多时间跨度数据的强解释特征血液透析低血压预测方法
文献发布时间:2024-01-17 01:28:27
技术领域
本发明属于机器学习领域。
背景技术
维持性血液透析是终末期肾病患者的主要治疗,当前有60万人在接受这种治疗。有终末期肾病的患者一般要经历每周三次的治疗,这对血液循环系统是一个极大的挑战。其治疗过程中存在着各种并发症,其中最为常见且严重的是血液透析中低血压(Intradialytic hypotension,IDH),影响到尿毒症患者的长期预后。低血压往往和长期的负性结果相关,包括心脏疾病发生率的增加和全因的致死率。在不同的研究中IDH的流行从8%到40%不等。
由于血液透析低血压的标准目前没有统一的定义,导致了对于低血压的相关因素预测难度很高。而且IDH的心血管和尿毒症机制作用复杂,并且还有其他原因也会引起低血压的发生,因此预测血液透析低血压的相关因素相互作用很困难。另外预测低血压模型的可解释性不强,对医生的临床实质帮助作用不大。
目前机器学习技术应用于血液透析低血压预测的方法主要有如下两种:1)预测模型特征单一的低血压预测方法。2)只有相关性研究的低血压相关特征预测方法
方案1)预测低血压的方法由于选择的特征单一,不能综合的把握血液透析低血压的疾病作用原理,造成对低血压疾病作用机理相关因素的误判,导致低血压预测结果准确率不高。方案2)的方法由于只是有相关性的因素分析,临床的可解释性不强,对临床的现实意义不大。在医生的临床中,需要医学检验的参考区间作为指导医生诊疗用药的重要保障。
综上所述,在现阶段的血液透析低血压的预测场景中,大部分的研究工作只进行单一特征相关因素的特征分析,这并不能实现利用与低血压真正疾病机理相关因素的分析对血液透析低血压进行预测的目的,对真实的医学临床场景作用不大。在使用相关因素分析的研究中,大部分工作并未探究相关因素与疾病的具体数值关系,比如相关因素与疾病相关的参考区间,这对于临床的意义会达到更好的效果。
发明内容
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明的目的在于提出一种多时间跨度数据的强解释特征血液透析低血压预测方法,用于实现对血液透析低血压的强解释预测。
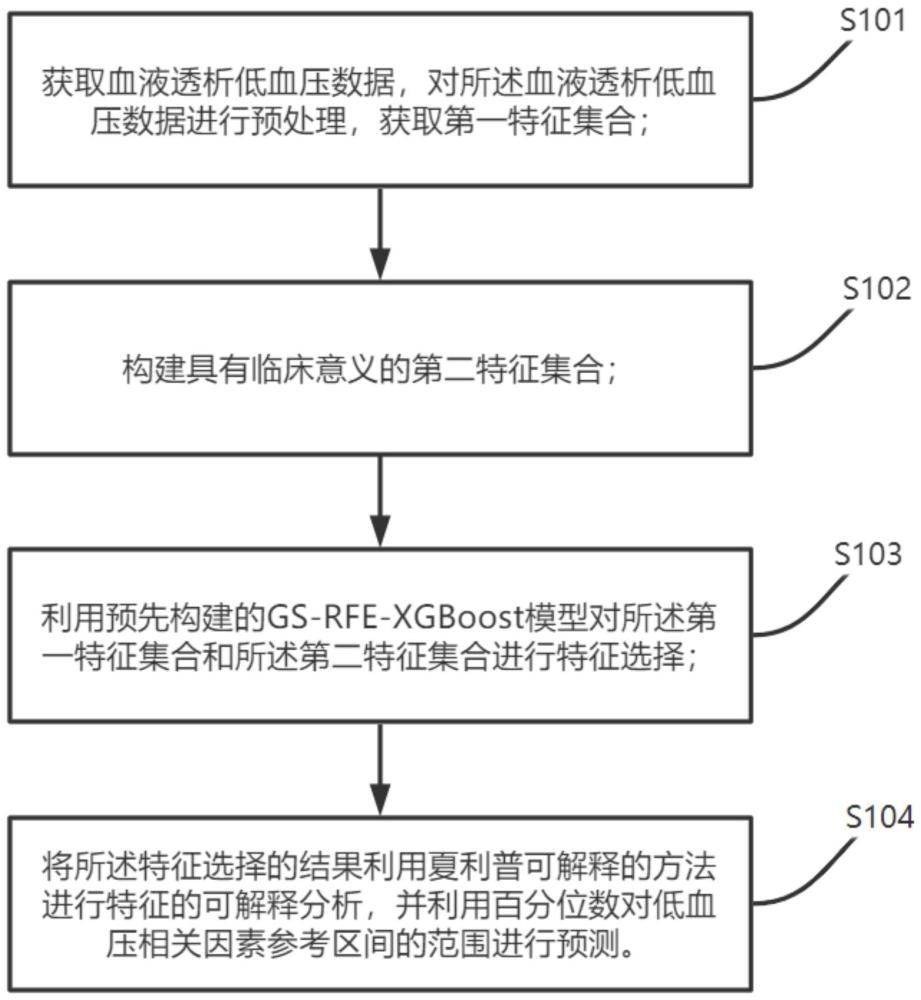
为达上述目的,本发明第一方面实施例提出了一种多时间跨度数据的强解释特征血液透析低血压预测方法,包括:
获取血液透析低血压数据,对所述血液透析低血压数据进行预处理,获取第一特征集合;
构建具有临床意义的第二特征集合;
利用预先构建的GS-RFE-XGBoost模型对所述第一特征集合和所述第二特征集合进行特征选择;
将所述特征选择的结果利用夏利普可解释的方法进行特征的可解释分析,并利用百分位数对低血压相关因素参考区间的范围进行预测。
另外,根据本发明上述实施例的一种多时间跨度数据的强解释特征血液透析低血压预测方法还可以具有以下附加的技术特征:
进一步地,在本发明的一个实施例中,在利用预先构建的GS-RFE-XGBoost模型对所述第一特征集合和所述第二特征集合进行特征选择之前,包括:
利用特征选择方法对所述第一特征集合进行特征筛选,将筛选后得到的特征输入预先构建的GS-RFE-XGBoost模型。
进一步地,在本发明的一个实施例中,在利用特征选择方法对所述第一特征集合进行特征筛选之前,还包括:
