用于与输出设备进行音频桥接的方法和系统
文献发布时间:2023-06-19 19:28:50
技术领域
本公开的一个方面涉及一种在用户的一个或多个回放设备与输出设备之间桥接音频回放的系统。还描述了其他方面。
背景技术
头戴受话器是包括一对扬声器的音频设备,当头戴受话器配戴在用户头部上或围绕用户头部配戴时,每个扬声器被放置在用户的耳朵上。类似于头戴受话器,耳机(或入耳式头戴受话器)是两个分开的音频设备,每个音频设备具有插入到用户耳朵中的扬声器。头戴受话器和耳机通常有线连接到单独的回放设备诸如数字音频播放器,该回放设备以音频信号驱动设备的每个扬声器以便生成声音(例如,音乐)。头戴受话器和耳机提供用户可凭借其来单独收听音频内容而不必将音频内容广播给附近其他人的一种方便的方法。
发明内容
本公开的一个方面是一种由包括第一扬声器的第一电子设备诸如头戴式耳机执行的方法。该第一设备经由计算机网络(例如,互联网)接收音频内容的表示。在第二电子设备正在通过第二扬声器回放音频内容时,第一设备确定第一设备正在移动远离该第二电子设备。响应于确定第一电子设备正在移动远离第二电子设备,使用该音频内容的表示来通过第一扬声器回放音频内容。
在一个方面,该音频内容的表示包括指示音频内容在第二电子设备处的回放状态的回放数据,并且使用音频内容的表示来回放音频内容包括:使用该回放数据来使由第一电子设备进行的音频内容的回放与回放状态同步。在另一方面,该方法还包括确定由第二扬声器产生的声音的声学飞行时间(ToF),该回放状态包括该音频内容的将要由第二电子设备回放的部分的时间戳,使用回放数据来使回放同步包括:在考虑该声学ToF的同时根据该时间戳通过第一扬声器回放该音频内容的该部分,使得该音频内容的该部分的由第二电子设备的第二扬声器产生的声音与该音频内容的该部分的由第一电子设备的第一扬声器产生的声音在由第一电子设备的用户感知到时是同步的。在一些方面,第一设备确定由第二扬声器产生的声音的声学飞行时间,其中该音频内容的该部分是在考虑该声学飞行时间的同时根据时间戳回放的。
在一个方面,第一电子设备在第二电子设备回放音频内容之后回放音频内容。在另一方面,由第一电子设备和第二电子设备两者进行的回放由握持着或穿戴着第一电子设备的用户感知为同步的,而第一电子设备和第二电子设备两者异步地回放音频内容。
在一个方面,第一设备基于该音频内容的表示来确定音频内容的目标声级,并且确定由第二电子设备回放的音频内容的声音在第一电子设备的麦克风处的声级,其中使用该音频内容的表示来通过第一扬声器回放音频内容包括:基于该声级在满足该目标声级的等级下通过第一扬声器回放音频内容。在一些方面,在满足该目标声级的等级下通过第一扬声器回放音频内容包括:在第一电子设备正在移动远离第二电子设备时,根据确定音频内容的声音在麦克风处的声级已改变,调整满足目标声级的等级以补偿声级的变化。在另一方面,调整满足目标声级的等级包括:基于声级与声级的变化之间的差异将音量调整应用于第一电子设备。在一个方面,在第一电子设备移动远离第二电子设备时,提高满足目标声级的等级。
在一个方面,根据确定第一电子设备正在朝向第二电子设备移动,第一设备降低第一扬声器的声音输出等级。在另一方面,使用该音频的表示来回放音频内容包括:使用具有音频内容的音频信号来驱动第一扬声器,其中降低第一扬声器的声音输出等级包括:在第一电子设备朝向第二电子设备移动时,基于由第二电子设备回放的音频内容的声音在第一电子设备的麦克风处的声级的变化来衰减音频信号在第一扬声器处的信号等级。在一些方面,根据确定第一电子设备已移动到距第二电子设备阈限距离内,第一设备通过停止使用音频信号驱动第一扬声器来停止音频内容通过第一扬声器的回放。
在一个方面,根据确定第一电子设备正在朝向正在通过第三扬声器回放音频内容的第三电子设备移动,第一设备降低第一扬声器的声音输出等级。在一些方面,第一电子确定第二电子设备相对于第一电子设备的位置;并且根据该位置在空间上渲染音频内容以通过第一扬声器产生包括音频内容的虚拟声源。在另一方面,第一电子设备经由无线连接与第二电子设备通信地耦接,并且其中确定第一电子设备正在移动远离第二电子设备包括:基于该无线连接的接收信号强度指示符(RSSI)来标识第一电子设备相对于第二电子设备的位置;并且基于该RSSI的变化来确定第一电子设备正在移动远离该位置。在一些方面,第一设备确定由第二电子设备回放的音频内容的声音在第一电子设备的麦克风处的声级,其中确定第一电子设备正在移动远离第二电子设备包括:检测该声音的声级正在以特定速率降低。
在一个方面,该第一电子设备是可穿戴设备。在另一方面,该可穿戴设备是一副智能眼镜,并且该第一扬声器是耳外式扬声器。在另一方面,该第一电子设备是头戴式耳机。在一些方面,该第二电子设备是智能扬声器。在另一方面,该第二电子设备是电视机。在一个方面,该音频内容的表示包括该音频内容。在另一方面,该音频内容的表示包括该音频内容的标识。在一些方面,使用该音频内容的表示来回放音频内容包括:使用该音频内容的该标识来从远程电子服务器或该第一电子设备的本地存储器检索音频信号,其中该音频信号包括音频内容;以及使用音频信号来驱动第一扬声器以产生音频内容的声音。
以上概述不包括本公开的所有方面的详尽列表。可预期的是,本公开包括可由上文概述的各个方面以及在下文的具体实施方式中公开并且在权利要求书中特别指出的各个方面的所有合适的组合来实践的所有系统和方法。此类组合可具有未在上述发明内容中具体阐述的特定优点。
附图说明
在附图的图示中通过举例而非限制的方式示出了多个方面,在附图中类似的附图标号指示类似的元件。应当指出的是,在本公开中提到“一”或“一个”方面未必是同一方面,并且其意指至少一个。另外,为了简洁以及减少附图的总数,某个附图可能被用于示出不止一个方面的特征,并且对于某个方面,可能并不需要该附图中的所有元素。
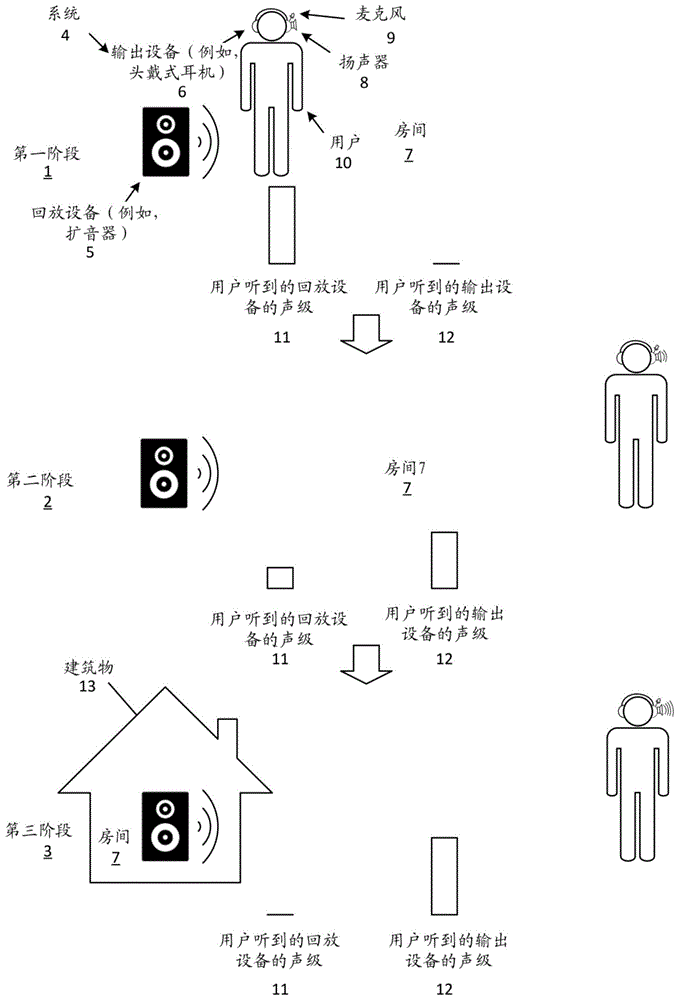
图1示出了系统的若干阶段,其中输出设备正在作为音频桥接设备进行操作,该音频桥接设备正在回放正在由回放设备回放的相同音频内容,以便在用户移动远离回放设备时维持由用户听到的音频内容的声级。
图2示出了根据一个方面的包括彼此通信地耦接的回放设备和输出设备的系统。
图3示出了正在与回放设备桥接音频回放的输出设备的框图。
图4是输出设备在输出设备移动远离回放设备时与回放设备桥接音频回放的过程的一个方面的流程图。
图5是输出设备在输出设备朝向回放设备移动时与回放设备桥接音频回放的过程的一个方面的流程图。
图6是输出设备与回放设备桥接音频回放的过程的一个方面的流程图。
图7示出了根据一个方面的若干阶段,其中输出设备在用户在正在回放音频内容的两个单独回放设备之间移动时维持由用户听到的声级。
具体实施方式
现在将参考所附附图来解释本公开的各方面。只要在某个方面中描述的部件的形状、相对位置和其他方面未明确限定,这里本公开的范围就不仅仅局限于所示出的部件,所示出的部件仅用于说明的目的。另外,虽然阐述了许多细节,但应当理解,一些实施方案可在没有这些细节的情况下被实施。在其他情况下,未详细示出熟知的电路、结构和技术,以免模糊对该描述的理解。此外,除非该含义明确相反,否则本文示出的所有范围被认为包括每个范围的端值。
现今,存在许多将音频内容(例如,音乐、播客等)回放到周围环境中的消费产品。例如,产品诸如智能扬声器可链接到允许智能扬声器流式传输音乐的在线音乐流媒体平台。一个人可购买智能扬声器并将其定位在此人家中收听者可最享受由扬声器回放的音乐的位置处(例如,厨房、客厅、卧室内等)。然而,声音输出可能限制在特定范围内,该特定范围可基于智能扬声器的装备限制(例如,智能扬声器的扬声器驱动器的大小、功率容量等)和/或物理环境(例如,在其中播放声音的房间的大小和形状)。例如,当放置在厨房中时,收听者可能能够在烹饪时听到声音输出,但在相邻客厅中时可能无法听到声音输出(或者可能能够模糊地听到声音)。因此,当一个人在家中四处移动(例如,在厨房与相邻客厅之间移动)时,此人可间歇性地听到由智能扬声器产生的声音,这可能不利地影响此人的收听体验,因为此人将仅听到音频内容的部分。当收听播客或有声读物时情况可能尤其如此,收听者在进出厨房时可能错过播客或有声读物的重要(或相关)部分。
