基于非关系型数据库的医疗数据管理方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本申请涉及数据库技术领域,具体涉及一种基于非关系型数据库的医疗数据管理方法及系统。
背景技术
现有的互联网医疗数据系统,数据库大多采用MySQL、Oracle等关系型数据库,并使用MyBatis、Hibernate等持久化框架,固化数据结构,并存储该数据结构的业务数据。
对于医疗数据系统而言,关系型数据库存在着很多弊端,如关系型数据库(MySQL、Oracle等)数据结构固定,增加、修改或删除字段操作复杂,数据结构不具备灵活性;不兼容多种数据结构,当遇到新科室接入时候,需要修改数据库表结构,并需修改项目源码,开发周期长;多科室之间数据结构过于独立,无法互相引用部分数据结构,操作不变,相同的数据结构需要多次配置;视觉展示效果不佳,欲修改外观必须修改源码,体验差,工作量大。
另外,在对数据库进行数据查询时,现有的一些数据统计产品通过Mybatis,执行提前写好的sql语句,并将查询结果返回值页面展示。此类产品可支持的数据库一般为关系型数据库,例如Oracle、MySql等,无法支持MongoDB等非关系型数据库,且查询速度较慢。且主要适用于原数据结构较为平面结构化数据,查询时所需条件也较为简单。在面对非结构化数据,以及更为复杂的查询条件的情况下,就显得有些单薄。
发明内容
本申请实施例提供了一种基于非关系型数据库的医疗数据管理方法及系统,以克服或部分克服现有技术的不足。
第一方面,提供了一种基于非关系型数据库的医疗数据管理方法,所述方法包括:
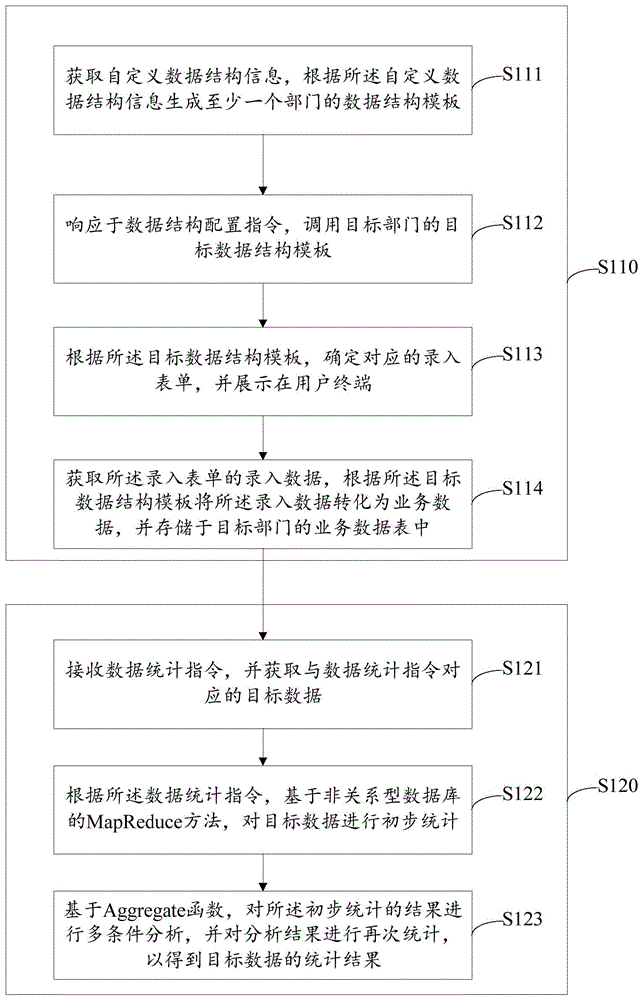
数据录入步骤:获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;响应于数据结构配置指令,调用目标部门的目标数据结构模板;根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中;以及
数据统计步骤:接收数据统计指令,并获取与数据统计指令对应的目标数据;根据所述数据统计指令,基于非关系型数据库的MapReduce方法,对目标数据进行初步统计;基于Aggregate函数,对所述初步统计的结果进行多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。
可选的,所述方法还包括:在多个终端节点安装非关系型数据库的离线数据录入程序,其中,一个终端节点为主节点,其余终端节点为从节点,所述主节点与各所述从节点分别通信连接;
在仅存在局域网的情况下,所述主节点接收各从节点发送的数据;
将各节点发送的数据进行汇总,得到待同步数据;
将所述待同步数据分发至各从节点,以实现各节点的数据录入。
可选的,所述方法还包括:
在网络环境恢复后,所述主节点将所述非关系型数据库的离线数据录入程序中的待同步数据发送至非关系型数据库的线上数据录入程序,以实现线上线下数据的同步。
可选的,在上述方法中,所述数据录入步骤还包括:
获取新增自定义数据结构信息,根据所述新增自定义数据结构信息生成新增部门的数据结构模板。
可选的,在上述方法中,所述数据录入步骤还包括:
提供配置界面,所述配置界面包括多个自定义数据结构信息配置项,其中多个自定义数据结构信息配置项包括:部门信息配置项、数据类型配置型、数据关系配置项;
响应于对所述自定义数据结构信息配置项的配置指令,通过所述配置界面,获取所述自定义数据结构信息;
其中,所述数据类型配置型包括高级节点数据类型配置型和低级节点数据类型配置型;所述高级节点数据类型配置型的可选项为group、list和引用类型中的一种;所述低级节点数据类型配置型的可选项为string、int、date、dropdown、radio和file中的一种,其中dropdown、radio还配置有可填写项。
可选的,在上述方法中,所述数据统计步骤还包括:
基于lookup函数,对目标数据的统计结果中的多个数据表进行关联处理,以得到关于目标数据的再次统计结果。
可选的,在上述方法中,所述数据统计步骤还包括:
基于ECharts方法,对所述目标数据的统计结果进行可视化处理,并在前端展示所述可视化处理结果。
可选的,所述方法还包括:
数据校核步骤:响应于数据校核请求,对待校核数据文件进行校核;
数据检索步骤:响应于数据检索请求,在所述非关系型数据库中查询到目标数据,并返回前端界面;
病例浏览步骤:响应于病例浏览请求,在所述非关系型数据库中查询到目标病例,并返回前端界面。
第二方面,提供了一种基于非关系型数据库的医疗数据管理系统,所述系统至少包括:
数据录入模块:用于获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;响应于数据结构配置指令,调用目标部门的目标数据结构模板;根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中;以及
数据统计模块:用于接收数据统计指令,并获取与数据统计指令对应的目标数据;根据所述数据统计指令,基于非关系型数据库的MapReduce方法,对目标数据进行初步统计;基于Aggregate函数,对所述初步统计的结果进行多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。
可选的,所述系统还包括:
数据校核模块:用于响应于数据校核请求,对待校核数据文件进行校核;
数据检索模块:用于响应于数据检索请求,在所述非关系型数据库中查询到目标数据,并返回前端界面;
病例浏览模块:用于响应于病例浏览请求,在所述非关系型数据库中查询到目标病例,并返回前端界面。
