基于多特征序列的匿名网络流量分类方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及网络安全、深度学习、匿名通信网络领域,具体地,涉及一种基于多特征序列的匿名网络流量分类方法及系统。
背景技术
近年来,随着信息时代的发展,互联网所承载的服务越来越多,在互联网为人们带来便利的同时,也使得用户的各类隐私信息被收集,并在互联网中传输。以安全协议为代表的传统网络安全,主要侧重于对信息内容的保护,而对于同样重要的通信双方的身份信息却缺乏有效的保护。因此,在用户对于身份信息的保护需求日益增长的背景下,匿名通信技术应运而生。
匿名通信技术是一种通过采用数据转发、内容加密、流量混淆等措施来隐藏通信内容及关系的隐私保护技术,为了提高通信的匿名性,这些数据转发链路通常由多跳加密代理服务节点构成,所有服务节点共同构成了匿名通信网络。近年来,针对不同用户的需求,匿名通信技术已经发展出多种类型的匿名通信网络。例如洋葱路由(The OnionRouter,Tor),基于Tor改进的大蒜路由(Invisible Internet Project,I2P),Freenet等,其中Tor的使用最为广泛,其使用用户数最多,规模最大,是近年来研究的热点。
然而,在匿名网络为合法用户提供更强大的隐私性的同时,它也被一些不法分子作为非法活动的载体和温床。因此,如何快速有效地完成网络流量分析,对于加强匿名网络的流量监管、维护网络空间安全具有重大的意义。
网络流量分析是指通过捕获网络中的数据包后,再通过其他手段对数据包进行分析并统计相关信息,进而诊断网络的运行状态,帮助监管者排查网络中存在的隐患,提高网络的防护能力。在匿名网络中,网络管理员可以通过监控网络中的流量信息,分析可能的恶意行为,并对流量进行分类,进而对恶意流量进行重定向,从而达到保护网络的目的。目前一般采用基于机器学习方法,如CNN、LSTM等来分类匿名流量,尽管这些方法能够自动提取流的特征,但是忽略了流之间的时空相关性,而Transformer框架能将一定时间范围内的多个连续流视为一个序列,并将该序列的特征作为输入数据,捕捉到流之间的关联关系和潜在的特征,实现更好的分类效果。
专利文献CN110059747B(申请号:CN201910314300.X)公开了一种网络流量分类方法,包括构建轻量级分类模型;所述构建轻量级分类模型包括如下步骤:S1:基于自步学习的深度神经网络流量去噪算法训练网络流量分类模型;S2:基于正则化损失知识蒸馏的模型压缩技术,将所述网络流量分类模型压缩成轻量级网络流量分类模型。但该发明没有抽出匿名通信流序列中重要的连续性特征,并挖掘其频域上的隐含信息。
发明内容
针对现有技术中的缺陷,本发明的目的是提供一种基于多特征序列的匿名网络流量分类方法及系统。
根据本发明提供的一种基于多特征序列的匿名网络流量分类方法,包括:
步骤S1:采集网络流量文件,提取特征,进行数据归一化和流序列生成;
步骤S2:对提取到的特征进行重要性排序,获取流量序列中最重要的连续性特征对应的特征序列,并转化为频域特征向量;
步骤S3:通过频域特征提取网络将频域特征向量转化为中间特征向量,并将流序列其他特征通过其他特征提取网络转化为中间特征向量;
步骤S4:拼接中间特征向量,通过分类网络后得到不同类别的概率分布。
优选地,在所述步骤S1中:
步骤S1.1:捕获流经设备的匿名网络流量数据包,捕获的数据包格式为pcap;
步骤S1.2:对采集到的数据集以预设时间跨度进行切割;
