦学习中基于夏普利值的高效激励机制。
背景技术
在分布式机器学习框架联邦学习中,客户使用他们的本地数据(隐私敏感)来训练本地局部模型。这些模型将被传递到服务器端并在服务器端进行聚合,从而得出一个全局模型,并下发给各个客户。上述过程会迭代直到全局模型收敛。客户的数量和客户数据的质量都会显著影响最终模型的性能。客户会因为以下原因不愿参与联邦学习。首先,参与联邦学习会给客户带来巨大的计算和通信开销,特别是当客户为像手机这样的低端移动设备时。其次,尽管联邦学习可以保证客户训练数据的私密性,但本地局部模型也可能被用来推断他们的本地数据,威胁到客户的隐私。因此,设计一种激励机制进行公平的贡献评估以及酬劳分配来吸引客户进行训练是非常重要的。
夏普利值是合作博弈理论中的一个经典概念,它可以在联盟之间公平分配利润。现有的基于夏普利值的方案有以下不足。首先,计算夏普利值的时间复杂度是客户数目的指数级别。在跨设备联邦学习中会带来巨大的计算开销。第二,不可或缺的客户可能会被错误地分配到负的夏普利值,特别是在数据非独立同分布的情况下。这是因为直接使用损失函数或准确度作为特征函数不满足作为必要条件的超可加性。第三,不能适应跨设备联邦学习每轮训练中客户的动态变化。现有的方法要求客户自始至终参与训练且不能及时得到他们的酬劳,不完全适用于跨设备联邦学习。
设计高效,公平,适用于跨设备联邦学习的激励机制,是本领域技术人员致力于解决的难题。
发明内容
本发明的目的是:提供一种计算开销小、酬劳分配公平、适应客户动态变化的联邦学习激励机制框架。
为了达到上述目的,本发明的技术方案是提供了一种基于合作夏普利值的联邦学习激励方法,其特征在于,使联邦学习的每一轮全局迭代成为一个单阶段的合作博弈,客户在任何一轮都能够加入或退出训练,同时,服务器能够在每次模型更新后直接分配酬劳,整个训练过程被建模为一个多次单阶段的合作博弈框架,设有n个客户C={c
步骤1、服务器公布这一轮的预算B
步骤2、服务器从所有客户中随机选择一些客户参与本轮训练,每个被选中的客户c
步骤3、客户c
步骤4、服务器从客户上传的本地梯度中构建所有可能联盟
步骤5、服务器计算每个联盟的价值V(S)=L(W
步骤6、服务器计算每个客户的合作夏普利值,然后按比例分配数据价值费,如下式所示:
式中:BV
步骤7、服务器通过加权平均汇总所有客户上传的本地梯度,得到全局梯度Δ
步骤8、服务器更新全局模型:W
优选地,步骤1中,每一轮的预算由参与费BP以及数据价值费BV组成。
优选地,步骤6中,所述第i个客户的夏普利值
式中,j为联盟S中的的一个客户,D
优选地,步骤6中,将全部客户分为K类C={C
式中,⊥表示互质。
优选地,在客户持有非独立同分布数据的情况下,客户能够被分为K类,每个类中的客户的数据都属于同一分布,使用k均值聚类来进行基于客户上传的梯度的聚类。
本发明提出了一种新的方法来评估联邦学习中客户的贡献。本发明利用基于客户类型的紧凑表示,将贡献评估的计算成本从指数级降低到多项式级。本发明引入了合作夏普利值来消除非独立同分布数据分布情况下的负夏普利值。本发明能够适应参与者的频繁变化,并且比现有的方法更有效率和公平。
附图说明
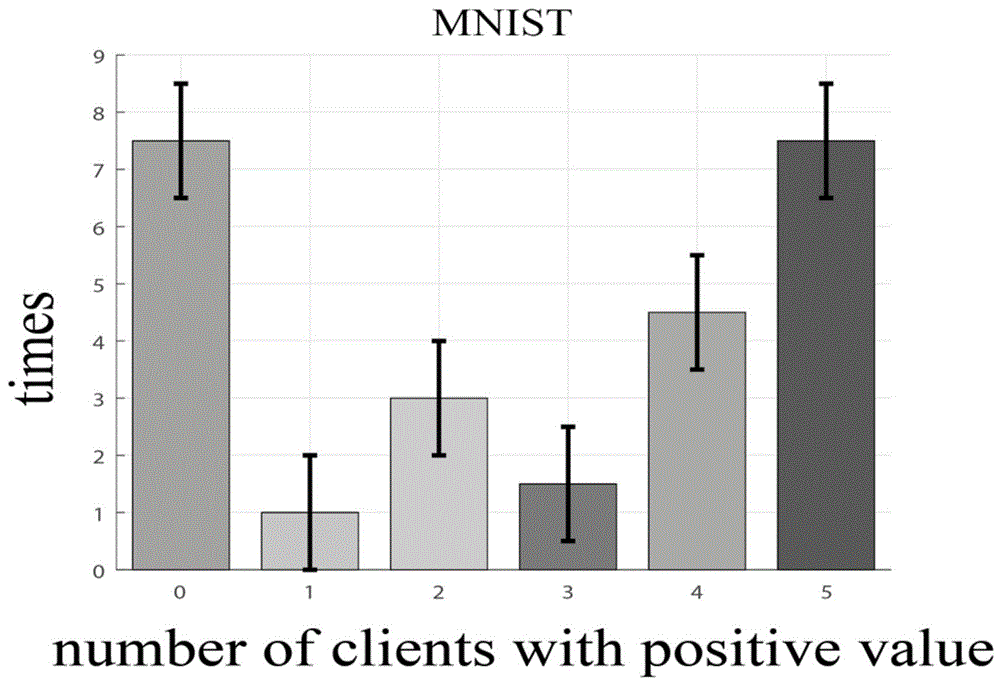
图1为MNIST数据集中夏普利值为正值的客户数量直方图;
图2为CIFAR10数据集中夏普利值为正值的客户数量直方图;
图3为FMNIST数据集中夏普利值为正值的客户数量直方图;
图4为近似计算夏普利值的准确率和时间开销的实验结果图;
图5为MNIST数据集中客户种类数对近似计算夏普利值的准确率和时间开销的影响结果图;
图6为CIFAR10数据集中客户种类数对近似计算夏普利值的准确率和时间开销的影响结果图;
