基于在线学习的移动群智感知最佳时空采样粒度确定方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于无人机技术领域,具体涉及一种移动群智感知最佳时空采样粒度确定方法。
背景技术
近年来随着移动设备的普及,持续性群智感知被广泛应用于现实区域的数据检测。近年来随着移动设备的普及,持续性群智感知被广泛应用于现实区域的数据检测,随着5G技术的发展移动设备在物联网环境下能够极快地采集、共享数据。群智感知的兴起,在城市测温、噪声检测、城市交通拥堵情况检测、智能农业等方面发挥了重要作用。我们对区域进行持续性群智感知的通用做法是对区域进行时空粒度划分,按照划分的时空粒度进行采样。时空粒度的划分方式通常是基于历史数据驱动的,即根据先验知识和数据的时空关联关系设置时空采样粒度。在压缩感知中,采样粒度通常也是根据历史数据或者先验数据设置的,利用数据的时空关联性设置合适的采样粒度,降低感知成本。由此可见历史数据在感知数据质量中发挥了重要作用。
然而在很多现实场景中,存在未知的区域内发生紧急事件的情况,比如遭遇灾情等情况,此时环境变化较快,以往掌握的该环境的历史经验失效,并且比如在洪涝灾害检测这种情况下,还需要尽快采集某物理观测量的数据,得到区域内观测量的分布情况,便于根据观测结果执行救援任务。在此类情况下,由于数据信息变化较快,根据历史数据确定的采样粒度显然是不适宜当前环境的,需要寻找一种在线学习方式,经过实时反馈调整采样方案。
多臂老虎机产生于在对已知信息利用和未知信息探索之间权衡,寻求所得效益的最大化。近年来多臂老虎机越来越多的被应用于移动群智感知领域,成为感知领域找到最大效益感知策略的一种可行方案。
现有的工作采集数据时候,往往根据先验知识得到能够最贴切反映区域数据分布的数据采样时空粒度。然而面对完全未知的环境,或者环境变化较快的情况,此时没有先验知识或者先验知识无法起作用。
发明内容
为了克服现有技术的不足,本发明提供了一种基于在线学习的移动群智感知最佳时空采样粒度确定方法,通过构建包含采样数据分布情况和采样成本的奖励函数,将采样结果转化成奖励,并且将奖励建模为广义线性模型,利用最佳臂感知未知区域数据分布的方法,多轮迭代完善模型,在最小化感知成本的基础上找到最优时空采样粒度。本发明解决了在无先验知识情况下的区域最佳采样时空粒度确认问题,便于以最能反映区域分布的采样策略高效地执行感知任务。面对未知的采样环境,采用多臂老虎机对探索和利用的权衡机制选择当前最佳采样策略,完善对实际奖励的估计。在多轮迭代中,找到奖励最多的采样策略,实现效益最佳的目标,即在最小成本下最能还原数据分布的采样策略。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1:假设未知区域A
无人机采样策略为在每个空间子区域中随机选择一个最细空间粒度区域进行采样,以此最细空间粒度区域的采样结果作为空间子区域中每个最细空间粒度区域的采样结果;
设无人机采样策略对应的特征向量x、未知的奖励参数向量θ以及奖励是有界的,满足:||x||
步骤2:设时空维度为d;
步骤2-1:采用多臂老虎机算法,在前E次迭代过程中,在候选采样策略集π={(Area
步骤2-2:从E+1次迭代开始根据当前获得的所有信息估计出当前最佳采样策略
在第t≥E+1轮,根据估计出当前已知的信息得到每个采样策略的预期奖励,找到预期奖励最多的策略
式中,
最有可能获得最多奖励的策略
△(j
/>
其中,
以及能获得未知区域最多信息的策略
其中,
步骤3:将与区域数据分布和采样成本有关的奖励函数建模为广义线性模型,根据当前已获得的策略
设奖励函数遵循泊松分布,根据广义线性模型得到,奖励函数的估计函数为μ(z)=1/(1+e
步骤4:计算估计最佳采样策略
如果对于步骤2-2中
式中,ζ为自定义的参数;μ(θ
当β(i,j)迭代间的降幅小于一定值时,判定误差阈值不再变化并且达到停止条件,即β(i
步骤5:根据估计最佳采样策略
对步骤1中
式中,
步骤6:本次迭代包含最多未知信息的采样策略
进一步地,所述无人机采样过程具体如下:
观测未知区域A
