用于虚拟现实应用的音频传递优化
文献发布时间:2024-04-18 19:52:40
本申请是申请日为2018年10月11日的PCT国际申请PCT/EP2018/077770在2020年6月11日向中国专利局递交并进入中国国家阶段后对应的题为“用于虚拟现实应用的音频传递优化”的发明专利申请No.201880080196.6的分案申请。
背景技术
说明
介绍
在虚拟现实(VR)环境中或类似地在增强现实(AR)或混合现实(MR)或360度视频环境中,用户通常可以使用例如头戴式显示器(HMD)来可视化完全360度内容并通过耳机(或类似地通过扩音器,包括取决于其位置的正确渲染)收听。
在简单的用例中,以这样的方式授权内容:在特定的时间点仅再现一个音频/视频场景(例如,360度视频)。音频/视频场景具有固定位置(例如,用户位于中心的球体),并且用户可能不在场景中移动,而是仅在各种方向(偏航、俯仰、横滚)上旋转他的头部。在这种情况下,基于用户头部的取向向用户播放不同的视频和音频(显示不同的视口)。
然而,对于视频,视频内容连同用于描述渲染过程的元数据(例如,拼接信息、投影映射等)一起被传送用于整个360度场景,并基于当前用户的视口进行选择,对于音频,针对整个场景内容都一样。基于元数据,音频内容适应于当前用户的视口(例如,基于视口/用户取向信息,音频对象被不同地呈现)。应当注意,360度内容是指用户可以(例如通过用户头部取向或通过使用遥控器)从其选择的包括相同时刻处的一个以上视角的任何类型的内容。
在更复杂的场景中,当用户可以在VR场景中移动或从一个场景“跳”到下一个场景时,音频内容也可能改变(例如,在一个场景中不可听见的音频源可能在下一个场景听得见-“门被打开”)。使用现有系统,可以将完整的音频场景编码为一个流,并且如果需要,还可以编码为附加流(取决于主流)。这样的系统被称为下一代音频系统(例如,MPEG-H 3D音频)。这种用例的示例可以包含:
·示例1:用户选择进入新房间,并且整个音频/视频场景改变
·示例2:用户在VR场景中移动、打开门并走过去,意味着需要将音频从一个场景转变到下一个场景
为了描述该场景,空间中的离散视点的概念被引入,作为空间中(或VR环境中)的离散位置,针对所述离散位置,不同的音频/视频内容是可用的。
“直接”方案将具有实时编码器,该实时编码器基于来自回放设备的关于用户位置/取向的反馈来改变编码(音频元素的数量、空间信息等)。该方案意味着例如在流环境中客户端与服务器之间的非常复杂的通信:
·客户端(通常假定仅使用简单的逻辑)将需要先进的机制,以不仅传达对不同流的请求,而且传达与将基于用户的位置来实现正确内容的处理的编码细节有关的复杂信息。
·媒体服务器通常预先填充有不同的流(以允许“分段方式”传递的特定方式格式化),并且服务器的主要功能是提供有关可用流的信息并在被请求时引起它们的传递。为了实现允许基于来自回放设备的反馈进行编码的场景,媒体服务器将需要与多个实时媒体编码器的先进通信链路,以及即时(on the fly)创建可能实时改变的所有信令信息(例如,媒体表示描述)的能力。
尽管可以想象这样的系统,但是其复杂性和计算要求超出了当今可用的设备和系统的功能和特性,或者甚至将在未来几十年内开发出来。
备选地,表示完整的VR环境(“完整的世界”)的内容可以一直传递。这将解决问题,但将需要超出可用通信链路能力的巨大比特率。
对于实时环境,这很复杂,并且为了使用可用系统来实现这样的用例,提出了以较低复杂度实现该功能的备选方案。
2.术语和定义
在技术领域中使用以下术语:
·音频元素:可以表示为例如音频对象、音频通道、基于场景的音频(高阶环境立体声-HOA)或全部中的任意组合的音频信号。
·感兴趣区域(ROI):在某一时刻用户感兴趣的视频内容(或显示或模拟的环境)的一个区域。这通常可以是例如球体上的区域,或者是来自2D地图的多边形选择。ROI针对特定目的识别特定区域,定义所考虑的对象的边界。
·用户位置信息:位置信息(例如,x、y、z坐标)、取向信息(偏航、俯仰、横滚)以及移动方向和速度等。
视口:当前显示和用户查看的部分球形视频。
·视点:视口的中心点。
·360度视频(也称为沉浸式视频或球形视频):在本文档的上下文中表示一种视频内容,该视频内容包含在相同时刻在一个方向上的一个以上的视图(即,视口)。可以例如使用全向相机或相机集合来创建这样的内容。在回放期间,观看者可以控制观看方向。
·媒体呈现描述(MPD)是一种包含有关媒体分段的信息、它们之间的关系以及在它们之间进行选择所必需的信息的语法例如XML。
·适应集包含媒体流或媒体流集。在最简单的情况下,一个适应集包含内容的所有音频和视频,但是为了减少带宽,可以将每个流拆分为不同的适应集。常见的情况是具有一个视频适应集和多个音频适应集(每个针对每一种支持的语言)。适应集还可以包含字幕或任意元数据。
·表示(Representation)允许适应集包含以不同方式编码的相同内容。在大多数情况下,将以多种比特率提供表示。这允许客户端请求他们可以播放的最高质量的内容,而不必等待缓冲。表示也可以使用不同的编解码器进行编码,允许支持具有不同支持的编解码器的客户端。
在本申请的上下文中,适应集的概念被更通用地使用,有时实际上是指表示。此外,通常将媒体流(音频/视频流)首先封装到媒体片段中,该媒体片段是由客户端(例如,DASH客户端)播放的实际媒体文件。各种格式可以用于媒体片段,例如类似于MPEG-4容器格式的ISO基本媒体文件格式(ISOBMFF)或MPEG-2传输流(TS)。封装到媒体片段中和封装在不同的表示/适应集中与本文中描述的方法无关,这些方法适用于所有各种选项。
此外,本文档中方法的描述以DASH服务器-客户端通信为中心,但是这些方法具有足以可以与其他传递环境(例如MMT、MPEG-2TS、DASH-ROUTE、用于文件播放的文件格式等)一起使用的通用性。
一般而言,适应集相对于流在较高层,并且可以包括元数据(例如,与位置相关联)。流可以包括多个音频元素。音频场景可以与作为多个适应集的一部分传递的多个流相关联。
3.当前方案
当前方案是:
[1].ISO/IEC 23008-3:2015,Information technology--High efficiencycoding and media delivery in heterogeneous environments--Part 3:3D audio
[2].N16950,Study of ISO/IEC DIS 23000-20Omnidirectional Media Format。
当前方案仅限于在一个固定位置处提供独立的VR体验,这允许用户改变其取向但不能在VR环境中移动。
发明内容
根据实施例,用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的系统可以被配置为接收要在媒体消费设备中再现的视频和音频流,其中所述系统可以包括:至少一个媒体视频解码器,被配置为解码来自视频流的视频信号,以向用户表示VR、AR、MR或360度视频环境场景,以及至少一个音频解码器,被配置为从至少一个音频流中解码音频信号,其中,所述系统可以被配置为:至少基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,向服务器请求至少一个音频流和/或音频流的一个音频元素和/或一个适应集。
根据一个方面,系统可以被配置为:向服务器提供用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,以获得来自服务器的至少一个音频流和/或音频流的一个音频元素和/或一个适应集。
实施例可以被配置为使得至少一个场景与至少一个音频元素相关联,每个音频元素与其中音频元素是可听见的视觉环境中的位置和/或区域相关联,使得针对不同用户的位置和/或视口和/或头部取向和/或移动数据和/或交互元数据和/或场景中的虚拟位置数据,提供不同的音频流。
根据另一方面,系统可以被配置为针对当前用户的视口和/或头部取向和/或移动数据和/或交互元数据和/或场景中的虚拟位置,决定是否要再现音频流的至少一个音频元素和/或一个适应集,并且其中系统可以被配置为请求和/或接收在当前用户的虚拟位置处的所述至少一个音频元素。
根据另一方面,系统可以被配置为至少基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,来预测性地决定音频流的至少一个音频元素和/或一个适应集是否将变得相关和/或可听见,并且其中,系统可以被配置为在预测的用户在场景中的移动和/或交互之前,请求和/或接收在特定用户的虚拟位置处的至少一个音频元素和/或音频流和/或适应集,其中,系统可以被配置为在用户在场景中的移动和/或交互之后,当接收到至少一个音频元素和/或语音流时,在特定的用户虚拟位置处再现至少一个音频元素和/或音频流。
系统的实施例可以被配置为在用户在场景中的移动和/或交互之前,在用户的虚拟位置处,以较低的比特率和/或质量水平请求和/或接收至少一个音频元素,其中系统可以被配置为在用户在场景中的移动和/或交互之后,在用户的虚拟位置处,以较高的比特率和/或质量水平来请求和/或接收至少一个音频元素。
根据一个方面,系统可以被配置为使得至少一个音频元素与至少一个场景相关联,每个音频元素与在与场景相关联的视觉环境中的位置和/或区域相关联,其中,系统可以被配置为针对与距用户更远的音频因素相比距用户更近的音频元素,以较高的比特率和/或质量水平来请求和/或接收流。
根据一个方面,在系统中,至少一个音频元素可以与至少一个场景相关联,至少一个音频元素与在与场景相关联的视觉环境中的位置和/或区域相关联,其中系统可以被配置为基于在场景中每个用户的虚拟位置处的音频元素的相关性和/或可听性水平,针对音频元素以不同的比特率和/或质量水平来请求不同的流,其中系统可以被配置为针对在当前用户的虚拟位置处为较大相关和/或较大可听的音频元素,以较高的比特率和/或质量水平来请求音频流,和/或针对在当前用户的虚拟位置处为较小相关和/或较小可听的音频元素,以较低的比特率和/或质量水平来请求音频流。
在实施例中,在系统中,至少一个音频元素可以与场景相关联,每个音频元素与视觉环境中与场景相关联的位置和/或区域相关联,其中系统可以被配置为向服务器周期性地发送用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,以:针对第一位置,从服务器提供较高比特率和/或质量的流,并且针对第二位置,从服务器提供较低比特率和/或质量的流,其中第一位置比第二位置更靠近至少一个音频元素。
在实施例中,在系统中,可以针对诸如邻近和/或相邻环境等的多个视觉环境来定义多个场景,从而提供与第一当前场景相关联的第一流,并且在到另一第二场景的用户转换的情况下,提供与第一场景相关联的流和与第二场景相关联的第二流两者。
在实施例中,在系统中,可以针对第一和第二视觉环境定义多个场景,第一和第二环境是邻近和/或相邻的环境,其中,在用户的位置或虚拟位置处于与第一场景相关联的第一环境中的情况下,从服务器提供与第一场景相关联的第一流以用于再现第一场景,在用户的位置或虚拟位置处于与第二场景相关联的第二环境中的情况下,从服务器提供与第二场景相关联的第二流以用于再现第二场景,以及在用户的位置或虚拟位置处于第一场景与第二场景之间的转换位置中的情况下,提供与第一场景相关联的第一流和与第二场景相关联的第二流两者。
在实施例中,在系统中,可以针对第一和第二视觉环境定义多个场景,第一和第二视觉环境是邻近和/或相邻的环境,其中,系统被配置为在用户的虚拟位置处于第一环境中的情况下,请求和/或接收与关联到第一环境的第一场景相关联的第一流,以用于再现第一场景,其中,系统可以被配置为在用户的虚拟位置处于第二环境中的情况下,请求和/或接收与关联到第二环境的第二场景相关联的第二流,以用于再现第二场景,以及其中,系统可以被配置为在用户的虚拟位置处于第一环境与第二环境之间的转换位置中的情况下,请求和/或接收与第一场景相关联的第一流和与第二场景相关联的第二流两者。
根据一个方面,系统可以被配置为使得当用户处于与第一场景相关联的第一环境中时,以较高的比特率和/或质量获得与第一场景相关联的第一流,而当用户处于从第一场景到第二场景的转换位置的开始时,以较低的比特率和/或质量获得与关联到第二环境的第二场景相关联的第二流,并且当用户处于从第一场景到第二场景的转换位置的末端时,以较低的比特率和/或质量获得与第一场景相关联的第一流,并且以较高的比特率和/或质量获得与第二场景相关联的第二流,其中较低的比特率和/或质量比较高的比特率和/或质量低。