步骤S1.3:对所采集到并切割好的pcap文件进行特征提取,输出数据包的流特征值;
步骤S1.4:使用归一化算法将数据统一映射到[0,1]区间,归一化算法公式为:
其中,μ为原始数据均值,σ为标准差,x为原始数据值,z为归一化后的新数据值;
步骤S1.5:选择Z个连续的流数据为一个块进行处理。
优选地,在所述步骤S2中:
步骤S2.1:对提取出的所有特征进行特征筛选,去除特征包括每个流数据的初始时间戳、最终时间戳、IP和TCP参数,保留预设个特征;
步骤S2.2:对筛选出的特征使用随机森林算法或主成分分析法计算每个特征的重要性,并根据重要性对特征进行排序;选择最重要的预设个特征;
步骤S2.3:对选择的特征,分别记为特征d,e,对Z个连续的流数据,分别构建Z维的特征向量,构建长度为Z的特征序列{d[n]}
将变换结果组合为频域特征向量
优选地,在所述步骤S3中:
对于未选择的其他特征,选择重要性位于前预设个的特征,对于所述的Z个连续的流数据,构建Z个1×20的向量,通过DNN映射为Z个1×h的向量,拼接后输入均值或最值池化层,得到1×h的中间特征向量b。
优选地,在所述步骤S4中:
对于输出的中间特征向量a,b,拼接后通过MLP映射为一个1×p最终特征向量,此处p为最终分类的类别数目,接着用softmax函数计算得到概率分布,根据概率分布确定分类结果。
根据本发明提供的一种基于多特征序列的匿名网络流量分类系统,执行所述的基于多特征序列的匿名网络流量分类方法,包括:
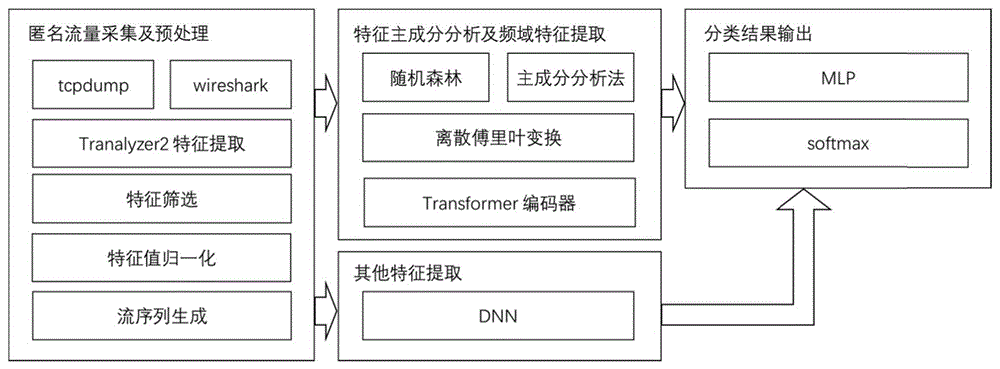
匿名网络流序列采集及预处理模块:通过数据流采集工具采集流经硬件设备的网络数据流,分割数据流后分析提取出数据流中的特征信息;
特征主成分分析及频域特征提取模块:通过特征选择方法对生成的流量进行特征预处理,对于符合预设标准的时域特征提取频域特征,将提取的频域特征序列,输入编码器获取中间特征向量;
其他特征提取模块:将预设标准以外的其他特征序列分别获取在高维空间中的嵌入,并将嵌入整合为矩阵,输入均值或最值池化层后,将其抽象为一个中间特征向量;
分类结果输出模块:整合中间向量,得到最终分类向量。
优选地,在所述匿名网络流序列采集及预处理模块中:
使用流量捕获工具,捕获完成后使用流量分析工具完成特征提取工作,对特征提取完成的数据进行归一化和流序列生成,其中:
流量捕获工具:使用的工具为tcpdump或Wireshark,捕获流经运行工具的硬件设备的网络数据包,并将其以pcap文件格式存储;
流量分析工具:使用的工具为Tranalyzer2,接收标准pcap格式文件数据,并根据用户需求增删插件,处理和分析各类网络流量,输出对应特征子集;
数据归一化和流序列生成:数据归一化是指将所有特征的数值映射到统一区间的方法,解决数据特征之间的可比性问题,流序列生成是指将多个连续的数据流信息组合拼接为一个流块,挖掘出连续的流之间的隐含关联关系和特征信息。
优选地,在所述特征主成分分析及频域特征提取模块中:
使用特征选择方法对特征进行重要性排序,对于多个数值具有具体含义的重要时域特征序列,使用离散傅里叶变换转化为多个频域特征序列,将频域特征序列输入多个基于Transformer框架的编码器获得中间特征向量a,其中:
特征选择方法:使用算法为随机森林法或主成分分析法。
优选地,在所述其他特征提取模块中:
将其他特征序列分别通过DNN获取其在高维空间中的嵌入,并将这些嵌入整合为矩阵,输入均值或最值池化层后,抽象为一个中间特征向量b。
优选地,在所述分类结果输出模块中:
