一种基于深度信息的图像渲染方法及装置
文献发布时间:2023-06-19 19:32:07
技术领域
本申请涉及计算机图形学技术领域,特别是涉及一种基于深度信息的图像渲染方法及装置。
背景技术
新视角图像渲染技术是计算机视觉领域和计算机图形学技术领域的一个重要研究课题,有助于虚拟体验真实场景、实现沉浸式通信、改善游戏和娱乐体验等。
目前,可以基于一组图像序列及拍摄该图像序列的相机参数,训练全连接网络(Multilayer Perceptron,MLP),并学习图像的场景中的某一静态点的体积密度和颜色后,通过体渲染的图形学方法,渲染出一张新视角图像。
然而,针对室内场景中的物体或场景的新视角图像渲染技术仍然充满挑战。一方面,室内场景的渲染计算量很大,需要对数量足够多的图像确定整个场景的隐式表征,否则会导致图像质量大大下降;另一方面,室内场景通常具有较大面积的弱纹理或镜面区域,例如墙面、地面、桌面等,这些区域可能在不同位置的图像中呈现不一样的颜色值,从而导致无法精确拟合场景,甚至产生严重的伪影。
发明内容
本申请提供了一种基于深度信息的图像渲染方法及装置,能够减少输入图像的数量,并提高了室内场景的图像渲染质量。
本申请公开了如下技术方案:
第一方面,本申请公开了一种基于深度信息的图像渲染方法,所述方法包括:
获取室内场景图像序列;
基于所述室内场景图像序列,获取室内场景中场景3D点的位置信息;
基于所述场景3D点的位置信息,设置高斯分布的采样点;
基于所述采样点,训练全连接网络;
基于所述全连接网络使用体渲染方法进行渲染,以得到所述室内场景的新视角图像。
优选地,所述基于所述室内场景图像序列,获取室内场景中场景3D点的位置信息,包括:
基于所述室内场景图像序列,通过运动结构恢复方法生成稀疏深度图序列;
将所述室内场景图像序列和所述稀疏深度图序列输入至深度图生成网络,以生成稠密深度图,所述稠密深度图中包含室内场景中场景3D点的位置信息。
优选地,所述高斯分布的公式具体如下:
其中,t
优选地,在基于所述采样点,训练全连接网络之后,所述方法还包括:
获取任一场景3D点对应的采样点和整体采样点的深度比例偏差值,所述整体采样点是所述任一场景3D点和所述任一场景3D点的临近场景3D点整体对应的采样点;
若所述深度比例偏差值大于预设阈值,则去除所述任一场景3D点对应的采样点。
优选地,在所述基于所述采样点,训练全连接网络之后,所述方法还包括:
基于平方误差公式,优化所述全连接网络,所述平方误差方法的公式具体如下:
其中,R为射线的集合,
第二方面,本申请公开了一种基于深度信息的图像渲染装置,所述装置包括:序列模块、位置模块、设置模块、训练模块、渲染模块;
所述序列模块,用于获取室内场景图像序列;
所述位置模块,用于基于所述室内场景图像序列,获取室内场景中场景3D点的位置信息;
所述设置模块,用于基于所述场景3D点的位置信息,设置高斯分布的采样点;
所述训练模块,用于基于所述采样点,训练全连接网络;
所述渲染模块,用于基于所述全连接网络使用体渲染方法进行渲染,以得到所述室内场景的新视角图像。
优选地,所述位置模块,具体包括:第一生成模块、第二生成模块;
所述第一生成模块,用于基于所述室内场景图像序列,通过运动结构恢复方法生成稀疏深度图序列;
所述第二生成模块,用于将所述室内场景图像序列和所述稀疏深度图序列输入至深度图生成网络,以生成稠密深度图,所述稠密深度图中包含室内场景中场景3D点的位置信息。