为了解决此问题,本公开描述了一种输出设备(例如,头戴式耳机),该输出设备与回放设备(例如,智能扬声器)桥接音频回放以向用户提供一致收听体验。例如,在智能扬声器回放音频内容时,输出设备(其可由在回放设备附近的用户穿戴或握持)可确定输出设备正在移动远离回放设备。例如,输出设备可经由无线连接通信地耦接到回放设备,并且基于无线连接的接收信号强度指示符(RSSI)确定输出设备正在移动远离。又如,该确定可基于声级(例如,由输出设备的麦克风捕获)正在降低(或渐弱),这可指示输出设备正在移动远离。响应于确定输出设备正在移动远离回放设备,输出设备可随着输出设备移动远离回放音频内容。在这种情况下,由输出设备产生的声音可补偿由输出设备的用户感知到的由回放设备产生的声音的降低,该降低是由于用户移动远离回放设备造成的。因此,输出设备可维持用户感知的音频回放,从而获得一致且令人愉悦的收听体验。
图1示出了系统4的三个阶段1-3,其中由用户10穿戴着的(例如,音频)输出设备6正在作为音频桥接设备进行操作,该音频桥接设备被布置为回放正在由回放设备5回放的相同音频内容,以便在用户移动远离回放设备5时维持由用户听到的音频内容的声级。如本文所述,“音频桥接设备”可以是任何电子设备,该任何电子设备可被配置为回放正在由一个或多个回放设备(例如,扩音器)回放(例如,回放到周围环境中)的相同(类似或不同)音频内容,以便桥接设备补偿由正在移动远离回放设备5和/或朝向回放设备移动的用户感知到的回放设备5的音频回放的变化(例如,正在由回放设备回放的音频内容的声级的变化)。换句话讲,输出设备6补偿由用户感知到的所回放的音频内容的表观响度的变化。本文描述了关于输出设备6如何桥接音频回放的更多内容。
如图所示,此图中的每个阶段示出了被示出为(例如,独立)扩音器的回放设备5,和穿戴着输出设备6的用户10,该输出设备被示出为穿戴在用户头部上的头戴式耳机(例如,开背式头戴受话器)。如图所示,回放设备5正在回放音频内容(例如,音频内容被示出为扩展远离设备的线)。具体地,回放设备5可正在使用一个或多个音频信号来驱动一个或多个扬声器(例如,集成在回放设备5的壳体内)将音频信号(包含在音频信号内的音频内容)的声音产生(或投射)到周围环境(例如,回放设备5所在的房间7)中,该一个或多个音频信号中的每个音频信号具有音频内容的至少一部分。在一个方面,扬声器正在回放的音频内容可以是一段用户期望的音频内容,诸如音乐作品、播客、有声读物、电影原声等。在一个方面,内容可以是“用户期望的”,使得系统4(例如,其回放设备5)已接收到用于(例如,开始)通过回放设备的扬声器回放音频内容的用户输入(例如,经由语音命令、对物理按钮的选择等)。在另一方面,回放设备5可响应于从设备通信地耦接到的另一电子设备接收到指令而开始回放。例如,回放设备5可从输出设备6接收用于回放音频内容的指令,该输出设备可能已接收到用户输入(例如,经由语音命令)。在一个方面,回放设备5可正在流式传输音频内容(例如,通过因特网)和/或可正在从设备的本地存储器或从远程存储器设备(例如,远程服务器)检索内容。本文描述了关于回放设备5如何回放音频内容的更多内容。
如图所示,头戴式耳机包括扬声器8和麦克风9(它们是头戴式耳机的左壳体或耳罩的一部分或集成到该左壳体或耳罩中)。如图所示,扬声器是被布置为将声音投射到周围环境中的“耳外式”扬声器。在一个方面,头戴式耳机可被布置为允许用户听到来自周围环境的声音和/或由耳外式扬声器产生的声音。具体地,头戴式耳机可被设计为允许声音穿过耳罩并进入用户的耳朵。例如,头戴式耳机可以是开背式头戴受话器,该开背式头戴受话器(例如,具有一个或多个开口)允许来自周围环境的声音穿过头戴式耳机(例如,其壳体)进入用户的耳朵。
在另一方面,输出设备6可执行一个或多个音频信号处理操作以允许用户听到周围声音。在这种情况下,扬声器8可以是布置在输出设备6的壳体(例如,耳罩)内部并且被布置为将声音投射到用户的耳朵中(或朝向耳朵投射)的“内部”扬声器。输出设备6可执行透明功能,其中由输出设备6的一个或多个内部扬声器回放的声音是由设备的麦克风以“透明”方式(例如,好像用户没有穿戴输出设备6那样)捕获的周围声音的再现。输出设备6(例如,其控制器,如图2所示)可处理由麦克风捕获的至少一个麦克风信号并且通过透明滤波器对信号进行滤波,这可减少由于音频输出设备6位于用户的耳朵上、其中或其之上引起的声学阻塞,同时还保留了穿戴者的解剖特征(例如,头部、耳廓、肩部等)的空间滤波效果。滤波器还有助于保留与实际环境声音相关联的音色和空间提示。在一个方面,根据用户头部的特定测量结果,透明功能的滤波器可以是特定于用户的。例如,输出设备6可根据基于用户的人体测量结果的头部相关传递函数(HRTF)或等效的头部相关脉冲响应(HRIR)来确定透明滤波器。因此,用户可经由输出设备6的至少一部分听到由回放设备5和/或扬声器8产生的声音。
此外,每个阶段示出了由用户感知到的由两个设备产生的声音的若干声级(例如,声压级(SPL)dB)。特别地,每个阶段示出了由用户10听到(或由收听者在收听者的位置处听到)的回放设备5的声级11和由用户10听到的输出设备6的声级12。在一个方面,这两个等级表示由两个设备产生的声音在用户耳朵(或双耳)处(或其附近)的声压。在另一方面,这些等级可表示由输出设备6的一个或多个麦克风(例如,麦克风9)测量(或感知)的声压级。在另一方面,这些等级表示由用户10感知到的由相应设备产生的声音的量(例如,百分比)。在一些方面,声级12可与扬声器8的声音输出等级相同。在另一方面,由于扬声器8与用户耳朵中的一只或多只耳朵相距一定距离,因此声级12可小于扬声器的声音输出等级。在这种情况下,扬声器的声音输出等级可高于由用户感知到的声音输出等级,以便补偿用户耳朵与扬声器(例如,其膜片)之间的距离。
第一阶段1示出了穿戴着输出设备6的用户10在回放设备5附近(例如,在回放设备的阈限距离内),并且正在房间7内主要收听正在由回放设备5回放的声音。具体地,用户仅(或主要)收听回放设备5,而输出设备6未在产生任何(或正在产生极少)(例如,正在由回放设备5回放的音频内容的)声音。这通过回放设备5的声音的声级11高(例如,处于最大声级阈限)而声级12低(例如,低于最小声级阈限)示出。在一个方面,此阶段中的声级12可指示输出设备6未在产生正在由回放设备5回放的音频内容的任何声音。在另一方面,虽然输出设备6可未在回放音频内容,但设备可替代地产生其他声音。
在一个方面,声级11可以是用户10感知到的声音的目标声级。具体地,这可以是收听者希望听到正在由回放设备5产生的声音所处的等级。在一个方面,目标声级可在回放设备5开始音频回放时限定。例如,目标声级可对应于回放设备5在设备开始输出声音时的音量等级。在另一方面,目标声级可以是从由麦克风9捕获的麦克风信号测量的声级。例如,一旦回放设备5开始回放,就可测量声级,如本文所述。又如,声级可基于用户输入(例如,在输出设备6处)来测量。本文描述了关于目标声级的更多内容。
第二阶段2示出了用户10已移动远离回放设备5(例如,超出阈限距离),但两者仍在同一房间中(例如,用户可正在朝向门移动以离开房间)。具体地,用户正在移动远离回放设备5,而回放设备5继续回放音频内容。由于越来越远,声级11降低(例如,下降至声级在第一阶段1中所处等级的25%)。在一个方面,在回放设备5与用户之间的距离加倍时,来自点源的声压可降低至少50%。例如,如果用户与回放设备5之间的距离在第一阶段1与第二阶段2之间加倍,则声级可降低至少6dB。
在一个方面,在确定输出设备6(和/或用户)正在移动远离回放设备5时,输出设备6可被配置为(例如,开始)通过扬声器8回放音频内容。具体地,输出设备6可回放与回放设备5相同的音频内容,以便使回放设备5和输出设备6的组合声音输出维持第一阶段1中的声级11(例如,其目标声级)。为了实现这一点,可使由回放设备5产生的声音和由扬声器8产生的声音在由输出设备6的用户10感知到时是同步的。在这种情况下,用户可能无法辨别或区分由回放设备5产生的声音和/或由输出设备6产生的声音,而是将两个设备的声音感知为源自(例如,同一)声源。这可以是由于由两个设备产生的声音在收听者的位置处(或其附近)(或更具体地,在用户的耳朵处)的相长干涉。
如本文所述,输出设备6可回放音频内容,以便补偿声级11的降低。如图所示,随着用户移动远离回放设备5,声级11与用户在第一阶段中更靠近设备时相比已降低。在这种情况下,输出设备6基于声级11的改变来调整由扬声器8产生的声音的声音输出等级。例如,输出设备6可(例如,开始音频回放和/或)应用音量调整(例如,提高音量)以便提高声音输出,如此图中由从扬声器8发出的曲线所示。因此,声级12已从如第一阶段1中所示的较低等级提高。在一个方面,提高可基于阶段1的目标声级11与第二阶段2中的(当前或新)声级11之间的差异。特别地,输出设备6随着声级11的降低按比例提高声级12。因此,第二阶段2中的声级12和11的组合等于(或近似于)阶段1的声级11。因此,在用户移动远离回放设备5时,用户不会感知到(表观)声级的变化。本文描述了关于输出设备6如何补偿声音输出的更多内容。