中间特征向量a和b通过多层感知器及softmax归一化处理得到最终分类向量,根据最终分类向量计算得到最终分类概率分布。
与现有技术相比,本发明具有如下的有益效果:
1、本发明能够抽出匿名通信流序列中重要的连续性特征,并挖掘其频域上的隐含信息,充分发挥Transformer框架对于连续的数据的序列特征捕获能力;
2、本发明对于其他重要性较低的特征,使用DNN进行嵌入,使得该方法能够在一定程度降低计算量的条件下,对匿名网络流量进行分类,提升了匿名网络流量分类的可行性。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明较佳实施例提供的一种基于多特征序列的匿名网络流量分类方法的模块结构示意图;
图2为本发明较佳实施例提供的一种基于多特征序列的匿名网络流量分类方法的流程示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
实施例1;
本发明提供了一种基于多特征序列的匿名网络流量分类方法。首先,采集网络流量文件,并通过数据集切割、数据流特征提取、数据归一化、特征选择等方式完成数据预处理;然后,通过主成分分析法对提取到的特征进行重要性排序,获取流量序列中最重要的若干连续性特征对应的特征序列,并通过离散傅里叶变换转化为频域特征向量;接着,通过基于Transformer框架的频域特征提取网络将频域特征向量转化为中间特征向量a,并将流序列其他特征通过基于深度神经网络(Deep Neural Networks,DNN)的其他特征提取网络转化为中间特征向量b;最后,拼接两个中间特征向量,通过分类网络后,得到不同类别的概率分布,完成匿名流量分类工作。
根据本发明提供的一种基于多特征序列的匿名网络流量分类方法,如图1-图2所示,包括:
步骤S1:采集网络流量文件,提取特征,进行数据归一化和流序列生成;
具体地,在所述步骤S1中:
步骤S1.1:捕获流经设备的匿名网络流量数据包,捕获的数据包格式为pcap;
步骤S1.2:对采集到的数据集以预设时间跨度进行切割;
步骤S1.3:对所采集到并切割好的pcap文件进行特征提取,输出数据包的流特征值;
步骤S1.4:使用归一化算法将数据统一映射到[0,1]区间,归一化算法公式为:
其中,μ为原始数据均值,σ为标准差,x为原始数据值,z为归一化后的新数据值;
步骤S1.5:选择Z个连续的流数据为一个块进行处理。
步骤S2:对提取到的特征进行重要性排序,获取流量序列中最重要的连续性特征对应的特征序列,并转化为频域特征向量;
具体地,在所述步骤S2中:
步骤S2.1:对提取出的所有特征进行特征筛选,去除特征包括每个流数据的初始时间戳、最终时间戳、IP和TCP参数,保留预设个特征;
步骤S2.2:对筛选出的特征使用随机森林算法或主成分分析法计算每个特征的重要性,并根据重要性对特征进行排序;选择最重要的预设个特征;
步骤S2.3:对选择的特征,分别记为特征d,e,对Z个连续的流数据,分别构建Z维的特征向量,构建长度为Z的特征序列{d[n]}
将变换结果组合为频域特征向量
步骤S3:通过频域特征提取网络将频域特征向量转化为中间特征向量,并将流序列其他特征通过其他特征提取网络转化为中间特征向量;
具体地,在所述步骤S3中:
对于未选择的其他特征,选择重要性位于前预设个的特征,对于所述的Z个连续的流数据,构建Z个1×20的向量,通过DNN映射为Z个1×h的向量,拼接后输入均值或最值池化层,得到1×h的中间特征向量b。