优选地,所述高斯分布的公式具体如下:
其中,t
优选地,所述装置还包括:偏差值模块、去除模块;
所述偏差值模块,用于获取任一场景3D点对应的采样点和整体采样点的深度比例偏差值,所述整体采样点是所述任一场景3D点和所述任一场景3D点的临近场景3D点整体对应的采样点;
所述去除模块,用于若所述深度比例偏差值大于预设阈值,则去除所述任一场景3D点对应的采样点。
优选地,所述装置还包括:优化模块;
所述优化模块,用于基于平方误差公式,优化所述全连接网络,所述平方误差方法的公式具体如下:
其中,R为射线的集合,
相较于现有技术,本申请具有以下有益效果:
本申请提供一种基于深度信息的图像渲染方法及装置,首先针对室内场景拍摄的室内场景图像序列获取场景3D点的位置信息,然后在基于场景3D点的位置信息设置高斯分布的采样点后,基于采样点训练神经辐射场的全连接网络。最后,基于全连接网络使用体渲染方法进行图像渲染,以得到新视角图像。由此,使用结合深度信息的神经辐射场,优化体渲染的射线采样方法,能够大幅度减少图像的数量,并提高了三维场景的图像渲染质量。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
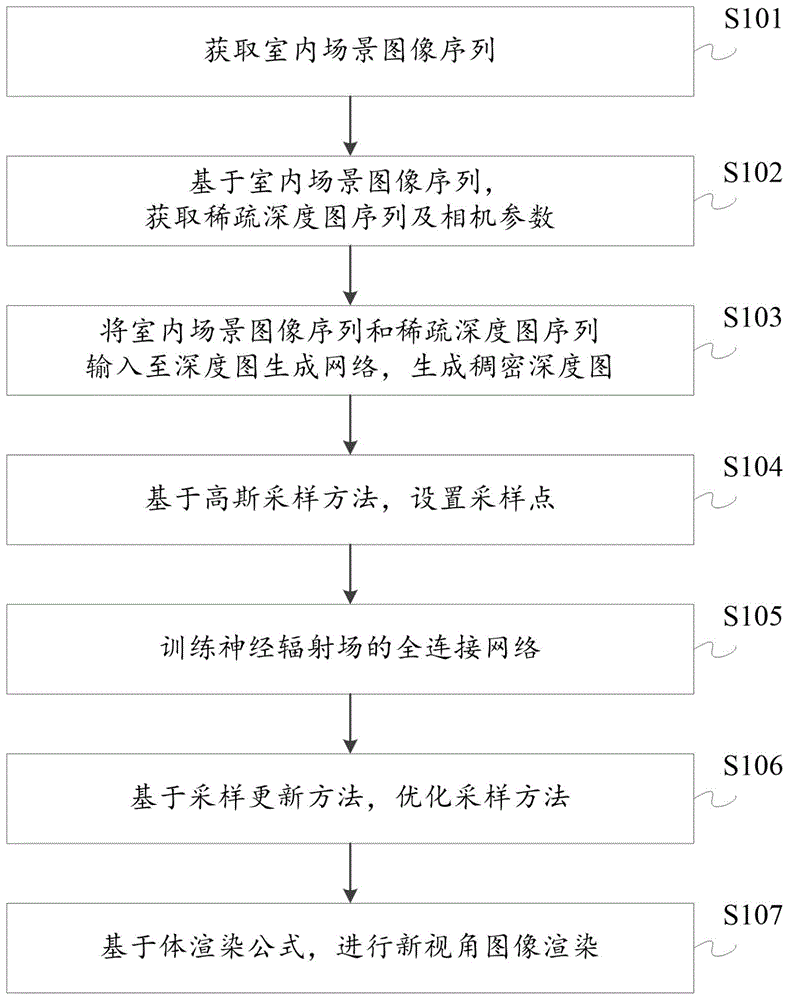
图1为本申请实施例提供的一种基于深度信息的图像渲染方法的流程图;
图2为本申请实施例提供的一种基于深度信息的图像渲染装置的示意图。
具体实施方式
下面先对本申请所涉及的技术术语进行介绍。
运动结构恢复(Structure from motion,SFM),即给出多幅图像及其图像特征的一个稀疏对应集合,从而估计图像中的3D点的位置,这个求解过程通常涉及3D几何(结构)和摄像机姿态(运动)的同时估计。
新视角图像渲染技术是计算机视觉领域和计算机图形学技术领域的一个重要研究课题,有助于虚拟体验真实场景、实现沉浸式通信、改善游戏和娱乐体验等。
目前的新视角图像渲染,可以通过给定的多个相机或者单个可以移动的相机拍摄出一个三维场景的一组图像序列,再基于这组图像序列获取当前图像序列对应的相机内参和外参信息,并基于图像序列及相机参数训练全连接网络(Multilayer Perceptron,MLP)后,学习场景中的某一静态点的体积密度和颜色,然后通过体渲染的图形学方法,渲染出一张新视角图像。
然而,针对室内场景中的物体或场景的新视角图像渲染技术仍然充满挑战。一方面,室内场景的渲染计算量很大,需要对数量足够多的图像确定整个场景的隐式表征,否则会导致图像质量大大下降;另一方面,室内场景通常具有较大面积的弱纹理或镜面区域,例如墙面、地面、桌面等,这些区域可能在不同位置的图像中呈现不一样的颜色值,从而导致无法精确拟合场景,甚至产生严重的伪影。
针对上述缺陷,本申请提供了一种基于深度信息的图像渲染方法及装置。首先针对室内场景拍摄的室内场景图像序列获取场景3D点的位置信息,然后在基于场景3D点的位置信息设置高斯分布的采样点后,基于采样点训练神经辐射场的全连接网络。最后,基于全连接网络使用体渲染方法进行图像渲染,以得到新视角图像。由此,使用结合深度信息的神经辐射场,优化体渲染的射线采样方法,能够大幅度减少图像的数量,并提高了三维场景的图像渲染质量。
