基于静态和动态表情图像的联合表情编码系统及其方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及图像处理技术领域,尤其是涉及一种基于静态和动态表情图像的联合表情编码系统及其方法。
背景技术
在人际交往中,面部表情作为非语言信号在情感表达中起着重要的作用。表情分为静态和动态两种。静态表情是指表情视频中,各帧图像表征的表情信息,而动态表情是指相邻两帧之间变化的信息。
目前,基于面部图像和深度学习的情感识别研究中,尽管使用静态和动态面部图像的信息融合和3维卷积方法(同时对于面部外观和时序进行卷积)取得了良好的性能。但是,静态和动态特征是通过各自通道独立提取的,缺少静态和动态信息的内在关联,影响了表情特征的表征能力。尽管3维卷积可以同时提取空间和时间信息,但是因为计算量大和效率低下而将视频分为若干子视频,使得卷积无法很好地提取动态特征,影响了情感识别性能。
发明内容
本发明的目的是解决上述背景技术存在的问题,本发明将静态表情图像和动态表情图像按照编码方法合并到一张图像中,使其能够同时表征静态的和动态的表情信息,提高基于面部表情的情感识别能力。
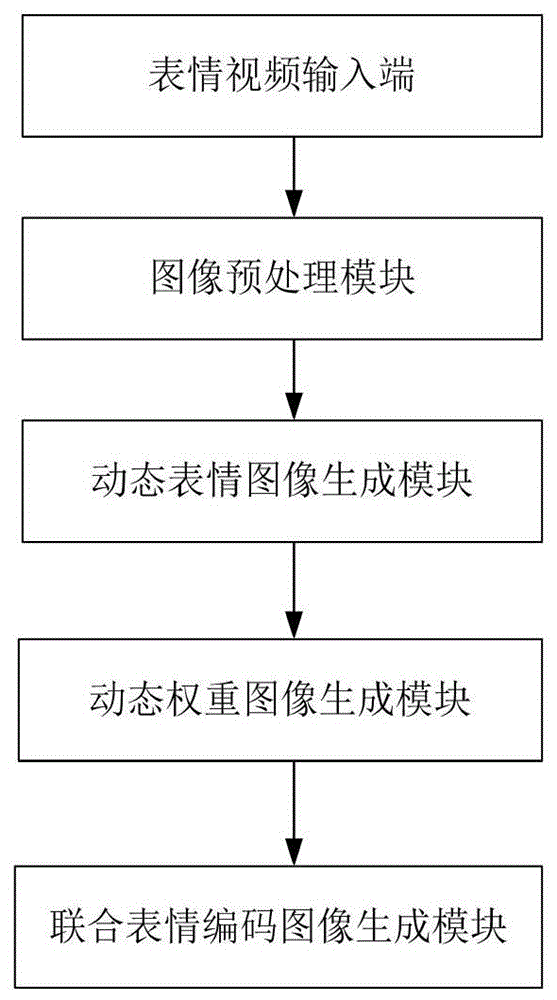
为实现上述目的,本发明提供了一种基于静态和动态表情图像的联合表情编码系统,包括图像预处理模块、动态表情图像生成模块、动态权重图像生成模块和联合表情编码图像生成模块;
所述图像预处理模块与表情视频输入端相连接,用于对输入的表情视频进行图像预处理;
所述图像预处理模块与所述动态表情图像生成模块相连接,用于将预处理后的图像生成动态表情图像;
所述动态表情图像生成模块与所述动态权重图像生成模块相连接,用于根据动态表情图像生成动态权重图像;
所述动态权重图像生成模块与所述联合表情编码图像生成模块相连接,用于根据动态权重图像和静态图像生成联合表情编码图像。
一种基于上述系统的联合表情编码方法,具体步骤如下:
步骤S1:对输入的表情视频图像进行图像预处理;
步骤S2:根据预处理后的表情视频生成动态表情图像;
步骤S3:根据动态表情图像生成动态权重图像;
步骤S4:根据动态权重图像和静态图像生成联合表情编码图像。
优选的,所述图像预处理包括下采样、图像裁剪以及图像对齐。
优选的,根据相邻两帧的图像计算生成动态表情图像的具体步骤如下:
步骤S21:计算运动矢量,计算公式如下:
其中,P(x)是t时刻图像I
步骤S22:计算动态图像,计算公式如下:
其中,I
Z
d
λ
优选的,根据动态表情图像生成动态权重图像的具体步骤如下:
步骤S31:对于动态表情图像进行归一化处理,处理公式如下:
步骤S32:根据归一化后的动态图像I
优选的,步骤S4具体为:
根据权重图像I
其中,I
因此,本发明具有的有益效果为:将静态和动态表情进行联合编码,生成包括静态和动态表情的联合编码的表情图像,使用同一空间同时表征表情的静态和动态信息,从而提高情感识别能力。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明一种基于静态和动态表情图像的联合表情编码系统结构示意图;
图2为本发明联合表情编码方法的流程图;
图3为本发明实施例1数据处理流程图;
图4为本发明实施例2数据处理流程图。
具体实施方式
实施例
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“安装”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
下面结合附图,对本发明的一些实施方式作详细说明。
一种基于静态和动态表情图像的联合表情编码系统,包括图像预处理模块、动态表情图像生成模块、动态权重图像生成模块和联合表情编码图像生成模块。
所述图像预处理模块与表情视频输入端相连接,用于对输入的表情视频进行图像预处理。所述图像预处理模块与所述动态表情图像生成模块相连接,用于将预处理后的图像生成动态表情图像。所述动态表情图像生成模块与所述动态权重图像生成模块相连接,用于根据动态表情图像生成动态权重图像。所述动态权重图像生成模块与所述联合表情编码图像生成模块相连接,用于根据动态权重图像和静态图像生成联合表情编码图像。
