VR系统卸载成本最小化的通信和计算资源的联合分配方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及在CCHN中基于NOMA-MEC的VR系统资源分配技术领域,具体涉及一种在CCHN中基于NOMA-MEC的VR系统卸载成本最小化的通信和计算资源的联合分配方法,包括下行传输的功率和时间,MEC服务器和VR设备的计算频率。
背景技术
VR是一种高端的人机界面交互技术,随着社会的发展,5G技术催生了多样化的VR应用新产业链,如360°VR视频、在线VR游戏等。为了满足海量VR业务在极短时间内完成超大量数据密集计算和传输的需求,MEC被提出作为关键推动力之一,通过将计算任务卸载到边缘服务器处理,可以很大程度缓解VR设备的压力。然而,频谱资源稀缺仍是不可避免的瓶颈,严重影响着MEC网络的性能。为了追求更高的频谱效率,引入了NOMA和CCHN。NOMA允许多个VR设备共享同一时频资源,CCHN允许不具备认知无线电(Cognitive Radio,CR)能力的VR设备利用任何CR技术获得CR服务,且CCHN中的CR路由器可以作为更靠近VR设备的MEC服务器,为VR设备提供访问更快、抖动更低的服务。此外,全球温室气体排放问题使得研究绿色通信至关重要,不仅可以延长VR设备寿命,还可以降低MEC服务器维护费用。
因此,考虑到MEC服务器计算成本、MEC服务器传输成本和CRB频谱占用成本,在VR设备时延和能耗约束下研究通信和计算资源的分配,最小化CCHN中基于NOMA-MEC的VR系统总计算卸载成本最小化问题非常重要。
发明内容
针对现有技术存在的问题,本发明的目的在于提供一种在CCHN中基于NOMA-MEC的VR系统的资源分配方法,在满足VR设备时延和能耗的约束下通过合理联合分配通信和计算资源实现VR设备在NOMA-MEC系统下的CCHN总计算卸载成本最小化。
为实现上述目的,本发明采用的技术方案是:
一种在CCHN中基于NOMA-MEC的VR系统卸载成本最小化的通信和计算资源的联合分配方法,所述方法包括以下步骤:
步骤1、网络中放置一组VR设备
步骤2、生成卸载VR设备集
步骤3、在卸载VR设备集
步骤4、进行卸载通信和计算资源分配问题P1的约束等价转换;
步骤5、随机生成满足卸载通信和计算资源分配问题P1约束的初始可行解集,即
步骤6、卸载通信和计算资源分配问题P1的凸逼近,获得凸问题P2;
步骤7、解决凸问题P2得到解
步骤8、更新问题P2约束的可行解集
步骤9、k
步骤10、在本地VR设备集
步骤11、进行本地通信和计算资源分配问题P3的约束等价转换;
步骤12、随机生成满足本地通信和计算资源分配问题P3约束的初始可行解集,即
步骤13、本地通信和计算资源分配问题P3的凸逼近,获得凸问题P4;
步骤14、解决凸问题P4得到解
步骤15、更新问题P4约束的可行解集
步骤16、k
步骤17、输出在给定VR设备的卸载决策α
所述步骤3中,卸载通信和计算资源分配问题P1的目标函数和约束如下:
(1)目标函数:卸载成本C
其中,η
(2)约束C
(3)约束C
其中,O
(4)约束C
其中,
(5)约束C
(6)约束C
其中,
所述步骤4具体如下:
(1)引入辅助变量
(2)引入辅助变量
/>
所述步骤6中,凸逼近处理如下:在上一次迭代的解集
(1)P1目标函数C
其中
(2)步骤4的(1)中三个等价后的约束在Ψ
(3)步骤4的(2)中等价后的第二个约束在Ψ
(4)根据步骤6(1)(2)(3)生成问题P1在第k
所述步骤10中,本地通信和计算资源分配问题P3的目标函数和约束具体如下:
(1)目标函数:本地成本C
(2)约束C
(3)约束C
(4)约束C
其中,
(5)约束C
其中κ
所述步骤11中,本地通信和计算资源分配问题P3的约束等价转换具体如下:
(1)引入辅助变量
(2)引入辅助变量
所述步骤13中,凸逼近处理如下:在上一次迭代的解集
