基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法
文献发布时间:2024-01-17 01:27:33
技术领域
本发明涉及油气勘探和开发技术领域,具体涉及一种基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法。
背景技术
钻井取心具有涉及沉积、地球化学和岩石物理等多个方面的大量重要信息,对油气田勘探和开发至关重要。明晰垂向和横向的岩相展布是将这些信息由岩心尺度向油气区块或盆地尺度拓展的重要前提。钻井取心精度高,但受成本限制,资料相对稀缺;岩屑录井分辨率较低、不确定性较高,通常用作参考信息;地球物理测井虽然是反映岩相的间接资料却具有明显的规模优势。在常规流程中,通过岩心描述归类总结岩相和岩相组合类型,再结合取心井段的测井响应实现岩相向测井相映射,单井、连井甚至结合地震资料逐步实现尺度拓展。从中可以看出,充分挖掘岩心—测井资料、构建岩心—测井资料映射关系是不可或缺的关键一环。
岩心—测井映射构建方法均是基于岩石物理属性来区分岩相类型,通常可以细分为常规手段(定性描述、交会图和经验公式等)、传统机器学习(支持向量机、K-最近邻聚类法、基于决策树的方法和反向传播神经网络等)以及深度学习方法。常规手段传统方法在很大程度上依赖于数据和参数选择的主观经验,效率低、不确定性高。传统机器学习方法往往过于依赖特征工程对数据复杂性(或维度)的简化,适合任务的复杂度相对较低且存在易过拟合问题,泛化能力相对较弱。岩石物理属性的控制因素(如矿物、孔隙、流体、钻孔环境)要求实现复杂高维特征组合,深度学习的网络结构使其擅于从输入数据中学习高维特征,进而减少对特征工程及地质专家的过多依赖,随着算法和计算能力的巨大进步以及海量数据的可用性,实施深度学习实现岩心—测井映射关系的构建具有更大潜力。
综上所述,有必要对现有技术做进一步完善和创新。
发明内容
针对上述背景技术中存在的技术问题,本发明提出了一种基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其构思合理,可获得精确度高、特别是细粒薄层砂体的识别能力远超于机器学习的模型,该模型具备很强的实际应用价值,且能避免因数据和参数的主观选择造成的高不确定性和低效率。
为解决上述技术问题,本发明提供的一种基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,主要包括以下步骤:
(1)数据集构建
利用钻井取心岩性描述结果和取心井段的测井数据组建样本;
(2)模型构建
确定样本输入方式及模型基本结构,即:通过一维卷积实现样本特征向量的输入和维度提升,根据岩性类别数量确定一维卷积的重复次数;接着组合一维卷积的结果,输入长短期记忆循环神经网络中,再加入自注意力机制实现加权输出,得到高维特征向量,并通过全连接降维;
(3)模型训练
去除空值和异常值,样本特征值归一化,标签值编码,并将样本分为训练集、验证集和测试集;
(4)模型评价
基于PyTorch实现构建模型、参数优化、模型训练和验证。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中,所述步骤(1)中所述测井数据为样本特征值、岩性描述结果作为样本标签。
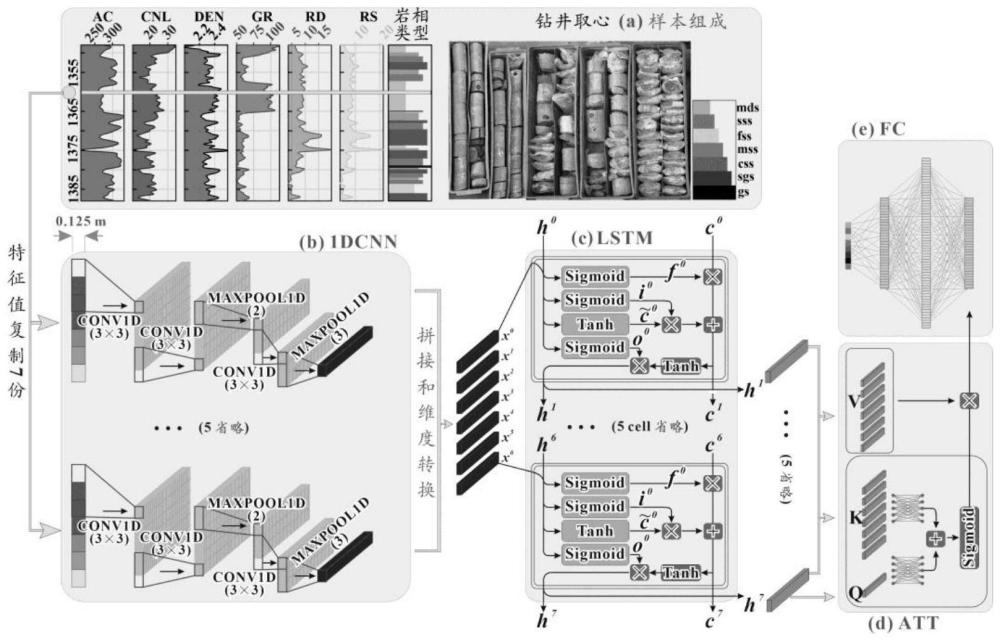
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中,所述步骤(2)中的所述模型基本结构主要分类四层结构即卷积网络层、长短期记忆递归神经网络层、注意机制层和全连接网络层;所述样本输入方式为:将6维特征向量复制7份岩相类型,分别通过独立的卷积网络层生成7份高维特征向量。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中:所述卷积网络层包括7个独立结构,7个独立结构共输出7份高维特征向量,经过拼接和维度转换输入所述长短期记忆递归神经网络层之中。