近眼显示器中的眼睛跟踪
文献发布时间:2024-04-18 19:52:40
技术领域
本公开一般地涉及用于在诸如增强现实系统之类的近眼显示器中跟踪眼睛运动的方法和系统,更具体地,涉及通过使用利用深度卷积神经网络的深度学习模型的基于视网膜的跟踪,以及利用卡尔曼滤波器模型的图像配准过程,而不使用常规的基于瞳孔亮斑的技术来跟踪眼睛运动。
背景技术
包括虚拟现实(VR)、增强现实(AR)、混合现实(MR)和扩展现实(XR)头戴式装置的空间计算头戴式装置已被证明对于跨越科学可视化、医学和军事训练、工程设计和原型设计、远程操作和远程呈现以及个人娱乐系统等领域的许多应用具有不可估量的价值。在空间计算头戴式装置中,虚拟或增强场景经由光学组件显示给用户,该光学组件可定位并可固定在用户头部,位于用户眼前。
已经开发了头戴式显示器(HMD),用于在3D虚拟和增强环境领域进行广泛应用。准确高速的眼睛跟踪对于实现HMD中的关键场景非常重要,例如,通过随中央凹变化的显示方案和新型人机交互界面实现的视场(FOV)和分辨率权衡。嵌入HMD中的眼睛跟踪器可分为侵入式方法(例如,巩膜线圈)和非侵入式基于视频的方法,后者更为常见。当前基于视频的方法主要使用眼球的不同特征,如虹膜、瞳孔和亮斑,其中瞳孔亮斑方法应用最为广泛。这些方法的平均跟踪误差为0.5°-1.°,而这些特征的跟踪分辨率约为每像素0.7°-1.°。要进一步提高超过跟踪分辨率的精度并不容易。
除了使用眼表面的特征外,也可以将视网膜图像用于医学领域的眼睛跟踪,例如眼睛跟踪扫描激光检眼镜(SLO)。他们利用小FOV高分辨率图像中视网膜运动估计的扫描失真,然而,该技术是专为小扫视而设计的,并且SLO不容易集成到HMD中。HMD中基于视网膜的眼睛跟踪有其自身的优势:无需高级传感器、线性注视估计模型和视网膜中央凹的直接定位,即可获得更高的跟踪分辨率。此外,视网膜跟踪提供了HMD的广泛医疗应用。
此外,现代对象识别方法基本上利用了机器学习方法。为了提高其性能,一些实施例可以收集更大的数据集,学习更强大的模型,并使用更好的技术来防止过拟合。直到最近,标记图像的数据集还相对较小,大约为数万张图像。使用这种大小的数据集,可以很好地解决可以建立对象跟踪的简单识别任务,特别是如果使用标签保留变换来增强这些任务。例如,MNIST数字识别任务的当前最佳错误率(<0.3%)接近人类表现。但现实环境中的对象表现出相当大的可变性,因此要学会识别它们,可能需要使用更大的训练集。小图像数据集的缺点已被广泛认识到,但最近才有可能收集具有数百万图像的标记数据集。
为了从数百万张图像中了解数千个对象,迫切需要一个具有强大学习能力的模型。尽管如此,对象识别任务的巨大复杂性意味着即使是像ImageNet(图像网络)这样大的数据集也无法确定这个问题,因此在一些实施例中,模型也应该具有大量的先验知识,以补偿现代技术根本不具备的所有数据。卷积神经网络(CNN)构成了一类这样的模型。它们的容量可以通过改变其深度和宽度来控制,并且它们还对图像的性质(即,统计的平稳性和像素相关性的局部性)做出了有力且基本正确的假设。因此,与具有类似大小的层的标准前馈神经网络相比,CNN具有更少的连接和参数,因此更易于训练,而其理论上的最佳性能可能仅稍差。
尽管CNN具有吸引人的品质,并且尽管其局部架构相对有效,但大规模应用于高分辨率图像的成本仍然十分高昂。
此外,视觉对象跟踪是计算机视觉各种任务(如自动驾驶和视频监控)的基本组成部分。它在由照明、变形、遮挡和运动引起的大的外观变化方面具有挑战性。此外,速度在实际应用中也很重要。
现代跟踪器大致可以分为两个分支。第一分支基于相关性滤波器,该滤波器通过利用循环关联的特性并在傅里叶域中执行运算来训练回归器。它可以进行在线跟踪,同时有效地更新滤波器的权重。原始版本在傅里叶域中执行,然后在跟踪共同体中广泛使用。最近基于相关性滤波器的方法使用深度特征来提高精度,但这在很大程度上损害了模型更新的速度。这些方法的另一分支旨在使用非常强大的深度特征,并且不更新模型。然而,由于未使用域特定的信息,这些方法的性能始终不如基于相关性滤波器的方法。
本文所述的各种实施例至少解决了常规方法的上述挑战和缺点,并提出了基于对象运动视频的对象跟踪的实时定位方法,其中可以在镶嵌(mosaic)搜索图像上定位每个帧。
发明内容
根据一些实施例,描述了一种用于在近眼显示器中跟踪眼睛运动的方法。在这些实施例中,可以识别对象或其一部分的多张基本图像;可以至少部分地基于所述多张基本图像中的至少一些生成搜索图像;可以至少通过使用深度学习模型中的神经网络对基本图像执行深度学习过程来生成深度学习结果;以及可以至少通过使用卡尔曼滤波器模型和所述深度学习结果对捕获的图像和所述搜索图像执行图像配准过程来将所述捕获的图像定位到所述搜索图像。
在这些实施例的一些中,其中,所述对象包括用户的视网膜,并且在不使用响应于一个或多个输入光图案而从所述瞳孔捕获亮斑的瞳孔亮斑技术的情况下,相对于所述搜索图像定位表示所述视网膜的至少一部分的所述捕获的图像。
在一些实施例中,生成所述深度学习结果包括使用深度卷积神经网络(DCNN)提取所述捕获的图像中的区域中的特征。此外,可以将所述特征转换为包括第一特征和第二特征的多个特征。可以至少部分地基于所述第一特征,将所述区域分类为正区域或负区域。可以至少部分地基于所述第二特征,确定所述区域的回归或校正。
在一些实施例中,为了生成所述深度学习结果,可以使用深度卷积神经网络(DCNN)提取所述捕获的图像中的区域中的特征;以及可以将所述特征转换为包括第一特征和第二特征的多个特征。
在紧邻的前面的实施例的一些中,为了生成所述深度学习结果,可以至少通过使用所述DCNN中的一个或多个卷积层卷积至少所述第一特征来生成第一响应图;以及可以至少部分地基于所述第一响应图,将所述区域分类为正区域或负区域。
在一些实施例中,为了生成所述深度学习结果,可以至少通过使用所述DCNN中的所述一个或多个卷积层或一个或多个不同的卷积层卷积所述第二特征来生成第二响应图;以及可以至少使用所述第二响应图来确定所述区域的预测位置的回归或校正。
在一些实施例中,定位所述捕获的图像包括:将所述深度学习过程嵌入到状态转换模型中;以及在所述卡尔曼滤波器模型处至少使用所述状态转换模型接收所述深度学习结果作为一个或多个测量,其中,所述状态转换模型用于至少部分地基于先前时间点的先前位置状态和状态估计模型的控制向量或过程噪声中的至少一个,确定下一时间点的下一位置状态。
在紧邻的前面的实施例的一些中,为了定位所述捕获的图像,可以通过在所述图像配准过程中至少使用所述卡尔曼滤波器模型来确定下一时间点的测量;可以至少通过执行所述图像配准过程来减少相似背景或一个或多个相似特征的干扰;以及可以使用所述卡尔曼滤波器模型和所述图像配准过程在所述搜索图像中将所述捕获的图像定位到所述搜索图像。
在一些实施例中,为了嵌入所述深度学习过程,可以确定所述状态转换模型的一个或多个控制向量;可以从统计分布中导出过程噪声;以及可以确定所述状态转换模型的时间步长。
在前面的实施例的一些中,使用所述卡尔曼滤波器模型和所述图像配准过程在所述搜索图像中定位所述捕获的图像包括:对所述捕获的图像的整个帧执行粗略配准;以及对在所述粗略配准中涉及的区域周围的外部区域中的一个或多个特征或特征点执行精细配准。
附加地或替代地,为了对所述捕获的图像的所述整个帧执行所述粗略配准,可以在所述捕获的图像的所述整个帧或所述搜索图像中的一个或多个区域中检测所述一个或多个特征或特征点;以及可以将所述捕获的图像配准到所述整个帧中的所述一个或多个区域。
在紧邻的前面的实施例的一些中,对在所述粗略配准中涉及的区域周围的外部区域中的所述一个或多个特征或特征点执行所述精细配准包括:选择放大区域内的特征或特征点,所述放大区域对应于在所述粗略配准中涉及的所述区域;以及将所述特征或所述特征点与所述搜索图像的所述外部区域中的对应特征或特征点进行匹配。
在一些实施例中,对在所述粗略配准中涉及的区域周围的外部区域中的所述一个或多个特征或特征点执行所述精细配准还可以包括:至少部分地基于将所述特征或所述特征点与所述搜索图像的所述外部区域中的对应特征或特征点进行匹配的结果,在所述搜索图像中定位所述捕获的图像。
一些实施例涉及一种用于在近眼显示器中跟踪眼睛运动的系统,包括处理器、扫描光纤组件、以及在其上存储指令的存储器,所述指令在被所述处理器执行时,使所述处理器执行上述任一方法以在近眼显示器中跟踪眼睛运动。
一些实施例涉及一种在其上存储指令的非暂时性计算机可读介质,所述指令在被微处理器执行时,使所述微处理器执行上述任一方法以在近眼显示器中跟踪眼睛运动。
本公开的一些实施例的概述
1.一种用于在近眼显示器中跟踪眼睛运动的方法,包括:识别对象或其一部分的多张基本图像;至少部分地基于所述多张基本图像中的至少一些生成搜索图像;至少通过使用深度学习模型中的神经网络对基本图像执行深度学习过程来生成深度学习结果;以及至少通过使用卡尔曼滤波器模型和所述深度学习结果对捕获的图像和所述搜索图像执行图像配准过程来将所述捕获的图像定位到所述搜索图像。
2.根据权利要求1所述的方法,其中,所述对象包括用户的视网膜,并且在不使用响应于一个或多个输入光图案而从所述瞳孔捕获亮斑的瞳孔亮斑技术的情况下,相对于所述搜索图像定位表示所述视网膜的至少一部分的所述捕获的图像。
3.根据权利要求1所述的方法,其中生成所述深度学习结果包括:使用深度卷积神经网络(DCNN)提取所述捕获的图像中的区域中的特征;以及将所述特征转换为包括第一特征和第二特征的多个特征。
4.根据权利要求3所述的方法,其中,生成所述深度学习结果包括:至少部分地基于所述第一特征,将所述区域分类为正区域或负区域。
5.根据权利要求3所述的方法,其中,生成所述深度学习结果包括:至少部分地基于所述第二特征,确定所述区域的回归。
6.根据权利要求4所述的方法,其中,至少部分地基于所述第一特征而非基于所述第二特征,对所述区域进行分类。
7.根据权利要求5所述的方法,其中,至少部分地基于所述第二特征而非基于所述第一特征,确定所述区域的所述回归。
8.根据权利要求1所述的方法,其中,生成所述深度学习结果包括:使用深度卷积神经网络(DCNN)提取所述捕获的图像中的区域中的特征;以及将所述特征转换为包括第一特征和第二特征的多个特征。
9.根据权利要求8所述的方法,其中,生成所述深度学习结果还包括:至少通过使用所述DCNN中的一个或多个卷积层卷积至少所述第一特征来生成第一响应图;以及至少部分地基于所述第一响应图,将所述区域分类为正区域或负区域。
10.根据权利要求9所述的方法,其中,对所述区域进行分类至少部分地基于所述第一响应图而非基于所述第二响应图。
11.根据权利要求9所述的方法,其中,生成所述深度学习结果还包括:至少通过使用所述DCNN中的所述一个或多个卷积层或一个或多个不同的卷积层卷积所述第二特征来生成第二响应图;以及至少使用所述第二响应图来确定所述区域的预测位置的回归或校正。
12.根据权利要求11所述的方法,其中,确定所述回归或所述校正至少部分地基于所述第二响应图而非基于所述第一响应图。
13.根据权利要求8所述的方法,其中,生成所述深度学习结果还包括:至少使用图像配准过程来补偿所述DCNN和/或所述深度学习模型。
14.根据权利要求1所述的方法,其中,定位所述捕获的图像包括:将所述深度学习过程嵌入到状态转换模型中。
15.根据权利要求14所述的方法,其中,定位所述捕获的图像包括:在所述卡尔曼滤波器模型处至少使用所述状态转换模型接收所述深度学习结果作为一个或多个测量。
16.根据权利要求14所述的方法,其中,所述状态转换模型用于至少部分地基于先前时间点的先前位置状态和状态估计模型的控制向量或过程噪声中的至少一个,确定下一时间点的下一位置状态。
17.根据权利要求14所述的方法,其中,定位所述捕获的图像包括:通过在所述图像配准过程中至少使用所述卡尔曼滤波器模型来确定下一时间点的测量。
18.根据权利要求17所述的方法,其中,定位所述捕获的图像包括:至少通过执行所述图像配准过程来减少相似背景或一个或多个相似特征的干扰。
19.根据权利要求17所述的方法,其中,定位所述捕获的图像包括:使用所述卡尔曼滤波器模型和所述图像配准过程在所述搜索图像中定位所述捕获的图像。
20.根据权利要求14所述的方法,其中,嵌入所述深度学习过程包括:确定所述状态转换模型的一个或多个控制向量;从统计分布中导出过程噪声;以及确定所述状态转换模型的时间步长。
21.根据权利要求20所述的方法,其中,所述时间步长包括由增强现实系统捕获的两个紧邻帧之间的持续时间,并且所述状态转换模型用于至少部分地基于先前时间点的先前位置状态和状态估计模型的控制向量或过程噪声中的至少一个确定下一时间点的下一位置状态。
22.根据权利要求20所述的方法,其中,所述过程噪声从所述统计分布中导出,并且所述统计分配包括零均值多变量正态分布。
23.根据权利要求19所述的方法,其中,使用所述卡尔曼滤波器模型和所述图像配准过程在所述搜索图像中定位所述捕获的图像包括:对所述捕获的图像的整个帧执行粗略配准;以及对在所述粗略配准中涉及的区域周围的外部区域中的一个或多个特征或特征点执行精细配准。
24.根据权利要求23所述的方法,其中,对所述捕获的图像的所述整个帧执行所述粗略配准包括:在所述捕获的图像的所述整个帧或所述搜索图像中的一个或多个区域中检测所述一个或多个特征或特征点。
25.根据权利要求24所述的方法,其中,对所述捕获的图像的所述整个帧执行所述粗略配准包括:将所述捕获的图像配准到所述整个帧中的所述一个或多个区域。
26.根据权利要求23所述的方法,其中,对在所述粗略配准中涉及的区域周围的外部区域中的所述一个或多个特征或特征点执行所述精细配准包括:选择放大区域内的特征或特征点,所述放大区域对应于在所述粗略配准中涉及的所述区域。
27.根据权利要求26所述的方法,其中,对在所述粗略配准中涉及的区域周围的外部区域中的所述一个或多个特征或特征点执行所述精细配准包括:将所述特征或所述特征点与所述搜索图像的所述外部区域中的对应特征或特征点进行匹配。
28.根据权利要求25所述的方法,其中,对在所述粗略配准中涉及的区域周围的外部区域中的所述一个或多个特征或特征点执行所述精细配准包括:至少部分地基于将所述特征或所述特征点与所述搜索图像的所述外部区域中的对应特征或特征点进行匹配的结果,在所述搜索图像中定位所述捕获的图像。
29.根据权利要求1所述的方法,其中,所述深度学习模型包括修改的孪生候选区域生成网络,其中,所述深度学习模型包括深度卷积神经网络和图像配准过程,并且基于所述搜索图像而非基于多张搜索图像定位在不同时间段捕获的多个不同的捕获的图像。
30.根据权利要求1所述的方法,其中,所述深度学习模型包括修改的孪生候选区域生成网络,其中使用两个正交方向上的一个或多个目标位置而非使用边界框,将捕获的图像定位到所述搜索图像。
31.根据权利要求1所述的方法,其中,所述搜索图像是通过将所述多张基本图像中的至少一些拼接、镶嵌或组合到所述搜索图像中来生成的。
32.根据权利要求1所述的方法,其中,所述深度学习模型包括深度卷积神经网络和图像配准过程,并且当所述卡尔曼滤波器模型的一个或多个测量丢失时,所述深层学习模型仅调用所述深度卷积神经网,而不调用所述图像配准过程,直到下一次成功配准第一捕获的图像。
33.一种用于在近眼显示器中跟踪眼睛运动的系统,包括处理器、扫描光纤组件、以及在其上存储指令的存储器,所述指令在被所述处理器执行时,使所述处理器执行权利要求1-32中任一项所述的方法以在近眼显示器中跟踪眼睛运动。