(1)P3目标函数C
(2)步骤11(1)中三个等价后的约束在Ψ
(3)步骤11(2)中等价后的第二个约束在Ψ
(4)根据步骤13的(1)(2)(3)生成问题P3在第k
所述步骤7和步骤14中,通过Matlab CVX工具箱解决凸问题P2和凸问题P4。
采用上述方案后,可以在VR设备的卸载决策α
附图说明
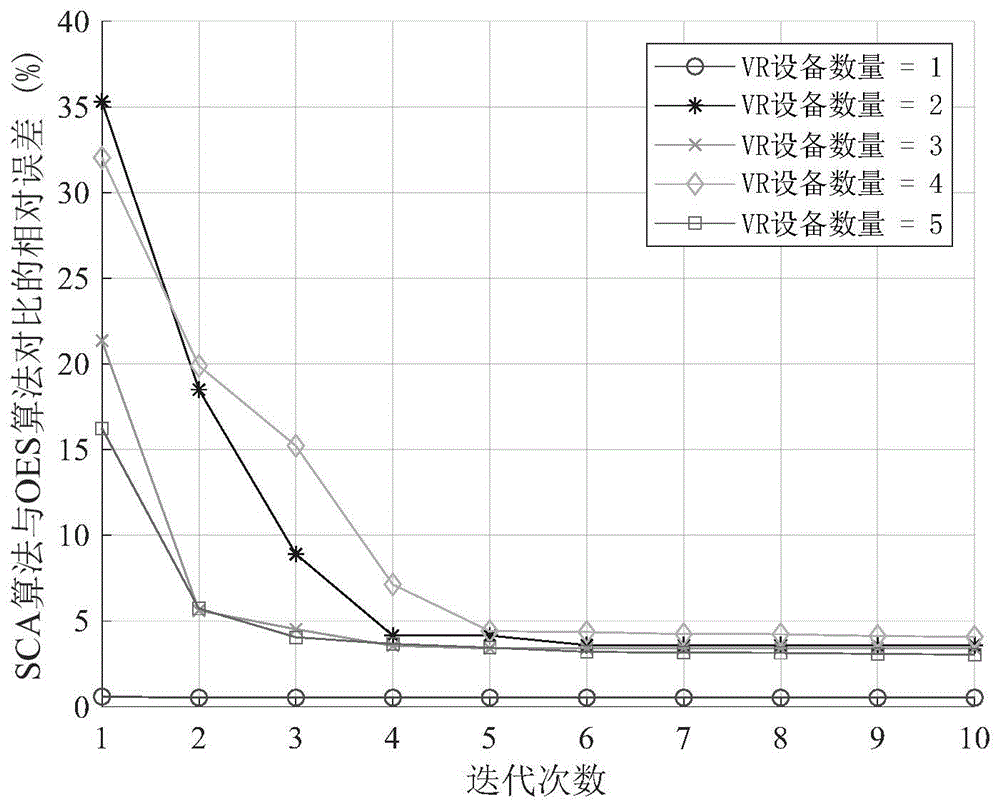
图1为在卸载通信和计算资源分配问题上,本发明(SCA)与穷举搜索(OES)算法对比得到的相对误差随最大迭代次数Γ的收敛曲线;
图2为在本地通信和计算资源分配问题上,本发明(SCA)与穷举搜索(OES)算法对比得到的相对误差随最大迭代次数Γ的收敛曲线;
图3为在卸载通信和计算资源分配问题上,本发明(SCA)与穷举搜索(OES)算法在30个随机例子下的性能比较;
图4为在本地通信和计算资源分配问题上,本发明(SCA)与穷举搜索(OES)算法在30个随机例子下的性能比较;
图5为在卸载通信和计算资源分配问题上,本发明(SCA)与ECRA、FTPA、NoTO和RFS算法在不同VR设备数下的性能比较;
图6为在本地通信和计算资源分配问题上,本发明(SCA)与ECRA、FTPA、NoTO和RFS算法在不同VR设备数下的性能比较;
图7为在卸载通信和计算资源分配问题上,本发明(SCA)与ECRA、FTPA、NoTO和RFS算法在不同输入数据大小下的性能比较;
图8为在本地通信和计算资源分配问题上,本发明(SCA)与ECRA、FTPA、NoTO和RFS算法在不同输入数据大小下的性能比较;
图9为在卸载通信和计算资源分配问题上,本发明(SCA)与ECRA、FTPA、NoTO和RFS算法在不同最大允许时延下的性能比较;
图10为在本地通信和计算资源分配问题上,本发明(SCA)与ECRA、FTPA、NoTO和RFS算法在不同最大允许时延下的性能比较。
具体实施方式
本发明揭示了一种在CCHN中基于NOMA-MEC的VR系统总计算卸载成本优化方法,应用场景是下行链路,它包含一个CR路由器、一组VR设备
为了方便处理,考虑准静态网络,即在完成任务计算和传输的整个过程,VR设备都保持不动。通过共享相邻蜂窝单元的频谱,完成MEC服务器到VR设备的数据传输。为了尽可能减小蜂窝用户(Cellular Users,CUs)间的相互干扰,相邻的蜂窝单元占用不同频谱,然后频谱又进一步划分为CRBs。考虑到MEC服务器到VR设备的数据传输过程会对CUs造成额外的干扰,CCHN的频谱需要从其他服务提供商购买,MEC服务器上的任务计算和下行传输过程会带来一定能耗,系统总计算卸载成本主要包含三个部分:
①MEC服务器为VR设备执行计算任务,产生电能消耗而造成的MEC服务器计算成本,
②MEC服务器给VR设备分配下行传输功率传输数据,产生传输能耗而造成的MEC服务器传输成本,
③VR设备共享CRB需要支付的CRB频谱占用成本,
因此,整个系统的计算卸载成本可以计算为,
其中,α
当VR设备卸载决策α
问题1:卸载通信和计算资源分配问题:当α
卸载通信和计算资源分配问题P1可以描述为
其中,约束C
h
问题2:本地通信和计算资源分配问题:本地通信和计算资源分配问题:当α
本地通信和计算资源分配问题P3可以描述为
其中,约束C
很显然,问题P1的目标函数、约束C
本发明的通信和计算资源联合分配方法具体包括以下步骤:
步骤1、网络中放置一组VR设备
步骤2、生成卸载VR设备集
步骤3、在卸载VR设备集
步骤4、卸载通信和计算资源分配问题P1的约束等价转换:
(1)引入辅助变量
(2)引入辅助变量
步骤5、随机生成满足卸载通信和计算资源分配问题P1约束的初始可行解集,即
步骤6、卸载通信和计算资源分配问题P1的凸逼近:在上一次迭代的解集
(1)P1目标函数C
其中
(2)步骤4的(1)中三个等价后的约束在Ψ
(3)步骤4的(2)中等价后的第二个约束在Ψ