步骤S4:拼接中间特征向量,通过分类网络后得到不同类别的概率分布。
具体地,在所述步骤S4中:
对于输出的中间特征向量a,b,拼接后通过MLP映射为一个1×p最终特征向量,此处p为最终分类的类别数目,接着用softmax函数计算得到概率分布,根据概率分布确定分类结果。
实施例2:
实施例2为实施例1的优选例,以更为具体地对本发明进行说明。
本发明还提供一种基于多特征序列的匿名网络流量分类系统,所述基于多特征序列的匿名网络流量分类系统可以通过执行所述基于多特征序列的匿名网络流量分类方法的流程步骤予以实现,即本领域技术人员可以将所述基于多特征序列的匿名网络流量分类方法理解为所述基于多特征序列的匿名网络流量分类系统的优选实施方式。
根据本发明提供的一种基于多特征序列的匿名网络流量分类系统,执行所述的基于多特征序列的匿名网络流量分类方法,包括:
匿名网络流序列采集及预处理模块:通过数据流采集工具采集流经硬件设备的网络数据流,分割数据流后分析提取出数据流中的特征信息;
具体地,在所述匿名网络流序列采集及预处理模块中:
使用流量捕获工具,捕获完成后使用流量分析工具完成特征提取工作,对特征提取完成的数据进行归一化和流序列生成,其中:
流量捕获工具:使用的工具为tcpdump或Wireshark,捕获流经运行工具的硬件设备的网络数据包,并将其以pcap文件格式存储;
流量分析工具:使用的工具为Tranalyzer2,接收标准pcap格式文件数据,并根据用户需求增删插件,处理和分析各类网络流量,输出对应特征子集;
数据归一化和流序列生成:数据归一化是指将所有特征的数值映射到统一区间的方法,解决数据特征之间的可比性问题,流序列生成是指将多个连续的数据流信息组合拼接为一个流块,挖掘出连续的流之间的隐含关联关系和特征信息。
特征主成分分析及频域特征提取模块:通过特征选择方法对生成的流量进行特征预处理,对于符合预设标准的时域特征提取频域特征,将提取的频域特征序列,输入编码器获取中间特征向量;
具体地,在所述特征主成分分析及频域特征提取模块中:
使用特征选择方法对特征进行重要性排序,对于多个数值具有具体含义的重要时域特征序列,使用离散傅里叶变换转化为多个频域特征序列,将频域特征序列输入多个基于Transformer框架的编码器获得中间特征向量a,其中:
特征选择方法:使用算法为随机森林法或主成分分析法。
其他特征提取模块:将预设标准以外的其他特征序列分别获取在高维空间中的嵌入,并将嵌入整合为矩阵,输入均值或最值池化层后,将其抽象为一个中间特征向量;
具体地,在所述其他特征提取模块中:
将其他特征序列分别通过DNN获取其在高维空间中的嵌入,并将这些嵌入整合为矩阵,输入均值或最值池化层后,抽象为一个中间特征向量b。
分类结果输出模块:整合中间向量,得到最终分类向量。
具体地,在所述分类结果输出模块中:
中间特征向量a和b通过多层感知器及softmax归一化处理得到最终分类向量,根据最终分类向量计算得到最终分类概率分布。
实施例3:
实施例3为实施例1的优选例,以更为具体地对本发明进行说明。针对现有技术的不足,本发明提出一种基于多特征序列的匿名网络流量分类方法,针对流量的重要连续性特征来提高流量分类的准确率。本发明提出的方法,旨在利用匿名通信流量的统计特征,多个重要特征序列及其隐含的上下文关联关系实现对匿名通信网络流量的分类。首先,通过tcpdump或Wireshark采集网络流量pcap数据,使用Tranalyzer2提取特征,并进行数据归一化和流序列生成;接着,通过离散傅里叶变换算法提取多个重要特征序列的频域信息,输入基于Transformer框架的编码器获取频域中间特征向量,将其他特征输入DNN获取另一中间特征向量;最后,拼接两个中间特征向量,通过MLP映射及softmax归一化转化为最终分类向量,完成分类过程。
