基于元辅助学习框架的工业大数据驾驶舱视图推荐方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及推荐系统领域,具体涉及一种基于元辅助学习框架的,面向工业大数据驾驶舱视图的推荐方法。
背景技术
随着互联网技术的不断发展,越来越多的技术在工业领域中得到运用,工业领域也大多由原来需要人力去控制生产转变成了半自动或者全自动的生产模式。这种生产模式减少了大量的人工成本的同时,也带来了许多反映当前生产状态的工业化数据。这些工业化数据大多蕴含了机器的运行状态和整体的生产效率等具有高价值的信息,因此,能够让驾驶舱用户全方位了解这些数据是十分重要的。
一种表达高效的数据可视化技术可以帮助工业生产操作员更好地了解当前机器的状态和工厂整体的生产情况,从而做出进一步地指令,达到最大化工厂整体利润的目的。不过,不同的工业大数据驾驶舱操作员对于不同的数据可视化视图的敏感程度是不一样的。用户可能更容易从一些类型的可视化视图读取数据信息,而较难从另一些类型的视图中获取表达的数据状态。并且由于数据可视化视图的种类是十分繁多的,在工业化数据场景中运用的视图不止包括简单的树形图、条形图等,更包括了涵盖着高维信息的视图如面积图、箱线图等。因此,大多数的工业大数据驾驶舱用户只是经常使用一部分较为偏好的视图,而缺乏对其他很大一部分的视图的探索,这种现象在一定程度上限制了大数据驾驶舱的功能性。本发明为了帮助可视化技术对用户可能存在偏好的其他视图进行探索,提出了一种用在工业大数据驾驶舱的视图推荐方法。
然而,对于现实生活中的工业化大数据驾驶舱视图推荐场景来说,也存在着一些技术挑战亟待解决。对于工业化数据驾驶舱的使用用户来说,大多数只是使用过极小一部分的视图,对极小一部分的视图有或高或低的兴趣,而对大多数的视图没有产生过历史交互信息。因此,这对应在视图推荐系统中,会使得可供模型训练的数据比较稀疏,可能会导致一种比较差的推荐效果。因此,如何缓解甚至解决工业化大数据驾驶舱视图推荐方法所面对的数据稀疏的问题是一个巨大的挑战。
同样,由于整体推荐模型的训练需要通过各种用户和视图的损失函数来完成对相应的特征向量的更新,一些实际中应用的推荐技术并没有考虑用户方面和视图方面的个性化信息,这将导致模型难以完成个性化推荐任务。因此,在视图推荐系统中,如何将用户和视图角度的个性化信息融入模型成为了一大难题。
最后,模型更新效率低,时间和空间花销大也是现如今工业化大数据驾驶舱视图推荐方法所面临的一个问题。由于对于不同的用户以及不同的视图来说,都需要一个特征向量来进行对应,并完成相应的训练。而在大多数的解决数据稀疏问题的场景下,都需要引入辅助任务来帮助主要任务更好地学习特征向量的表示,这样的更新架构会增加时间上和空间上花销,对于工业化数据驾驶舱场景是难以接受的。
例如,中国专利申请号CN 202122835104.2公开了一种基于数字化的信息数据管理平台大数据驾驶舱,包括座椅,所述座椅的底部安装有底板,移动组件,所述移动组件设置在移动箱的内部,调节组件,所述调节组件设置在调节箱的内部,所述调节组件包括转杆,涉及数字化设备领域。包括底部设置有移动组件,通过驱动移动组件中的电机,能够带动座椅左右移动调节,方便工作人员使用,且通过螺纹杆转动带动移动板移动,能够防止座椅在移动过程中受外力影响产生的移位,座椅底部设置有调节组件,推动座椅转动,通过底板带动轴杆定轴转动,能够快速实现对座椅角度的调节,通过转杆能够增加底板与调级箱内部的连接,能够增加底板的稳定性。