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
参见图1,该图为本申请实施例提供的一种基于深度信息的图像渲染方法的流程图。该方法包括:
S101:获取室内场景图像序列。
室内场景图像序列可以是两张及以上的室内场景图像组成的序列,也可以是一个室内场景视频所拆分形成的图像帧序列。对于具体的室内场景图像序列,本申请不做限定。
室内场景图像序列中包含的所有室内场景图像均为同一个室内场景的不同角度的图像。对于具体的室内场景图像个数,本申请不做限定。可以理解的是,该室内场景图像可以是RGB图像,也可以是其他格式的图像,对于具体的图像格式,本申请不做限定。
可以理解的是,该室内场景图像序列可以是一系列不同方位的相机同时进行拍摄,也可以是单个相机进行移动拍摄,对于具体的拍摄方法,本申请不做限定。
S102:基于室内场景图像序列,获取稀疏深度图序列及相机参数。
稀疏深度图序列可以是两张及以上的稀疏深度图组成的序列,一张稀疏深度图可以由少量场景3D点构成,该场景3D点表征能够获取该点的深度信息,深度信息指室内场景中的物体至拍摄室内场景图像的相机之间的距离的信息。
相机参数可以分为相机内参和相机外参。相机内参可以表征相机的固定参数,是一个3×3的矩阵,相机外参可以表征当前相机旋转和和位置相对于世界坐标系的参数,是一个4×4的矩阵。
将稀疏深度图中的场景3D点结合相机参数,可以获取该稀疏深度图中的场景3D点的位置信息x=(x,y,z)及从相机看向该场景3D点的视角方向d=
在一些具体的实施方式中,可以基于S101步骤中获取到的室内场景图像序列,通过SFM中的三维重建函数库Colmap方法,对室内场景中的物体进行稀疏重建,以获取室内场景图像序列对应的稀疏深度图序列及相机参数。其中,SFM可以通过给出多幅图像及其图像特征的一个稀疏对应集合,从而估计图像中场景3D点的位置。Colmap方法是一种通用的SFM和多视图立体(MVS)管道的方法,它为有序和无序图像集合的重建提供了广泛的功能。
需要说明的是,该相机参数可以是通过SFM中的Colmap方法自动获取,也可以是外界直接输入的。对于相机参数的具体获取方法,本申请不做限定。
S103:将室内场景图像序列和稀疏深度图序列输入至深度图生成网络,生成稠密深度图。
深度图生成网络是基于大规模数据集预先完成训练的室内场景的深度图生成网络,该网络可以是网络结构为ResNet-50的卷积神经网络(Convolutional NeuralNetwork,CNN),也可以是其他结构的网络。需要说明的是,对于具体的网络结构,本申请不做限定。
在一些具体的实施方式中,可以将S101步骤中获取的室内场景图像序列和S102步骤中获取的稀疏深度图序列作为深度图生成网络的输入,从而推理输出当前室内场景图像的完整的稠密深度图,该稠密深度图可以由大量场景3D点构成,并且包含了室内场景中所有场景3D点的位置信息。
S104:基于高斯采样方法,设置采样点。
采样点是从相机位置沿着经过某一场景3D点的视角方向发出的一条射线上的点,可以表征室内场景图像中物体所处的位置。由于室内场景的复杂性,因此可以设置多个采样点。需要说明的是,具体的采样点个数可以由本领域技术人员自行设定,也可以基于室内场景的实际情况设定,可以是5个,也可以是10个、20个等,对于具体的采样点个数,本申请不做限定。
