技术领域
本发明涉及网络安全领域,尤其涉及一种恶意网站检测方法、装置、系统及设备。
背景技术
恶意网站是试图通过漏洞,安装恶意软件的方式来干扰计算机操作,收集用户个人信息甚至完全控制用户机器的网站。在多数情况下,恶意网站往往伪装成合法网站的样子,它可以让人们正常浏览页面内容,同时非法获取用户机器中的各种数据。恶意网站不仅是传播电脑病毒的重要源头,还会善用“伪装”手段,传播不良信息或者实现欺诈行为。严重影响了网民利益以及上网的安全性。
恶意网站一般有三种表现形式:钓鱼网站,垃圾邮件网站以及恶意软件网站。钓鱼网站会尽可能的模仿正常网站的表现形式,通过视觉上欺骗用户来窃取用户的隐私信息。当访问者输入自己的个人信息或者银行卡信息时,这些数据将会被不法分子窃取,甚至可能出售用户的个人信息,造成严重损失。垃圾网站是指通过一系列技术颠覆搜索引擎排名算法导致其搜索结果优先的不良网站。垃圾网站中可能含有指向不良网站的链接,虚假或非法的内容等。通过增加用户搜索的几率来像用户传播不良信息。恶意软件网站会在用户未注意时在用户设备上安装恶意软件。通过部署恶意软件来作为提取设备数据,控制设备的切入点。
传统的检测方法主要利用人为选定的网站定量特征结合机器学习方法进行检测,该方法在特征选择上过于依赖专家经验,并且仅考虑单个网站节点的特征,没有将网站节点放在网络整体环境中,忽略了相邻网站节点对于该网站的重要影响关系。基于单个网站节点的机器学习方法无法充分考虑网站的空间特性。
恶意网站作为一种重要的网络攻击手段,近年来随着网络技术的发展,恶意网站形式越来越多样化,增强了恶意网站的隐蔽性与加密性,使得检测越来越困难,对于恶意网站的检测需求也日益增加。传统的检测方法主要使用模式匹配算法或者机器学习算法对单个网站节点的相关统计特征进行检测,该类方法仅考虑了单个网站节点的特征,不能有效的表现相邻网站节点之间的强关系性以及空间特性,且没有考虑现实存在的网站种类数量严重不平衡问题。特征的提取方式也较为依赖专家经验。
近年来,随着自然语言处理的兴起,提供了许多抽取文本信息的方法。在网页中,文本是重要的组成部分,网页的文本语义是判断网页好坏的重要依据。依靠自然语言分析处理网页文本信息,不仅可以强化网页语义表示,还可以不完全依赖专家经验而获取网站特征信息。
有鉴于此,特提出本发明。
发明内容
本发明的目的是提供了一种恶意网站检测方法、装置、系统及设备,能通过检测网站的节点特征以及与网络的拓扑关系对恶意网站准确识别,进而解决现有技术中存在的上述技术问题。
本发明的目的是通过以下技术方案实现的:
本发明实施方式提供一种恶意网站攻击检测方法,包括:
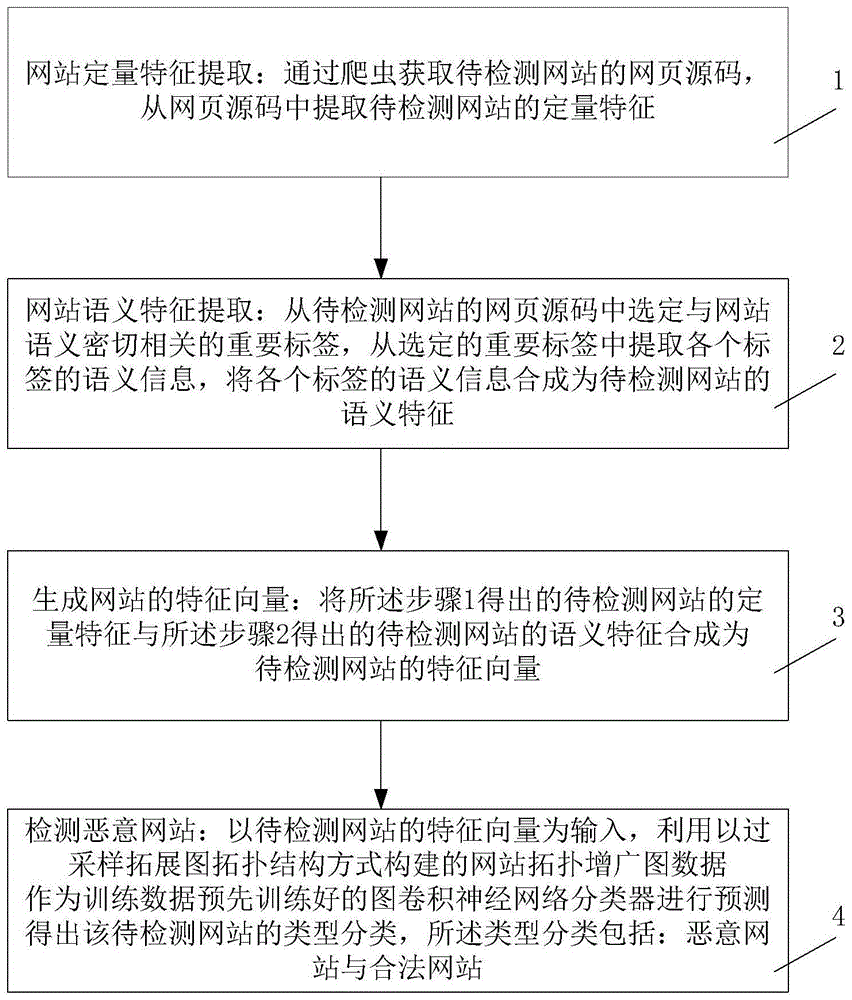
步骤1,网站定量特征提取:获取待检测网站的网页源码,从网页源码中提取待检测网站的定量特征,所述定量特征包括:内容特征和链接特征;
步骤2,网站语义特征提取:从待检测网站的网页源码中选定与网站语义密切相关的重要标签,从选定的重要标签中提取各个标签的语义信息,将各个标签的语义信息合成为待检测网站的语义特征;
步骤3,生成网站的特征向量:将所述步骤1得出的待检测网站的定量特征与所述步骤2得出的待检测网站的语义特征合成为待检测网站的特征向量;
步骤4,检测恶意网站:以待检测网站的特征向量为输入,利用以过采样拓展图拓扑结构方式构建的网站拓扑增广图数据作为训练数据预先训练好的图卷积神经网络分类器进行预测得出该待检测网站的类型分类,所述类型分类包括:恶意网站与合法网站。
本发明实施例还提供一种恶意网站攻击检测装置,包括:网站定量特征提取模块、网站语义特征提取模块、网站特征向量生成模块和恶意网站检测模块;其中,
所述网站定量特征提取模块,与所述网站特征向量生成模块通信连接,能获取待检测网站的网页源码,从网页源码中提取待检测网站的定量特征,所述定量特征包括:内容特征和链接特征;
所述网站语义特征提取模块,与所述网站特征向量生成模块通信连接,能从待检测网站的网页源码中选定与网站语义密切相关的重要标签,从选定的重要标签中提取各个标签的语义信息,将各个标签的语义信息合成为待检测网站的语义特征;
所述网站特征向量生成模块,与所述恶意网站检测模块通信连接,能将所述网站定量特征提取模块得出的待检测网站的定量特征与所述网站语义特征提取模块得出的待检测网站的语义特征合成为待检测网站的特征向量;
所述恶意网站检测模块,能以所述网站特征向量生成模块输出的待检测网站的特征向量为输入,利用以过采样拓展图拓扑结构方式构建的网站拓扑增广图数据作为训练数据预先训练好的图卷积神经网络分类器进行预测得出该待检测网站的类型分类,所述类型分类包括:恶意网站与合法网站。
本发明实施方式还提供一种恶意网站攻击检测系统包括若干终端设备和至少一个应用数据安全网关,所述应用数据安全网关采用本发明所述的恶意网站攻击检测装置;
各终端设备均通过应用数据安全网关访问互联网的网站,在任一终端设备通过应用数据安全网关访问互联网的网站时,由所述应用数据安全网关对所访问的网站进行检测,若检测确认所访问网站为恶意网站时,则禁止终端设备对该恶意网站的访问。
本发明实施方式进一步提供一种处理设备,包括:
至少一个存储器,用于存储一个或多个程序;
至少一个处理器,能执行所述存储器所存储的一个或多个程序,在一个或多个程序被处理器执行时,使得所述处理器能实现本发明所述的方法。
与现有技术相比,本发明所提供的恶意网站检测方法、装置、系统及设备,其有益效果包括:
通过网站语义特征提取将网站标签文本语义引入特征提取环节,摒弃了传统特征提取方式过于依赖专家经验的缺陷,强化表达了网站文本标签主题的相关性以及相邻网页的语义连接性;在预先训练阶段,利用过采样处理方式得到网站拓扑增广图数据训练图卷积神经网络分类器,充分考虑到恶意网站与合法网站数据不平衡的问题,避免了恶意网站样本量不足,若直接用于训练,存在过拟合降低检测准确率的问题;检测恶意网站步骤利用图卷积神经网络作为特征提取器以及分类器,不同于传统方式考虑单节点特征,能挖掘网站之间的关联关系,以构建拓扑图的方式将邻居节点网站的属性融入网站特征学习中,可以更有效地检测网站是否为恶意网站。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
图1为本发明实施例提供的恶意网站检测方法的流程图。
图2为本发明实施例提供的恶意网站检测方法的训练阶段流程图。
图3为本发明实施例提供的恶意网站检测方法的网站语义特征提取步骤的page2vec算法流程图。
图4为本发明实施例提供的恶意网站检测方法的图卷积神经网络分类器的训练框架图。
图5为本发明实施例提供的恶意网站检测装置的构成示意图。
图6为本发明实施例提供的恶意网站检测系统的构成示意图。
具体实施方式
下面结合本发明的具体内容,对本发明实施例中的技术方案进行清楚、完整地描述;显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,这并不构成对本发明的限制。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
首先对本文中可能使用的术语进行如下说明:
术语“和/或”是表示两者任一或两者同时均可实现,例如,X和/或Y表示既包括“X”或“Y”的情况也包括“X和Y”的三种情况。
术语“包括”、“包含”、“含有”、“具有”或其它类似语义的描述,应被解释为非排它性的包括。例如:包括某技术特征要素(如原料、组分、成分、载体、剂型、材料、尺寸、零件、部件、机构、装置、步骤、工序、方法、反应条件、加工条件、参数、算法、信号、数据、产品或制品等),应被解释为不仅包括明确列出的某技术特征要素,还可以包括未明确列出的本领域公知的其它技术特征要素。
术语“由……组成”表示排除任何未明确列出的技术特征要素。若将该术语用于权利要求中,则该术语将使权利要求成为封闭式,使其不包含除明确列出的技术特征要素以外的技术特征要素,但与其相关的常规杂质除外。如果该术语只是出现在权利要求的某子句中,那么其仅限定在该子句中明确列出的要素,其他子句中所记载的要素并不被排除在整体权利要求之外。
除另有明确的规定或限定外,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如:可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本文中的具体含义。