34.一种在其上存储指令的非暂时性计算机可读介质,所述指令在被微处理器执行时,使所述微处理器执行权利要求1-28中任一项所述的方法以在近眼显示器中跟踪眼睛运动。
附图说明
图1示出了一些实施例中的用于近眼显示器中的眼睛跟踪的方法或系统的高级框图。
图2示出了一些实施例中的通过扫描光纤内窥镜(SFE)捕获的一些示例视网膜帧、基本帧或模板帧以及镶嵌基线或搜索图像。
图3示出了一些实施例中的400帧上以度数表示的视网膜跟踪误差的示例累积分布函数(CDF)。
图4示出了一些实施例中的与常规瞳孔亮斑方法相比的示例性的基于视网膜的跟踪的一些示例基准结果。
图5示出了一些实施例中的用于捕获视网膜的SFE图像的系统的简化示例。
图6示出了一些实施例中的视网膜的一些示例模板图像或基本图像。
图7示出了一些实施例中的示例深度学习模型。
图8示出了一些实施例中的机器人定位的简化工作示例。
图9示出了一些实施例中的在手术中定位显微镜或内窥镜的另一简化工作示例。
图10A示出了一些实施例中的用于人脸或眼睛跟踪的人脸或一个或多个眼睛定位的另一简化工作示例。
图10B示出了一些实施例中的用于对象跟踪的对象定位的另一简化工作示例。
图10C示出了一些实施例中的用于对象跟踪的对象定位的另一简化工作示例。
图11A示出了一个或多个实施例中的微型投影仪阵列和将微型投影仪阵列与光学系统耦合的示例配置。
图11B示出了一个或多个实施例中的可穿戴XR设备的示意性表示的一些示例部件的俯视图。
图11C示出了一个或多个实施例中的可穿戴XR设备的示意性表示的示例性实施例。
图12A示出了一个或多个实施例中的用于近眼显示器中的眼睛跟踪的高级框图。
图12B示出了一个或多个实施例中的示例候选区域生成网络(RPN)。
图12C示出了一个或多个实施例中的作为单次检测的另一示例跟踪。
图12D示出了一个或多个实施例中的RPN特征图中的示例中心尺寸。
图12E示出了一个或多个实施例中的具有ReLU(校正线性单元)的四层卷积神经网络的一些示例训练误差率。
图13示出了一个或多个实施例中的关于图12所示的高级框图的一部分的更多细节。
图14A示出了一个或多个实施例中的关于图12所示的高级框图的另一部分的更多细节。
图14B示出了一个或多个实施例中的示例深度卷积神经网络。
图15A示出了一个或多个实施例中的关于图12所示的高级框图的另一部分的更多细节。
图15B示出了一个或多个实施例中的关于图15A的一部分的更多细节。
图15C示出了一个或多个实施例中的关于图15A的另一部分的更多细节。
图16A-I示出了一个或多个实施例中的微型投影仪阵列和将微型投影仪阵列与光学系统耦合的示例配置。
具体实施方式
在以下描述中,阐述了某些特定细节以便提供对各种公开的实施例的透彻理解。然而,相关领域的技术人员将认识到,可以在没有这些具体细节中的一个或多个的情况下,或者使用其他方法、部件、材料等来实践实施例。在其他情况下,与眼镜相关联的众所周知的结构,包括空间计算头戴式装置和用于眼镜镜腿的铰链系统没有被详细示出或描述以避免不必要地混淆实施例的描述。
除非上下文另有要求,否则在随后的整个说明书和权利要求书中,“comprise(包括)”一词及其变体,例如“comprises(包括)”和“comprising(包括)”应以开放、包容的意义解释为“包括但不仅限于”。
在整个说明书中对“一个实施例”或“实施例”的引用意味着结合该实施例描述的特定特征、结构或特性被包括在至少一个实施例中。因此,在整个说明书的各个地方出现的短语“在一个实施例中”或“在实施例中”不一定都指示相同的实施例。此外,特定特征、结构或特性可以在一个或多个实施例中以任何合适的方式组合。
在以下描述中,阐述了某些特定细节以便提供对各种公开的实施例的透彻理解。然而,相关领域的技术人员将认识到,可以在没有这些具体细节中的一个或多个的情况下,或者使用其他方法、部件、材料等来实践实施例。在其他情况下,与虚拟现实(VR)、增强现实(AR)、混合现实(MR)和扩展现实(XR)系统相关联的众所周知的结构未详细示出或描述以避免不必要地模糊实施例的描述。应当注意,术语虚拟现实(VR)、增强现实(AR)、混合现实(MR)和扩展现实(XR)在本公开中可以互换使用,以表示用于至少经由本文所述的可穿戴光学组件12至少向用户显示虚拟内容的方法或系统。
除非上下文另有要求,否则在随后的整个说明书和权利要求书中,“comprise(包括)”一词及其变体,例如“comprises(包括)”和“comprising(包括)”应以开放、包容的意义解释为“包括但不仅限于”。
本文描述了示例装置、方法和系统。应当理解,此处使用词语“示例”、“示例性”和“说明性”来表示“用作示例、实例或说明”。本文描述为“示例”、“示例性的”或“说明性的”的任何实施例或特征不一定被解释为优于或优先于其他实施例或特征。本文所述的示例实施例并不意味着限制。将容易理解,如本文一般描述和图中所示的,本公开的各方面可以以各种不同的配置来布置、替换、组合、分离和设计,所有这些配置都在本文中明确地设想。
此外,图中所示的特定布置不应视为限制。应当理解,其他实施例可以或多或少地包括给定图中所示的每个元件。此外,可以组合或省略一些所示的元件。另外,示例实施例可以包括图中未示出的元件。如本文所用,关于测量,“大约”表示+/-5%。
已经开发了头戴式显示器(HMD),用于3D虚拟和增强环境领域中的广泛应用。准确高速的眼睛跟踪对于实现HMD中的关键场景非常重要,例如,通过随中央凹变化的显示方案和新型人机交互界面实现的视场(FOV)和分辨率权衡。嵌入HMD中的眼睛跟踪器可分为侵入式方法(例如,巩膜线圈)和非侵入式基于视频的方法,后者更为常见。当前基于视频的方法主要使用眼球的不同特征,如虹膜、瞳孔和亮斑,其中,瞳孔亮斑方法应用最为广泛。这些方法的平均跟踪误差为0.5°-1.°,而这些特征的跟踪分辨率大约为每像素0.7°-1.°。要进一步提高超过跟踪分辨率的精度并不容易。
除了使用眼表面的特征外,也可以将视网膜图像用于医学领域的眼睛跟踪,例如眼睛跟踪扫描激光检眼镜(SLO)。他们利用小FOV高分辨率图像中视网膜运动估计的扫描失真,然而,该技术专为小扫视而设计,并且SLO不容易集成到HMD中。HMD中基于视网膜的眼睛跟踪有其自身的优势:无需高级传感器、线性注视估计模型和视网膜中央凹的直接定位,即可获得更高的跟踪分辨率。此外,视网膜跟踪提供了HMD的广泛医疗应用。
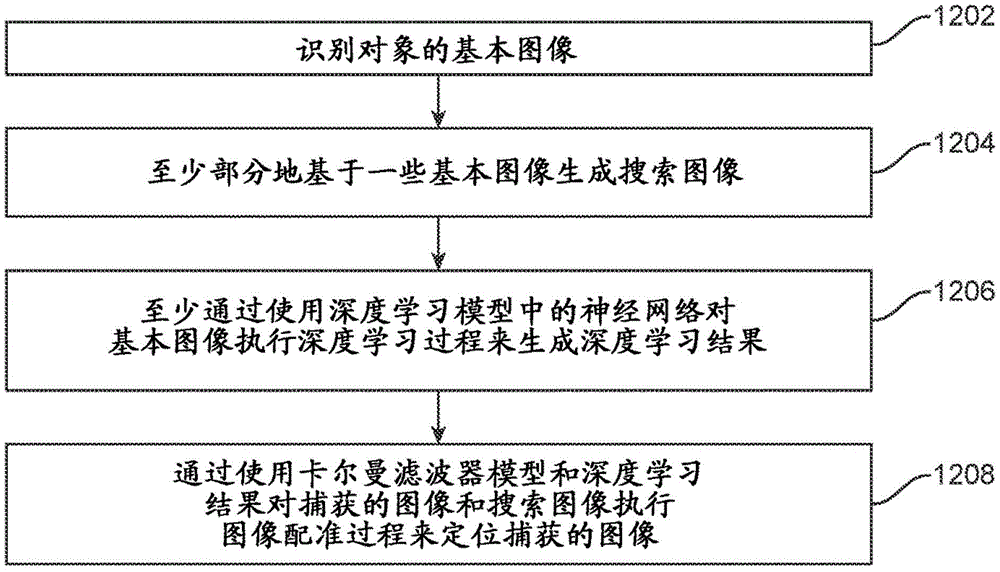
各种实施例提出了一种用于基于对象运动视频的对象跟踪的实时定位方法,其中,可以在镶嵌搜索图像上定位每个帧。图12A示出了一个或多个实施例中的用于近眼显示器中的眼睛跟踪的高级框图。
在这些实施例中,在1202,可以识别对象或其一部分(例如,视网膜或其一部分)的多个基本图像或模板图像。应当注意,术语“模板图像”和“基本图像”可以在本公开中互换使用,以区别于例如可以用多个基本图像中的一些或全部构建的搜索图像。在这些实施例的一些中,可以通过使用例如扫描光纤内窥镜(SFE)来捕获多个基本图像,而在一些其他实施例中可以通过任何图像捕获设备来捕获基本图像。
在1204,可以至少部分地基于多个基本图像中的至少一些来生成搜索图像。例如,搜索图像可以由多个基本图像镶嵌、拼接或以其他方式组合而成,这些基本图像可以用相同或不同的图像捕获设备来捕获。在一些实施例中,基本图像可以具有比搜索图像更低的分辨率和/或更窄的视场。在1204生成的搜索图像可进一步用于定位并因此跟踪移动的对象。应当注意,尽管本文参考用户的视网膜描述了一些实施例,但是本文所述的各种技术也可以应用于其他对象,如下所述。
在一些实施例中,一旦构建了搜索图像,任何随后捕获的图像帧(例如,通过XR系统的眼睛跟踪设备)都可以相对于同一搜索图像而不是像在一些常规方法中那样相对于多个图像进行配准。尽管在一些其他实施例中,随后捕获的图像帧(例如,通过XR系统的眼睛跟踪设备)可以相对于本文所述的多个搜索图像进行配准。
在1206处,可以至少通过使用深度学习模型中的神经网络对基本图像或捕获的图像执行深度学习过程来生成深度学习结果。利用在1206处生成的深度学习结果,可以在1208处至少通过使用卡尔曼滤波器模型和深度学习结果对捕获的图像和/或搜索图像执行图像配准过程来定位捕获的图像。在这些实施例中,在不使用响应于一个或多个输入光图案而捕获来自瞳孔的亮斑的瞳孔亮斑技术的情况下,表示视网膜的至少一部分的捕获的图像相对于搜索图像被定位。下面描述关于图12A所示的一些框图的更多细节。
图12B示出了一个或多个实施例中的示例候选区域生成网络(RPN)。更具体地,示例RPN网络包括孪生子网络1202B和候选区域生成网络1258B,它们共同用于执行特征提取,该特征提取生成具有正区域、特征、点、位置1222B和负区域、特征、点、位置1224B的第一输出。在第一输出中,1226B表示一个组,并且第一输出包括多个组1228B。孪生子网络1202B和候选区域生成网络1258B可以进一步执行特征提取,该特征进一步生成具有多个个体组1250B、1252B的第二输出。
一些实施例可以使用图像对进行离线训练,这可以利用大规模训练数据,例如Youtube-BB。消融实验表明,更多的数据有助于获得更好的性能。附加地或替代地,一些实施例发现,候选区域生成子网络通常预测生成的准确比例和比率,以获得如图12E所示的紧凑边界框。
图12E示出了具有ReLU(实线)的4层卷积神经网络在CIFAR-10上达到25%的训练错误率,比具有tanh神经元(虚线)的等效网络快六倍。每个网络的学习率都是独立选择的,以使训练尽可能快。没有采用任何形式的正则化。这里所展示的效果的大小随网络架构而变化,但具有ReLU的网络的学习速度始终比具有饱和神经元的网络快几倍。
图12B所示的一些实施例可以使用孪生候选区域生成网络(孪生RPN),该网络通过大规模图像对离线进行端到端训练,用于跟踪任务。当执行线上跟踪时,所提出的框架被制定为一个局部(local)单次检测任务,这可以改善生成以放弃昂贵的多尺度测试。它以160FPS的速度在VOT2015、VOT2016和VOT2017实时挑战中实现了领先的性能,这证明了它在准确性和效率方面的优势。
候选区域生成网络(RPN)首次在Faster R-CNN中提出。在RPN之前,传统的生成提取方法非常耗时。例如,选择性搜索需要2秒钟来处理一张图像。此外,这些生成还不足以进行检测。多个锚点的枚举和共享卷积特征使得生成提取方法在实现高质量的同时更省时。由于对前景-背景分类和边界框回归的监督,RPN能够提取更精确的生成。采用RPN的FasterR-CNN(更快的R-CNN)有几种变体。R-FCN考虑了部件的位置信息,FPN采用特征金字塔网络来提高微小对象检测的性能。与两级探测器相比,改进的RPN版本(如SSD和YOLO9000)是有效的探测器。RPN由于其速度快、性能好,在检测中有许多成功的应用,但它在跟踪方面还没有得到充分利用。
在图12B中,候选区域生成子网络1258B位于中间,其具有两个分支,一个分支1254B用于分类,另一分支1256B用于回归。采用成对的相关性来获得两个分支(1228B和1252B)的输出。这些两两成对的输出特征图(1226B、1228B、1250B和1252B)的详细信息在图中示出。在分类分支1254B中,输出特征图(1226B和1228B)具有与k个锚点的前景和背景相对应的2k个通道。在回归分支1256B中,输出特征图(1250B和1252B)具有与用于k个锚点的生成优化的两个坐标(x方向的dx和y方向的dy,而不是除了dx和dy之外,还具有宽度方向的dw和长度方向的dl的边界框)相对应的4k个通道。在图12B中,★1240B和1214B表示相关算子。
一些实施例详细描述了所生成的孪生RPN框架。如图2所示,所生成的框架由用于特征提取的孪生子网络和用于生成形成的候选区域生成子网络组成。具体地,RPN子网络中有两个分支,一个负责前景-背景分类,另一个用于生成优化。包括目标对象的图像块被馈送到所生成的框架中,并且整个系统被端到端地训练。
在孪生网络中,一些实施例采用无填充(padding)的完全卷积网络。设Lτ表示平移算子(Lτx)[u]=x[u-τ],则移除所有填充以满足具有步长k的完全卷积的定义:
h(L
一些实施例使用改进的AlexNet,其中,conv2和conv4的组被移除。孪生特征提取子网络由两个分支组成。一个被称为模板分支,其接收历史帧中的目标块作为输入(表示为z)。另一个被称为检测分支,其接收当前帧中的目标块作为输入(表示为x)。这两个分支共享CNN中的参数,以便通过适用于后续任务的相同变换对两个块进行隐式编码。为了便于说明和描述,一些实施例将φ(z)和φ(x)表示为孪生子网络的输出特征图。
候选区域生成子网络由成对的相关部分和监督部分组成。监督部分具有两个分支,一个用于前景-背景分类,另一个用于生成回归。如果有k个锚点,则网络需要输出2k个通道用于分类,输出4k个通道用于回归。因此,成对的相关部分首先通过两个卷积层将φ(z)的通道增加为两个分支[φ(z)]
模板特征图[φ(z)]
然后,它们通过平滑L1损失,其可以写成下式,
最后,可以优化损失函数:
loss=L
其中,λ是平衡两个部分的超参数。L
在训练阶段,以随机间隔从ILSVRC和从Youtube BB连续抽取样本对。从同一视频的两个帧中提取模板块和检测块。在使用Imagenet对孪生子网络进行预训练之后,一些实施例使用随机梯度下降(SGD)对孪生RPN进行端到端训练。由于需要训练回归分支,因此采用了一些数据增强,包括仿射变换。
一些实施例通过注意到两个相邻帧中的相同对象不会发生太大变化,在跟踪任务中选择比检测任务更少的锚点。因此,仅采用具有不同锚点比率的一个比例,并且一些实施例采用的锚点比率可以是[0.33、0.5、1、2、3]。