又例如,中国专利申请号CN107748763A公开了一种基于ELA大数据驾驶舱的3D触摸系统及数据处理方法,数据处理方法包括以下步骤:S1:第一Logstash服务器通过web服务器获取实时Log数据,采集到web服务器实时Log数据后暂存到Redis缓存模块;S2:Redis缓存模块中临时存储的实时Log数据传送至ElasticSearch服务器中存储;S3:通过ElasticSearch服务器将数据分拣后传送至数据库存储模块;S4:数据库存储模块将数据传送至数据分析与处理模块。本发明为用户行为分析、用户画像等类型业务大数据计算、数据呈现提供了一种有效解决方案,有效解决了传统数据仓库存储容量有限、读取效率低、报表实现过程僵化的问题,本发明还结合3D触摸技术,创造一个可提供隔空自定义手势操作服务的ELA大数据驾驶舱系统。
再例如,中国专利申请号108657186A公开了一种应用于无人驾驶车的智能驾驶舱的交互方法和装置,属于智能驾驶中的无人驾驶技术领域。所述方法包括:在检测到未识别用户将进入或位于智能驾驶舱内时,获取用户的面部信息;根据用户的面部信息识别用户身份,以使大数据服务器根据该用户身份获取对应的用户偏好信息,并基于该用户偏好信息找到相应的资讯数据;从大数据服务器接收该资讯数据;自动或根据接收到的播放指令播放该资讯数据。本申请可以根据不同用户的偏好播放其感兴趣的内容,且无需用户手动操作即可获取自己感兴趣的资讯,解决了现有技术中人车交互方式单一的问题,为用户带来了良好的驾乘体验,达到了使人车交互内容更加丰富的效果。
上述专利申请均未解决工业化大数据驾驶舱视图推荐方法所面对的数据稀疏的问题,以及如何将用户和视图角度的个性化信息融入模型和模型更新效率低、时间和空间花销大的问题。
发明内容
针对现有技术中的缺陷空白,本发明提出一种基于元辅助学习框架的工业大数据驾驶舱视图的推荐方法。
所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法包括:
步骤1,将工业大数据驾驶舱用户对各种视图的评分信息导入驾驶舱视图推荐系统;
步骤2,驾驶舱视图推荐系统的数据处理模块读取并处理评分信息,生成用户、视图的特征向量;
步骤3,驾驶舱视图推荐系统的数据采样模块根据特征向量和评分信息,生成一组关于用户、视图的采样数据;
步骤4,驾驶舱视图推荐系统的主模型和基于自监督对比学习构建的辅助模型根据采样数据计算得到对应的损失函数L
步骤5,驾驶舱视图推荐系统的参数更新模块,通过整体模型的目标函数L,采用一种双层的元辅助学习更新架构,在内层更新驾驶舱视图推荐系统的主模型的参数以及用户、视图的特征向量,外层更新用户、视图的对比学习辅助模型的参数以及贡献系数λ
步骤6,反复执行步骤3、步骤4、步骤5直至主模型的参数、辅助模型的参数、用户和视图的特征向量以及贡献系数λ
步骤7,驾驶舱视图推荐系统的推荐模块通过用户以及视图的特征向量,计算用户对各种视图的偏好值,为不同的用户推荐不同的工业大数据驾驶舱视图。
进一步地,步骤1中,所述的工业大数据驾驶舱用户对各种视图的评分数据包括多个评分三元组(u,v,r),其中:u表示不同用户的ID,下标为1–N,N为用户的个数;v表示不同视图的ID,下标为1–M,M为视图的个数;r表示用户u对于不同视图v的评分,取值范围为1–5。
进一步地,步骤2中,所述驾驶舱视图推荐系统的数据处理模块读取并处理评分信息,生成用户、视图的特征向量,包括:
步骤201,所述驾驶舱视图推荐系统的数据处理模块根据评分信息中用户和视图的ID下标,得到用户个数N和视图个数M,生成一个稀疏的评分矩阵R
步骤202,系统的数据处理模块得到用户集合U,和视图集合V,根据用户个数N和视图的个数M,分别为用户一侧和视图一侧生成N个和M个的可训练特征向量,并通过映射的构建,使得每个用户和每个视图和这些可训练特征向量一一对应。
进一步地,步骤3中,所述驾驶舱视图推荐系统的数据采样模块根据特征向量和评分信息,生成一组关于用户、视图的采样数据,具体包括:
步骤301,数据采样模块对评分信息进行预处理,根据用户u对视图评分的取值,将用户评分大于或等于4的视图定义为用户u偏好的视图,也就是用户u的正样本视图
上式(1)中:
步骤302,根据步骤301得到的所有用户对所有视图的关系,计算不同用户之间的相似度,得到用户侧的相似度矩阵U
步骤303,根据步骤302得到的用户之间的相似度矩阵,为每个用户筛选出相似度大于或等于0.3的用户,视为它的正相关用户邻居,同时将其他剩下的用户视为当前用户的负相关用户邻居,在视图侧也进行相同的操作,为每个视图筛选出正相关邻居和负相关邻居;
步骤304,数据采样模块生成一组样本,一组样本由7部分组成,包括用户,用户偏好的视图、用户不偏好的视图,用户的正相关邻居,用户的负相关邻居,用户偏好的视图的正相关邻居,用户偏好的视图的负相关邻居。
进一步地,步骤4中,所述驾驶舱视图推荐系统的主模型和基于自监督对比学习构建的辅助模型根据采样数据,计算得到对应的损失函数L
步骤401,步骤3生成的采样数据传递给主模型和辅助模型,主模型运用BPR-loss的方法,求出损失函数L
上式(2)至式(5)中,u表示特定的用户,v
步骤402,步骤401中计算得到的主模型和辅助模型损失函数的加权求和之后得到整体模型的目标函数L,其中,整体模型的目标函数的计算如下式(6)所示:
上式(6)中,σ表示激活函数sigmiod,λ
进一步地,步骤5中,所述的驾驶舱视图推荐系统的参数更新模块,通过整体模型的目标函数L,采用一种双层的元辅助学习更新架构,在内层更新主模型的参数以及用户、视图的特征向量,外层更新辅助模型的参数以及贡献系数λ
步骤501,在参数更新模块的内层,使用步骤4中得到的整体模型的目标函数L,固定辅助模型参数以及贡献系数λ
上式(7)中,θ包括主模型的参数以及用户、视图的特征向量,
步骤502,步骤501中更新后得到的参数
上式(8)中,β表示学习率,d表示求全导数。
进一步地,步骤6中,所述的反复执行步骤3、步骤4、步骤5直至各个模型的参数不再发生改变。
进一步地,步骤7中,所述的驾驶舱视图推荐系统的推荐模块通过用户以及视图的特征向量,计算用户对各种视图的偏好值,为不同的用户推荐不同的工业大数据驾驶舱视图,包括:
步骤701,系统的推荐模块根据用户、视图训练好的特征向量,通过内积的计算,得到用户和视图之间的偏好值矩阵P
步骤702,根据步骤701中得到的用户对视图的偏好值矩阵P
相对于现有技术,本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法的优越效果在于:
1.本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法,通过辅助模型的贡献,缓解了传统的工业大数据驾驶舱视图推荐系统所存在的数据稀疏的问题;鉴于本发明中的辅助模型运用了自监督对比学习的思想,通过最大化用户、视图与其所对应的正、负样本邻居之间的互信息来构建,起到了一种数据增广的意义,因此,使得整体的模型不仅仅依靠源数据来训练,更通过增广后的邻居数据来训练,使得整体模型的感知范围变大,提升了模型的推荐效果。
2.本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法,运用了一种双层的元辅助学习的参数更新架构,克服了传统多任务学习工作中经常出现的负迁移的现象,通过元辅助学习的参数更新架构,使得系统整体将驾驶舱视图推荐主模型和辅助模型的参数更新分开来,在第一阶段保持辅助模型参数不变,更新主模型的参数,同时使得更新后的主模型参数保存一部分辅助模型的梯度;并且在第二阶段更新辅助模型的参数时,固定主模型的参数,这样的一种参数更新架构能够使得每次更新只影响单一任务的参数,同时又能保证任务之间的关联性,既保证了多任务模型的整体效果,又避免了负迁移现象的产生。