图7为FMNIST数据集中客户种类数对近似计算夏普利值的准确率和时间开销的影响结果图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本实施例公开了一种基于合作夏普利值的联邦学习激励方法分为四个部分:1、多次单阶段合作博弈框架:将联邦学习的每一轮都全局迭代当作一次独立的单阶段合作博弈,构建多次单阶段合作博弈框架。2、合作夏普利值:基于持有非独立同分布的客户无法拿到合理的报酬这一观察,修改夏普利值。3、基于客户类别的紧凑表达:基于同类客户夏普利值相近的观察,使用紧凑表达降低计算复杂度。4、客户聚类:基于同类客户梯度相近的观察,将客户聚类。本发明具体包括以下内容:
第一部分:多次单阶段的合作博弈框架
该部分,我们使联邦学习的每一轮全局迭代成为一个单阶段的合作博弈,这允许客户在任何一轮都可以加入或退出训练。同时,服务器可以在每次模型更新后直接分配酬劳。因此,整个训练过程被建模为一个多次单阶段的合作博弈框架。
该多次单阶段的合作博弈框架主要适用于横向联邦学习,处理客户数据服从非独立同分布的情况。在横向联邦学习中,有n个客户C={c
总共有T轮的全局迭代,每一轮迭代t∈{1,2,...,T}包括以下步骤:
步骤一:服务器公布了这一轮的预算B
步骤二:服务器从所有客户中随机选择一些客户参与本轮训练。每个被选中的客户c
步骤三:客户c
步骤四:服务器从客户上传的本地梯度中构建所有可能联盟
步骤五:服务器计算每个联盟的价值V(S)=L(W
步骤六:服务器计算每个客户的夏普利值,然后按比例分配数据价值费,如下式所示:
式中:BV
步骤七:服务器通过加权平均汇总所有客户上传的本地梯度,得到全局梯度Δ
步骤八:服务器更新全局模型,如下式所示:
W
第二部分:合作夏普利值
对于一个数据分布与验证集不同的客户,即使他有高质量的数据,原始夏普利值也会给他们分配负值。在联邦学习中,客户持有非独立同分布的数据的情况非常普遍。我们认为,将上述持有高质量数据的客户视为负贡献者是不合理的。
为了解决上述问题,我们不再关注由单个客户或拥有遵循相同分布的数据的客户所训练的局部模型,从而提出合作夏普利值。在计算合作夏普利值时,我们忽略了这些局部模型与验证集上的原始全局模型相比的增量损失值。我们只计算每个客户在加入由数据分布X与该客户不同的客户组成的联盟时的损失值减少。
/>
式中,φ
第三部分:基于客户类别的紧凑表达
在联邦学习中,计算夏普利值的大部分时间都是对不同的局部模型的评估。当我们把特征函数看作是一个黑盒函数时,我们必须列举所有可能的联盟并对其进行评估,这种基于枚举的特征函数表达使得夏普利值的计算复杂度达到了参与客户数n的指数级。在联邦学习中,客户的数量往往非常大,指数级的复杂度是不可接受的。有效降低夏普利值计算复杂度的方法之一是使用特征函数的紧凑表示。我们采用一种基于客户类型的紧凑特征函数表达。如果两个客户具有相同的策略能力,那么他们就属于同一策略类型。将夏普利值的计算复杂度降低至多项式级别。
并且有以下定义:
定义一:如果对于任何联盟S,如
客户的策略能力等价性是一种等价关系。据此,我们将拥有非独立同分布数据的客户归入不同的类别。
我们提出以下引理:
引理一:如果有客户i,j∈C,
引理一证明如下:
我们可以得到,对于x∈{i,j},有如下公式
我们对上述方程的右侧进行展开,得到以下公式:
我们提出定理一如下:
定理一:如果有客户i,j∈C,
定理一证明如下:
结合特征函数我们可以得到
结合引理一,可以得到V(S∪i)=V(S∪j)。
我们提出定理二如下:
定理二:在合作博弈中,如果客户的类型数量固定为K,那么计算夏普利值的复杂度为O(|C|