下面对本发明所提供的恶意网站检测方法、装置、系统及设备进行详细描述。本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。本发明实施例中未注明具体条件者,按照本领域常规条件或制造商建议的条件进行。本发明实施例中所用试剂或仪器未注明生产厂商者,均为可以通过市售购买获得的常规产品。
如图1所示,本发明实施例提供一种恶意网站攻击检测方法,包括:
步骤1,网站定量特征提取:获取待检测网站的网页源码,从网页源码中提取待检测网站的定量特征,所述定量特征包括:内容特征和链接特征;
步骤2,网站语义特征提取:从待检测网站的网页源码中选定与网站语义密切相关的重要标签,从选定的重要标签中提取各个标签的语义信息,将各个标签的语义信息合成为待检测网站的语义特征;
步骤3,生成网站的特征向量:将所述步骤1得出的待检测网站的定量特征与所述步骤2得出的待检测网站的语义特征合成为待检测网站的特征向量;
步骤4,检测恶意网站:以待检测网站的特征向量为输入,利用以过采样拓展图拓扑结构方式构建的网站拓扑增广图数据作为训练数据预先训练好的图卷积神经网络分类器进行预测得出该待检测网站的类型分类,所述类型分类包括:恶意网站与合法网站。
上述方法中,按以下方式以过采样拓展图拓扑结构方式构建的网站拓扑增广图数据作为训练数据训练图卷积神经网络分类器,包括:
步骤401,对现有网站拓扑进行特征提取:通过图神经网络分类器对输入的网站的特征向量进行提取,学习网站节点表示,得出网站节点属性和图拓扑信息;
步骤402,在嵌入空间中生成少数类节点的特征属性:利用恶意网站的特征值与它们在嵌入空间中最近的邻域进行插值生成新节点属性,该新节点属性属于恶意网站节点类别;
步骤403,构造新合成节点与旧节点之间的链接关系:
新合成节点后需要构造新、旧节点的链接关系,对网站原拓扑图进行扩充,采用带权内积解码器计算新合成节点与旧节点之间的相关性,推导边的生成,根据生成的边在网站原拓扑图上链接新合成节点完成网站原拓扑图的扩充得到网站拓扑增广图数据;
步骤404,以得到的网站拓扑增广图数据作为训练数据训练图卷积神经网络分类器。
上述方法中,所述图卷积神经网络分类器的结构是由输入层、隐藏层和输出层组成的双层图卷积神经网络;
其中,输入层的输入为网站拓扑增广图数据的邻接矩阵以及各网站的特征向量,输入层的图卷积公式为:
其中,g
隐藏层作为特征提取器,接收所述输入层的输出,该隐藏层的传递函数为:
其中,各参数含义为:σ是非线性激活函数;
输出层的前向传播公式为:
其中,W
输出层分类的损失函数为:
其中,Loss是输出层的分类损失函数;Y
上述方法的步骤1中,按以下方式从网页源码中提取待检测网站的内容特征和链接特征,包括:
以标签为单位对网页源码进行拆分,拆分后得到以标签为单位的HTML代码,从
、<meta>、<body>、<a>各标签对应的HTML代码提取待检测网站的内容特征及链接特征;其中,</p><p>所述待检测网站的内容特征包括:停用词数量特征值、错误词数量特征值、关键字数量特征值、网页文本词汇数量特征值;</p><p>所述待检测网站的链接特征包括:网页排名值、空链接数量特征值、网页重定向链接数量特征值、网页外部链接数量特征值。</p><p>上述方法中,所述停用词数量特征值的停用词指网页文本中没有实际意义的词汇,该停用词数量特征值的计算方式如下:</p><p>/></p><p>其中,F1为停用词数量特征值;stop_rate是停用词比率,指网页中停用词数量占总字数的比率,N</p><p>所述错误词数量特征值的错误词汇指网页文本中拼写错误或者不存在的词汇,该错误词数量特征值的计算方式如下:</p><p>其中,F2为错误词数量特征值;error_rate为错误词比率,指网页中错误的词数量占总字数的比率,N</p><p>所述关键字数量特征值的计算方式如下:</p><p>其中,F3为关键字数量特征值;N</p><p>所述网页排名值的计算方式如下:</p><p>其中,F5为网页排名值;PR是网络拓扑图中网站节点的PageRank值;d是阻尼因子,一般取0.85;p</p><p>所述空链接数量特征值的计算方式如下:</p><p>其中,F6为空链接数量特征值;null_rate是网页空链接率,L</p><p>所述网页重定向链接数量特征值的计算方式如下:</p><p>其中,F7为网页重定向链接数量特征值;redirect_rate是网页重定向链接率,L</p><p>所述网页外部链接数量特征值的计算方式如下:</p><p>其中,F8为网页外部链接数量特征值;out_rate是网页重定向链接率,L</p><p>上述方法的步骤2中,按以下方式从待检测网站的网页源码中选定与网站语义密切相关的重要标签,从选定的重要标签中提取各个标签的语义信息,合成待检测网站的语义特征,包括:</p><p>从待检测网站的网页源码中选定<body>、<keyword>、<description>和<title>四种标签作为与网站语义密切相关的重要标签;</p><p>将选定的同一标签内的文本视为整体,采用word2vec算法从各标签中的上下文词汇,预测当前词汇得到当前词汇的向量化表示,将得到的每个词汇的输出向量以标签为单位聚合成为标签向量,将所有标签向量结合生成标签矩阵,利用标签矩阵通过自注意力机制得出查询向量序列、关键向量序列和值向量序列,通过查询向量序列、关键向量序列和值向量序列计算得出各标签的注意力值,标签的注意力值的计算公式为:</p><p>其中,D是注意力值;Q,K,V分别为查询向量序列、关键向量序列和值向量序列,</p><p>利用上述方式计算得出的<body>、<keyword>、<description>和<title>标签的注意力值,按以下方式计算合成待检测网站的语义特征,为:</p><p>o</p><p>其中,各参数含义为:F9为待检测网站的语义特征;o</p><p>本发明实施例还提供一种恶意网站攻击检测装置,包括:网站定量特征提取模块、网站语义特征提取模块、网站特征向量生成模块和恶意网站检测模块;其中,</p><p>所述网站定量特征提取模块,与所述网站特征向量生成模块通信连接,能获取待检测网站的网页源码,从网页源码中提取待检测网站的定量特征,所述定量特征包括:内容特征和链接特征;</p><p>所述网站语义特征提取模块,与所述网站特征向量生成模块通信连接,能从待检测网站的网页源码中选定与网站语义密切相关的重要标签,从选定的重要标签中提取各个标签的语义信息,将各个标签的语义信息合成为待检测网站的语义特征;</p><p>所述网站特征向量生成模块,与所述恶意网站检测模块通信连接,能将所述网站定量特征提取模块得出的待检测网站的定量特征与所述网站语义特征提取模块得出的待检测网站的语义特征合成为待检测网站的特征向量;</p><p>所述恶意网站检测模块,能以所述网站特征向量生成模块输出的待检测网站的特征向量为输入,利用以过采样拓展图拓扑结构方式构建的网站拓扑增广图数据作为训练数据预先训练好的图卷积神经网络分类器进行预测得出该待检测网站的类型分类,所述类型分类包括:恶意网站与合法网站。