在此框架中,选择正负训练样本的策略也很重要。这里采用在对象检测任务中使用的标准,一些实施例使用IoU以及两个阈值th_hi和th_lo作为测量。正样本被定义为具有IoU>th_hi及其相应地面真实值的锚点。负样本被定义为满足IoU 在本小节中,一些实施例首先将跟踪任务制定为局部单次检测任务。然后,对该解释下的推理阶段进行详细分析并简化,以加快速度。最后,引入一些特定的策略,以使框架适合于跟踪任务。 一些实施例将单次检测视为有区别的任务,其目的是找出使预测函数ψ(x;W)的平均损失L最小化的参数W。此参数是在n个样本x i和相应标签 单次学习旨在从感兴趣分类的单个模板z中学习W。有区别的单次学习的挑战是找到一种机制,将类别信息纳入学习机中,即学会学习。为了解决这一挑战,一些实施例使用一种方法来借助元学习过程(即,将(z;W’)映射到W的前馈函数ω)从单个模板z中学习预测器的参数W。设z 如上所述,设z表示模板块,x表示检测块,函数φ为孪生特征提取子网络,函数ζ表示候选区域生成子网络,则一次检测任务可公式化为: 一些实施例现在可以将孪生子网络中的模板分支重新解释为训练参数,以预测局部检测任务的内核,这通常是指学会学习过程。在该解释中,模板分支用于将类别信息嵌入内核中,并且检测分支使用嵌入的信息执行检测。在训练阶段,元学习者不需要任何其他监督,除了成对的边界框监督。在推理阶段,孪生框架被修剪,只留下除了初始帧之外的检测分支,从而导致速度提高。来自第一帧的目标块被发送到模板分支,并且检测内核被预先计算,以便一些实施例可以在其他帧中执行单次检测。因为局部检测任务基于仅由初始帧上的模板给出的类别信息,所以它可以被视为如图12C所示的单次检测。在图12C中,1214C表示回归的权重;1216C表示分类的权重;conv表示卷积层;而CNN表示连接的神经网络。各种数字(例如,17×17×2K)表示数据集(例如,特征图)的维度。 一些实施例将模板分支的输出视为用于局部检测的内核。两个内核都在初始帧上被预先计算,并在整个跟踪期间固定。在当前特征图通过预先计算的核卷积的情况下,检测分支执行在线推断作为单次检测,如图3所示。在检测分支上执行正推法以获得分类和回归输出,从而获得前M个提议。具体地,在方程2中定义的一些实施例的符号之后,这些实施例将分类和回归特征图表示为点集: 其中i∈[0,w)、j∈[0,h)、l∈[0,2k) 其中i∈[0,w)、j∈[0,h)、p∈[0,k) 由于分类特征图上的奇数通道表示正激活,因此一些实施例收集所有 在生成前K个提议之后,一些实施例使用一些提议选择策略以使它们适合于跟踪任务,并将在下一节中讨论。 为了使一次性检测框架适合于跟踪任务,一些实施例可以采用两种策略来选择提议。第一提议选择策略是丢弃由锚点生成的距离中心太远的边界框。例如,一些实施例仅在 第二提议选择策略是,一些实施例使用余弦窗和比例改变惩罚(penalty)来重新排列提议的分数以获得最佳提议。丢弃异常值后,添加余弦窗口以抑制大位移,然后添加惩罚以抑制尺寸和比率的大幅变化: 这里,k是超参数。r表示提议的高宽比,r′表示最后一帧的高宽比。s和s′表示提议和最后一帧的总体比例,计算如下: (w+p)×(h+p)=s 其中,w和h表示目标的宽度和高度,p表示等于(w+h)/2的填充。在这些运算之后,前K个提议将在分类分数乘以时间惩罚后重新排序。随后执行非最大抑制(NMS)以获得最终的跟踪边界框。选择最终边界框后,通过线性插值更新目标大小,以保持形状平滑变化。 图12D示出了一个或多个实施例中的RPN特征图中的示例中心尺寸。更具体地,图12D示出了RPN特征图中的中心尺寸7,每个网格表示对应位置处的k个锚点的编码特征。例如,在分类特征图中有2k个通道,表示前景和背景激活。锚点的中心尺寸指示模型的搜索区域。 关于上述Alexnet,一些实施例在ILSVRC-2010和ILSVRC-2012比赛中使用的ImageNet子集上训练了迄今为止最大的卷积神经网络之一,并获得了迄今为止在这些数据集上报告的最佳结果。一些实施例调用2D卷积的高度优化的GPU实施方式以及训练卷积神经网络时固有的所有其他运算,一些实施例公开了这些运算。该网络包括许多新颖且不寻常的特征,这些特征提高了其性能并减少了其训练时间,具体描述如下。即使有120万个标记的训练示例,网络的规模也使过拟合成为了一个重要问题,因此一些实施例使用了以下描述的几种有效技术来防止过拟合。在一些实施例中,网络包括五个卷积层和三个全连接层,这一深度似乎很重要:一些实施例发现,去除任何卷积层(每个卷积层包含不超过1%的模型参数)会导致性能变差。在一些实施例中,网络的大小主要受限于当前GPU上可用的内存量以及一些实施例可以容忍的训练时间量。一些实施例网络需要五到六天的时间来训练两个GTX 580 3GB GPU。所有的实验表明,只要等待更快的GPU和更大的数据集可用,结果就会得到改善。 ImageNet是一个包含超过1500万张标记的高分辨率图像的数据集,这些图像属于大约22000个类别。这些图像是从网络上收集的,并由人类标签制作者使用Amazon的Mechanical Turk众包工具进行标记。从2010年开始,作为Pascal视觉对象挑战赛的一部分,每年举办一次名为ImageNet大规模视觉识别挑战赛(ILSVRC)的比赛。ILSVRC使用具有分别属于1,000个类别的大约1000张图像的ImageNet的子集。总共有大约120万张训练图像、50,000张验证图像和150,000张测试图像。 ILSVRC-2010是可使用测试集标签的ILSVRC的唯一版本,因此这是一些实施例执行大部分实验的版本。由于一些实施例也在ILSVRC-2012比赛中加入了模型,因此一些实施例还报告了不可使用测试集标签的该数据集版本的结果。在ImageNet上,通常报告两种错误率:top-1和top-5,其中,top-5错误率是测试图像的一部分,正确的标签不在模型认为最可能的五个标签中。ImageNet由可变分辨率图像组成,而系统需要恒定的输入维度。因此,一些实施例将图像降采样到256×256的固定分辨率。在给定矩形图像的情况下,一些实施例首先重新缩放图像,使得较短边具有长度256,然后从生成的图像中裁剪出中心的256×256块。除了从每个像素减去训练集上的平均活度之外,一些实施例没有以任何其他方式预处理图像。因此,一些实施例在像素的(居中)原始RGB(红-绿-蓝)值上训练网络。 将神经元的输出f作为其输入x的函数进行建模的标准方法是f(x)=tanh(x)or f(x)=(1+e 一些实施例防止过拟合,因此它们观察到的效果与一些实施例在使用ReLU时报告的拟合训练集的加速能力不同。更快的学习对在大型数据集上训练的大型模型的性能有很大影响。 一些实施例将网络扩展到两个GPU上。目前的GPU特别适合于跨GPU并行化,因为它们能够直接读取和写入对方的内存,而不需要经过主机内存。一些实施例采用的并行化方案基本上将一半的内核(或神经元)放在每个GPU上,还有一个额外的技巧:GPU仅在某些层中通信。这意味着,例如,第3层的内核从第2层的所有内核映射中获取输入。然而,第4层的内核仅从位于同一GPU上的第3层的内核映射中获取输入。选择连接模式是交叉验证的问题,但这允许我们精确地调整通信量,直到它是计算量的可接受部分。 ReLU具有理想的特性,即它们不需要输入归一化来防止饱和。如果至少有一些训练示例产生对ReLU正输入,则学习将在该神经元中发生。然而,一些实施例仍然发现以下局部归一化方案有助于归纳概括。用 其中,总和在同一空间位置的n个“相邻”内核映射上运行,N是层中内核的总数。内核映射的顺序当然是任意的,并在训练开始之前确定。这种反应归一化实现了一种受真实神经元类型启发的侧抑制,在使用不同内核计算的神经元输出中产生对大活动的竞争。常数k、n、α和β是超参数,其值使用验证集确定;一些实施例使用k=2,n=5,α=10 该方案与局部对比度归一化方案有一些相似之处,但我们的方案将被更准确地称为“亮度归一化”,因为一些实施例不减去平均活度。响应归一化将top-1和top-5的错误率分别降低1.4%和1.2%。一些实施例还验证了该方案在CIFAR-10数据集上的有效性:四层CNN在没有归一化的情况下实现了13%的测试错误率,在有归一化的情况下实现了11%的测试错误率。 神经网络中的池化层汇总了同一内核映射中相邻神经元组的输出。传统上,相邻池化单元汇总的邻域不重叠。更准确地说,池化层可以被认为是由间隔s个像素的池化单元网格组成的,每个池化单元汇总以池化单元位置为中心的大小为z×z的邻域。如果设置s=z,则一些实施例获得了通常在CNN中使用的传统局部池化。如果设置s<z,则一些实施例获得重叠池化。这是一些实施例在整个网络中使用的,其中s=2并且z=3。与产生等效维度输出的非重叠方案s=2,z=2相比,该方案将top-1和top-5的错误率分别降低0.4%和0.3%。一些实施例通常在训练过程中观察到,具有重叠池化的模型发现过拟合稍微困难一些。 网络包含八个具有权重的层;前五个层是卷积层,其余三个层是全连接层。最后一个全连接层的输出被馈送到1000路softmax,它产生了1,000个类别标签的分布。网络最大化了多项逻辑回归目标,这相当于最大化了预测分布下正确标签的对数概率的训练案例的平均值。 第二、第四和第五卷积层的内核仅被连接到位于同一GPU上的前一层中的内核映射(见图2)。第三卷积层的内核被连接到第二层中的所有内核映射。全连接层中的神经元与前一层中的所有神经元连接。响应归一化层遵循第一和第二卷积层。第3.4节所述类型的最大池化层遵循响应归一化层以及第五卷积层。ReLU非线性地被应用于每个卷积层和全连接层的输出。 第一卷积层使用96个大小为11×11×3的内核,以及4像素步长(这是内核映射中相邻神经元的感受野中心之间的距离)过滤224×224×3的输入图像。第二卷积层将第一卷积层的(响应归一化和池化的)输出作为输入,并使用256个大小为5×5×48的内核对输入进行过滤。第三、第四和第五卷积层彼此连接,无需任何中间的池化或归一化层。第三卷积层具有连接到第二卷积层的(归一化、池化的)输出的384个大小为3×3×256的内核。第四卷积层具有384个大小为3×3×192的内核,第五卷积层具有256个大小为3×3×192的内核。全连接层具有4096个神经元。 在一些实施例中,神经网络架构具有6,000万个参数。尽管ILSVRC的1,000个类别使每个训练示例对从图像到标签的映射施加了10位约束,但事实证明,这不足以在没有明显过拟合的情况下学习这么多参数。下面,一些实施例描述了这些实施例对抗过拟合的两种主要方式。 在一些实施例中,减少对图像数据的过拟合是使用标签保留变换人为地放大数据集。一些实施例采用两种不同的数据增强形式,这两种形式都允许以极小的计算量从原始图像生成变换图像,因此变换图像不需要存储在磁盘上。在一个示例实施方式中,当在前一批图像上训练GPU时,在CPU上以Python代码生成变换图像。在这些实施例中,这些数据增强方案实际上是无计算的。 第一数据增强形式包括生成图像平移和水平反射。一些实施例通过从256×256图像中提取随机的224×224块(及其水平反射)并在这些提取的块4上训练网络来实现这一点。这将训练集大小增加了2048倍,当然,尽管生成的训练示例是高度相互依赖的。如果没有该方案,网络会遭受严重的过拟合,这将迫使我们使用小很多的网络。在测试时,网络通过提取五个224×224块(四个角块和一个中心块)及其水平反射(因此总共十个块),并由网络的softmax层对十个块所做的预测进行平均来进行预测。 第二形式的数据增强包括改变训练图像中RGB通道的强度。具体地,一些实施例对整个ImageNet训练集的RGB像素值集执行PCA。对于每个训练图像,一些实施例添加多个找到的主分量,其幅度与对应的特征值乘以从均值为零且标准差为0.1的高斯函数中提取的随机变量成比例。因此,对于每个RGB图像像素 /> 其中,p 组合许多不同模型的预测是减少测试误差的非常成功的方法,但对于已经需要几天训练的大型神经网络来说似乎太昂贵。然而,存在一个非常有效的模型组合版本,在训练期间只需要大约两倍的费用。最近引入的被称为“dropout(丢弃)”的技术包括以0.5的概率将每个隐藏神经元的输出设置为零。以这种方式“丢弃”的神经元不参与正推法,也不参与后推法。因此,每次提供输入时,神经网络都会对不同的架构进行采样,但所有这些架构都共享权重。这种技术减少了神经元的复杂共适应,因为神经元不能依赖于特定其他神经元的存在。因此,它被迫学习与其他神经元的许多不同的随机子集结合使用的更稳健的特征。在测试时,一些实施例使用所有神经元,但将它们的输出乘以0.5,这是一个合理的近似值,以获取由指数级多个丢弃网络产生的预测分布的几何平均值。 一些实施例在图2的前两个全连接层中使用丢弃。在没有丢弃的情况下,网络表现出严重的过拟合。丢弃大约使得收敛所需的迭代次数翻倍。 一些实施例使用随机梯度下降训练模型,批大小为128个示例,动量为0.9,权重衰减为0.0005。一些实施例发现,这种少量的权重衰减对于模型学习是重要的。换言之,这里的权重衰减不仅仅是一个正则化器:它减少了模型的训练误差。权重w的更新规则为: 其中,i是迭代指数,v是动量变量,∈是学习率,并且 一些实施例用标准差为0.01的零均值高斯分布初始化了每个层中的权重。一些实施例使用常数1初始化了第二、第四和第五卷积层以及完全连接的隐藏层中的神经元偏置。该初始化通过向ReLU(修正线性单元)提供正输入来加速早期学习阶段。一些实施例使用常数0初始化了其余层中的神经元偏置。 一些实施例对所有层使用相同的学习率,一些实施例在整个训练过程中手动调整该学习率。一些实施例遵循的启发式是在验证错误率停止随着当前学习率而提高时,将学习率除以10。学习率初始化为0.01,并在终止前降低了三倍。一些实施例通过120万张图像的训练集将网络训练大约90个周期。 图13示出了一个或多个实施例中的关于图12A所示的高级框图的一部分的更多细节。更具体地,图13示出了关于在图12A的1206处通过使用深度学习模型对图像执行深度学习过程来生成深度学习结果的更多细节。在这些一个或多个实施例中,可以在1302处通过至少使用深度学习模型中的深度卷积神经网络(DCNN)来提取捕获的图像和/或搜索图像的区域中的特征(例如,顶点、边缘、表面等)或特征点(例如,与特征相关的点节点)。在这些实施例的一些中,除了DCNN之外,深度学习模型还可以包括图像配准过程。应当注意,除非彼此明确区分,否则术语“特征”和“特征点”可在整个公开中互换使用。 在1302处提取的特征或特征点可以在1304处转换为至少包括第一特征和第二特征的多个特征。在1306处,可以至少部分地基于第一特征对区域进行分类;并且在1308处,可以至少部分地基于第二特征确定区域的回归或校正。在一些实施例中,在1306处,可以仅基于第一特征而非基于第二特征对区域进行分类。附加地或替代地,其中,确定区域的回归至少部分地基于第二特征而非基于第一特征。 图14A示出了一个或多个实施例中的关于图12A所示的高级框图的另一部分的更多细节。更具体地,图14A示出了关于在图12A的1206处通过使用深度学习模型对图像执行深度学习过程来生成深度学习结果的更多细节。在这些一个或多个实施例中,可以在1402处使用DCNN来提取捕获的图像和/或搜索图像的区域中的特征或特征点。 在1402处提取的特征或特征点可以在1404处转换为至少包括第一特征和第二特征的多个特征。在1406处,可以至少通过使用DCNN中的一个或多个卷积层卷积第一特征(例如,将第二特征提供给DCNN中的一组卷积层)来生成第一响应映射。然后,在1408处,可以至少使用第一响应映射将该区域分类为正区域(例如,感兴趣的目标区域)或负区域(例如,可以忽略的非目标区域)。 还可以在1410处至少通过将第二特征与DCNN卷积来生成第二响应映射(例如,将第二特征提供给DCNN中的一组卷积层)。在1412处,可以至少使用第二响应映射来确定区域的回归或校正。在一些实施例中,可以在1414处至少使用图像配准过程来补偿深度卷积神经网络和/或包括DCNN的深度学习模型。在这些实施例的一些中,除了深度卷积神经网络(DCNN)之外,深度学习模型还可以包括图像配准过程。 在图13和/或14A所示的一些实施例中,深度卷积神经网络例如可以包括许多新的和不寻常的特征,这些特征提高了深度卷积网络的性能并减少了其训练时间,下面将更详细地描述这些特征。即使有120万个标记的训练示例,网络的规模也使过拟合成为了一个重要问题,因此一些实施例使用了以下更详细描述的几种有效技术来防止过拟合。最终的网络包括五个卷积层和三个全连接层,这一深度似乎很重要:会发现,去除任何卷积层(每个卷积层包含不超过1%的模型参数)会导致性能变差。 在一些实施例中,网络的大小主要受限于当前GPU上可用的内存量以及一些实施例可以容忍的训练时间量。网络需要五到六天的时间来训练两个GTX 580 3GB GPU。