第三阶段3示出了用户不再位于包括回放设备5的房间7内(例如,已移动超出阈限距离)。具体地,用户已移动到容纳正在继续回放音频内容的回放设备5的建筑物13之外。由于移动到离回放设备5很远的地方,用户听不到(或模糊地听到)回放设备5的声级11(例如,用户已移动到回放设备5的声学可听范围之外)。此外,输出设备6的声级12已提高以便补偿回放设备5的低声级,这在此图中示出为从扬声器8发出的曲线的数量与第二阶段2中的线的数量相比已增加。具体地,输出设备的声级现在与阶段1中的声级11相同(或类似)。因此,贯穿阶段1-3,声级11和12的组合是相同的(例如,由第一阶段1中的目标声级限定),并且因此在用户移动远离回放设备5时,用户感知到音频内容的连续且不间断的声级。
如迄今为止所述,在用户移动远离回放设备5时,输出设备6可提高声音输出以便补偿声级11的降低。在一个方面,在用户朝向回放设备5移动时,输出设备6可降低声音输出。在这种情况下,在用户朝向回放设备5移动时,声级11提高,并且因此输出设备6可降低扬声器的声音输出等级,以便降低由用户感知到的声音的声级12。
图2示出了根据一个方面的包括彼此通信地耦接的回放设备5和输出设备6的系统4。在一个方面,回放设备5可以是被配置为回放音频内容和/或执行联网操作的任何电子设备。如图所示,回放设备5是扩音器。在另一方面,回放设备5可包括独立扬声器、智能扬声器、家庭影院系统(作为其一部分的元件)或集成在车辆内的信息娱乐系统。在另一方面,回放设备5可以是台式计算机、膝上型计算机、数字媒体播放器、电视机等。在一个方面,设备5可以是便携式电子设备(例如,可手持式操作),诸如平板计算机、智能电话等。
如图所示,回放设备5包括控制器20、网络接口22和扬声器21。在一个方面,回放设备5可包括更多或更少的元件,诸如具有两个或更多个扬声器。在一个方面,网络接口22被配置为与一个或多个其他电子设备诸如输出设备6建立(例如,无线)通信链路(或连接),以便交换数字数据。在一个方面,扬声器21可以是例如可被专门设计用于特定频带的声音输出的电动驱动器,诸如低音扬声器、高音扬声器或中音驱动器。在一个方面,扬声器21可以是“全音域”(或“全频”)电动驱动器,其尽可能多地再现可听频率范围。在一个方面,扬声器21是被配置为将声音输出到周围环境中的耳外式扬声器。在一个方面,扬声器21可以是集成到回放设备5(例如,其壳体)中的“设备内”扬声器。例如,当回放设备5是电视机时,设备可包括集成到电视机中的一个或多个扬声器。
控制器20可以是专用处理器诸如专用集成电路(ASIC)、通用微处理器、现场可编程门阵列(FPGA)、数字信号控制器或一组硬件逻辑结构(例如滤波器、算术逻辑单元和专用状态机)。控制器被配置为执行音频信号处理操作和/或联网操作。例如,控制器20可被配置为(例如,通过网络23经由网络接口22)检索音频内容(例如,包括音频内容的一个或多个音频信号),并且使用音频信号来驱动扬声器21以输出音频内容的声音。在另一方面,控制器被配置为执行联网操作,诸如(经由网络23)与输出设备6通信。本文描述了关于由控制器20执行的操作的更多内容。
如图1所示,输出设备6可以是被设计成穿戴在收听者(例如,用户10)(例如,其头部)上或由收听者穿戴的头戴式耳机。在另一方面,输出设备6可以是包括至少一个扬声器(并且包括至少一个麦克风)并且被配置为通过用一个或多个音频信号驱动扬声器来回放音频内容的任何电子设备。例如,设备6可以是被设计成定位在用户的耳朵上(或其中)并且被设计为将声音输出到用户的耳道中的无线头戴式耳机(例如,入耳式头戴受话器或耳塞)。在一些方面,耳机可以是具有柔性耳机末端的密封类型,该柔性耳机末端用于通过阻挡或闭塞在耳道中来相对于周围环境在声学上密封用户的耳道的入口。在这种情况下,输出设备6可包括用于用户左耳的左耳机和用于用户右耳的右耳机。在这种情况下,每个耳机可被配置为输出媒体内容的至少一个音频声道(例如,右耳机输出立体声录音(诸如音乐作品)的双声道输入的右音频声道并且左耳机输出左音频声道)。在另一方面,输出设备6可以是包括至少一个扬声器并且被布置为由用户穿戴并且被布置为通过用音频信号驱动扬声器来输出声音的任何电子设备。又如,输出设备6可以是至少部分地覆盖用户耳朵并且被布置为将声音引导至用户耳朵中的任何类型的头戴式耳机,诸如包耳式(或耳上)耳机。
在另一方面,输出设备6可以是被配置为回放音频内容的任何类型的可穿戴电子设备。例如,输出设备6可以是一副智能眼镜或智能手表。在另一方面,输出设备6可以是类似于关于回放设备5描述的那些设备的设备。例如,输出设备6可以是智能电话。在另一方面,输出设备6可以是被配置为将经放大周围声音产生到用户的耳朵(例如,耳道)中的助听设备。
如图所示,输出设备6包括控制器24、一个或多个传感器26,该一个或多个传感器包括麦克风9、相机28和惯性测量单元(IMU)29、扬声器8和显示屏27。在一个方面,输出设备6可包括更多或更少的元件。例如,输出设备6可包括更多传感器(例如,温度传感器、加速度计、接近传感器等)。在另一方面,输出设备6可包括两个或更多个元件,诸如具有两个或更多个麦克风、扬声器和/或显示屏。
在一个方面,一个或多个传感器26被配置为检测环境(例如,输出设备6位于其中)并且基于环境产生传感器数据。麦克风9可以是被配置为将由在声学环境中传播的声波导致的声能转换成麦克风信号的任何类型的麦克风(例如,差分压力梯度微机电系统(MEMS)麦克风)。如本文所述,麦克风9可以是被布置为感测周围声音的(例如,参考)麦克风。在另一方面,麦克风9可以是被布置为在用户穿戴着输出设备6时捕获用户耳道内的声音的误差(或内部)麦克风。在一些方面,输出设备6可包括两种类型的麦克风的中的至少一种麦克风。
在一个方面,相机28是互补金属氧化物半导体(CMOS)图像传感器,该CMOS图像传感器能够捕获数字图像包括表示相机的视场的图像数据,其中视场包括设备6所处的环境的场景。在一些方面,相机可以是电荷耦合器件(CCD)相机类型。该相机被配置为捕获由一系列数字图像表示的静态数字图像和/或视频。在一个方面,相机可被定位在设备周围的任何地方。在一些方面,设备可包括多个相机(例如,其中每个相机可具有不同视场)。IMU 29可以是被设计为测量输出设备6的位置和/或取向的电子设备。
显示屏27(或显示器)被设计为呈现(或显示)视频(或图像)数据的数字图像或视频。在一个方面,显示屏27可使用液晶显示器(LCD)技术、发光聚合物显示器(LPD)技术或发光二极管(LED)技术,但在其他方面可使用其他显示技术。在一些方面,显示器27可以是被配置为感测用户输入作为输入信号的触敏显示屏。在一些方面,显示器可使用任何触摸感测技术,包括但不限于电容、电阻、红外和表面声波技术。
如本文所述,这些设备中的每一个设备可包括一个或多个元件。在一个方面,这些元件中的至少一些元件可以是每个相应设备的壳体的一部分(或集成在壳体内)。在另一方面,设备中的任一设备可包括本文所述的一个或多个元件。例如,回放设备5可包括一个或多个显示屏、一个或多个麦克风和/或一个或多个相机。在另一方面,不是(或除了)使元件集成在每个设备内,而是元件中的一个或多个元件可以是与控制器通信地耦接(例如,经由网络接口)的单独电子设备。例如,麦克风9可以是(例如,无线地)通信地耦接到控制器24的单独设备(的一部分),该单独设备将一个或多个麦克风信号(作为音频数字数据)传输到控制器。
在一个方面,输出设备6可被配置为经由网络23与回放设备5通信地耦接,使得两个设备可被配置为彼此通信。在一个方面,网络可以是任何类型的计算机网络,诸如广域网(WAN)(例如,互联网)、局域网(LAN)等,通过该网络,设备可彼此交换数据和/或可与一个或多个其他电子设备诸如远程电子服务器交换数据。在另一方面,网络可以是无线网络诸如无线局域网(WLAN)、蜂窝网络等,以便交换数字(例如,音频)数据。关于蜂窝网络,输出设备6可被配置为建立无线(例如,蜂窝)呼叫,其中蜂窝网络可包括一个或多个小区塔,该一个或多个小区塔可以是通信网络(例如,4G长期演进(LTE)网络)的一部分,该通信网络支持电子设备诸如移动设备(例如,智能手机)的数据传输(和/或语音呼叫)。在另一方面,设备可被配置为经由其他网络诸如无线个域网(WPAN)连接无线地交换数据。例如,输出设备6可被配置为经由无线通信协议(例如,蓝牙协议或任何其他无线通信协议)与回放设备5建立无线连接。在所建立的无线连接期间,设备可交换(例如,发射和接收)具有数字(例如,音频)数据的数据分组(例如,互联网协议(IP)分组),该数字数据可包括正在由回放设备5回放的音频内容的表示。