</p><p>上述装置中,所述网站定量特征提取模块按以下方式从网页源码中提取待检测网站的内容特征和链接特征,包括:</p><p>以标签为单位对网页源码进行拆分,拆分后得到以标签为单位的HTML代码,从<title>、<meta>、<body>、<a>各标签对应的HTML代码提取待检测网站的内容特征及链接特征;其中,</p><p>所述待检测网站的内容特征包括:停用词数量特征值、错误词数量特征值、关键字数量特征值、网页文本词汇数量特征值;</p><p>其中,所述停用词数量特征值的停用词指网页文本中没有实际意义的词汇,该停用词数量特征值的计算方式如下:</p><p>其中,F1为停用词数量特征值;stop_rate是停用词比率,指网页中停用词数量占总字数的比率,N</p><p>所述错误词数量特征值的错误词汇指网页文本中拼写错误或者不存在的词汇,该错误词数量特征值的计算方式如下:</p><p>其中,F2为错误词数量特征值;error_rate为错误词比率,指网页中错误的词数量占总字数的比率,N</p><p>所述关键字数量特征值的计算方式如下:</p><p>其中,F3为关键字数量特征值;N</p><p>所述待检测网站的链接特征包括:网页排名值、空链接数量特征值、网页重定向链接数量特征值、网页外部链接数量特征值;</p><p>其中,所述网页排名值的计算方式如下:</p><p>其中,F5为网页排名值;PR是网络拓扑图中网站节点的PageRank值;d是阻尼因子;</p><p>所述空链接数量特征值的计算方式如下:</p><p>其中,F6为空链接数量特征值;null_rate是网页空链接率,L</p><p>所述网页重定向链接数量特征值的计算方式如下:</p><p>其中,F7为网页重定向链接数量特征值;out_rate是网页重定向链接率,L</p><p>所述网页外部链接数量特征值的计算方式如下:</p><p>其中,F8为网页外部链接数量特征值;out_rate是网页重定向链接率,L</p><p>所述网站语义特征提取模块按以下方式从待检测网站的网页源码中选定与网站语义密切相关的重要标签,从选定的重要标签中提取各个标签的语义信息,合成待检测网站的语义特征,包括:</p><p>从待检测网站的网页源码中选定<body>、<keyword>、<description>和<title>四种标签作为与网站语义密切相关的重要标签;</p><p>将选定的同一标签内的文本视为整体,采用word2vec算法从各标签中的上下文词汇,预测当前词汇得到当前词汇的向量化表示,将得到的每个词汇的输出向量以标签为单位聚合成为标签向量,将所有标签向量结合生成标签矩阵,利用标签矩阵通过自注意力机制得出查询向量序列、关键向量序列和值向量序列,通过查询向量序列、关键向量序列和值向量序列计算得出各标签的注意力值,标签的注意力值的计算公式为:</p><p>其中,D是注意力值;Q,K,V分别为查询向量序列、关键向量序列和值向量序列,</p><p>利用上述方式计算得出的<body>、<keyword>、<description>和<title>标签的注意力值,按以下方式计算合成待检测网站的语义特征,为:</p><p>o</p><p>其中,各参数含义为:F9为待检测网站的语义特征;o</p><p>所述恶意网站检测模块的图卷积神经网络分类器的结构是由输入层、隐藏层和输出层组成的双层图卷积神经网络;</p><p>其中,输入层的输入为网站拓扑增广图数据的邻接矩阵以及各网站的特征向量,输入层的图卷积公式为:</p><p>其中,g</p><p>隐藏层作为特征提取器,接收所述输入层的输出,该隐藏层的传递函数为:</p><p>其中,各参数含义为:</p><p>输出层的前向传播公式为:</p><p>其中,W</p><p>输出层分类的损失函数为:</p><p>其中,Loss是输出层的分类损失函数;Y</p><p>本发明实施例又提供一种恶意网站攻击检测系统,包括若干终端设备和至少一个应用数据安全网关,所述应用数据安全网关采用上述的恶意网站攻击检测装置;</p><p>各终端设备均通过应用数据安全网关访问互联网的网站,在任一终端设备通过应用数据安全网关访问互联网的网站时,由所述应用数据安全网关对所访问的网站进行检测,若检测确认所访问网站为恶意网站时,则禁止终端设备对该恶意网站的访问。</p><p>本发明实施例进一步提供一种处理设备,包括:</p><p>至少一个存储器,用于存储一个或多个程序;</p><p>至少一个处理器,能执行所述存储器所存储的一个或多个程序,在一个或多个程序被处理器执行时,使得所述处理器能实现上述的方法。这种处理设备也可以用于应用数据安全网关,在恶意网站攻击检测系统中检测恶意网站。</p><p>本发明实施例进一步提供一种可读存储介质,存储有计算机程序,当计算机程序被处理器执行时能实现上述的方法。</p><p>综上可见,本发明实施例的检测方法、装置及系统,通过网站语义特征提取步骤,利用page2vec算法将网站标签文本语义引入特征提取环节,摒弃了传统特征提取方式过于依赖专家经验的缺陷,强化表达了网站文本标签主题的相关性以及相邻网页的语义连接性;在预先训练阶段,利用过采样处理方式得到增广图数据训练图卷积神经网络分类器,充分考虑到恶意网站与合法网站数据不平衡的问题,避免了恶意网站样本量不足,直接用于训练,过拟合降低检测准确率的问题;检测恶意网站步骤利用图卷积神经网络作为特征提取器以及分类器,不同于传统方式考虑单节点特征,能挖掘网站之间的关联关系,以构建拓扑图的方式将邻居节点的属性融入网站特征学习中,可以更有效地检测网站是否为恶意网站。</p><p>为了更加清晰地展现出本发明所提供的技术方案及所产生的技术效果,下面以具体实施例对本发明实施例所提供的恶意网站检测方法、装置及系统进行详细描述。</p><p>实施例1</p><p>本发明提供一种恶意网站检测方法,是一种基于图卷积神经网络的检测方法,该方法先提取待检测网站进行定量特征与语义特征,根据定量特征与语义特征生成待检测网站的特征向量,通过预先利用增广图数据训练好的图卷积神经网络分类器,通过检测网络与节点特征对恶意网站准确识别。</p><p>具体的,该恶意网站检测方法如图1所示,包括如下步骤:</p><p>步骤1,网站定量特征提取:通过爬虫获取待检测网站的网页源码,从网页源码中提取待检测网站的定量特征,所述定量特征包括:内容特征和链接特征;</p><p>步骤2,网站语义特征提取:从待检测网站的网页源码中选定与网站语义密切相关的重要标签,从选定的重要标签中提取各个标签的语义信息,将各个标签的语义信息合成为待检测网站的语义特征;</p><p>步骤3,生成网站的特征向量:将所述步骤1得出的待检测网站的定量特征与所述步骤2得出的待检测网站的语义特征合成为待检测网站的特征向量;</p><p>步骤4,检测恶意网站:以待检测网站的特征向量为输入,利用以过采样拓展图拓扑结构方式构建的增广图数据作为训练数据预先训练好的图卷积神经网络分类器进行预测得出该待检测网站的类型分类,所述类型分类包括:恶意网站与合法网站。</p><p>如图2所示,该检测方法的检测过程主要分为四个阶段,分别是:网络定量特征提取,网络语义特征提取,使用过采样方法拓展图拓扑结构和利用图卷积神经网络分类器检测恶意网站。第一个阶段将通过定量分析方法,从网站的内容以及链接两个方面提取一些代表性的统计特征;第二阶段将使用page2vec算法,从标签角度向量化网站语义特征;第三阶段采用GraphSmote方法对图进行过采样处理,构建增广图缓解数据不平衡问题;第四阶段使用图卷积神经网络作为分类器进行恶意网站检测。</p><p>下面对上述各处理步骤进行具体说明。</p><p>(1)网站定量特征提取:</p><p>恶意网站一般通过网站的内容或者网站的链接实施攻击,本发明旨在通过对恶意网站一些典型的内容或者链接特征进行定量分析来进行网站定量特征提取。网站的特征提取通过对网页HTML源码分析的方式。</p><p>首先通过爬虫得到网站的HTML源码,由于网站源码信息比较复杂,本发明以标签为单位对源码进行拆分,着重对网页中<title>,<meta>,<body>,<a>这些标签进行分析并生成特征向量F,F=<F1,F2,F3,F4,F5,F6,F7,F8,F9>。其中前4个F1,F2,F3,F4为网站的内容特征,F5、F6、F7、F8为网站的链接特征,最后一个F9为网站的语义特征。</p><p>对于网站的内容特征,主要分析<body>,<meta>标签以及JavaScript代码。主要的网站的内容特征有:</p><p>停用词数量特征值:停用词是网页文本中没有实际意义的词汇,如it、she、or、a、the、am等。恶意网站会采用机器自动填充内容或者用关键词填充文本,使得停用词较合法网站少,网页停用词数量特征值的定义如下:</p><p>其中,其中,F1为停用词数量特征值;stop_rate是停用词比率,指网页中停用词数量占总字数的比率,N</p><p>错误词数量特征值:恶意网站为了避免搜索引擎的检测,通常使用错误或者不存在的词汇,而合法网站中几乎没有拼写错误。恶意网站与合法网站较为突出的区别就是错误词汇的数量,使用常用词汇库对网站内容错误词汇进行检查,网页错误词数量特征值的定义如下:</p><p>其中,F2为错误词数量特征值;error_rate为错误词比率,指网页中错误的词数量占总字数的比率,N</p><p>关键字个数特征值:恶意网站会在网页内容中尽可能多的添加关键字,从而欺骗搜索引擎,诱导用户点击网页。