在一些具体的实施方式中,可以基于如下公式(1)获取采样点在射线上的分布,即,通过在采样点的深度坐标处计算高斯分布的方式,沿着射线寻找采样点。
其中,t
基于上述公式,通过获取室内场景图像中场景3D点的深度信息,可以在从相机位置沿着视角方向发出的一条射线上设置更少的采样点,在降低采样点数目的同时,达到提高采样的精度和效率的效果。
S105:训练神经辐射场的全连接网络。
基于采样点的位置信息x=(x,y,z)以及从相机看向该采样点的视角方向
F
其中,x是采样点的位置信息、d是从相机看向采样点的视角方向、c是采样点沿着视角方向d发射出去的颜色、σ是采样点的体积密度。
在一些具体的实施方式中,由于全连接网络中使用体渲染方法渲染出的像素颜色(即渲染像素颜色)与室内场景图像中的真实像素颜色(即真实像素颜色)存在差异,所以可以使用渲染像素颜色和真实像素颜色之间的平方误差优化全连接网络的训练。
在一些可能的实施例中,可以基于以下公式(3)进行全连接网络的优化。
其中,R为射线的集合,
S106:基于采样更新方法,优化采样方法。
由于处于相同深度的区域一般都具有近似的场景3D点分布,因此,可以基于任一场景3D点对应的采样点和整体采样点的设置信息,优化当前场景3D点的采样点设置,即剔除当前射线上的奇异采样点以优化采样方法。其中,整体采样点是任一场景3D点和任一场景3D点的临近场景3D点整体对应的采样点。
可以理解的是,可以依据5个、8个或其他数目个邻近场景3D点的采样点设置信息,优化当前场景3D点的采样点设置。需要说明的是,对于具体的临近采样点的采样个数,本申请不做限定。
在一些可能的实现方式中,该采样更新的方法可以具体为:首先,基于稠密深度图获取当前场景3D点和周围8个场景3D点的深度后,保留和当前场景3D点深度近似的邻近场景3D点。其次,基于确定的邻近场景3D点,使用确定的邻近场景3D点的采样点分布,通过计算当前场景3D点和周围8个场景3D点的整体的高斯分布,得到整体的采样点分布。最后,计算整体的采样点分布和确定的邻近场景3D点的采样点分布的深度比例偏差值,倘若该深度比例偏差值大于预设阈值,则可以剔除当前场景3D点的采样奇异点,以更新当前场景3D点的采样分布。
需要说明的是,该设定的预设阈值为技术人员自行设定,例如可以是深度比例偏差值大于1.1%,也可以是深度比例偏差值大于1.5%等,对于具体的预设阈值大小,本申请不做限定。
S107:基于体渲染公式,进行新视角图像渲染。
在获取优化后的全连接网络后,可以基于体渲染公式对优化后的全连接网络进行渲染,以得到室内场景的新视角图像。
本申请提供了一种基于深度信息的图像渲染方法。首先针对室内场景拍摄的室内场景图像序列,基于运动结构恢复方法获取稀疏深度图序列及相机参数,然后将室内场景图像序列和稀疏深度图序列输入至深度图生成网络以生成稠密深度图。然后在基于稠密深度图中的场景3D点位置信息设置高斯分布的采样点后,基于采样点训练神经辐射场的全连接网络。在训练过程中,基于采样更新方法,剔除奇异采样点,优化采样方法。最后,基于体渲染公式进行新视角图像渲染。由此,使用结合深度信息的神经辐射场,优化体渲染的射线采样方法,能够大幅度减少图像的数量,并提高了三维场景的图像渲染质量。
需要说明的是,虽然采用特定次序描绘了各操作,但是这不应当理解为要求这些操作以所示出的特定次序或以顺序次序执行来执行。在一定环境下,多任务和并行处理可能是有利的。
