一种云原生分布式多租户数据库实现方法及系统
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及数据库技术领域,尤其涉及一种云原生分布式多租户数据库实现方法及系统。
背景技术
云原生数据库是近年来数据库领域最火热的技术方向,云原生数据库通过资源解耦和资源池化等技术,具备了高弹性、高可用性、可扩展性等特点,支撑了不同业务领域的应用对数据管理高性能、高并发和按需使用的需求。与此同时,云原生数据库对于多租户的需求也愈发迫切。
针对传统单机数据库,需要提供一种云原生分布式多租户管理的方法,以解决分布式元数据一致性问题,确保元数据在任意节点上的读写一致性;多租户元数据隔离,确保租户数据可见性、可访问性隔离;以及多租户数据负载均衡调度及物理隔离。
发明内容
为解决分布式场景下跨物理服务器的数据读写一致性问题,以及元数据管理内部采用Raft一致性协议来解决数据的可靠性和一致性问题,本发明提供了一种云原生分布式多租户数据库实现方法及系统,将元数据管理从单机数据库系统中剥离出来,作为一个单独的服务为分布式集群提供元数据服务,结合数据库的RLS机制实现元数据的隔离;通过并置库的方式,将租户的数据库的所有数据集中在一组分片上进行管理,不同组合的数据分布在不同的分片上,实现数据隔离存储。
为实现上述目的,本发明提供了如下的技术方案:
第一方面,在本发明提供的一个实施方案中,提供了一种云原生分布式多租户数据库实现方法,包括以下步骤:
基于集中式管理元数据进行统一元数据管理,将元数据管理从单机数据库系统中剥离出来并提取为公共服务,作为一个单独的服务为分布式集群提供元数据服务;
在数据库进程中构建元数据缓存并构建缓存失效机制,缓存有效时直接读取缓存中的数据,缓存失效时,从元数据服务中获取数据并更新本地元数据缓存;
将元数据进行分片管理,并引入Raft一致性协议,每个分片内部通过Raft Group管理一组数据副本;
基于行级安全策略实现数据库元数据的多租户隔离机制,允许当前租户查询元数据表中的对应记录;
基于物理隔离方式对用户业务数据进行隔离,并对租户创建的每一个数据库在存储层分配一个并置数据库,并置数据库将租户的所有表集中在一个或一组分片上。
作为本发明的进一步方案,所述基于集中式管理元数据进行统一元数据管理,将元数据管理从单机数据库系统中剥离出来并提取为公共服务,包括:
基于单机数据库进行分布式改造,使每个节点运行一个数据库进程,所有节点显示的元数据信息一致,元数据服务提供事务级别的ACI D语义保障。
作为本发明的进一步方案,缓存失效机制进行元数据缓存失效的更新方法,包括以下步骤:
S1、系统启动时从元数据服务加载元数据信息到本地缓存;并加载元数据服务器的当前版本号v1,该版本号由元数据服务维护,每次元数据发生变化就回增加该版本号;
S2、当数据库实例接收到外部查询指令后,读取元数据服务最新的版本号信息v2;用最新版本号v2与上次缓存的版本号进行比较,如果不相等,则执行S21,否则执行S3;
S21、若版本号不同,表示元数据发生了变化,刷新本地缓存;从元数据服务加载最新的元数据信息到本地缓存后,更新v1的值为最新的元数据服务的版本号;
S3、处理用户下发的查询指令;根据指令执行具体的数据处理操作;
S4、返回S2,处理用户的下一跳指令。
作为本发明的进一步方案,元数据进行分片管理时,元数据分布方式由若干元数据节点分别对应一个数据的分片,元数据进行分片管理时还包括元数据高可用机制,所述元数据高可用机制实现时包括以下步骤:
S101、元数据按照哈希规则被分配到不同的分片上进行存储;
S102、每个分片在系统中创建三个副本,每个副本存储完全一样的数据,副本被调度到不同的节点上进行存储,分片的三个副本构成一个Raft group;