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中:所述长短期记忆递归神经网络层包括7个顺序排列且具有共享权重的结构单元,每个结构单元输出一个高维向量,共计7个高维向量;最后一个隐层输出历经7个结构单元,具备共性特征,作为所述注意机制层的搜寻向量,所述长短期记忆递归神经网络层的7个高维向量输出作为所述注意机制层的键和值对,经所述注意机制层加权之后输出一个具有个性特征的高维向量并进入所述全连接网络层。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中:所述全连接网络层共包括一个输入层、两个隐藏层和一个输出层,将所述注意机制层的高维向量降维至7维向量对应岩相类型。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中,每个所述独立结构依次包括5个基本单元,即依次分别为:一维卷积单元、一维卷积单元、最大池化层、一维卷积单元和最大池化层。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中,所述卷积网络层和全连接网络层的激活函数选取双曲正切函数,模型学习策略设置为:学习率2e-5,衰减率0.1,当连续15个周期的验证损失减少小于0.008时,将执行学习率衰减。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中:所述步骤(3)中所述训练集和验证集的划分比例为8:2。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中,所述步骤(3)的具体步骤为:
(3.1)采用scikit-learn模块中的标准差标准化方法将输入的特征数据转换为平均值为0和单位方差的范围,通过标签编码方法使用[0,6]范围内的整数对7种岩相类型进行编码;
(3.2)在加载到混合模型中之前,数据集按20样本量划分批次,采用交叉熵损失法和模型优化算法对混合模型进行梯度下降优化,并同时考虑加权交叉熵损失用于处理不平衡数据集,权重值通过各岩相类型占比获取。
所述基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法,其中:所述步骤(4)模型评价的评价指标选取精度、召回率、平衡F分数以及准确度对模型进行评价,并以五折交叉验证的结果计算。
采用上述技术方案,本发明具有如下有益效果:
本发明基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法构思合理,通过构建岩心—测井映射关系实现测井岩性识别。相较于机器学习方法,本发明获得的准确度高、特别是细粒薄层砂体的识别能力远超于机器学习模型,并且加权损失的使用更进一步提升了样品量少的岩性识别能力。
相较于其他模型,本发明提出在输入端构建与岩性分类数量等同的高维向量,并经过含有7个单元的长短时记忆循环神经网络形成演化序列,最后利用注意力机制赋权能力选择最优的高维向量特征以代表各类岩性,以应对不同岩性间的测井响应叠置问题;评价和测试结果表明,本发明获得的精确度高、特别是细粒薄层砂体的识别能力远超于机器学习模型,该模型具备很强的实际应用价值,且能避免因数据和参数的主观选择造成的高不确定性和低效率。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法的模型结构图;
图2为本发明基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法的模型测试以及与AutoGluon的第一组对比结果;
图3为本发明基于自注意力机制的卷积循环深度学习网络实现测井岩性识别的方法的模型测试以及与AutoGluon的第二组对比结果。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合具体的实施方式对本发明做进一步的解释说明。
本实施例提供的基于自注意力机制的卷积循环深度学习模型实现测井岩性识别的方法,具体包括以下步骤:
(1)数据集构建