根据一个方面,系统可以被配置为使得针对多个环境(例如,邻近和/或相邻环境)来定义多个场景,使得系统可以被配置为获得与关联到第一当前环境的第一当前场景相关联的流,以及在用户的位置或虚拟位置距场景的边界的距离低于预定阈值的情况下,系统还可以获得与关联到第二场景的第二邻近和/或相邻环境相关联的音频流。
根据一个方面,系统可以被配置为使得可以针对多个视觉环境定义多个场景,从而系统以较高的比特率和/或质量请求和/或获得与当前场景相关联的流并且以较低的比特率和/或质量请求和/或获得与第二场景相关联的流,其中较低的比特率和/或质量低于较高的比特率和/或质量。
根据一个方面,系统可以被配置为使得可以定义多个N个音频元素,并且在用户到这些音频元素的位置或区域的距离大于预定阈值的情况下,对N个音频元素进行处理以获得与靠近N个音频元素的位置或区域的位置或区域相关联的较少数量的M个音频元素(M<N),以在用户到N个音频元素的位置或区域的距离小于预定阈值的情况下,向系统提供与N个音频元素相关联的至少一个音频流,或者在用户到N个音频元素的位置或区域的距离大于预定阈值的情况下,向系统提供与M个音频元素相关联的至少一个音频流。
根据一个方面,系统可以被配置为使得至少一个视觉环境场景与至少一个多个N个音频元素(N>=2)相关联,每个音频元素与视觉环境中的位置和/或区域相关联,其中以高比特率和/或质量水平以至少一个表示来提供至少至少一个多个N个音频元素,并且其中以低比特率和/或质量水平以至少一个表示来提供至少至少一个多个N个音频元素,其中通过处理N个音频元素以获得与靠近N个音频元素的位置或区域的位置或区域相关联的较少数量的M个音频元素(M<N)来获得至少一个表示,其中,系统可以被配置为在场景中当前用户的虚拟位置处音频元素为较大相关和/或较大可听的情况下,针对音频元素以较高的比特率和/或质量水平来请求表示,其中,在场景中当前用户的虚拟位置处音频元素为较小相关和/或较小可听的情况下,系统可以被配置为针对音频元素以较低的比特率和/或质量水平来请求表示。
根据一个方面,系统可以被配置为使得在用户的距离和/或相关性和/或可听性水平和/或角度取向低于预定阈值的情况下,针对不同的音频元素来获得不同的流。
在实施例中,系统可以被配置为基于用户的取向和/或用户的移动方向和/或场景中的用户交互来请求和/或获得流。
在系统的实施例中,视口可以与位置和/或虚拟位置和/或移动数据和/或头部相关联。
根据一个方面,系统可以被配置为使得在不同的视口处提供不同的音频元素,其中,系统可以被配置为:在一个第一音频元素落入视口内的情况下,相比未落入视口的第二音频元素,以更高的比特率请求和/或接收第一音频元素。
根据一个方面,系统可以被配置为请求和/或接收第一音频流和第二音频流,其中,第一音频流中的第一音频元素比第二音频流中的第二音频元素更大相关和/或更大可听,其中以比第二音频流的比特率和/或质量更高的比特率和/或质量来请求和/或接收第一音频流。
根据一个方面,系统可以被配置为使得定义至少两个视觉环境场景,其中至少一个第一和第二音频元素与关联到第一视觉环境的第一场景相关联,并且至少一个第三音频元素与关联到第二视觉环境的第二场景相关联,其中系统可以被配置为获取描述至少一个第二音频元素另外与第二视觉环境场景相关联的元数据,并且其中,在用户的虚拟位置处于第一视觉环境中的情况下,系统可以被配置为请求和/或接收至少第一和第二音频元素,并且其中,在用户的虚拟位置处于第二视觉环境场景中的情况下,系统可以被配置为请求和/或接收至少第二和第三音频元素,并且其中,在用户的虚拟位置处于第一视觉环境场景和第二视觉环境场景之间转换中的情况下,系统可以被配置为请求和/或接收至少第一、第二和第三音频元素。
在一个实施例中,系统可以被配置为使得在至少一个音频流和/或适应集中提供至少一个第一音频元素,并且在至少一个第二音频流和/或适应集中提供至少一个第二音频元素,并且在至少一个第三音频流和/或适应集中提供至少一个第三音频元素,并且其中至少第一视觉环境场景由元数据描述为需要至少第一和第二音频流和/或适应集的完整场景,并且其中第二视觉环境场景由元数据描述为需要至少第三音频流和/或适应集以及与至少第一视觉环境场景相关联的至少第二音频流和/或适应集的不完整的场景,其中,系统包括元数据处理器,该元数据处理器被配置为在用户的虚拟位置处于第二视觉环境中的情况下,操控元数据以允许将属于第一视觉环境的第二音频流和与第二视觉环境相关联的第三音频流合并为新的单个流。
根据一个方面,系统包括元数据处理器,该元数据处理器被配置为基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,在至少一个音频解码器之前操控至少一个音频流中的元数据。
根据一个方面,元数据处理器可以被配置为基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,来在至少一个音频解码器之前启用和/或禁用至少一个音频流中的至少一个音频元素,其中元数据处理器可以被配置为在由于当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据而系统决定不再再现音频元素的情况下,在至少一个音频解码器之前禁用至少一个音频流中的至少一个音频元素,并且其中元数据处理器可以被配置为在由于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据而系统决定将再现音频元素的情况下,在至少一个音频解码器之前启用至少一个音频流中的至少一个音频元素。
根据一个方面,系统可以被配置为禁用对基于用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置而选择的音频元素的解码。
根据一个方面,系统可以被配置为将与当前音频场景相关联的至少一个第一音频流合并到与相邻、邻近和/或未来音频场景相关联的至少一个流。
根据一个方面,所述系统可以被配置为获取和/或收集关于用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据的统计或聚合数据,以向服务器发送与统计或聚合数据相关联的请求。
根据一个方面,系统可以被配置为基于与至少一个流相关联的元数据并且基于用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据,不激活至少一个流的解码和/或再现。
根据一方面,系统可以被配置为:至少基于用户的当前或估计的视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据,来操控与选择的音频流组相关联的元数据,以:选择和/或启用和/或激活合成要再现的音频场景的音频元素;和/或允许将所有选择的音频流合并为单个音频流。
根据一个方面,系统可以被配置为基于用户的位置距与不同场景相关联的相邻和/或邻近环境的边界的距离或与用户在当前环境中的位置相关联的度量或对未来环境的预测,来控制向服务器对至少一个流的请求。
根据系统的一个方面,针对每个音频元素或音频对象,从服务器系统提供信息,其中,信息包括关于其中声音场景或音频元素是活动的位置的描述性信息。
根据一个方面,系统可以被配置为基于当前或未来或视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置和/或用户的选择,在再现一个场景与合成或混合或复用或叠加或组合至少两个场景之间进行选择,两个场景与不同的相邻和/或邻近环境相关联。
根据一个方面,系统可以被配置为至少创建或使用适应集,使得:多个适应集与一个音频场景相关联;和/或提供将每个适应集与一个视点或一个音频场景相关联的附加信息;和/或提供可以包括以下项的附加信息:关于一个音频场景的边界的信息和/或关于一个适应集与一个音频场景之间的关系的信息(例如,音频场景被编码在三个流中,所述三个流被封装在三个适应集中)和/或关于音频场景的边界与多个适应集之间的连接的信息。
根据一个方面,系统可以被配置为:接收针对与相邻或邻近环境相关联的场景的流;在检测到两个环境之间的边界的转换时,开始解码和/或再现用于相邻或邻近环境的流。
根据一个方面,系统可以被配置为包括作为客户端和服务器进行操作,所述服务器被配置为传递要在媒体消费设备中再现的视频和/音频流。
根据一个方面,系统可以被配置为:请求和/或接收至少一个第一适应集,所述第一适应集包括与至少一个第一音频场景相关联的至少一个音频流;请求和/或接收至少一个第二适应集,所述第二适应集包括与至少两个音频场景相关联的至少一个第二音频流,所述至少两个音频场景包括至少一个第一音频场景;以及基于与用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据和/或描述至少一个第一适应集与至少一个第一音频场景的关联的信息和/或至少一个第二适应集与至少一个第一音频场景的关联有关的可用的元数据,使至少一个第一音频流和至少一个第二音频流合并为要解码的新的音频流。
根据一个方面,系统可以被配置为接收关于用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据和/或表征由用户的动作触发的变化的任何信息的信息;以及接收关于适应集的可用性的信息以及描述至少一个适应集与至少一个场景和/或视点和/或视口和/或位置和/或虚拟位置和/或移动数据和/或取向的关联的信息。
根据一个方面,系统可以被配置为:决定是否要再现嵌入在至少一个流中的来自至少一个音频场景的至少一个音频元素和嵌入在至少一个附加流中的来自至少一个附加音频场景的至少一个附加音频元素;以及在肯定的决定的情况下,引起将附加音频场景的至少一个附加流合并或合成或复用或叠加或组合到至少一个音频场景的至少一个流的操作。
根据一方面,系统可以被配置为:至少基于用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据,来操控与选择的音频流相关联的音频元数据,以:选择和/或启用和/或激活合成决定要再现的音频场景的音频元素;以及使得能够将所有选择的音频流合并为单个音频流。
根据一个方面,可以提供服务器,用于将音频和视频流传递到用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的客户端,将在媒体消费设备中再现视频和音频流,其中,服务器可以包括用于编码的编码器和/或用于对描述视觉环境的视频流进行存储的存储器,视觉环境与音频场景相关联;其中,服务器还可以包括用于编码的编码器和/或存储器,所述存储器用于存储要被传递给客户端的多个流和/或音频元素和/或适应集,流和/或音频元素和/或适应集与至少一个音频场景相关联,其中,服务器被配置为:基于来自客户端的请求来选择并传递视频流,视频流与环境相关联;基于来自客户端的请求,选择音频流和/或音频元素和/或适应集,所述请求至少与用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据相关联以及与关联到环境的音频场景相关联;以及向客户端传递音频流。
根据一个方面,流可以被封装到适应集中,每个适应集包括与相同音频内容的具有不同比特率和/或质量的不同表示相关联的多个流,其中,基于来自客户端的请求来选择所选择的适应集。
根据一个方面,系统可以作为客户端和服务器进行操作。
根据一个方面,系统可以包括服务器。
根据一个方面,可以提供一种用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的方法,该方法被配置为接收要在媒体消费设备(例如,回放设备)中再现的视频和/或音频流,包括:从视频流中解码视频信号,以向用户表示VR、AR、MR或360度视频环境场景,以及从音频流中解码音频信号,其中基于用户的当前视口和/或位置数据和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据和/或元数据,向服务器请求和/或从服务器获取至少一个音频流。
根据一个方面,可以提供计算机程序,该计算机程序包括指令,该指令当由处理器执行时使处理器执行上述方法。
附图说明
图1.1至图1.8示出本发明的示例。
图2a至图6示出本发明的场景。
图7a至图8b示出本发明的方法。
具体实施方式
本发明的方面
在下文中(例如,图1.1至图1.8),公开了根据本发明的方面的系统的示例。
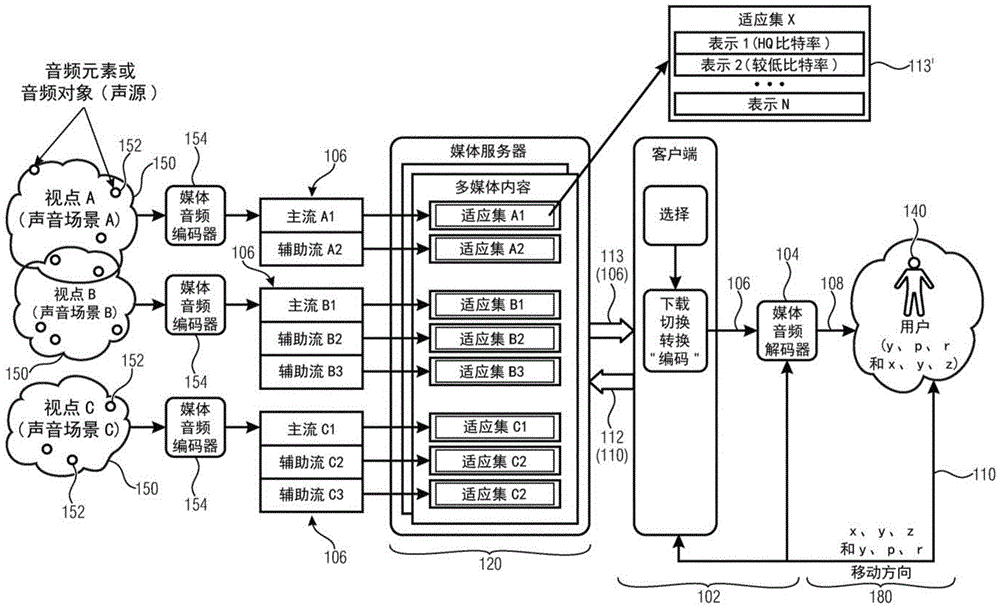
