包含SIRPα突变体的融合蛋白
文献发布时间:2024-04-18 19:52:40
技术领域
本申请涉及生物医药领域,具体的涉及一种结合CD47和CLDN18.2的多功能融合蛋白,及其在治疗疾病和/或病症中的应用。
背景技术
CD47蛋白是一种跨膜糖蛋白,属于免疫球蛋白超家族成员,除正常组织细胞表达CD47以外,许多肿瘤细胞过度表达CD47。肿瘤细胞表面的CD47与巨噬细胞表面的SIRPα相结合会阻止巨噬细胞对肿瘤细胞的吞噬,这被视为肿瘤逃避机体免疫监视的一种机制。阻断CD47蛋白和SIRPα的相互作用,可抑制肿瘤增长。
紧密连接蛋白为表达于上皮及内皮中且形成决定紧密连接渗透性的细胞旁障壁及微孔的紧密连接膜蛋白家族。紧密连接蛋白18同型2(CLDN18.2),即紧密连接蛋白18蛋白的剪接变异体,为表达于短寿命经分化胃上皮细胞上的胃系抗原。在许多癌症中都能检测到紧密连接蛋白的表达失调,并且可能导致肿瘤发生和癌症侵袭。在胰腺导管腺癌、食道肿瘤、非小细胞肺癌、卵巢癌、胆管腺癌和胆管癌中,CLDN18.2的表达升高。
发明内容
本申请提供了一种双功能融合蛋白,其包含特异性结合CLDN18.2的部分和特异性结合CD47蛋白的部分。本申请所述的融合的蛋白能够有效抑制肿瘤或肿瘤细胞的生长和/或增殖。
一方面,本申请提供了一种融合蛋白,其包含:特异性结合CLDN18.2的第一结合域;以及特异性结合CD47蛋白的第二结合域;其中,所述第二结合域具有以下特性中的至少一项:(a)以4×10
在某些实施方式中,所述第二结合域包含人SIRPα变体1的突变体,所述突变体与SEQ ID NO:22的第33位至第149位氨基酸序列相比,包含一个或多个位置的氨基酸残基突变。
在某些实施方式中,所述融合蛋白中的所述突变体包含选自下组的一个或多个氨基酸位置处的氨基酸突变:L44、I61、V63、E77、Q82、K83、E84、V93、D95、L96、K98、N100、R107、G109和V132。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61和E77氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61和V132氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61和E84氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61、K83和E84氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61、G109和V132氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61、D95、L96、G109和V132氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含V93和R107氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含L44和I61氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含L44和E77氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含Q82、K83和E84氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含E77和V132氨基酸残基处的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体在选自下组的氨基酸残基处包含氨基酸突变:
(1)I61、V63、E77、E84、V93、L96、K98、N100和V132;
(2)I61、E77、Q82、K83和E84;
(3)I61、V63、K83、E84和V132;
(4)I61、E77、E84、R107和V132;
(5)I61、V63、E77、K83、E84和N100;
(6)I61、E77、Q82、K83、E84和R107;
(7)I61、E77、Q82、E84、V93、L96、N100、R107、G109和V132;
(8)I61、E77、Q82、K83、E84和V132;
(9)I61;
(10)I61、D95、L96、G109和V132;
(11)I61、D95、L96、K98、G109和V132;
(12)I61、E77、E84、V93、R107和V132;
(13)E77、L96、N100、G109和V132;
(14)I61、V63、Q82、E84、D95、L96、N100和V132;
(15)I61、E77、Q82、K83、E84、V93、D95、L96、K98、N100和V132;
(16)I61、E77、Q82、K83、E84和V93;
(17)I61、V63、E77、K83、E84、D95、L96、K98和N100;
(18)I61、V63、E77、K83、D95、L96、K98、N100和G109;
(19)I61、E77、Q82、E84、V93、D95、L96、K98和N100;
(20)I61、V63、E77、Q82和E84;以及
(21)L44、I61、E77、Q82、K83、E84和V132。
在某些实施方式中,所述融合蛋白中的所述突变体包含选自下组的一个或多个氨基酸取代:L44V、I61L/V/F、V63I、E77I/N/Q/K/H/M/R/V/L、Q82S/R/G/N、K83R、E84Q/K/H/D/R/G、V93L/A、D95H/R/E、L96S/T、K98R、N100G/K/D/E、R107N/S、G109R/H和V132L/R/I/S。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61L/V/F和E77Q/N/I的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61L/V/F和V132I/S的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61L/V/F、K83R和E84Q/D/H的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61L/V/F、G109H和V132I/S的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含I61L/V/F、D95H、L96S、G109H和V132I/S的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含V93A和R107N的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含L44V和I61L/V/F的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含L44V和E77Q/N/I的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含Q82S/R/G/N、K83R和E84Q/K/H/D/R/G的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含E77Q/N/I和V132I/S的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含选自下组的氨基酸突变:
(1)I61L、V63I、E77I、E84K、V93L、L96S、K98R、N100G和V132L;
(2)I61V、E77N、Q82S、K83R和E84H;
(3)I61F、V63I、K83R、E84K和V132I;
(4)I61L、E77Q、E84D、R107N和V132I;
(5)I61L、V63I、E77K、K83R、E84D和N100G;
(6)I61V、E77H、Q82R、K83R、E84H和R107S;
(7)I61L、E77I、Q82G、E84R、V93L、L96T、N100G、R107S、G109R和V132R;
(8)I61L、E77M、Q82G、K83R、E84D和V132L;
(9)I61L;
(10)I61F、D95H、L96S、G109H和V132S;
(11)I61F、D95H、L96S、K98R、G109H和V132S;
(12)I61L、E77Q、E84D、V93A、R107N和V132I;
(13)E77K、L96S、N100K、G109H和V132L;
(14)I61L、V63I、Q82G、E84G、D95R、L96S、N100D和V132I;
(15)I61L、E77R、Q82N、K83R、E84G、V93L、D95E、L96T、K98R、N100D和
V132L;
(16)I61V、E77N、Q82S、K83R、E84H和V93A;
(17)I61V、V63I、E77V、K83R、E84D、D95E、L96T、K98R和N100E;
(18)I61L、V63I、E77V、K83R、D95E、L96S、K98R、N100D和G109R;
(19)I61V、E77L、Q82G、E84G、V93L、D95E、L96T、K98R和N100G;
(20)I61L、V63I、E77N、Q82G和E84G;以及
(21)L44V、I61F、E77I、Q82R、K83R、E84Q和V132I。
在某些实施方式中,所述融合蛋白中的所述突变体还包含一个或多个糖基化位点改造。
在某些实施方式中,所述糖基化位点改造包含糖基化位点突变。
在某些实施方式中,所述糖基化位点突变位于N110位置处。
在某些实施方式中,所述糖基化突变包含N110A的氨基酸取代。
在某些实施方式中,所述融合蛋白中的所述突变体包含SEQ ID NO:1-21中任一项所示的氨基酸序列。
在某些实施方式中,所述融合蛋白的第一结合域包含靶向CLDN18.2的抗原结合蛋白。
在某些实施方式中,所述抗原结合蛋白包含抗体或其抗原结合片段。
在某些实施方式中,所述抗体选自下组:单克隆抗体、单链抗体、嵌合抗体、人源化抗体和全人源抗体。
在某些实施方式中,所述抗原结合片段选自下组:Fab,Fab’,F(ab)2,dAb,分离的互补决定区CDR,Fv和scFv。
在某些实施方式中,所述CLDN18.2包含人CLDN18.2。
在某些实施方式中,所述第一结合域包含重链可变区(VH)中的至少一个CDR,所述VH包含SEQ ID NO:24所示的氨基酸序列。
在某些实施方式中,所述第一结合域包含HCDR3,所述HCDR3包含SEQ ID NO:25所示的氨基酸序列。
在某些实施方式中,所述第一结合域包含HCDR2,所述HCDR2包含SEQ ID NO:26所示的氨基酸序列。
在某些实施方式中,所述第一结合域包含HCDR1,所述HCDR1包含SEQ ID NO:27所示的氨基酸序列。
在某些实施方式中,所述第一结合域包含VH,所述VH包含SEQ ID NO:24所示的氨基酸序列。
在某些实施方式中,所述第一结合域包含免疫球蛋白单可变结构域。
在某些实施方式中,所述免疫球蛋白单可变结构域包含V
在某些实施方式中,所述融合蛋白中的所述第一结合域包含V
在某些实施方式中,所述V
在某些实施方式中,所述V
在某些实施方式中,所述V
在某些实施方式中,所述V
在某些实施方式中,所述第一结合域包含重链恒定区Fc片段。
在某些实施方式中,所述重链恒定区源自IgG。
在某些实施方式中,所述重链恒定区源自人IgG。
在某些实施方式中,所述IgG选自下组:IgG1和IgG4。
在某些实施方式中,所述重链恒定区Fc片段包含SEQ ID NO:28的氨基酸序列。
在某些实施方式中,所述融合蛋白的第一结合域位于所述第二结合域的N端。
在某些实施方式中,所述融合蛋白还包含连接子,所述连接子位于所述第一结合域的C端且位于所述第二结合域的N端。
在某些实施方式中,所述连接子包含如SEQ ID NO:24所示的氨基酸序列。
在某些实施方式中,所述融合蛋白包含至少2个所述第二结合域。
在某些实施方式中,所述融合蛋白的每个所述第二结合域分别位于所述第一结合域的C端。
在某些实施方式中,所述融合蛋白包含至少一条多肽链,其中所述多肽链包含SEQID NO:30-35中任一项所示的氨基酸序列。
在某些实施方式中,所述融合蛋白包含两条多肽链,每条多肽链包含SEQ ID NO:30-35中任一项所示的氨基酸序列。
另一方面,本申请还提供了一种免疫缀合物,其包含所述融合蛋白。
另一方面,本申请还提供了一个或多个核酸分子,其编码所述融合蛋白或所述免疫缀合物。
另一方面,本申请还提供了所述一种载体,其包含所述核酸分子。
另一方面,本申请还提供了所述药物组合物,其包含所述融合蛋白、所述免疫缀合物、所述核酸分子、以及任选地药学上可接受的载剂。
另一方面,本申请还提供了细胞,其包含所述融合蛋白、所述免疫缀合物、所述核酸分子或所述载体。
另一方面,本申请还提供了制备所述融合蛋白的方法,其包括在使得所述融合蛋白能够表达的条件下培养所述的细胞。
另一方面,本申请还提供了所述融合蛋白、所述免疫缀合物、所述核酸分子、所述载体、所述药物组合物、所述细胞在制备药物中的用途,所述药物用于预防和/或治疗疾病和/或病症。
在某些实施方式中,所述疾病和/或病症包含与CLDN18.2相关的疾病和/或病症。
在某些实施方式中,所述与CLDN18.2相关的疾病和/或病症包括涉及表达CLDN18.2的细胞的疾病或与表达CLDN18.2的细胞相关的疾病。
在某些实施方式中,所述疾病和/或病症包括肿瘤。
在某些实施方式中,所述肿瘤包括实体瘤和/或非实体瘤。
在某些实施方式中,所述肿瘤包括胃癌、食道癌、胰腺癌、肺癌、卵巢癌、结肠癌、肝癌、头颈癌和/或胆囊癌。
本领域技术人员能够从下文的详细描述中容易地洞察到本申请的其它方面和优势。下文的详细描述中仅显示和描述了本申请的示例性实施方式。如本领域技术人员将认识到的,本申请的内容使得本领域技术人员能够对所公开的具体实施方式进行改动而不脱离本申请所涉及发明的精神和范围。相应地,本申请的附图和说明书中的描述仅仅是示例性的,而非为限制性的。
附图说明
本申请所涉及的发明的具体特征如所附权利要求书所显示。通过参考下文中详细描述的示例性实施方式和附图能够更好地理解本申请所涉及发明的特点和优势。对附图简要说明如下:
图1显示的是本申请所述融合蛋白的结构示例。
图2显示的是本申请所述融合蛋白与CD47的结合结果。
图3A-图3B显示的是本申请所述融合蛋白与Raji细胞的结合结果。
图4显示的是本申请所述融合蛋白与293T/CLDN18.2细胞的结合结果。
图5显示的是本申请所述融合蛋白阻断CD47/SIRPα相互作用的结果。
图6显示的是本申请所述融合蛋白的ADCC活性检测。
图7A-图7B显示的是本申请所述融合蛋白与红细胞结合活性检测。
图8显示的是治疗开始后小鼠293T/CLDN18.2细胞异体移植模型的生长曲线。
具体实施方式
以下由特定的具体实施例说明本申请发明的实施方式,本领域技术人员可由本说明书所公开的内容容易地了解本申请发明的其他优点及效果。
术语定义
在本申请中,术语“融合蛋白”通常指由两个或更多个连接在一起的部分的多肽或蛋白。其中每个部分可以是具有不同特性的多肽或蛋白。该特性可以是生物学性质,例如体外或体内活性。该性质也可以是简单的化学或物理性质,例如与靶分子的结合,反应的催化等。这两个部分可以通过单个肽键或通过肽接头直接连接。融合蛋白可通过重组DNA技术人工制备。例如,编码所述两个或更多个蛋白或多肽的基因或核酸分子可彼此连接而形成融合基因或融合的核酸分子,该融合基因或融合的核酸分子可编码所述融合蛋白。所述融合基因的翻译可以产生单一多肽,其可以具有融合前的所述两个或更多个蛋白或多肽中至少一个、甚至每一个的性质。
在本申请中,术语“特异性结合”或“特异性的”通常指可测量的和可再现的相互作用,例如靶标和抗体之间的结合,可在分子(包括生物分子)的异质群体存在的情况决定靶标的存在。例如,特异性结合靶标(其可以为表位)的抗体可以是以比它结合其它靶标更大的亲和性、亲合力、更容易、和/或以更大的持续时间结合该靶标的抗体。在某些实施方案中,抗体特异性结合蛋白质上的表位,所述表位在不同种属的蛋白质中是保守的。在某些实施方案中,特异性结合包括但不要求排他性地结合。
在本申请中,术语“结合域”通常是可以特异性结合和/或识别靶标(例如抗原)上的特定表位的结构域。在本申请中,术语“结构域”通常是指蛋白质亚基结构中明显分开的紧密球状结构区域。例如,多肽链首先可以是在某些区域相邻的氨基酸残基形成有规则的二级结构,然后,又可以由相邻的二级结构片段组装在一起形成超二级结构,在此基础上多肽链可以折叠成近似于球状的三级结构。对于较大的蛋白质分子或亚基,多肽链往往可以由两个或多个在空间上可明显区分的、相对独立的区域性结构缔合而成三级结构,这种相对独立的区域性结构可以称为结构域。
在本申请中,术语“第一结合域”和“第二结合域”中的所述“第一”、“第二”可以只是为了在描述上进行区分。