S103、任意时刻只有一个副本是raft group中的l eader节点,所述l eader节点用于接受来自客户端的读写请求,当数据发生改动时,l eader节点将变更的数据通过raft协议同步到raft group中的其他节点,当至少超过一半的节点已经确认更改生效后,leader告知客户端数据变更成功;
S104、当l eader节点发生故障时,raft group中的剩余节点重新选举出一个leader节点对外提供服务;
S105、当fo l l ower发生故障时,所述fo l l ower的数据被复制到系统中合适的节点上,系统始终保持三个副本。
作为本发明的进一步方案,当前租户查询元数据表中的对应记录时,数据库处理租户查询请求的方法,包括:
S201、租户下发查询请求,基于租户下发的SQL请求在系统表中查询所有的数据库信息;
S202、通过词法分析器解析目标表;
S203、读取目标表的行级安全策略,其中,数据库内核查询行级安全策略表,获取系统表的策略信息;
S204、查询到相关的策略信息后,内核引擎重写用户下发的查询语句;
S205、使用重写后的查询语句进行数据查询;
S206、根据数据查询后的结果返回租户关联的数据。
作为本发明的进一步方案,将元数据进行分片管理,还包括数据分片调度,数据分片调度的方法,包括以下步骤:
S301、租户在创建新的数据库时或者数据库分片大小达到阈值时,为该租户的数据创建新的分片;
S302、数据完成分片后,根据当前系统的实际负载情况来决定每个分片的存储位置。
作为本发明的进一步方案,步骤S301中,数据分片依据用户建表时设置的分片策略确定,默认采用hash方法进行数据分片,若新建数据库,则执行步骤S311,若数据库分片大小达到阈值,则执行步骤S312;
S311、当用户创建新的数据库时,为该数据库在每个节点创建预设数量的分片,在磁盘上设置对应数据文件;若是数据库分片,初始创建数据分片数量为1,随着数据的写入,根据识别到的真实数据的分布对分片进行切分;
S312、当数据分片文件达到阈值时,将该分片一分为二,并对分片进行重新调度。
作为本发明的进一步方案,根据当前系统的实际负载情况来决定每个分片的存储位置,包括:
S321、获取系统配置信息,对于集群中的任意节点,其CPU核心数为cn,物理磁盘数量为dn;
S322、计算每个节点的实时资源使用指数,Core
S323、计算租户在每个节点的数据实时分布指数,对于集群中的任意租户,PN
S24、计算该租户下一个数据分片的节点调度优先级,计算方法为:
Next=min(S
即:
作为本发明的进一步方案,所述云原生分布式多租户数据库实现方法还包括数据分片调度机制,数据分片调度机制时数据库的处理方法,包括:
S401、指令解析器和查询优化器用于解析用户下发的查询请求并针对性的进行查询优化;
S402、执行引擎负责按步骤执行用户的查询请求,所有的数据操作则下发到存储引擎进行处理;
S403、存储引擎负责数据分片管理、分片调度算法的执行、查询任务的分派;
S404、分片服务负责分片内数据的组织、数据I O操作的实际执行以及事务性保障;
S405、磁盘文件存储了用户的最终数据,通过合理的磁盘管理方式物理上隔离不同租户的数据。
第二方面,本发明还提供了一种云原生分布式多租户数据库实现系统,用于执行上述所述云原生分布式多租户数据库实现方法;所述云原生分布式多租户数据库实现系统包括:
统一元数据管理模块,用于基于集中式管理元数据进行统一元数据管理,将元数据管理从单机数据库系统中剥离出来并提取为公共服务,作为一个单独的服务为分布式集群提供元数据服务;
元数据缓存失效更新模块,用于在数据库进程中构建元数据缓存并构建缓存失效机制,缓存有效时直接读取缓存中的数据,缓存失效时,从元数据服务中获取数据并更新本地元数据缓存;
元数据分片管理模块,用于将元数据进行分片管理,并引入Raft一致性协议,每个分片内部通过Raft Group管理一组数据副本;