第三方面,本申请实施例还提供了一种电子设备,包括:处理器;以及被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处理器执行上述任一的方法。
第四方面,本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储一个或多个程序,所述一个或多个程序当被包括多个应用程序的电子设备执行时,使得所述电子设备执行上述任一的方法。
本申请实施例采用的上述至少一个技术方案能够达到以下有益效果:
本申请一方面通过获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;响应于数据结构配置指令,调用目标部门的目标数据结构模板;根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中。本申请能够实现数据的灵活定义,用户可以根据自身需要设置不同的自定义数据结构信息,其能够轻松实现多层数据结构的嵌套;数据结构以部门为基本单位,当有新部门接入时,无需修改数据库结构和项目源码,开发周期短,能够很好的体现多部门之间的从属关系;且多部门之间数据结构完全独立,在对数据进行访问时,可以互相引用;且不仅可适用于互联网医疗行业,还可广泛用于需要灵活数据定义的领域。另一方面,以非关系型数据库为基础,采用非关系型数据库固有的MapReduce方法,对目标数据进行初步统计,在该初步统计过程中,不添加复杂条件,然后基于Aggregate聚合函数,对初步统计的结果进行复杂的多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。本申请整个统计过程,将复杂结构的数据统计为扁平数据,将此结果保存在数据库中,在外部应用访问数据库时,显著提高了数据库的查询速度;适用于复杂的数据结构和查询条件,尤其对于非结构化数据,有显著的效果;且适用范围广。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1示出了根据本申请的一个实施例的一种基于非关系型数据库的数据管理方法的流程示意图;
图2示出根据本申请的一个实施例的仅存在局域网时,一种基于非关系型数据库的数据管理系统的的用户端的结构示意图;
图3示出根据本申请的一个实施例的仅存在局域网时,基于非关系型数据库的数据管理过程中数据录入的流程示意图;
图4示出了根据本申请一个实施例的一种基于非关系型数据库的医疗数据管理系统的结构示意图;
图5为本申请实施例中一种电子设备的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
以下结合附图,详细说明本申请各实施例提供的技术方案。
现有技术中,现有的互联网医疗数据库大多采用MySQL、Oracle等关系型数据库,并使用MyBatis、Hibernate等持久化框架,固化数据结构,并存储该数据结构的业务数据。关系型数据库只能保存固定数据结构的数据,虽然增加或减少数据库表字段,但必须同步修改项目源码并重启系统,费时费力且容易产生兼容问题;另外数据结构完全独立且针对性强,当接入新科室数据时,需要增加一套完整的数据库表结构;数据结构以科室为基本单位,当有新科室接入时,需要修改数据库结构和项目源码,开发周期长。且常见的关系型数据库的统计原理,不适用于MongoDB等非关系型数据库。且现有技术中的非关系型数据库的统计方案,所支持的原数据结构较为平面结构化数据,查询时所需条件也较为简单,无法适用于医疗场景等复杂的数据结构和条件。
针对上述情况,本申请提供了一种基于非关系型数据库的数据管理方法,在该方法中,一方面,用户能够根据自身的需求,实现对数据结构的个性化定制,以对数据灵活定义。另一方面,在查询时适用于复杂的数据结构和查询条件。
图1示出了根据本申请的一个实施例的一种基于非关系型数据库的数据管理方法的流程示意图,从图1可以看出,本申请至少包括步骤S110~步骤S120,在步骤S110包含多个子步骤S111~子步骤S114;在步骤S120包含多个子步骤S121~子步骤S113,具体的如下所述:
数据录入步骤S110包含子步骤S111:获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;子步骤S112:响应于数据结构配置指令,调用目标部门的目标数据结构模板;子步骤S113:根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;子步骤S114:获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中。
子步骤S111:获取自定义数据结构信息,根据自定义数据结构信息生成至少一个部门的数据结构模板。
本申请中的非关系型数据库可以为现有技术中的任意一种,如MongoDB数据库,其实基于分布式文件存储的数据库,是非关系数据库当中功能最丰富,最像关系数据库的,其主要特点为支持的数据结构非常松散。
自定义数据结构信息的填写可以由专业技术人员在后端实现,也可以通过前端界面,由普通工作人员实现,在下述实施例中,以后者为例进行说明。
首先获取用户填写的自定义数据结构信息,在自定义数据结构信息中,可以获得自定义结构和嵌套关系的数据结构,也就是说,用户通过填写自定义数据结构信息就可以实现对数据结构的定义。
本实施例以医院的应用场景为例,用户在填写自定义数据结构信息时,可以以科室为单位进行填写,一个科室对应着一套自定义数据结构信息。需要说明的是,在本申请的一些实施例中,在一个配置界面中,可配置多个科室的数据结果,如果只要注意选择科室就行,这样大幅度节省了用户对数据结构的配置时间。