合法网站的关键词描述精确而且数量较少,能够较为准确的概括文本信息,而恶意网站的关键词个数较多,而且没有关联性。关键字个数特征值的定义如下:</p><p>其中,F3为关键字数量特征值;N</p><p>网页文本词汇数量特征值F4:一般来说,合法网站中的字数可能高于恶意网站。恶意网站可能包含不良图像或者能够重定向到恶意网站,例如,通过<iframe>标签嵌套页面。网页文本词汇数量较少,是恶意网站的可能性会增大。</p><p>网站链接特征主要分析网页源码中的<a>标签以及一些可获得的链接数据来提取网页链接定量特征,主要的网站内容特征有:</p><p>网页PageRank值,即网页排名值:PageRank是最早由Google提出的网页排名算法,根据网页之间的链接关系,可靠性越高的网站会获得更高的PR值(网站的重要性)。将PageRank值添加到基于链接的特征中,以对网页的可靠性做出初步判断。PageRank值的计算公式为:</p><p>其中,F5为网页排名值;PR是网络拓扑图的网站节点的PageRank值;d是阻尼因子;O</p><p>空链接数量特征值:空链接是出现在网页上没有指向目标端点的链接。当用户点击空链接时,它会保持静止。恶意网站为了伪装地像合法网站,会放一些空链接伪造链接数量。恶意网站可使用一些设计空链接的代码,例如<a href=””></a>,<a href=”#”></a>,<a href=”###”></a>,或使用JavaScript伪协议,<a href=”javascript:void(0);”></a>,<a href=”javascript:void(0)”></a>,<a href=”javascript:;”></a>,<a href=”javascript:”></a>等。空链接数量特征值的定义如下:</p><p>其中,F6为空链接数量特征值;null_rate是网页空链接率,L</p><p>网页重定向链接数量特征值:重定向链接是指网页通过链接可以跳转到另一个地方,可能处于页面内也可能在页面外部。恶意网站会设计重定向链接,将用户重定向到其他网站,例如广告或恶意网站等。通常,可以通过<meta http-equiv=”refresh”>或使用JavaScript进行重定向,例如设置window.location或document.location值进行重定向。网页重定向链接的参数定义如下:</p><p>其中,F7为网页重定向链接数量特征值;out_rate是网页重定向链接率,L</p><p>网页外部链接数量特征值:外部链接是指能够链接到与网站不同的域的链接。恶意网站通常情况下经常链接到不同域名网站或提升自身排名,或指向不同的恶意网站。因此恶意网站可能比合法网站拥有更多的外部链接。网页外部链接数的参数定义如下:</p><p>其中,F8为网页外部链接数量特征值;out_rate是网页重定向链接率,L</p><p>(2)网站语义特征提取:</p><p>将采用网站源码中与网站语义密切相关的标签进行语义分析,并使用page2vec算法提取各个标签的语义信息,合成网站的语义特征。page2vec算法流程如图3所示。</p><p>网站的定量特征的选择依赖专家经验。由于恶意网站常采用机器填充字段或者添加多种关键词混淆浏览器检测机制,因此恶意网站的标签语义关联性较合法网站弱,因此本发明考虑了将网站语义特征融入特征提取阶段。本发明使用标签语义融合的方式向量化网站语义特征。对于爬虫得到的网页源码,提取重要的标签,简化多于的网页文本,这里采用的主要标签有<body>、<keyword>、<description>和<title>四种标签。将同一标签内的文本视为整体,并分别处理这四个标签,可以更好地拟合网页的文本特征。</p><p>网页的文本向量嵌入方法是采用word2vec算法,通过同一标签中的上下文词汇,预测当前词汇从而得到当前词汇的向量化表示。同一标签中的词汇表示为{w</p><p>其中,w</p><p>将所有单词的one-hot编码作为输入。在输入层,它将使用目标词i之前和之后的c个词来预测词i。在投影层,将输入层的2c个向量相加,将得到K</p><p>结合哈夫曼树以及梯度上升方法,最终得到的预测单词的向量化表示为:</p><p>其中η是学习率,取值为0.1。</p><p>通过word2vec嵌入单词后,将得到每个单词的输出向量以标签为单位聚合,以<body>标签为例,合成的标签向量可以表示为:</p><p>在网站的标签属性上,选择的标签之间应有语义关联性,它们相互影响。合法网站的标签语义应高度关联而恶意网站不同标签的关联性可能较低。使用自注意力机制的目的是充分地考虑了标签之间的语义联系,衡量标签向量之间的关联性,突出表示较为重要的网页内容。</p><p>使用x</p><p>Q=W</p><p>K=W</p><p>V=W</p><p>为了计算不同标签之间的相关性,在合成了上述向量之后,通过以下方式计算标签注意力值,为:</p><p>/></p><p>其中,</p><p>为了合成网页向量表示,在得到了经过自注意力机制的输出向量之后,将标签分离并融合,使得网站特征可以由向量形式表示,而非矩阵形式。便于后续图卷积神经网络分类器处理。网页语义向量合成公式为:</p><p>o</p><p>(3)图卷积神经网络检测模型:</p><p>在检测模型方面,本发明采用图卷积神经网络,并结合GraphSmote算法对网站拓扑进行过采样处理,平衡网络中恶意网站与合法网站数量极度不平衡问题。使用获取得到的网站定量特征与语义特征,结合网络中网站间的拓扑关系捕获相邻节点的特征进行学习,并使用双层图卷积神经网络进行恶意网站检测,检测模型的总体框架如图3所示。</p><p>无论是现实检测场景中或者是采样获得的数据集中,合法网站的数量都远大于真实网站的数量。如果不经过处理,仅仅依据少量的恶意网站数据训练的模型,不仅泛化能力较差而且严重影响了检测的准确性。为了解决这个问题,本发明在模型训练阶段进行了数据过采样处理,与恶意网站分类器进行结合。</p><p>对图结构进行过采样处理利用GraphSmote算法构建网站拓扑增广图数据,针对已有样本特征进行图的扩展,主要分为以下几个阶段:</p><p>401)对现有网站拓扑进行特征提取:</p><p>本发明实施例中,利用图神经网络对现有的网站拓扑结构进行特征学习。图神经网络对输入的网站节点特征进行提取,学习网站节点表示,保留了网站节点属性以及图拓扑信息。图神经网络隐藏层消息传播和融合的过程可以表示为:</p><p>h</p><p>其中,h</p><p>402)在嵌入空间中生成少数类的特征属性:</p><p>新节点属性生成利用恶意网站的特征值与它们在嵌入空间中最近的邻域进行插值,合成的属性值应同样属于恶意网站节点类别。取少数类样本v,获得同标签样本的最近邻域样本为:</p><p>其中,cn(v)指的是来自同一类的样本v的最近邻,使用嵌入空间中的欧几里德距离测量。通过获得的最近邻域样本,通过插值方法合成新的恶意网站节点属性:</p><p>h</p><p>403)构造新合成节点与旧结点之间的链接关系:</p><p>合成新的少数类节点后需要构造新、旧节点的链接关系,对旧的网站拓扑图进行扩充。采用带权内积解码器来计算节点之间的相关性,从而推导边的生成。利用带权内积解码器计算节点u和节点v的相关性的方式为:</p><p>Ed</p><p>其中,Ed</p><p>通过原始图来训练解码器的权重矩阵S,计算得到原始的网站拓扑图的重构邻接矩阵,用E表示,重构误差可计算为:</p><p>Cost</p><p>解码器训练好后,可利用解码器预测新、旧网站节点间边的关系,这里设置每条边没有权重,节点间有边则邻接矩阵设为1,否则为0,则新的增广图的邻接矩阵为:</p><p>其中,γ是阈值,</p><p>(4)图卷积神经网络分类器:</p><p>图卷积神经网络将卷积运算推广到图结构的数据。本发明在网站拓扑上采用基于谱图方法的图卷积处理网站单节点信息,处理相邻网站之间的强关系性。在谱图方法中,图由相应的拉普拉斯矩阵表示,通过分析拉普拉斯矩阵及其特征值,可以得到图结构的性质。定义图的拉普拉斯矩阵L=D–A,其中D为对角度矩阵,D</p><p>g</p><p>其中g</p><p>其中</p><p>经过上述的图卷积神经网络方法可以较好的传递并预测网站的特征,将真实的网站特征与预测值做差值,将结果经过下一层图卷积神经网络并使用损失函数优化模型参数。