3.本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法,在对辅助模型进行参数更新的时候,运用了一种隐式的梯度更新方法,减少了时间和空间的高额花销,由于元辅助学习需要构建一个双层的更新方式,所以需要在第一阶段更新驾驶舱视图推荐主模型的参数之后,保留辅助模型的参数的计算图;然后在第二阶段更新辅助模型的参数的时候,需要对高阶导数进行计算和存储,这一操作将导致大量的时间和空间上的负担,从而降低模型的效率,增加工业大数据驾驶舱视图推荐系统的成本。
4.本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法,通过隐式梯度方法,避免了这一步的计算,直接通过公式推导得到辅助模型的参数梯度,完成参数更新。
5.本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法,能够装载在任意的现有的工业大数据驾驶舱视图推荐模型,并能够显著地提升推荐效果,由于本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法提出的主要是一种应用在工业大数据驾驶舱视图推荐系统的辅助模型框架,主要贡献在于提出一种基于自监督对比学习的高效辅助任务模型,以及一种双层参数优化架构,所以能够装载在诸多现有的推荐模型上,并使这些推荐模型充当本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法中所提到的驾驶舱视图推荐主模型即可。
6.由于本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法起到了一种数据增广的作用,增大了整体模型的感受视野,能够提升推荐效果,并且通过双层参数优化架构和隐式梯度更新方法,降低整体系统所需的时间和空间消耗。
附图说明
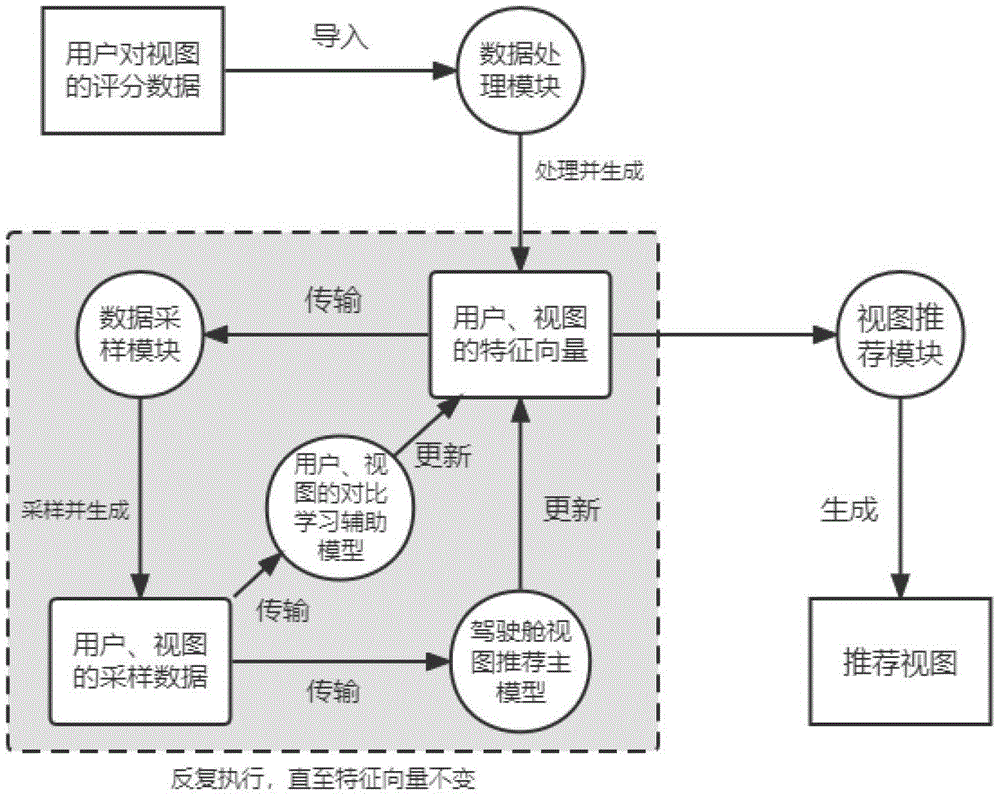
图1为本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法整体框架图。
图2为本发明所述基于元辅助学习框架的工业大数据驾驶舱视图推荐方法的双层参数更新框架的示意图。
图3为带有个性化贡献参数的模型与原始模型的Top-K召回率的示意图。
图4为带有个性化贡献参数的模型与原始模型的Top-K归一化折损累计增益的示意图。
图5为带有个性化贡献参数的模型与原始模型的Top-K精确率的示意图。
图6为本发明所述的隐式梯度下降法和传统梯度下降法的计算花销比较的示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明所述方法进行进一步的详细描述。
结合图1,本发明所述方法提出了一种基于元辅助学习框架的工业大数据驾驶舱视图推荐算法,所述方法包括:
步骤1,将工业大数据驾驶舱用户对各种视图的评分信息导入驾驶舱视图推荐系统:
系统的管理人员通过对原始数据的获取,处理等预操作,得到工业大数据驾驶舱用户的使用习惯数据,这些数据常见的一种表现形式是工业大数据驾驶舱用户对不同视图的评分数据,数据文件的每一行是一个三元组(u,v,r),其中u表示不同用户的ID,下标为1–N,N为用户的个数;v表示不同视图的ID,下标为1–M,M为视图的个数;r表示用户u对于视图v的评分,取值范围为1–5,评分数值的大小表示用户对视图的偏好程度,在系统的管理人员为通过设置数据路径等方式导入评分数据文件之后,系统自动申请一定的内存空间,用来对这些评分数据进行存储;
步骤2,驾驶舱视图推荐系统的数据处理模块读取并处理评分信息,生成用户、视图的特征向量:
步骤201,系统的数据处理模块根据评分信息中用户和视图的ID下标,得到用户个数N和视图个数M,生成一个稀疏的评分矩阵R
步骤202,系统的数据处理模块得到用户集合U,和视图集合V,根据用户个数N和视图的个数M,分别为用户一侧和视图一侧生成N个和M个的可训练特征向量,并通过映射的构建,使得每个用户和每个视图和这些可训练的特征向量一一对应,在这一步骤中,系统设置N+M个可训练的特征向量,分别对应N个用户和M个视图,并且每个特征向量设置为50维;