本发明的系统的示例(可以由以下公开的不同示例来体现)用102统一表示。系统102可以是例如客户端系统,因为它可以从服务器系统(例如,120)获得音频和/或视频流,以向用户表示音频场景和/或视觉环境。客户端系统102还可以从服务器系统120接收元数据,该元数据提供例如关于音频和/或视频流的副和/或辅助信息。
系统102可以与媒体消费设备(MCD)相关联(或在一些示例中包括媒体消费设备),该媒体消费设备实际向用户再现音频和/或视频信号。在一些示例中,用户可以佩戴MCD。
系统102可以执行对服务器系统120的请求,该请求与至少一个用户的当前视口(viewport)和/或头部取向(例如,角度取向)和/或移动数据和/或交互元数据和/或虚拟位置数据110(可以提供几个度量)相关联。视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据110可以在来自MCD的反馈中提供给客户端系统102,客户端系统102进而可以基于该反馈向服务器系统120提供请求。
在某些情况下,请求(由112指示)可以包含用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据110(或其指示或处理版本)。基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据110,服务器系统120将提供所需的音频和/或视频流和/或元数据。在这种情况下,服务器系统120可以具有用户的位置(例如,在虚拟环境中)的知识,并且可以将正确的流与用户的位置相关联。
在其他情况下,来自客户端系统102的请求112可以包含对特定音频和/或视频流的显式请求。在这种情况下,请求112可以基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据110。客户端系统102具有了必须向用户呈现的音频和视频信号的知识,即使客户端系统102不具有存储在其中的必需的流。在示例中,客户端系统102可以寻址服务器系统120中的特定流。
客户端系统102可以是用于虚拟现实VR、增强现实AR、混合现实MR、或被配置为接收要在媒体消费设备中再现的视频和音频流的360度视频环境的系统,
其中系统102包括:
至少一个媒体视频解码器,被配置为解码来自视频流的视频信号,以向用户表示VR、AR、MR或360度视频环境场景,以及
至少一个音频解码器104,被配置为解码来自至少一个音频流106的音频信号(108),
其中系统102被配置为至少基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据110向服务器120请求112至少一个音频流106和/或音频流的一个音频元素和/或一个适应集。
应当注意,在VR、AR、MR环境中,用户140可以意味着处于特定环境(例如,特定房间)中。使用例如在服务器侧(服务器系统120侧,该服务器侧不必一定包括服务器系统120,但是可以包括先前已经编码了视频流的不同的编码器,该视频流此后已经被存储在服务器120的存储器中)编码的视频信号来描述环境。在某些示例中,在每个瞬间,用户可能仅欣赏一些视频信号(例如,视口)。
一般而言,每个环境可以与特定的音频场景相关联。音频场景可以理解为在特定环境中并且在特定时间段内将被再现给用户的所有声音的集合。
传统上,已经将环境理解为处于离散的数量。因此,已经将环境的数量理解为有限的。出于相同的原因,已经将音频场景的数量理解为有限的。因此,在现有技术中,VR、AR、MR系统已经被设计为使得:
-用户每次都打算在一个单个环境中;因此,对于每种环境:
o客户端系统102仅向服务器系统120请求与单个环境相关联的视频流;
o客户端系统102仅向服务器系统120请求与单个场景相关联的音频流。
这种方法带来了不便。
例如,对于每个场景/环境,音频流将全部一起被传递到客户端系统102,并且当用户移动到不同的环境时(例如,当用户通过门,因此暗示着环境/场景的传输时)需要传递完全新的音频流。
此外,在某些情况下已经引起不自然的体验:例如,当用户靠近墙壁(例如,虚拟房间的虚拟墙壁)时,他应该体验到来自墙壁另一侧的声音。然而,通过传统环境这种体验是不可能的:与当前场景相关联的音频流的集合显然不包含与相邻环境/场景相关联的任何流。
另一方面,当音频流的比特率增加时,通常可以改善用户的体验。这可能导致其他问题:比特率越高,服务器系统需要传递给客户端系统102的有效载荷就越高。例如,当音频场景包含(作为音频元素被传送的)多个音频源(其中一些位于用户位置附近,而其他远离用户位置)时,则远离的声源将更少的可听见。因此,以相同的比特率或质量水平传送所有音频元素可能导致非常高的比特率。这意味着非有效的音频流被传递。如果服务器系统120以尽可能最高的比特率传递音频流,则引起非有效传递,因为类似于更接近用户的生成的相关声音,具有低可听性水平或与整个音频场景的低相关性的声音仍然需要高比特率。因此,如果以最高比特率传递一个场景的所有音频流,则服务器系统120与客户端系统102之间的通信将不必要地增加有效载荷。如果以较低的比特率传递一个场景的所有音频流,则用户的体验将是不令人满意的。
通信的问题加剧了上面讨论的不便之处:当用户通过门时,应该假设他立即改变了环境/场景,这将需要服务器系统120应该立即向客户端系统102提供所有流。
因此,传统上不可能解决上述问题。
然而,利用本发明,可以解决这些问题:客户端系统102向服务器系统120提供请求,该请求也可以基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据(并且不仅基于环境/场景)。因此,服务器系统120可以针对每个瞬间提供要针对每个例如用户的位置渲染的音频流。
例如,如果用户从不靠近墙壁,则客户端系统102不需要请求邻近环境的流(例如,仅当用户接近墙壁时,客户端系统102才可以请求它们)。此外,来自墙壁外部的流的比特率可能降低,因为它们可能被听到很小的音量。值得注意的是,服务器系统120可以以最高比特率和/或最高质量水平将较大相关的流(例如,来自当前环境内的音频对象的流)传送给客户端系统102(由于以下事实:较小相关的流处于较低的比特率和/或质量水平,因此为较大相关的流留有空闲带宽)。
例如,可以以这样的方式通过降低比特率或通过处理音频元素来获得较低的质量水平:减少要传输的所需数据,同时每个音频信号的使用比特率保持恒定。例如,如果10个音频对象位于全部远离用户的不同位置,则可以基于用户位置将这些对象混合到较低数量的信号中:
-在离用户位置很远的位置(例如,高于第一阈值)处,将对象混合为2个信号(基于其空间位置和语义,其他数量也是可能的),并作为2个“虚拟对象”进行传递
-在更靠近用户位置的位置(例如,低于第一阈值但高于小于第一阈值的第二阈值)处,将对象混合为5个信号(基于其空间位置和语义),并作为5个(其他数量是可能的)“虚拟物体”进行传递
-在非常接近用户位置的位置(低于第一阈值和第二阈值)处,将10个对象作为提供最高质量的10个音频信号进行传递。
当对于最高质量,音频信号都可以被认为非常重要且听得见时,用户可以能够单独地定位每个对象。对于远离的位置处的较低质量水平,某些音频对象可能变得较小相关或较小可听,因此用户将无法以任何方式单独地定位空间中的音频信号,因此降低传递这些音频信号的质量水平将不会导致用户的体验质量的任何下降。
另一示例是当用户越过门时:在转换位置(例如,在两个不同环境/场景之间的边界处)中,服务器系统120将提供场景/环境两者的两个流,但是以较低的比特率。这是因为用户将体验到来自两个不同环境的声音(这些声音可以从最初与不同场景/环境相关联的不同音频流中合并在一起),因此不需要每个声音源(或音频元素)的最高质量水平。
鉴于以上所述,本发明允许超出离散数量的视觉环境和音频场景的传统方法,但是可以允许不同环境/场景的渐进表示,从而给予用户更真实的体验。
在下文中,认为每个视觉环境(例如,虚拟环境)都与音频场景相关联(环境的属性也可以是场景的属性)。每个环境/场景可以例如与几何坐标系统(其可以是虚拟几何坐标系统)相关联。环境/场景可能具有边界,因此,当用户的位置(例如,虚拟位置)超出边界时,到达不同的环境/场景。边界可以基于所使用的坐标系。环境可以包括可以定位在环境/场景的某些特定坐标中的音频对象(音频元素、声源)。关于例如用户相对于音频对象(音频元素、声源)的相对位置和/或取向,客户端系统102可以请求不同的流和/或服务器系统120可以提供不同的流(例如,根据距离和/或取向以较高/较低的比特率和/或质量水平)。
更一般地,客户端系统102可以基于流的可听性和/或相关性向服务器系统120请求和/或从服务器系统120获得不同的流(例如,以不同比特率和/或质量水平的相同声音的不同表示)。可以例如基于至少用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据来确定可听性和/或相关性。
在几个示例中,可以合并不同的流。在几种情况下,存在合成或混合或复用或叠加或组合至少两个场景的可能性。例如,存在使用混合器和/或渲染器(例如,可以在多个解码器的下游使用,每个解码器至少解码一个音频流)、或者执行流复用操作(例如,在流的解码的上游)的可能性。在其他情况下,可能存在解码不同的流并使用不同的扬声器设置渲染它们的可能性。
要注意的是,本发明不一定拒绝视觉环境和音频场景的构思。特别地,利用本发明,当用户进入环境/场景时,与特定场景/环境相关联的音频和视频流可以从服务器系统120传递到客户端系统102。尽管如此,在相同的环境/场景中,可以请求、寻址和/或传递不同的音频流和/或音频对象和/或适应集。具体地,可能存在以下可能性:
-与视觉环境相关联的至少一些视频数据在用户进入场景时从服务器120传递给客户端102;和/或
-仅基于当前(或未来)视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置和/或用户的选择/交互,将至少一些音频数据(流、对象、适应集......)传递给客户端系统102;和/或
-(在某些情况下):基于当前场景(不考虑当前位置或未来位置或视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置和/或用户的选择)将一些音频数据传递给客户端系统102,而基于当前或未来或视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置和/或用户的选择对其余音频数据进行传递。
要注意的是,各种元素(服务器系统、客户端系统、MCD等)可以表示不同硬件设备中的元素,或甚至可以表示相同的元素(例如,客户端和MCD可以实现为相同移动电话的一部分,或类似地,客户端可以在PC上连接到包含MCD的辅助屏幕)
示例:
如图1.1中所示的系统102(客户端)的一个实施例被配置为基于环境(例如,虚拟环境)中的定义位置来接收(音频)流106,该环境可以被理解为与视频和音频场景(以下称为场景150)相关联。通常,相同场景150中的不同位置意味着要(例如,从媒体服务器120)提供给系统102的音频解码器104的不同流106或与流106相关联的不同元数据。系统102连接到媒体消费者设备(MCD),从该媒体消费者设备(MCD)接收与用户在相同环境中的位置和/或虚拟位置相关联的反馈。在下文中,用户在环境中的位置可以与用户喜欢的特定视口相关联(视口意指例如呈现给用户的表面,假定为投影在球体上的矩形表面)。
在示例性场景中,当用户在VR、AR和/或MR场景150中移动时,可以将音频内容想象为由可能改变的一个或多个音频源152虚拟地生成。音频源152可以被理解为虚拟音频源,在该意义上它们可以指虚拟环境中的位置:每个音频源的渲染适应于用户位置(例如,在简化示例中,当用户靠近音频源的位置时,音频源的水平较高,而当用户离音频源较远时,音频源较低)。尽管如此,每个音频元素(音频源)被编码在提供给解码器的音频流中。音频流可以与场景中的各种位置和/或区域相关联。例如,在一个场景中不可听见的音频源152可以在下一场景中变得可听见,例如,当打开VR、AR和/或MR场景150中的门时。然后,用户可以选择进入新的场景/环境150(例如,房间),并且整个音频场景改变。为了描述该场景,可以将空间中的离散视点这一术语用作空间中(或VR环境中)的离散位置,针对离散位置,不同的音频内容是可用的。
一般而言,媒体服务器120可以基于用户在场景150中的位置来提供与特定场景150相关联的流106。流106可以由至少一个编码器154编码,并且被提供给媒体服务器120。媒体服务器120可以通过通信113(例如,经由通信网络)发送流113。流113的提供可以根据系统102基于用户的位置110(例如,在虚拟环境中)而提出的请求112。用户的位置110也可以理解为与用户喜欢的视口(对于每个位置,存在被表示的单个矩形)和视点(如视点是视口的中心)相关联。因此,在一些示例中,视口的提供可以与位置的提供相同。