应当理解,本公开的方法实施方式中记载的各个步骤可以按照不同的顺序执行,和/或并行执行。此外,方法实施方式可以包括附加的步骤和/或省略执行示出的步骤。本公开的范围在此方面不受限制。
参见图2,该图为本申请实施例提供的一种基于深度信息的图像渲染装置的示意图。该基于深度信息的图像渲染装置200包括:序列模块201、位置模块202、设置模块203、训练模块204、渲染模块205。
序列模块201,用于获取室内场景图像序列;
位置模块202,用于基于室内场景图像序列,获取室内场景中场景3D点的位置信息;
设置模块203,用于基于场景3D点的位置信息,设置高斯分布的采样点;
训练模块204,用于基于采样点,训练全连接网络;
渲染模块205,用于基于全连接网络使用体渲染方法进行渲染,以得到室内场景的新视角图像。
在一些具体的实现方式中,位置模块202具体包括第一生成模块和第二生成模块。其中,第一生成模块用于基于室内场景图像序列,通过运动结构恢复方法生成稀疏深度图序列。第二生成模块用于将室内场景图像序列和稀疏深度图序列输入至深度图生成网络,以生成稠密深度图,稠密深度图中包含室内场景中场景3D点的位置信息。
在一些具体的实现方式中,高斯分布的公式(4)具体如下:
其中,t
在一些具体的实现方式中,该基于深度信息的图像渲染装置200还包括偏差值模块、去除模块。其中,偏差值模块用于获取任一场景3D点对应的采样点和整体采样点的深度比例偏差值,所述整体采样点是所述任一场景3D点和所述任一场景3D点的临近场景3D点整体对应的采样点。去除模块用于若所述深度比例偏差值大于预设阈值,则去除所述任一场景3D点对应的采样点。
在一些具体的实现方式中,该基于深度信息的图像渲染装置200还包括优化模块。优化模块用于基于平方误差公式,优化全连接网络。其中,该平方误差方法的公式(5)具体如下:
其中,R为射线的集合,
本申请提供了一种基于深度信息的图像渲染装置。首先针对室内场景拍摄的室内场景图像序列,基于运动结构恢复方法获取稀疏深度图序列及相机参数,然后将室内场景图像序列和稀疏深度图序列输入至深度图生成网络以生成稠密深度图。然后在基于稠密深度图中的场景3D点位置信息设置高斯分布的采样点后,基于采样点训练神经辐射场的全连接网络。在训练过程中,基于采样更新方法,剔除奇异采样点,优化采样方法。最后,基于体渲染公式进行新视角图像渲染。由此,使用结合深度信息的神经辐射场,优化体渲染的射线采样方法,能够大幅度减少图像的数量,并提高了三维场景的图像渲染质量。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元提示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上所述,仅为本申请的一种具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 一种提升3D图像深度信息的方法、装置及无人机
- 一种基于深度学习的图像自动标注方法及装置
- 一种基于深度学习的图像配准方法及装置
- 一种基于深度神经网络模型的图像识别方法、装置及设备
- 一种基于颜色和深度信息的穴盘苗长势无损监测方法和装置
- 基于深度图前向映射的图像渲染方法和图像渲染装置
- 基于深度图后向映射的图像渲染方法和图像渲染装置