(4)根据步骤6(1)(2)(3)生成问题P1在第k
步骤7、通过Matlab CVX工具箱解决凸问题P2得到解
步骤8、更新问题P2约束的可行解集
步骤9、k
步骤10、在本地VR设备集
步骤11、本地通信和计算资源分配问题P3的约束等价转换:
(1)引入辅助变量
/>
(2)引入辅助变量
步骤12、随机生成满足本地通信和计算资源分配问题P3约束的初始可行解集,即
步骤13、本地通信和计算资源分配问题P3的凸逼近:在上一次迭代解集
(1)P3目标函数C
(2)步骤11(1)中三个等价后的约束在Ψ
(3)步骤11(2)中等价后的第二个约束在Ψ
(4)根据步骤13(1)(2)(3)生成问题P3在第k
步骤14、通过Matlab CVX工具箱解决凸问题P4得到解
步骤15、更新问题P4约束的可行解集
步骤16、k
步骤17、输出在给定VR设备的卸载决策α
为了评估本发明的性能,进行以下仿真。设置以MEC服务为中心的蜂窝单元的服务半径为500m,VR设备随机放置在这个范围内。在与所考虑的蜂窝单元相邻的6个单元中,基站都位于单元中心位置。信道增益根据对数距离路径损失模型计算,路径损失指数为4。仿真参数设置为:VR设备最大传输功率为23dBm,CRB个数为20,信道带宽B为500MHz,2D FOVs数据大小取值范围为[1,6]Mbits,3D FOVs数据大小取值范围为[2-12]Mbits,计算载荷ρ
图1和图2分别描述了卸载通信和计算资源分配问题和本地通信和计算资源分配问题在不同VR设备数量下,由SCA算法得到的系统成本值与与最优穷举(OES)算法相比得到的相对误差随迭代次数变化的趋势。可以看出,所提出的SCA算法获得的成本随着迭代次数增加而快速下降,当最大迭代次数为5时相对误差基本上就能够控制在5%以下,说明SCA算法的收敛速度较快。在本发明接下里的仿真中,SCA算法的最大迭代次数设置为Γ=5。
由于OES算法的时间、空间复杂度随着VR设备数呈指数型增长,我们只在小网络场景下对比SCA算法和OES算法。如图3和图4所示,我们在30个随机例子中对比了SCA算法和OES算法,其中Case 1-Case10、Case 11-Case 20、Case 21-Case 30分别是在VR设备数量M=3,4,5的场景下仿真运行的。可以看出,OES算法的运行时间随VR设备数增加快速增长,但SCA算法能在非常短的时间内得到和OES算法相近的性能。
为了在大网络中衡量SCA算法的性能,我们提出了4种基准测试方案作为对比,即计算资源平均分配算法(ECRA)、分式发射功率分配算法(FTPA)、无时间优化算法(NoTO)、随机优化算法(RFS)。VR设备数量的默认值设为20,ECRA算法中MEC服务器和VR设备的计算CPU频率固定为3GHz,FTPA算法中下行传输功率按照信道增益排序分配,NoTO算法中下行传输时间固定为4ms。
如图5、图6和图7、图8所示,系统成本随VR设备的数量和输入数据量的增加而增加。这是因为系统中参与传输和计算的VR设备的数量或输入数据量增加时,系统需要提供更多的通信和计算资源来满足所有VR设备的传输、计算需求,因此系统的总成本随之上升。反之,如图9、图10所示,系统的成本随VR设备最大容许时延的增加而减少。因为当任务的时延要求越严格时,系统需要以更多的通信和计算资源为代价,来保证传输和计算在任务最大容许时延内完成,因此系统成本增加。另外,相比于RFS、NoTO、ECRA和FTPA算法,所提的SCA算法平均减少了83.04%、58.47%、29.79%和12.52%的系统成本。
以上所述,仅是本发明实施例而已,并非对本发明的技术范围作任何限制,故凡是依据本发明的技术实质对以上实施例所作的任何细微修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 基于D2D通信的多任务联合计算卸载与资源分配方法
- 联合计算和通信资源分配的LEO边缘卸载方法