在本申请中,术语“CD47蛋白”通常是指整联蛋白相关蛋白(IAP),其为一种属于免疫球蛋白超家族的多次跨膜受体。例如,CD47蛋白可与膜整合素(membrane integrins)结合,并与其配体凝血栓蛋白-1(thrombospondin-1,TSP-1)和信号调节蛋白α(signal-regulatory protein alpha,SIRPα)结合。CD47蛋白广泛表达于细胞膜表面。在本申请中,所述CD47蛋白可包括人CD47的任何变体、同种型和物种同系物。人CD47蛋白的氨基酸序列在GenBank中作为CEJ95640.1列出。所述CD47蛋白可以由细胞天然表达或在用CD47基因转染的细胞上表达。
在本申请中,术语“SIRPα”通常是指来自SIRP家族的调节性膜糖蛋白,其可作为CD47蛋白的配体。在本申请中,所述SIRPα可包括人SIRPα。
在本申请中,术语“人SIRPα结构域”通常是指野生型、内源的成熟形式的人SIRPα、其片段或功能性变体。在人类中,发现SIRPα蛋白主要有两种形式,一种形式(变体1或V1型)的氨基酸序列作为NCBI RefSeq NP_542970.1列出(残基31-504构成成熟型)。另一种形式(变体2或V2型)与所述变体1或V1型有13个氨基酸不同并且氨基酸序列在GenBank中作为CAA71403.1列出。这种两种形式的SIRPα构成了存在于人类中的大约80%的各种类型的SIRPα。在本申请中,术语“抗原结合蛋白”通常指脱离了其天然存在状态的具有抗原结合能力的蛋白。该“分离的抗原结合蛋白”可以包含结合抗原的部分和任选地,允许抗原结合部分采用促进所述抗原结合部分结合抗原的构象的框架或构架部分。抗原结合蛋白可以包含例如抗体来源的蛋白框架区(FR)或具有移植的CDR或CDR衍生物的备选蛋白框架区或人工框架区。此类框架包括,但不限于包含被引入例如以稳定抗原结合蛋白的三维结构的突变的抗体来源的框架区以及包含例如生物相容性聚合物的完全合成的框架区。
在本申请中,术语“CDR”也称“互补决定区”,通常指抗体可变结构域中的区域,其序列是高度可变的和/或形成结构定义环。通常,抗体包括六个CDR;在VH中三个(HCDR1、HCDR2、HCDR3),和在VL中三个(LCDR1、LCDR2、LCDR3)。在某些实施方案中,仅由重链组成的天然存在的骆驼抗体在缺乏轻链的情况下,其功能也能够正常且稳定。参见,例如,Hamers-Casterman et al.,Nature 363:446-448(1993);Sheriff et al,Nature Struct.Biol.3:733-736(1996)。抗体CDR可以通过多种编码系统来确定,如CCG、Kabat、AbM、Chothia、IMGT、综合考虑Kabat/Chothia等。这些编码系统为本领域内已知,具体可参见,例如,http://www.bioinf.org.uk/abs/index.html#kabatnum。
在本申请中,术语“可变结构域”与“可变区”可以互换使用,通常指抗体重链和/或轻链的一部分。重链和轻链的可变结构域可以分别称为“V
在本申请中,术语“抗体”通常指免疫球蛋白或其片段或其衍生物,涵盖包括抗原结合位点的任何多肽,无论其是在体外还是体内产生的。该术语包括但不限于多克隆的、单克隆的、单特异性的、多特异性的、非特异性的、人源化的、单链的、嵌合的、合成的、重组的、杂化的、突变的和移植的抗体。除非另外被术语“完整的”修饰,如在“完整的抗体”中,为了本发明的目的,术语“抗体”也包括抗体片段,比如Fab、F(ab')
在本申请中,术语“抗原结合片段”通常指具有特异结合抗原(例如,CLDN18.2)能力的一个或多个片段。在本申请中,所述抗原结合片段可以包括Fab,Fab’,F(ab)
在本申请中,术语“Fab”通常指抗体的抗原结合片段。如上所述,可以使用木瓜蛋白酶消化完整的抗体。抗体经木瓜蛋白酶消化后产生两个相同的抗原结合片段,即“Fab”片段,和残余的“Fc”片段(即Fc区,同上)。Fab片段可以由一条完整的L链与一条重链的可变区和该H链(VH)的第一恒定区(CH1)组成。在本申请中,术语“Fab′片段”通常指人单克隆抗体的单价抗原结合片段。例如,Fab′片段可以包括所有轻链,所有重链可变区以及重链的所有或部分第一和第二恒定区。例如,Fab′片段还可包括重链的部分或所有。在本申请中,术语“F(ab')2”通常指通过胃蛋白酶消化完整抗体所产生的抗体片段。F(ab')2片段含有由二硫键维持在一起的两个Fab片段和部分铰链区。F(ab')2片段具有二价抗原结合活性并且能够交联抗原。在本申请中,术语“Fv片段”通常指人单克隆抗体的单价抗原结合片段,包括所有或部分重链可变区和轻链可变区,并且缺乏重链恒定区和轻链恒定区。重链可变区和轻链可变区包括例如CDR。在本申请中,术语“scFv”通常指包含至少一个包括轻链的可变区抗体片段和至少一个包括重链的可变区的抗体片段的融合蛋白,其中所述轻链和重链可变区是邻接的(例如经由合成接头例如短的柔性多肽接头),并且能够以单链多肽形式表达,且其中所述scFv保留其所来源的完整抗体的特异性。除非特别说明,否则如本申请中使用的那样,scFv可以以任何顺序(例如相对于多肽的N末端和C末端)具有所述的VL和VH可变区,scFv可以包括VL-接头-VH或可以包括VH-接头-VL。在本申请中,术语“dAb”通常是指具有VH域、VL域或具有VH域或VL域的抗原结合片段,参考例如Ward等人(Nature,1989Oct12;341(6242):544-6),参考Holt等人,Trends Biotechnol.,2003,21(11):484-490;以及参考例如WO 06/030220、WO 06/003388和DomantisLtd的其它公布的专利申请。术语“dAb”通常包括sdAb。术语“sdAb”通常指单域抗体。单域抗体通常指仅由抗体重链可变区(VH结构域)或抗体轻链的可变区(VL)组成的抗体片段,在某些情况下,单域抗体还可以包含重链恒定区。
在本申请中,术语“单克隆抗体”通常指单分子组成的抗体分子制备物。单克隆抗体通常针对单个抗原位点具有高度特异性。而且,与常规多克隆抗体制剂(通常具有针对不同决定簇的不同抗体)不同,各单克隆抗体是针对抗原上的单个决定簇。除了它们的特异性之外,单克隆抗体的优点在于它们可以通过杂交瘤培养合成,不受其他免疫球蛋白污染。修饰语“单克隆”表示从基本上同质的抗体群体获得的抗体的特征,并且不被解释为需要通过任何特定方法产生抗体。例如,本申请使用的单克隆抗体可以在杂交瘤细胞中制备,或者可以通过重组DNA方法制备。
在本申请中,术语“嵌合抗体”通常是指其中可变区源自一个物种,而恒定区源自另一个物种的抗体。通常,可变区源自实验动物诸如啮齿动物的抗体(“亲本抗体”),且恒定区源自人类抗体,使得所得嵌合抗体与亲本抗体相比,在人类个体中引发不良免疫反应的可能性降低。
在本申请中,术语“人源化抗体”通常是指非人抗体的CDR区以外的部分或全部氨基酸被源自人免疫球蛋白的相应的氨基酸置换的抗体。在CDR区中,氨基酸的小的添加、缺失、插入、置换或修饰也可以是允许的,只要它们仍保留抗体结合特定抗原的能力。人源化抗体可任选地包含人类免疫球蛋白恒定区的至少一部分。“人源化抗体”保留类似于原始抗体的抗原特异性。非人抗体的“人源化”形式可以最低限度地包含衍生自非人免疫球蛋白的序列的嵌合抗体。在某些情形中,可以将人免疫球蛋白(受体抗体)中的CDR区残基用具有所期望性质、亲和力和/或能力的非人物种(供体抗体)(诸如羊驼,小鼠,大鼠,家兔或非人灵长类动物)的CDR区残基替换。在某些情形中,可以将人免疫球蛋白的FR区残基用相应的非人残基替换。此外,人源化抗体可包含在受体抗体中或在供体抗体中没有的氨基酸修饰。进行这些修饰可以是为了进一步改进抗体的性能,诸如结合亲和力。
在本申请中涉及的蛋白质、多肽和/或氨基酸序列,还应理解为至少包含以下的范围:与该所述蛋白质或多肽具备相同或类似功能的变体或同源物。
在本申请中,所述变体可以为,在所述蛋白质和/或所述多肽(例如,特异性结合CLDN18.2的抗体或其片段)的氨基酸序列中经过取代、缺失或添加一个或多个氨基酸的蛋白质或多肽。例如,所述功能性变体可包含已经通过至少1个,例如1-30个、1-20个或1-10个,又例如1个、2个、3个、4个或5个氨基酸取代、缺失和/或插入而具有氨基酸改变的蛋白质或多肽。所述功能性变体可基本上保持改变(例如取代、缺失或添加)之前的所述蛋白质或所述多肽的生物学特性。例如,所述功能性变体可保持改变之前的所述蛋白质或所述多肽的至少60%,70%,80%,90%,或100%的生物学活性(例如抗原结合能力)。例如,所述取代可以为保守取代。
在本申请中,所述同源物可以为,与所述蛋白质和/或所述多肽(例如,特异性结合CLDN18.2的抗体或其片段)的氨基酸序列具有至少约85%(例如,具有至少约85%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%或更高的)序列同源性的蛋白质或多肽。
在本申请中,所述同源性通常是指两个或多个序列之间的相似性、类似或关联。可以通过以下方式计算“序列同源性百分比”:将两条待比对的序列在比较窗中进行比较,确定两条序列中存在相同核酸碱基(例如,A、T、C、G、I)或相同氨基酸残基(例如,Ala、Pro、Ser、Thr、Gly、Val、Leu、Ile、Phe、Tyr、Trp、Lys、Arg、His、Asp、Glu、Asn、Gln、Cys和Met)的位置的数目以得到匹配位置的数目,将匹配位置的数目除以比较窗中的总位置数(即,窗大小),并且将结果乘以100,以产生序列同源性百分比。为了确定序列同源性百分数而进行的比对,可以按本领域已知的多种方式实现,例如,使用可公开获得的计算机软件如BLAST、BLAST-2、ALIGN或Megalign(DNASTAR)软件。本领域技术人员可以确定用于比对序列的适宜参数,包括为实现正在比较的全长序列范围内或目标序列区域内最大比对所需要的任何算法。所述同源性也可以通过以下的方法测定:FASTA和BLAST。对FASTA算法的描述可以参见W.R.Pearson和D.J.Lipman的“用于生物学序列比较的改进的工具”,美国国家科学院院刊(Proc.Natl.Acad.Sci.),85:2444-2448,1988;和D.J.Lipman和W.R.Pearson的“快速灵敏的蛋白质相似性搜索”,Science,227:1435-1441,1989。对BLAST算法的描述可参见S.Altschul、W.Gish、W.Miller、E.W.Myers和D.Lipman的“一种基本的局部对比(alignment)搜索工具”,分子生物学杂志,215:403-410,1990。
在本申请中,术语“CLDN18.2”、或“Claudin18.2”可以互换使用,通常指细胞连接密蛋白Claudin18的亚型2。所述术语涵盖“全长”、未加工的CLDN18.2以及由细胞加工所产生的任何形式的CLDN18.2。CLDN18.2可以包括完整的CLDN18.2及其片段,其功能性变体、同工型、物种同源物、衍生物、类似物以及具有至少一个与CLDN18.2共同表位的类似物。
通常情况下,在多肽链中,氨基与多肽链中的另一个羧基相连可以使其成为一个链,但是在蛋白质的两个末端,分别剩余没有成肽键的氨基酸残基,分别是携带游离的氨基的多肽链末端和携带羧基的多肽链末端。在本申请中,术语“N端”通常是指氨基酸残基携带游离的氨基的多肽链的末端。在本申请中,术语“C端”通常是指氨基酸残基携带游离的羧基的多肽链的末端。
在本申请中,术语“核酸分子”通常是指从其天然环境中分离的或人工合成的任何长度的分离形式的核苷酸、脱氧核糖核苷酸或核糖核苷酸或其类似物。
在本申请中,术语“免疫缀合物”通常是指缀合了一个或多个异源分子(包括但不限于细胞毒素)的具有免疫功能的多肽分子。在本申请中,“缀合”和“连接”、“融合”在本申请中可以互换使用,并且通常是指将两个或更多个化学元素、序列或组分连接在一起,例如通过包括化学缀合或重组手段。所述异源分子可以是细胞毒素、化疗药物等。例如,将本申请所述的融合蛋白缀合一个或多个异源分子(例如,细胞毒素)可以得到所述的免疫缀合物。
在本发明中,术语“载体”指的是,可将编码某蛋白的多聚核苷酸插入其中并使蛋白获得表达的一种核酸运载工具。载体可通过转化、转导或转染宿主细胞,使其携带的遗传物质元件在宿主细胞内表达得以表达。举例来说,载体包括:质粒;噬菌粒;柯斯质粒;人工染色体如酵母人工染色体(YAC)、细菌人工染色体(BAC)或P1来源的人工染色体(PAC);噬菌体如λ噬菌体或M13噬菌体及动物病毒等。用作载体的动物病毒种类有逆转录酶病毒(包括慢病毒)、腺病毒、腺相关病毒、疱疹病毒(如单纯疱疹病毒)、痘病毒、杆状病毒、乳头瘤病毒、乳头多瘤空泡病毒(如SV40)。一种载体可能含有多种控制表达的元件,包括启动子序列、转录起始序列、增强子序列、选择元件及报告基因。另外,载体还可含有复制起始位点。载体还有可能包括有协助其进入细胞的成分,如病毒颗粒、脂质体或蛋白外壳,但不仅仅只有这些物质。
在本申请中,术语“药物组合物”通常指用于预防/治疗疾病或病症的组合物。所述药物组合物可以包含本申请所述的分离的抗原结合蛋白、本申请所述的核酸分子、本申请所述的载体和/或本申请所述的细胞,以及任选地药学上可接受的佐剂。此外,所述药物组合物还可以包含一种或多种(药学上有效的)载剂、稳定剂、赋形剂、稀释剂、增溶剂、表面活性剂、乳化剂和/或防腐剂的合适的制剂。组合物的可接受成分在所用剂量和浓度下优选地对接受者无毒。本发明的药物组合物包括但不限于液体、冷冻和冻干组合物。
在本申请中,术语“药学上可接受的载剂”通常包括药剂学可接受的载剂、赋形剂或稳定剂,它们在所采用的剂量和浓度对暴露于其的细胞或哺乳动物是无毒的。
在本申请中,术语“肿瘤”通常是指哺乳动物中的机体(例如,细胞或其组成部分)在各种致瘤因子作用下,局部组织细胞增生所形成的赘生物。在本申请中,肿瘤可以包括实体瘤和非实体瘤。在本申请中,所述肿瘤可以包含胃癌、食道癌、胰腺癌、肺癌、卵巢癌、结肠癌、肝癌、头颈癌和/或胆囊癌。
在本申请中,术语“包含”通常是指包括明确指定的特征,但不排除其他要素。
在本申请中,术语“约”通常是指在指定数值以上或以下0.5%-10%的范围内变动,例如在指定数值以上或以下0.5%、1%、1.5%、2%、2.5%、3%、3.5%、4%、4.5%、5%、5.5%、6%、6.5%、7%、7.5%、8%、8.5%、9%、9.5%、或10%的范围内变动。
发明详述
融合蛋白
一方面,本申请提供一种融合蛋白,所述融合蛋白可以包含第一结合域以及第二结合域。所述第一结合域可以特异性结合CLDN18.2;所述第二结合域可以特异性结合CD47蛋白,其中所述第二结合域可以具有以下特性中的至少一项:(a)以4×10
在某些实施方式中,所述第二结合域可以包含SIRPα变体1的突变体或其片段。所述突变体与SEQ ID NO:22的第33位至第149位氨基酸序列相比,包含一个或多个(例如,1-2个、1-3个、1-4个、1-5个、1-6个、1-7个、1-8个、1-9个、1-10个或更多个)位置的氨基酸残基突变。其中所述氨基酸残基突变可以包含氨基酸残基的取代、缺失或添加。其中所述氨基酸的位置由SEQ ID NO:22所示的氨基酸位置来确定。例如,I61通常指以SEQ ID NO:22所示的氨基酸序列为基准的第61位氨基酸。在本申请中,SEQ ID NO:23所示的氨基酸序列可以指人SIRPα变体1(SEQ ID NO:22)的第33-149位氨基酸残基,即SEQ ID NO:23所示的氨基酸序列的第一个氨基酸的位置编号为“第33位”。
在本申请中,所述SIRPα变体1的突变体可以包括在SIRPα变体1的第33位至第149位氨基酸序列中含有一个或多个氨基酸突变。例如,所述SIRPα变体1的突变体可以包含在SEQ ID NO:23所示的氨基酸序列中含有一个或多个氨基酸突变。例如,本申请中所述SIRPα变体1的突变体,与SEQ ID NO:23所示的氨基酸序列相比,包含一个或多个氨基酸突变。
在本申请中,所述融合蛋白能够同时结合肿瘤相关抗原和CD47蛋白,从而起到治疗疾病和/或病症的作用。
在本申请中,术语“第一结合域”通常是指可以特异性结合CLDN18.2的结构域。术语“第二结合域”通常是指可以特异性结合CD47蛋白的结构域。
特异性结合CD47的第二结合域
在本申请中,所述突变体(例如特异性结合CD47蛋白的人SIRPα变体1的突变体)在包含选自下组的一个或多个(例如,1-2个、1-3个、1-4个、1-5个、1-6个、1-7个、1-8个、1-9个、1-10个或更多个)氨基酸残基处包含氨基酸取代:L44、I61、V63、E77、Q82、K83、E84、V93、D95、L96、K98、N100、R107、G109和V132。
例如,所述突变体可以包含L44位的氨基酸突变。例如,所述突变体可以包含I61位的氨基酸突变。例如,所述突变体可以包含V63位的氨基酸突变。例如,所述突变体可以包含E77位的氨基酸突变。例如,所述突变体可以包含Q82位的氨基酸突变。例如,所述突变体可以包含K83位的氨基酸突变。例如,所述突变体可以包含E84位的氨基酸突变。例如,所述突变体可以包含V93位的氨基酸突变。例如,在所述突变体可以包含D95位的氨基酸突变。例如,所述突变体可以包含L96位的氨基酸突变。例如,所述突变体可以包含K98位的氨基酸突变。例如,所述突变体可以包含N100位的氨基酸突变。例如,所述突变体可以包含R107位的氨基酸突变。例如,所述突变体可以包含G109位的氨基酸突变。例如,所述突变体可以包含V132位的氨基酸突变。
在本申请中,所述氨基酸取代中氨基酸残基的位置是以SEQ ID NO:22所示氨基酸序列为基准确定的残基编号。