使用Python的pandas包合并函数对所述血液透析低血压数据进行聚合;
使用映射函数将分类值转换为数值,包括将分类特征转换为数字属性;
根据低血压专家的指导以及文献的查找进行低血压标签的定义。
进一步地,在本发明的一个实施例中,所述利用百分位数对低血压相关因素参考区间的范围进行预测,包括:
利用医学检验参考区间对获得的重要的特征进行强解释;其中,所述参考区间的获得方式包括:
正态分布,包括利用求得平均值和标准差的方式来求得参考区间;以及
偏态分布,包括利用百分位点,求得百分位2.5和百分位97.5的区间得到参考区间。
为达上述目的,本发明第二方面实施例提出了一种多时间跨度数据的强解释特征血液透析低血压预测装置,包括以下模块:
获取模块,用于获取血液透析低血压数据,对所述血液透析低血压数据进行预处理,获取第一特征集合;
构建模块,用于构建具有临床意义的第二特征集合;
预测模块,用于利用预先构建的GS-RFE-XGBoost模型对所述第一特征集合和所述第二特征集合进行特征选择;
分析模块,用于将所述特征选择的结果利用夏利普可解释的方法进行特征的可解释分析,并利用百分位数对低血压相关因素参考区间的范围进行预测。
进一步地,在本发明的一个实施例中,所述预处理模块,还用于:
利用特征选择方法对所述第一特征集合进行特征筛选,将筛选后得到的特征输入预先构建的GS-RFE-XGBoost模型。
进一步地,在本发明的一个实施例中,所述预处理模块,还用于:
使用Python的pandas包合并函数对所述血液透析低血压数据进行聚合;
使用映射函数将分类值转换为数值,包括将分类特征转换为数字属性;
根据低血压专家的指导以及文献的查找进行低血压标签的定义。
进一步地,在本发明的一个实施例中,所述分析模块,还用于:
利用医学检验参考区间对获得的重要的特征进行强解释;其中,所述参考区间的获得方式包括:
正态分布,包括利用求得平均值和标准差的方式来求得参考区间;以及
偏态分布,包括利用百分位点,求得百分位2.5和百分位97.5的区间得到参考区间。
为达上述目的,本发明第三方面实施例提出了一种计算机设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如上所述的一种多时间跨度数据的强解释特征血液透析低血压预测方法。
为达上述目的,本发明第四方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上所述的一种多时间跨度数据的强解释特征血液透析低血压预测方法。
本发明实施例提出的多时间跨度数据的强解释特征血液透析低血压预测方法,使用211个特征以及构建的21个特征利用模型进行相关因素预测,对重要的20个相关因素利用夏利普值方法进行相关分析,并利用百分位数2.5与97.5得到重要特征的参考区间,可实现对血液透析低血压的强解释预测。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1为本发明实施例所提供的一种多时间跨度数据的强解释特征血液透析低血压预测方法的流程示意图。
图2为本发明实施例所提供的一种数据预处理示意图。
图3为本发明实施例所提供的一种IDH不同标准的频率示意图。
图4为本发明实施例所提供的一种数据特征处理示意图。
图5为本发明实施例所提供的一种多跨度特征的强解释血液透析低血压预测方法对应的系统流程图。