如本文所述,控制器20和/或24被配置为执行数字信号处理操作,诸如音频信号处理操作和联网操作。在一个方面,由控制器执行的操作可在软件中实现(例如,作为存储在存储器中并由控制器执行的指令)并且/或者可由如本文所述的硬件逻辑结构实现。
图3示出了正在与回放设备5桥接音频回放的输出设备6的框图。具体地,输出设备6正在通过扬声器8回放也正在由回放设备5回放(例如,通过扬声器21,如图2所示)的音频内容,以便维持由输出设备6的用户感知到的音频内容的(例如,目标)声级。在一个方面,可在握持着或穿戴着输出设备6的用户10(例如,将要或正在)移动远离回放设备5(或朝向回放设备移动)时执行本文所述的操作。
如图所示,回放设备5正在通过用包括一段音频内容的一个或多个音频信号驱动一个或多个扬声器(例如,扬声器21)来回放音频内容。在一个方面,回放设备5可正在基于用户指令回放音频内容。例如,回放设备5可已(例如,从输出设备6的用户10)接收到用于发起回放的用户输入。例如,回放设备5可已经由一个或多个输入设备诸如回放设备5的一个或多个(例如,物理)按钮接收到用户输入。在另一方面,回放设备5可接收用户的用于回放音频内容的语音命令(例如,由回放设备5的麦克风捕获)。在这种情况下,回放(例如,其控制器20)可分析麦克风的麦克风信号以检测其中包含的言语。一旦检测到,控制器就可确定言语是否包括(例如,用于回放音频内容的)语音命令。如果是,则回放设备5可开始回放。在另一方面,可已经由对显示在显示屏(未示出)上的图形用户界面(GUI)中的用户界面(UI)项目的用户选择接收到用户输入,该UI项目在被选择时将控制信号传输到控制器以回放音频内容。
如迄今为止所述,回放设备5可经由耦接到回放设备5的一个或多个输入设备接收用户输入。在另一方面,可从通信地耦接到回放设备5的另一电子设备接收用户输入。例如,输出设备6可接收用于指示回放设备5(例如,开始)音频回放的用户输入。返回到前一示例,用户可选择显示在显示屏27上的GUI中的UI项目。一旦被选择,输出设备6就可将控制消息(例如,经由网络23)传输到回放设备5,从而指示控制器20开始(或恢复)流式传输音频内容(例如,通过网络23)以供回放。
控制器24包括用于执行用于与回放设备5桥接音频内容回放的音频信号处理操作的一个或多个操作块。例如,控制器包括回声消除器31、回放同步器32、声级估计器33、内容提取器34和音频渲染器35。如图所示,控制器24被配置为(经由网络23)从回放设备5接收回放数据30。例如,在回放设备5回放音频内容时(或之前),设备可与输出设备6建立(例如,无线)连接,并且将回放数据作为一个或多个数据(例如,互联网协议(IP))分组传输。在一个方面,回放数据可以是(或包括)音频内容的表示。特别地,数据可包括描述音频内容的元数据,诸如音频内容的标识。例如,当音频内容是音乐作品时,标识可描述作品,诸如包括音乐作品的名称、流派、艺术家等。在另一方面,标识可以是唯一地标识音频内容的唯一标识符。
在另一方面,回放数据可包括正在由回放设备5回放的音频内容的(例如,当前)回放状态。在一个方面,回放状态可指示音频内容是否当前正在由回放设备播放,或音频内容是否已暂停或停止(例如,基于用户输入)。例如,当回放数据指示内容已暂停或停止时,输出设备6也可暂停或停止回放。在另一方面,回放状态可包括一个或多个时间戳,该一个或多个时间戳指示正在由回放设备5回放的音频内容的定时特性。例如,回放状态可包括将要(或正在)由回放设备5回放的音频内容的一部分(或音频内容的未来部分)的内容时间时间戳。例如,内容时间时间戳可指示相对于音频内容的整个回放持续时间的回放时间(例如,时间戳指示将要回放的音频内容的一部分处于具有三分钟长回放持续时间的音乐作品的两分钟标记处)。
在另一方面,回放状态可包括内容启动时间戳,该内容开起时间戳可指示开起时间(例如,回放设备5和/或输出设备6起始或开始回放音频内容的时刻)。在一些方面,开起时间可以是相对于两个设备之间的共享时钟(或由其限定),该共享时钟允许两个设备同步回放(例如,在由一个或多个收听者感知到时,如本文所述)。在一个方面,两个设备可经由任何时间同步方法使(例如,内部)时钟同步或共享时钟。例如,为了使时钟同步,设备可使用任何时间同步协议(例如,IEEE 802.1AS协议)交换同步消息,这些同步消息可包括在回放数据内或与回放数据分离(例如,包括在内容开起时间戳内)。在另一方面,设备可使用两个设备从网络时间协议(NTP)服务器(例如,经由网络23)获得的信息使内部时钟同步。在一些方面,设备可响应于回放设备5接收到用于发起(或回放)音频内容的用户输入而使时钟同步。
在一些方面,回放状态可包括当前回放时间戳,该当前回放时间戳指示回放设备5将要(或正在)回放音频内容的一部分的沿着共享时钟的时间。具体地,当前回放时间戳可指示相对于共享时钟将要在何时回放音频内容的可与回放状态相关联的部分。例如,当前回放状态可将沿着共享时钟的时间与内容时间时间戳相关联,因为当前回放时间戳指示沿着共享时钟将要在何时回放音频内容的与一个或多个内容时间时间戳相关联的部分。在一个方面,本文所述的时间戳中的一个或多个时间戳可允许输出设备6与回放设备5同步回放(例如,在由一个或多个收听者感知到时)。
在另一方面,回放状态可指示音频内容(和/或回放设备5)的其他特性。例如,它可包括正在由回放设备5回放的音频内容的音量等级(或声音输出等级)。具体地,音量等级可以是收听者希望听到回放设备5的声音输出所处的用户限定的音量等级。在另一方面,这些特性可指示正在对正在回放的音频内容(例如,音频内容的一个或多个音频信号)执行的音频信号处理操作,诸如是否正在执行均衡操作或动态范围压缩。在另一方面,除了(或代替)包括本文所述的数据中的至少一些数据,回放数据30还可包括正在(或将)由回放设备5回放的音频内容(的至少一部分)。例如,回放数据可包括呈任何音频格式的音频内容的一个或多个音频信号(例如,作为数字音频数据)。
如迄今为止所述,回放数据30可由输出设备6从回放设备5接收。例如,一旦回放起始,回放设备5就可开始传输回放数据30。在一些方面,回放设备5可在回放音频内容的同时传输回放数据。在另一方面,回放数据30的至少一些数据可由输出端(和/或回放设备5)通过一个或多个其他设备接收。例如,设备中的任一设备可从电子远程服务器接收回放数据,该电子远程服务器可被配置为将音频内容流式传输到设备。在这种情况下,服务器可传输一个或多个时间戳、关于音频内容的元数据、和/或特性。
内容提取器34被配置为接收回放数据30,并且被配置为提取(或检索)与回放数据相关联的音频内容。如本文所述,回放数据可包括与正在由回放设备5回放的音频内容相关联的标识符,并且可包括指示音频内容的由(或将由)回放设备5回放的部分的(例如,内容时间)时间戳。内容提取器34可使用此信息(的至少一部分)来检索由(或将由)回放设备5回放的音频内容(例如,其一个或多个音频信号)。在一个方面,内容提取器34可从远程电子设备(例如,经由网络23从远程服务器)和/或从第一电子设备的本地存储器检索音频信号。在一个方面,内容提取器34可将所检索的音频内容的一个或多个音频信号供应到音频渲染器35,该音频渲染器可使用一个或多个音频信号来驱动扬声器8产生音频内容的声音。本文描述了关于音频渲染器35的更多内容。
回声消除器(或消除器)31被配置为从麦克风9接收包括由麦克风捕获的周围声音(该周围声音可包括由回放设备5产生的音频内容的声音)的至少一个麦克风信号,并且被配置为减少(或消除)来自麦克风信号的回声线性分量,这些回声线性分量可由扬声器8产生的声音引起。如本文所述,输出设备6可被配置为通过扬声器8回放音频内容。连同捕获由回放设备5产生的声音,麦克风还可捕获由扬声器8产生的声音。因此,回声消除器31使用由音频渲染器35用于驱动扬声器8的音频信号(驱动器信号)作为参考输入对麦克风信号执行声学回声消除过程,以产生线性回声估计,该线性回声估计表示由麦克风9产生的麦克风信号中有多少(由扬声器8输出的)驱动器信号的估计。在一个方面,消除器31确定线性滤波器(例如,有限脉冲响应(FIR)滤波器),并且将滤波器应用于驱动器信号以生成线性回声的估计,该估计被从麦克风信号减去。所得的经回声消除的信号可包括由回放设备5产生的声音。在一些方面,回声消除器31可使用任何回声消除方法。