数据库租户查询管理模块,用于基于行级安全策略实现数据库元数据的多租户隔离机制,允许当前租户查询元数据表中的对应记录;
多租户隔离管理模块,用于基于物理隔离方式对用户业务数据进行隔离,并对租户创建的每一个数据库在存储层分配一个并置数据库,并置数据库将租户的所有表集中在一个或一组分片上。
第三方面,在本发明提供的又一个实施方案中,提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器加载并执行所述计算机程序时实现云原生分布式多租户数据库实现方法的步骤。
第四方面,在本发明提供的再一个实施方案中,提供了一种存储介质,存储有计算机程序,所述计算机程序被处理器加载并执行时实现所述云原生分布式多租户数据库实现方法的步骤。
本发明提供的技术方案,具有如下有益效果:
本发明提供的云原生分布式多租户数据库实现方法及系统,可以将元数据管理从单机数据库系统中剥离出来,作为一个单独的服务为分布式集群提供元数据服务,解决分布式场景下跨物理服务器的数据读写一致性问题,元数据管理内部采用Raft一致性协议来解决数据的可靠性和一致性问题;结合数据库的RLS机制实现元数据的隔离;通过并置库的方式,将租户的数据库的所有数据集中在一组分片上进行管理,不同组合的数据分布在不同的分片上,实现数据隔离存储。
本发明的这些方面或其他方面在以下实施例的描述中会更加简明易懂。应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例。在附图中:
图1为本发明实施例的一种云原生分布式多租户数据库实现方法中传统单机数据库的元数据的分布示意图。
图2为本发明实施例的一种云原生分布式多租户数据库实现方法中在数据库进程中构建元数据缓存的结构图。
图3为本发明实施例的一种云原生分布式多租户数据库实现方法中元数据缓存失效更新的流程图。
图4为本发明实施例的一种云原生分布式多租户数据库实现方法中元数据分布方式的结构图。
图5为本发明实施例的一种云原生分布式多租户数据库实现方法中数据库元数据表的结构图。
图6为本发明实施例的一种云原生分布式多租户数据库实现方法中数据库处理租户查询请求执行的流程图。
图7为本发明实施例的一种云原生分布式多租户数据库实现方法中多租户场景下分配并置数据库的示意图。
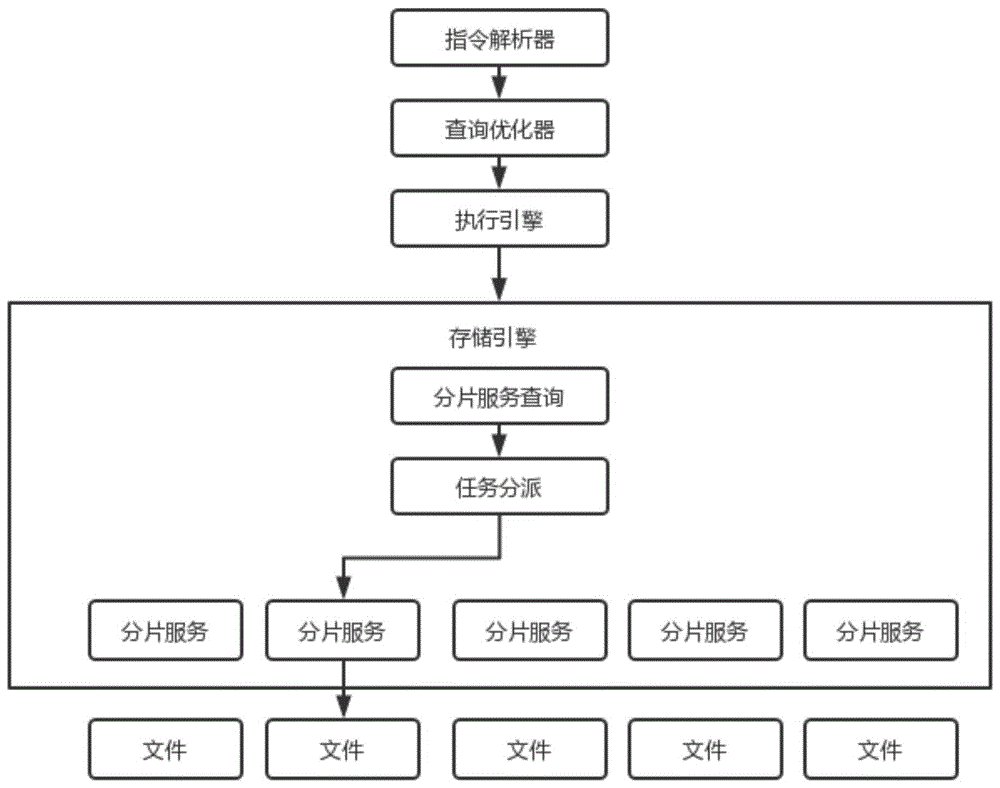
图8为本发明实施例的一种云原生分布式多租户数据库实现方法中数据分片调度机制下数据库处理的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
在本发明的说明书和权利要求书及上述附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如101、102等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
下面将结合本发明示例性实施例中的附图,对本发明示例性实施例中的技术方案进行清楚、完整地描述,显然,所描述的示例性实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
具体地,下面结合附图,对本申请实施例作进一步阐述。
参见图1所示,本发明的一个实施例提供一种云原生分布式多租户数据库实现方法,该云原生分布式多租户数据库实现方法具体包括如下步骤:
基于集中式管理元数据进行统一元数据管理,将元数据管理从单机数据库系统中剥离出来并提取为公共服务,作为一个单独的服务为分布式集群提供元数据服务;
在数据库进程中构建元数据缓存并构建缓存失效机制,缓存有效时直接读取缓存中的数据,缓存失效时,从元数据服务中获取数据并更新本地元数据缓存;
将元数据进行分片管理,并引入Raft一致性协议,每个分片内部通过Raft Group管理一组数据副本;