定理二证明如下:
假设基于策略类型的大联盟C的划分是K={C
因为每个类别的客户是策略能力等价的,他们对任何联盟的边际贡献都是一样的。因此,对于一个联盟,我们不需要关心谁在其中,我们只需要关注在这个联盟中每个类别有多少客户。所以时间复杂度如下:
在联邦学习中,需要评估的局部模型的数量可以进一步减少。
我们提出推论一如下:
推论一:
给出两个联盟S={S
那么V(S)=V(T)。
推论一证明如下:
那么
表示包含j个客户的战略类型K的子联盟,将全部客户分为K类C={C
式中,⊥表示互质。
第四部分:客户聚类
在客户持有非独立同分布数据的情况下,客户可以被分为K类。每个类中的客户的数据都属于同一分布。
我们使用k均值聚类来进行基于客户上传的梯度的聚类。我们使用梯度中绝对值最大的5%进行聚类。
验证实验,本发明的实验设置如下:
我们共设置了n=100个客户。在每轮训练中,随机选择其中的10%进行训练。总共将进行T=25轮的训练。每个客户在每轮训练中执行一个局部迭代。我们使用数据集MNIST、FMNIST和CIFAR10。对于MNIST和FMNIST,我们预处理了训练集。我们从每个类别中抽取了5400个样本来组成训练集。因此,最终的训练集包含54000个样本。我们为MNIST和FMNIST选择的模型是LeNet-5,为CIFAR选择的是CNN。两者都包含两个卷积层和三个全连接层。我们使用随机梯度下降作为优化器,学习率设置为0.01。本地批次大小为128。我们将客户端类的数量k分别设置为2、3和4,如下:
两类:客户被分为两个同等规模的组,客户分别从0-4类和5-9类中均匀地选择样本。
三类:客户被分为三个同等规模的组,客户分别从0-3、4-6和7-9类中均匀地选择样本。
四类:客户首先被分为两个同等规模的组,然后每个组被分成两个小组,分别包含30和20个客户。相应地,两个30人的小组分别从0-2和3-5类中选择样本。两个20个客户的小组分别从6-7类和8-9类中选择样本。
实验与精确夏普利值、蒙特卡洛采样、组测试三种方法进行对比。
精确夏普利值:这种方法指的是直接使用梯度来重建所有的子模型进行评。
蒙特卡洛采样:这种方法从所有n!客户的排列组合中随机抽取π,然后计算该排列组合中每个客户加入在他之前的客户的子联盟时的边际贡献。此外,它还截断了不必要的子模型评估。
组测试:这种方法随机地对多个子联盟进行采样,并对其价值进行评估。它估计的是客户之间的夏普利值差异,而不是每个客户的夏普利值。然后,它通过解决一个可行性问题来计算夏普利值。
实验中采用的评价标准如下:
时间:在整个训练过程中,每轮训练计算夏普利值的平均时间。
余弦距离(CD)。在第t次全局迭代中,我们根据以下公式计算近似的BV
欧几里得距离(ED):用以下方法计算
最大差异(MD):用以下方法计算
首先,我们使用2类设置,其中任何一类客户都是不可缺少的,因为如果缺少任何一组客户,全局模型的准确率就不能超过50/%。
图1、图2、图3表明,如果使用原始的夏普利值,那么在训练过程中,一整组或接近一整组的客户在近一半的轮次被分配了负值。本发明总是给所有的客户分配正值,所以我们没有在图中画出它。
图4显示,b本发明在更短的时间内实现了更高的近似精度。我们通过将客户分为两类的情况下进行实验。本发明用于近似的时间和近似值与实际值之间的余弦距离对在MINST数据集上是6.47*10
为了测试客户端类型的数量对本发明的影响,我们将客户端类型的数量分别设置为2、3和4。图5、图6、图7显示,本发明的计算时间随着客户端类型的增加而增加。同时,近似精度也随着客户类型数量的增加而增加。
- 基于夏普利值的联邦学习移动设备分布数据处理方法
- 一种基于夏普利值的区块链医疗数据共享激励方法