回放同步器32被配置为使输出设备6的回放与回放设备5的回放同步。具体地,同步器32确定(或估计)用于回放音频内容的时间对准,该时间对准使得由扬声器8产生的音频内容的声音与回放设备5的声音在(或大约在)相同时间到达用户的位置,使得两个设备的回放在由输出设备6的用户感知到时是同步的(例如,由两个设备产生的声音彼此相长干涉)。因此,控制器24可使用所估计的时间对准来使由输出设备6回放的音频内容的(例如,未来)部分与由回放设备5回放的相同部分同步。
在一个方面,时间对准考虑了由回放设备5产生的声音到达输出设备6的用户10(和/或被其听到)所花费的时间。具体地,时间是声学飞行时间(ToF),该声学飞行时间是由回放设备5产生的声音行进穿过周围环境并到达输出设备6(例如,其麦克风9)所花费的时间段。因此,输出设备6可根据时间对准而晚于回放设备5回放音频内容,使得两个设备的声音在(大约在)相同时间到达用户。因此,收听者感知到设备的同步回放,而两个设备实际上异步地回放音频内容。本文描述了关于同步回放的更多内容。
在一个方面,同步器32被配置为接收回放数据30(的至少一部分),该回放数据指示正在由回放设备5回放的音频内容的当前回放状态。例如,回放状态可包括当前回放时间戳,该当前回放时间戳指示回放设备5正在回放音频内容的一部分(例如,音频内容的长回放持续时间)的沿着两个设备的共享时钟的时间。在另一方面,同步器32可从内容提取器34接收所检索的音频内容(的至少一部分)(例如,作为至少一个音频信号)。具体地,回放同步器32可接收音频内容的与回放数据(例如,其当前回放状态)相关联的部分。例如,所接收的音频内容可以是根据当前回放状态将要由回放设备5回放的部分。在一个方面,所接收的音频内容可跨越一定时间段(例如,一秒、一分钟等),该时间段包括沿着与所接收的回放数据相关联的音频内容的回放持续时间的时间(或在该时间处开始)。特别地,所接收的音频内容可在与跟回放数据的当前回放状态相关联的内容时间时间戳相关联的时间处开始。在另一方面,同步器32可接收(经回声消除的)麦克风信号,该麦克风信号包括所捕获的周围环境的声音(例如,以及由回放设备5产生的音频内容的声音)。
在一个方面,同步器32使用所接收的数据(中的至少一些数据)来确定(或估计)声学ToF。具体地,输出设备6可接收回放数据30,该回放数据指示相对于设备的共享时钟回放设备5将立即回放音频内容的一部分(例如,根据与回放数据相关联的回放状态)。然而,由于声学传输时间大于通过网络的传输时间(例如,经由蓝牙连接),因此由回放设备5产生的声音可晚于所接收的回放数据到达输出设备6。在一个方面,同步器32可将(例如,经回声消除的)麦克风信号(例如,其波谱内容)与由内容提取器34检索的音频内容的音频信号进行比较,以确定音频信号的波谱内容是否(例如,至少部分地)匹配麦克风信号的波谱内容。在一个方面,匹配可基于所比较的波谱内容至少部分地匹配(例如,至少在阈限值内匹配)来确定。在标识到匹配时,意指由回放设备5产生的声音现在已到达输出设备6(例如,其麦克风),同步器32可确定共享时钟的当前时间。利用当前时间,同步器32可基于回放数据的当前回放时间戳与共享时钟的当前时间之间的差异来确定声学ToF。在一个方面,声学ToF可以是所确定差异。例如,回放状态可指示在共享时钟的T
在另一方面,回放同步器32可通过其他方法来确定(或估计)声学ToF。具体地,输出设备6可基于输出设备6与回放设备5之间的所确定(或所估计)距离来估计声学ToF。在一个方面,同步器32可基于来自一个或多个传感器26的传感器数据来确定该距离。例如,同步器32可获得由相机捕获的图像数据并且对图像数据执行对象识别,以确定回放设备5(的至少一部分)是否在图像数据内(例如,在相机的视场内)。响应于确定回放设备5在图像数据内,同步器可基于图像数据来确定距离。在另一方面,同步器可基于(例如,IMU 29的)运动数据和/或位置数据来确定距回放设备5的距离。例如,传感器26可包括全球定位系统(GPS)传感器(未示出),该GPS传感器可产生指示输出设备6的位置的位置数据。在一个方面,回放数据可包括回放设备5的位置数据。在这种情况下,输出设备6可基于位置数据来确定设备之间的距离,并且根据距离估计声学ToF。在另一方面,设备之间的距离可基于两个设备之间的无线连接来确定。例如,输出设备6可基于无线连接的接收信号强度指示符(RSSI)来确定设备相对于回放设备5的位置。
在另一方面,ToF可基于麦克风信号的声级与回放数据30的(目标)声级之间的差异来确定。如本文所述,声音输出可关于距离在环境内消散。因此,同步器32可基于回放数据的声级(例如,回放设备5的音量等级)与由麦克风捕获的由回放设备5产生的声音的(当前)声级之间的差异来估计声学ToF。在另一方面,回放同步器32可通过其他方法确定声学ToF。
在一个方面,回放同步器32可使用声学ToF确定用于回放音频内容的时间对准。在一个方面,时间对准可与声学ToF相同。在另一方面,时间对准可基于ToF。例如,除麦克风9与扬声器8之间的距离之外,时间对准还可考虑声学ToF。
在一个方面,声级估计器33被配置为维持由输出设备6的用户感知到的音频内容的声音的恒定(或一致)声级(或表观音频响度)。具体地,估计器33被配置为确定用户将要感知的音频内容的目标声级。在一个方面,估计器33可基于回放数据来确定目标声级。例如,估计器33可将目标等级确定为回放设备5(当前)正在回放音频内容所处的音量等级。
在另一方面,目标等级可以是用户限定的。例如,输出设备6的用户可基于用户输入(例如,通过限定用户限定的音量等级)来限定目标等级。在另一方面,目标声级可基于回放设备5已开始音频回放的时间来限定。例如,一旦回放设备5开始(例如,特定的一段用户期望的音频内容的)音频回放,回放设备5就可传输(例如,初始)回放数据。根据此初始回放数据,声级估计器33可限定目标声级。在另一方面,目标声级可基于回放设备5已起始特定音频回放会话的时间(例如,基于回放设备5已打开并起始音频回放的时间)。
在另一方面,目标声级可基于麦克风9的麦克风信号来估计。例如,在确定回放已起始时,声级估计器33可基于由麦克风捕获的由回放设备5回放的音频内容的初始部分来限定目标声级。在另一方面,目标声级可基于回放设备5的音量等级与麦克风信号的声级(例如,它们之间的关系)。
声级估计器33接收由麦克风9捕获的(例如,经回声消除的)麦克风信号,并且基于麦克风信号和回放数据30来确定等级调整。具体地,估计器33使用麦克风信号确定由回放设备5播放的音频内容的声音的声级,并且基于所确定的声级和回放数据的目标声级来确定(估计)输出设备6的等级(例如,音量)调整。特别地,估计器33可基于所确定的声级来确定满足(例如,维持)目标声级的音量调整。例如,在确定声级小于目标声级时,估计器33可确定将要提高输出设备6的音量,以便补偿声级的下降。特别地,估计器33可确定将要应用于将要用于驱动扬声器8的音频内容的一个或多个音频信号的(例如,标量)增益。
在另一方面,声级估计器33可基于麦克风信号的声级提高来确定将要降低音量等级。例如,估计器33可确定麦克风处的声级正在提高(例如,与声级的前一估计相比已提高),这可能是由于用户正在更靠近回放设备5移动)。因此,为了维持目标声级,估计器33可确定音量等级的降低(例如,音频内容的音频信号的衰减)。因此,声级估计器33可动态地调整扬声器8的声音输出等级,以便维持输出设备6的用户听到的目标声级。
音频渲染器35被配置为从内容提取器34接收音频内容(例如,包括音频内容的一个或多个音频信号),并且被配置为使用一个或多个音频信号来驱动扬声器8,使得音频内容的声音与回放设备5的声音同时地由输出设备6的用户感知到。在另一方面,音频渲染器35从回放同步器接收时间对准,并且使用时间对准来使回放与回放设备5同步。特别地,音频渲染器35可按时间对准所指示的时间段(例如,相对于共享时钟)延迟音频内容(例如,和未来音频内容)的回放。例如,音频渲染器35可接收音频内容的立即(例如,回放数据所指示)由回放设备5回放的一部分,并且在由时间对准指示的时间段之后回放该部分。
在另一方面,音频渲染器35被配置为从声级估计器33接收等级调整,并且被配置为基于等级调整来对音频内容应用一个或多个音频信号处理操作。例如,音频渲染器35可对音频信号(的至少一部分)应用标量增益(或增益值),以调整(例如,降低或提高)音频信号的等级(或量值)。在一个方面,渲染器35可在模拟域中应用增益调整(例如,当信号是模拟信号时)。在另一方面,可在数字域中应用增益(例如,当信号是数字音频信号时)。在一个方面,音频渲染器35可调整音频信号的某些部分,诸如某些频率。在另一方面,渲染器35可通过执行音频压缩操作诸如动态范围压缩(DRC)来对输入音频信号的部分应用一个或多个增益值。在另一方面,音频渲染器35可基于等级调整来对音频信号应用其他信号处理操作诸如均衡操作(例如,对音频信号进行波谱整形)。