基于行级安全策略实现数据库元数据的多租户隔离机制,允许当前租户查询元数据表中的对应记录;
基于物理隔离方式对用户业务数据进行隔离,并对租户创建的每一个数据库在存储层分配一个并置数据库,并置数据库将租户的所有表集中在一个或一组分片上。
本发明的一种云原生分布式多租户数据库实现方法,将元数据管理从单机数据库系统中剥离出来,作为一个单独的服务为分布式集群提供元数据服务,结合数据库的RLS机制实现元数据的隔离;通过并置库的方式,将租户的数据库的所有数据集中在一组分片上进行管理,不同组合的数据分布在不同的分片上,实现数据隔离存储。
由于基于单机数据库进行分布式多租户改造,其中一个要解决的问题就是系统表的管理问题,包括系统表数据一致性问题、系统表隔离问题。其中,针对系统表数据一致性问题。
其中,系统表数据一致性问题即为:在一个多节点的集群环境下,当用户在节点1上执行DDL操作时,对数据库的系统表所做的所有修改,应该实时的反映的集群的其他节点上,否则用户在其他节点上看到的可能是旧的表结构、旧的字段名称,这会导致应用访问数据库时发生不可预知的行为,此类问题称之为元数据一致性问题。
在本实施例中,所述基于集中式管理元数据进行统一元数据管理,将元数据管理从单机数据库系统中剥离出来并提取为公共服务,包括:基于单机数据库进行分布式改造,使每个节点运行一个数据库进程,所有节点显示的元数据信息一致,元数据服务提供事务级别的ACI D语义保障。
在本实施例中,采用集中式元数据管理方案解决上述的系统表数据一致性问题。如图1所示,传统单机数据库的元数据都是在本地管理,基于单机数据库进行分布式改造后,每个节点都会运行一个数据库进程,为了确保所有节点看到的元数据信息都是一致的,本发明将单机的元数据管理模块提取成为公共服务,统一维护集群的元数据信息,集群中的任意数据库进程需要对元数据进行增删改查时,都统一访问元数据服务,元数据服务要提供事务级别的ACI D语义保障。
由于数据库进程和元数据服务之间是通过RPC通信的,如果应用程序的DML操作需要访问元数据时都跟元数据服务进行次RPC通信,会导致DML操作延迟变高。数据库系统对延迟非常敏感,应用程序每秒钟会跟数据库产生数万甚至数十万次交互,任何微小的开销都会导致整体系统的性能下降,因此,需要在数据库进程中构建元数据缓存。
参见图2所示,引入元数据缓存之后,系统随之而来的一个挑战就是如何保证缓存有效性,由于系统中的任意节点会随时修改元数据从而更新元数据服务中的数据,本发明需要构建一种缓存失效机制,也就是任何时候当数据库进程需要访问元数据时,如果缓存有效则直接读取缓存中的数据,如果缓存失效则从元数据服务中获取数据并更新本地元数据缓存。
在一些实施例中,参见图3所示,缓存失效机制进行元数据缓存失效的更新方法,包括以下步骤:
S1、系统启动时从元数据服务加载元数据信息到本地缓存;并加载元数据服务器的当前版本号v1,该版本号由元数据服务维护,每次元数据发生变化就回增加该版本号;
S2、当数据库实例接收到外部查询指令后,读取元数据服务最新的版本号信息v2;用最新版本号v2与上次缓存的版本号进行比较,如果不相等,则执行S21,否则执行S3;
S21、若版本号不同,表示元数据发生了变化,刷新本地缓存;从元数据服务加载最新的元数据信息到本地缓存后,更新v1的值为最新的元数据服务的版本号;
S3、处理用户下发的查询指令;根据指令执行具体的数据处理操作;
S4、返回S2,处理用户的下一跳指令。
由于分布式系统的核心之一就是要解决系统单点问题,本发明将元数据管理提取为公共服务之后,元数据服务就成为了系统的单点,为了解决该问题。本发明将元数据进行分片管理,并引入Raft一致性协议,每个分片内部则通过Raft Group管理一组数据副本,从而保障任意节点或者副本发生故障,不会导致元数据丢失、服务不可用的情况出现,元数据分布方式如图4所示,图4中A、B、C...表示数据的分片。