对网站的分类是一个二分类问题,将网站类型分为合法网站与恶意网站两种类别。为了实现图卷积神经网络二分类,双层图卷积神经网络的前向传播公式可以计算为:</p><p>其中,W</p><p>其中,Y</p><p>本实施例的基于图卷积神经网络机制的恶意网站检测方法,利用page2vec算法首次将网站标签文本语义引入特征提取环节。摒弃了传统特征提取方式过于依赖专家经验的缺陷。强化表达了网站文本标签主题的相关性以及相邻网页的语义连接性。利用过采样处理方式结合图卷积神经网络分类器,充分考虑到网站数据不平衡的现实问题,避免了过拟合降低检测准确率的问题。不同于传统方式考虑单节点特征,利用图卷积神经网络作为特征提取器以及分类器,可以通过图的方式,挖掘网站之间的关联关系,以构建拓扑图的方式将邻居节点的属性融入网站特征学习中,可以有效地检测网站是否为恶意网站。</p><p>本实施例的方法可部署在安全检测软件中,实现检测恶意网站的准确识别,提高恶意网站检测的准确度。</p><p>实施例2</p><p>图6示意了恶意网站检测系统的部署。将对应于检测方法实现的恶意网站检测装置部署在应用数据安全网关上,通过互联网传递的各种网站数据可分为正常网站与恶意网站。通过应用数据安全网管上部署的恶意网站检测系统,如果网站检测为恶意网站,则过滤掉恶意网站,由网关进行告警处理。若为合法网站,则终端用户可以正常访问,进行数据传输,防止网站通过漏洞或内容攻击而收集用户个人信息,造成用户信息以及财产安全威胁。</p><p>本领域普通技术人员可以理解:实现上述实施例方法中的全部或部分流程是可以通过程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。</p><p>以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。本文背景技术部分公开的信息仅仅旨在加深对本发明的总体背景技术的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域技术人员所公知的现有技术。</p>
</div>
<div class="gradBox" style="display: block;"></div>
<div class="download">
<a href="javascript:orderEmailTipnew('06120115937841',95,12);;">完整全部详细技术资料下载</a>
</div>
</div>
<div class="col-art-footer" style="background-color: #fff;line-height: 25px;padding: 25px;">
<ul>
<li><span>该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。</span></li>
<li><span>专利发明人:陈双武;徐子鎐;刘丽哲;何华森;杨坚;杨锋;</span></li>
<li><span>专利申请人:中国科学技术大学;中国电子科技集团公司第五十四研究所;</span></li>
</ul>
<ul>
<li><span>上一篇:</span><a style="color: #666;"
href="https://zhuanli.zhangqiaokeyan.com/patent_7_124/06120115937840.html" title="上一篇">CU间迁移中的IAB节点切换</a></li>
<li><span>下一篇:</span><a style="color: #666;"
href="https://zhuanli.zhangqiaokeyan.com/patent_7_124/06120115937842.html" title="下一篇">气密性密封的封装件及其生产方法</a></li>
</ul>
</div>
<div class="detailxgjs">
<div class="tit">相关技术</div>
<div class="left">
<ul>
<li>
一种物联网设备检测方法、系统、装置及设备
</li>
<li>
一种触觉信号检测方法、装置、系统、设备及存储介质
</li>
<li>
一种山寨设备的检测、验证方法、装置及系统
</li>
<li>
一种接口的异常检测方法、装置、设备及系统
</li>
<li>
一种存储系统的状态检测方法、装置、设备及存储介质
</li>
<li>
一种恶意网站的检测方法、装置及电子设备
</li>
<li>
一种恶意网站的检测方法、装置及电子设备
</li>
</ul>
</div>
</div>
</div>
<div class="aside">
<div class="asidelist">
<div class="title">技术分类</div>
<ul>
<li><a href="/patent_1_9/" title="农业、林业、畜牧业、狩猎、诱捕、捕鱼">农业;林业;畜牧业;狩猎;诱捕;捕鱼</a></li>
<li><a href="/patent_1_10/" title="焙烤;制作或处理面团的设备;焙烤用面团">焙烤;制作或处理面团的设备;焙烤用面团</a></li>
<li><a href="/patent_1_11/" title="屠宰;肉品处理;家禽或鱼的加工">屠宰;肉品处理;家禽或鱼的加工</a></li>
<li><a href="/patent_1_12/" title="其他类不包含的食品或食料;及其处理">其他类不包含的食品或食料;及其处理</a></li>
<li><a href="/patent_1_13/" title="烟草、雪茄烟、纸烟、吸烟者用品">烟草、雪茄烟、纸烟、吸烟者用品</a></li>
<li><a href="/patent_1_14/" title="服装">服装</a></li>
<li><a href="/patent_1_15/" title="帽类制品">帽类制品</a></li>
<li><a href="/patent_1_16/" title="鞋类">鞋类</a></li>
<li><a href="/patent_1_17/" title="服饰缝纫用品、珠宝">服饰缝纫用品、珠宝</a></li>
<li><a href="/patent_1_18/" title="手携物品或旅行品">手携物品或旅行品</a></li>
<li><a href="/patent_1_19/" title="刷类制品">刷类制品</a></li>
<li><a href="/patent_1_20/" title="家具、家庭用的物品或设备、咖啡磨、香料磨、一般吸尘器">家具、家庭用的物品或设备、咖啡磨、香料磨、一般吸尘器</a></li>
<li><a href="/patent_1_21/" title="医学或兽医学、卫生学">医学或兽医学、卫生学</a></li>
<li><a href="/patent_1_22/" title="救生、消防">救生、消防</a></li>
<li><a href="/patent_1_23/" title="运动、游戏、娱乐活动">运动、游戏、娱乐活动</a></li>
<li><a href="/patent_1_24/" title="本部其他类目中不包括的技术主题">本部其他类目中不包括的技术主题</a></li>
<li><a href="/patent_2_25/" title="一般的物理或化学的方法或装置">一般的物理或化学的方法或装置</a></li>
<li><a href="/patent_2_26/" title="破碎、磨粉或粉碎、谷物碾磨的预处理">破碎、磨粉或粉碎、谷物碾磨的预处理</a></li>
<li><a href="/patent_2_27/" title="用液体或用风力摇床或风力跳汰机分离固体物料、从固体物料或流体中分离固体物料的磁或静电分离、高压电场分离">用液体或用风力摇床或风力跳汰机分离固体物料、从固体物料或流体中分离固体物料的磁或静电分离、高压电场分离</a></li>