图6为本发明实施例所提供的一种多时间跨度数据的强解释特征血液透析低血压预测装置的流程示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
下面参考附图描述本发明实施例的多时间跨度数据的强解释特征血液透析低血压预测方法。
图1为本发明实施例所提供的一种多时间跨度数据的强解释特征血液透析低血压预测方法的流程示意图。
如图1所示,该多时间跨度数据的强解释特征血液透析低血压预测方法包括以下步骤:
S101:获取血液透析低血压数据,对所述血液透析低血压数据进行预处理,获取第一特征集合;
通过来自于837个患者的211个特征的1173783个透析记录(包括跨越月、日、小时和患者的基本信息)作为数据集,将医学检验以月为时间跨度,透析记录以天为时间跨度,透析机监测记录以小时为时间跨度,最后汇总到透析机监测记录来进行实时的血压监测。具体过程如图2所示。
这211个特征包括:
基本信息:患者ID、性别、民族、出生日期、身高、体重、入院日期、首次透析时间、家庭地址、工作单位、医保付费方式、婚姻状况、职业、吸烟、饮酒、视力障碍、透龄、原发病;
检查检验:患者标识、随访日期、白细胞计数、红细胞计数、血红蛋白、红细胞压积、平均红细胞体积、平均血红蛋白量、平均血红蛋白浓度、血小板计数、网织红细胞(%)、淋巴细胞(%)、单核细胞(%)、中性粒细胞(%)、嗜酸性粒细胞(%)、嗜碱性粒细胞(%)、网织红细胞、淋巴细胞、单核细胞、中性粒细胞、嗜酸性粒细胞、嗜碱性粒细胞、红细胞分布宽度、血小板分布宽度、平均血小板体积、大血小板比率、血小板压积、红细胞沉降率、总蛋白、白蛋白、球蛋白、白球蛋白比例、谷丙转氨酶、谷草转氨酶、碱性磷酸酶、胆碱酯酶、总胆汁酸、总胆红素、直接胆红素、间接胆红素、谷氨酰转肽酶、腺苷酸脱氨酶、乳酸脱氢酶_02肝功能、羟丁酸脱氢酶、透析前肌酐、透析后肌酐、透析前尿素氮、透析后尿素氮、透析前尿酸、透析后尿酸、透析前钾、透析前钙、透析前磷、透析后氯、透析前钠、透析后钠、透析前氯、透析后磷、透析后钾、透析后钙、透析前镁、透析后镁、Ca*P、透前二氧化碳、透后二氧化碳、甘油三酯、总胆固醇、高密度脂蛋白-C、低密度脂蛋白-C、极低密度脂蛋白-C、血糖、餐后2小时血糖、HbA1C、甲状旁腺激素、血清铁、血清铁蛋白、总铁结合力、转铁蛋白饱和度、转铁蛋白、叶酸、VitB12、透前尿素、透后尿素、透析时间、Urr、脱水量、体重、KT/V、前白蛋白、C反应蛋白、前降钙素、透前血β2微球蛋白、透后血β2微球蛋白、β2-MG的下降率、钠尿肽、钠尿肽前体、乳酸脱氢酶_26LDH;
透析记录:患者ID、透析日期、床号、透析器、透析机型号、透析模式、通路类型、血液流速、置换方式、置换液总量、透析液温度、透析液流速、抗凝剂、首剂、维持量、钾、钙、钠、碳酸氢根、冲盐水时间、冲盐水剂量、冲盐水总量、透析时间、干体重、透前体重、衣物重量、透前净体重、拟脱水、体温、透前收缩压、透前舒张压、透前脉搏、透前心率、前次透析后体重、单超模式、透析器凝血级、动脉血路管凝血等级、静脉血路管凝血等级、策略、动脉壶、静脉壶、内瘘真颤音、皮肤完整性、皮肤描述、动脉端、动脉端原因、静脉端、静脉端原因、流量不足、血肿、血肿情况、感染、动脉穿刺针、动脉穿刺方向、静脉穿刺针、静脉穿刺方向、导管连接方式、隧道口感染、隧道口感染原因、分泌物、分泌物描述、血肿、血肿情况、血栓、静脉炎、缝线脱落、外用药、更换敷料、敷料感染、导管脱落、脱落原因、下机封管、封管液、导管腔容量a、导管腔容量v、导管距cuff距离、透后体重、实际脱水、透后收缩压、透后舒张压、透后心率;