这里的应用场景为医院,因此可以将部门理解为科室。然后根据自定义数据结构信息生成各科室的数据结构模板,若每个科室的自定义数据结构信息均不同,则分别生成各科室的数据结构模板;若其中两个或多个科室的各科室的数据结构模板相同,则可同时生成多个科室的数据结构模板,但需要注意的是,各科室的数据结构模板是互相独立的。
各科室的数据结构模板可以存储于数据库的指定区域,并且可以通过访问调用实现复用,对于数据结构模板的存储可以以数据库表的形式实现。
子步骤S121:响应于数据结构配置指令,调用目标部门的目标数据结构模板。
在进行数据录入时,用户首先可以进入科室数据录入页面,系统根据所选科室的不同,确定出目标科室,并访问数据库的指定区域,调用并加载与目标科室对应的数据结构模板,记为目标数据结构模板。
子步骤S131:根据目标数据结构模板,确定对应的录入表单,并展示在用户终端。
在加载完目标科室的数据结构模板后,将该模板转化为录入表单,该录入表单可以是可视化的,可以在用户终端显示,用户终端包括但不限于个人电脑、平板电脑和一体机等等。在本申请的一些实施例中,录入表单可以是多功能可嵌套的,即在已有的录入表单的各可填写项中可以再加进去一个或多个项目,如表格、图像、图层或函数等。
子步骤S144:获取录入表单的录入数据,根据目标数据结构模板将录入数据转化为业务数据,并存储于所述数据库中目标部门的业务数据表中。
在录入数据界面的录入表单上,用户可录入任意内容和任意嵌套结构的数据,然后根据目标数据结构模板,将这些任意内容和任意嵌套结构的数据转化为目标科室的业务数据,并将其存储与数据库中目标部门的业务数据表中,以便应用访问和查询这些数据。
在将任意内容和任意嵌套结构的数据转化为目标科室的业务数据时,主要根据目标数据结构模板中的自定义结构和嵌套关系实现,确定出不同数据之间的关联,并形成业务数据。
通过获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;响应于数据结构配置指令,调用目标部门的目标数据结构模板;根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中。本申请能够实现数据的灵活定义,用户可以根据自身需要设置不同的自定义数据结构信息,其能够轻松实现多层数据结构的嵌套;在现有技术中,在录入数据时,通过界面显示那些字段,用户可填写哪些字段,但是本申请弱化了字段的概念,可以接收任意内容和任意嵌套结构的数据,使得数据输入更加灵活,实现了个性化的定义;此外本申请中,数据结构以部门为基本单位,多部门之间数据结构完全独立,在对数据进行访问时,可以互相引用;且不仅可适用于互联网医疗行业,还可广泛用于需要灵活数据定义的领域。
以及数据统计步骤S120包含子步骤S121:接收数据统计指令,并获取与数据统计指令对应的目标数据;子步骤S122:根据所述数据统计指令,基于非关系型数据库的MapReduce方法,对目标数据进行初步统计;子步骤S123:基于Aggregate函数,对所述初步统计的结果进行多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。
子步骤S121:接收数据统计指令,并获取与数据统计指令对应的目标数据。
本申请适用于现有技术的所有的非关系型数据库,由于MongoDB数据库是非关系数据库当中功能最丰富,它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型;它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。因此本申请一下均以MongoDB数据库作为示例进行说明。
首先,接收数据统计指令,并获取与数据统计指令对应的目标数据。数据包括但不限于结构化数据、半结构化数据或非结构化数据。
如关系数据表就是一种结构化数据,其通常以表格的形式呈现,在表格中包含字段,以及字段对应的具体值等信息,由于结构化数据的规整性,对其进行统计是比较容易的。
网页的页面源码的数据可以理解为一种非结构化数据,由于其规整性差,采用关系型数据库对其进行统计,往往得不到较为理性的效果,为此,提出了本申请,本申请的数据统计方法不仅适用于结构化数据,也适用于非结构化数据,尤其对后者具有较好的效果。
对于与数据统计指令对应的目标数据可采取现有技术中的任意一种,根据数据源的不同类型,具体采用的抽取技术不同,主要包括数据库访问技术、远程过程调用(RemoteProcedure Call,RPC)技术以及网页抓取技术。通信设备采集到本地的数据通常存储在数据库中,主要通过数据库访问技术进行抽取。RPC是一种用于创建分布式客户机/服务器应用的高效技术,使用RPC的用户只需关注应用程序的细节,而无需过多关注网络通信的细节。对于网页形式的数据,通常使用网页抓取技术进行抽取。网页抓取技术的一般步骤是:首先通过HTTP(Hypertext Transport Protocol)协议访问目标页面,获取页面内容;其次使用预定义的模板与获取的页面内容进行匹配,抽取出所需数据。对于上述没有描述到的技术方法,或者各方法的详细技术,均可参考现有技术。
子步骤S122:根据数据统计指令,基于非关系型数据库的MapReduce方法,对目标数据进行初步统计。
本发明利用了MongoDB数据库自带的MapReduce特性,用来替代传统关系型数据库通过Mybatis执行预设sql的统计方案。MapReduce具有以下2个特性:第一,MapReduce有2个阶段:map和reduce,mapper处理每一行数据并加入筛选条件,然后reducer将map操作的结果进行分组累加操作。第二,MapReduce使用javascript语法编写,其内部也是基于javascript V8引擎解析并执行,javascript语言的灵活性也让MapReduce可以处理更加复杂的业务场景。