<li><a href="/patent_2_28/" title="用于实现物理或化学工艺过程的离心装置或离心机">用于实现物理或化学工艺过程的离心装置或离心机</a></li>
<li><a href="/patent_2_29/" title="一般喷射或雾化、对表面涂覆液体或其他流体的一般方法">一般喷射或雾化、对表面涂覆液体或其他流体的一般方法</a></li>
<li><a href="/patent_2_30/" title="一般机械振动的发生或传递">一般机械振动的发生或传递</a></li>
<li><a href="/patent_2_31/" title="将固体从固体中分离、分选">将固体从固体中分离、分选</a></li>
<li><a href="/patent_2_32/" title="清洁">清洁</a></li>
<li><a href="/patent_2_33/" title="固体废物的处理、被污染土壤的再生">固体废物的处理、被污染土壤的再生</a></li>
<li><a href="/patent_2_34/" title="基本上无切削的金属机械加工、金属冲压">基本上无切削的金属机械加工、金属冲压</a></li>
<li><a href="/patent_2_35/" title="铸造、粉末冶金">铸造、粉末冶金</a></li>
<li><a href="/patent_2_36/" title="机床、其他类目中不包括的金属加工">机床、其他类目中不包括的金属加工</a></li>
<li><a href="/patent_2_37/" title="磨削、抛光">磨削、抛光</a></li>
<li><a href="/patent_2_38/" title="手动工具、轻便机动工具、手动器械的手柄、车间设备、机械手">手动工具、轻便机动工具、手动器械的手柄、车间设备、机械手</a></li>
<li><a href="/patent_2_39/" title="手动切割工具、切割、切断">手动切割工具、切割、切断</a></li>
<li><a href="/patent_2_40/" title="木材或类似材料的加工或保存、一般钉钉机或钉U形钉机">木材或类似材料的加工或保存、一般钉钉机或钉U形钉机</a></li>
<li><a href="/patent_2_41/" title="加工水泥、黏土或石料">加工水泥、黏土或石料</a></li>
<li><a href="/patent_2_42/" title="塑料的加工、一般处于塑性状态物质的加工">塑料的加工、一般处于塑性状态物质的加工</a></li>
<li><a href="/patent_2_43/" title="压力机">压力机</a></li>
<li><a href="/patent_2_44/" title="纸品或纸板或类似纸的方式加工的材料制品制作、纸或纸板或类似纸的方式加工的材料的加工">纸品或纸板或类似纸的方式加工的材料制品制作、纸或纸板或类似纸的方式加工的材料的加工</a></li>
<li><a href="/patent_2_45/" title="层状产品">层状产品</a></li>
<li><a href="/patent_2_46/" title="附加制造技术">附加制造技术</a></li>
<li><a href="/patent_2_47/" title="印刷、排版机、打字机、模印机">印刷、排版机、打字机、模印机</a></li>
<li><a href="/patent_2_48/" title="装订、图册、文件夹、特种印刷品">装订、图册、文件夹、特种印刷品</a></li>
<li><a href="/patent_2_49/" title="书写或绘图器具、办公用品">书写或绘图器具、办公用品</a></li>
<li><a href="/patent_2_50/" title="装饰艺术">装饰艺术</a></li>
<li><a href="/patent_2_51/" title="一般车辆">一般车辆</a></li>
<li><a href="/patent_2_52/" title="铁路">铁路</a></li>
<li><a href="/patent_2_53/" title="无轨陆用车辆">无轨陆用车辆</a></li>
<li><a href="/patent_2_54/" title="船舶或其他水上船只、与船有关的设备">船舶或其他水上船只、与船有关的设备</a></li>
<li><a href="/patent_2_55/" title="飞行器、航空、宇宙航行">飞行器、航空、宇宙航行</a></li>
<li><a href="/patent_2_56/" title="输送、包装、贮存、搬运薄的或细丝状材料">输送、包装、贮存、搬运薄的或细丝状材料</a></li>
<li><a href="/patent_2_57/" title="卷扬、提升、牵引">卷扬、提升、牵引</a></li>
<li><a href="/patent_2_58/" title="开启或封闭瓶子、罐或类似的容器、液体的贮运">开启或封闭瓶子、罐或类似的容器、液体的贮运</a></li>
<li><a href="/patent_2_59/" title="鞍具、家具罩面">鞍具、家具罩面</a></li>
<li><a href="/patent_2_60/" title="微观结构技术">微观结构技术</a></li>
<li><a href="/patent_2_61/" title="纳米技术">纳米技术</a></li>
<li><a href="/patent_3_63/" title="无机化学">无机化学</a></li>
<li><a href="/patent_3_64/" title="水、废水、污水或污泥的处理">水、废水、污水或污泥的处理</a></li>
<li><a href="/patent_3_65/" title="玻璃、矿棉或渣棉">玻璃、矿棉或渣棉</a></li>
<li><a href="/patent_3_66/" title="水泥、混凝土、人造石、陶瓷、耐火材料">水泥、混凝土、人造石、陶瓷、耐火材料</a></li>
<li><a href="/patent_3_67/" title="肥料、肥料制造">肥料、肥料制造</a></li>
<li><a href="/patent_3_68/" title="炸药、火柴">炸药、火柴</a></li>
<li><a href="/patent_3_69/" title="有机化学">有机化学</a></li>
<li><a href="/patent_3_70/" title="有机高分子化合物、其制备或化学加工、以其为基料的组合物">有机高分子化合物、其制备或化学加工、以其为基料的组合物</a></li>
<li><a href="/patent_3_71/" title="染料、涂料、抛光剂、天然树脂、黏合剂、其他类目不包含的组合物、其他类目不包含的材料的应用">染料、涂料、抛光剂、天然树脂、黏合剂、其他类目不包含的组合物、其他类目不包含的材料的应用</a></li>
<li><a href="/patent_3_72/" title="石油、煤气及炼焦工业、含一氧化碳的工业气体、燃料、润滑剂、泥煤">石油、煤气及炼焦工业、含一氧化碳的工业气体、燃料、润滑剂、泥煤</a></li>
<li><a href="/patent_3_73/" title="动物或植物油、脂、脂肪物质或蜡、由此制取的脂肪酸、洗涤剂、蜡烛">动物或植物油、脂、脂肪物质或蜡、由此制取的脂肪酸、洗涤剂、蜡烛</a></li>
<li><a href="/patent_3_74/" title="生物化学、啤酒、烈性酒、果汁酒、醋、微生物学、酶学、突变或遗传工程">生物化学、啤酒、烈性酒、果汁酒、醋、微生物学、酶学、突变或遗传工程</a></li>
<li><a href="/patent_3_75/" title="糖工业">糖工业</a></li>