“氨基酸取代Xn”是指在相应于SEQ ID NO:22所示氨基酸序列中第n位的残基X处发生氨基酸取代,其中n为正整数,X为任意氨基酸残基的缩写。例如,“氨基酸取代I61”表示在相应于SEQ ID NO:22所示氨基酸序列中第61位的残基I处发生氨基酸取代。
本申请中,所述的氨基酸取代可以为非保守取代。所述非保守取代可包括以非保守的形式改变目标蛋白或多肽中的氨基酸残基,例如将具有某种侧链大小或某种特性(例如,亲水性)的氨基酸残基变为具有不同侧链大小或不同特性(例如,疏水性)的氨基酸残基。
本申请中,所述的氨基酸取代也可以为保守取代。所述保守取代可包括以保守的形式改变目标蛋白或多肽中的氨基酸残基,例如将具有某种侧链大小或某种特性(例如,亲水性)的氨基酸残基变为具有相同或相似侧链大小或者相同或相似特性(例如,仍为亲水性)的氨基酸残基。这样的保守取代通常不会对所产生的蛋白质的结构或功能带来很大影响。在本申请中,作为所述融合蛋白或其片段的氨基酸序列变体可包括不显著改变蛋白质结构或其功能(例如,阻断CD47与特异性结合CD47蛋白的人SIRPα变体1的突变体)的保守氨基酸取代。
作为示例,下述各组中每组内各氨基酸间的相互取代在本申请中可被认为是保守取代:具有非极性侧链的氨基酸组:丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯丙氨酸、色氨酸和甲硫氨酸。不带电荷、具有极性侧链的氨基酸组:甘氨酸、丝氨酸、苏氨酸,半胱氨酸,酪氨酸,天冬酰胺和谷氨酰胺。带负电荷、具有极性侧链的氨基酸组:天冬氨酸和谷氨酸。带正电荷的碱性氨基酸:赖氨酸、精氨酸和组氨酸。带苯基的氨基酸:苯丙氨酸、色氨酸和酪氨酸。
在本申请中,所述突变体可以在选自下组的氨基酸残基处包含氨基酸取代:(1)I61、V63、E77、E84、V93、L96、K98、N100和V132;(2)I61、E77、Q82、K83和E84;(3)I61、V63、K83、E84和V132;(4)I61、E77、E84、R107和V132;(5)I61、V63、E77、K83、E84和N100;(6)I61、E77、Q82、K83、E84和R107;(7)I61、E77、Q82、E84、V93、L96、N100、R107、G109和V132;(8)I61、E77、Q82、K83、E84和V132;(9)I61;(10)I61、D95、L96、G109和V132;(11)I61、D95、L96、K98、G109和V132;(12)I61、E77、E84、V93、R107和V132;(13)E77、L96、N100、G109和V132;(14)I61、V63、Q82、E84、D95、L96、N100和V132;(15)I61、E77、Q82、K83、E84、V93、D95、L96、K98、N100和V132;(16)I61、E77、Q82、K83、E84和V93;(17)I61、V63、E77、K83、E84、D95、L96、K98和N100;(18)I61、V63、E77、K83、D95、L96、K98、N100和G109;(19)I61、E77、Q82、E84、V93、D95、L96、K98和N100;(20)I61、V63、E77、Q82和E84;以及(21)L44、I61、E77、Q82、K83、E84和V132。
在本申请中,所述突变体可以包含选自下组的一个或多个(例如,1-2个、1-3个、1-4个、1-5个、1-6个、1-7个、1-8个、1-9个、1-10个或更多个)氨基酸取代:L44V、I61L/V/F、V63I、E77I/N/Q/K/H/M/R/V/L、Q82S/R/G/N、K83R、E84Q/K/H/D/R/G、V93L/A、D95H/R/E、L96S/T、K98R、N100G/K/D/E、R107N/S、G109R/H和V132L/R/I/S。
在本申请中,氨基酸取代“XnY/Z”是指相应于SEQ ID NO:22所示氨基酸序列中第n位的残基X被取代为氨基酸残基Y或者氨基酸残基Z,其中n为正整数,X、Y和Z分别独立地为任意氨基酸残基的缩写,且X不同于Y或Z。例如,氨基酸取代“I61L/V/F”是指相应于SEQ IDNO:22所示氨基酸序列中第61位的残基I被取代为氨基酸残基L、V或F。
例如,所述突变体可以包含L44V氨基酸突变。例如,所述突变体可以包含I61L、I61V或I61F氨基酸突变。例如,所述突变体可以包含V63I氨基酸突变。例如,所述突变体可以包含E77I、E77N、E77Q、E77K、E77H、E77M、E77R、E77V或E77L氨基酸突变。例如,所述突变体可以包含Q82S、Q82R、Q82G或Q82N氨基酸突变。例如,所述突变体可以包含K83R氨基酸突变。例如,所述突变体可以包含E84Q、E84K、E84H、E84D、E84R或E84G氨基酸突变。例如,所述突变体可以包含V93L或V93A氨基酸突变。例如,所述突变体可以包含D95H、D95R或D95E氨基酸突变。例如,所述突变体可以包含L96S或L96T氨基酸突变。例如,所述突变体可以包含K98R氨基酸突变。例如,所述突变体可以包含N100G、N100K、N100D或N100E氨基酸突变。例如,所述突变体可以包含R107N或R107S氨基酸突变。例如,所述突变体可以包含G109R或G109H氨基酸突变。例如,所述突变体可以包含V132L、V132R、V132I或V132S氨基酸突变。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:I61和E77。例如,所述突变体可以包含I61L/V/F和E77Q/N/I的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:I61和V132。例如,所述突变体可以包含I61L/V/F和V132I/S的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:I61和E84。例如,所述突变体可以包含I61L/V/F和E84D/H的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:I61、K83和E84。例如,所述突变体可以包含I61L/V/F、K83R和E84Q/D/H的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:I61、D95和L96。例如,所述突变体可以包含I61L/V/F、D95H和L96S的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:I61、D95、L96、G109和V132。例如,所述突变体可以包含I61L/V/F、D95H、L96S、G109H和V132I/S的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:I61、G109和V132。例如,所述突变体可以包含I61L/V/F、G109H和V132I/S的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:V93和R107。例如,所述突变体可以包含V93A和R107N的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:L44和I61。例如,所述突变体可以包含L44V和I61L/V/F的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:L44和E77。例如,所述突变体可以包含L44V和E77Q/N/I的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代:Q82、K83和E84。例如,所述突变体可以包含Q82S/R/G/N、K83R和E84Q/K/H/D/R/G的氨基酸取代。
在本申请中,所述突变体可以包含在以下氨基酸位置处具有取代;E77和V132。例如,所述突变体可以包含E77Q/N/I和V132I/S的氨基酸取代。
在本申请中,所述突变体可以包含选自下组的氨基酸取代:(1)I61L、V63I、E77I、E84K、V93L、L96S、K98R、N100G和V132L;(2)I61V、E77N、Q82S、K83R和E84H;(3)I61F、V63I、K83R、E84K和V132I;(4)I61L、E77Q、E84D、R107N和V132I;(5)I61L、V63I、E77K、K83R、E84D和N100G;(6)I61V、E77H、Q82R、K83R、E84H和R107S;(7)I61L、E77I、Q82G、E84R、V93L、L96T、N100G、R107S、G109R和V132R;(8)I61L、E77M、Q82G、K83R、E84D和V132L;(9)I61L;(10)I61F、D95H、L96S、G109H和V132S;(11)I61F、D95H、L96S、K98R、G109H和V132S;(12)I61L、E77Q、E84D、V93A、R107N和V132I;(13)E77K、L96S、N100K、G109H和V132L;(14)I61L、V63I、Q82G、E84G、D95R、L96S、N100D和V132I;(15)I61L、E77R、Q82N、K83R、E84G、V93L、D95E、L96T、K98R、N100D和V132L;(16)I61V、E77N、Q82S、K83R、E84H和V93A;(17)I61V、V63I、E77V、K83R、E84D、D95E、L96T、K98R和N100E;(18)I61L、V63I、E77V、K83R、D95E、L96S、K98R、N100D和G109R;(19)I61V、E77L、Q82G、E84G、V93L、D95E、L96T、K98R和N100G;(20)I61L、V63I、E77N、Q82G和E84G;和(21)L44V、I61F、E77I、Q82R、K83R、E84Q和V132I。
在本申请中,在人SIRPα变体1的截短结构域(如SEQ ID NO:23所示的氨基酸序列,即人SIRPα变体1的氨基酸序列中的第33-149位残基)的基础上,分别包含上述(1)-(21)的氨基酸取代组的SIRPα变体1的突变体可依次被命名为M1、M5、M12、M35、M37、M41、M57、M67、M81、M82、M84、M91、M99、M102、M111、M122、M126、M130、M135、M145和M169。
在本申请中,所述突变体还可以包含一个或多个糖基化位点改造。所述改造包含通过人工手段使得糖基化位点发生改变。例如,所述糖基化位点改造包含糖基化位点突变。在某些实施方式中,所述糖基化位点突变位于N110位置处。某些实施方式中,所述糖基化位点突变包含N110A。
在本申请中,所述突变体(例如特异性结合CD47蛋白的人SIRPα变体1的突变体)与SEQ ID NO:23所示的氨基酸序列相比,在包含选自下组的一个或多个氨基酸残基处包含氨基酸取代:L44、I61、V63、E77、Q82、K83、E84、V93、D95、L96、K98、N100、R107、G109、N110和V132。
在本申请中,所述融合蛋白中的所述突变体可以在选自下组的氨基酸残基处包含氨基酸取代:(1)I61、V63、E77、E84、V93、L96、K98、N100、N110和V132;(2)I61、E77、Q82、K83、E84和N110;(3)I61、V63、K83、E84、N110和V132;(4)I61、E77、E84、R107N110和V132;(5)I61、V63、E77、K83、E84、N100和N110;(6)I61、E77、Q82、K83、E84、R107和N110;(7)I61、E77、Q82、E84、V93、L96、N100、R107、G109、N110和V132;(8)I61、E77、Q82、K83、E84、V132和N110;(9)I61和N110;(10)I61、D95、L96、G109、N110和V132;(11)I61、D95、L96、K98、G109、N110和V132;(12)I61、E77、E84、V93、R107、N110和V132;(13)E77、L96、N100、G109、N110和V132;(14)I61、V63、Q82、E84、D95、L96、N100、N110和V132;(15)I61、E77、Q82、K83、E84、V93、D95、L96、K98、N100、N110和V132;(16)I61、E77、Q82、K83、E84、V93和N110;(17)I61、V63、E77、K83、E84、D95、L96、K98、N100和N110;(18)I61、V63、E77、K83、D95、L96、K98、N100、G109和N110;(19)I61、E77、Q82、E84、V93、D95、L96、K98、N100和N110;(20)I61、V63、E77、Q82、E84和N110;以及(21)L44V、I61F、E77I、Q82R、K83R、E84Q、N110A和V132I。
在本申请中,所述融合蛋白中的所述突变体可以包含选自下组的氨基酸取代:(1)I61L、V63I、E77I、E84K、V93L、L96S、K98R、N100G、N110A和V132L;(2)I61V、E77N、Q82S、K83R、E84H和N110A;(3)I61F、V63I、K83R、E84K、N110A和V132I;(4)I61L、E77Q、E84D、R107N、N110A和V132I;(5)I61L、V63I、E77K、K83R、E84D、N100G和N110A;(6)I61V、E77H、Q82R、K83R、E84H、R107S和N110A;(7)I61L、E77I、Q82G、E84R、V93L、L96T、N100G、R107S、G109R、N110A和V132R;(8)I61L、E77M、Q82G、K83R、E84D、N110A和V132L;(9)I61L和N110A;(10)I61F、D95H、L96S、G109H、N110A和V132S;(11)I61F、D95H、L96S、K98R、G109H、N110A和V132S;(12)I61L、E77Q、E84D、V93A、R107N、N110A和V132I;(13)E77K、L96S、N100K、G109H、N110A和V132L;(14)I61L、V63I、Q82G、E84G、D95R、L96S、N100D、N110A和V132I;(15)I61L、E77R、Q82N、K83R、E84G、V93L、D95E、L96T、K98R、N100D、N110A和V132L;(16)I61V、E77N、Q82S、K83R、E84H、V93A和N110A;(17)I61V、V63I、E77V、K83R、E84D、D95E、L96T、K98R、N100E和N110A;(18)I61L、V63I、E77V、K83R、D95E、L96S、K98R、N100D、G109R和N110A;(19)I61V、E77L、Q82G、E84G、V93L、D95E、L96T、K98R、N100G和N110A;(20)I61L、V63I、E77N、Q82G、E84G和N110A;以及(21)L44V、I61F、E77I、Q82R、K83R、E84Q、N110A和V132I。
在本申请中,在人SIRPα变体1的截短结构域(如SEQ ID NO:23所示的氨基酸序列,即人SIRPα变体1的氨基酸序列中的第33-149位残基)的基础上,分别包含上述(1)-(21)的氨基酸取代组的SIRPα变体1的突变体可依次被命名为M1N、M5N、M12N、M35N、M37N、M41N、M57N、M67N、M81N、M82N、M84N、M91N、M99N、M102N、M111N、M122N、M126N、M130N、M135N、M145N和M169N。所述SIRPα变体1的突变体可依次包含如SEQ ID NO:1-21所示的氨基酸序列。在本申请中,所述SIRPα变体1的突变体可包含与SEQ ID NO:1-21中任一项所示的氨基酸序列具有至少80%(例如,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同源性的氨基酸序列。
特异性结合CLDN18.2的第一结合域
在本申请中,所述第一结合域包含抗原结合蛋白。在本申请中,所述抗原结合蛋白可以包含抗体或抗原结合片段。在某些实施方式中,所述抗体选自下组:单克隆抗体、单链抗体、嵌合抗体、人源化抗体和全人源抗体。在某些实施方式中,所述抗原结合片段选自下组:Fab,Fab’,F(ab')2,F(ab)2,dAb,分离的互补决定区CDR,Fv和scFv。
在某些实施方式中,所述抗原结合蛋白能够结合CLDN18.2。
在本申请中,所述抗原结合蛋白可以包含抗体重链可变区的至少一个CDR,所述抗体重链可变区可以包含SEQ ID NO:24所示的氨基酸序列。例如,所述CDR可以通过IMGT编号方案划分得到。
在某些实施方式中,所述抗原结合蛋白包含HCDR3,所述HCDR3可以包含SEQ IDNO:25所示的氨基酸序列。
在本申请中,所述抗原结合蛋白可以包含HCDR2,所述HCDR2可以包含SEQ ID NO:26所示的氨基酸序列。
在本申请中,所述抗原结合蛋白可以包含HCDR1,所述HCDR1可以包含SEQ ID NO:27所示的氨基酸序列。
在本申请中,所述抗原结合蛋白可以包含HCDR1,HCDR2和HCDR3。所述HCDR1可以包含SEQ ID NO:27所示的氨基酸序列,所述HCDR2可以包含SEQ ID NO:26所示的氨基酸序列,且所述HCDR3可以包含SEQ ID NO:25所示的氨基酸序列。