本发明较佳实施例提供的一种基于多特征序列的匿名网络流量分类方法的模块结构图如图1所示。
进一步地,本发明较佳实施例提供的一种基于多特征序列的匿名网络流量分类方法的流程图如图2所示。所述方法具体包括以下步骤:匿名网络流序列采集及预处理、特征主成分分析及频域特征提取、其他特征提取、分类结果输出。
S1.匿名网络流序列采集及预处理:包括匿名网络数据集采集,并对采集到的数据流切分、进行数据流特征提取、数据归一化等步骤
S2.特征主成分分析及频域特征提取:并将其中时域上连续的重要的特征成分通过频域转化方法转化为频域特征中间向量。
S3.其他特征提取:构建其他特征矩阵,并获取其他特征在高维空间中的中间特征向量。
S4.多序列匿名流量分类:将频域特征向量与其他特征向量进行拼接操作,输入流量分类模型中,生成流量分类结果标签。
优选的,所述步骤S1中具体包括以下步骤:
A1.通过在交换机或其他设备上运行tcpdump或Wireshark捕获流经该设备的匿名网络流量数据包,捕获的数据包格式为pcap
A2.对采集到的数据集以一定时间跨度进行切割,经过实验比较分析,得出以10s为时间跨度切割的流量分类性能最佳
A3.使用Tranalyzer2工具对所采集到并切割好的pcap文件进行特征提取,通过其自带的等插件输出数据包的流基本特征信息、统计信息等124种特征值。
A4.由于不同特征的取值范围差距较大,因此需要对数据进行归一化处理,以均衡数据特征之间的可比性。使用归一化算法将数据统一映射到[0,1]区间,归一化算法公式为:
其中,μ为原始数据均值,σ为标准差,x为原始数据值,z为归一化后的新数据值。
A5.由于Transformer框架的编码器的输入需要接受一个块(或称序列)作为输入,输入序列由多个连续数据构成,经过实验比较分析,选择8个连续的流数据为一个块进行处理。
优选的,所述步骤S2中具体包括以下步骤:
B1.对步骤A3所提取出的所有特征进行特征筛选,去除每个流数据的初始时间戳、最终时间戳、部分IP、TCP参数等不提供有用信息的特征,最终保留84个特征。
B2.对步骤B1中所筛选出的特征使用随机森林算法或主成分分析法计算每个特征的重要性,并根据重要性对特征进行排序。选择最重要的若干个特征数值具备具体含义的特征(数值并非表示种类),如接收数据包数目、数据流对称性。
B3.对于步骤B2中选择的特征,分别记为特征,e,对于步骤A5中所述的8个连续的流数据,分别构建8维的特征向量,即可构建长度为8的序列{d[n]}
其中,i为虚数单位;
可将变换结果组合为频域特征向量
优选的,所述步骤S3中具体包括以下步骤:
C1.对于步骤B2中未选择的其他特征,选择重要性前20的特征,对于步骤A5中所述的8个连续的流数据,构建8个1×20的向量,通过DNN映射为8个1×h的向量,拼接后输入均值或最值池化层,得到1×h的中间特征向量b。
优选的,所述步骤S4中具体包括以下步骤:
D1.对于步骤B3及步骤C1中输出的中间特征向量a,b,拼接后通过MLP映射为一个1×p最终特征向量(此处p为最终分类的类别数目),接着用softmax函数计算得到概率分布,根据该分布确定分类结果。