所有的实验表明,只要等待更快的GPU和更大的数据集可用,结果就会得到改善。 数据集: ImageNet是一个包含超过1500万张标记的高分辨率图像的数据集,这些图像属于大约22000个类别。这些图像是从网络上收集的,并由人类标签制作者使用Amazon的Mechanical Turk众包工具进行标记。从2010年开始,作为Pascal视觉对象挑战赛的一部分,每年举办一次名为ImageNet大规模视觉识别挑战赛(ILSVRC)的比赛。ILSVRC使用具有分别属于1,000个类别的大约1000张图像的ImageNet的子集。总共有大约120万张训练图像、50,000张验证图像和150,000张测试图像。 ILSVRC-2010是可使用测试集标签的ILSVRC的版本,因此这是一些实施例执行大部分实验的版本。由于一些实施例也在ILSVRC-2012比赛中加入了模型,因此一些实施例还报告了不可使用测试集标签的该数据集版本的结果。在ImageNet上,通常报告两种错误率:top-1和top-5,其中,top-5错误率是测试图像的一部分,正确的标签不在模型认为最可能的五个标签中。 ImageNet由可变分辨率图像组成,而示例系统需要恒定的输入维度。因此,一些实施例将图像降采样到256×256的固定分辨率。在给定矩形图像的情况下,一些实施例首先重新缩放图像,使得较短边具有长度256,然后从生成的图像中裁剪出中心的256×256块。除了从每个像素减去训练集上的平均活度之外,一些实施例没有以任何其他方式预处理图像。一些实施例在像素的(居中)原始RGB值上训练网络。 架构: 图2概述了网络的架构。它包含八个学习层—五个卷积层和三个全连接层。下面,一些实施例描述了网络架构的一些新颖或不寻常的特征。 ReLU非线性: 将神经元的输出f作为其输入x的函数进行建模的标准方法是f(x)=tanh(x)or f(x)=(1+e 一些实施例考虑CNN中传统神经元模型的替代。在一些实施例中,非线性f(x)=|tanh(x)|与其对比度归一化类型以及Caltech-101数据集上的局部平均池化一起使用时效果非常好。然后,在该数据集上,主要关注的是防止过拟合,因此它们观察到的效果与一些实施例在使用ReLU时报告的拟合训练集的加速能力不同。更快的学习对在大型数据集上训练的大型模型的性能有很大影响。 局部响应归一化: ReLU具有理想的特性,即它们不需要输入归一化来防止饱和。如果至少有一些训练示例产生对ReLU正输入,则学习将在该神经元中发生。然而,一些实施例仍然发现以下局部归一化方案有助于归纳概括。用 其中,总和在同一空间位置的n个“相邻”内核映射上运行,N是层中内核的总数。内核映射的顺序当然是任意的,并在训练开始之前确定。这种反应归一化实现了一种受真实神经元类型启发的侧抑制,在使用不同内核计算的神经元输出中产生对大活动的竞争。常数k、n、α和β是超参数,其值使用验证集确定;一些实施例使用k=2,n=5,α=10 本文所述的这些实施例可以更准确地称为“亮度归一化”,因为一些实施例不减去平均活度。响应归一化将top-1和top-5的错误率分别降低1.4%和1.2%。一些实施例还验证了该方案在CIFAR-10数据集上的有效性:四层CNN在没有归一化的情况下实现了13%的测试错误率,在有归一化的情况下实现了11%的测试错误率。 重叠池化: CNN中的池化层汇总了同一内核映射中相邻神经元组的输出。传统上,相邻池化单元汇总的邻域不重叠。更准确地说,池化层可以被认为是由间隔s个像素的池化单元网格组成的,每个池化单元汇总以池化单元位置为中心的大小为z×z的邻域。如果一些实施例设置s=z,则这些实施例可以获得通常在CNN中使用的传统局部池化。如果一些实施例设置s<z,则一些实施例获得重叠池化。这是一些实施例在整个网络中使用的,其中s=2并且z=3。与产生等效维度输出的非重叠方案s=2,z=2相比,该方案将top-1和top-5的错误率分别降低0.4%和0.3%。一些实施例通常在训练过程中观察到,具有重叠池化的模型发现过拟合稍微困难一些。 整体架构: 一些实施例将描述示例CNN的整体架构。如图2所示,网络包含八个具有权重的层;前五个层是卷积层,其余三个层是全连接层。最后一个全连接层的输出被馈送到1000路softmax,它产生了1,000个类别标签的分布。网络最大化了多项逻辑回归目标,这相当于最大化了预测分布下正确标签的对数概率的训练案例的平均值。 第二、第四和第五卷积层的内核仅被连接到位于同一GPU上的前一层中的内核映射(见图14B,该图示出了一个或多个实施例中的示例深度卷积神经网络)。第三卷积层的内核被连接到第二层中的所有内核映射。全连接层中的神经元与前一层中的所有神经元连接。响应归一化层遵循第一和第二卷积层。下面所述类型的最大池化层遵循响应归一化层以及第五卷积层。ReLU非线性地被应用于每个卷积层和全连接层的输出。 第一卷积层使用96个大小为11×11×3的内核,以及4像素步长(这是内核映射中相邻神经元的感受野中心之间的距离)过滤224×224×3的输入图像。第二卷积层将第一卷积层的(响应归一化和池化的)输出作为输入,并使用256个大小为5×5×48的内核对输入进行过滤。第三、第四和第五卷积层彼此连接,无需任何中间的池化或归一化层。第三卷积层具有连接到第二卷积层的(归一化、池化的)输出的384个大小为3×3×256的内核。第四卷积层具有384个大小为3×3×192的内核,第五卷积层具有256个大小为3×3×192的内核。全连接层分别具有4096个神经元。 减少过拟合: 示例神经网络架构具有6,000万个参数。尽管ILSVRC的1,000个类别使每个训练示例对从图像到标签的映射施加了10位约束,但事实证明,这不足以在没有明显过拟合的情况下学习这么多参数。下面,一些实施例描述了这些实施例对抗过拟合的两种主要方式。 数据增强 减少对图像数据的过拟合的一种方式是使用标签保留变换人为地放大数据集。一些实施例采用两种不同的数据增强形式,这两种形式都允许以极小的计算量从原始图像生成变换图像,因此变换图像不需要存储在磁盘上。在一个示例实施方式中,当在前一批图像上训练GPU时,在CPU上以Python代码生成变换图像。因此,这些数据增强方案实际上是无计算的。 第一数据增强形式包括生成图像平移和水平反射。一些实施例通过从256×256图像中提取随机的224×224块(及其水平反射)并在这些提取的块4上训练示例网络来实现这一点。这将示例训练集大小增加了2048倍,当然,尽管生成的训练示例是高度相互依赖的。如果没有该方案,示例网络会遭受严重的过拟合,这将迫使我们使用小很多的网络。在测试时,网络通过提取五个224×224块(四个角块和一个中心块)及其水平反射(因此总共十个块),并对网络的softmax层对十个块所做的预测进行平均来进行预测。 第二形式的数据增强包括改变训练图像中RGB通道的强度。具体地,一些实施例对整个ImageNet训练集的RGB像素值集执行PCA。对于每个训练图像,一些实施例添加多个找到的主分量,其幅度与对应的特征值乘以从均值为零且标准差为0.1的高斯函数中提取的随机变量成比例。因此,对于每个RGB图像像素 [P 在上述公式中,p 丢弃: 组合许多不同模型的预测是减少测试误差的非常成功的方法,但对于已经需要几天训练的大型神经网络来说似乎太昂贵。然而,存在一个非常有效的模型组合版本,在训练期间只需要大约两倍的费用。最近引入的被称为“dropout”的技术包括以0.5的概率将每个隐藏神经元的输出设置为零。以这种方式“丢弃”的神经元不参与正推法,也不参与后推法。因此,每次提供输入时,神经网络都会对不同的架构进行采样,但所有这些架构都共享权重。这种技术减少了神经元的复杂共适应,因为神经元不能依赖于特定其他神经元的存在。因此,它被迫学习与其他神经元的许多不同的随机子集结合使用的更稳健的特征。在测试时,一些实施例使用所有神经元,但将它们的输出乘以0.5,这是一个合理的近似值,以获取由指数级多个丢弃网络产生的预测分布的几何平均值。 一些实施例在图2的前两个全连接层中使用丢弃。在没有丢弃的情况下,网络表现出严重的过拟合。丢弃大约使得收敛所需的迭代次数翻倍。 虚拟的细节 一些实施例使用随机梯度下降训练模型,批大小为128个示例,动量为0.9,权重衰减为0.0005。一些实施例确定,这种少量的权重衰减对于模型学习是重要的。换言之,这里的权重衰减不仅仅是一个正则化器:它减少了模型的训练误差。权重w的更新规则为: 其中,i是迭代指数,v是动量变量,∈是学习率,并且 一些实施例用标准差为0.01的零均值高斯分布初始化了每个层中的权重。一些实施例使用常数1初始化了第二、第四和第五卷积层以及完全连接的隐藏层中的神经元偏置。该初始化通过向ReLU提供正输入来加速早期学习阶段。一些实施例使用常数0初始化了其余层中的神经元偏置。 一些实施例对所有层使用相同的学习率,这些实施例中的一些在整个训练过程中手动调整该学习率。一些实施例遵循的启发式是在验证错误率停止随着当前学习率而提高时,将学习率除以10。学习率初始化为0.01,并在终止前降低了三倍。一些实施例通过120万张图像的训练集将网络训练大约90个周期。 图15A示出了一个或多个实施例中的关于图12A所示的高级框图的另一部分的更多细节。更具体地,图15A示出了关于至少通过使用卡尔曼滤波器模型和上述深度学习结果执行图像配准处理来定位图像的更多细节。在这些一个或多个实施例中,可以在1502A处将深度学习过程和/或由深度学习过程生成的深度学习结果嵌入到状态转换模型中。在一些实施例中,状态转换模型至少部分地基于先前时间点的先前位置状态和状态估计模型的控制向量或过程噪声中的至少一个确定下一时间点的下一位置状态。在这些实施例的一些中,状态转换模型包括一阶状态估计模型。 状态转换模型示例如下: 在上述等式(1)中,X 可以在1504A处至少通过使用上面参考1502A描述的状态转换模型,在卡尔曼滤波器模型处接收由上述深度学习模型生成的深度学习结果作为一个或多个测量。在一些实施例中,卡尔曼滤波器模型能够通过使用嵌入了深度学习过程和/或深度学习结果的状态转换模型来接收深度学习结果。 可以在1506A处,通过在图像配准过程中至少使用卡尔曼滤波器模型来确定下一时间点的测量。在一些实施例中,可以将时间步长确定为两个紧邻帧之间的持续时间。例如,在30帧/秒的视频序列中,时间步长可以被确定为1/30秒。应当注意,在不同的实施例中可以使用其他一致的、固定的时间步长或甚至可变的时间步长。在一些实施例中,可以在1508A处,可以至少通过执行图像配准过程来减少捕获的图像和/或搜索图像中的相似背景和/或一个或多个相似特征的干扰。在一些实施例中,卡尔曼滤波器模型可以被配置为接收图像配准结果。附加地或替代地,卡尔曼滤波器模型可以包括线性模型(例如,线性马尔可夫模型或任何其他合适的模型)和加性高斯噪声。 在1510A处,可以通过至少使用卡尔曼滤波器模型和图像配准过程,将上述捕获的图像帧定位到搜索图像中或定位在搜索图像中。下面将参考图15B和15C描述关于一些上述动作的更多细节。 图15B示出了一个或多个实施例中的关于图15A的一部分的更多细节。更具体地,图15B示出了关于在图15A的1502A中将深度学习过程嵌入到状态转换模型中的更多细节。在这些一个或多个实施例中,可以在1502B处确定状态转换模型的一个或多个控制向量。在1504B处,可以从统计分布(例如但不限于零均值多变量正态分布)中导出过程噪声。 在1506B处,可以确定状态转换模型的时间步长。如上所述,在一些实施例中,时间步长可以确定为两个紧邻帧之间的持续时间,尽管还应当注意,在不同的实施例中可以使用其他一致的、固定的时间步长或甚至可变的时间步长。 在1508B处,状态转换模型可用于至少部分地基于在1504B处导出的过程噪声和/或在1502B处确定的一个或多个控制向量,至少通过使用一个或多个对应的先前时间点的一个或多个先前位置状态来确定一个或多个对应的下一时间点的一个或多个下一位置状态。上面参考图15A描述的示例状态转换模型允许将深度学习过程嵌入到卡尔曼滤波器模型中。 图15C示出了一个或多个实施例中的关于图15A的另一部分的更多细节。更具体地,图15B示出了关于在图15A的1510A处通过使用卡尔曼滤波器模型和图像配准过程来将图像定位在搜索图像中或定位到搜索图像的更多细节。在这些一个或多个实施例中,定位捕获的图像可以包括在1502C处对捕获的图像的整个帧执行粗略配准。在这些实施例的一些中,执行粗略配准包括在1506C处,在捕获的图像的整个帧中的一个或多个区域中检测一个或多个特征或特征点。 在这些实施例的一些中,执行粗略配准还可以包括检测(如果尚未对搜索图像执行粗略配准)或识别(如果已经对搜索图像执行粗略配准)搜索图像中的一个或多个区域中的一个或多个对应的特征或特征点。然后在1508C处,可以至少部分地基于从捕获图像检测到的一个或多个特征或特征点以及搜索图像中的一个或多个对应的特征或特征点将捕获图像配准到搜索图像。 粗略配准完成后,可以在1504C处对从捕获的图像中检测到的一个或多个特征或特征点中的至少一个和/或搜索图像中的一个或多个对应特征或特征中的至少一个执行精细配准。在一些实施例中,可以对图像的整个帧执行粗略配准,同时可以仅对一个或多个外环执行精细配准。在这些实施例中,使用卡尔曼滤波器模型进行具有外环配准的测量避免了重复计算特征或特征点。在这些实施例的一些中,深度学习模型包括卷积神经网络和图像配准过程;和 在一些实施例中,在1504C处,可以通过使用卡尔曼滤波器对该区域周围的外环区域中的至少一个特征或特征点执行精细配准。在这些实施例的一些中,执行精细配准可以包括在1510C处选择放大区域内的特征或特征点,该放大区域与上面参考1506C描述的用于粗略配准的区域相对应。使用放大区域可以提高定位过程的鲁棒性,特别是在粗略配准时匹配的特征或特征点更集中于内部区域或更靠近内侧的情况下(与更靠近一个或多个外环或以其他方式在搜索图像上分布的情况相反)。 然后可以将在1510C处选择的特征或特征点与搜索图像上外部区域中的对应特征或对应特征点进行比较。在其中搜索图像包括用户的视网膜的多个镶嵌基本图像的眼睛跟踪示例中,一些实施例在完成帧时将视网膜上的成像位置作为地面真值。因此,每一帧中的外环更接近地面真值。 关于卡尔曼滤波器模型,卡尔曼滤波器包括一组数学方程,该组方程提供了一种有效的计算(递归)方法,以最小化平方误差的平均值的方式估计过程的状态。该滤波器在几个方面都非常强大:它支持对过去、现在甚至未来状态的估计,即使在建模系统的精确性质未知的情况下也可以这样做。 离散卡尔曼滤波器: 卡尔曼滤波器解决了试图估计由线性随机差分方程控制的离散时间控制过程状态 x 其中,测量为 z 随机变量w p(w)~N(0,Q),(1.3) p(v)~N(0,R), (1.4) 在实践中,过程噪声协方差Q和测量噪声协方差R矩阵可能会随着每个时间步长或测量而改变,然而这里一些实施例假设它们是恒定的。 在没有驱动函数或过程噪声的情况下,差分方程(1.1)中的n×n矩阵A将前一时间步长k-1的状态与当前步长k的状态相关联。请注意,在实践中,A可能随着每个时间步长而改变,但这里的一些实施例假设它是恒定的。n×Z矩阵B将可选控制输入 一些实施例将 被定义为在给定测量zk的情况下,在步长k处的后验状态估计。