在一个方面,音频渲染器35可在空间上渲染音频内容,使得由输出设备6产生的声音由设备的用户感知为源自空间内的位置。在一个方面,音频渲染器35可被配置为确定空间特性(例如,方位角、高度、频率等),这些空间特性指示空间中的将要再现音频内容的声音所在的位置(例如,作为虚拟声源)。在一个方面,音频渲染器35可确定空间特性,以便再现回放设备5的位置处的声音。具体地,音频渲染器35可被配置为确定回放设备5相对于输出设备6的位置。例如,渲染器35可使用来自回放数据30的数据(例如,回放设备5的位置数据)和/或由回放设备5的控制器24相对于输出设备6确定的位置数据。根据此数据,渲染器35可确定(或估计)空间特性,并且可使用这些特性来选择一个或多个空间滤波器,诸如头部相关传递函数(HRTF)或等效的一个或多个头部相关脉冲响应(HRIR),当应用于音频内容的音频信号时,该一个或多个空间过滤器产生空间音频(例如,双耳渲染的音频信号)。因此,渲染器35可根据回放设备5的位置在空间上渲染音频内容以通过扬声器8产生包括音频内容的虚拟声源。在一个方面,输出设备6可包括至少一个其他扬声器,输出设备6可使用该至少一个其他扬声器来驱动双耳渲染的音频信号。
在一些方面,音频渲染器35可执行其他音频信号处理操作。例如,当输出设备6包括两个或更多个扬声器时,音频渲染器35可执行声音输出波束形成器操作,以将一个或多个声音朝向空间中的特定位置投射。在另一方面,渲染器35可执行有源噪声消除(ANC)功能以使扬声器8产生抗噪声,以便减少泄漏到用户耳朵中的来自环境的周围噪声。ANC功能可被实现为前馈ANC、反馈ANC或它们的组合中的一者。因此,控制器24可从捕获外部周围声音的麦克风接收参考麦克风信号。在另一方面,控制器24可执行任何ANC方法以产生抗噪声。
在另一方面,控制器24可包括声音拾取波束形成器,该声音拾取波束形成器可被配置为处理输出设备6的两个或更多个外部麦克风产生的音频(或麦克风)信号以形成用于在某些方向上进行空间选择性声音拾取的定向波束方向图(作为一个或多个音频信号),以便对一个或多个声源位置更敏感。例如,控制器可使用声音拾取波束形成器来捕获由回放设备5产生的声音。
图4-图6分别是过程70、80和90的流程图,这些过程用于执行一个或多个操作以便输出设备6与回放设备5桥接音频回放,使得回放设备和输出设备的声音在由收听者感知到时是同步的,并且使得在用户在回放设备5周围移动时,维持由收听者听到的声级。在一个方面,操作中的至少一些操作可由系统4的一个或多个设备执行,如图2所示。例如,这些过程中的一个或多个过程的操作中的至少一些操作可由输出设备6(例如,其控制器24)执行。在另一方面,操作中的至少一些操作可由回放设备5和/或由与任一设备通信地耦接的另一电子设备(例如,经由网络23耦接的远程电子服务器)执行。
图4是输出设备6在输出设备6移动远离回放设备5时与回放设备5桥接音频回放的过程70的一个方面的流程图。过程70通过以下操作开始:输出设备6(的控制器24)确定(例如,在输出设备6的声学可听范围内的)回放设备5正在回放(或将要回放)音频内容(在框71处)。在一个方面,此确定可基于从与两个设备通信地耦接的电子设备(例如,远程电子服务器)获得的数据。例如,远程服务器可从一个或多个回放设备和/或输出设备6获得位置数据,并且确定输出设备6和回放设备5是否在阈限距离内(例如,在声学可听范围内)。如果是,则电子设备可将指示回放设备5在可听范围内的确认消息传输到输出设备6。在另一方面,远程服务器可将(例如,类似)消息传输到回放设备5。一旦接收到确认消息,两个设备就可建立通信链路(例如,无线连接),以便彼此通信。
在一个方面,远程服务器可确定输出设备6在与输出设备6相关联的回放设备5的声学可听范围内。例如,远程服务器可确定设备在(例如,对应于声学可听范围的)特定阈限内,并且确定两个设备是否与(例如,基于云的服务的)同一用户或用户账户相关联。如果是,则远程服务器可与输出设备6通信,以便与回放设备5建立连接。在另一方面,远程服务器可在确定回放设备5正在回放音频内容时将确认消息传输到输出设备6。
在一个方面,输出设备6可基于传感器数据确定回放设备5正在声学可听范围内回放音频内容。例如,输出设备6可监测(由麦克风9捕获的)周围声音以确定音频内容的声音是否包含在一个或多个麦克风信号内。如果是,则输出设备6可确定是否存在回放设备5(例如,在输出设备6的声学可听范围内)。例如,输出设备6可将对范围内的回放设备的位置数据的请求传输到远程服务器。在接收到确认时,输出设备6可与回放设备5建立通信链路。在另一方面,输出设备6可尝试与区域内的一个或多个设备建立连接,并且在建立连接时,确定设备是否是正在回放音频内容的回放设备5。
在一个方面,此确定可基于用户输入作出。例如,一旦设备由设备的用户激活(或打开),输出设备6就可作出此确定。在另一方面,设备可接收用户指令以执行此确定(例如,基于用户输入)。
控制器24接收音频内容的表示(在框72处)。具体地,输出设备6可从回放设备5接收表示。例如,在确定(例如,与输出设备6相关联的)回放设备5正在回放音频内容时,输出设备6与回放设备5建立连接,并且接收表示。在一个方面,表示可以是(或包括)指示音频内容在回放设备5处的回放状态的回放数据(例如,数据30),如本文所述。在另一方面,控制器24可基于来自一个或多个传感器26的传感器数据来确定表示。例如,控制器可被配置为将来自环境的声音捕获为由麦克风9产生的一个或多个麦克风信号,并且可被配置为使用麦克风信号确定表示。例如,控制器可对麦克风信号执行波谱分析以确定表示,诸如将声音标识为包括由回放设备产生的音乐作品。在另一方面,输出设备6可从回放设备接收回放数据。在一些方面,回放数据可从不同设备(例如,输出设备经由网络23与之通信地耦接的远程服务器)接收。
控制器24基于音频内容的表示来检索音频内容(在框73处)。例如,内容提取器34可基于经由网络23从回放设备5(和/或从远程服务器)接收的音频内容的回放数据来检索音频内容的至少一部分。控制器24基于音频内容的表示来确定正在由回放设备5回放的音频内容的目标声级(在框74处)。例如,声级估计器33可基于回放数据30和/或基于由麦克风9捕获的麦克风信号来确定目标声级。
控制器确定输出设备6正在移动远离回放设备5(在框75处)。在一个方面,输出设备6可基于传感器数据来确定输出设备6正在移动远离。例如,输出设备6可从IMU 29接收指示输出设备6正在移动的运动数据。在另一方面,确定可基于位置数据。例如,输出设备6可确定位置数据(例如,来自输出设备6的GPS传感器)相对于从回放设备5接收的位置数据正在改变。在另一方面,输出设备6可基于从相机28获得的图像数据来确定输出设备正在移动远离。在一些方面,输出设备6可基于由麦克风9捕获的麦克风信号来确定输出设备正在移动远离。例如,输出设备6可确定正在由回放设备5回放的音频内容的声音的声级正在改变(例如,以特定速率降低),这可指示设备正在分开移动。在另一方面,输出设备6可基于在设备之间建立的无线连接来确定输出设备正在移动远离。例如,输出设备6可通过基于无线连接的RSSI标识设备相对于回放设备5的位置来确定输出设备正在移动远离,并且基于RSSI的改变来确定输出设备6正在移动远离。在另一方面,输出设备6可使用任何方法确定输出设备正在移动远离回放设备5。
控制器确定与由回放设备5回放的音频内容相关联的回放特性(在框76处)。具体地,声级估计器33确定正在由回放设备5产生的声音在麦克风9处的声级(例如,使用由麦克风9捕获的一个或多个(例如,经回声消除的)麦克风信号)。除了(或代替)确定声级,回放同步器32确定用于使输出设备6的回放与回放设备5的回放同步的时间对准。特别地,回放同步器可基于回放数据(例如,其一个或多个时间戳)和麦克风信号与音频内容的比较来确定用于控制器24的时间对准,如本文所述。在一些方面,控制器可响应于确定输出设备6已移动(例如,基于来自IMU的运动数据)而确定一个或多个回放特性。特别地,控制器24可确定与由回放设备5回放的音频内容相关联的空间特性,诸如在输出设备6在空间内移动时确定设备相对于输出设备的位置。
控制器基于所确定的回放特性诸如声级并且根据时间对准在满足目标声级的(例如,提高的)等级下回放音频内容(在框77处)。具体地,由于输出设备6正在移动远离回放设备5,输出设备6可确定麦克风处的声级小于目标声级。因此,作为响应,输出设备6可调整输出设备6的声音输等级(例如,等级),以便补偿声级与目标声级之间的差异。例如,为了调整等级,输出设备6可基于两个等级之间的差异来应用音量调整。特别地,可通过提高输出设备6的音量来调整声音输出等级。在一个方面,这通过以下方式执行:在考虑时间对准的同时,对音频内容的一个或多个音频信号应用标量增益,并且使用音频信号来驱动扬声器8。