基于多特征序列的匿名网络流量分类方法,对输入的多个重要特征序列进行频域特征提取,整体考虑并提取其他特征,将两部分中间特征向量整合后输入分类模块,完成匿名网络流量分类工作。具体包括以下模块:匿名网络流序列采集及预处理模块、特征主成分分析及频域特征提取模块、其他特征提取模块、分类结果输出模块。其中:
匿名网络流序列采集及预处理模块,通过数据流采集工具采集流经交换机、网关等硬件设备的网络数据流,分割数据流后分析提取出数据流中的特征信息,从而支撑后续的特征筛选和模型训练及分类步骤。
特征主成分分析,频域特征提取模块,通过特征选择方法去除生成的流量中不重要的特征,使输入模型的特征更符合有效性和时效性。对于数值具备具体含义的重要时域特征,使用离散傅里叶变换提取频域特征。将提取的多个频域特征序列,输入到以Transformer为框架的编码器中,获取中间特征向量a。
其他特征提取模块,将其他特征序列分别通过DNN获取其在高维空间中的嵌入,并将这些嵌入整合为矩阵,输入均值或最值池化层后,将其抽象为一个中间特征向量b。
分类结果输出模块,整合中间向量,得到最终分类向量,用于训练网络和获得分类结果。
所述的匿名网络序列采集及预处理模快,使用流量捕获工具,捕获完成后使用流量分析工具完成特征提取工作,对特征提取完成的数据进行归一化和流序列生成,其中:
流量捕获工具:主要使用的工具为tcpdump或Wireshark,能够捕获流经运行此工具的硬件设备的网络数据包,并将其以pcap文件格式存储。
流量分析工具:主要使用的工具为Tranalyzer2,能够接收标准pcap格式文件数据,并根据用户需求增删插件,有效处理和分析各类网络流量,输出对应特征子集。
数据归一化和流序列生成:数据归一化是指将所有特征的数值映射到统一区间的方法,以解决数据特征之间的可比性问题。流序列生成是指将多个连续的数据流信息组合拼接为一个流块,以挖掘出连续的流之间的隐含关联关系和特征信息。
所述的特征主成分分析,频域特征提取模块,使用特征选择方法对特征进行重要性排序。对于多个数值具有具体含义的重要时域特征序列,使用离散傅里叶变换转化为多个频域特征序列,将频域特征序列输入多个基于Transformer框架的编码器获得中间特征向量a,其中:
特征选择方法:主要使用的算法为随机森林法或主成分分析法,随机森林法具有实现简单、不容易过拟合等优点,其本质是基于Bootstrap Aggregating思想的决策树模型。
Transformer框架:一种以编码器-解码器为基础,以自注意力机制(Self-Attention mechanism)为重点的深度学习框架,其能够有效解决循环神经网络(Recurrentneural network,RNN)无法并行处理和卷积神经网络(Convolutional Neural Networks,CNN)无法高效地捕捉长距离依赖的问题。
所述的其他特征提取模块,将其他特征序列分别通过DNN获取其在高维空间中的嵌入,并将这些嵌入整合为矩阵,输入均值或最值池化层后,将其抽象为一个中间特征向量b。
所述的分类结果输出模块,中间特征向量a和b,通过多层感知器(MultilayerPerceptron,MLP)及softmax归一化处理得到最终分类向量,可根据此向量计算得到最终分类概率分布。
MLP:一种前向结构的人工神经网络,映射一组输入向量到一组输出向量,输出向量的维度能够根据需求自定义。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 一种基于两阶段序列特征学习的网络流量分类方法及系统
- 一种基于两阶段序列特征学习的网络流量分类方法及系统