一种基于上述系统的联合表情编码方法,具体步骤如下:
步骤S1:对输入的表情视频图像进行图像预处理,所述图像预处理包括下采样、图像裁剪以及图像对齐。
步骤S2:根据预处理后的表情视频生成动态表情图像。
根据相邻两帧的图像计算生成动态表情图像的具体步骤如下:
步骤S21:计算运动矢量,计算公式如下:
其中,P(x)是t时刻图像I
步骤S22:计算动态图像,计算公式如下:
其中,I
Z
d
λ
步骤S3:根据动态表情图像生成动态权重图像。
根据动态表情图像生成动态权重图像的具体步骤如下:
步骤S31:对于动态表情图像进行归一化处理,处理公式如下:
步骤S32:根据归一化后的动态图像I
步骤S4:根据动态权重图像和静态图像生成联合表情编码图像。
根据权重图像I
其中,I
实施例1
本实施例用于表情识别。
表情识别数据集使用公开的动态表情库CK+和Oulu-CASIA分别进行表情识别。
CK+Dataset:包含123名受试者的593个表情序列,其中,有327个表情序列带有情绪标签,共有7种情绪:愤怒,轻蔑,厌恶,恐惧,快乐,悲伤,惊讶。所有表情图像序列都是从中性表情开始逐渐过渡到峰值表情结束。
Oulu-CASIA Dataset:包含80名年龄在23-58岁的受试者的480个表情序列,共有6种情绪,分别是:愤怒、厌恶、恐惧、快乐、悲伤、惊喜。表情图像序列从中性情绪开始,以情绪的峰值结束。
图3为本发明实施例1数据处理流程图,如图3所示,在公开的表情数据集中,每一帧表情图像都包含了背景等干扰因素,如图3中的(a)行所示,因此,首先对表情图像进行裁剪和人脸对齐,得到预处理后的表情图像,如图3中的(b)行所示;其次是根据相邻两帧图像计算生成动态表情图像,如图3中的(c)行所示;然后将动态表情图像归一化并且计算生成动态表情权重图像,如图3中的(d)行所示;最后根据动态表情权重图像和静态图像计算生成联合编码表情图像,如图3中的(e)行所示。
表1所示的是不同方法在CK+和Oulu-CASIA数据集上使用深度学习方法的分类结果。
表1.基于不同表情图像的情感识别能力的比较(准确率±标准差)%
可以看出,基于联合编码表情图像的分类准确率显著大于基于静态表情、基于动态表情、基于静态与动态表情融合以及3D编码方法的分类准确率。
实施例2
本实施例用于抑郁症表情识别,抑郁症识别数据集使用用于抑郁症识别的表情数据集(EFEV),创建的表情数据集(EFEV)包括86名抑郁症患者和44名正常人。在采集数据时,让参试者分别观看快乐和悲伤的视频短片(每段视频持续90s),使用相机同步采集参试者的面部表情。摄像装置以分辨率1280*960和80帧/秒的采样频率记录参试者观看视频时的面部表情变化,最终每个参试者共被记录14400帧的面部表情图像。
图4为本发明实施例2数据处理流程图,如图4所示,在EFEV表情数据集中,每个视频有14,400帧图像。由于相邻两帧图像的表情变化很微小,我们对数据集进行下采样,每10帧抽取一帧图像,这样每个视频得到1440张的面部表情图像。
每一帧表情图像都包含了背景等干扰因素,因此,首先对表情图像进行裁剪和人脸对齐,得到预处理后的表情图像,如图4中的(a)行所示;其次是根据相邻两帧图像计算生成动态表情图像,如图4中的(b)行所示;然后将动态表情图像归一化并且计算生成动态表情权重图像,如图4中的(c)行所示;最后根据动态表情权重图像和静态图像计算生成联合编码表情图像,如图4中的(d)行所示。
表2所示的是不同方法在EFEV数据集上使用深度学习方法的分类结果。
表2.基于不同表情图像的抑郁症识别能力的比较(准确率±标准差)%
可以看出,基于联合编码表情图像的分类性能显著大于基于静态表情、基于动态表情、基于静态与动态表情融合以及3D编码方法的分类性能。
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。
- 基于静态和动态表情图像的联合表情编码系统及其方法
- 利用静态人脸图像生成动态表情图像序列的方法和装置