一些实施例然后将先验估计误差和后验估计误差定义为 先验估计误差协方差为 并且后验估计误差协方差为 在导出卡尔曼滤波器的方程时,一些实施例的目标是找到一个方程,该方程将后验状态估计 (1.7)中的差 (1.7)中的n×m矩阵K被选择为使后验误差协方差(1.6)最小化的增益或混合因子。该最小化可通过以下方式实现:首先将(1.7)代入上述e 根据方程(1.8),当测量误差协方差R接近零时,增益K使残差的权重更大。具体地, 另一方面,随着先验估计误差协方差Pk接近零,增益K使残差的权重降低。具体地, 考虑K加权的另一方式是,随着测量误差协方差R接近零,实际测量z (1.7)的理由植根于基于所有先验测量z 后验状态估计(1.7)反映状态分布的均值(第一矩)-如果满足(1.3)和(1.4)的条件,则为正态分布。后验估计误差协方差(1.6)反映状态分布的方差(第二非中心矩)。换言之, 离散卡尔曼滤波器算法: 卡尔曼滤波器通过使用一种形式的反馈控制来估计过程:滤波器估计某个时间的过程状态,然后以(噪声)测量的形式获得反馈。因此,卡尔曼滤波器的方程分为两组:时间更新方程和测量更新方程。时间更新方程负责预测(在时间上)当前状态和误差协方差估计,以获得下一时间步长的先验估计。测量更新方程负责反馈,例如,将新的测量并入先验估计中,以获得改进的后验估计。 时间更新方程也可以被看作预测方程,而测量更新方程可以被看作校正方程。实际上,最终估计算法类似于用于解决数值问题的预测-校正算法,如下所示。 /> 时间更新和测量更新的具体方程如下表1-1和表1-2所示。 表1-1:离散卡尔曼滤波器时间更新方程 表1-2:离散卡尔曼滤波器测量更新方程 测量更新期间的第一项任务是计算卡尔曼增益K 在每个时间和测量更新对之后,使用用于预计或预测新的先验估计的先前的后验估计重复该过程。这种递归性质是卡尔曼滤波器的一个非常吸引人的特征,它使得实际实施方式比(例如)被设计为直接针对每个估计对所有数据进行操作的维纳滤波器的实施方式更可行。相反,卡尔曼滤波器递归地调节所有过去测量的当前估计。 滤波器参数和调整: 在滤波器的实际实施方式中,通常在滤波器操作之前测量测量噪声协方差R。测量测量误差协方差R一般来说是实际的(可能的),因为一些实施例无论如何都需要使能测量过程(同时操作滤波器),因此这些实施例通常应该能够进行一些离线采样测量,以便确定测量噪声的方差。 确定过程噪声协方差Q一般来说更困难,因为一些实施例通常不具有直接观察某些实施例正在估计的过程的能力。有时,如果经由选择Q向过程中“注入”足够的不确定性,则相对简单(较差)的过程模型可能会产生可接受的结果。当然,在这种情况下,人们希望过程测量是可靠的。 在任何一种情况下,无论某些实施例是否具有选择参数的合理依据,经常都是通过调整滤波器参数Q和R来获得优异的滤波器性能(从统计上讲)。在一般称为系统识别的过程中,如下所示,通常频繁地借助于另一(不同的)卡尔曼滤波器离线执行调整。 在Q和R实际上恒定的条件下,估计误差协方差Pk和卡尔曼增益K 然而,通常情况下,测量误差(具体地)不会保持恒定。例如,当看到光电跟踪器天花板面板(ceiling panel)中的信标时,附近信标的测量噪声将小于远处信标。此外,过程噪声Q有时在滤波器操作期间动态地变化(变为Q 扩展卡尔曼滤波器(EKF): 如上所述,卡尔曼滤波器解决了试图估计由线性随机差分方程控制的离散时间控制过程状态 但该过程现在由非线性随机差分方程控制 x 其中,测量为 z 其中,随机变量w 在实践中,人们当然不知道每个时间步长处的噪声w 以及 其中, 请注意,EKF的一个基本规律是,在经过相应的非线性变换后,各种随机变量的分布(或连续情况下的密度)不再是正态的。EKF只是一个临时状态估计器,它仅通过线性化逼近贝叶斯规则的最优性。Julier等人使用在整个非线性变换中保持正态分布的方法,在开发EKF的变体方面做了一些有趣的工作。 为了估计具有非线性差分和测量关系的过程,一些实施例首先编写线性化有关(2.3)和(2.4)的估计的新控制方程, 其中, ·x · · ·随机变量w ·A是f相对于x的偏导数的雅可比矩阵,即 ·W是f相对于w的偏导数的雅可比矩阵, ·H是h相对于x的偏导数的雅可比矩阵, ·V是h相对于v的偏导数的雅可比矩阵, 请注意,为了简化符号,一些实施例可能不使用雅可比矩阵A、W、H和V的时间步长下标k,即使它们实际上在每个时间步长处都不同。 一些实施例定义了预测误差的新符号, /> 以及测量残差, 请注意,在实践中,我们无法访问(2.7)中的x 其中,ε 请注意,方程(2.9)和(2.10)是线性的,它们与离散卡尔曼滤波器的差分和测量方程(1.1)和(1.2)非常相似。这促使我们使用(2.8)中的实际测量残差 (2.9)和(2.10)的随机变量近似具有以下概率分布: p(ε p(η 给定这些近似值,并设 通过将(2.12)代回(2.11)并使用(2.8),可能不需要或不使用第二(假设的)卡尔曼滤波器: 方程(2.13)现在可用于扩展卡尔曼滤波器中的测量更新,其中,ick和Z 完整的EKF方程组如下面在表2-1和表2-2中所示。请注意,一些实施例已经替换了ick,以保持与先前的“超减”先验符号一致,并且一些实施例可以将下标k附加到雅可比A、W、H和V,以加强它们在每个时间步长处不同(因此可以在每个时间步长处重新计算)的概念。 表2-1:EKF时间更新方程 /> 对于基本离散卡尔曼滤波器,表2-1中的时间更新方程根据先前的时间步长k-1处的状态和协方差估计预计时间步长k处的状态和协方差估计。同样,(2.14)中的f来自(2.3),Ak和W 表2-2:EKF测量更新方程 对于基本离散卡尔曼滤波器,表2-2中的测量更新方程使用测量z EKF的基本操作与线性离散卡尔曼滤波器相同,如下所示,提供了EKF操作的完整画面,将图1的高级图与表2-1和表2-2的方程结合在一起。 EKF的一个重要特征是卡尔曼增益K 估计随机常数的过程模型: 以下尝试估计标量随机常数,例如电压。一些实施例具有测量常数的能力,但是测量被0.1伏RMS(均方根)白测量噪声破坏(例如,模数转换器不是非常准确)。在该示例中,该过程由线性差分方程控制 /> 测量为 状态在步长之间没有变化,因此A=1。没有控制输入,因此u=0。噪声测量是直接的状态,因此H=1(请注意,这些实施例在几个地方丢弃了下标k,因为在这个简单模型中各个参数保持不变)。 滤波器方程和参数: 时间更新方程为 并且测量更新方程为 假设过程方差非常小,一些实施例可以在一些实施例中设Q=1e 类似地,一些实施例可以选择P 本文所述的各种实施例可以在头戴式显示器(HMD)(例如XR系统)或其他类型的系统(例如独立计算节点、具有多个计算节点的集群环境等)上实现。系统可以包括显示子系统(例如,投影仪或微型投影仪阵列),以向用户投射虚拟内容。图11A示出了一个或多个实施例中的微型投影仪阵列和将微型投影仪阵列与光学系统耦合的示例配置。更具体地,图11A示出了一个或多个实施例中的可操作地耦合到光学系统或XR设备的电子器件的示例架构2500。光学系统或XR设备本身或耦合到光学系统或XR设备的外部设备(例如,腰包)可以包括一个或多个印刷电路板部件,例如左(2502)和右(2504)印刷电路板组件(PCBA)。如图所示,左PCBA2502包括大部分有源电子器件,而右PCBA 604主要支撑显示器或投影仪元件。 右PCBA 2504可以包括多个投影仪驱动结构,这些投影仪驱动结构向图像生成部件提供图像信息和控制信号。例如,右PCBA 2504可以承载第一或左投影仪驱动结构2506和第二或右投影仪驱动结构2508。第一或左投影仪驱动结构2506连接第一或左投影仪光纤2510和一组信号线(例如,压电驱动线)。第二或右投影仪驱动结构2508连接第二或右投影仪光纤2512和一组信号线(例如,压电驱动线)。第一或左投影仪驱动结构2506通信地耦合到第一或左图像投影仪,而第二或右投影仪驱动结构2508通信地耦合到第二或右图像投影仪。 在操作中,图像投影仪经由相应的光学部件(例如波导和/或补偿透镜)将虚拟内容渲染给用户的左眼和右眼(例如视网膜),以改变与虚拟图像相关联的光。 图像投影仪例如可以包括左和右投影仪组件。投影仪组件可以使用多种不同的图像形成或生产技术,例如光纤扫描投影仪、液晶显示器(LCD)、LCOS(硅基液晶)显示器、数字光处理(DLP)显示器。在采用光纤扫描投影仪的情况下,图像可以沿着光纤传送,以经由光纤的尖端从光纤投影。此尖端可以取向为馈入波导。光纤的尖端可以投射图像,该尖端可以被支撑以弯曲或摆动。多个压电致动器可以控制尖端的摆动(例如,频率、幅度)。投影仪驱动结构向各自的光纤提供图像,并提供控制信号以控制压电致动器,从而将图像投影到用户的眼睛。 继续右PCBA 2504,按钮板连接器2514可以提供与携带各种用户可访问按钮、按键、开关或其他输入设备的按钮板2516的通信和物理耦合。右PCBA 2504可以包括右耳机或扬声器连接器2518,以将音频信号通信地耦合到头戴式部件的右耳机2520或扬声器。右PCBA 2504还可以包括右麦克风连接器2522以通信地耦合来自头戴式部件的麦克风的音频信号。右PCBA 2504还可以包括右遮挡驱动器连接器2524,以将遮挡信息通信地耦合到头戴式部件的右遮挡显示器2526。右PCBA 2504还可以包括板对板连接器以通过左PCBA 2502的板对板连接器2534提供与左PCBA2502的通信。 右PCBA 2504可以通信地耦合到一个或多个面向外部的或世界视图相机2528以及可选地耦合到右侧相机视觉指示器(例如LED),该相机由身体或头部穿戴,该指示器通过照射指示其他人何时捕获图像。右PCBA2504可以通信地耦合到一个或多个右眼相机2532,这些右眼相机由头戴式组件携带,被定位和取向为捕获右眼的图像,以允许跟踪、检测或监测右眼的取向和/或运动。可选地,右PCBA 2504可通信地耦合到一个或多个右眼照射源2530(例如,LED),如本文所解释的,右眼照射源2530以照射模式(例如,时间、空间)照射右眼,以促进跟踪、检测或监测右眼的取向和/或运动。 左PCBA 2502可以包括控制子系统,该控制子系统可以包括一个或多个控制器(例如,微控制器、微处理器、数字信号处理器、图形处理单元、中央处理单元、专用集成电路(ASIC)、现场可编程门阵列(FPGA)2540和/或可编程逻辑单元(PLU))。控制系统可以包括一个或多个存储可执行逻辑或指令和/或数据或信息的非暂时性计算机或处理器可读介质。非暂时性计算机或处理器可读介质可以采用多种形式,例如易失性和非易失性的形式,例如只读存储器(ROM)、随机存取存储器(RAM、DRAM、SD-RAM)、闪存等。非暂时性计算机或处理器可读介质可以被形成为例如微处理器、FPGA或ASIC的一个或多个寄存器。 左PCBA 2502可以包括左耳机或扬声器连接器2536,以将音频信号通信地耦合到头戴式部件的左耳机或扬声器2538。左PCBA 2502可以包括与驱动耳机或扬声器通信耦合的音频信号放大器(例如,立体声放大器)2542。左PCBA 2502还可以包括左麦克风连接器2544以通信地耦合来自头戴式部件的麦克风的音频信号。左PCBA 2502还可以包括左遮挡驱动器连接器2546以将遮挡信息通信地耦合到头戴式部件的左遮挡显示器2548。 左PCBA 2502还可以包括一个或多个传感器或换能器,它们检测、测量、捕获或以其他方式感测关于周围环境和/或关于用户的信息。例如,加速度换能器2550(例如,三轴加速度计)可以检测三个轴上的加速度,从而检测运动。陀螺仪传感器2552可以检测取向和/或磁或罗盘航向或取向。可以类似地使用其他传感器或换能器。 左PCBA 2502可以通信地耦合到一个或多个面朝外的或世界视图的左侧相机2524以及可选地耦合到左侧相机视觉指示器(例如LED)2556,该相机由身体或头部穿戴,该指示器通过照射指示其他人何时捕获图像。左PCBA可以通信地耦合到一个或多个左眼相机2558,这些左眼相机由头戴式部件携带,被定位和取向为捕获左眼的图像,以允许跟踪、检测或监测左眼的取向和/或运动。可选地,左PCBA 2502通信地耦合到一个或多个左眼照射源(例如,LED)2556,如本文所解释的,左眼照射源2556以照射模式(例如,时间、空间)照射左眼,以促进跟踪、检测或监测左眼的取向和/或运动。 PCBA 2502和2504经由一个或多个端口、连接器和/或路径与不同的计算部件(例如,腰包)通信地耦合。例如,左PCBA 2502可以包括一个或多个通信端口或连接器以提供与腰包的通信(例如,双向通信)。一个或多个通信端口或连接器还可以从腰包向左PCBA 2502供电。左PCBA2502可以包括功率调节电路2580(例如,DC/DC功率转换器、输入滤波器),其电耦合到通信端口或连接器,并可根据条件(例如,升压、降压、平滑电流、减少瞬变)操作。 通信端口或连接器例如可以采用数据和电源连接器或收发器2582(例如, 如图所示,左PCBA 2502包括大部分有源电子器件,而右PCBA 2504主要支持显示器或投影仪以及相关的压电驱动信号。跨光学系统或XR设备的身体或头戴式部件的前部、后部或顶部采用电和/或光纤连接。PCBA2502和2504通信地(例如,电学地、光学地)耦合到腰包。左PCBA 2502包括电源子系统和高速通信子系统。右PCBA 2504处理光纤显示压电驱动信号。在所示的实施例中,仅右PCBA 2504需要光学连接到腰包。在其他实施例中,右PCBA和左PCBA都可以连接到腰包。 虽然图示为采用两个PCBA 2502和2504,但身体或头戴式部件的电子器件可以采用其他架构。例如,一些实施方式可以使用更少或更多的PCBA。作为另一示例,各种部件或子系统可以以不同于图11A所示的方式布置。例如,在一些替代实施例中,不失一般性地,图11A中示出为驻留在一个PCBA上的一些部件可以位于另一PCBA上。 如本文参考例如图1所述,在一些实施例中,本文所述的光学系统或XR设备可以向用户呈现虚拟内容,使得虚拟内容可以被感知为三维内容。在一些其他实施例中,光学系统或XR设备可以将四维或五维光场(或光场)中的虚拟内容呈现给用户。 如图11B-C所示,光场生成子系统(例如,分别为1100C和1102C)优选地可操作以产生光场。例如,光学装置1160C或子系统可以产生或投射光以模拟由从真实的三维对象或场景反射的光产生的四维(4D)或五维(5D)光场。例如,在一些实施例中,诸如波导反射器阵列投影仪(WRAP)装置1110C或多深度平面三维(3D)显示系统之类的光学装置可以在相应的径向焦距处生成或投影多个虚拟深度平面以模拟4D或5D光场。在这些实施例中,光学系统或XR设备用作近眼光场发生器以及通过将输入图像解释为表示光场的4D函数的二维(2D)小片来用作4D或5D光场的显示器。需要指出,图11B-C示出了光学系统或XR设备,在一些实施例中,该光学系统或XR设备具有本文所述的光场生成子系统,或者在一些其他实施例中,该光学系统或XR设备具有将与多个深度平面相对应的光束投射到用户眼睛的立体虚拟内容生成子系统。 在一些实施例中,光学系统或XR设备利用基于图像的渲染向用户渲染虚拟内容的立体表示,基于图像的渲染通过一组预先获取或预先计算的影像生成虚拟内容的不同视图。通过使用例如环境地图、世界地图、拓扑地图(例如,具有点节点的地图,这些节点表示相应的位置和/或特征以及连接节点的边缘,并且表示连接的节点之间的一个或多个关系等)中的一种或多种,可以将虚拟内容混合或放置在观看虚拟内容的用户所在的环境中。