基于以上2个特性,本申请使用javascript语法编写MapReduce中的map和reduce处理逻辑,最终调用MongoDB数据库内置的db.collection.mapReduce()方法,将复杂结构的数据统计为扁平数据,并将此结果保存在数据库中,以供查询。
需要说明的是,在本步骤中,采用MapReduce对目标数据进行初步统计时,不附加复杂的条件过滤逻辑,专注于提供初步统计结果。
子步骤S123:基于Aggregate函数,对初步统计的结果进行多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。
在得到初步统计结构后,本申请基于Aggregate聚合函数,对初步统计的结果进行多条件分析,Aggregate聚合函数对数据进行聚合操作,其可根据数据统计指令中的统计要求,通过条件筛选的方式,将所需数据进行聚合。aggregate()方法的语法如下:aggregate(operators,[options],callback)。
其中,operators参数是聚合运算符的数组,包括但便于$project、$match、$limit和$skip等等,它允许定义对数据执行什么汇总操作。options参数允许你设置readPreference属性,它定义了从哪里读取数据。callback参数是接受err和res。
Aggregate聚合函数专注于多条件分析和查询,对MapReduce提供的初步统计结果进行二次统计,从而得到范围更精确的统计结果。
本申请根据数据统计指令,以非关系型数据库为基础,采用非关系型数据库固有的MapReduce方法,对目标数据进行初步统计,在该初步统计过程中,不添加复杂条件,然后基于Aggregate聚合函数,对初步统计的结果进行复杂的多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。本申请整个统计过程,将复杂结构的数据统计为扁平数据,将此结果保存在数据库中,在外部应用访问数据库时,显著提高了数据库的查询速度;适用于复杂的数据结构和查询条件,尤其对于非结构化数据,有显著的效果;且适用范围广,本申请不仅能够面向企业级医疗数据的抽取、计算、统计,还可以应用于其他企业级项目;还可以通过大数据预测对消费者习惯进行甄别推荐其需要的信息,可以通过对海量数据的汇总分析,提升企业决策能力,切实为用户降低成本。
从图1所示的方法可以看出,本申请能够解决医疗系统中,多维度数据采集、多维度数据统计、数据全生命周期管理、完善数据共享等诸多问题,实现数据的全面开放与利用,释放数据潜在价值,助力医学研究。同时具有处理大数量,高并发,多线程计算等大数据处理能力。并且能够通过ETL技术对原始数据进行抽取、转换、清洗并转存到标准化的数据模型中形成集中存储的临床数据集,并保持与临床业务数据实时同步,为临床诊疗、科研、质控提供数据服务支撑。本申请不仅可适用于互联网医疗行业,还可广泛用于需要灵活数据定义的领域。
在本申请的一些实施例中,所述数据录入步骤还包括:获取新增自定义数据结构信息,根据新增自定义数据结构信息生成新增部门的数据结构模板。
也就是说,当有新部门接入时,用户可以直接在前端界面,对要接入的新部门的数据结构进行定义,具体的,仍然是指定新部门的自定义数据结构信息,这里称之为新增自定义数据结构信息,然后执行本申请的电子设备根据新增自定义数据结构信息生成新增部门的数据结构模板,并将该模板存储于数据库的指定区域等待调用。即在本申请的一些实施例中,当有新部门接入时无需修改数据库结构和项目源码,开发周期短;灵活方法,尤其对于普通工作人员而言,只需要在配制界面,定义想要的数据结构信息,即可实现新部门的接入和数据的自定义。
在本申请的一些实施例中,上述数据录入步骤还包括:提供配置界面,配置界面包括多个自定义数据结构信息配置项,其中多个自定义数据结构信息配置项包括:部门信息配置项、数据类型配置型、数据关系配置项;响应于对自定义数据结构信息配置项的配置指令,通过配置界面,获取所述自定义数据结构信息。
为了方便用户的使用,本申请提供了前端的配置界面,在配制界面多个自定义数据结构信息配置项,需要说明的是,在现有技术中,数据库在配置时通常需要制定数据字段,如姓名、年龄、身高、体重等等。但是在本申请的一些实施例中,在这些数据字段配置项中不是必要的,非关系型数据库弱化了数据库的字段,在本申请中,无需指定数据字段,只需指定部门信息、数据类型和数据关系,即指定一个部门中包含哪些数据类型以及数据关系,数据关系可以是多级的以及嵌套的。用户可以填写任意的内容以及任意嵌套结构的数据,极大提高了数据录入的灵活性,满足不同部门的个性化需求,显著扩大了数据库的应用场景。
对应的,在后端执行本申请的电子设备中,含有与前端配制界面对应的配置规则和配置组件,以便响应于前端配制界面中用户提交的配置指令,对获取所述自定义数据结构信息,并触发后续进程。
在本申请的一些实施例中,数据类型配置型包括高级节点数据类型配置型和低级节点数据类型配置型;其中,高级节点数据类型配置型的可选项为group、list和引用类型中的一种;低级节点数据类型配置型的可选项为string、int、date、dropdown、radio和file中的一种,其中dropdown、radio还配置有可填写项。
在本申请的一些实施例中,数据结构之间支持相互引用,进一步,解决引用不便和多层嵌套数据实现困难的问题,支持多种数据类型。具体的,数据结构可以包括但不限于高级节点和低级节点,低级节点可置于高级节点下层。