透析机监测信息:患者ID、jc_time、透析日期、监测时间、体温、脉搏、收缩压、舒张压、血流量、肝素量、超滤量、电导度、低分子肝素、护理记录、静脉压、动脉压、机温、跨膜压、无肝素、氯化钠;
月小结:患者id、年份、月份、降压药、Epo、铁剂、磷结合剂、vitd制剂、其它、评价。
S102:构建具有临床意义的第二特征集合;
构建18个透析前后医学检验离子变化的指标,以及透析龄,透析期间体重增长,平均动脉压一共21个指标。
S103:利用预先构建的GS-RFE-XGBoost模型对所述第一特征集合和所述第二特征集合进行特征选择;
进一步地,在本发明的一个实施例中,在利用预先构建的GS-RFE-XGBoost模型对所述第一特征集合和所述第二特征集合进行特征选择之前,包括:
利用特征选择方法对所述第一特征集合进行特征筛选,将筛选后得到的特征输入预先构建的GS-RFE-XGBoost模型。
进一步地,在本发明的一个实施例中,在利用特征选择方法对所述第一特征集合进行特征筛选之前,还包括:
使用Python的pandas包合并函数对所述血液透析低血压数据进行聚合;
使用映射函数将分类值转换为数值,包括将分类特征转换为数字属性;
根据低血压专家的指导以及文献的查找进行低血压标签的定义。
具体地,本发明使用Python的pandas包合并函数来聚合所有数据,得到1173783个透析记录和211个特征。数据集包含血液透析期间初始和血液透析时间的信息。
本发明通过使用映射函数将分类值转换为数值。例如,通路类型类别包括临时插管、移植植物血管瘘、长期插管、直接穿刺和自体动静脉瘘,本发明将其分别转换为1、2、3、4和5。本发明总共将29个分类特征转换为数字属性。
根据低血压专家的指导以及文献的查找进行8种低血压标签的定义,得到的图3所示,由于考虑到不同标准的发生频率各异,只关注标准8(KDOQI)。
利用4种特征选择方法对211个特征进行特征筛选,得到89个特征,对这89个特征进行训练和测试。如图4所示,本发明构建的GS-RFE-XGBoost模型进行的特征选择方法的表现最好。
根据预先构建的模型GS-RFE-XGBoost对重新组合成的特征进行选择,得到20个特征。这20个特征包括:
透前收缩压、透前舒张压、收缩压、舒张压、血小板计数、通路类型、透前净体重、透析机型号、红细胞压积、嗜碱性粒细胞、血小板分布宽度、透析前尿酸、KT/V、甲状旁腺激素、透析前中收缩压变化、透析前中舒张压变化、透析前后舒张压变化、透析前后收缩压变化、透析前后钙变化、透析龄
S104:将所述特征选择的结果利用夏利普可解释的方法进行特征的可解释分析,并利用百分位数对低血压相关因素参考区间的范围进行预测。
进一步地,在本发明的一个实施例中,所述利用百分位数对低血压相关因素参考区间的范围进行预测,包括:
利用医学检验参考区间对获得的重要的特征进行强解释;其中,所述参考区间的获得方式包括:
正态分布,包括利用求得平均值和标准差的方式来求得参考区间;以及
偏态分布,包括利用百分位点,求得百分位2.5和百分位97.5的区间得到参考区间。
图5为多跨度特征的强解释血液透析低血压预测方法对应的系统流程图。