在这些实施例中,光学系统或XR设备针对基于图像的渲染使用一种或多种显示或渲染算法,这些基于图像的渲染需要相对适度(例如,与生成相同虚拟内容的光场相比)的计算资源,尤其是在虚拟内容的实时实施方式中。此外,与所生成的虚拟内容交互的成本与虚拟内容的复杂性无关。此外,用于生成虚拟内容的图像源可以是真实的(例如,物理对象的照片或视频序列)或虚拟的(例如,来自一个或多个模型)。 这些以基于图像的渲染和一个或多个映射为基础的实施例可以基于一个或多个固定视点(例如,从中获取一组图像以渲染基于图像的虚拟内容的视点)。这些实施例中的一些使用深度值(例如,由深度传感器获取或通过诸如三角测量等之类定位技术计算的深度信息)通过视图插值来放宽固定视点限制。在这些实施例中,光学系统或XR设备使用深度信息(例如,图像中的较小像素子集或图像中的每个像素的深度数据)来解释视图,以便例如基于用户的位置、取向和/或注视方向在例如环境地图(例如,具有地图中的特征、点等的详细几何和/或地理信息的几何地图)中相对于用户重新投影点。 使用基于图像的渲染和一个或多个地图的一些其他实施例通过确定一对图像中的一个或多个对应点和/或对应关系来放宽固定视点限制,这些对应点和/或对应关系用于至少部分地基于捕获该对图像的一个或多个图像传感器的位置渲染虚拟内容。具有基于图像的渲染的两类实施例有效地生成和呈现可被观看用户感知为立体的虚拟内容,尽管可能存在例如不一定确定性地确定一个或多个图像对之间的对应关系的情况。 因此,一些其他实施例利用光学系统或XR设备生成4D或5D光场,而不是采用上述基于图像的渲染。光场可以使用5D函数(例如,5D全光函数)生成,并包括三维空间中给定方向上的点处的辐射。因此,一个光场可能包括定义一组空间角度图像的5D函数。在空间中坐标为(x,y,z)的点A处的辐射R沿方向D(φ,θ)传播的这些实施例中,可以具有R(x,y,z,φ,θ)的形式,其中φ具有范围[0,π],包括两个端点,并且θ具有范围[0,2π],也包括两个端点。在这种形式中,φ表示与由x轴和y轴定义的水平面的夹角;θ表示连接3D空间中的点和坐标系原点的矢量与参考单位矢量(例如,沿x轴的单位矢量)之间的角度。 在一些实施例中,辐射在介质(例如,诸如空气之类的透明介质)中是守恒的。由于辐射守恒,上述5D函数表现出一定量的冗余。在这些实施例中,当光学系统或XR设备在表面(例如,平面z=0)中创建5D函数时,上述表示光场的5D函数可以简化为4D函数R(x,y,φ,θ),并因此有效地将具有三个空间维度(x,y,z)和两个角度维度(φ,θ)的5D函数简化为具有两个空间维度(x,y)和两个角度维度(φ,θ)的4D函数。将光场函数的维数从5D函数简化为4D函数不仅可以加快虚拟内容的光场生成,而且可以节省计算资源。 在这些实施例中,本文所述的光学系统或XR设备通过使用上述4D函数(或者在更一般的光场技术应用中使用5D函数)计算虚拟内容的多个点的相应辐射生成并向用户呈现虚拟内容的光场。所计算的点的辐射(或辐射通量)包括由该点发射、反射、透射或接收的光的数据,并且可以基于每投影面积计算。点的辐射还可以包括频率和/或波长信息,并且具有方向性,因为辐射表示代表虚拟内容的一个点(例如,一个像素或一组像素)或一部分的点可以被光学系统或XR设备的用户感知成什么。可以使用任何技术计算辐射,例如通过点和方向参数化一条线(例如,从用户的眼睛到虚拟内容的一点的线),利用使用齐次坐标的一个或多个正投影图像或使用固定视场的一个或多个图像。例如,可以通过使用将虚拟内容的点和代表用户眼睛的点限制在相应的凸四边形内的光板技术以及通过虚拟内容的点(例如,虚拟内容的图像像素)和利用线性投影图(例如,3×3矩阵)表示用户眼睛的点之间的映射来确定点的辐射。 例如,光学系统或XR设备或电子器件(例如,上述腰包)可以通过渲染2D图像阵列来生成光板,其中每张图像表示固定平面上的4D光板的小片,并且通过执行与用于生成立体图像对的投影基本相似的剪切透视投影,将虚拟相机的投影中心放置在对应于该虚拟内容的点的样本位置来形成。在一些实施例中,光板可以由正投影视图的2D阵列形成。 为了经由光学系统或XR设备生成虚拟内容的光场表示并将其呈现给用户,光学系统或XR设备的透镜(例如,图11B中的1180C)可以包括一个或多个平面或自由形式波导的堆叠,其中,波导可以定义一个或多个不同的焦平面,这些焦平面分别对应于一个或多个不同焦距。在一些实施例中,一个或多个平面或自由形式波导的堆叠因此限定位于对应焦距处的多个焦平面。图像的2D小片可以在特定焦距处的焦平面上渲染,因此可以在多个焦平面上渲染一组2D小片以表示虚拟内容,然后该虚拟内容可以被光学系统或XR设备的用户感知为立体的。 在一些实施例中,波导可以包括与平面光波导的第一面相关联的正交光瞳扩展(OPE)元件,用于将耦入光束分成第一组正交子光束,并包括与平面光波导的第二面相关联的第二正交光瞳扩展(OPE)元件,用于将耦入光束分成第二组正交子光束。在一些实施例中,第一OPE元件被设置在平面光波导的第一面上,第二OPE元件被设置在平面光波导的第二面上。耦入元件可以被配置为将来自图像投影组件的准直光束光学耦合为耦入光束,以经由全内反射(TIR)沿着第一光学路径在平面光波导内传播,该第一光学路径交替地与第一OPE元件和第二OPE元件相交,使得耦入光束的各个部分被偏转为相应的第一组正交子光束和第二组正交子光束,这些子光束经由TIR沿着第二平行的光学路径在平面光波导内传播。在这种情况下,第二平行的光学路径可以与第一光学路径正交。 在一些实施例中,半反射界面被配置为将耦入光束分成至少两个耦入子光束。在这种情况下,一个或多个DOE包括正交光瞳扩展(OPE)元件,其被配置为将至少两个耦入子光束分别分成至少两组正交子光束,半反射界面还被配置为将至少两组正交子光束分成至少四组正交子光束,并且一个或多个DOE包括出瞳扩展(EPE)元件,其被配置为将至少四组正交子光束分成一组耦出子束。OPE元件和EPE元件可以设置在光平面波导的表面上。 在一些实施例中,波导可以包括与平面光波导相关联的出瞳扩展(EPE)元件,用于将正交子光束分成从平面光波导射出的耦出子光束阵列(例如,二维耦出子光束阵列)。准直光束可以限定入瞳,耦出子光束阵列可以限定比入瞳大的出瞳,例如,比入瞳大至少十倍,甚至比入瞳大至少一百倍。 在一些实施例中,EPE元件被设置在平面光波导的第一表面和第二表面之一上。第一组正交子光束和第二组正交子光束可以与EPE元件相交,使得第一组正交子光束和第二组正交子光束的部分被偏转为从平面光波导射出的耦出子光束阵列。在一些实施例中,EPE元件被配置为在从平面光波导射出的耦出光束阵列上赋予凸波前轮廓。在这种情况下,凸波前轮廓可以在焦点处具有半径中心,以在给定焦平面处产生图像。在另一实施例中,IC元件、OPE元件和EPE元件中的每一个都是衍射的。 虚拟图像生成系统还包括与平面光波导相关联的一个或多个衍射光学元件(DOE),用于进一步将多个初级子光束分成从平面光波导的一面射出的耦出子光束阵列(例如,二维耦出子光束阵列)。准直光束可以限定入瞳,耦出子光束阵列可以限定比入瞳大的出瞳,例如,比入瞳大至少十倍,甚至比入瞳大至少一百倍。在一些实施例中,选择主基板的第一厚度和次基板的第二厚度,使得耦出子光束中至少两个相邻子光束的中心之间的间距等于或小于准直光束的宽度。在另一实施例中,选择第一厚度和第二厚度,使得耦出子光束中的大于一半的相邻子光束的边缘之间不存在间隙。 在一些实施例中,半反射界面被配置为将耦入光束分成至少两个耦入子光束。在这种情况下,一个或多个DOE包括正交光瞳扩展(OPE)元件,其被配置为分别将至少两个耦入子光束分成至少两组正交子光束,半反射界面还被配置为将至少两组正交子光束分成至少四组正交子光束,并且一个或多个DOE包括出瞳扩展(EPE)元件,其被配置为将至少四组正交子光束分成一组耦出子光束。OPE元件和EPE元件可以被设置在光平面波导的表面上。 至少两个耦入子光束可以经由全内反射(TIR)沿着第一光学路径在平面光波导内传播,该第一光学路径与OPE元件相交,使得至少两个耦入子光束的各个部分被偏转为至少两组正交子光束,这些子光束经由TIR沿着第二平行的光学路径在平面光波导内传播。第二平行的光学路径可以与第一光学路径正交。至少两组正交子光束可以与EPE元件相交,使得至少两组正交子光束的各个部分作为耦出子光束组被衍射出平面光波导的表面。在一些实施例中,EPE元件可以被配置为在从平面光波导射出的耦出子束阵列上赋予凸波前轮廓。在这种情况下,凸波前轮廓可以在焦点处具有半径中心,以在给定焦平面处产生图像。 根据本公开的第三方面,一种虚像生成系统包括平面光波导,该平面光波导包括多个基板,其中包括具有第一厚度的主基板、分别具有至少一个第二厚度的至少一个次基板、以及分别设置于基板之间的至少一个半反射界面。 第一厚度是至少一个第二厚度中的每一个的至少两倍。在一些实施例中,第一厚度不是一个或多个第二厚度中的每一个的倍数。在另一实施例中,一个或多个次基板包括多个次基板。在这种情况下,第二厚度可以彼此相等,或者两个或更多个次基板可以具有彼此不相等的第二厚度。第一厚度可以不是至少一个第二厚度的倍数。不相等的第二厚度中的至少两个可以不是彼此的倍数。 在一些实施例中,一个或多个半反射界面中的每一个包括半反射涂层,其例如可以经由物理气相沉积(PVD)、离子辅助沉积(IAD)和离子束溅射(IBS)中的一种分别设置在基板之间。每个涂层例如可以由金属(Au、Al、Ag、Ni-Cr、Cr等)、电介质(氧化物、氟化物和硫化物)和半导体(Si、Ge)中的一种或多种组成。在又一实施例中,相邻的基板由具有不同折射率的材料组成。 虚拟图像生成系统还包括耦入(IC)元件,其被配置为光学耦合来自图像投影组件的准直光束,以在平面光波导内作为耦入光束传播。图像投影组件可以包括被配置为扫描准直光束的扫描设备。一个或多个半反射界面被配置为将耦入光束分成在主基板内传播的多个主子光束。 虚拟图像生成系统还包括与平面光波导相关联的一个或多个衍射光学元件(DOE),以进一步将多个主子光束分成从平面光波导的表面射出的耦出子束阵列(例如,二维耦出子束阵列)。准直光束可以限定入瞳,耦出子光束阵列可以限定比入瞳大的出瞳,例如,比入瞳大至少十倍,甚至比入瞳大至少一百倍。在一些实施例中,选择主基板的第一厚度和一个或多个次基板的一个或多个第二厚度,使得耦出子光束中至少两个相邻子光束的中心之间的间距等于或小于准直光束的宽度。在另一实施例中,选择第一厚度和一个或多个第二厚度,使得耦出子光束中的大于一半的相邻子光束的边缘之间不存在间隙。 在一些实施例中,一个或多个半反射界面被配置为将耦入光束分成至少两个耦入子光束。在这种情况下,一个或多个DOE包括正交光瞳扩展(OPE)元件,其被配置为分别将至少两个耦入子光束分成至少两组正交子光束,一个或多个半反射界面还被配置为将至少两组正交子光束分成至少四组正交子光束,并且一个或多个DOE包括出瞳扩展(EPE)元件,其被配置为将至少四组正交子光束分成一组耦出子光束。OPE元件和EPE元件可以被设置在光平面波导的表面上。 至少两个耦入子光束可以经由全内反射(TIR)沿着第一光学路径在平面光波导内传播,该第一光学路径与OPE元件相交,使得至少两个耦入子光束的各个部分被偏转为至少两组正交子光束,这些子光束经由TIR沿着第二平行的光学路径在平面光波导内传播。第二平行的光学路径可以与第一光学路径正交。至少两组正交子光束可以与EPE元件相交,使得至少两组正交子光束的各个部分作为耦出子光束组被衍射出平面光波导的表面。在一些实施例中,EPE元件可以被配置为在从平面光波导射出的耦出子光束阵列上赋予凸波前轮廓。在这种情况下,凸波前轮廓可以在焦点处具有半径中心,以在给定焦平面处产生图像。 根据本公开的第四方面,一种虚拟图像生成系统包括预扩瞳(PPE)元件,其被配置为接收来自成像元件的准直光束并将准直光束分成一组初始耦出子光束。虚像生成系统还包括:平面光波导;耦入(IC)元件,其被配置为将该组初始耦出子光束作为一组耦入子光束光学耦合到平面光波导中;以及与平面光波导相关联的一个或多个衍射元件,其用于将该组耦入子光束分成从平面光波导的一个面射出的一组最终耦出子光束。衍射元件可以包括与平面光波导相关联的正交光瞳扩展(OPE)元件,用于进一步将该组耦入子光束分成一组正交子光束,以及衍射元件包括与平面光波导相关联的出瞳扩展(EPE)元件,用于将该组正交子光束分成该组最终耦出子光束。 在一些实施例中,准直光束限定入瞳,该组初始耦出子光束限定比入瞳大的预扩瞳,并且该组最终耦出子光束限定比预扩瞳大的出瞳。在一个示例中,预扩瞳比入瞳至少大十倍,出瞳比预扩瞳大至少十倍。在一些实施例中,该组初始耦出子光束作为二维子光束阵列被光学耦合到平面光波导中,并且该组最终耦出子光束作为二维子光束阵列从平面光波导的表面射出。在另一实施例中,该组初始耦出子光束作为一维子光束阵列被光学耦合到平面光波导中,并且该组最终耦出子光束作为二维子光束阵列从平面光波导的表面射出。 在一些实施例中,PPE元件包括微型平面光波导、与微型平面光波导相关联的用于将准直光束分成一组初始正交子光束的微型OPE元件、以及与微型平面光波导相关联的用于将该组初始正交子光束分成从微型平面光波导的表面射出的该组初始耦出子光束的微型EPE元件。PPE还可以包括被配置为将准直光束光学耦合到平面光波导中的微型IC元件。 在另一实施例中,PPE元件包括:衍射分束器(例如,1x N分束器或M x N分束器),其被配置为将准直光束分成一组初始发散子光束;以及透镜(例如,衍射透镜),其被配置为将该组初始发散子光束重新准直成该组初始耦出子光束。 在又一实施例中,PPE元件包括棱镜(例如,实心棱镜或空腔棱镜),其被配置为将准直光束分成一组耦入子光束。棱镜可以包括半反射棱镜平面,其被配置为将准直光束分成该组耦入子光束。棱镜可以包括多个平行的棱镜平面,其被配置为将准直光束分成该组耦入子光束。在这种情况下,平行的棱镜平面可以包括半反射棱镜平面。多个平行的棱镜平面可以包括完全反射的棱镜平面,在这种情况下,准直光束的一部分可以被至少一个半反射棱镜沿第一方向反射,并且准直光束的一部分可以透射到完全反射的棱镜平面以沿第一方向反射。棱镜可以包括:第一组平行的棱镜平面,其被配置为将准直光束分成一组沿第一方向反射的初始正交子光束;以及第二组平行的棱镜平面,其被配置为将该组初始正交子光束分成该组耦入子光束,这些耦入子光束沿着不同于第一方向的第二方向反射。第一方向和第二方向可以彼此正交。 在又一实施例中,PPE元件包括:第一平面光波导组件,其被配置为将准直光束分成二维耦出子光束阵列(例如,N×N子束阵列),这些耦出子光束阵列从第一平面光波导组件的表面射出;以及第二平面光波导组件,其被配置为将二维耦出子光束阵列分成多个二维耦出子光束阵列,这些二维耦出子光束阵列作为该组耦入子光束从第二平面光波导组件的表面射出。第一平面光波导组件和第二平面光波导组件可以分别具有不相等的厚度。 二维耦出子光束阵列具有子束间间距,并且多个二维耦出子光束阵列在空间上相互错开一阵列间间距,该阵列间间距不同于二维耦出子光束阵列的子束间间距。在一些实施例中,多个二维耦出子光束阵列的阵列间间距与二维耦出子光束阵列的子束间间距互不为倍数。多个二维耦出子光束阵列的阵列间间距可以大于二维耦出子光束阵列的子束间间距。 