如图1.2所示的系统102被配置为基于在客户端侧处的另一配置来接收(音频)流113。在该示例实现中,在编码侧,提供了多个媒体编码器154,其可以用于针对与一个视点的一个声音场景部分相关联的每个可用场景150来创建一个或多个流106。
媒体服务器120可以存储多个音频和(未示出)视频适应集,该视频适应集包括以不同比特率的相同音频和视频流的不同编码。另外,媒体服务器可以包含所有适应集的描述性信息,该描述性信息可以包括所有创建的适应集的可用性。适应集还可以包括描述一个适应集与一个特定音频场景和/或视点的关联的信息。以这种方式,每个适应集可以与可用音频场景之一相关联。
此外,适应集可以包括描述每个音频场景和/或视点的边界的信息,该信息可以包含例如完整的音频场景或只是单独的音频对象。一个音频场景的边界可以被定义为例如球体的几何坐标(例如,中心和半径)。
客户端侧的系统102可以接收有关当前视口和/或头部取向和/或移动数据和/或交互元数据和/或用户的虚拟位置的信息,或表征由用户的动作触发的变化的任何信息。此外,系统102还可以接收关于所有适应集的可用性的信息以及描述一个适应集与一个音频场景和/或视点的关联的信息;和/或描述每个音频场景和/或视点的“边界”的信息(可以包含例如完整的音频场景或仅包含单独的对象)。例如,在DASH传递环境的情况下,这样的信息可以作为媒体呈现描述(MPD)XML语法的一部分来提供。
系统102可以向用于内容消费的媒体消费设备(MCD)提供音频信号。媒体消费设备还负责收集关于用户位置和/或取向和/或移动方向的信息和/或移动的方向(或表征由用户的动作触发的变化的信息)作为位置和转换数据110。
视口处理器1232可以被配置为从媒体消费设备侧接收所述位置和转换数据110。视口处理器1232还可以接收关于在元数据中用信号发送的ROI的信息以及在接收端(系统102)处可用的所有信息。然后,视口处理器1232可以基于接收到的和/或从接收到的导出的所有信息和/或可用的元数据,来决定应该在特定时刻再现哪个音频视点。例如,视口处理器1232可以决定将再现一个完整的音频场景,一个新的音频场景108必须从所有可用音频场景中创建,例如,仅将再现来自多个音频场景的一些音频元素,而这些音频场景中的其他剩余音频元素将不被再现。视口处理器1232还可以决定是否必须再现两个或更多个音频场景之间的转换。
可以提供选择部分1230,以基于从视口处理器1232接收的信息,从可用的适应集中选择在由接收端接收的信息中用信号发送的一个或多个适应集;所选择的适应集完全描述了应该在用户的当前位置处再现的音频场景。该音频场景可以是在编码侧处定义的一个完整的音频场景,或者可以必须从所有可用的音频场景中创建一个新的音频场景。
另外,在当基于视口处理器1232的指示即将发生两个或更多个音频场景之间的转换时的情况下,选择部分可以被配置为从可用的适应集中选择在由接收端接收到的信息中用信号发送的一个或多个适应集;所选择的适应集完全描述了可能需要在不久的将来再现的音频场景(例如,如果用户以特定速度沿下一个音频场景的方向行走,则可以预测到下一个音频场景将是必需的,并且在再现之前选择该音频场景)。
另外,可以首先以较低的比特率和/或较低的质量水平来选择与相邻位置相对应的一些适应集,例如,从一个适应集中的可用表示中选择出以较低的比特率编码的表示,并且基于位置改变,通过针对那些特定的适应集选择较高的比特率来提高质量,例如,从一个适应集中的可用表示中选择以较高比特率编码的表示。
可以提供下载和切换部分1234,以基于从选择部分接收到的指示来从来自媒体服务器的可用适应集中请求一个或多个适应集,下载和切换部分1234被配置为接收来自媒体服务器的可用适应集中的一个或多个适应集,并从所有接收到的音频流中提取元数据信息。
可以提供元数据处理器1236以从下载和切换中接收关于接收到的音频流的信息,该信息可以包括与接收到的每个音频流相对应的音频元数据。元数据处理器1236还可以被配置为基于从视口处理器1232接收的、可以包括关于用户位置和/或取向和/或移动方向110的信息的信息,来处理和操控与每个音频流113相关联的音频元数据,以选择/启用合成由视口处理器1232指示的新音频场景的所需音频元素152,允许将所有音频流113合并为单个音频流106。
流复用器/合并器1238可以被配置为基于从元数据处理器1236接收的信息将所有选择的音频流合并为一个音频流106,该信息可以包括与所有接收到的音频流113相对应的已修改和处理的音频元数据。
媒体解码器104被配置为基于关于用户位置和/或取向和/或移动方向的信息来接收和解码至少一个音频流,以再现由视口处理器1232指示的新音频场景。
在另一实施例中,如图1.7所示的系统102可以被配置为以不同的音频比特率和/或质量水平接收音频流106。该实施例的硬件配置类似于图1.2的硬件配置。至少一个视觉环境场景152可以与至少一个多个N音频元素(N≥2)相关联,每个音频元素与视觉环境中的位置和/或区域相关联。以高比特率和/或质量水平在至少一个表示中提供至少至少一个多个N个音频元素152,并且其中以低比特率和/或质量水平在至少一个表示中提供至少至少一个多个N个音频元素152,其中通过处理N个音频元素152以获得与靠近N个音频元素152的位置或区域的位置或区域相关联的较少数量M个音频元素152(M<N),来获得至少一个表示。
N个音频元素152的处理可以是例如音频信号的简单相加,或者可以是基于它们的空间位置110的有效降混或使用它们的空间位置到位于音频信号之间的新虚拟位置的音频信号的渲染。在音频元素在场景中的当前用户的虚拟位置处较大相关和/或较大可听的情况下,该系统可以被配置针对音频元素以较高的比特率和/或质量水平来请求表示,其中该系统被配置在音频元素在场景中的当前用户的虚拟位置处较小相关性和/或较小可听性的情况下,针对音频元素以较低的比特率和/或质量水平来请求表示。
图1.8示出了系统(可以是系统102)的示例,该系统示出了用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的系统102,系统102被配置为接收视频流1800和音频流106以将其在媒体消费设备中再现。
其中,系统102可以包括:
至少一个媒体视频解码器1804,被配置为解码来自视频流1800的视频信号1808,以向用户表示VR、AR、MR或360度视频环境,以及
至少一个音频解码器104,被配置为解码来自至少一个音频流106的音频信号108。
系统102可以被配置为至少基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据110(例如,作为来自媒体消费设备180的反馈而提供)向服务器(例如,120)请求(112)至少一个音频流106和/或音频流的一个音频元素和/或一个适应集。
系统102可以与图1.1至图1.7的系统102相同和/或获得图2a和图2b的场景。
本示例还涉及用于虚拟现实VR、增强现实AR、混合现实MR、或被配置为接收要在媒体消费设备[例如,回放设备]中再现的视频和音频流的360度视频环境的方法,包括:
从视频流中解码视频信号,以向用户表示VR、AR、MR或360度视频环境场景,以及
从音频流中解码音频信号,
基于用户的当前视口和/或位置数据和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据和/或元数据,向服务器请求和/或从服务器获取至少一个音频流。
情况1
通常,不同的场景/环境150意味着从服务器120接收不同的流106。然而,由音频解码器104接收的流106也可以由用户在相同场景150中的位置来调节。
在图2a中所示的第一(开始)时刻(t=t
在图2b中所示的第二示例性时刻(t=t
配备有用于在360度环境内可视化某个视口的所述MCD的用户可能正在例如通过耳机收听。用户可以欣赏针对相同场景150的图2a和图2b中描述的不同位置的不同声音的再现。
可以将例如来自图2a和图2b的场景内的任何位置和/或任何转换和/或视口和/或虚拟位置和/或头部取向和/或移动数据作为信号110从MCD周期性地(例如,以反馈的方式)发送给系统102(客户端)。客户端可以将位置和转换数据110′或110″(例如,视口致据)重新发送给服务器120。客户端102或服务器120可以基于位置和转换数据110′或110”(例如,视口数据)来决定需要哪些音频流106以在当前用户位置处再现正确的音频场景。客户端可以决定并发送针对相应音频流106的请求112,而服务器120可以被配置为根据客户端(系统102)提供的位置信息来相应地传递流106。备选地,服务器120可以根据客户端(系统102)提供的位置信息来决定并相应地传递流106。
客户端(系统102)可以请求发送要被解码以表示场景150的流。在一些示例中,系统102可以发送与要在MCD上再现的最高质量水平有关的信息(在其他示例中,服务器120基于用户在场景中的位置来决定要在MCD上再现的质量水平)。作为响应,服务器120可以选择与要表示的音频场景相关联的多个表示之一,以根据用户的位置110’或110”来传递至少一个流106。客户端(系统102)因此可以被配置为例如通过音频解码器104将音频信号108传递给用户,以再现与他的实际(有效)位置110’或110”相关联的声音。(可以使用适应集113:可以针对用户的不同位置来使用相同流的不同变体(例如,以不同的比特率)。)
流106(可以被预处理或即时生成)可以被发送给客户端(系统102),并且可以被配置为用于与特定声音场景相关联的多个视点。
已经注意到,可以根据用户在(例如,虚拟)环境中的特定位置(例如,110′或110″),针对不同的流106提供不同的质量(例如,不同的比特率)。例如:在多个音频源152-1和152-2的情况下,每个音频源152-1和152-2可以与场景150内的特定位置相关联。用户的位置110′或110′距第一音频源152-1越近,与第一音频源152-2相关的流的所需分辨率和/或质量越高。该示例性情况可以应用于图2a中的音频元素1(152-1)以及图2b中的音频元素2(152-2)。用户的位置110与第二音频源152-2的距离越远,与第二音频源152-2相关联的流106所需的分辨率越低。该示例性情况可以应用于图2a中的音频元素2(152-2)以及图2b中的音频元素1(152-1)。
实际上,第一,较近的音频源将被以较高的水平(因此以较高的比特率提供)听到,而第二,较远的音频源将被以较低的水平(可能允许需要较低的分辨率)听到;
因此,基于由客户端102提供的环境中的位置110’或110”,服务器120可以以不同的比特率(或其他质量)提供不同的流106。基于远离的音频元素不需要高质量水平的事实,即使以较低的比特率或质量水平传递音频,也可以保持用户的整体体验质量。
因此,在保持体验质量的同时,可以将不同质量水平用于不同用户位置处的某些音频元素。
在没有该方案的情况下,服务器120应该以最高比特率将所有流106提供给客户端,这将增加从服务器120到客户端的通信信道中的有效载荷。
情况2
图3(情况2)示出了具有另一示例性场景的实施例(在空间XYZ的垂直平面XZ中表示,其中轴Y表示为进入纸),其中用户在第一VR、AR和/或MR场景A(150A)中移动,打开门并走过(转换150AB),这意味着音频从时间t
在时间点t
在这种上下文下,用户正在将他的位置110例如从第一VR环境(由图1.1所示的第一视点(A)表征)改变到第二VR环境(由图1.1所示的第二视点(B)表征)。在特定情况下,例如,在通过位于x方向上的位置x
用户(配备有MCD)正在朝着门改变其位置110(x
现在从MCD将从第一位置(x
媒体服务器120可以选择与前述信息相关联的多种表示之一,不仅与MCD显示最高比特率的能力有关,而且与用户在其从一个位置移动到另一位置期间的位置和转换数据110(x
因此,媒体服务器120可以根据位置的转换来传递专用流106(例如,作为新的适应集113’)。客户端102可以被配置为例如经由媒体音频解码器104将音频信号108相应地传递给用户140。
(即时产生和/或预处理的)流106可以在周期性(例如,连续地)实现的适应集113’中被发送给客户端102。
当用户走过门时,服务器120可以发送第一场景150A的流106和第二场景150B的流106两者。这是为了同时混合或复用或合成或再现这些流106,以给用户真实的印象。因此,基于用户的位置110(例如,“与门相对应的位置”),服务器120向客户端发送不同的流106。