高级节点的数据类型包括但不限于group、list和引用类型中的一种。其中,group(组类型),可包含任意节点类型和数据类型,侧重实现复杂的嵌套数据结构;list(数组类型),包含group和引用类型,标明此节点为数组,节点下包含的数据结构为数组单个元素的内容;引用类型,可连接指向已有的公共数据结构,被引用的结构可被引用多次,例如多个科室下都包含有患者基本信息,可将患者基本信息配置为公共数据结构,多个科室共同引用。
低级节点数据类型可以为但不限于string、int、date、dropdown、radio和file中的一种,其中dropdown、radio等组件支持扩展“其他”选项的二级输入框,也支持配置如dropdown组件内的选项。低级节点数据类型具体内容可参考现有技术。
在本申请的一些实施例中,根据所述自定义数据结构信息生成至少一个部门的数据结构模板包括:根据目标部门的自定义数据结构信息,确定目标部门的数据的自定义结构和嵌套关系,并保存在一个模板数据表中,作为该目标部门的数据结构模板;其中,自定义数据结构信息包括目标部门,以及目标部门的数据类型和数据关系。
根据一个部门的自定义数据结构信息,生成的数据结构表,在后续进程中,起到模板的作用,记为模板数据表,将该模板数据表中存储于数据库的指定区域中,可在数据录入过程中进行调用。在数据结构没有变化的前提下,无需每一次对数据结构进行定义,直接调用模板即可。而如果需要对数据结构修改,用户可直接在配置界面进行修改,修改包括增加、删除等操,无需修改数据库结构和项目源码。
在本申请的一些实施例中,根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端包括:获取目标数据结构模板中各节点的组件参数,根据组件参数生成与目标数据结构模板对应的录入表单,其中,组件参数包括组件的长、宽、高、边距、对齐方式。
为了方便前端用户的使用,可将录入表单可视化,具体的,获取目标数据结构模板中各节点的组件参数,然后根据组件参数生成与目标数据结构模板对应的录入表单。对于组件参数的获取,可以从执行本申请的电子设备的指定区域中读取默认值,也可以从前端配制界面获取用户填写的指定值,组件参数包括但不限于组件的长、宽、高、边距、对齐方式,还可以包含色调、亮度等等。也就是说,在本申请的一些实施例中,数据结构配置还可以融合外观配置,用户可自定义组件的长宽高、边距、对齐方式等,无需修改源码即可修改视觉效果,即修改即生效。
在本申请的一些实施例中,对于数据结构模板可以不存储于数据库的内存中,而是通过key-value形式缓存在Redis高速缓存中,即将多个部门的数据结构模板分别独立存储于非关系型数据库的Redis缓存中;将多个部门的业务数据表分别独立存储于非关系型数据库的Redis缓存中。Redis即远程字典服务,是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库。当不涉及数据结构本身的修改时,直接从Redis中读取,减少和MongoDB数据库交互次数,减少响应时间。
在本申请的一些实施例中,所述数据统计步骤还包括:基于lookup函数,对目标数据的统计结果中的多个数据表进行关联处理,以得到关于目标数据的再次统计结果。
在更加复杂的场景下,还可以引入lookup函数,将多个初步统计结果进行联表操作,从而适应更复杂的统计场景。通过联表操作,允许人们通过转换和合并多个文档中的数据来生成新的单个文档中不存在的信息。
lookup函数的主要功能是将每个输入待处理的文档,这里指经过Aggregate聚合函数获得的多个统计文档,经过$lookup阶段的处理,输出的新文档中会包含一个新生成的数组列。
lookup函数的基本语法为:
lookup函数中,语法的含义可参考现有技术。对于lookup函数的应用场景,比如,对于两个文档,可以以字段“商品名称”为主题,基于lookup函数,将两个文档中关于一个特定商品的内容呈现在一个文档里,在这个文档里,如果有不同于原始文档的维度的信息,人们就能够获取到这个特定商品的新的信息。
在本申请的一些实施例中,所述数据统计步骤还包括:基于ECharts方法,对所述目标数据的统计结果进行可视化处理,并在前端展示所述可视化处理结果。
ECharts是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。在执行本申请的电子设备中,可以增加ECharts组件,用于将统计结果进行可视化操作,使用ECharts将统计数据展示为折线图、柱状图、散点图、饼图、K线图等可视化图,使用户一目了然的获知统计结果。
具体的,在本申请的一些实施例中,所述基于ECharts方法,对所述目标数据的统计结果进行可视化处理,包括:读取所述ECharts中内置的type参数;根据所述type参数,确定目标展示类别;根据所述目标展示类别,将所述目标数据的统计结果转化为可视化图形。也就是说,ECharts展示图形的类别由其内置的type参数决定,例如type:'bar'代表柱状图,type:'line'代表折线图。由此本申请将type参数设计成一个可传入的参数,页面加载ECharts图时,同时获得统计数据和图类型type参数,后将type参数传入ECharts,用以实现图标展示的可配置,用户可以通过配置type参数,获取自己想要的图标类型。
因此,本申请的视觉设计,均可采用目前较流行的设计原则进行设计。功能上更贴合实际需求,操作上符合用户实际使用习惯,将用户体检做到超出用户预期的程度。在本申请的一些实施例中,视觉设计方面,可以采用类似大屏的主页展示方式,重点数据通过图形、图表、字体形态的变化等方法达到图文结合、重点突出、易浏览的效果。
在本申请的一些实施例中,在上述方法的数据统计步骤中,对初步统计的结果进行多条件分析,包括:将初步统计的结果转换为aggregate函数可识别的语法规则;根据分析条件,对简单初步统计的结果进行过滤,以得到分析结果;其中,分析条件包括一下的至少一项:分组、排序、分页、过滤空值、以及等、不等、包含、不包含。