在一些实施例中,第一平面光波导组件包括具有相对的第一表面和第二表面的第一平面光波导;第一耦入(IC)元件,其被配置为光耦合准直光束以经由全内反射(TIR)沿着第一光学路径在第一平面光波导内传播;与第一平面光波导相关联的第一出瞳扩展器(EPE)元件,其用于将准直光束分成从第一平面光波导的第二表面射出的一维子光束阵列;具有相对的第一表面和第二表面的第二平面光波导;第二IC元件,其被配置为光学耦合一维子光束阵列,以经由TIR沿着与第一光学路径垂直的相应的第二光学路径在第二平面光波导内传播;以及与第二平面光波导相关联的第二出瞳扩展器(EPE)元件,其用于将一维子光束阵列分成从第二平面光波导的第二表面射出的二维子光束阵列。在这种情况下,第二平面光波导的第一表面可以被附接到第一平面光波导的第二表面。第一平面光波导和第二平面光波导可以分别具有基本相等的厚度。 第二平面光波导组件可以包括具有相对的第一表面和第二表面的第三平面光波导;第三IC元件,其被配置为光耦合第一二维子光束阵列,以经由TIR沿着相应的第三光学路径在第三平面光波导内传播;与第三平面光波导相关联的第三EPE元件,其用于将二维子光束阵列分成从第三平面光波导的第二表面射出的多个二维子光束阵列;具有相对的第一表面和第二表面的第四平面光波导;第四IC元件,其被配置为光学耦合多个二维子光束阵列,以经由TIR沿着与第三光学路径垂直的相应的第四光学路径在第四平面光波导内传播;以及与第四平面光波导相关联的第四EPE元件,其用于将多个二维子光束阵列分成多个二维子光束阵列,这些子光束阵列作为输入的子光束组从第四平面光波导的第二标面射出。在这种情况下,第四平面光波导的第一表面可以被附接到第三平面光波导的第二表面,第三平面光波导的第一表面可以被附接到第二平面光波导的第二表面。第一平面光波导和第二平面光波导可以分别具有基本相等的厚度,第三平面光波导和第四平面光波导可以分别具有基本相等的厚度。在这种情况下,第一平面光波导和第二平面光波导的基本相等的厚度可以与第三平面光波导和第四平面光波导的基本相等的厚度不同。第三平面光波导和第四平面光波导的相等厚度可以大于第一平面光波导和第二平面光波导的相等厚度。 WRAP装置1110C或多深度平面3D显示系统形式的光学装置1160C例如可以直接或间接地将图像投影到用户的每只眼睛中。当虚拟深度平面的数量和径向位置与作为径向距离的函数的人类视觉系统的深度分辨率相当时,一组离散的投影深度平面模拟了由真实的连续三维对象或场景产生的心理物理效应。在一个或多个实施例中,系统1100C可以包括为每个AR用户定制的框架1170C。系统1100C的附加部件可以包括电子器件1130C(例如,图11A所示的一些或所有电子器件),以将AR系统的各种电气和电子子部件相互连接。 系统1100C还可以包括微型显示器1120C,其将与一个或多个虚拟图像相关联的光投射到波导棱镜1110C中。如图11B所示,从微型显示器1120C产生的光在波导1110C内行进,并且一些光到达用户的眼睛1190C。在一个或多个实施例中,系统1100C还可以包括一个或多个补偿透镜1180C以改变与虚拟图像相关联的光。图11C示出了与图11B相同的部件,但是示出了来自微型显示器1120C的光如何行进穿过波导1110C到达用户的眼睛1190C。 应当理解,光学装置1160C可以包括多个线性波导,每个线性波导具有嵌入、定位或形成在每个线性波导内的相应系列的解构弯曲球面反射器或反射镜。该系列的解构弯曲球面反射器或反射镜旨在将无限聚焦的光重新聚焦在特定的径向距离处。凸球面镜可用于产生输出球面波,以表示呈现为位于凸球面镜后面的限定距离处的虚拟点源。 通过在线性或矩形波导中将一系列具有形状(例如,围绕两个轴的曲率半径)和取向的微型反射器连接在一起,可以投影对应于由虚拟点源在特定x、y、z坐标处产生的球面波前的3D图像。每个2D波导或层提供相对于其他波导独立的光学路径,并对波前进行整形以及聚焦入射光以投射与相应径向距离相对应的虚拟深度平面。利用分别在不同焦深处提供焦平面的多个2D波导,观看投影的虚拟深度平面的用户可以体验3D效果。 说明性实施例和工作示例 已经开发了头戴式显示器(HMD),用于在3D虚拟和增强环境领域进行广泛应用。准确高速的眼睛跟踪对于实现HMD中的关键场景非常重要,例如,通过随中央凹变化(fovea-contingent)的显示方案和新颖人机交互界面实现的视场(FOV)和分辨率权衡。 嵌入HMD中的眼睛跟踪器可被分为侵入式方法(例如,巩膜线圈)和非侵入式基于视频的方法,后者更为常见。当前基于视频的方法主要使用眼球的不同特征,如虹膜、瞳孔和亮斑,其中,瞳孔亮斑方法应用最为广泛。这些方法的平均跟踪误差为0.5°-1.°,而这些特征的跟踪分辨率约为每像素0.7°-1.°。要进一步提高超过跟踪分辨率的精度并不容易。 除了使用眼表面的特征外,也可以将视网膜图像用于医学领域的眼睛跟踪,例如眼睛跟踪扫描激光检眼镜(SLO)。他们利用小FOV高分辨率图像中视网膜运动估计的扫描失真,然而,该技术专为小扫视而设计,并且SLO不容易被集成到HMD中。 HMD中基于视网膜的眼睛跟踪有其自身的优势:无需高级传感器、线性注视估计模型和视网膜中央凹的直接定位,即可获得更高的跟踪分辨率。此外,视网膜跟踪提供了HMD的广泛医疗应用。 各种实施例提出了一种用于基于对象运动视频的眼睛跟踪的实时视网膜定位方法,其中,每个帧被定位在镶嵌搜索图像上。图1示出了所提出的方法的示意图。在一些实施例中,本文所述的方法的新颖性在于使用卡尔曼滤波器106将一个或多个机器学习或一个或多个深度学习模型100的性能与一个或多个神经网络104和图像配准方法102相结合,其中,深度学习的结果用于构建状态转变模型,图像配准提供测量。 图6示出了在一些实施例中的视网膜的一些示例模板图像或基本图像602,其可以通过例如这里描述的扫描光纤内窥镜获得。例如,扫描光纤内窥镜(SFE)可以在各个时刻捕获多张基本图像或模板图像。基本图像或模板图像可以具有比例如从多个这样的较低分辨率和/或较窄FOV的基本图像和模板图像生成的搜索图像更低的分辨率和/或更窄的视场(FOV)。在一些实施例中,一旦构建了搜索图像,就可以相对于同一搜索图像而不是像一些常规方法中那样相对于多个图像来配准任何随后捕获的图像帧(例如,通过XR系统的眼睛跟踪设备捕获的图像帧)。尽管在一些其他实施例中,随后捕获的图像帧(例如,通过XR系统的眼睛跟踪设备捕获的图像帧)可以相对于本文所述的多个搜索图像进行配准。 在一些实施例中,该方法在合成数据以及通过扫描光纤内窥镜(SFE)成像的视网膜运动视频上验证。本文描述了数据集的细节及其挑战。使用视网膜视频,示例系统中的眼睛跟踪分辨率为0.05°/像素。在一些实施例中,视网膜定位方法当前达到0.68°的优化前平均误差,不考虑注释变化。与具有低跟踪分辨率的经典瞳孔亮斑方法相比,一些实施例大大提高了基于视网膜的眼睛跟踪的精度。 图5示出了一些实施例中的用于捕获视网膜的SFE图像的系统的简化示例。在这些实施例中,扫描光纤内窥镜(SFE)502可以通过一个或多个扫描光纤504发射扫描光束。SFE502可以通过遵循从扫描图案506的起点506A到终点506B的扫描图案506来扫描对象520(例如,视网膜)。反射光508可以通过SFE 502中的一个或多个返回光纤接收;并且反射光508可以被进一步处理以在显示器512上呈现扫描图像510(例如,视网膜的一张或多张基本图像或模板图像514)。在一些实施例中,本文所述的一些技术通过镶嵌多张基本或模板图像514来生成搜索图像516。 数据采集和特性 用于AR/VR的虚拟视网膜显示(视网膜扫描显示)已经被提出了很长时间。为了保持HMD系统的紧凑性,视网膜成像可以与视网膜扫描显示共享大部分光路。VRD将扫描显示直接绘制到视网膜上,因此使用具有扫描图案的SFE成像设备,因为它成本低且具有微型探针尖端。SFE具有从中心到外围的螺旋扫描图案,整个帧逐环成像。当目标移动时,在不同时间扫描的环来自不同的区域,这会在视频帧中产生移动失真。一些实施例在完成帧时将视网膜上的成像位置作为地面真值,因此每个帧中的外环更接近地面真值。 在数据收集时,一些实施例将视网膜幻像和激光指示器连接到机器人臂(Meca500)的尖端,以模拟视网膜运动,并将位置敏感检测器(PSD)用于实时记录激光束的位置。PSD数据可以是数据预处理后每个帧的注释。当前设置中的注释的平均误差为0.35°。图2中的图像202示出了捕获的视网膜帧的示例,图2中的图像204示出了来自一系列帧的镶嵌图像(例如202)。一些实施例可以从圆环形视盘看到图像具有运动失真。请注意,视网膜图像具有许多具有相似背景的区域,成像质量低,静止帧上存在局部失真,这增加了定位的难度。 示例流程: 给定大FOV镶嵌图像作为参考,一些实施例将捕获的SFE帧实时定位到搜索图像上,如图2所示。由于数据的挑战,一些实施例使用深度学习方法来导出用于分析的代表性深度特征。然而,神经网络具有不确定性,而且深度特征并不总是可靠的,因此使用图像配准方法来补偿深度学习的性能。另一方面,由于数据的挑战,图像配准的结果也具有噪声。如上所述,两个过程与卡尔曼滤波器相结合,其中深度学习结果被嵌入转换模型中,并且配准结果被作为卡尔曼滤波器中的测量。在一些实施例中,满足线性马尔可夫模型和加性高斯噪声的卡尔曼滤波器要求。在本节中,一些实施例分别介绍卡尔曼滤波器中的示例状态转换模型和测量的形式。 具有深度学习能力的状态转换模型 状态转换模型假设时间k处的真实状态是从时间k-1处的状态演变而来的。在所提出的方法中,转换模型形成如下: X 一些实施例中使用的深度学习框架是从孪生RPN修改而来的。在一些实施例中,首先使用Alexnet来提取帧和搜索图像的深度特征,然后利用卷积层将帧特征转换为两个不同的特征,分别用于分类和回归。通过帧和搜索图像特征的卷积来创建两个相应的响应图。一个响应图用于目标区域/非目标(正/负)区域分类,另一响应图预测每个正位置处的位置细化。与在孪生RPN中学习特定对象的鲁棒表示不同,一些实施例将不同的模板定位在同一搜索图像上。搜索图像的深度特征被保存并在训练过程之后重复使用。由于HMD中的成像比例不会发生很大变化,因此一些实施例关注x和y上的目标位置,而不是高度和宽度可调的边界框。 图7示出了一些实施例中的可用于实现本文所述的各种技术中的至少一些的示例深度学习模型。在图7所示的这些实施例中,可以从孪生RPN(候选区域生成网络)修改深度学习模型,以在AlexNet 705处接收图像帧702,AlexNet 705针对所接收的图像帧702生成特征图706(例如,具有6×6×256维度的帧的特征图)。特征图706可以分别提供给卷积710和712,卷积710和712进一步分别生成上采样数据(例如,710的第一输出,具有6×6×(256×2k)维度;712的第二输出,具有6×6×(256×4K)维度。第一输出和第二输出两者可以由算子710单独处理,这些算子710分别产生第一下采样输出(例如,第一输出,具有17×17×2K维度)和第二下采样输出(例如,第二输出,具有17×17×4K维度)。附加地或替代地,深度学习模块在算子710处提取搜索区域的特征图708(例如,提取具有6×6×256维度的特征图)。 具有外环配准的测量: 在卡尔曼滤波器中,在当前时间获得测量: 其中,z 如上所述,帧中的外环指示更准确的视网膜位置,而由于外环包含非常稀疏的特征,因此很难在全局范围内直接匹配外环。为了减少相似背景和外环配准的较少特征的干扰,图像配准包括两个步骤:整个帧的粗略配准和仅与外环的精细配准。在粗略定位中,一些实施例从两个图像中检测特征点,并将帧f配准到搜索图像上的对应区域f~。在外环配准中,选择搜索图像上f~周围放大区域内的特征点,并将它们与落入帧上外环区域中的特征点重新匹配。当粗略配准中匹配的特征点集中在内部区域时,使用放大区域提高了算法的鲁棒性。该方法还避免了特征点的重复计算。由于视网膜图像的挑战,卡尔曼滤波器的这种测量偶尔会中断,因此然后跟踪系统只能依靠深度神经工作,直到下一次成功配准。 例如,图4示出了一些实施例中的与常规瞳孔亮斑方法相比的示例性基于视网膜的跟踪的一些示例基准结果402。更具体地,常规瞳孔亮斑方法的跟踪误差通常落在0.5°-1°以内,而诸如本文所述的基于视网膜的跟踪方法提供0.68°的跟踪误差。此外,常规瞳孔亮斑方法的跟踪分辨率通常落在0.7°-1°/像素内,而诸如本文所述的基于视网膜的跟踪方法提供0.05°/像素的跟踪分辨率。 工作示例: 实验在两个数据集上进行:本文介绍的合成视网膜运动视频和SFE视频。一些实施例将所提出的跟踪方法的性能与仅使用深度学习的卡尔曼滤波器进行比较。 合成数据根据来自STARE项目的公共视网膜数据集STARE(视网膜结构分析)产生。一些实施例根据300张视网膜图像生成视网膜运动视频的总体36000帧作为深度学习的训练集,并根据15张视网膜图像生成4000帧作为测试集。一些实施例在测试视频帧上添加四个不同级别的图像退化以评估该方法的鲁棒性:1)均值为0,方差选自0.001-0.005的高斯噪声;2)分别为-10°~10°以及-5~5°的旋转和剪切角;03)从0.8到1.2的比例变化。退化水平在参数范围内均匀增加。表1显示,即使发生最大退化,上述方法也具有可接受的精度0.63°。 SFE视频的实验在一张视网膜图像上进行。一些实施例收集了总共7000帧用于训练和400帧用于测试。测试误差300概括为图3中的累积分布函数(CDF)。一些实施例可以看到在仅使用深度学习时具有超过5°的异常值。数据注释的精度如上所述约为0.35°,该方法的平均误差为0.68°,不包括注释的影响,而仅使用神经网络的平均误差为1.01°。使用Titan RTX的GPU,速度可以达到72fps。 一些实施例提出了用于HMD的基于视网膜的眼睛跟踪的应用,以及使用卡尔曼滤波器结合深度学习和图像配准的性能的新颖实时定位方法。在一些实施例中,这是在AR/VR头戴装置中嵌入视网膜跟踪并提供算法解决方案的第一次系统讨论。 使用来自不同用户视网膜的更大数据集,可以提高准确性。这里所示的细节仅作为示例,仅出于说明性地讨论本发明的优选实施例的目的,呈现这些细节是为了提供被认为是本发明各种实施例的原理和概念方面的最有用和最容易理解的描述。就此而言,并不试图显示比基本理解本发明所必需的细节更详细的结构细节,结合附图和/或示例进行的描述使本领域技术人员清楚本发明的几种形式如何在实践中体现。 图8示出了一些实施例中的机器人定位的简化工作示例。更具体地,图8示出机器人定位场景的示例,其中,框804示出机器人802的相机的当前FOV。例如,对于使用传感器映射的一个或多个房间或建筑物的已知完整地图,例如全景光学相机场景,可以通过例如将捕获的相机帧(例如804)匹配到图8所示的场景地图上来定位机器人。 图9示出了一些实施例中的在手术中定位显微镜或内窥镜的另一简化工作示例。更具体地,一些实施例可以被应用于在外科手术中定位观察组织的内窥镜902的显微镜。用显微镜或内窥镜成像的视频帧可以定位在人体组织(例如,定位帧904)的更大场景地图上。这些实施例可以帮助手术工具的路径规划。 图10A示出了一些实施例中的用于人脸或一个或两个眼睛跟踪的人脸或一个或两个眼睛定位的另一简化工作示例。更具体地,图10A示出了用于眼睛跟踪的一个或两个眼睛1004A的识别和跟踪和/或对象用户的人脸1002A的识别和跟踪。 图10B示出了一些实施例中的用于对象跟踪的对象定位的另一简化工作示例。更具体地,图10B示出了用于对象跟踪的汽车1002B(图10B中的车辆)的识别和跟踪。 图10C示出了一些实施例中的用于对象跟踪的对象定位的另一简化工作示例。