步骤3,驾驶舱视图推荐系统的数据采样模块根据特征向量和评分信息,生成一组关于用户、视图的采样数据:
步骤301,数据采样模块对评分信息进行预处理,根据用户u对视图评分的取值,将用户评分大于等于4的视图定义为用户u偏好的视图,也就是用户u的正样本视图
上式中,R
步骤302,根据步骤301得到的所有用户对所有视图的关系,计算不同用户之间的相似度,得到用户侧的相似度矩阵U
本步骤中,首先根据用户对样本之间的正负样本关系,对每个用户u生成一个长度为M的独热向量,对于向量的每一位来说,如果对应的视图属于
步骤303,根据步骤302得到的用户之间的相似度矩阵,为每个用户筛选出相似度大于或等于0.3的用户,视为它的正相关用户邻居,与此同时将其他剩下的用户视为当前用户的负相关用户邻居,在视图侧也进行相同的操作,为每个视图筛选出正相关邻居和负相关邻居;
步骤304,数据采样模块生成一组样本,一组样本由7部分组成,包括用户、用户偏好的视图、用户不偏好的视图、用户的正相关邻居、用户的负相关邻居、用户偏好的视图的正相关邻居、用户偏好的视图的负相关邻居;
步骤4,驾驶舱视图推荐系统的主模型和基于自监督对比学习构建的辅助模型根据采样数据,计算得到对应的损失函数L
步骤401,步骤3生成的采样数据传递给主模型和辅助模型,主模型运用BPR-loss的方法,求出损失函数L
上式中,u表示特定的用户,v
步骤402,步骤401中计算得到的主模型和辅助模型损失函数的加权求和之后得到整体模型的目标函数L,其中整体模型的目标函数的计算如下式所示:
上式中,σ表示激活函数sigmiod,λ
本发明所述方法为不同的用户和视图设置一个可训练的贡献权重参数,这个参数会在参数更新过程中不断自适应地更新,并且通过sigmoid激活函数映射到(0,1)区间内,再加权求和得到整体模型的目标函数L;
步骤5,驾驶舱视图推荐系统的参数更新模块,通过整体模型的目标函数L,采用一种双层的元辅助学习更新架构,在内层更新驾驶舱视图推荐主模型的参数以及用户、视图的特征向量,外层更新用户、视图的对比学习辅助模型的参数以及贡献系数λ
步骤501,在参数更新模块的内层,使用步骤4中得到的整体模型的目标函数L,固定辅助模型参数以及贡献系数λ
上式中,θ包括主模型的参数以及用户、视图的特征向量,
结合图2,参数θ和参数
步骤502,步骤501中更新后得到的参数
上式中,β表示学习率,d表示求全导数;
结合图2,在系统更新得到
上式中,γ表示正则化系数,d表示求全导,
步骤6,反复执行步骤3、步骤4、步骤5直至各个模型的参数不再发生改变;
步骤7,驾驶舱视图推荐系统的推荐模块通过用户以及视图的特征向量,计算用户对各种视图的偏好值,为不同的用户推荐不同的工业大数据驾驶舱视图:
用户u对视图v的偏好值通过用户u和视图v的特征向量的内积求得,推荐模块计算所有用户对于所有视图的偏好值,然后对于每一个用户来说,推荐偏好值前20高的视图。
在本发明所述方法中,对算法的实现过程中,用户和视图的特征向量的长度设为50,每次采样过程中抽选的样本数目为5000,学习率α,β为0.001,负采样的样本个数为2,隐式梯度方法中运用的共轭梯度算法步数为2,辅助模型中分别用来控制用户和视图的贡献系数λ
为了便于展示本发明所述方法在工业大数据驾驶舱视图场景下推荐的性能,本发明所述方法进行了详尽的功能测试,具体是在两个和工业大数据驾驶舱视图场景较为相似的数据集上进行测试,数据集选取分别为Amazon-Books(购买书籍推荐,简写为Books)和MovieLens-20M(推荐电影,简写为ML20m),具体的评价指标为如下的三个指标:
1.Top-K召回率(Recall@K,简写为R@K):衡量前K个推荐的为正样本视图的数目和视图库中所有的正样本视图数的比率,衡量的是推荐系统的查全率。