在采用aggregate聚合函数对初步统计结果进行二次统计时,先将初步统计结果转化为aggregate函数可识别的语法规则,然后依据分组、排序、分页、过滤空值、以及等、不等、包含、不包含条件等复杂条件进行分析,从而实现对初步统计结果的过滤分析,得到进一步的目标数据的统计结果。
在现有技术中,对于上述复杂的多条件查询,通常是由MapReduce直接实现的,MapReduce是从原始数据抽取、统计目标数据的步骤,在这个阶段附件复杂的条件过滤逻辑,无疑严重增加了MapReduce的负担,影响了查询的速度和精度。而在本申请中,不同于现有技术之处在于,MapReduce只是从原始数据进行简单的统计,而Aggregate聚合函数在MapReduce的初步统计的结果之上,主要专注于多条件查询,这将原本由MapReduce负担的工作量,转移至下游的Aggregate聚合函数中,而Aggregate聚合函数已经有了MapReduce的初步统计的基础,能够实现快速、准确的统计,这种方式尤其对非结构化数据效果显著。
在本申请的一些实施例中,在上述方法的数据统计步骤中,对分析结果进行再次统计,以得到目标数据的统计结果,包括:根据目标维度,将分析结果进行汇总,得到目标数据的统计结果。
在采用MapReduce形成的初步统计结果中,由于没有进行条件过滤,数据是相对杂乱的,在采用Aggregate聚合函数的二次统计中,可以将具有共性的数据汇总在一起,如目标维度为一个目标商品的相关信息,则可以根据Aggregate聚合函数将还有该目标商品的数据整合在一起,到的最终的统计结果。
在本申请的一些实施例中,医疗数据录入产品是部署在外网环境下的web服务,用户在有网络的情况下通过浏览器能正常的使用此类产品,而无外网的时候无法使用。为了满足用户在无网络的环境下也能正常使用产品功能,本申请开发了相对应的离线数据录入程序,以满足上述需求。将离线数据录入程序部署在多个用户的设备终端,在无网的情况下,用户可以根据离线数据录入程序进行数据的录入。
图2示出根据本申请的一个实施例的仅存在局域网时,一种基于非关系型数据库的数据管理系统的用户端的结构示意图,本申请可以基于但不限于图2示出系统来实现,从图2可以看出,在图2所示的系统200中,包括多个设备终端210,在每个设备终端210中部署有本申请的数据库的离线数据录入程序。在多个设备终端210中,可以指定一个为主节点,其余为从节点,该指定可以是任意的,本申请不做限制。这里将主节点记为210-1,将从节点记为210-2;主节点210-1与各从节点210-2分别通信连接,如在从节点输入主节点的数据库的离线数据录入程序的IP地址,从节点在与主节点进行数据交互时,可以通过IP地址实现。
图3示出根据本申请的一个实施例的仅存在局域网时,基于非关系型数据库的数据管理过程中数据录入的流程示意图,从图3可以看出,本实施例至少包括步骤S310~步骤S330:
步骤S310:接收各从节点发送的数据。
本申请主要针对无外网存在,只有局域网存在的情况下设计的。
用户可以在各节点输入数据,包括本节点,即主节点以及各从节点。各从节点将用户输入的数据发送至主节点,主节点接收各从节点发来的数据。在本申请的一些实施例中,为了保障数据的安全性,从节点在向主节点发送数据时,可以对数据进行加密保护。
如图2所示,实现本申请的各终端节点中,需要提前安装数据库的离线数据录入程序,在本申请的一些实施例中,安装数据库的离线数据录入程序是与线上版本对应的,其无需完全重新开发,可以在线上版本的基础上,使用C++语言编写的一套对Chromium和NodeJs环境封装、并且集成了java和mongoDB应用环境的原生应用。通过nodeJs访问操作系统原生层,Chromium解析浏览器HTML,CSS和JavaScript脚本,java环境解析后台jar包语言、并使用mongoDB做为数据库处理后台逻辑的一整套应用生态。
在安装数据库的离线数据录入程序时,可通过网络、无网络(硬盘/U盘拷贝)的传输方式,这里首次安装该程序过程中需要有网环境,将在线的web程序包和后台需要的jar包程序下载到本地,以进行安装。在后续使用数据库的离线数据录入程序的过程中,会根据用户终端设备当前的网络状态,来自动判断是否需要更新程序包。
步骤S320:将各节点发送的数据进行汇总,得到待同步数据。
主节点将本节点以及各从节点的数据进行汇总,具体的,包括但不限于进行去重等操作,得到汇总后的数据,该数据记为待同步数据,该待同步数据包含不同的用户从各个节点输入的数据。
步骤S330:将待同步数据分发至各从节点,以实现各节点的数据录入。
主节点在完成数据汇总后,将待同步数据分发至各从节点,具体的,可以依据从节点的IP地址发送给各从节点,以实现各节点的数据的同步和录入。
从图3所示的方法可以看出,本申请针对数据库在无网或者仅有局域网的情况下,数据库无法进行使用的问题,提出了一种离线数据录入方法,在多个终端节点安装数据库的离线数据录入程序,在这些终端节点中,一个主节点,其余为从节点,主节点与各从节点分别通信连接;各从节点将数据发送至主节点,主节点得到多个从节点发送来的数据后,进行汇总、整合,然后将汇总得到的数据分发给各个从节点由此实现只存在局域网时,各节点之间的数据同步。本申请通过在多个终端设备中部署以数据库为依托的离线数据录入程序,使得用户在无外网,仅存在局域网的时候,在离线数据录入程序实现数据的录入,并且能够同步给部门的多个终端设备,以实现数据的同步和共享;数据录入效率高,克服了现有技术中,无网或仅有局域网环境下,数据库系统无法使用的问题。且本申请适用范围广,不仅适用于医疗系统,对于其他多设备的离线数据录入场景也适用。