更具体地,图10C示出了当被跟踪对象(例如,车辆1002C)没有太大变化时的一般跟踪任务。在一些实施例中,可以将对象作为要在每个场景中定位的模板,并且卡尔曼滤波器用于平衡神经网络和图像配准的性能。在一些实施例中,当对象的图像配准完全工作时,神经网络的跟踪精度可以提高到像素级。在这些实施例的一些中,当对象被扭曲或阻挡而导致图像配准失败时,跟踪将仅依赖于神经网络。 图16A-I示出了一个或多个实施例中的微型投影仪阵列和将微型投影仪阵列与光学系统耦合的示例配置。参考图16G,在离散波前显示配置中,多个入射子束11332中的每一个相对于眼睛1158穿过小出瞳11330。参考图16H,该组子束11332的子集11334可以用匹配的颜色和强度水平来驱动,以被感知为它们是同一较大尺寸射线的一部分(加粗的子组11334可以被视为“聚集束”)。在这种情况下,小束的子集彼此平行,表示来自光学无限远的准直聚集光束(例如来自远山的光)。眼睛被调节到光学无限远,使得小束的子集被眼睛的角膜和晶状体偏转,从而基本上全部落在视网膜的相同位置上并且被感知为包括单个聚焦像素。 图16I示出了表示从用户眼睛1158的视场右侧进入的聚集准直光束11336的小束的另一子集(如果从上方观看冠型平面图中的眼睛1158)。图16I示出了与图16H相同的元件,并且还包括表示聚集准直光束11336的小束的其他子集。同样,眼睛被显示为调节到无限远,使得小束落在视网膜的同一点上,并且像素被感知为聚焦。相反,如果选择了作为发散的扇形射线到达眼睛的小束的不同子集,则这些小束将不会落在视网膜的同一位置上(并且被视为聚焦),直到眼睛将调节移动到与该扇形射线的几何原点相匹配的近点。 关于小束与眼睛的解剖瞳孔的交叉点的图案(例如,出瞳的图案),交叉点可以被组织成诸如有效截面的六边形栅格或正方形栅格或其他二维阵列之类的配置。此外,还可以创建出瞳的三维阵列以及出瞳的时变阵列。 可以使用多种配置来创建离散的聚集波前,例如与观看光学器件的出瞳光学共轭地放置的微型显示器或微型投影仪阵列、耦合到直接视场基底(例如眼镜透镜)的微型显示器和微型投影仪阵列,使得它们直接将光投射到眼睛,无需额外的中间观看光学器件、连续空间光调制阵列技术或波导技术。 参考图16A,在一个实施例中,可以通过捆绑一组小型投影仪或显示单元(如扫描光纤显示器)来创建立体(例如,三维)或四维或五维光场。图16A示出了六边形栅格投影束11338,其例如可以创建直径为7mm的六边形阵列,其中每个光纤显示器输出子图像11340。如果这样的阵列具有放置在其前面的光学系统,例如透镜,使得阵列与眼睛的入瞳光学共轭地放置,则这将在眼睛的瞳孔处创建阵列的图像,如图16B所示,其基本上提供与图16G的实施例相同的光学布置。 此配置的每个小出瞳由束11338中的专用小显示器(如扫描光纤显示器)创建。光学上,在一些实施例中,整个六边形阵列11338似乎正好定位在解剖瞳孔1145中。这样的实施例可用于将不同的子图像驱动到眼睛的较大解剖入瞳1145内的不同小出瞳,包括具有多个入射角和与眼睛瞳孔的交叉点的小束超集。每个单独的投影仪或显示器可以用稍微不同的图像来驱动,从而可以创建子图像,这些子图像拉出(pull out)以不同的光强度和颜色驱动的不同的射线集。 在一个实施例中,可以创建严格的图像共轭,如在图16B的实施例中,其中阵列11338与瞳孔1145直接一对一映射。在另一变体中,可以改变阵列中的显示器和光学系统(图16B中的透镜11342)之间的间隔,使得代替接收阵列到眼睛瞳孔的共轭映射,眼睛瞳孔可以在某个另一距离处捕获来自阵列的光线。使用这样的构造,人们仍然可以获得光束的角度分集,通过该角度分集可以创建离散的聚集波前表示,但是关于如何驱动哪个射线以及以何种功率和强度驱动的数学原理可能会变得更加复杂(但另一方面,从观看光学角度来看,这样的构造可能被认为更简单)。光场图像捕获所涉及的数学原理可用于这些计算。 参考图16C,示出了另一光场创建实施例,其中微型显示器或微型投影仪的阵列11346可以被耦合到框架11344,例如眼镜框架。此配置可以位于眼睛1158的前方。所示配置是非共轭布置,其中在阵列11346的显示器(例如,扫描光纤显示器)和眼睛1158之间没有插入大型光学元件。人们可以想象一副眼镜,与这些眼镜耦合的是多个显示器,例如扫描光纤引擎,它们垂直于眼镜表面定位,并且都向内倾斜,使得它们指向用户的瞳孔。每个显示器可以被配置为创建表示小束超集的不同元件的一组射线。 通过此配置,在解剖瞳孔1145处,用户可以接收到与参考图16G讨论的实施例中接收到的结果类似的结果,其中用户瞳孔处的每个点都接收到来自不同显示器的带多个入射角和交叉点的射线。图16D示出了类似于图16C的非共轭配置,不同之处在于图16D的实施例具有反射表面11348,以便于将显示器阵列11346移动远离眼睛1158的视场,同时还允许通过反射表面1138观看现实世界11144。 提出了用于创建离散化聚集波前显示的角度分集的另一配置。为了优化此配置,可以将显示器的尺寸减小到最大值。可用作显示器的扫描光纤显示器可以具有1mm范围内的基线直径,但是外壳和投影透镜硬件的减小可以将这种显示器的直径减小到约0.5mm或更小,这对用户的影响不大。在光纤扫描显示器阵列的情况下,可通过将准直透镜(例如可以包括梯度折射率或“GRIN”透镜、常规弯曲透镜或衍射透镜)直接耦合到扫描光纤本身的尖端来实现另一尺寸缩小的几何优化。例如,参考图16E,GRIN(梯度折射率)透镜11354被示为熔接到单模光纤的端部。致动器11350(如压电致动器)可以被耦合到光纤11352,并且可以用于扫描光纤尖端。 在另一实施例中,可以使用光纤的弯曲抛光处理将光纤端部成形为半球形,以产生透镜效应。在另一实施例中,可以使用粘合剂将标准折射透镜耦合到每个光纤的端部。在另一实施例中,透镜可以由诸如环氧树脂之类的透光性聚合物材料或玻璃的小板制成。在另一实施例中,光纤的端部可以被熔化以产生实现透镜效应的弯曲表面。 图16F示出了一个实施例,其中显示器配置(例如,具有GRIN透镜的扫描光纤显示器,在图16E的特写视图中示出)可以通过单个透明基板11356耦合在一起,该单个透明基板优选地具有与光纤11352的包层紧密匹配的折射率,使得对于穿过所示组件观看外部世界而言,光纤本身基本不可见。应当理解,如果精确地完成了包层的折射率匹配,则较大的包层/外壳变得透明,并且只有直径优选地为约三(3)微米的小芯将阻碍观察。在一个实施例中,显示器的矩阵11358可以全部向内倾斜,使得它们指向用户的解剖瞳孔(在另一实施例中,它们可以保持彼此平行,但此构造的效率较低)。 如本文所用,除非另有说明,否则术语“一”和“一个”被视为“一个”、“至少一个”或“一个或多个”。除非上下文另有要求,否则本文使用的单数术语应包括复数,复数术语应包括单数。 除非上下文另有明确要求,否则在整个说明书和权利要求中,词语“comprise(包括)”、“comprising(包括)”等应在包含意义上解释,而不是在排他或穷举的意义上解释;也就是说,在“包括但不限于”的意义上解释。使用单数或复数的词语也分别包括复数和单数。此外,当在本申请中使用时,词语“此处”、“上文”和“下文”以及具有类似含义的词语应指本申请的通篇,而不是指本申请的任何特定部分。 本公开的实施例的描述并非旨在是穷举的或将本公开限于所公开的精确形式。尽管本文出于说明性目的描述了本公开的具体实施例和示例,但如相关领域技术人员将认识到的,在本公开的范围内可以进行各种等效修改。 本文引用的所有参考文献通过引用并入本文。如果需要,可以修改本公开的各方面,以采用上述参考文献和申请的系统、功能和概念来提供本公开的其他更多实施例。根据详细描述,可以对本公开进行这些和其他改变。 任何前述实施例的特定元件都可以与其他实施例中的元件组合或替换。此外,这些实施例的至少一些中可包括特定元件是可选的,其中其他实施例可以包括具体排除这些特定元件中的一个或多个的一个或多个实施例。此外,虽然已经在这些实施例的上下文中描述了与本公开的某些实施例相关联的优点,但是其他实施例也可以表现出这样的优点,并且并非所有实施例都必须表现出这样优点才能落在本公开的范围内。 应当理解,上述各种实施例的特征和方面可以组合以提供进一步的实施例。根据以上详细描述,可以对实施例进行这些和其他改变。一般而言,在以下权利要求中,所使用的术语不应被解释为将权利要求限制为说明书和权利要求中公开的特定实施例,而应被解释为包括所有可能的实施例以及这些权利要求享有权利的全部范围的等价物。 本文描述了本公开的各种示例实施例。以非限制性的方式参考这些示例。提供它们是为了说明本公开的更广泛适用的方面。在不背离本公开的真实精神和范围的情况下,可以对所描述的公开进行各种改变并且可以替换为等价物。此外,可以进行许多修改以使特定情况、材料、物质组成、过程、一个或多个过程动作或一个或多个步骤适应本公开的一个或多个目标、精神或范围。此外,如本领域技术人员将理解的,在此描述和图示的每个单独的变体都具有离散的部件和特征,它们可以容易地与其他几个实施例的任一实施例的特征分离或与其他几个实施例的任一实施例的特征相结合,而不背离本公开的范围或精神。所有这些修改都旨在落入与本公开相关联的权利要求的范围内。 本公开包括可以使用主题设备执行的方法。该方法可以包括提供这种合适的设备的动作。这种提供可以由最终用户执行。换言之,“提供”动作仅要求最终用户获得、访问、接近、定位、设置、激活、加电或以其他动作提供主题方法中的必要设备。在此列举的方法可以以逻辑上可能的所列举事件的任何顺序以及以所列举的事件顺序来执行。 本公开的示例方面,连同关于材料选择和制造的细节已经在上面阐述。至于本公开的其他细节,可以结合上面引用的专利和公开以及本领域技术人员通常已知或理解的来理解。对于本公开的基于方法的方面,就如通常或逻辑上采用的附加动作而言,这同样适用。 此外,虽然本公开已经参考可选地结合各种特征的几个示例进行了描述,但是本公开不限于关于本公开的每个变体所描述或指示的内容。在不背离本公开的真实精神和范围的情况下,可以对所描述的公开进行各种改变并且可以替换为等价物(无论是在本文中列举的还是为了简洁起见未包括在内)。此外,在提供数值范围的情况下,应当理解,该范围的上限和下限之间的每个中间值、以及所述范围内的任何其他所述的值或中间值都包含在本公开内。 此外,可以构想,所描述的本发明变体的任何可选特征可以独立地,或者与本文所述的任何一个或多个特征组合地阐述和要求保护。对单数项目的引用包括存在多个相同项目的可能性。更具体地,如在本文和与本文相关联的权利要求中使用的,单数形式“一”、“一个”、“所述”和“该”包括复数指示物,除非另有明确说明。换言之,冠词的使用允许上述描述以及与本公开相关联的权利要求中的“至少一个”主题项目。还应注意,可以起草此类权利要求以排除任何可选要素。因此,本声明旨在作为结合权利要求要素的叙述使用“唯一”、“仅”等之类排他性术语,或者使用“否定”限制的先行基础。 在不使用此类排他性术语的情况下,与本公开相关联的权利要求中的术语“包括”应允许包含任何附加要素—无论在此类权利要求中是否列举了给定数量的要素,或者,一个特征的添加可以被认为是改变了在这些权利要求中提出的要素的性质。除非本文特别定义,否则在此使用的所有技术和科学术语应被赋予尽可能广泛的普遍理解的含义,同时保持权利要求的有效性。 本公开的广度不限于所提供的示例和/或主题说明书,而是仅受限于与本公开相关联的权利要求语言的范围。 以上对所示实施例的描述并不旨在穷举或将实施例限制为所公开的精确形式。尽管本文出于说明性目的描述了特定实施例和示例,但是如相关领域的技术人员将认识到的,在不背离本公开的精神和范围的情况下可以进行各种等效修改。此处提供的各种实施例的教导可以应用于实现VR、AR、MR、XR或混合系统和/或采用用户界面的其他设备,不一定是上面一般描述的示例光学系统(12)。 例如,前述详细描述已经通过使用框图、示意图和示例阐述了设备和/或过程的各种实施例。就此类框图、示意图和示例包含一个或多个功能和/或操作而言,本领域技术人员将理解,可以通过各种硬件、软件、固件或它们的几乎任何组合单独和/或集体地实现此类框图、流程图或示例中的每个功能和/或操作。 在一个实施例中,本主题可以通过专用集成电路(ASIC)来实现。然而,本领域技术人员将认识到,本文公开的实施例全部或部分可以等效地在标准集成电路中实现为由一个或多个计算机执行的一个或多个计算机程序(例如,作为在一个或多个计算机系统上运行的一个或多个程序)、由一个或多个控制器(例如,微控制器)执行的一个或多个程序、由一个或多个处理器(例如,微处理器)执行的一个或多个程序、固件、或上述的几乎任何组合,并且将认识到,根据本公开的教导,设计电路和/或编写软件和/或固件的代码将完全在本领域普通技术人员的技能范围内。 当逻辑被实现为软件并存储在存储器中时,逻辑或信息可以存储在任何计算机可读介质上以供任何处理器相关系统或方法使用或与其结合使用。在本公开的上下文中,存储器是计算机可读介质,其是包含或存储计算机和/或处理器程序的电、磁、光或其他物理设备或装置。逻辑和/或信息可以体现在任何计算机可读介质中,以供指令执行系统、装置或设备使用或与其结合使用,例如基于计算机的系统、包含处理器的系统或可以从指令执行系统、装置或设备获取指令并执行与逻辑和/或信息相关联的指令的其他系统。 在本说明书的上下文中,“计算机可读介质”可以是可以存储与逻辑和/或信息相关联的程序以供指令执行系统、装置和/或设备使用或与其结合使用的任何元件。计算机可读介质可以是例如但不限于电、磁、光、电磁、红外线或半导体系统、装置或设备。计算机可读介质的更具体示例(未详尽列出)将包括以下项:便携式计算机软盘(磁盘、紧凑型闪存卡、安全数字等)、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(EPROM、EEPROM或闪存)、便携式光盘只读存储器(CDROM)、数字磁带和其他非暂时性介质。 在此描述的许多方法可以通过变体来执行。例如,许多方法可以包括附加动作,省略一些动作,和/或以不同于所示或描述的顺序执行动作。 可以组合上述各种实施例以提供进一步的实施例。只要不与本文的具体教导和定义不一致,所有美国专利、美国专利申请公开、美国专利申请、外国专利、外国专利申请和非专利公开均在本说明书中提及和/或在申请书资料表中列出。如果需要,可以修改实施例的各方面以采用各种专利、申请和公开的系统、电路和概念来提供更进一步的实施例。 根据以上详细描述,可以对实施例进行这些和其他改变。一般而言,在以下权利要求中,所使用的术语不应被解释为将权利要求限制为说明书和权利要求中公开的特定实施例,而应被解释为包括所有可能的实施例以及这些权利要求享有权利的全部范围的等价物。因此,权利要求不受本公开的限制。 此外,可以组合上述各种实施例以提供进一步的实施例。如果需要,可以修改实施例的方面以采用各种专利、申请和公开的概念来提供更进一步的实施例。 根据以上详细描述,可以对实施例进行这些和其他改变。一般而言,在以下权利要求中,所使用的术语不应被解释为将权利要求限制为说明书和权利要求中公开的特定实施例,而应被解释为包括所有可能的实施例以及这些权利要求享有权利的全部范围的等价物。因此,权利要求不受本公开的限制。
- 一种近眼显示系统及近眼显示器
- 一种近眼显示系统及眼镜式虚拟显示器
- 经由眼睛跟踪扩大有效眼动范围的近眼显示器
- 经由眼睛跟踪扩大有效眼动范围的近眼显示器