在本申请中,所述抗原结合蛋白可以包含VH,所示VH可以包含SEQ ID NO:24所示的氨基酸序列。
在本申请中,所述抗原结合蛋白可以包含免疫球蛋白单可变结构域。在本申请中,所述抗原结合蛋白可以包含V
在本申请中,所述V
在本申请中,所述V
在本申请中,所述V
在本申请中,所述V
在本申请中,所述抗原结合蛋白可以包含抗体重链恒定区Fc片段。在本申请中,所述抗原结合蛋白的重链恒定区可以源自IgG。在本申请中,所述重链恒定区可以源自人IgG。在本申请中所述IgG可以选自IgG1和IgG4。在本申请中,所述抗体重链恒定区Fc区可以包含SEQ ID NO:28所示的氨基酸序列。
第一结合域和第二结合域的连接方式
在本申请中,所述第一结合域可以位于所述第二结合域的N端。例如,所述第一结合域的C端可以与所述第二结合域的N端直接或间接相连。例如,所述第一结合域的C端可以通过连接子间接连接于所述第二结合域的N端。例如,所述第一结合域的C端也可以直接连接于第二结合域的N端。
在本申请中,所述融合蛋白还可以包含连接子,所述连接子可以位于所述第一结合域的C端且位于所述第二结合域的N端。例如,在所述融合蛋白中,第一结合域的C端可以连接连接子的N端,连接子的C端可以连接第二结合域的N端。例如,在所述融合蛋白中,从N端到C端,可以依次包含第一结合域、连接子和第二结合域。
在本申请中,所述连接子可以包含SEQ ID NO:29所示的氨基酸序列。
在某些情形中,所述融合蛋白可以包含至少2个(例如,至少2个,至少3个,至少4个,至少5个,至少6个,至少7个,至少8个,至少9个,至少10个,或更多)所述第二结合域。在本申请中,所述每个所述第二结合域可以分别位于所述第一结合域的C端。在本申请中,所述2个以上的第二结合域可以分别直接或间接连接于所述第一结合域的C端。
在本申请中,所述融合蛋白可以包含特异性结合CLDN18.2的第一结合域,以及特异性结合CD47蛋白的第二结合域,其中所述第二结合域可以包含人SIRPα变体1的突变体,特异性结合CLDN18.2的抗体或其抗原结合片段或变体的C端可以直接或间接连接人SIRPα变体1的突变体的N端。例如,所述第二结合域可以包含至少2个人SIRPα变体1的突变体,且2个人SIRPα变体1的突变体的N端分别连接特异性结合CLDN18.2的抗体或其抗原结合片段或变体的C端。
在本申请中,所述融合蛋白可以包含至少一条多肽链,其中所述多肽链从N端到C端可依次包含能够特异性结合CLDN18.2的V
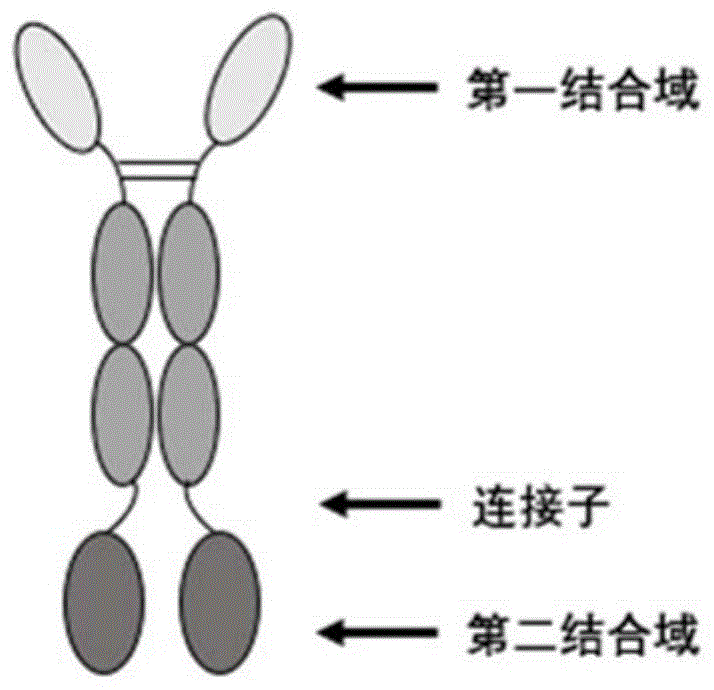
例如,如图1所示,所述融合蛋白的第一结合域可以包含NA3S-H1,所述融合蛋白的第二结合域可以包含人SIRPα变体1的突变体。所述第一结合域和所述第二结合域可以通过连接子相连接。所述连接子可以包含SEQ ID NO:29所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:1所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:2所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:3所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:4所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:5所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:6所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:7所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:8所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:9所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:10所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:11所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:12所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:13所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:14所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:15所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:16所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:17所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:18所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:19所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:20所示的氨基酸序列。
例如,所述融合蛋白的所述多肽链从N端到C端可分别依次包含SEQ ID NO:24、SEQID NO:28、SEQ ID NO:29和SEQ ID NO:21所示的氨基酸序列。
免疫缀合物、核酸分子、载体和细胞及制备方法
另一方面,本申请还提供了免疫缀合物,其包含所述融合蛋白。例如,所述免疫缀合物可以为融合蛋白-药物缀合物(ADC),其中本申请所述的融合蛋白与一种或多种治疗剂缀合,所述治疗剂包括但不限于细胞毒性剂、放射性毒性剂(例如,放射性同位素)和/或免疫抑制剂(例如,通过抑制免疫应答等途径杀伤细胞的任何药剂)等。在某些实施方式中,所述治疗剂可以为能够治疗肿瘤相关的疾病或病症的治疗剂。
所述缀合可通过肽连接子(例如,可切割连接子)或其它方式进行,例如,所述连接子可以为酸不稳定连接子、肽酶敏感连接子、光不稳定连接子等。
另一方面,本申请提供了一个或多个分离的核酸分子其编码所述融合蛋白或者所述免疫缀合物。例如,所述一个或多个核酸分子中的每一个核酸分子可以编码完整的所述抗体或其抗原结合片段,也可以编码其中的一部分(例如,HCDR1-3、LCDR1-3、VL、VH、轻链或重链中的一种或多种)。
本申请所述的核酸分子可以为分离的。例如,其可以是通过以下方法产生或合成的:(i)在体外扩增的,例如通过聚合酶链式反应(PCR)扩增产生的,(ii)通过克隆重组产生的,(iii)纯化的,例如通过酶切和凝胶电泳分级分离,或者(iv)合成的,例如通过化学合成。在某些实施方式中,所述分离的核酸是通过重组DNA技术制备的核酸分子。
重组DNA和分子克隆技术包括由Sambrook,J.,Fritsch,E.F.和Maniatis,T.Molecular Cloning:A Laboratory Manual;Cold Spring Harbor Laboratory Press:Cold Spring Harbor,(1989)(Maniatis)和由T.J.Silhavy,M.L.Bennan和L.W.Enquist,Experiments with Gene Fusions,Cold Spring Harbor Laboratory,Cold SpringHarbor,N.Y.(1984)以及由Ausubel,F.M.等,Current Protocols in Molecular Biology,pub.by Greene Publishing Assoc.and Wiley-Interscience(1987)描述的那些技术。简而言之,可从基因组DNA片段、cDNA和RNA制备所述核酸,所有这些核酸可直接从细胞中提取或通过各种扩增方法(包括但不限于PCR和RT-PCR)重组产生。
核酸的直接化学合成通常涉及将3'-封闭的和5'-封闭的核苷酸单体依次添加至生长中的核苷酸聚合物链的末端5'-羟基,其中每次添加通过亲核攻击所添加的单体的3'-位上的生长链的末端5'-羟基来实现,所述单体通常是磷衍生物,诸如磷酸三酯、亚磷酰胺等。参见,例如,Matteuci等,Tet.Lett.521:719(1980);属于Caruthers等的美国专利第4,500,707号;和属于Southern等的美国专利第5,436,327号和第5,700,637号;在另一方面,本申请提供了包含本申请的分离的多核苷酸的载体。所述载体可以是任何线性核酸、质粒、噬菌粒、粘粒、RNA载体、病毒载体等。病毒载体的非限制性实例可包括逆转录病毒、腺病毒和腺相关病毒。在一些实施方案中,所述载体是表达载体,例如,噬菌体展示载体。
另一方面,本申请提供一个或多个载体,其包含所述的核酸分子。例如,所述载体可以包含本申请所述的一种或多种核酸分子。每种载体中可包含一种或多种所述核酸分子。此外,所述载体中还可包含其他基因,例如允许在适当的宿主细胞中和在适当的条件下选择该载体的标记基因。此外,所述载体还可包含允许编码区在适当宿主中正确表达的表达控制元件。这样的控制元件为本领域技术人员所熟知的,例如,可包括启动子、核糖体结合位点、增强子和调节基因转录或mRNA翻译的其他控制元件等。在某些实施方式中,所述表达控制序列为可调的元件。所述表达控制序列的具体结构可根据物种或细胞类型的功能而变化,但通常包含分别参与转录和翻译起始的5’非转录序列和5’及3’非翻译序列,例如TATA盒、加帽序列、CAAT序列等。例如,5’非转录表达控制序列可包含启动子区,启动子区可包含用于转录控制功能性连接核酸的启动子序列。所述表达控制序列还可包括增强子序列或上游活化子序列。在本申请中,适当的启动子可包括,例如用于SP6、T3和T7聚合酶的启动子、人U6RNA启动子、CMV启动子及其人工杂合启动子(如CMV),其中启动子的某部分可与其他细胞蛋白(如人GAPDH,甘油醛-3-磷酸脱氢酶)基因启动子的某部分融合,其可包含或不包含另外的内含子。本申请所述的一种或多种核酸分子可以与所述表达控制元件可操作地连接。
所述载体可以包括,例如质粒、粘粒、病毒、噬菌体或者在例如遗传工程中通常使用的其他载体。在某些实施方式中,所述载体可以为表达载体。
所述载体还可含有一个或多个选择标记基因,其在表达后赋予可用于选择或以其它方式鉴定携带载体的宿主细胞的一个或多个表型性状。用于真核细胞的合适的选择标记的非限制性实例包括二氢叶酸还原酶和新霉素抗性。
另一方面,本申请提供一种细胞,所述细胞包含所述的融合蛋白,所述的免疫缀合物,所述的核酸分子,或所述的载体。所述细胞可以是宿主细胞。例如,所述细胞可以包括如下许多细胞类型,如大肠杆菌或枯草菌等原核细胞,如酵母细胞或曲霉菌等真菌细胞,如S2果蝇细胞或Sf9等昆虫细胞,或者如纤维原细胞,CHO细胞,COS细胞,NSO细胞,HeLa细胞,BHK细胞,HEK 293细胞或人细胞的动物细胞。
例如,可通过多种已建立的技术将所述载体稳定地或瞬时引入宿主细胞。例如,一种方法涉及氯化钙处理,其中通过钙沉淀引入载体。也可以按照类似方法使用其它盐,例如磷酸钙。另外,可以用电穿孔(即,施加电流以增加细胞对核酸的渗透性)。转化方法的其它实例包括显微注射、DEAE葡聚糖介导的转化和在乙酸锂存在下的热休克。脂质复合物、脂质体和树状聚合物也可用于转染宿主细胞。
在将异源序列引入宿主细胞中时,可实施多种方法来鉴定已向其中引入了载体的宿主细胞。一种示例性选择方法包括将单个细胞继代培养以形成单个菌落,然后测试所需蛋白质产物的表达。另一种方法需要基于通过载体内包含的选择标记基因的表达赋予的表型性状选择含有异源序列的宿主细胞。
例如,将本申请的各种异源序列引入宿主细胞可通过方法诸如PCR、Southern印迹或Northern印迹杂交来确认。例如,可从所得宿主细胞制备核酸,并且可使用对目标序列是特异的引物,通过PCR扩增特定目标序列。将扩增产物进行琼脂糖凝胶电泳、聚丙烯酰胺凝胶电泳或毛细管电泳,然后用溴化乙锭、SYBR Green溶液等染色,或用UV检测来检测DNA。或者,可在杂交反应中使用对目标序列是特异的核酸探针。特定基因序列的表达可以通过与PCR,Northern印迹杂交或通过使用与编码的基因产物反应的抗体的免疫测定的反转录检测相应的mRNA来确定。示例性免疫测定包括但不限于ELISA、放射免疫测定和夹心免疫测定。
此外,将本申请的各种异源序列引入宿主细胞可以通过异源序列编码的酶(例如,酶促标志物)的酶促活性来确认实。可通过本领域已知的多种方法测定酶。通常,酶促活性可通过产物的形成或正在研究的酶促反应的底物的转化来确定。所述反应可在体外或体内进行。
另一方面,本申请提供一种制备所述的融合蛋白的方法,其可以包括在使得所述融合蛋白能够表达的条件下培养所述的细胞。例如,可通过使用适当的培养基、适当的温度和培养时间等,这些方法是本领域普通技术人员所了解的。
在某些情形中,所述方法还可包括分离和/或纯化所述融合蛋白的步骤。例如,可以采用蛋白G-琼脂糖或蛋白A-琼脂糖进行亲和层析,还可通过凝胶电泳和/或高效液相色谱等来纯化和分离本申请所述的融合蛋白。
组合物和应用
另一方面,本申请提供一种组合物,所述组合物包含所述的融合蛋白,所述的免疫缀合物,或所述的核酸分子,以及任选地药学上可接受的赋形剂。
例如,所述药学上可接受的赋形剂可以包括缓冲剂、抗氧化剂、防腐剂、低分子量多肽、蛋白质、亲水聚合物、氨基酸、糖、螯合剂、反离子、金属复合物和/或非离子表面活性剂等。
在本申请中,可按照本领域的常规技术手段将所述组合物与药学上可接受的载体或稀释剂以及任何其他已知的辅剂和赋形剂配制在一起,例如按照Remington:TheScience and Practice of Pharmacy,第十九版,Gennaro编辑,Mack Publishing Co.,Easton,PA,1995中公开的技术进行操作。
在本申请中,所述组合物可被配制用于口服给药,静脉内给药,肌肉内给药,在肿瘤部位的原位给药,吸入,直肠给药,阴道给药,经皮给药或通过皮下储存库给药。
例如,所述组合物可以用于抑制肿瘤生长。例如,本申请的组合物可以抑制或延缓疾病的发展或进展,可以减小肿瘤大小(甚至基本消除肿瘤),和/或可以减轻和/或稳定疾病状态。
例如,本申请所述的组合物可以为适于口服给药的形式,如片剂,胶囊剂,丸剂,粉剂,缓释制剂,溶液剂,混悬剂,或者用于肠胃外注射,如无菌溶液剂,混悬剂或乳剂,或者用于软膏或乳膏局部给药或作为栓剂直肠给药。所述组合物可以是适合精确剂量单次给药的单位剂量形式。所述组合物可以进一步包含常规的药物载体或赋形剂。此外,所述组合物可以包括其他药物或药剂,载体,佐剂等。
本申请所述的组合物可以包含治疗有效量的所述融合蛋白。所述治疗有效量是能够预防和/或治疗(至少部分治疗)患有或具有发展风险的受试者中的病症或病症(例如肿瘤)和/或其任何并发症而所需的剂量。所述剂量的具体量/浓度可以根据施用方法和患者需要而变化,并且可以基于例如患者体积,粘度和/或体重等来确定。应当理解的是,基于特定患者,制剂和/或疾病的状况,本领域技术人员(例如,医生或药剂师)可以方便地调整这些特定剂量。
在本申请中,术语“治疗”或“医治”或“缓解”或“改善”在本申请中可互换使用,并且是指获得有益或所需的结果(包括但不限于治疗益处和/或预防益处)的方法。在本申请中,治疗益处通常是指根除或减轻所治疗的潜在病症的严重性。此外,通过根除、减轻严重性或减少与潜在病症相关的一种或多种生理症状的发生率,以使得在受试者中观察到改善(尽管受试者仍然可能受到潜在病症折磨)来实现治疗益处。对于预防益处,可向处于发展特定疾病的风险中的受试者,或报告疾病的一种或多种生理症状的受试者施用组合物,即使可能尚未进行该疾病的诊断。
另一方面,本申请提供了所述的融合蛋白,所述的免疫缀合物,所述的核酸分子,所述的载体,所述的组合物,或所述的细胞在制备药物中的用途,其中所述药物可以用于预防和/或治疗疾病和/或病症。
另一方面,本申请提供了所述的融合蛋白、免疫缀合物、核酸分子、载体、组合物或细胞,其用于预防和/或治疗疾病和/或病症。
另一方面,本申请提供了一种预防和/或治疗疾病和/或病症的方法,所述方法包括向受试者施用本申请所述的融合蛋白、免疫缀合物、核酸分子、载体、组合物或细胞。
另一方面,本申请提供了一种抑制肿瘤或肿瘤细胞生长和/或增殖的方法,所述方法可包括使本申请所述的融合蛋白或组合物与所述肿瘤或肿瘤细胞接触。例如,所述接触可在体外发生。
另一方面,本申请提供了一种可以抑制肿瘤或肿瘤细胞生长和/或增殖的方法,其可以包括向有需要的受试者施用有效量的所述的融合蛋白,所述的免疫缀合物,所述的核酸分子,所述的载体,所述的组合物,或所述的细胞。
在本申请中,所述疾病和/或病症可以包括与CLDN18.2相关的疾病和/或病症。
在本申请中,所述与CLDN18.2相关的疾病和/或病症包括涉及表达CLDN18.2的细胞的疾病或与表达CLDN18.2的细胞相关的疾病。
在本申请中,所述肿瘤可以包括实体瘤和非实体瘤。
在本申请中,所述肿瘤可以包括胃癌、食道癌、胰腺癌、肺癌、卵巢癌、结肠癌、肝癌、头颈癌和/或胆囊癌。