在一些实施例中,元数据进行分片管理时,元数据分布方式由若干元数据节点分别对应一个数据的分片,元数据进行分片管理时还包括元数据高可用机制,所述元数据高可用机制实现时包括以下步骤:
S101、元数据按照哈希规则被分配到不同的分片上进行存储;
S102、每个分片在系统中创建三个副本,每个副本存储完全一样的数据,副本被调度到不同的节点上进行存储,分片的三个副本构成一个Raft group;
示例性的,如图4中A1、A2、A3就是分片A的三个副本;三个副本构成一个Raftgroup。
S103、任意时刻只有一个副本是raft group中的l eader节点,所述l eader节点用于接受来自客户端的读写请求,当数据发生改动时,l eader节点将变更的数据通过raft协议同步到raft group中的其他节点,当至少超过一半的节点已经确认更改生效后,leader告知客户端数据变更成功;
S104、当l eader节点发生故障时,raft group中的剩余节点重新选举出一个leader节点对外提供服务;
S105、当fo l l ower发生故障时,所述fo l l ower的数据被复制到系统中合适的节点上,系统始终保持三个副本。
通过以上数据分布和同步方式,任意时刻当系统发生节点故障时,都可以确保元数据服务以一致的方式对外提供服务,不会导致数据丢失、错乱等情况发生。
由于Raft协议为了保障数据可靠性,数据读写必须串行执行,因此单个raftgroup的延迟会比较高。本系统将Raft group构建在数据分片级别的,而不是节点级别的,这种构建方式可以更细粒度的分散风险,同时提高系统的整体吞吐率。
数据库元数据多租户隔离的实现方式有很多种,本发明实施例中,借助行级安全策略(RLS),以较少的侵入性巧妙的实现多租户隔离功能。其中,行级安全策略允许本发明对表中的每一行数据设置访问权限,数据库的元数据信息也是以表的形式存储的,因此,可以充分利用行级安全策略的能力,对元数据的每一行进行细粒度的权限管理,从而实现多租户场景下元数据的可见性、可操作性的隔离。
参见图5所示,以数据库元数据表为例,展示基于行级安全策略的多租户隔离机制。如图5所示,元数据表中记录了每个数据库的owner id信息,本发明通过构建行级安全策略,只owner能看到元数据表中的对应记录,从而实现数据库系统表的隔离。以租户允许当前102为例,该租户查询元数据表中的所有数据库记录时,只会返回db02、db04这两条记录,其他记录对该用户是不可见的。
在一些实施例中,参见图6所示,当前租户查询元数据表中的对应记录时,数据库处理租户查询请求的方法,包括:
S201、租户下发查询请求,基于租户下发的SQL请求在系统表中查询所有的数据库信息;
示例性的,租户下发的SQL请求为:SELECT*FROM pg_database;该请求从系统表pg_database中查询所有的数据库信息。
S202、通过词法分析器解析目标表;
示例性的,SQL解析引擎对该SQL语句进行词法分析,提取出当前要查询的目标表为pg_database。
S203、读取目标表的行级安全策略,其中,数据库内核查询行级安全策略表,获取系统表的策略信息;
在本实施例中,数据库内核查询行级安全策略表,获取pg_database的po l icy信息。本发明会在行级安全策略中预先设置好pg_database的相关策略属性,示例性的,本发明为pg_database设置如下策略:
CREATE POLI CY pg_database_i so l ation ON pg_database
USI NG(pg_get_userbyid(datdba)=current_user)。
S204、查询到相关的策略信息后,内核引擎重写用户下发的查询语句;