时空划分策略集被定义为:π={(Area
设以X={x
设策略
本发明的有益效果如下:
本发明解决了在无先验知识情况下的区域最佳采样时空粒度确认问题,便于以最能反映区域分布的采样策略高效地执行感知任务。面对未知的采样环境,采用多臂老虎机对探索和利用的权衡机制选择当前最佳采样策略,完善对实际奖励的估计。在多轮迭代中,找到奖励最多的采样策略,实现效益最佳的目标,即在最小成本下最能还原数据分布的采样策略。
附图说明
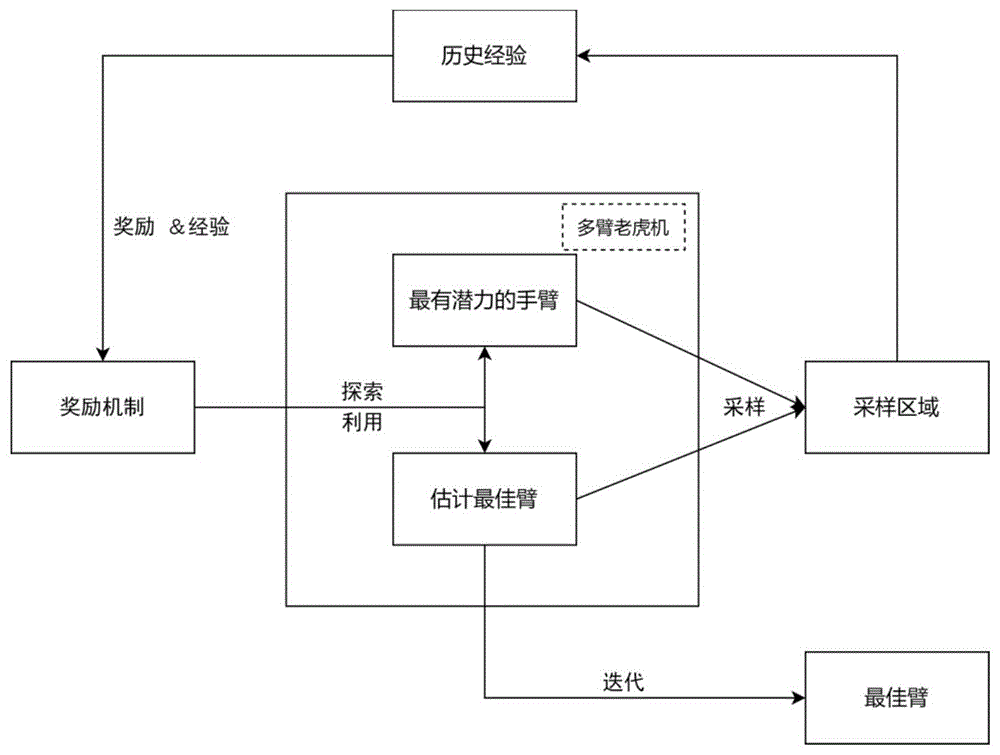
图1为本发明方法流程图。
图2为本发明实施例4×4的采样区域的空间划分策略。
图3为本发明实施例4×4的采样区域的时间划分策略。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
在现实场景中,面对未知的区域,或者区域内发生紧急事件时环境变化较快,区域的历史数据缺失,然而基于成本和任务本身考虑,需要尽快采集某物理观测量的数据,得到区域内观测量的分布情况。比如发生火灾或者洪涝灾害时,需要尽快确定灾情最严重的位置。在此类情况下,由于待观测量数据分布变化较快,根据历史数据确定的数据分布显然是不适宜当前环境的。针对这一实际问题,在无先验数据的情况下,找到一种合适的时空采样粒度划分方式,这种时空采样划分方式能够最大程度反应数据的区域分布,并且这种方式还兼顾了采样成本,从实时性、经济性以及准确性角度找到一种综合最佳采样方案。希望能够通过多次迭代的实时反馈建立起对未知区域的认知。由于感知预算有限以及感知目标具有时间敏感性,应尽量减少迭代次数。本发明针对未知区域,找到一种时空采样粒度确认机制,这种机制在感知预算尽量少的情况下,找到一种较为理想的采样时空粒度。
本发明的目的可以通过采取如下技术方案达到:
一种基于在线学习的基于移动群智感知的数据采样粒度确认方法,包括以下步骤:
一种基于在线学习的基于移动群智感知的数据采样粒度确认方法,包括以下步骤:
步骤1:假设未知环境A
步骤2:设时空维度为d;
步骤2-1:给定参数E,在前E次迭代过程中,在候选采样策略集π={(Area
步骤2-2:从E+1次迭代开始根据当前获得的所有信息估计出当前最佳采样策略
步骤3:将与区域数据分布和采样成本有关的奖励函数建模为广义线性模型,根据当前根据目前已获得的策略
步骤4:计算估计最佳采样策略
步骤5:根据估计最佳采样策略
步骤6:本次迭代包含最多未知信息的采样策略
在步骤4引入切尔诺夫界衡量渐进最佳采样策略是否可靠地反应未知环境数据分布,具体如下:当最佳采样策略与近似最佳策略奖励差值小于一定值ε时,有ζ的置信度认为近似最佳策略就是最佳,对于ε和δ的取值,使用切尔诺夫界来规范。当最佳策略
其中ε取值为
步骤5引入JS散度来衡量数据质量,参与奖励函数的设计,具体如下:假设奖励函数服从指数族分布,应用广义线性模型(GLM)来拟合决定奖励函数的向量θ,给定策略集π={π
当结束本次迭代后,能获得最多信息的采样结果汇入历史加权平均分布P={p
具体实施例:
本发明设计了基于在线学习的移动群智感知最佳时空采样粒度确定方法,参阅图1所示,本发明的具体步骤如下:
假设未知环境A
1、对于相关参数设置,假设采样策略对应的特征向量x、未知的奖励参数向量θ以及奖励是有界的,满足:||x||
1-1、首先前E轮,随机选择策略
1-2、在第t≥E+1轮,根据估计出当前已知的信息得到每个采样策略的预期奖励,找到预期奖励最多的策略
最有可能获得最多奖励的策略
△(j
其中,
以及能获得未知区域最多信息的策略
2、设奖励函数遵循泊松分布,根据广义线性模型得到,奖励函数的估计函数为μ(z)=1/(1+e
3、如果对于步骤1-2中
在实际应用中,考虑到高昂的采样成本和变化迅速的环境,以一个快速停止条件来减少采样次数,当β(i
4、对步骤1中
式中,KL(.)表示KL散度即相对熵,JS(.)表示JS散度。
5、本次迭代包含最多未知信息的采样策略
无人机采样过程具体如下:
观测未知区域A
- 基于时空移动特征分布的移动群智感知用户联盟聚类方法
- 基于时空移动特征分布的移动群智感知用户联盟聚类方法