<li><a href="/patent_3_76/" title="使用化学药剂、酶类或微生物处理小原皮、大原皮或皮革的工艺,如鞣制、浸渍或整饰、其所用的设备、鞣制组合物(皮革或毛皮的漂白入D06L、皮革或毛皮的染色入D06P)">使用化学药剂、酶类或微生物处理小原皮、大原皮或皮革的工艺,如鞣制、浸渍或整饰、其所用的设备、鞣制组合物(皮革或毛皮的漂白入D06L、皮革或毛皮的染色入D06P)</a></li>
<li><a href="/patent_3_77/" title="铁的冶金">铁的冶金</a></li>
<li><a href="/patent_3_78/" title="冶金、黑色或有色金属合金、合金或有色金属的处理">冶金、黑色或有色金属合金、合金或有色金属的处理</a></li>
<li><a href="/patent_3_79/" title="对金属材料的镀覆、用金属材料对材料的镀覆、表面化学处理、金属材料的扩散处理、真空蒸发法、溅射法、离子注入法或化学气相沉积法的一般镀覆、金属材料腐蚀或积垢的一般抑制">对金属材料的镀覆、用金属材料对材料的镀覆、表面化学处理、金属材料的扩散处理、真空蒸发法、溅射法、离子注入法或化学气相沉积法的一般镀覆、金属材料腐蚀或积垢的一般抑制</a></li>
<li><a href="/patent_3_80/" title="电解或电泳工艺、其所用设备">电解或电泳工艺、其所用设备</a></li>
<li><a href="/patent_3_81/" title="晶体生长">晶体生长</a></li>
<li><a href="/patent_3_82/" title="组合技术">组合技术</a></li>
<li><a href="/patent_4_84/" title="天然或化学的线或纤维、纺纱或纺丝">天然或化学的线或纤维、纺纱或纺丝</a></li>
<li><a href="/patent_4_85/" title="纱线、纱线或绳索的机械整理、整经或络经">纱线、纱线或绳索的机械整理、整经或络经</a></li>
<li><a href="/patent_4_86/" title="织造">织造</a></li>
<li><a href="/patent_4_87/" title="编织、花边制作、针织、饰带、非织造布">编织、花边制作、针织、饰带、非织造布</a></li>
<li><a href="/patent_4_88/" title="缝纫、绣花、簇绒">缝纫、绣花、簇绒</a></li>
<li><a href="/patent_4_89/" title="织物等的处理、洗涤、其他类不包括的柔性材料">织物等的处理、洗涤、其他类不包括的柔性材料</a></li>
<li><a href="/patent_4_90/" title="绳、除电缆以外的缆索">绳、除电缆以外的缆索</a></li>
<li><a href="/patent_4_91/" title="造纸、纤维素的生产">造纸、纤维素的生产</a></li>
<li><a href="/patent_5_93/" title="道路、铁路或桥梁的建筑">道路、铁路或桥梁的建筑</a></li>
<li><a href="/patent_5_94/" title="水利工程、基础、疏浚">水利工程、基础、疏浚</a></li>
<li><a href="/patent_5_95/" title="给水、排水">给水、排水</a></li>
<li><a href="/patent_5_96/" title="建筑物">建筑物</a></li>
<li><a href="/patent_5_97/" title="锁、钥匙、门窗零件、保险箱">锁、钥匙、门窗零件、保险箱</a></li>
<li><a href="/patent_5_98/" title="一般门、窗、百叶窗或卷辊遮帘、梯子">一般门、窗、百叶窗或卷辊遮帘、梯子</a></li>
<li><a href="/patent_5_99/" title="土层或岩石的钻进、采矿">土层或岩石的钻进、采矿</a></li>
<li><a href="/patent_6_101/" title="一般机器或发动机、一般的发动机装置、蒸汽机">一般机器或发动机、一般的发动机装置、蒸汽机</a></li>
<li><a href="/patent_6_102/" title="燃烧发动机、热气或燃烧生成物的发动机装置">燃烧发动机、热气或燃烧生成物的发动机装置</a></li>
<li><a href="/patent_6_103/" title="液力机械或液力发动机、风力、弹力或重力发动机、其他类目中不包括的产生机械动力或反推力的发动机">液力机械或液力发动机、风力、弹力或重力发动机、其他类目中不包括的产生机械动力或反推力的发动机</a></li>
<li><a href="/patent_6_104/" title="液体变容式机械、液体泵或弹性流体泵">液体变容式机械、液体泵或弹性流体泵</a></li>
<li><a href="/patent_6_105/" title="流体压力执行机构、一般液压技术和气动技术">流体压力执行机构、一般液压技术和气动技术</a></li>
<li><a href="/patent_6_106/" title="工程元件或部件、为产生和保持机器或设备的有效运行的一般措施、一般绝热">工程元件或部件、为产生和保持机器或设备的有效运行的一般措施、一般绝热</a></li>
<li><a href="/patent_6_107/" title="气体或液体的贮存或分配">气体或液体的贮存或分配</a></li>
<li><a href="/patent_6_108/" title="照明">照明</a></li>
<li><a href="/patent_6_109/" title="蒸汽的发生">蒸汽的发生</a></li>
<li><a href="/patent_6_110/" title="燃烧设备、燃烧方法">燃烧设备、燃烧方法</a></li>
<li><a href="/patent_6_111/" title="供热、炉灶、通风">供热、炉灶、通风</a></li>
<li><a href="/patent_6_112/" title="制冷或冷却、加热和制冷的联合系统、热泵系统、冰的制造或储存、气体的液化或固化">制冷或冷却、加热和制冷的联合系统、热泵系统、冰的制造或储存、气体的液化或固化</a></li>
<li><a href="/patent_6_113/" title="干燥">干燥</a></li>
<li><a href="/patent_6_114/" title="炉、窑、烘烤炉、蒸馏炉">炉、窑、烘烤炉、蒸馏炉</a></li>
<li><a href="/patent_6_115/" title="一般热交换">一般热交换</a></li>
<li><a href="/patent_6_116/" title="武器">武器</a></li>
<li><a href="/patent_6_117/" title="弹药、爆破">弹药、爆破</a></li>
<li><a href="/patent_7_119/" title="测量、测试">测量、测试</a></li>
<li><a href="/patent_7_120/" title="光学">光学</a></li>
<li><a href="/patent_7_121/" title="摄影术、电影术、利用了光波以外其他波的类似技术、电记录术、全息摄影术">摄影术、电影术、利用了光波以外其他波的类似技术、电记录术、全息摄影术〔4〕</a></li>
<li><a href="/patent_7_122/" title="测时学">测时学</a></li>
<li><a href="/patent_7_123/" title="控制、调节">控制、调节</a></li>
<li><a href="/patent_7_124/" title="计算、推算、计数">计算、推算、计数</a></li>