另一方面,本申请提供了所述的融合蛋白,所述的免疫缀合物,所述的核酸分子,所述的载体,所述的组合物,或所述的细胞,其可以预防和/或治疗疾病和/或病症。
在本申请中,术语“受试者”通常是指人或非人动物,包括但不限于猫、狗、马、猪、牛、绵羊、山羊、兔、小鼠、大鼠或猴。
本申请还包含以下技术方案:
1.融合蛋白,其包含:
特异性结合CLDN18.2的第一结合域;以及
特异性结合CD47蛋白的第二结合域;
其中,所述第二结合域具有以下特性中的至少一项:
(a)以4×10-8M或更低的KD值与CD47蛋白相结合;
(b)特异性阻断CD47蛋白与SIRPα的相互作用;
(c)不引起凝血反应;以及
(d)能够抑制肿瘤或肿瘤细胞的生长和/或增殖。
2.根据实施方案1所述的融合蛋白,其中所述第二结合域包含人SIRPα变体1的突变体,其中所述突变体与SEQ ID NO:22的第33位至第149位氨基酸序列相比,包含一个或多个位置的氨基酸残基突变。
3.根据实施方案2所述的融合蛋白,其中所述突变体包含选自下组的一个或多个氨基酸位置处的氨基酸突变:L44、I61、V63、E77、Q82、K83、E84、V93、D95、L96、K98、N100、R107、G109和V132。
4.根据实施方案2-3中任一项所述的融合蛋白,其中所述突变体包含I61和E77氨基酸残基处的氨基酸取代。
5.根据实施方案2-4中任一项所述的融合蛋白,其中所述突变体包含I61和V132氨基酸残基处的氨基酸取代。
6.根据实施方案2-5中任一项所述的融合蛋白,其中所述突变体包含I61和E84氨基酸残基处的氨基酸取代。
7.根据实施方案2-6中任一项所述的融合蛋白,其中所述突变体包含I61、K83和E84氨基酸残基处的氨基酸取代。
8.根据实施方案2-7中任一项所述的融合蛋白,其中所述突变体包含I61、G109和V132氨基酸残基处的氨基酸取代。
9.根据实施方案2-8中任一项所述的融合蛋白,其中所述突变体包含I61、D95、L96、G109和V132氨基酸残基处的氨基酸取代。
10.根据实施方案2-9中任一项所述的融合蛋白,其中所述突变体包含V93和R107氨基酸残基处的氨基酸取代。
11.根据实施方案2-10中任一项所述的融合蛋白,其中所述突变体包含L44和I61氨基酸残基处的氨基酸取代。
12.根据实施方案2-11中任一项所述的融合蛋白,其中所述突变包含L44和E77氨基酸残基处的氨基酸取代。
13.根据实施方案2-12中任一项所述的融合蛋白,其中所述突变包含Q82、K83和E84氨基酸残基处的氨基酸取代。
14.根据实施方案2-13中任一项所述的融合蛋白,其中所述突变包含E77和V132氨基酸残基处的氨基酸取代。
15.根据实施方案2-14中任一项所述的融合蛋白,其中所述突变体在选自下组的氨基酸残基处包含氨基酸突变:
(1)I61、V63、E77、E84、V93、L96、K98、N100和V132;
(2)I61、E77、Q82、K83和E84;
(3)I61、V63、K83、E84和V132;
(4)I61、E77、E84、R107和V132;
(5)I61、V63、E77、K83、E84和N100;
(6)I61、E77、Q82、K83、E84和R107;
(7)I61、E77、Q82、E84、V93、L96、N100、R107、G109和V132;
(8)I61、E77、Q82、K83、E84和V132;
(9)I61;
(10)I61、D95、L96、G109和V132;
(11)I61、D95、L96、K98、G109和V132;
(12)I61、E77、E84、V93、R107和V132;
(13)E77、L96、N100、G109和V132;
(14)I61、V63、Q82、E84、D95、L96、N100和V132;
(15)I61、E77、Q82、K83、E84、V93、D95、L96、K98、N100和V132;
(16)I61、E77、Q82、K83、E84和V93;
(17)I61、V63、E77、K83、E84、D95、L96、K98和N100;
(18)I61、V63、E77、K83、D95、L96、K98、N100和G109;
(19)I61、E77、Q82、E84、V93、D95、L96、K98和N100;
(20)I61、V63、E77、Q82和E84;以及
(21)L44、I61、E77、Q82、K83、E84和V132。
16.根据实施方案2-15中任一项所述的融合蛋白,其中所述突变体包含选自下组的一个或多个氨基酸取代:L44V、I61L/V/F、V63I、E77I/N/Q/K/H/M/R/V/L、Q82S/R/G/N、K83R、E84Q/K/H/D/R/G、V93L/A、D95H/R/E、L96S/T、K98R、N100G/K/D/E、R107N/S、G109R/H和V132L/R/I/S。
17.根据实施方案2-16中任一项所述的融合蛋白,其中所述突变体包含I61L/V/F和E77Q/N/I的氨基酸取代。
18.根据实施方案2-17中任一项所述的融合蛋白,其中所述突变体包含I61L/V/F和V132I/S的氨基酸取代。
19.根据实施方案2-18中任一项所述的融合蛋白,其中所述突变体包含I61L/V/F、K83R和E84Q/D/H的氨基酸取代。
20.根据实施方案2-19中任一项所述的融合蛋白,其中所述突变体包含I61L/V/F、G109H和V132I/S的氨基酸取代。
21.根据实施方案2-20中任一项所述的融合蛋白,其中所述突变体包含I61L/V/F、D95H、L96S、G109H和V132I/S的氨基酸取代。
22.根据实施方案2-21中任一项所述的融合蛋白,其中所述突变体包含V93A和R107N的氨基酸取代。
23.根据实施方案2-22中任一项所述的融合蛋白,其中所述突变体包含L44V和I61L/V/F的氨基酸取代。
24.根据实施方案2-23中任一项所述的融合蛋白,其中所述突变体包含L44V和E77Q/N/I的氨基酸取代。
25.根据实施方案2-24中任一项所述的融合蛋白,其中所述突变体包含Q82S/R/G/N、K83R和E84Q/K/H/D/R/G的氨基酸取代。
26.根据实施方案2-25中任一项所述的融合蛋白,其中所述突变体包含E77Q/N/I和V132I/S的氨基酸取代。
27.根据实施方案2-26中任一项所述的融合蛋白,其中所述突变体包含选自下组的氨基酸突变:
(1)I61L、V63I、E77I、E84K、V93L、L96S、K98R、N100G和V132L;
(2)I61V、E77N、Q82S、K83R和E84H;
(3)I61F、V63I、K83R、E84K和V132I;
(4)I61L、E77Q、E84D、R107N和V132I;
(5)I61L、V63I、E77K、K83R、E84D和N100G;
(6)I61V、E77H、Q82R、K83R、E84H和R107S;
(7)I61L、E77I、Q82G、E84R、V93L、L96T、N100G、R107S、G109R和V132R;
(8)I61L、E77M、Q82G、K83R、E84D和V132L;
(9)I61L;
(10)I61F、D95H、L96S、G109H和V132S;
(11)I61F、D95H、L96S、K98R、G109H和V132S;
(12)I61L、E77Q、E84D、V93A、R107N和V132I;
(13)E77K、L96S、N100K、G109H和V132L;
(14)I61L、V63I、Q82G、E84G、D95R、L96S、N100D和V132I;
(15)I61L、E77R、Q82N、K83R、E84G、V93L、D95E、L96T、K98R、N100D和V132L;
(16)I61V、E77N、Q82S、K83R、E84H和V93A;
(17)I61V、V63I、E77V、K83R、E84D、D95E、L96T、K98R和N100E;
(18)I61L、V63I、E77V、K83R、D95E、L96S、K98R、N100D和G109R;
(19)I61V、E77L、Q82G、E84G、V93L、D95E、L96T、K98R和N100G;
(20)I61L、V63I、E77N、Q82G和E84G以及
(21)L44V、I61F、E77I、Q82R、K83R、E84Q和V132I。
28.根据实施方案2-27中任一项所述的融合蛋白,其中所述突变体还包含一个或多个糖基化位点改造。
29.根据实施方案28所述的融合蛋白,其中所述的糖基化位点改造包含糖基化位点突变。
30.根据实施方案29所述的融合蛋白,其中所述糖基化位点突变位于N110位置处。
31.根据实施方案29-30中任一项所述的融合蛋白,其中所述糖基化位点突变包含N110A的氨基酸取代。
32.根据实施方案2-31中任一项所述的融合蛋白,其中所述突变体包含SEQ IDNO:1-21中任一项所示的氨基酸序列。
33.根据实施方案1-33中任一项所述的融合蛋白,其中所述第一结合域包含靶向CLDN18.2的抗原结合蛋白。
34.根据实施方案33所述的融合蛋白,其中所述抗原结合蛋白包含抗体或其抗原结合片段。
35.根据实施方案34所述的融合蛋白,其中所述抗体选自下组:单克隆抗体、单链抗体、嵌合抗体、人源化抗体和全人源抗体。
36.根据实施方案34-35中任一项所述的融合蛋白,其中所述抗原结合片段选自下组:Fab,Fab’,F(ab)2,dAb,分离的互补决定区CDR,Fv和scFv。
37.根据实施方案1-36中任一项所述的融合蛋白,其中所述CLDN18.2包含人CLDN18.2。
38.根据实施方案1-37中任一项所述的融合蛋白,其中所述第一结合域包含重链可变区(VH)中的至少一个CDR,所述VH包含SEQ ID NO:24所示的氨基酸序列。
39.根据实施方案1-38中任一项所述的融合蛋白,其中所述第一结合域包含HCDR3,所述HCDR3包含SEQ ID NO:25所示的氨基酸序列。
40.根据实施方案1-39中任一项所述的融合蛋白,其中所述第一结合域包含HCDR2,所述HCDR2包含SEQ ID NO:26所示的氨基酸序列。
41.根据实施方案1-40中任一项所述的融合蛋白,其中所述第一结合域包含HCDR1,所述HCDR1包含SEQ ID NO:27所示的氨基酸序列。
42.根据实施方案1-41中任一项所述的融合蛋白,其中所述第一结合域包含VH,所述VH包含SEQ ID NO:24所示的氨基酸序列。
43.根据实施方案1-42中任一项所述的融合蛋白,其中所述第一结合域包含免疫球蛋白单可变结构域。
44.根据实施方案43所述的融合蛋白,其中所述免疫球蛋白单可变结构域包含VHH。
45.根据实施方案1-44中任一项所述的融合蛋白,其中所述第一结合域包含VHH中的至少一个CDR,所述VHH包含SEQ ID NO:24所示的氨基酸序列。
46.根据实施方案44-45中任一项所述的融合蛋白,其中所述VHH包含HCDR3,所述HCDR3包含SEQ ID NO:25所示的氨基酸序列。
47.根据实施方案44-46中任一项所述的融合蛋白,其中所述VHH包含HCDR2,所述HCDR2包含SEQ ID NO:26所示的氨基酸序列。
48.根据实施方案44-47中任一项所述的融合蛋白,其中所述VHH包含HCDR1,所述HCDR1包含SEQ ID NO:27所示的氨基酸序列。
49.根据实施方案44-48中任一项所述的融合蛋白,其中所述VHH包含SEQ ID NO:24所示的氨基酸序列。
50.根据实施方案1-49中任一项所述的融合蛋白,其中所述第一结合域包含重链恒定区Fc片段。
51.根据实施方案50所述的融合蛋白,其中所述重链恒定区源自IgG。
52.根据实施方案50-51中任一项所述的融合蛋白,其中所述重链恒定区源自人IgG。
53.根据实施方案51-52中任一项所述的融合蛋白,其中所述IgG选自下组:IgG1和IgG4。
54.根据实施方案50-53中任一项所述的融合蛋白,其中所述重链恒定区Fc片段包含SEQ ID NO:28所示的氨基酸序列。
55.根据实施方案1-55中任一项所述的融合蛋白,其中所述第一结合域位于所述第二结合域的N端。
56.根据实施方案1-55中任一项所述的融合蛋白,其中所述融合蛋白还包含连接子,所述连接子位于所述第一结合域的C端且位于所述第二结合域的N端。
57.根据实施方案56所述的融合蛋白,其中所述连接子包含如SEQ ID NO:29所示的氨基酸序列。
58.根据实施方案1-57中任一项所述的融合蛋白,其包含至少2个所述第二结合域。
59.根据实施方案58所述的融合蛋白,其中每个所述第二结合域分别位于所述第一结合域的C端。
60.根据实施方案1-59中任一项所述的融合蛋白,其包含至少一条多肽链,其中所述多肽链包含SEQ ID NO:30-35中任一项所示的氨基酸序列。
61.根据实施方案1-60中任一项所述的融合蛋白,其包含两条多肽链,所述两条多肽链包含相同的氨基酸序列。
62.免疫缀合物,其包含实施方案1-61中任一项所述的融合蛋白。
63.一个或多个分离的核酸分子,其编码实施方案1-61中任一项所述的融合蛋白或实施方案62所述的免疫缀合物。
64.载体,其包含实施方案63所述的核酸分子。
65.药物组合物,其包含实施方案1-61中任一项所述的融合蛋白,实施方案62所述的免疫缀合物,实施方案63所述的核酸分子,以及任选地药学上可接受的载剂。
66.细胞,其包含实施方案1-61中任一项所述的融合蛋白,实施方案62所述的免疫缀合物,实施方案63所述的核酸分子,或实施方案64所述的载体。
67.制备实施方案1-61中任一项所述的融合蛋白的方法,其包括在使得所述融合蛋白能够表达的条件下培养实施方案66所述的细胞。
68.实施方案1-61中任一项所述的融合蛋白,实施方案62所述的免疫缀合物,实施方案63所述的核酸分子,实施方案64所述的载体,实施方案65所述的药物组合物,或实施方案66所述的细胞在制备药物中的用途,所述药物用于预防和/或治疗疾病和/或病症。
69.根据实施方案68所述的用途,其中所述疾病和/或病症包含与CLDN18.2相关的疾病和/或病症。
70.根据实施方案68-69中任一项所述的用途,其中所述与CLDN18.2相关的疾病和/或病症包括涉及表达CLDN18.2的细胞的疾病或与表达CLDN18.2的细胞相关的疾病。
71.根据实施方案68-70中任一项所述的用途,其中所述疾病和/或病症包括肿瘤。
72.根据实施方案71所述的用途,其中所述肿瘤包括实体瘤和/或非实体瘤。
73.根据实施方案71-72中任一项所述的用途,其中所述肿瘤包括胃癌、食道癌、胰腺癌、肺癌、卵巢癌、结肠癌、肝癌、头颈癌和/或胆囊癌。
不欲被任何理论所限,下文中的实施例仅仅是为了阐释本申请发明的各个技术方案,而不用于限制本申请发明的范围。
实施例
实施例1构建融合蛋白
参照如图1所示的融合蛋白结构,以CS001为例,从N端到C端,选用选择连接子1(氨基酸序列如SEQ ID NO:29所示),依次连接Claudin18.2纳米抗体NA3S-H1、连接子和SIRPα突变体M91N(氨基酸序列如SEQ ID NO:12所示),其中M91N的N端和NA3S-H1的重链的C端通过连接子连接,得到融合蛋白CS001。
CS002、CS003、CS004、CS005、CS006在CS001基础上将M91N按照表1替换成相应的SIRPα突变体002N、M5N、M169N、M82N以及M84N。其中,002N为将SEQ ID NO:23所示的氨基酸序列进行N110A突变所得。
纳米抗体NA3S-H1的HCDR1-3的氨基酸序列分别如SEQ ID NO:27、SEQ ID NO:26和SEQ ID NO:25所示,VHH的氨基酸序列如SEQ ID NO:24所示。IgG Fc的氨基酸序列如SEQ IDNO:28所示。
表1各融合蛋白的构成
实施例2与双抗原结合的活性检测
(1)ELISA评价双功能融合蛋白和CD47的结合活性。
将CD47(CD47 Protein,Human,Recombinant(ECD,His Tag),Sino Biological)包被ELISA板条,4℃过夜;PBST洗涤后,加入10%的胎牛血清,37℃封闭1小时;加入不同浓度的双功能融合蛋白CS001、CS002、CS003、CS004、CS005和CS006,37℃反应1小时;PBST洗涤后,加入辣根过氧化物酶标记的羊抗人IgG Fc二抗(Goat anti-human IgG Fc antibody,horseradish peroxidase(HRP)conjugate,affinity purified,Invitrogen),37℃反应30分钟;PBST洗涤5次;每孔加入100μL TMB(eBioscience),室温(20±5℃)避光放置1~2min;随后每孔加入100μL 2N H
结果如图2所示。图2显示双功能融合蛋白CS001与CD47的结合能力最强,CS002和CS003与CD47的结合能力相似且最弱。
(2)流式评价双功能融合蛋白和CD47阳性细胞株Raji细胞的结合活性。
收集人淋巴瘤肿瘤细胞Raji,按照每管5×10
结果如图3A-3B所示。图3A-3B显示双功能融合蛋白CS001与CD47阳性肿瘤细胞Raji的结合能力最强,CS002与Raji细胞的结合能力最弱。
(3)以Claudin18.2纳米抗体NA3S-H1为对照,流式评价双功能融合蛋白和过表达人Claudin18.2基因的HEK-293T细胞(简称293T/CLDN18.2)的结合活性。
收集293T/CLDN18.2细胞,按照每管5×10