在本申请的一些实施例中,所述方法还包括:在网络环境恢复后,将所述离线数据录入程序中的待同步数据发送至线上数据录入程序,以实现线上线下数据的同步。
也就是说,在网络环境恢复后,主节点将待同步数据发送至线上数据录入程序,以实现线上线下数据的同步。具体的,在本申请的一些实施例中,当网络环境可连接外网时,离线数据录入程序所在的终端节点访问线上数据录入程序提供的http接口,将本节点数据发送给线上数据录入程序,从而实现数据上报。
在本申请的一些实施例中,所述方法还包括:响应于数据拷贝指令,将所述待同步数据发送至移动存储设备。如果网络环境一直无法恢复,则可以采用人工的方法进行数据的传输,在无网环境,甚至是没有局域网的情况下,可以使用U盘等移动存储设备拷贝数据。
在本申请的一些实施例中,在上述方法中,所述接收各从节点发送的数据包括:接收从节点发送的数据包,所述数据包是从节点将原始数据采用密码盐进行压缩,得到压缩包,并对所述压缩包进行字节异或加密得到的。所述将各从节点发送的数据进行汇总,得到待同步数据包括:分别对接收的各节点发送的数据包按位异或解密,得到压缩包,并对压缩包采用密码盐进行解压;对解密得到的数据去重以及整合操作,得到待同步数据。
为了保障数据的安全,终端节点之间传送数据可以对数据进行加密后再进行传输。主节点接到加密后的数据需要进行解密操作才能得到数据。
对于数据的加密了采用现有技术中的任意一种,如采用文件特征值的技术对数据进行加密,文件特征值包括但不限于MD5签名值以及超级特征值等。如MD5签名值的生成原理可简述为:将数据按一定的规则排序,加上appkey码(暂无统一中文名)一起生成签名值,MD5签名值通常最少是32位的,很难破解,因此安全性非常高,举例来讲,一个文件的MD5签名值为:839f612973312fa82d406aa90b8f5fd。
在本申请的一些实施例中,提供了一种双重加密方法,考虑到数据安全,本申请使用密码盐压缩文件、异或字节加密压缩包双重加密,密码加密压缩文件:使得欲解压压缩文件必须使用正确密码盐;异或字节加密压缩包:使得压缩包解密后,还需二次解密为原始数据,双重保险,保证传输过程中的数据安全。
具体的加密-解密过程如下:加密过程中,数据提供方,即从节点,接收用户填写的原始数据,该原始数据为明文原文件,从节点对该明文原文件进行密码盐压缩文件,产生zip压缩包,然后对zip压缩进行按字节异或加密,最终获得双重加密的zip压缩包,可进行导出或http协议传输。
解密过程中,数据获取方,即主节点得到双重加密后的zip压缩包,进行与加密相反的解密过程。首先对aip包进行按位异或解密,得到解密后的zip压缩包,然后使用密码盐进行解压zip文件,得到完全解密的明文文件夹,最后将数据从文件中读取,保存到数据库中,在本申请中推荐使用分布式的MongoDB数据库。
在本申请的一些实施例中,在上述方法中,所述离线数据录入程序的安装包是采用Xjar并附加密码盐进行加密得到的系统安装包文件和解密运行程序文件;所述在多个终端节点安装离线数据录入程序包括:采用所述解密运行程序文件运行所述系统安装包文件,以实现所述离线数据录入程序的安装。
也就是说,在本申请的一些实施例中,对于离线数据录入程序的安装包本申请也是进行加密保护的,具体的,引入Xjar加密工具,基于对JAR包内资源的加密以及拓展ClassLoader来构建的一套程序,在安装包进行安装时,加密启动,动态解密运行的方案,避免源码泄露以及反编译,以此杜绝反编译源码泄露风险。
对于安装包加密-解密的过程,可简单陈述如下:在安装包加密中,对离线版安装包使用Xjar加密并附加密码盐,得到加密后的系统安装包xxx.jar文件和解密运行程序xxx.go文件。在对安装包进行安装时,要对安装包解密运行,具体的,运行时使用xxx.go解密程序,解密运行加密后的xxx.jar离线版安装包;由于以上解密运行过程中,xxx.go运行xxx.jar,并未对xxx.jar进行解密操作,故无法进行反编译得到源码,杜绝源码泄露。
在本申请的一些实施例中,所述方法还包括:数据校核步骤:响应于数据校核请求,对待校核数据文件进行校核;数据检索步骤:响应于数据检索请求,在所述非关系型数据库中查询到目标数据,并返回前端界面;病例浏览步骤:响应于病例浏览请求,在所述非关系型数据库中查询到目标病例,并返回前端界面。也就是说,本申请能够响应于各种业务请求,进行各种业务操作,如数据校核、数据检索以及病例浏览等等。
图4示出了根据本申请一个实施例的一种基于非关系型数据库的医疗数据管理系统的结构示意图,所述系统400至少包括互相连接的数据录入模块410以及数据统计模块420,各模块分别用于实现上述相对应的方法步骤,具体的:
数据录入模块410:用于获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;响应于数据结构配置指令,调用目标部门的目标数据结构模板;根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中;以及
数据统计模块420:用于接收数据统计指令,并获取与数据统计指令对应的目标数据;根据所述数据统计指令,基于非关系型数据库的MapReduce方法,对目标数据进行初步统计;基于Aggregate函数,对所述初步统计的结果进行多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。
在本申请的一些实施例中,所述系统400还包括:数据校核模块:用于响应于数据校核请求,对待校核数据文件进行校核;数据检索模块:用于响应于数据检索请求,在所述非关系型数据库中查询到目标数据,并返回前端界面;病例浏览模块:用于响应于病例浏览请求,在所述非关系型数据库中查询到目标病例,并返回前端界面。