在另一方面,控制器还可被配置为基于回放(例如,空间)特性在回放设备的位置处在空间上渲染音频内容,如本文所述)。特别地,控制器24可基于用户相对于回放设备的所确定位置的位置(例如,基于IMU传感器数据)来应用一个或多个空间滤波器。
在一个方面,输出设备6可在输出设备6移动远离回放设备5时执行这些操作中的至少一些操作,以便提供一致收听体验。如本文所述,输出设备6可在满足目标声级的等级下通过扬声器8回放音频内容。在输出设备6移动远离时,麦克风信号处的声级可降低。因此,在确定声音在麦克风处的声级已改变时,输出设备6可调整满足目标声级的输出声级,以补偿麦克风处的声级的变化。换句话讲,这些操作中的至少一些操作可连续执行(例如,在一定时间段内),以便在输出设备6移动远离时满足目标声级。
控制器确定输出设备6是否已移动超出阈限距离(在决策框78处)。在一个方面,此确定可基于传感器数据。例如,控制器可确定输出设备6是否在声学可听范围之外(例如,基于麦克风信号是否具有低于声级阈限的声级)。如果是,则这可意指输出设备6的用户无法听到正在由回放设备5产生的任何声音。因此,输出设备6可在目标声级下回放音频内容(在框79处)。具体地,输出设备6的输出声级可等于针对回放设备5确定的目标声级。在一个方面,输出设备6可在输出设备6超出阈限距离(例如,在声学可听范围之外)时维持此声级。
图5是输出设备6在输出设备6朝向回放设备5移动时与回放设备5桥接音频回放的过程80的一个方面的流程图。在一个方面,此过程中所述的操作中的至少一些操作可在图4的过程70中所述的一个或多个操作之后(或之前)执行。例如,此过程中的操作可在过程70执行之后的一定时间段执行。例如,过程70可在设备的用户10移动远离回放设备5时由输出设备6执行,如关于图1所示和所述。此过程的操作可在输出设备6正在回放音频内容并且穿戴着或握持着输出设备6的用户10正在朝向回放设备5(例如,在房间7内)移动(回)时执行。
过程80通过以下操作开始:控制器24确定输出设备6正在朝向回放设备5移动(在框81处)。具体地,控制器可执行与本文所述的那些类似的操作,以确定设备正在朝向回放设备5移动。在一个方面,控制器可执行与过程70的框75中所述的那些类似的操作。例如,控制器可接收位置数据(例如,从回放设备5和/或从设备与之通信地耦接的远程服务器),并且将位置数据与输出设备6的位置数据进行比较。控制器确定与由回放设备5回放的音频内容相关联的回放特性(在框82处)。特别地,控制器可执行与过程70的框76中所述的那些类似的操作,以便基于来自回放设备5的回放数据来确定正在由回放设备5产生的音频内容的声音的声级和/或时间对准。
控制器基于回放特性诸如所确定的声级并且根据时间对准在满足目标声级的(例如,降低的)等级下回放音频内容(在框83处)。具体地,控制器确定麦克风处的声级已提高,并且因此由回放设备5产生的声音的声级和扬声器8的声音输出等级的组合可能超过目标声级。因此,控制器可调整输出设备6的声音输出等级,以便补偿总体声级的提高。特别地,控制器可基于麦克风的声级的提高(例如,基于先前所确定声级相对于当前声级的比较)来降低扬声器8的声级。在另一方面,控制器可基于麦克风处的声级与扬声器的输出声级的组合之间的差异来降低声级。因此,响应于确定输出设备6正在朝向回放设备5移动,降低扬声器8的声音输出等级。
在一个方面,音频渲染器35可执行一个或多个音频信号处理操作,以便降低扬声器的输出声级。例如,为了降低声音输出等级,音频渲染器35可基于由回放设备5产生的声音在输出设备6的麦克风处的声级的改变来衰减音频内容的音频信号的信号等级(例如,通过对音频内容的音频信号应用基于麦克风处的声级的标量增益)。在一个方面,输出设备6可在设备正在朝向回放设备5移动时执行这些操作。因此,在输出设备6更靠近回放设备5移动时,设备可继续衰减音频信号(例如,按成比例)。因此,控制器通过使由扬声器8产生的声音渐弱(或部分地渐弱)来处理音频信号。
控制器24确定输出设备6是否在回放设备5的阈限距离内(在决策框84处)。具体地,控制器确定输出设备6是否靠近回放设备5,使得由回放设备5产生的声音满足目标声级,并且因此不再需要输出设备6来产生音频内容的声音。在一个方面,控制器可基于麦克风处的声级作出此确定。具体地,控制器可确定由回放设备5回放的声音的声级是否等于或超过目标声级。如果是,则控制器可确定输出设备6在阈限距离内。在另一方面,确定可基于其他数据,如本文所述。如果输出设备6在阈限距离内,则控制器可通过停止使用来自内容提取器34的音频信号驱动扬声器8来停止通过扬声器8回放音频内容(在框85处)。
图6是输出设备6与回放设备5桥接音频回放的过程90的一个方面的流程图。过程90通过以下操作开始:控制器经由计算机网络(例如,网络23)接收音频内容的表示(在框91处)。例如,表示可包括由正在回放音频内容的一个或多个回放设备接收的回放数据。在第二电子设备(例如,回放设备5)正在通过第二扬声器(例如,扬声器21)回放音频内容时,控制器确定第一电子设备(例如,输出设备6)正在移动远离第二电子设备(在框92处)。响应于确定第一电子设备正在移动远离第二电子设备,控制器使用音频内容的表示以通过第一扬声器回放音频内容(在框93处)。例如,控制器可使用回放数据来使由第一电子设备进行的音频内容的回放与音频内容在第二电子设备处的回放状态同步。特别地,控制器可根据回放状态的(例如,当前回放)时间戳回放音频内容,使得由第二扬声器产生的声音和由第一扬声器产生的声音在由输出设备6的用户10感知到时是同步的。如本文所述,控制器可在考虑声学ToF的同时根据时间戳回放音频内容。因此,两个设备可异步地回放音频内容(例如,输出设备6在回放设备5之后回放音频内容),而由两个设备产生的声音在(大约在)相同时间到达用户(例如,用户的耳朵),从而给予用户声音是同步的感知。在一个方面,由输出设备6进行的声音输出可向用户提供组合声音源自回放设备的位置的感知。例如,控制器可在(大约)位于回放设备的位置处的虚拟声源处在空间上渲染音频信号(例如,使用一个或多个HRTF)。
一些方面可执行图4-图6中所述的过程70、80和/或90的变型。例如,这些过程中的至少一些的特定操作可以不以所示出和所描述的确切顺序执行。可不在连续的一系列操作中执行该特定操作,并且可在不同方面中执行不同的特定操作。例如,如迄今为止所述,控制器可基于所确定的声级并且根据时间对准在满足目标等级的等级下回放音频内容。在一个方面,控制器可在没有用户干预的情况下(例如,自动地)执行这些操作。在另一方面,控制器可在应用音频信号处理操作以便满足目标等级之前请求用户授权(批准)。例如,控制器可输出指示不满足目标声级的通知(例如,经由扬声器8的可听声音通知和/或经由显示屏27的可视(例如,弹出)通知)。具体地,控制器可指示扬声器8的声音输出等级不足以补偿麦克风处的声级的所检测变化。在接收到用户输入(例如,对显示屏上的用户界面(UI)项目的用户选择、语音命令等)时,控制器可继续回放音频内容,如本文所述。
如迄今为止所述,输出设备6被配置为与一个或多个回放设备5桥接音频回放。具体地,输出设备6可执行本文所述的操作中的至少一些操作,以便补偿由回放设备5进行的音频回放。在另一方面,输出设备6可被配置为与回放设备桥接已在输出设备6处起始的音频回放。例如,输出设备6可能正在回放音频内容(例如,基于用户10的用户输入)。在这种情况下,用户可能正在以特定声级感知音频内容。在一个方面,输出设备6可与附近(例如,在声学可听范围内)的回放设备桥接回放。例如,输出设备6可与远程电子服务器通信(例如,经由网络23)以标识一个或多个回放设备是否在声学可听范围内。如果是,则输出设备6可将回放数据传输到回放设备5,并且指示回放设备5回放音频内容。在一个方面,输出设备6可将指令传输到回放设备5以在特定声级(例如,目标等级)下回放音频内容。因此,输出设备6可执行本文所述的一个或更多个操作,以便满足回放设备5的声级。
如迄今为止所述,输出设备6的控制器24可执行一个或多个操作以满足回放设备5的目标声级。在另一方面,输出设备6可将回放数据传输到回放设备5,该回放数据包括供回放设备5执行本文所述的操作中的一个或多个操作的一个或多个指令。例如,在输出设备6更靠近回放设备5移动时,输出设备6可基于所确定的回放特性来确定针对回放设备5的音量调整,并且可将音量调整传输到回放设备5。进而,回放设备5可根据音量调整来调整声音输出。例如,在输出设备6移动远离回放设备5时,输出设备6可指示回放设备5调高音量以便补偿设备之间的增加的距离。