结果如图4所示。图4显示所有双功能融合蛋白与293T/CLDN18.2细胞的结合能力相似,同纳米抗体NA3S-H1。
实施例3阻断CD47/SIRPα相互作用的活性分析
ELISA评价双功能融合蛋白阻断CD47/SIRPα相互作用的生物学活性。
将SIRPα(Recombinant Human SIRPA,Sino Biological)包被酶联板,1ug/ml,4℃过夜;PBST洗涤后,加入10%的胎牛血清,37℃封闭1小时;分别加入不同浓度的双功能融合蛋白CS001、CS002、CS003、CS004、CS005和CS006,37℃反应1小时;PBST洗涤后,加入生物素标记Biotin-CD47(Recombinant Human CD47-biotin,嘉暄生物)至终浓度2ug/ml,37℃反应30min;PBST洗涤5次;加入辣根过氧化物酶标记的亲和素(Streptavidin-HRP,嘉暄生物),37℃孵育30分钟;PBST洗5遍,每孔加入100μL TMB(eBioscience),室温(20±5℃)避光放置1-5min;每孔加入100μL 2N H
从图5中可以看出,双功能融合蛋白CS001竞争性阻断CD47与SIRPα结合的能力最强,CS002的阻断能力最弱。
实施例4ADCC活性分析
以Claudin18.2纳米抗体NA3S-H1为对照,Claudin18.2阳性细胞株293T/CLDN18.2为靶细胞,过表达人FcγRIIIa基因及NFAT荧光报告基因的Jurkat细胞(简称Jurkat-ADCC细胞)为效应细胞,用报告基因法评价双功能融合蛋白的ADCC活性。
收集293T/CLDN18.2细胞,按照每管2×10
结果如图6所示。图6显示所有双功能融合蛋白均具有相似的ADCC活性,且活性同纳米抗体NA3S-H1。
实施例5结合红细胞的活性分析
流式评价双功能融合蛋白和健康人红细胞的结合活性。
收集健康人红细胞,按照每管1×10
结果如图7A-7B所示。图7A-7B显示双功能融合蛋白均可以不同程度的与红细胞结合。CS001与红细胞结合的能力最强,CS003与红细胞结合的能力最弱。
实施例6双功能融合蛋白体内抑制肿瘤活性
利用过表达Claudin18.2基因的HEK-293T细胞(293T/CLDN18.2)异体移植SCID小鼠模型,评价双功能融合蛋白抑制肿瘤活性的效果。
将293T/CLDN18.2细胞接种于雌性SCID小鼠右侧肩部皮下,共接种24只,在肿瘤生长至100mm
结果如图8所示,图8显示,IMAB362、NA3S-H1、M91-Fc、NA3S-H1+M91-Fc、CS001、CS002、CS004组的肿瘤生长抑制率分别为40%、54%、36%、53%、34%、96%、97%,各治疗组肿瘤体积均显著低于空白对照组(p<0.05),显示出显著的抗肿瘤作用,有效地抑制了肿瘤生长。CS002和CS004组肿瘤体积相似,且在所有治疗组中最小,显著低于M91-Fc(p<0.01)、NA3S-H1(p<0.01)及NA3S-H1+M91-Fc组(p<0.05),显示其抑制肿瘤活性优于单药组及联合用药组。治疗期间,荷瘤鼠对测试物IMAB362、NA3S-H1、M91-Fc、NA3S-H1+M91-Fc、CS001、CS002、CS004均表现出很好的耐受性,各组小鼠体重正常,无异常表现,一般状态良好。
前述详细说明是以解释和举例的方式提供的,并非要限制所附权利要求的范围。目前本申请所列举的实施方式的多种变化对本领域普通技术人员来说是显而易见的,且保留在所附的权利要求和其等同方式的范围内。
序列表
<110> 杭州尚健生物技术有限公司、尚健单抗(北京)生物技术有限公司
<120> 包含SIRPα突变体的融合蛋白
<130> 0070-PA-023
<160> 35
<170> PatentIn version 3.5
<210> 1
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M1N
<400> 1
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Ile Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Ile Leu Ile Tyr
354045
Asn Gln Lys Lys Gly His Phe Pro Arg Val Thr Thr Leu Ser Asp Ser
505560
Thr Arg Arg Gly Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Leu Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 2
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M5N
<400> 2
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Val Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Asn Leu Ile Tyr
354045
Asn Ser Arg His Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 3
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M12N
<400> 3
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Phe Pro Ile Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
354045
Asn Gln Arg Lys Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Ile Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 4
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M35N
<400> 4
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Gln Leu Ile Tyr
354045
Asn Gln Lys Asp Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Asn Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Ile Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 5
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M37N
<400> 5
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Ile Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Lys Leu Ile Tyr
354045
Asn Gln Arg Asp Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Gly Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 6
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M41N
<400> 6
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Val Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg His Leu Ile Tyr
354045
Asn Arg Arg His Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Ser Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 7
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M57N
<400> 7
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Ile Leu Ile Tyr
354045
Asn Gly Lys Arg Gly His Phe Pro Arg Val Thr Thr Leu Ser Asp Thr
505560
Thr Lys Arg Gly Asn Met Asp Phe Ser Ile Ser Ile Arg Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Arg Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 8
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M67N
<400> 8
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Met Leu Ile Tyr
354045
Asn Gly Arg Asp Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Leu Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 9
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M81N
<400> 9
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
354045
Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 10
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M82N
<400> 10
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Phe Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
354045
Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser His Ser
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile His Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Ser Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 11
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M84N
<400> 11
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Phe Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
354045
Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser His Ser
505560
Thr Arg Arg Asn Asn Met Asp Phe Ser Ile Arg Ile His Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Ser Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 12
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M91N
<400> 12
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Gln Leu Ile Tyr
354045
Asn Gln Lys Asp Gly His Phe Pro Arg Val Thr Thr Ala Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Asn Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Ile Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 13
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M99N
<400> 13
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Lys Leu Ile Tyr
354045
Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Ser
505560
Thr Lys Arg Lys Asn Met Asp Phe Ser Ile Arg Ile His Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Leu Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 14
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M102N
<400> 14
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Ile Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
354045
Asn Gly Lys Gly Gly His Phe Pro Arg Val Thr Thr Val Ser Arg Ser
505560
Thr Lys Arg Asp Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Ile Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 15
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M111N
<400> 15
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Arg Leu Ile Tyr
354045
Asn Asn Arg Gly Gly His Phe Pro Arg Val Thr Thr Leu Ser Glu Thr
505560
Thr Arg Arg Asp Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Leu Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 16
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M122N
<400> 16
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Val Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Asn Leu Ile Tyr
354045
Asn Ser Arg His Gly His Phe Pro Arg Val Thr Thr Ala Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 17
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M126N
<400> 17
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Val Pro Ile Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu Ile Tyr
354045
Asn Gln Arg Asp Gly His Phe Pro Arg Val Thr Thr Val Ser Glu Thr
505560
Thr Arg Arg Glu Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 18
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M130N
<400> 18