即使在这种情况下,由于不同的流106将同时被听到,因此它们可以具有不同的分辨率,并且可以以不同的分辨率从服务器120传送给客户端。当用户已经完成转换并且处于第二(位置)场景150A中(并且已经关闭了他身后的门)时,服务器120将有可能减少或限制发送第一场景150的流106(如果服务器120已经向客户端102提供了流,则客户端102可以决定不使用它们)。
情况3
图4(情况3)示出了具有另一示例性场景的实施例(在空间XYZ的垂直平面XZ中表示,其中轴Y表示为进入纸),其中用户在VR、AR和/或MR场景150A中移动,意味着音频从时间t
当用户处于第二位置(d
即使在这种情况下,第二场景150B的流106的比特率(质量)可以较低,因此需要减少从服务器120到客户端的传输有效载荷。值得注意的是,客户端(和/或视口)的位置110(d
例如,系统102可以被配置为获取与第一当前场景(150A)相关联的流,该第一当前场景与第一当前环境相关联,并且在用户的位置或虚拟位置距场景的边界(例如,对应于墙壁)的距离低于预定阈值(例如,当d
情况4
图5a和图5b示出了具有另一示例性场景的实施例(在空间XYZ的水平面XY中表示,其中,轴Z表示为从纸中退出),其中,用户被定位在一个且相同的VR、AR和/或MR场景150中,但是在不同的时刻处于例如到两个音频元素的不同距离处。
在图5a中所示的第一时刻t=t
在图5b所示的第二时刻t=t
实际上,如图5b所示,音频源1(152-1)和2(152-2)相对于用户定位得越近,必须调节的水平就越高,并且因此可以以较高的质量水平渲染音频信号108。相反,图5b中表示的远程定位的音频源1和2必须以单个虚拟源所再现的较低的水平被收听,因此例如以较低的质量水平被再现。
在类似的配置中,多个音频元素可以位于用户的前面,所有音频元素都被定位在大于距用户的阈值距离的距离处。在一个实施例中,两组五个音频元素中的每一个可以被组合在两个虚拟源中。用户位置数据从MCD发送给系统102,随后发送给服务器120,服务器120可以决定发送要由系统服务器120渲染的适当的音频流106。通过将全部10个音频元素分组为仅两个单个虚拟源,服务器120可以选择与上述信息相关联的多个表示之一,以适应集113’相应地传递专用流106,适应集113’相应地与例如两个单个音频元素相关联。因此,用户可以通过MCD接收从与真实音频元素位于相同定位区域中的两个不同的虚拟音频元素发送的音频信号。
在随后的时刻,用户正在接近多个(十个)音频元素。在该随后的场景中,所有音频元素都位于小于阈值距离d
情况5
图6(情况5)描绘了佩戴媒体消费者设备(MCD)的、位于一个单个场景150的一个位置中的用户140,该媒体消费者设备可以被引导到示例性的三个不同方向(每个方向与不同的视口160-1、160-2、160-3相关联)。如图6所示的这些方向可以具有在极坐标系和/或笛卡尔XY系统中的取向(例如,角取向),该取向指向例如在图6的底部中以180°定位的第一视点801,例如在图6的右侧上以90°定位的第二视点802,以及例如在图6的上部中以0°定位的第三视点803处。这些视点中的每一个都与佩戴媒体消费者设备(MCD)的用户140的取向相关联,定位在中心的用户被提供有特定视口,其中根据MCD的取向而渲染相应的音频信号108的由MCD显示的特定视口。
在该特定的VR环境中,第一音频元素s1(152)位于在位于例如180°处的视点附近的第一视口160-1中,并且第二音频元素s2(152)位于在位于例如180°处的视点附近的第三视口160-3中。在改变他的取向之前,用户140在朝向视点801(视口160-1)的第一取向中体验与他的实际(有效)位置相关联的来自音频元素s1的比音频元素s2更大的声音。
通过改变他的取向,用户140可以在朝向视点802的第二取向中体验与他的实际位置110相关联的从两个音频元素s1和s2侧向传来的几乎相同响度的声音。
最后,通过改变他的取向,用户140可以在朝向视点801(视口160-3)的第三取向中体验与音频元素2相关联的比与音频元素s1相关联的声音大的声音(实际上,来自音频元素2的声音从前方到达,而来自音频元素1的声音从后方到达)。
因此,不同的视口和/或取向和/或虚拟位置数据可以与不同的比特率和/或质量相关联。
其他情况和示例
图7a以图中的操作步骤序列的形式示出了用于由系统接收音频流的方法的实施例。在任何时候,系统102的用户都与其当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置相关联。在特定时刻,在图7a的步骤701中系统可以基于当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置来确定要再现的音频元素。因此,在下一步骤703中,可以确定每个音频元素的相关性和可听性。如上文在图6中所描述的,VR环境可以不仅具有位于用户附近或更远处的特定场景150中的不同音频元素,而且具有在360度环境中的特定取向。所有这些因素确定了每个所述音频元素的相关性和可听性水平。
在下一步骤705中,系统102可以根据针对每个音频元素所确定的相关性和可听性水平,从媒体服务器120来请求音频流。
在下一步骤707中,系统102可以接收由媒体服务器120相应地准备的音频流113,其中,具有不同比特率的流可以反映如在前述步骤中确定的相关性和可听性水平。
在下一步骤709中,系统102(例如,音频解码器)可以对接收到的音频流113进行解码,以使得在步骤711处,根据当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置,(例如,通过MCD)来再现特定场景150。
图7b描绘了根据前述的操作序列图的在媒体服务器120和系统102之间的交互。在特定时刻,媒体服务器可以根据前述场景150的相关音频元素的前述确定的较低相关性和可听性水平,以较低的比特率发送音频流750。系统可以在随后的时刻752处确定发生了位置数据的交互或改变。这样的相互作用可以由例如来自相同场景150中的位置数据的改变或当用户试图通过由门把手提供的门进入与第一场景分开的第二场景时激活门把手引起。
当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置的改变可以导致系统102向媒体服务器120发送请求754。该请求可以反映针对该后续场景150确定的相关音频元素的较高的相关性和可听性水平。作为对请求754的响应,媒体服务器可以以较高的比特率发送流756,从而使得系统102能够在任何当前用户的虚拟位置对场景150进行合理且真实的再现。
图8a也以图中的操作步骤序列的形式示出了用于由系统接收音频流的方法的另一实施例。在特定时刻801,可以执行对第一当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置的确定。通过除去肯定情况,在步骤803处,可以由系统102准备并发送与由低比特率定义的与第一位置相关联的流的请求。
具有三个不同结果的确定步骤805可以在随后的时刻执行。一个或两个定义的阈值在该步骤中可能与确定例如与随后视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置有关的预测决策相关。因此,关于改变到第二位置的概率,可以执行与第一和/或第二阈值的比较,导致例如要执行的三个不同的随后步骤。
在反映例如非常低的概率(例如,与上述与第一预定阈值的比较相关联的概率)的结果下,将执行新的比较步骤801。
反映低概率(例如,高于第一预定阈值,但是在示例中,低于比第一阈值高的第二预定阈值)的结果可能导致在步骤809处请求以低比特率的音频流113。
在反映高概率(例如,高于第二预定阈值)的结果处,在步骤807处可以执行对以高比特率的音频流113的请求。在执行步骤807或809之后要执行的随后步骤可以因此再次是确定步骤801。
图8b描绘了仅根据前述的操作序列图之一在媒体服务器120与系统102之间的交互。在特定时刻,媒体服务器可以根据前述场景150的音频元素的前述确定的低相关性和可听性水平,以低比特率发送音频流850。该系统可以在随后的时刻852处确定交互将预测性地发生。当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置的预测改变可以导致系统102向媒体服务器120发送适当的请求854。该请求可以根据针对相应随后场景150而要求的音频元素的可听水平,来反映与达到与高比特率相关联的第二位置的高概率有关的上述情况之一。作为响应,媒体服务器可以以较高的比特率发送流856,从而使得系统102能够在任何当前用户的虚拟位置处对场景150进行合理且真实的再现。
如图1.3所示的系统102被配置为基于客户端侧的另一配置来接收音频流113,其中系统架构可以基于使用多个音频解码器1320、1322的方案来使用离散视点。在客户端侧,系统102可以体现为例如图1.2中描述的系统的部分,其附加地或备选地包括多个音频解码器1320、1322,音频解码器1320、1322可以被配置为对由元数据处理器1236所指示的各个音频流(例如,其中多个音频元素未被激活)进行解码。
可以在系统102中提供混合器/渲染器1238,该混合器/渲染器1238被配置为基于关于用户位置和/或取向和/或移动方向的信息来再现最终的音频场景,即例如,在该特定位置处是不可听见的一些音频元素应该被禁用或不被渲染。
图1.4、图1.5和图1.6所示的以下实施例基于具有灵活适应集的用于离散视点的独立适应集。在当用户在VR环境中移动的情况下,音频场景可以以连续的方式变化。为了确保良好的音频体验,在特定时刻合成音频场景的所有音频元素可能必须对媒体解码器是可用的,该媒体解码器可以利用位置信息来创建最终的音频场景。
如果针对多个预定义的位置对内容进行了预编码,则系统可以在这些音频场景不重叠并且用户可以从一个位置“跳转/切换”到下一位置的前提下,对在这些特定位置处的音频场景提供准确再现。
但是在当用户从一个位置“步行”到下一位置的情况下,可以同时听见来自两个(或更多个)音频场景的音频元素。在先前的系统示例中提供了针对此用例的方案,其中与针对解码多个音频流而提供的机制(使用具有单个媒体解码器的复用器或具有附加的混合器/渲染器的多个媒体解码器)无关,描述完整的音频场景的音频流必须提供给客户端。
下面通过引入多个音频流之间的公共音频元素的概念来提供优化。
讨论方面和示例
方案1:针对离散位置(视点)的独立适应集。
解决上述问题的一种方法是针对每个位置使用完整的独立适应集。为了更好地理解方案,图1.1用作示例场景。在该示例中,使用了三个不同的离散视点(包括三个不同的音频场景)来创建用户应该能够进入的完整VR环境。因此:
·多个独立或重叠的音频场景被编码为多个音频流。对于每个音频场景,可以根据使用情况使用一个主流,一个主流和附加辅助流(例如,可以将包含不同语言的某些音频对象编码为独立的流以进行有效传递)。在提供的示例中,音频场景A被编码为两个流(A1和A2),音频场景B被编码为三个流(B1、B2和B3),而音频场景C被编码为三个流(C1、C2和C3)。要注意的是,音频场景A和音频场景B共享多个公共元素(在该示例中为两个音频对象)。由于每个场景必须完整且独立(用于例如在非VR回放设备上进行独立再现),因此针对每个场景,公共元素必须被编码两次。
·所有音频流都以不同的比特率(即,不同的表示)进行编码,从而允许根据网络连接的有效比特率适应(即,对于使用高速连接的用户,高比特率编码版本被传递,而对于低速网络连接的用户,较低比特率版本被传递)。
·音频流被存储在媒体服务器上,其中,对于每个音频流,以不同比特率的不同编码(即,不同的表示)被分组在一个适应集中,该适应集具有用信号发送所有创建的自适应集的可用性的适当数据。
·另外,对于适应集,媒体服务器接收关于每个音频场景的位置“边界”及其与每个适应集(可以包含例如完整的音频场景或仅包含各个对象)的关系的信息。以这种方式,每个适应集可以与可用音频场景之一相关联。一个音频场景的边界可以被定义为例如球体的几何坐标(例如,中心和半径)。
o每个适应集还包含关于声音场景或音频元素处于活动状态的位置的描述性信息。例如,如果一个辅助流包含一个或几个对象,则适应集可以包含诸如其中对象是可听见的位置之类的信息(例如,球体中心和半径的坐标)。
·媒体服务器向客户端(例如,DASH客户端)提供关于与每个适应集相关联的位置“边界”的信息。例如,在DASH传递环境的情况下,这可以被嵌入到媒体呈现描述(MPD)XML语法中。