在本实施例中,查询到相关的策略信息后,内核引擎会重写用户下发的SQL语句,以S203对pg_database设置的po l icy为例,重写后的语句为:SELECT*FROM pg_databasewhere pg_get_userbyid(datdba)=current_user。
S205、使用重写后的查询语句进行数据查询;
在本实施例中,语句重写完成后,会为该语句构建执行计划,并将相应的查询指令通RPC下发到存储引擎执行实际的数据查询操作,获取相关的数据。根据S204步骤重写后的SQL,本发明实际上只会返回当前登录用户所拥有的数据库条目,而不是默认的把系统表中所有的数据库条目都返回。这样可以在一套系统中运行多个用户创建自己的数据库,并且这些用户在查询系统表时,不会将其他用户创建的数据库信息查询出来。从而实现了元数据的隔离。
S206、根据数据查询后的结果返回租户关联的数据。
上述步骤都是在内核中完成的,租户无法干预该过程,因此通过行级安全策略,实现了每个租户只能查询到与自己相关联的数据的目标。
如图7所示,多租户场景下,系统为租户创建的每一个数据库在存储层会分配一个并置数据库,并置数据库会将租户的所有表集中在一个或一组分片上,同时为该组分片的数据文件分配指定的磁盘,从而实现用户数据的物理隔离。
其中,数据在物理磁盘上的分片调度需要考虑如下一些因素:
1)节点的CPU使用率2)磁盘IO的繁忙程度3)租户突发流量的处理能力。
为充分发挥集群整体效率,调度算法应当尽可能的保障各个节点的资源使用率均衡,与此同时,对于单个租户来说,其资源应当尽量均衡在集群节点分布,确保租户业务出现突发流量时,能充分利用整体集群的能力来处理峰值请求。
基于以上考虑,在一些实施例中,将元数据进行分片管理,还包括数据分片调度,数据分片调度的方法,包括以下步骤:
S301、租户在创建新的数据库时或者数据库分片大小达到阈值时,为该租户的数据创建新的分片;
在一些实施例中,步骤S301中,数据分片依据用户建表时设置的分片策略确定,默认采用hash方法进行数据分片,若新建数据库,则执行步骤S311,若数据库分片大小达到阈值,则执行步骤S312;
S311、当用户创建新的数据库时,为该数据库在每个节点创建预设数量的分片,在磁盘上设置对应数据文件;若是数据库分片,初始创建数据分片数量为1,随着数据的写入,根据识别到的真实数据的分布对分片进行切分。
示例性的,系统默认分片数量为8,当用户创建新的数据库时,会为该数据库在每个节点创建8个分片,在磁盘上对应8个数据文件;如果是range分片方法,则初始创建数据分片数量为1,随着用户不断的写入数据,系统会逐渐识别到真实数据的分布情况,从而能根据数据的真实分布来对分片进行切分,避免数据分布不均衡。
S312、当数据分片文件达到阈值时,将该分片一分为二,并对分片进行重新调度。
示例性的,当数据分片文件达到阈值时(默认阈值1G),会将该分片一分为二,并对分片进行重新调度,避免个别分片的数据过多导致系统存在热点。
S302、数据完成分片后,根据当前系统的实际负载情况来决定每个分片的存储位置。在一些实施例中,根据当前系统的实际负载情况来决定每个分片的存储位置,包括:
S321、获取系统配置信息,对于集群中的任意节点,其CPU核心数为cn,物理磁盘数量为dn;
S322、计算每个节点的实时资源使用指数,Core
S323、计算租户在每个节点的数据实时分布指数,对于集群中的任意租户,PN
S24、计算该租户下一个数据分片的节点调度优先级,计算方法为:
Next=min(S
即:
通过组合不同的分片策略以及分片数据调度算法,可以做到灵活的适配用户的不同应用场景,针对性的对数据查询进行优化,根据用户选择的分片策略是hash还是range方法,数据在分片内会以符合业务场景需求的方式进行存储,以实现更高的数据查询性能。
分片数据调度算法可以同时解决三方面的问题:
1)整体系统的负载均衡性:即集群中的所有节点的计算和存储资源会均衡利用,避免系统长时间运行后部分节点负载过高。2)租户数据均衡分布:算法将租户作为一个参考因子,确保特定租户的数据不会被调度到个别节点上,导致该租户的整体性能受限于少量节点,从而很好的应对租户突发流量场景需求。3)热点数据分散存储:分片调度算法能够很好的适应系统实时负载情况,避免个别节点过热,也能够将部分过热的数据通过重新分片的方式调度到更多节点上来分散压力。
在一些实施例中,参见图8所示,所述云原生分布式多租户数据库实现方法还包括数据分片调度机制,数据分片调度机制时数据库的处理方法,包括:
S401、指令解析器和查询优化器用于解析用户下发的查询请求并针对性的进行查询优化;
S402、执行引擎负责按步骤执行用户的查询请求,所有的数据操作则下发到存储引擎进行处理;
S403、存储引擎负责数据分片管理、分片调度算法的执行、查询任务的分派;
S404、分片服务负责分片内数据的组织、数据I O操作的实际执行以及事务性保障;
S405、磁盘文件存储了用户的最终数据,通过合理的磁盘管理方式物理上隔离不同租户的数据。
应该理解的是,上述虽然是按照某一顺序描述的,但是这些步骤并不是必然按照上述顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,本实施例的一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
参见图5所示,在本发明的一个实施例中还提供了一种云原生分布式多租户数据库实现系统,应用于执行上述云原生分布式多租户数据库实现方法,所述云原生分布式多租户数据库实现系统包括统一元数据管理模块401、元数据缓存失效更新模块402、元数据分片管理模块403、数据库租户查询管理模块404以及多租户隔离管理模块405。
所述统一元数据管理模块401,用于基于集中式管理元数据进行统一元数据管理,将元数据管理从单机数据库系统中剥离出来并提取为公共服务,作为一个单独的服务为分布式集群提供元数据服务;
所述元数据缓存失效更新模块402,用于在数据库进程中构建元数据缓存并构建缓存失效机制,缓存有效时直接读取缓存中的数据,缓存失效时,从元数据服务中获取数据并更新本地元数据缓存;
所述元数据分片管理模块403,用于将元数据进行分片管理,并引入Raft一致性协议,每个分片内部通过Raft Group管理一组数据副本;
所述数据库租户查询管理模块404,用于基于行级安全策略实现数据库元数据的多租户隔离机制,允许当前租户查询元数据表中的对应记录;
所述多租户隔离管理模块405,用于基于物理隔离方式对用户业务数据进行隔离,并对租户创建的每一个数据库在存储层分配一个并置数据库,并置数据库将租户的所有表集中在一个或一组分片上。
需要特别说明的是,云原生分布式多租户数据库实现系统在执行时采用如前述的一种云原生分布式多租户数据库实现方法的步骤,因此,本实施例中对云原生分布式多租户数据库实现系统的运行过程不再详细介绍。
在一个实施例中,在本发明的实施例中还提供了一种计算机设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器执行所述的云原生分布式多租户数据库实现方法,该处理器执行指令时实现上述各方法实施例中的步骤。
在本发明的一个实施例中还提供了一种存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述云原生分布式多租户数据库实现方法的步骤。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种多租户的数据库分库实现方法
- 一种基于ETCD的云原生分布式数据库事务管理方法及系统
- 一种分布式云原生数据库管理方法和系统