本申请基于非关系型数据库的医疗数据管理系统从整体架构设计开始,充分考虑医疗体系特色,尤其是医院的特殊性需求,重点设计系统人员管理、权限管理、科室管理等重点功能,以科室为最小数据存储单元,加以灵活的权限配置方式,做到从人员到科室到医院的全灵活配置。
本申请的基于非关系型数据库的医疗数据管理系统从流程设计方面,采用最扁平化设计,是整个系统操作通过一条主线能够全部完成。避免用户在使用系统时,因为流程复杂而造成效率低下、成本浪费等问题。同时角色设计时,也将基础角色数量降到最低,以实现在灵活权限配置时,因为角色复杂而造成配置繁琐的问题。
综上所述,本申请能够解决医疗系统中,多维度数据采集、多维度数据统计、数据全生命周期管理、完善数据共享等诸多问题,实现数据的全面开放与利用,释放数据潜在价值,助力医学研究。同时具有处理大数量,高并发,多线程计算等大数据处理能力。并且能够通过ETL技术对原始数据进行抽取、转换、清洗并转存到标准化的数据模型中形成集中存储的临床数据集,并保持与临床业务数据实时同步,为临床诊疗、科研、质控提供数据服务支撑。本申请不仅可适用于互联网医疗行业,还可广泛用于需要灵活数据定义的领域。管理系统
管理系统管理系统
图5是本申请的一个实施例电子设备的结构示意图。请参考图3,在硬件层面,该电子设备包括处理器,可选地还包括内部总线、网络接口、存储器。其中,存储器可能包含内存,例如高速随机存取存储器(Random-Access Memory,RAM),也可能还包括非易失性存储器(non-volatile memory),例如至少1个磁盘存储器等。当然,该电子设备还可能包括其他业务所需要的硬件。
处理器、网络接口和存储器可以通过内部总线相互连接,该内部总线可以是ISA(Industry Standard Architecture,工业标准体系结构)总线、PCI(PeripheralComponent Interconnect,外设部件互连标准)总线或EISA(Extended Industry StandardArchitecture,扩展工业标准结构)总线等。所述总线可以分为地址总线、数据总线、控制总线等。为便于表示,图5中仅用一个双向箭头表示,但并不表示仅有一根总线或一种类型的总线。
存储器,用于存放程序。具体地,程序可以包括程序代码,所述程序代码包括计算机操作指令。存储器可以包括内存和非易失性存储器,并向处理器提供指令和数据。
处理器从非易失性存储器中读取对应的计算机程序到内存中然后运行,在逻辑层面上形成非关系型数据库的数据管理系统。处理器,执行存储器所存放的程序,并具体用于执行以下操作:
数据录入步骤:获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;响应于数据结构配置指令,调用目标部门的目标数据结构模板;根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中;以及
数据统计步骤:接收数据统计指令,并获取与数据统计指令对应的目标数据;根据所述数据统计指令,基于非关系型数据库的MapReduce方法,对目标数据进行初步统计;基于Aggregate函数,对所述初步统计的结果进行多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果
上述如本申请图1所示实施例揭示的非关系型数据库的数据管理系统执行的方法可以应用于处理器中,或者由处理器实现。处理器可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器可以是通用处理器,包括中央处理器(CentralProcessing Unit,CPU)、网络处理器(Network Processor,NP)等;还可以是数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific IntegratedCircuit,ASIC)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本申请实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本申请实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。
该电子设备还可执行图1中非关系型数据库的数据管理系统执行的方法,并实现非关系型数据库的数据管理系统在图1所示实施例的功能,本申请实施例在此不再赘述。
本申请实施例还提出了一种计算机可读存储介质,该计算机可读存储介质存储一个或多个程序,该一个或多个程序包括指令,该指令当被包括多个应用程序的电子设备执行时,能够使该电子设备执行图1所示实施例中非关系型数据库的数据管理系统执行的方法,并具体用于执行:
数据录入步骤:获取自定义数据结构信息,根据所述自定义数据结构信息生成至少一个部门的数据结构模板;响应于数据结构配置指令,调用目标部门的目标数据结构模板;根据所述目标数据结构模板,确定对应的录入表单,并展示在用户终端;获取所述录入表单的录入数据,根据所述目标数据结构模板将所述录入数据转化为业务数据,并存储于目标部门的业务数据表中;以及
数据统计步骤:接收数据统计指令,并获取与数据统计指令对应的目标数据;根据所述数据统计指令,基于非关系型数据库的MapReduce方法,对目标数据进行初步统计;基于Aggregate函数,对所述初步统计的结果进行多条件分析,并对分析结果进行再次统计,以得到目标数据的统计结果。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 基于非易失存储系统的高性能关系型数据库服务系统
- 基于区块链的分布式关系型数据库的管理方法及系统