·客户端接收关于用户位置和/或取向和/或移动方向的信息(或表征由用户的动作触发的变化的任何信息)
·客户端接收关于每个适应集的信息,并基于该信息以及用户位置和/或取向和/或移动方向(或表征由用户的动作触发的变化的任何信息,例如包括x、y、z坐标和/或偏航、俯仰、横滚值),客户端选择完全描述应在用户当前位置处再现的音频场景的一个或多个适应集。
·客户端请求一个或多个适应集
o此外,客户可以选择更多的适应集来完全描述一个以上的音频场景,并使用与一个以上的音频场景相对应的音频流来创建新的音频场景,该新的音频场景应该在用户的当前位置处进行再现。例如,如果用户在VR环境中行走,并且在某一时刻位于两者之间(或位于两个音频场景具有可听效果的位置)。
o一旦音频流是可用的,则可以使用多个媒体解码器对各个音频流进行解码,并使用附加的混合器/渲染器1238以基于关于用户位置和/或取向和/或移动方向的信息来再现最终的音频场景(即,例如,在该特定位置处不可听见的某些音频元素应该被禁用或不被渲染)
o备选地,基于关于用户位置和/或取向和/或移动方向的信息,元数据处理器1236可以用于操控与所有音频流相关联的音频元数据,以:
·选择/启用合成新音频场景的所需音频元素152;
·并允许将所有音频流合并为单个音频流。
·媒体服务器传递所需的适应集
·备选地,客户端将关于用户定位的信息提供给媒体服务器,而媒体服务器提供关于所需的适应集的指示。
图1.2显示了这种系统的另一示例实现,包括:
·在编码侧
o多个媒体编码器,其可以用于针对与一个视点的一个声音场景部分相关联的每个可用音频场景来创建一个或多个音频流
o多个媒体编码器,其可以用于针对与一个视点的一个视频场景部分相关联的每个可用视频场景来创建一个或多个视频流。为了简单起见,图中未呈现视频编码器
o媒体服务器,其存储多个音频和视频适应集,音频和视频适应集包括以不同的比特率(即,不同的表示)对相同的音频和视频流的不同编码。此外,媒体服务器包含所有适应集的描述性信息,该描述性信息可以包括
·所有已创建的适应集的可用性;
·描述一个适应集与一个音频场景和/或视点的关联的信息;以这种方式,每个适应集可以与可用的音频场景之一相关联;
·描述每个音频场景和/或视点(可以包含例如完整的音频场景或仅各个对象)的“边界”的信息。一个音频场景的边界可以被定义为例如球体的几何坐标(例如,中心和半径)。
·在客户端侧的系统(客户端系统),该系统可以包含以下任何一项:
o接收端,可以接收:
·关于用户位置和/或取向和/或移动方向的信息(或表征由用户的动作触发的变化的任何信息)
·关于所有适应集的可用性的信息,以及描述一个适应集与一个音频场景和/或视点的关联的信息;和/或描述每个音频场景和/或视点(可以包含例如完整的音频场景或仅各个对象)的“边界”的信息。例如,在DASH传递环境的情况下,这样的信息可以作为媒体呈现描述(MPD)XML语法的一部分来提供。
o用于内容消费的媒体消费设备侧(例如,基于HMD)。媒体消费设备还负责收集关于用户位置和/或取向和/或移动方向的信息(或表征由用户的动作触发的变化的任何信息)
o视口处理器1232,可以被配置为:
·接收关于当前视口的信息,该信息可以包含来自媒体消费设备侧的用户位置和/或取向和/或移动方向(或表征由用户的动作触发的变化的任何信息)。
·接收关于在元数据中用信号发送的ROI的信息(如在OMAF规范中用信号发送的视频视口)。
·在接收端处接收所有可用信息;
·基于接收到的和/或从接收到的导出的所有信息和/或可用的元数据,来决定应该在特定时刻再现哪个音频/视频视点。例如,视口处理器1232可以决定:
·将再现一个完整的音频场景
·必须从所有可用的音频场景中创建一个新的音频场景(例如,仅将再现多个音频场景中的一些音频元素,而这些音频场景中的其他剩余音频元素将不被再现)
·必须再现两个或更多个音频场景之间的转换
o选择部分1230,被配置为基于从视口处理器1232接收的信息,从可用的适应集中选择在由接收端接收的信息中用信号发送的一个或多个适应集;所选择的适应集完全描述了应该在用户的当前位置处再现的音频场景。该音频场景可以是编码侧处定义的一个完整的音频场景,或者必须在所有可用的音频场景中创建的新的音频场景。
·另外,在当基于视口处理器1232的指示即将发生两个或更多个音频场景之间的转换时的情况下,选择部分可以被配置为从可用的适应集中选择在由接收端接收到的信息中用信号发送的一个或多个适应集;所选择的适应集完全描述了可能需要在不久的将来再现的音频场景(例如,如果用户以特定速度沿下一个音频场景的方向行走,则可以预测到下一个音频场景将是必需的,并且在再现之前选择该音频场景)。
·此外,可以首先以较低的比特率选择与相邻位置相对应的一些适应集(即,从一个适应集中的可用表示中选择以较低比特率编码的表示),并且基于位置变化,通过针对那些特定的适应集选择较高的比特率来提高质量(即,从一个适应集中的可用表示中选择以较高比特率编码的表示)。
o下载和切换部分,可以被配置为:
·基于从选择部分1230接收到的指示,从媒体服务器120请求可用适应集中的一个或多个适应集;
·从媒体服务器120接收可用的适应集中的一个或多个适应集(即,每个适应集内部可用的所有表示中的一个表示);
·从所有接收到的音频流中提取元数据信息
o元数据处理器1236,可以被配置为:
·从下载和切换中接收关于接收到的音频流的信息,信息可以包括与接收到的每个音频流相对应的音频元数据
·基于从视口处理器1232接收的信息,处理和操控与每个音频流相关联的音频元数据,该信息可以包括关于用户位置和/或取向和/或移动方向的信息,以:
·选择/启用合成由视口处理器1232指示的新音频场景的所需音频元素152;
·允许将所有音频流合并为单个音频流。
o流复用器/合并器1238,可以被配置为基于从元数据处理器1236接收的信息,将所有选择的音频流合并为一个音频流,该信息可以包括与所有接收到的音频流相对应的已修改和处理的音频元数据
o媒体解码器,被配置为基于关于用户位置和/或取向和/或移动方向的信息来接收和解码至少一个音频流,以再现由视口处理器1232指示的新音频场景。
图1.3示出了包括客户端侧处的系统(客户端系统)的系统,该系统可以体现为例如图1.2中所述的系统的部分,该部分附加地或备选地包括:
·多个媒体解码器,可以被配置为解码由元数据处理器1236指示的单个音频流(例如,其中多个音频元素未被激活)。
·混合器/渲染器1238,可以被配置为基于关于用户位置和/或取向和/或移动方向的信息来再现最终的音频场景,(即,例如,在该特定位置处是不可听见的一些音频元素应该被禁用或不被渲染)。
方案2
图1.4、图1.5和图1.6是指根据本发明的方案2的示例(可以是图1.1和/或图1.2和/或图1.3的示例的实施例):具有灵活的适应集的离散位置(视点)的独立适应集。
在用户在VR环境中移动的情况下,音频场景150可以以连续方式改变。为了确保良好的音频体验,在特定时刻合成音频场景的所有音频元素152可能对媒体解码器必须是变得可用的,该媒体解码器可以利用位置信息来创建最终的音频场景。
如果针对多个预定义的位置对内容进行了预编码,则系统可以在这些音频场景不重叠并且用户可以从一个位置“跳转/切换”到下一位置的前提下,对在这些特定位置处的音频场景提供准确再现。
但是在当用户从一个位置“步行”到下一位置的情况下,可以同时听见来自两个(或更多个)音频场景的音频元素152。在先前的系统示例中提供了针对该用例的方案,其中与针对解码多个音频流而提供的机制(使用具有单个媒体解码器的复用器或具有附加的混合器/渲染器1238的多个媒体解码器)无关,描述完整的音频场景150的音频流必须提供给客户端/系统102。
下面通过引入多个音频流之间的公共音频元素152的概念来提供优化。
图1.4示出了其中不同的场景共享至少一个音频元素(音频对象、声源......)的示例。因此,客户端102可以接收例如仅与一个场景A相关联(例如,与用户当前所在的环境相关联)并且与对象152A相关联的一个主流106A,以及由不同的场景B共享(例如,用户当前所在的场景A与共享对象152B的相邻或邻近流B之间的边界中的流)并与对象152B相关联的一个辅助流106B。
因此,如图1.4所示:
·多个独立或重叠的音频场景被编码为多个音频流。以如下方式创建音频流106:
o对于每个音频场景150,可以通过仅包含作为相应音频场景的一部分而不是任何其他音频场景的一部分的音频元素152来创建一个主流;和/或
o针对共享音频元素152的所有音频场景150,可以仅在仅与音频场景之一相关联的辅助音频流中对公共音频元素152进行编码,并且创建指示与其他音频场景的关联的适当的元数据信息。或换句话说,附加元数据指示某些音频流可能与多个音频场景一起使用的概率;和/或
o根据使用情况,可以创建附加辅助流(例如,包含不同语言的某些音频对象可以在独立的流中进行编码以用于有效传递)。
o在提供的实施例中:
·音频场景A被编码为:
·主音频流(A1、106A),
·辅助音频流(A2、106B)
·元数据信息,可以指示来自音频场景A的某些音频元素152B未被编码在这些音频流A中,而是被编码在属于不同音频场景(音频场景B)的辅助流A2(106B)中
·音频场景B被编码为:
·主音频流(B1、106C),
·辅助音频流(B2),
·辅助音频流(B3),
·元数据信息,可以指示来自音频流B2的音频元素152B是也属于音频场景A的公共音频元素152B。
·音频场景C被编码为三个流(C1、C2和C3)。
·音频流106(106A、106B、106C......)可以以不同的比特率(即,不同的表示)进行编码,从而允许例如根据网络连接的有效比特率适应(即,对于使用高速连接的用户,高比特率编码版本被传递,而对于低速网络连接的用户,较低比特率版本被传递)。
·音频流106被存储在媒体服务器120上,其中,对于每个音频流,以不同比特率(即,不同的表示)的不同编码被分组在一个适应集中,该适应集具有用信号发送所有创建的自适应集的可用性的适当数据。(与相同的音频信号相关联但处于不同的比特率和/或质量和/或分辨率的流的多种表示可以存在于相同的适应集中。)
·此外,对于适应集,媒体服务器120可以接收关于每个音频场景的位置“边界”及其与每个适应集(可以包含例如完整的音频场景或仅包含各个对象)的关系的信息。以这种方式,每个适应集可以与可用音频场景150中的一个或多个相关联。一个音频场景的边界可以被定义为例如球体的几何坐标(例如,中心和半径)。
o每个适应集还可以包含关于其中声音场景或音频元素152处于活动状态的位置的描述性信息。例如,如果一个辅助流(例如,A2、106B)包含一个或几个对象,则适应集可以包含诸如其中对象是可听见的位置之类的信息(例如,球体中心和半径的坐标)。
o附加地或备选地,每个适应集(例如,与场景B相关联的适应集)可以包含描述性信息(例如,元数据),该描述性信息可以指示来自一个音频场景(例如,B)的音频元素(例如,152B)(也或另外地)被编码在属于不同音频场景(例如,A)的音频流(例如,106B)中)。
·媒体服务器120可以向系统102(客户端)(例如,DASH客户端)提供关于与每个适应集相关联的位置“边界”的信息。例如,在DASH传递环境的情况下,这可以被嵌入到媒体呈现描述(MPD)XML语法中。
·系统102(客户端)可以接收关于用户位置和/或取向和/或移动方向的信息(或表征由用户的动作触发的变化的任何信息)。
·系统102(客户端)可以接收关于每个适应集的信息,并基于该信息以及用户位置和/或取向和/或移动方向(或表征由用户的动作触发的变化的任何信息,例如包括x、y、z坐标和/或偏航、俯仰、横滚值),系统102(客户端)可以选择完全或部分地描述应在用户140的当前位置处再现的音频场景150的一个或多个适应集。
·系统102(客户端)可以请求一个或多个适应集:
o此外,系统102(客户端)可以选择完全或部分地描述一个以上的音频场景150的一个或多个适应集,并使用与一个以上的音频场景150相对应的音频流106来创建要在用户140的当前位置处再现的新的音频场景150。
o基于指示音频元素152是多个音频场景150的一部分的元数据,可以仅请求公共音频元素152一次以创建新的音频场景,而不是请求公共音频元素152两次,针对每个完整的音频场景请求一次。
o一旦音频流可用于客户端系统102,在示例中,一个或多个媒体解码器(104)可以用于对各个音频流进行解码,和/或使用附加的混合器/渲染器以基于关于用户位置和/或取向和/或移动方向的信息来再现最终的音频场景(即,例如,在该特定位置处不可听见的某些音频元素应该被禁用或不被渲染)