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Ile Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu Ile Tyr
354045
Asn Gln Arg Glu Gly His Phe Pro Arg Val Thr Thr Val Ser Glu Ser
505560
Thr Arg Arg Asp Asn Met Asp Phe Ser Ile Arg Ile Arg Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 19
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M135N
<400> 19
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Val Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Leu Leu Ile Tyr
354045
Asn Gly Lys Gly Gly His Phe Pro Arg Val Thr Thr Leu Ser Glu Thr
505560
Thr Arg Arg Gly Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 20
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M145N
<400> 20
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Leu Pro Ile Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Asn Leu Ile Tyr
354045
Asn Gly Lys Gly Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 21
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> M169N
<400> 21
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Val Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Phe Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Ile Leu Ile Tyr
354045
Asn Arg Arg Gln Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Ile Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 22
<211> 504
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人SIRPa变体1
<400> 22
Met Glu Pro Ala Gly Pro Ala Pro Gly Arg Leu Gly Pro Leu Leu Cys
1 5 1015
Leu Leu Leu Ala Ala Ser Cys Ala Trp Ser Gly Val Ala Gly Glu Glu
202530
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
354045
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro Val Gly
505560
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
65707580
Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
859095
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn Ile Thr
100 105 110
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
115 120 125
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
130 135 140
Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala Arg Ala
145 150 155 160
Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly Phe Ser
165 170 175
Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu Leu Ser
180 185 190
Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser Tyr Ser
195 200 205
Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val His Ser
210 215 220
Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp Pro Leu
225 230 235 240
Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro Thr Leu
245 250 255
Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn Val Thr
260 265 270
Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr Trp Leu
275 280 285
Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val Thr Glu
290 295 300
Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val Asn Val
305 310 315 320
Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu His Asp
325 330 335
Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser Ala His
340 345 350
Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly Ser Asn
355 360 365
Glu Arg Asn Ile Tyr Ile Val Val Gly Val Val Cys Thr Leu Leu Val
370 375 380
Ala Leu Leu Met Ala Ala Leu Tyr Leu Val Arg Ile Arg Gln Lys Lys
385 390 395 400
Ala Gln Gly Ser Thr Ser Ser Thr Arg Leu His Glu Pro Glu Lys Asn
405 410 415
Ala Arg Glu Ile Thr Gln Asp Thr Asn Asp Ile Thr Tyr Ala Asp Leu
420 425 430
Asn Leu Pro Lys Gly Lys Lys Pro Ala Pro Gln Ala Ala Glu Pro Asn
435 440 445
Asn His Thr Glu Tyr Ala Ser Ile Gln Thr Ser Pro Gln Pro Ala Ser
450 455 460
Glu Asp Thr Leu Thr Tyr Ala Asp Leu Asp Met Val His Leu Asn Arg
465 470 475 480
Thr Pro Lys Gln Pro Ala Pro Lys Pro Glu Pro Ser Phe Ser Glu Tyr
485 490 495
Ala Ser Val Gln Val Pro Arg Lys
500
<210> 23
<211> 117
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 人野生型SIRPα截短结构域(第33-149位)
<400> 23
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
1 5 1015
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro Val Gly
202530
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
354045
Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
505560
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn Ile Thr
65707580
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
859095
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
100 105 110
Arg Ala Lys Pro Ser
115
<210> 24
<211> 120
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> CLDN18.2VHH
<400> 24
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 1015
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Asn Ile Pro
202530
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
354045
Ala Gly Ile Ser Thr Gly Gly Thr Thr Asn Tyr Gly Asp Ser Val Lys
505560
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65707580
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
859095
Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 25
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> HCDR3(IMGT)
<400> 25
Asn Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val
1 5 10
<210> 26
<211> 7
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> HCDR2(IMGT)
<400> 26
Ile Ser Thr Gly Gly Thr Thr
1 5
<210> 27
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> HCDR1(IMGT)
<400> 27
Gly Ser Ile Phe Asn Ile Pro Val
1 5
<210> 28
<211> 232
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> IgG1-Fc
<400> 28
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
1 5 1015
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
202530
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
354045
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
505560
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
65707580
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
859095
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
100 105 110
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
115 120 125
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
130 135 140
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
145 150 155 160
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
165 170 175
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
180 185 190
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
195 200 205
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
210 215 220
Ser Leu Ser Leu Ser Pro Gly Lys
225 230
<210> 29
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> 连接子
<400> 29
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 30
<211> 479
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> CS001
<400> 30
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 1015
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Asn Ile Pro
202530
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
354045
Ala Gly Ile Ser Thr Gly Gly Thr Thr Asn Tyr Gly Asp Ser Val Lys
505560
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65707580
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
859095
Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Glu Pro Lys Ser Cys Asp Lys Thr
115 120 125
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
165 170 175
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Leu Gln Val Ile Gln
355 360 365
Pro Asp Lys Ser Val Leu Val Ala Ala Gly Glu Thr Ala Thr Leu Arg
370 375 380
Cys Thr Ala Thr Ser Leu Leu Pro Val Gly Pro Ile Gln Trp Phe Arg
385 390 395 400
Gly Ala Gly Pro Gly Arg Gln Leu Ile Tyr Asn Gln Lys Asp Gly His
405 410 415
Phe Pro Arg Val Thr Thr Ala Ser Asp Leu Thr Lys Arg Asn Asn Met
420 425 430
Asp Phe Ser Ile Asn Ile Gly Ala Ile Thr Pro Ala Asp Ala Gly Thr
435 440 445
Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser Pro Asp Asp Ile Glu Phe
450 455 460
Lys Ser Gly Ala Gly Thr Glu Leu Ser Val Arg Ala Lys Pro Ser
465 470 475
<210> 31
<211> 479
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> CS002
<400> 31
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 1015
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Asn Ile Pro
202530
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
354045
Ala Gly Ile Ser Thr Gly Gly Thr Thr Asn Tyr Gly Asp Ser Val Lys
505560
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65707580
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
859095
Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Glu Pro Lys Ser Cys Asp Lys Thr
115 120 125
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
165 170 175
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Leu Gln Val Ile Gln
355 360 365
Pro Asp Lys Ser Val Leu Val Ala Ala Gly Glu Thr Ala Thr Leu Arg
370 375 380
Cys Thr Ala Thr Ser Leu Ile Pro Val Gly Pro Ile Gln Trp Phe Arg
385 390 395 400
Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr Asn Gln Lys Glu Gly His
405 410 415
Phe Pro Arg Val Thr Thr Val Ser Asp Leu Thr Lys Arg Asn Asn Met
420 425 430
Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr Pro Ala Asp Ala Gly Thr
435 440 445
Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser Pro Asp Asp Val Glu Phe
450 455 460
Lys Ser Gly Ala Gly Thr Glu Leu Ser Val Arg Ala Lys Pro Ser
465 470 475
<210> 32
<211> 479
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> CS003
<400> 32
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 1015
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Asn Ile Pro
202530
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
354045
Ala Gly Ile Ser Thr Gly Gly Thr Thr Asn Tyr Gly Asp Ser Val Lys
505560
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65707580
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
859095
Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Glu Pro Lys Ser Cys Asp Lys Thr
115 120 125
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
165 170 175
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Leu Gln Val Ile Gln
355 360 365
Pro Asp Lys Ser Val Leu Val Ala Ala Gly Glu Thr Ala Thr Leu Arg
370 375 380
Cys Thr Ala Thr Ser Leu Val Pro Val Gly Pro Ile Gln Trp Phe Arg
385 390 395 400
Gly Ala Gly Pro Gly Arg Asn Leu Ile Tyr Asn Ser Arg His Gly His
405 410 415
Phe Pro Arg Val Thr Thr Val Ser Asp Leu Thr Lys Arg Asn Asn Met
420 425 430
Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr Pro Ala Asp Ala Gly Thr
435 440 445
Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser Pro Asp Asp Val Glu Phe
450 455 460
Lys Ser Gly Ala Gly Thr Glu Leu Ser Val Arg Ala Lys Pro Ser
465 470 475
<210> 33
<211> 479
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> CS004
<400> 33
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 1015
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Asn Ile Pro
202530
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
354045
Ala Gly Ile Ser Thr Gly Gly Thr Thr Asn Tyr Gly Asp Ser Val Lys
505560
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65707580
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
859095
Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Glu Pro Lys Ser Cys Asp Lys Thr
115 120 125
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
165 170 175
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Leu Gln Val Ile Gln
355 360 365
Pro Asp Lys Ser Val Val Val Ala Ala Gly Glu Thr Ala Thr Leu Arg
370 375 380
Cys Thr Ala Thr Ser Leu Phe Pro Val Gly Pro Ile Gln Trp Phe Arg
385 390 395 400
Gly Ala Gly Pro Gly Arg Ile Leu Ile Tyr Asn Arg Arg Gln Gly His
405 410 415
Phe Pro Arg Val Thr Thr Val Ser Asp Leu Thr Lys Arg Asn Asn Met
420 425 430
Asp Phe Ser Ile Arg Ile Gly Ala Ile Thr Pro Ala Asp Ala Gly Thr
435 440 445
Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser Pro Asp Asp Ile Glu Phe
450 455 460
Lys Ser Gly Ala Gly Thr Glu Leu Ser Val Arg Ala Lys Pro Ser
465 470 475
<210> 34
<211> 479
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> CS005
<400> 34
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 1015
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Asn Ile Pro
202530
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
354045
Ala Gly Ile Ser Thr Gly Gly Thr Thr Asn Tyr Gly Asp Ser Val Lys
505560
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65707580
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
859095
Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Glu Pro Lys Ser Cys Asp Lys Thr
115 120 125
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
165 170 175
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Leu Gln Val Ile Gln
355 360 365
Pro Asp Lys Ser Val Leu Val Ala Ala Gly Glu Thr Ala Thr Leu Arg
370 375 380
Cys Thr Ala Thr Ser Leu Phe Pro Val Gly Pro Ile Gln Trp Phe Arg
385 390 395 400
Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr Asn Gln Lys Glu Gly His
405 410 415
Phe Pro Arg Val Thr Thr Val Ser His Ser Thr Lys Arg Asn Asn Met
420 425 430
Asp Phe Ser Ile Arg Ile His Ala Ile Thr Pro Ala Asp Ala Gly Thr
435 440 445
Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser Pro Asp Asp Ser Glu Phe
450 455 460
Lys Ser Gly Ala Gly Thr Glu Leu Ser Val Arg Ala Lys Pro Ser
465 470 475
<210> 35
<211> 479
<212> PRT
<213> 人工序列(Artificial Sequence)
<220>
<223> CS006
<400> 35
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 1015
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Asn Ile Pro
202530
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
354045
Ala Gly Ile Ser Thr Gly Gly Thr Thr Asn Tyr Gly Asp Ser Val Lys
505560
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65707580
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
859095
Val Leu Val Val Ser Gly Ile Gly Ser Thr Leu Glu Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Glu Pro Lys Ser Cys Asp Lys Thr
115 120 125
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
130 135 140
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
145 150 155 160
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
165 170 175
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
180 185 190
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
195 200 205
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
210 215 220
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
225 230 235 240
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
245 250 255
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
260 265 270
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
275 280 285
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
290 295 300
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
305 310 315 320
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
325 330 335
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Leu Gln Val Ile Gln
355 360 365
Pro Asp Lys Ser Val Leu Val Ala Ala Gly Glu Thr Ala Thr Leu Arg
370 375 380
Cys Thr Ala Thr Ser Leu Phe Pro Val Gly Pro Ile Gln Trp Phe Arg
385 390 395 400
Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr Asn Gln Lys Glu Gly His
405 410 415
Phe Pro Arg Val Thr Thr Val Ser His Ser Thr Arg Arg Asn Asn Met
420 425 430
Asp Phe Ser Ile Arg Ile His Ala Ile Thr Pro Ala Asp Ala Gly Thr
435 440 445
Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser Pro Asp Asp Ser Glu Phe
450 455 460
Lys Ser Gly Ala Gly Thr Glu Leu Ser Val Arg Ala Lys Pro Ser
465 470 475
- SIRPα变体或其融合蛋白及其应用
- SIRPα突变体及其融合蛋白
- 一种靶向CD47的高亲和力SIRPα突变体及其融合蛋白