本发明实施例提出的多时间跨度数据的强解释特征血液透析低血压预测方法,使用211个特征以及构建的21个特征利用模型进行相关因素预测,对重要的20个相关因素利用夏利普值方法进行相关分析,并利用百分位数2.5与97.5得到重要特征的参考区间,可实现对血液透析低血压的强解释预测。
相对于现有技术,本发明的优点有:
1)本发明利用以天为时间跨度的透析记录,以月为时间跨度的医学检验记录,最后与以小时为时间跨度的透析机监测信息融合进行低血压实时监测,第一次实现了利用不同时间跨度的数据对低血压进行综合的实时疾病预测。
2)本发明构建的21个特征,提高了低血压预测准确率的40%,这些构建的特征都和血液透析前后离子的变化相关,第一次实现了利用血液透析前后离子的变化的数据特征对低血压进行疾病预测。
3)本发明针对低血压预测模型利用夏利普可解释的方法进行特征的可解释分析,并且利用百分位数对低血压相关因素参考区间的范围进行预测,得到的低血压预测模型可以应用于血液透析低血压的强解释模型预测。
为了实现上述实施例,本发明还提出多时间跨度数据的强解释特征血液透析低血压预测装置。
图6为本发明实施例提供的一种多时间跨度数据的强解释特征血液透析低血压预测装置的结构示意图。
如图6所示,该多时间跨度数据的强解释特征血液透析低血压预测装置包括:预处理模块100,构建模块200,预测模块300,分析模块400,其中,
预处理模块,用于获取血液透析低血压数据,对所述血液透析低血压数据进行预处理,获取第一特征集合;
构建模块,用于构建具有临床意义的第二特征集合;
预测模块,用于利用预先构建的GS-RFE-XGBoost模型对所述第一特征集合和所述第二特征集合进行特征选择;
分析模块,用于将所述特征选择的结果利用夏利普可解释的方法进行特征的可解释分析,并利用百分位数对低血压相关因素参考区间的范围进行预测。
进一步地,在本发明的一个实施例中,所述预处理模块,还用于:
利用特征选择方法对所述第一特征集合进行特征筛选,将筛选后得到的特征输入预先构建的GS-RFE-XGBoost模型。
进一步地,在本发明的一个实施例中,所述预处理模块,还用于:
使用Python的pandas包合并函数对所述血液透析低血压数据进行聚合;
使用映射函数将分类值转换为数值,包括将分类特征转换为数字属性;
根据低血压专家的指导以及文献的查找进行低血压标签的定义。
进一步地,在本发明的一个实施例中,所述分析模块,还用于:
利用医学检验参考区间对获得的重要的特征进行强解释;其中,所述参考区间的获得方式包括:
正态分布,包括利用求得平均值和标准差的方式来求得参考区间;以及
偏态分布,包括利用百分位点,求得百分位2.5和百分位97.5的区间得到参考区间。
为达上述目的,本发明第三方面实施例提出了一种计算机设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如上所述的多时间跨度数据的强解释特征血液透析低血压预测方法。
为达上述目的,本发明第四方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上所述的多时间跨度数据的强解释特征血液透析低血压预测方法。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、 “示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 血液透析中低血压事件的预测模型的构建方法
- 基于历史数据集时间跨度优化的光伏发电功率预测方法及系统