o备选地或另外地,基于关于用户位置和/或取向和/或移动方向的信息,元数据处理器可以用于操控与所有音频流相关联的音频元数据,以:
·选择/启用合成新音频场景的所需音频元素152(152A-152c);和/或
·并允许将所有音频流合并为单个音频流。
·媒体服务器120可以传递所需的适应集
·备选地,系统102(客户端)将关于用户140定位的信息提供给媒体服务器120,而媒体服务器提供关于所需的适应集的指示。
·图1.5示出了这种系统的另一示例实现,包括:
·在编码侧处
o多个媒体编码器154,可以用于根据与一个视点的一个声音场景部分相关联的一个或多个可用音频场景150,来创建嵌入音频元素152的一个或多个音频流106。
·对于每个音频场景150,可以通过仅包含作为相应音频场景的一部分而不是任何其他音频场景的一部分的音频元素152来创建一个主流
·可以针对相同的音频场景来创建附加的辅助流(例如,包含不同语言的某些音频对象可以在独立的流中进行编码以用于高效传递)。
·可以创建附加辅助流,其包含:
·对一个以上的音频场景150为公共的音频元素152
·元数据信息,指示该辅助流与共享公共音频元素152的所有其他音频场景150的关联。或换句话说,元数据指示某些音频流可以与多个音频场景一起使用的概率。
o多个媒体编码器,其可以用于针对与一个视点的一个视频场景部分相关联的每个可用视频场景来创建一个或多个视频流。为了简单起见,图中未呈现视频编码器
o媒体服务器120,存储多个音频和视频适应集,音频和视频适应集包括以不同的比特率(即,不同的表示)对相同的音频和视频流的不同编码。另外,媒体服务器120包含所有适应集的描述性信息,该描述性信息可以包括
·所有已创建的适应集的可用性;
·描述一个适应集与一个音频场景和/或视点的关联的信息;以这种方式,每个适应集可以与可用的音频场景之一相关联;
·描述每个音频场景和/或视点(可以包含例如完整的音频场景或仅各个对象)的“边界”的信息。一个音频场景的边界可以被定义为例如球体的几何坐标(例如,中心和半径)。
·指示一个适应集与一个以上的音频场景的关联的信息,共享至少一个公共音频元素。
·在客户端侧的系统(客户端系统),该系统可以包含以下任何一项:
o接收端,可以接收:
·关于用户位置和/或取向和/或移动方向的信息(或表征由用户的动作触发的变化的任何信息)
·关于所有适应集的可用性的信息,以及描述一个适应集与一个音频场景和/或视点的关联的信息;和/或描述每个音频场景和/或视点(可以包含例如完整的音频场景或仅各个对象)的“边界”的信息。例如,在DASH传递环境的情况下,可以提供这样的信息作为媒体呈现描述(MPD)XML语法的一部分。
·指示一个适应集与一个以上的音频场景的关联的信息,共享至少一个公共音频元素。
o用于内容消费的媒体消费设备侧(例如,基于HMD)。媒体消费设备还负责收集关于用户位置和/或取向和/或移动方向的信息(或表征由用户的动作触发的变化的任何信息)
o视口处理器1232,可以被配置为:
·接收关于当前视口的信息,该当前视口可以包含来自媒体消费设备侧的用户位置和/或取向和/或移动方向(或表征由用户的动作触发的变化的任何信息)。
·接收关于ROI的信息以及在元数据中用信号发送的ROI(如在OMAF规范中用信号发送的视频视口)。
·在接收端处接收所有可用信息;
·基于接收到的和/或从接收到的导出的所有信息和/或可用的元数据,来决定应该在特定时刻再现哪个音频/视频视点。例如,视口处理器1232可以决定:
·将再现一个完整的音频场景
·必须从所有可用的音频场景中创建一个新的音频场景(例如,仅将再现多个音频场景中的一些音频元素,而这些音频场景中的其他剩余音频元素将不被再现)
·必须再现两个或更多个音频场景之间的转换
o选择部分1230,被配置为基于从视口处理器1232接收的信息,从接收端接收的信息中以信号通知从可用的适应集中选择一个或多个适应集;所选的适应集完全或部分描述了应在用户当前位置再现的音频场景。该音频场景可以是编码侧处定义的一个完整或部分完整的音频场景,或者必须在所有可用音频场景中创建新的音频场景。
·另外,在音频元素152属于一个以上的音频场景的情况下,基于指示至少一个适应集与一个以上的音频场景的关联的信息来选择至少一个适应集,该一个以上的音频场景包含相同的音频元素152。
·另外,在当基于视口处理器1232的指示即将发生两个或更多个音频场景之间的转换时的情况下,选择部分可以被配置为从可用的适应集中选择在由接收端接收到的信息中用信号发送的一个或多个适应集;所选择的适应集完全描述了可能需要在不久的将来再现的音频场景(例如,如果用户以特定速度沿下一个音频场景的方向行走,则可以预测到下一个音频场景将是必需的,并且在再现之前选择该音频场景)。
·此外,可以首先以较低的比特率选择与相邻位置相对应的一些适应集(即,从一个适应集中的可用表示中选择以较低比特率编码的表示),并且基于位置变化,通过针对那些特定的适应集选择较高的比特率来提高质量(即,从一个适应集中的可用表示中选择以较高比特率编码的表示)。
o下载和切换部分,可以被配置为:
·基于从选择部分1230接收到的指示,从媒体服务器120请求可用适应集中的一个或多个适应集;
·从媒体服务器120接收可用的适应集中的一个或多个适应集(即,每个适应集内部可用的所有表示中的一个表示);
·从所有接收到的音频流中提取元数据信息
o元数据处理器1236,可以被配置为:
·从下载和切换中接收关于接收到的音频流的信息,信息可以包括与接收到的每个音频流相对应的音频元数据
·基于从视口处理器1232接收的信息,处理和操控与每个音频流相关联的音频元数据,该信息可以包括关于用户位置和/或取向和/或移动方向的信息,以:
·选择/启用合成由视口处理器1232指示的新音频场景的所需音频元素152;
·允许将所有音频流合并为单个音频流。
o流复用器/合并器1238,可以被配置为基于从元数据处理器1236接收的信息,将所有选择的音频流合并为一个音频流,该信息可以包括与所有接收到的音频流相对应的已修改和处理的音频元数据
o媒体解码器,被配置为基于关于用户位置和/或取向和/或移动方向的信息来接收和解码至少一个音频流,以再现由视口处理器1232指示的新的音频场景。
图1.6示出了包括客户端侧处的系统(客户端系统)的系统,该系统可以体现为例如图5a和图5b中所述的系统的部分,该部分附加地或备选地包括:
·多个媒体解码器,可以被配置为解码由元数据处理器1236指示的单个音频流(例如,其中多个音频元素未被激活)。
·混合器/渲染器1238,可以被配置为基于关于用户位置和/或取向和/或移动方向的信息来再现最终的音频场景(即,例如,在该特定位置处是不可听见的一些音频元素应该被禁用或不被渲染)。
用于文件回放的文件格式更新
对于文件格式用例,可以将多个主流和辅助流作为单独的轨道(Track)封装到单个ISOBMFF文件中。如前所述,这种文件的单个轨道将表示单个音频元素。由于不存在包含用于正确播放所需的信息的可用的MPD,因此需要在文件格式水平上提供该信息,例如通过提供/引入在轨道和电影水平上的一个特定文件格式框或多个特定文件格式框。根据用例,存在允许对封装的音频场景进行正确渲染所需的不同信息,然而以下信息集是基础的,并且因此应始终存在:
·关于包括的音频场景的信息,例如,“位置边界”
·关于所有可用音频元素的信息,尤其是将哪个音频元素封装到哪个轨道中
·有关封装的音频元素的位置的信息
·属于一个音频场景的所有音频元素的列表,音频元素可以属于多个音频场景
通过这些信息,包括具有附加元数据处理器和共享编码的用例在内的所有提到的用例也应该在基于文件的环境中可以使用。
对以上示例的进一步考虑
在示例中(例如,图1.1至图6中的至少一个),至少一个场景可以与至少一个音频元素(音频源152)相关联,每个音频元素与其中音频元素是可听见的视觉环境中的位置和/或区域相关联,使得针对不同用户的位置和/或视口和/或头部取向和/或移动数据和/或交互元数据和/或场景中的虚拟位置数据,从服务器系统120向客户端系统102提供不同的音频流。
在示例中,客户端系统102可以被配置为在存在当前用户的视口和/或头部取向和/或移动数据和/或交互元数据和/或场景中的虚拟位置的情况下,决定是否要再现音频流(例如,A1、A2)的至少一个音频元素152和/或一个适应集,其中系统102被配置为请求和/或接收在当前用户的虚拟位置处的至少一个音频元素。
在示例中,客户端系统(例如,102)可以被配置为至少基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据(110),来预测性地决定音频流的至少一个音频元素(152)和/或一个适应集是否将变得相关和/或可听见,并且其中,系统被配置为在预测的用户在场景中的移动和/或交互之前,请求和/或接收在特定用户的虚拟位置处的至少一个音频元素和/或音频流和/或适应集,其中,系统被配置为在用户在场景中的移动和/或交互之后,当接收到至少一个音频元素和/或语音流时,在特定的用户虚拟位置处,再现至少一个音频元素和/或音频流。参见例如上面的图8a和图8b。在一些示例中,可以基于预测和/或统计和/或聚合数据来执行系统102或120的操作中的至少一个。
在示例中,客户端系统(例如,102)可以被配置为在用户在场景中的移动和/或交互之前,在用户的虚拟位置处,以较低的比特率和/或质量水平请求和/或接收至少一个音频元素(例如,152),其中系统被配置为在用户在场景中的移动和/或交互之后,在用户的虚拟位置处以较高的比特率和/或质量水平来请求和/或接收至少一个音频元素。参见例如图7b。
在示例中,至少一个音频元素可以与至少一个场景相关联,至少一个音频元素与在与场景相关联的视觉环境中的位置和/或区域相关联,其中系统被配置为基于在场景中每个用户的虚拟位置处的音频元素的相关性和/或可听性水平,针对音频元素以不同的比特率和/或质量水平来请求不同的流,其中系统被配置为针对在当前用户的虚拟位置处为较大相关和/或较大可听的音频元素,以较高的比特率和/或质量水平来请求音频流,和/或针对在当前用户的虚拟位置处具有较小相关和/或较小可听的音频元素,以较低的比特率和/或质量水平来请求音频流。一般而言,参见图7a。还参见图2a和图2b(其中,更大相关和/或可听源可以更接近用户),图3(其中,当用户处于位置x
在示例中,至少一个音频元素(152)与场景相关联,每个音频元素与视觉环境中与场景相关联的位置和/或区域相关联,其中客户端系统102被配置为向服务器系统120周期性地发送用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据(110),以:针对靠近至少一个音频元素(152)的位置,从服务器提供较高比特率和/或质量的流,并且针对距至少一个音频元素(152)更远的位置,从服务器提供较低比特率和/或质量的流。参见例如图2a和图2b。
在示例中,可以针对诸如邻近和/或相邻环境等的多个视觉环境来定义多个场景(例如,150A、150B),从而提供与第一当前场景(例如,150A)相关联的第一流,并且在到另一第二场景(例如,150B)的用户转换(150AB)的情况下,提供与第一场景相关联的流和与第二场景相关联的第二流两者。参见例如图3。
在示例中,针对第一和第二视觉环境定义了多个场景,第一和第二环境是邻近和/或相邻的环境,其中,在用户的虚拟位置处于与第一场景相关联的第一环境中的情况下,从服务器提供与第一场景相关联的第一流以用于再现第一场景,在用户的虚拟位置处于与第二场景相关联的第二环境中的情况下,从服务器提供与第二场景相关联的第二流以用于再现第二场景,以及在用户的虚拟位置处于第一场景与第二场景之间的转换位置中的情况下,提供与第一场景相关联的第一流和与第二场景相关联的第二流两者。参见例如图3。
在示例中,当用户处于与第一场景相关联的第一环境中时,以较高的比特率和/或质量获得与第一场景相关联的第一流,而当用户处于从第一场景到第二场景的转换位置的开始时,以较低的比特率和/或质量获得与第二环境相关联的第二场景环境相关联的第二流,并且当用户处于从第一场景到第二场景的转换位置的末端时,以较低的比特率和/或质量获得与第一场景相关联的第一流,并且以更高的比特率和/或质量获得与第二场景相关联的第二流。这可以是例如图3的情况。
在示例中,针对多个视觉环境(例如,邻近环境)定义了多个场景(例如,150A、150B),使得系统102可以以较高的比特率和/或质量请求和/或获得与当前场景相关联的流,并且以较低的比特率和/或质量请求和/或获得与第二场景相关联的流。参见例如图4。
