一种基于语义分割的图像地标识别方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及图像语义分割以及地标识别技术,具体涉及一种基于语义分割的图像地标识别方法。
背景技术
地标,指有助于识别所处地点的标志性建筑物或遗址。地标识别(Landmarkrecognition)是基于图像的建筑物特征进行地标判断的过程。地标识别可广泛应用于社交图片的定位,旅游景点的信息推荐等应用中。地标识别的关键在于提取图片中地标建筑的特征信息,进而进行地标特征相似度计算与识别。地标图片中可能包含不同视角和不同的局部信息,呈现出显著的类内差异。此外,地标图片通常还包含着复杂多样的背景和前景信息,如天空、人像、植被、道路等。现有的技术手段通常直接将整幅拍摄图像作为输入,通过特征表示进行地标的识别,这种方式引入了地标无关的背景信息,导致地标识别精度降低。
图像的语义分割技术能够较为准确的将图片中的不同物体类型区别开来,这为地标图像中建筑物的提取与识别提供了技术支持,有望提升复杂背景图像的地标识别精度。
发明内容
本发明的目的在于提出一种基于语义分割的图像地标识别方法。
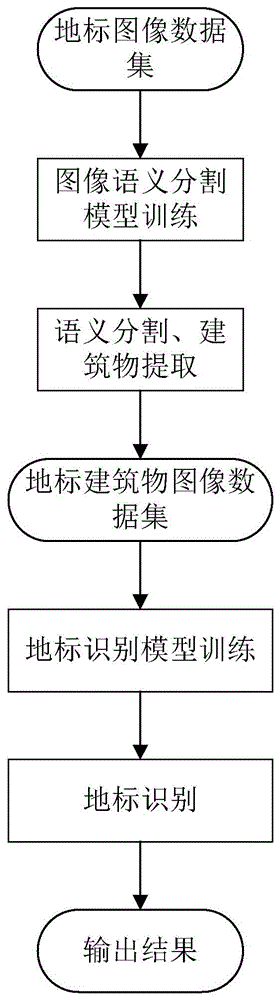
实现本发明目的的技术解决方案为:一种基于语义分割的图像地标识别方法,包括如下步骤:
步骤1:数据准备:收集包含地标建筑的图片,构建样本数据集;
步骤2:语义分割地标图像:利用预训练好的语义分割模型得到步骤1样本数据集的掩膜图,掩膜前景和背景,得到只包含建筑信息的图片;
步骤3:训练地标识别模型:基于EfficientNet构建地标识别深度学习模型,利用步骤2得到的只包含建筑信息的样本图片训练并优化模型结构,得到最优的地标识别深度学习模型;
步骤4:识别图片地标信息:输入待识别的地标图像,使用步骤2中的语义分割模型进行输入地标图像的语义分割和掩膜,得到只包含建筑信息的图片,然后使用步骤3得到的地标识别模型对掩膜后图像进行地标识别,得到并输出图片地标的名称信息。
步骤1,收集包含地标建筑的图片,构建样本数据集,具体方法为:
步骤1.1:收集包含地标建筑的相关图片,地标建筑主要指具有标志性特征的建筑,收集的图片包含不同视角和不同部分的图片;
步骤1.2:将不同地标的图片分开保存,同一类别的图标放在同一个文件夹下进行存储;
步骤1.3:从不同类别的地标图片中随机抽取数量不等的图片,进行标准化操作,包括拉伸、压缩、裁剪,构造样本数据集,作为训练数据集。
步骤2,利用预训练好的语义分割模型得到步骤1样本数据集的掩膜图,掩膜前景和背景,得到只包含建筑信息的图片,其中语义分割模型采用Segnet语义分割网络,主要分为编码器、解码器和预测模块3个模块,具体如下:
步骤2.1:编码
编码器采用VGG16中的前13层,通过对底层像素进行特征提取,得到图像包含的高阶特征信息,编码器部分由卷积层、Batch Normalization层、池化层、激活层组成,计算过程如下:
其中,
步骤2.2:解码
解码器对步骤2.1中编码器获得的高阶特征信息进行上采样,弥补编码时丢失的空间细节信息,在上采样时直接采用编码过程中记录的池化层索引进行上采样,最终上采样后的特征图和输入编码器的图片的高度和宽度相同;
步骤2.3:预测
利用步骤2.1编码器提取图片的高阶特征信息,利用步骤2.2解码器对提取的高阶特征信息进行上采样,然后通过soft max分类器对上采样后的特征图进行像元级的分类,类别包括人物、建筑物、地面、植被、天空和其他。
步骤3,基于EfficientNet构建地标识别深度学习模型,利用步骤2得到的只包含建筑信息的样本图片训练并优化模型结构,得到最优的地标识别深度学习模型,具体方法为:
步骤3.1:基准网络结构确定:基准网络包含卷积层conv、MBConv模块、全局平均池化层GAP、dropout层、全连接层FC以及softmax分类;
首先,基准网络接收地标建筑输入图片,使用卷积核大小为3*3的卷积层进行特征提取得到浅层特征图;其次,将提取的浅层特征图依次输入卷积核大小为3*3的MBConv1模块、2个卷积核大小为3*3的MBConv6模块、2个卷积核大小为5*5的MBConv6模块、3个卷积核大小为3*3的MBConv6模块、3个卷积核大小为5*5的MBConv6模块、4个卷积核大小为5*5的MBConv6模块、1个卷积核大小为3*3的MBConv6模块以及一个卷积核大小1*1的卷积层,计算得到图像的深层特征;最后,将计算得到的深层特征使用全局平均池化层GAP进行降维,并经过dropout层和全连接层后得到维度大小为地标类别个数的特征向量,使用softmax对特征向量进行分类最终得到输入的地标建筑图片所属的类别。网络整体结构如图4所示。
步骤3.2:网络结构搜索优化:基于步骤3.1中的基准网络,优化其网络结构参数,包括网络宽度d、深度w和输入分辨率r,参数优化过程表示为:
优化过程如下:
固定φ=1,使用网格搜索,确定α、β、γ在baseline网络上的最优值;
固定α、β、γ的值,优化不同的φ得到不同尺寸结构的深度网络;
步骤3.3:识别模型训练:将步骤2整理得到的只包含建筑信息的样本图片划分为训练数据和验证数据,训练步骤3.2得到的优化网络结构后的模型,得到最优的地标识别深度学习模型,识别掩膜后图片包含的地标建筑。
一种基于语义分割的图像地标识别系统,基于任一项所述图像地标识别方法,实现基于语义分割的图像地标识别。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时,基于任一项所述图像地标识别方法,实现基于语义分割的图像地标识别。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,基于任一项所述图像地标识别方法,实现基于语义分割的图像地标识别。
本发明与现有技术相比,其显著优点为:1)能够自动的从包含地标的图像中提取出地标建筑物的信息,移除了无关背景对地标识别的影响。2)基于EfficientNet自动化地进行网络结构寻优,优化地标识别网络的深度、宽度和分辨率参数,得到最优的网络结构。
附图说明
图1是基于语义分割的图像地标建筑识别的流程图;
图2是图像语义分割的流程图;
图3是地标建筑识别的流程图;
图4是步骤3中的基准网络。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
一种基于语义分割的图像地标识别方法,使用图像语义分割技术提取图像建筑区域,掩膜无关背景信息,然后基于提取的建筑区域进行地标识别,能够更有效地实现图像地标的识别。流程包括以下步骤:
步骤1:数据准备
步骤1.1:收集包含地标建筑的相关图片,地标建筑主要指具有标志性特征的建筑,收集的图片包含不同视角和不同部分的图片。
步骤1.2:将不同地标的图片分开保存,同一类别的图标放在同一个文件夹下进行存储。
步骤1.3:从不同类别的地标图片中随机抽取数量不等的图片,经过拉伸、压缩、裁剪等操作组成256*256的图片,构造训练数据集和验证数据集。
步骤2:语义分割地标图像
利用Segnet语义分割网络进行语义分割模型训练,主要分为3个模块:编码器模块、解码器模块和预测模块。
步骤2.1:编码器模块。编码器通过对底层像素进行特征提取,得到图像包含的高阶特征信息。编码器部分由连续的卷积网络构成,网络层级卷积层、Batch Normalization层、池化层、激活层组成,编码器采用的特征提取网络为VGG16中的前13层。主要的计算过程如下:
其中,
步骤2.2:解码器模块。解码器对步骤2.1中编码器获得的特征进行上采样,弥补丢失的空间细节信息。在上采样时直接采用编码过程中记录的池化层索引进行上采样,最终获得的特征层和输入图片的高度和宽度相同。
步骤2.3:预测模块。利用步骤2.1编码器模块提取图片的特征信息,并使用步骤2.2解码器模块上采样弥补丢失的空间信息,得到了输入图片的特征结果,然后通过softmax分类器对解码器输出特征进行像元级的分类,类别包括人物、建筑物、地面、植被等,如下表1所示。最终得到图像的语义分割图。
表1语义分割模型的类别体系
通过对样本数据集中的地标图片进行语义分割,得到只包含建筑信息的样本图片。
步骤3:训练地标识别模型。
采用EfficientNet作为地标特征提取网络主干部分,进行网络训练和结构寻优,主要包括3个步骤:基准网络结构确定,网络结构搜索优化,识别模型训练。
步骤3.1:基准网络结构确定。基准网络由多个MBConv模块堆叠组成,其基本结构组成如图4所示。模型首先接收地标建筑输入图片,使用3*3的卷积核进行特征提取,随后图片特征经过多层MBConv模块进行特征计算,最后将特征输入全局池化层并进行分类,得到输入地标图片所属地标类型。
步骤3.2:网络结构搜索优化。基于步骤3.1中的基准网络,优化其网络结构参数,包括网络宽度d,深度w和输入分辨率r。其参数优化过程表示为
优化过程如下:
1)固定φ=1,使用网格搜索,确定α,β,γ在baseline网络上的最优值。
2)固定α,β,γ的值,优化不同的φ得到不同尺寸结构的深度网络。
步骤3.3:识别模型训练。将步骤2得到的只包含建筑信息的样本图片划分为训练数据和验证数据,训练并优化地标识别模型结构得到最优的地标识别深度学习模型,训练后的模型可以识别掩膜后图片包含的地标建筑。
步骤4:识别图片地标信息
步骤4.1:输入待识别的地标图像,使用步骤2中预训练的语义分割模型进行图像分割得到只包含建筑物区域的图片。
步骤4.2:针对只包含建筑物区域的图片,使用步骤3确定的地标识别模型进行地标识别,输出地标名称。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请的保护范围应以所附权利要求为准。
- 一种基于图像语义分割的车牌字符分割与识别方法及系统
- 一种基于图像语义分割的智能车辆可行驶区域的识别方法