<li><a href="/patent_7_125/" title="核算装置">核算装置</a></li>
<li><a href="/patent_7_126/" title="信号装置">信号装置</a></li>
<li><a href="/patent_7_127/" title="教育、密码术、显示、广告、印鉴">教育、密码术、显示、广告、印鉴</a></li>
<li><a href="/patent_7_128/" title="乐器、声学">乐器、声学</a></li>
<li><a href="/patent_7_129/" title="信息存储">信息存储</a></li>
<li><a href="/patent_7_130/" title="仪器的零部件">仪器的零部件</a></li>
<li><a href="/patent_7_131/" title="特别适用于特定应用领域的信息通信技术">特别适用于特定应用领域的信息通信技术</a></li>
<li><a href="/patent_7_132/" title="核物理、核工程">核物理、核工程</a></li>
<li><a href="/patent_8_134/" title="基本电气元件">基本电气元件</a></li>
<li><a href="/patent_8_136/" title="发电、变电或配电">发电、变电或配电</a></li>
<li><a href="/patent_8_137/" title="基本电子电路">基本电子电路</a></li>
<li><a href="/patent_8_138/" title="电通信技术">电通信技术</a></li>
<li><a href="/patent_8_140/" title="其他类目不包含的电技术">其他类目不包含的电技术</a></li>
<li><a href="/patent_9999_9999/" title="其他专利">其他专利</a></li>
</ul>
</div>
</div>
<div class="paging"></div>
</div>
</div>
<div style="clear: both;"></div>
<div style="display:none">
<p id="docid">06120115937841</p>
<span id="06120115937841down" data-source="6,"
data-out-id="CN115994351A," data-f-source-id="6" data-title="一种恶意网站检测方法、装置、系统及设备" data-price="10"
data-transnum="0" style="display:none;"></span></div>
<div class="xllindexfooter">
<div style="width: 1120px;margin: 0 auto;margin-top: 30px; ">
<div>
<div class="hotlinklisttitle">
<ul >
<li><a href="javascript:;">友情链接</a></li>
</ul>
</div>
<div class="hotlinklistcontent">
<div class="hotlinklistcontent1">
<ul style="overflow:hidden">
<li><a title="掌桥专利" href="https://zhuanli.zhangqiaokeyan.com/" target="_blank">掌桥专利</a></li>
<li><a title="科技查新" href="https://kejichaxin.zhangqiaokeyan.com/" target="_blank">科技查新</a></li>
<li><a title="掌桥科研" href="https://www.zhangqiaokeyan.com/" target="_blank">掌桥科研</a></li>
<li><a title="浸没式液冷" href="http://www.blueocean-china.net " target="_blank">浸没式液冷</a></li>
<li><a title="步入式恒温恒湿试验箱" href="http://www.deruitest.com" target="_blank">步入式恒温恒湿试验箱</a></li>
<li><a title="杭州室内设计培训" href="http://www.qingfengsheji.com" target="_blank">杭州室内设计培训</a></li>
<li><a title="散文精选" href="http://www.mangowenxue.com" target="_blank">散文精选</a></li>
<li><a title="管理博士" href="https://www.pxemba.com" target="_blank">管理博士</a></li>
<li><a title="雅思培训" href="https://www.longre.com" target="_blank">雅思培训</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<div class="footer">
<p>
<a href="https://www.zhangqiaokeyan.com/about.html" title="关于我们">关于我们</a><span class="line">|</span>
<a onclick="window.open('https://103941.kefu.easemob.com/webim/im.html?configId=e4dad0df-e3b7-4d34-ba80-342ddc88f278','','width=980,height=600,left=529,top=261');" rel="nofollow" title="联系方式">联系方式</a><span
class="line"></span>
</p>
<p> 六维联合信息科技 (北京) 有限公司©版权所有,并保留所有权利。京ICP备15016152号-6 </p>
</div>
</body>
<script type="text/javascript" src="/js/jquery-1.12.4.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/jquery.cookie.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/variable.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/tip.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/login.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/common.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/lwlh_ajax.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/down.js?v=5.1.1"></script>
<script type="text/javascript" src="/js/common/tj.js?v=5.1.1"></script>
<script type="text/javascript" src="https://www.zhangqiaokeyan.com/statistics/static/pagecollection.js"></script>
<script>
</script>
</html>