在一些方面,由于输出设备的位置可相对于用户静止,因此输出设备6也可执行一个或多个音频信号处理操作。例如,在输出设备6移动远离回放设备5时,输出设备6也可应用音量调整以便使两个设备提高总体音量。
如本文所述,输出设备6被配置为与回放设备5桥接音频回放,如图1所示。在另一方面,输出设备6可被配置为与两个或更多个回放设备桥接音频回放,由此输出设备6可被配置为基于回放设备的音频回放来调整声音输出,以便向用户提供一致收听体验。图7示出这种示例。
图7示出了根据一个方面的三个阶段50-52,其中输出设备6在用户在两个单独回放设备(第一回放设备55和第二回放设备56)之间移动时维持由用户10听到的声级,两个回放设备正在回放音频内容。具体地,每个阶段示出了均正在回放相同音频内容(例如,音乐作品)的第一回放设备55和第二回放设备56,和穿戴着输出设备6的用户10。此外,每个阶段示出了第一回放设备55的声级11、第二回放设备56的声级57以及输出设备6的声级12,其中每个等级被用户10(例如,其穿戴着的输出设备6的麦克风9)听到。在一个方面,声级中的每一个声级可以是用户耳朵(或耳道)处或其附近的(例如,感知的)响度等级(例如,以dB SPL为单位)。
在第一阶段50中,穿戴着输出设备6的用户10紧挨第一回放设备55定位。在这种情况下,用户听到来自第一回放设备55的大部分(如果不是全部)音频内容,而不会听到(或听到非常少的)来自输出设备6和第二回放设备56的内容。这通过声级12和57为大约零(或低于阈限)示出。在一个方面,此阶段处的声级11可被限定(例如,由系统4)为目标声级。例如,在此阶段中,输出设备6可执行本文(例如,在图4的过程70中)所述的操作中的至少一些操作以确定目标声级。在一个方面,输出设备6可基于用户输入(例如,用户激活输出设备6,用户在显示在显示屏27上的图形用户界面(GUI)中选择UI项目等)来执行这些操作。例如,在被激活时,输出设备6可确定麦克风9(在此位置处)的声级是用户10希望听到音频内容所处的目标声级。在一个方面,由于此阶段处的声级11是目标声级,因此输出设备6可不回放音频内容,因为麦克风处的声级等于(或大于)目标等级11。在另一方面,在此阶段50处,可限定输出设备6停止回放音频内容的阈限距离(例如,限定为用户10与第一回放设备55之间的距离)。
第二阶段51示出了用户10已远离第一回放设备55并且朝向第二回放设备56移动。特别地,随着用户移动远离第一回放设备55,由用户10感知到的声级11降低,而第二回放设备56的声级57提高。例如,这可能是由于用户10在以下房间内移动,在该房间中,两个回放设备位于房间的相反侧。由于移动远离第一回放设备55,输出设备6开始产生声音以满足目标声级,如第一阶段50中所示。此外,输出设备6可被配置为考虑声级57。具体地,在检测到两个设备的声音时,输出设备6可确定它们的相应声级,然后调整扬声器8的声音输出等级(例如,对用于驱动扬声器的音频内容的音频信号应用标量增益),以便维持由用户感知到的目标声级。因此,如图所示,声级11、12和57的组合等于(或近似于)第一阶段50中的声级11。
在一个方面,输出设备6可基于从回放设备55和56中的任一者或两者接收到和/或传输到该任一者或两者的回放数据来使回放同步。例如,输出设备6可从两个设备接收回放数据,并且确定将要应用以便使由输出设备6产生的声音被用户感知为与回放设备中的任一者或两者的声音同步的一个或多个时间对准。在一个方面,输出设备6可将不同的时间对准应用于音频内容的一个或多个音频信号。在另一方面,输出设备6可传输回放数据以使回放同步。例如,输出设备6可将回放数据传输到第二回放设备56以应用一个或多个时间对准以延迟回放,以便使由第二回放设备产生的声音与来自第一回放设备55的声音(在麦克风9处)在(大约在)相同时间到达。连同(或代替)指示声音回放设备56延迟回放,输出设备6可指示第二回放设备56调整声音输出以便确保在用户更靠近第二回放设备56移动时维持目标声级。
第三阶段52示出了用户10已更靠近第二回放设备56移动,使得用户现在无法听到来自第一回放设备的声音(和/或由第一回放设备产生的声音的声级低于用户位置处的阈限等级),如通过声级11为低示出。在声级57由于用户更靠近第二回放设备56而提高的情况下,输出设备6使扬声器8的声音输出等级降低。具体地,在用户朝向第二回放设备56移动的情况下,输出设备6使扬声器声音输出衰减,并且使输出设备6的声级12降低。如图所示,实际上,输出设备6已停止回放音频内容(如声级12所示)。在一个方面,输出设备6可能已基于输出设备在第二回放设备56的阈限距离内而停止回放。在另一方面,输出设备6可能已基于麦克风处的声级为至少(或已达到)目标声级而停止声音输出。
在一个方面,电子设备(例如,输出设备6,其可以是头戴式耳机和/或可穿戴设备诸如一副智能眼镜,其具有耳外式扬声器)在第二电子设备(例如,回放设备5,诸如智能扬声器或电视机)回放音频内容之后回放音频内容(例如,以便使用户10所感知到的音频内容的声音同步)。在另一方面,由第一电子设备和第二电子设备两者进行的回放由握持着或穿戴着第一电子设备的用户感知为同步的,而第一电子设备和第二电子设备两者异步地回放音频内容(例如,输出设备6与回放设备5回放相同音频内容,但在稍后的时间处)。
在一些方面,在满足目标声级的等级下通过第一扬声器(例如,扬声器8)回放音频内容包括:在第一电子设备正在移动远离第二电子设备时,根据确定音频内容的声音在麦克风处的声级已改变,调整满足目标声级的等级以补偿声级的变化。在一些方面,调整满足目标声级的等级包括:基于声级与声级的变化之间的差异将音量调整应用于第一电子设备。在另一方面,在第一电子设备移动远离第二电子设备时,提高满足目标声级的等级。
在一个方面,根据确定第一电子设备已移动到距第二电子设备的阈限距离内,第一电子设备停止音频内容的回放(例如,通过停止使用音频信号来驱动第一扬声器)。
在一个方面,第一电子设备经由无线连接与第二电子设备通信地耦接,并且其中确定第一电子设备正在移动远离第二电子设备包括:标识第一电子设备相对于第二电子设备的位置(例如,基于无线连接的RSSI),并且基于RSSI的改变来确定第一电子设备正在移动远离该位置。在另一方面,使用音频内容的表示来回放音频内容包括:使用使用音频内容的标识来从远程电子服务器或第一电子设备的本地存储器检索音频信号,其中音频信号包括音频内容;以及使用音频信号来驱动第一扬声器以产生音频内容的声音。
在另一方面,该回放状态包括该音频内容的将要由第二电子设备回放的部分的时间戳,使用回放数据来使回放同步包括:根据该时间戳回放该音频内容的该部分,使得由第二电子设备的第二扬声器在回放该音频内容的该部分时产生的声音与由第一电子设备的第一扬声器在回放该音频内容的该部分时产生的声音在由第一电子设备的用户感知到时是同步的。
众所周知,使用个人可识别信息应遵循公认为满足或超过维护用户隐私的行业或政府要求的隐私政策和做法。具体地,应管理和处理个人可识别信息数据,以使无意或未经授权的访问或使用的风险最小化,并应当向用户明确说明授权使用的性质。
如前所述,本公开的一个方面可为其上存储有指令的非暂态机器可读介质(诸如微电子存储器),该指令对一个或多个数据处理部件(这里通常称为“处理器”)进行编程以执行网络操作和音频信号处理操作,如本文所述。在其他方面,可通过包含硬连线逻辑的特定硬件部件来执行这些操作中的一些操作。另选地,可通过所编程的数据处理部件和固定硬连线电路部件的任何组合来执行那些操作。
虽然已经在附图中描述和示出了某些方面,但是应当理解,此类方面仅仅是对广义公开的说明而非限制,并且本公开不限于所示出和所述的具体结构和布置,因为本领域的普通技术人员可以想到各种其他修改型式。因此,要将描述视为示例性的而非限制性的。
在一些方面,本公开可包括语言例如“[元素A]和[元素B]中的至少一者”。该语言可以是指这些元素中的一者或多者。例如,“A和B中的至少一者”可以是指“A”、“B”、或“A和B”。具体地讲,“A和B中的至少一者”可以是指“A中至少一者和B中至少一者”或者“至少A或B任一者”。在一些方面,本公开可包括语言例如“[元素A]、[元素B]、和/或[元素C]”。该语言可以是指这些元素中任一者或其任何组合。例如,“A、B和/或C”可以是指“A”、“B”、“C”、“A和B”、“A和C”、“B和C”或“A、B和C”。