利用钻井取心岩相类型和取心井段的测井数据组建样本,其中测井数据为样本特征值、岩相类型结果作为样本标签。因实例数据的实际情况,测井曲线特征值为6类测井曲线(图1),包括密度测井(DEN)、自然伽马测井(GR)、深浅双侧向电阻率测井(RD和RS)、声波测井(AC)和补偿中子测井(CNL)。标签值为7类岩相,即砾岩(gs)、砂砾岩(sgs)、粗砂岩(css)、中砂岩(mss)、细砂岩(fss)、粉砂岩(sss)和泥岩(mds)。
(2)模型构建
确定样本输入方式及模型基本结构:模型结构如图1所示,主要分类四层结构,即卷积网络层(CNN)、长短期记忆递归神经网络层(LSTM)、注意机制层(ATT)和全连接网络层(FC),基于PyTorch深度学习框架搭建。
样本输入方式为:将6维特征向量复制7份(岩相类型数量),分别通过独立的卷积网络层CNN生成7份高维特征向量。因此,卷积网络层CNN包括7个独立结构,每个独立结构依次包括5个基本运算单元,即:一维卷积单元(CNNV1D)、一维卷积单元(CNNV1D)、最大池化层(MAXPOOL1D)、一维卷积单元(CNNV1D)、最大池化层(MAXPOOL1D)。卷积网络层(CNN)的7个独立结构共输出7份高维特征向量,经过拼接和维度转换输入长短期记忆递归神经网络层(LSTM)之中,长短期记忆递归神经网络层(LSTM)包括7个顺序排列且具有共享权重的结构单元(cell),每个结构单元(cell)输出一个高维向量,共计7个高维向量。最后一个隐层输出(c
(3)模型训练
去除空值和异常值,样本特征值归一化,标签值编码,预留连续取心井段作为测试数据集,其余样本按8:2划分为训练集和验证集。采用scikit-learn模块中的标准差标准化方法(StandardScaler)将输入的特征数据转换为平均值为0和单位方差的范围,使用标签编码方法(LabelEncoder)使用[0,6]范围内的整数对7种岩相类型进行编码;在加载到混合模型中之前,数据集按20样本量划分批次;采用交叉熵损失法和模型优化算法(Adam)对混合模型进行梯度下降优化,并同时考虑加权交叉熵损失用于处理不平衡数据集;权重值通过各岩相类型占比获取。权重衰减正则化方法(L2)被用于解决模型过拟合问题。另外,卷积网络层(CNN)和全连接网络层(FC)选取双曲正切函数(Tanh)作为激活函数;混合模型学习策略设置为:学习率2e-5,衰减率0.1,当连续15个周期的验证损失减少小于0.008时,将执行学习率衰减。
(4)模型评价
评价指标选取精度(Precision)、召回率(Recall)、平衡F分数(F1-score)以及准确度(Accuracy)对混合模型进行评价,并以五折交叉验证的结果计算。亚马逊公司研发的自动机器学习框架(Autogluon),已有研究和竞赛结果均证明其具有很好的测试效果,因此使用Autogluon作为对比模型用于评价本发明提出的模型。验证集评价结果中可以看出,专利模型在未使用加权损失的情况下能达到与Autogluon一样的验证精度,即:0.83。在使用加权损失之后专利模型精度下降为0.78,但模型对砂岩(样本量少)的召回能力明显提升(表1)。
表1混合模型及AutoGluon验证评价结果
测试集(两口具有连续取心的钻井)的结果也可以看出,Autogluon对薄层、细粒的岩性识别能力较弱,特别是图3中几乎识别为泥岩。而专利模型在薄层、细粒的岩性具备明显的优势,特别是使用加权损失之后,识别结果明显提升(图3)。因此,尽管加权损失函数对混合模型精度有负面影响,但样本量少的岩性召回率增加以及两口井的测试结果均证明了加权损失函数对专利模型的提升。另外,准确度(Accuracy)的下降与泥岩召回率下降有关。
本发明设计充分考虑(1)岩石物理性质对高维特征组合的要求;(2)岩石物理性质作为岩性识别基础的这一共性特征,以及(3)不同岩性具有不同的岩石物理优势响应这一个性特征,即:一维卷积神经网络层(1DCNN)将输入特征转换为高维特征向量,利用长短时记忆循环神经网络层(LSTM)的参数共享和注意机制层(ATT)的加权能力,依次实现高维特征向量的共性和个性提取,并通过全连接网络层(FC)降维输出。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 基于卷积神经网络的测井岩性识别方法及系统
- 一种基于卷积神经网络学习的测井岩性识别方法