2.Top-K归一化折损累计增益(NDCG@K,简写为N@K):衡量所推荐的K个视图的排序结果,评价排序的准确性。
3.Top-K精确率(Precision@K,简写为P@K):衡量前K个推荐的视图为正样本的个数占总数的比例。
对于所有评价指标,本发明所述方法在K=5,10,15,20上进行了多重实验,使得实验数据更具有一般性,同时,为了证明本发明所述方法中所提出的框架能够显著提升主模型的推荐效果,采用了以下四个基准算法作为主任务:
MF:通过贝叶斯个性化排名来计算损失函数的一种基于矩阵分解的模型,这是一种学习成对视图排名的经典方法。
Multi-VAE:一种利用变分自动编码器(VAE)方法的、基于图1侧的推荐模型。
NGCF:一种基于图卷积的视图推荐模型,视图推荐模型使用二分图捕获用户-视图交互,并通过传播特征向量来学习高阶信息。
LightGCN:一种基于图神经网络的视图推荐模型,视图推荐模型通过在用户-视图交互图上进行多跳卷积来学习用户和视图的特征向量,并使用在不同深度的特征向量的加权和作为最终结果。
本发明所述方法进行了一系列的实验测试,将以上四种基准算法和带有本发明所述方法所提出的基于元辅助学习框架(MAL)的对应算法进行了一系列的对比,在保证所有其他参数一致的情况下,探讨本发明所述方法所提出的框架能够帮助模型推荐任务的表现做出多大的提升。
如下表1-3所示,展示了带有本发明所述方法所提出的基于元辅助学习框架(MAL)的模型比对应的原模型在推荐效果上的提升,从表1至-3看出,相比于基准算法,带有本发明所述方法所提出的框架的对应算法的推荐效果更好,所提出的基于元辅助学习框架(MAL)的模型整体在Top-K召回率上比相对应的模型提升了3%-35%,在Top-K归一化折损累计增益上比相对应的模型提升了4%-30%,在Top-K精确率上比相对的模型提升了3%-30%。
表1
表2
表3
同时,为了验证本发明所述方法所提出的用户和视图的个性化贡献参数能够有效地帮助整体模型更好地学习信息,在Amazon-Books数据集上做了一系列的实验,通过控制是否引入个性化权重来观察评价指标的改变。结合图5发现当为不同的用户和视图增加一个可学习的贡献参数时,三个评价指标在K取(5,10,15,20)时,都得到了提升,表明了可学习的贡献参数提供了一定的来源于用户和视图的个性化信息,使得整体模型能够更好地挖掘用户之间和视图之间的不同点,并作出推荐结果。
同时,为了验证所提出的双层元辅助学习更新架构能够有效地减少参数在更新过程中的计算量,本发明所述方法进行了一系列的实验,当采用梯度下降的方法对双层更新架构中内循环参数θ进行更新时,针对不同的梯度下降的步数,统计了更新外循环参数
通过观察本发明所述方法在各个数据集上进行实验的评价指标和运行时间,能够观察到以下规律:
1.得益于本发明所述方法所构建的基于自监督对比学习的辅助模型,结合该辅助模型之后,整体模型的推荐效果比相对应的单独模型的推荐效果做了很大的提升,这一现象表明了本发明所述方法提出的通过构建邻域之间用户侧和视图侧的互信息所设计的辅助模型涵盖了一些主模型中难以学到的隐含信息,在一定程度上缓解了数据稀疏的问题,使得整体模型达到更好的效果。
2.得益于本发明所述方法所提出的为不同的用户和视图构建的个性化贡献参数,整体模型能够学习到用户和视图的个性化信息,从而更好地为用户进行推荐。
3.本发明所述方法所提出的双层元辅助学习框架不但能够有效地结合辅助模型,使得整体模型的效果得到提升,还引导出了一个双层参数更新框架,在外循环的参数更新过程中有效地减少更新时间,避免了高阶导数的计算。
本发明并不限于上述实施方式,在不背离本发明实质内容的情况下,本领域技术人员可以想到的任何变形、改进、替换均落入本发明的保护范围。
- 面向混合采样工业大数据的基于多视图字典学习分类方法
- 面向混合采样工业大数据的基于多视图字典学习分类方法