在示例中,定义了多个N个音频元素,并且在用户到这些音频元素的位置或区域的距离大于预定阈值的情况下,对N个音频元素进行处理以获得与靠近N个音频元素的位置或区域的位置或区域相关联的较少数量的M个音频元素(M<N),以在用户到N个音频元素的位置或区域的距离小于预定阈值的情况下,向系统提供与N个音频元素相关联的至少一个音频流,或者在用户到N个音频元素的位置或区域的距离大于预定阈值的情况下,向系统提供与M个音频元素相关联的至少一个音频流。参见例如图1.7。
在示例中,至少一个视觉环境场景与至少一个多个N个音频元素(N>=2)相关联,每个音频元素与视觉环境中的位置和/或区域相关联,其中至少可以以高比特率和/或质量水平以至少一个表示来提供至少一个多个N个音频元素,并且其中以低比特率和/或质量水平以至少一个表示来提供至少至少一个多个N个音频元素,其中通过处理N个音频元素以获得与靠近N个音频元素的位置或区域的位置或区域相关联的较少数量的M个音频元素(M<N)来获得至少一个表示,其中,系统被配置为在场景中当前用户的虚拟位置处音频元素为较大相关和/或较大可听的情况下,针对音频元素以更高的比特率和/或质量水平来请求表示,其中,在场景中当前用户的虚拟位置处音频元素为较小相关和/或较小可听的情况下,系统被配置为针对音频元素以较低的比特率和/或质量水平来请求表示。参见例如图1.7。
在示例中,在用户的距离和/或相关性和/或可听性水平和/或角度取向低于预定阈值的情况下,针对不同的音频元素来获得不同的流。参见例如图1.7。
在示例中,在不同的视口处提供了不同的音频元素,使得在一个第一音频元素落入当前视口内的情况下,以比未落入视口内的第二音频元素更高的比特率来获得第一音频元素。参见例如图6。
在示例中,定义了至少两个视觉环境场景,其中至少一个第一和第二音频元素与关联到第一视觉环境的第一场景相关联,并且至少一个第三音频元素与关联到第二视觉环境的第二场景相关联,其中系统102被配置为获取描述至少一个第二音频元素另外与第二视觉环境场景相关联的元数据,并且其中,在用户的虚拟位置处于第一视觉环境中的情况下,系统被配置为请求和/或接收至少第一和第二音频元素,并且其中,在用户的虚拟位置处于第二视觉环境场景中的情况下,系统配置为请求和/或接收至少第二和第三音频元素,并且其中,在用户的虚拟位置处于第一视觉环境场景和第二视觉环境场景之间转换中的情况下,系统被配置为请求和/或接收至少第一、第二和第三音频元素。参见例如图1.4。这也可以适用于图3。
在示例中,可以在至少一个音频流和/或适应集中提供至少一个第一音频元素,并且在至少一个第二音频流和/或适应集中提供至少一个第二音频元素,并且在至少一个第三音频流和/或适应集中提供至少一个第三音频元素,并且其中至少第一视觉环境场景由元数据描述为需要至少第一和第二音频流和/或适应集的完整场景,并且其中第二视觉环境场景由元数据描述为需要至少第三音频流和/或适应集以及与至少第一视觉环境场景相关联的至少第二音频流和/或适应集的不完整的场景,其中,系统包括元数据处理器,该元数据处理器被配置为在用户的虚拟位置处于第二视觉环境中的情况下,操控元数据以允许将属于第一视觉环境的第二音频流和与第二视觉环境相关联的第三音频流合并为新的单个流。参见例如图1.2、图1.3、图1.5和图1.6。
在示例中,系统102可以包括元数据处理器(例如,1236),该元数据处理器被配置为基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,在至少一个音频解码器之前操控至少一个音频流中的元数据。
在示例中,元数据处理器(例如,1236)可以被配置为基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,来在至少一个音频解码器之前启用和/或禁用至少一个音频流中的至少一个音频元素,其中元数据处理器可以被配置为在由于当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据而系统决定不再再现音频元素的情况下,在至少一个音频解码器之前禁用至少一个音频流中的至少一个音频元素,并且其中元数据处理器可以被配置为在由于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据而系统决定将再现音频元素的情况下,在至少一个音频解码器之前启用至少一个音频流中的至少一个音频元素。
服务器侧
在此上述还涉及服务器(120),用于将音频和视频流传递到用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的客户端,该视频和音频流将在媒体消费设备中再现,其中服务器(120)包括:用于编码的编码器和/或用于存储描述视觉环境的视频流的存储器,视觉环境与音频场景相关联;其中,服务器还包括用于编码的编码器和/或用于存储要被传递给客户端的多个流和/或音频元素和/或适应集,流和/或音频元素和/或适应集与至少一个音频场景相关联,其中,服务器被配置为:
基于来自客户端的请求来选择并传递视频流,所述视频流与环境相关联;
基于来自所述客户端的请求,选择音频流和/或音频元素和/或适应集,所述请求至少与所述用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据相关联以及与关联到所述环境的音频场景相关联;以及
向所述客户端传递所述音频流。
进一步的实施例和变型
取决于特定实现要求,可以以硬件实现示例。可以使用其上存储有电子可读控制信号的数字存储介质(例如,软盘、数字多功能盘(DVD)、蓝光盘、紧凑盘(CD)、只读存储器(ROM)、可编程只读存储器(PROM)、可擦除可编程只读存储器(EPROM)、电可擦除可编程只读存储器(EEPROM)或闪存)来执行实现,该电子可读控制信号与可编程计算机系统协作(或者能够与之协作)从而执行相应方法。因此,数字存储介质可以是计算机可读的。
通常,示例可以被实现为具有程序指令的计算机程序产品,程序指令可操作以在计算机程序产品在计算机上运行时执行方法之一。程序指令可以例如存储在机器可读介质上。
其他示例包括存储在机器可读载体上的计算机程序,该计算机程序用于执行本文所述的方法之一。换言之,方法示例因此是具有程序指令的计算机程序,该程序指令用于在计算机程序在计算机上运行时执行本文所述的方法之一。
因此,方法的另一示例是其上记录有计算机程序的数据载体介质(或者数字存储介质或计算机可读介质),该计算机程序用于执行本文所述的方法之一。数据载体介质、数字存储介质或记录介质是有形的和/或非转换性的,而不是无形和暂时的信号。
另一示例包括执行本文所述的方法之一的处理单元,例如,计算机或可编程逻辑器件。
另一示例包括其上安装有计算机程序的计算机,该计算机程序用于执行本文所述的方法之一。
另一示例包括向接收器(例如,以电子方式或以光学方式)传送计算机程序的装置或系统,该计算机程序用于执行本文所述的方法之一。接收器可以是例如计算机、移动设备、存储设备等。装置或系统可以例如包括用于向接收器传送计算机程序的文件服务器。
在一些示例中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文所述的方法的功能中的一些或全部。在一些示例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之。通常,这些方法由任何合适的硬件装置执行。
上述示例对于以上公开的原理是说明性的。应当理解的是,本文所述的布置和细节的修改和变形将是显而易见的。因此,旨在由所附专利权利要求的范围来限制而不是由借助对本文示例的描述和解释所给出的具体细节来限制。
示例实施例1,一种用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的系统(102),被配置为接收要在媒体消费设备中再现的视频和音频流,
其中所述系统(102)包括:
至少一个媒体视频解码器,被配置为解码来自视频流的视频信号,以向用户表示VR、AR、MR或360度视频环境场景,以及
至少一个音频解码器(104),被配置为从至少一个音频流(106)中解码音频信号(108),
其中,所述系统(102)被配置为:至少基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据(110),向服务器(120)请求(112)至少一个音频流(106)和/或音频流的一个音频元素和/或一个适应集。
示例实施例2,根据示例实施例1所述的系统,被配置为:向所述服务器(120)提供所述用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据(110),以从所述服务器(120)获得至少一个音频流(106)和/或音频流的一个音频元素和/或一个适应集。
示例实施例3,根据示例实施例1或2所述的系统,其中,至少一个场景与至少一个音频元素(152)相关联,每个音频元素与其中所述音频元素能够听见的视觉环境中的位置和/或区域相关联,使得针对所述场景中不同的用户的位置和/或视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,提供不同的音频流。
示例实施例4,根据前述示例实施例中的任一项所述的系统,被配置为:针对场景中所述当前用户的视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置,决定是否要再现音频流的至少一个音频元素和/或一个适应集,以及
其中,所述系统被配置为请求和/或接收所述当前用户的虚拟位置处的所述至少一个音频元素。
示例实施例5,根据前述示例实施例中的任一项所述的系统,其中,所述系统被配置为:至少基于所述用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据(110),预测性地决定音频流的至少一个音频元素(152)和/或一个适应集是否将变得相关和/或能够听见,以及
其中,所述系统被配置为:在预测的用户在场景中的移动和/或交互之前,请求和/或接收在特定用户的虚拟位置处的至少一个音频元素和/或音频流和/或适应集,
其中,所述系统被配置为:在用户在所述场景中的移动和/或交互之后,当接收到所述至少一个音频元素和/或音频流时,在所述特定用户的虚拟位置处对所述至少一个音频元素和/或音频流进行再现。
示例实施例6,根据前述示例实施例中的任一项所述的系统,被配置为:在用户在所述场景中的移动和/或交互之前,在所述用户的虚拟位置处以较低的比特率和/或质量水平来请求和/或接收所述至少一个音频元素(152),
其中,所述系统被配置为:在用户在所述场景中的移动和/或交互之后,在所述用户的虚拟位置处以较高的比特率和/或质量水平来请求和/或接收所述至少一个音频元素。
示例实施例7,根据前述示例实施例中的任一项所述的系统,其中,至少一个音频元素(152)与至少一个场景相关联,每个音频元素与关联到所述场景的所述视觉环境中的位置和/或区域相关联,
其中,所述系统被配置为:与距所述用户更远的音频元素相比,对于距所述用户更近的音频元素,以更高的比特率和/或质量来请求和/或接收流。
示例实施例8,根据前述示例实施例中的任一项所述的系统,其中,至少一个音频元素(152)与至少一个场景相关联,所述至少一个音频元素与关联到所述场景的所述视觉环境中的位置和/或区域相关联,
其中,所述系统被配置为:基于音频元素在所述场景中每个用户的虚拟位置处的相关性和/或可听性水平,针对音频元素以不同的比特率和/或质量水平请求不同的流,
其中,所述系统被配置为:针对在所述当前用户的虚拟位置处为更相关和/或更能够听见的音频元素,以较高的比特率和/或质量水平来请求音频流,和/或
针对在所述当前用户的虚拟位置处为更不相关和/或更不能够听见的音频元素,以较低比特率和/或质量水平请求音频流。
示例实施例9,根据前述示例实施例中的任一项所述的系统,其中,至少一个音频元素(152)与场景相关联,每个音频元素与关联到所述场景的所述视觉环境中的位置和/或区域相关联,
其中,所述系统配置为定期向所述服务器发送所述用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据(110),使得:
针对第一位置,从所述服务器提供较高比特率和/或质量的流,以及
针对第二位置,从所述服务器提供较低比特率和/或质量的流,
其中所述第一位置比所述第二位置更靠近所述至少一个音频元素(152)。
示例实施例10,根据前述示例实施例中的任一项所述的系统,其中,针对多个视觉环境定义多个场景(150A、150B),所述多个视觉环境例如是邻近和/或相邻环境,
使得提供与第一当前场景相关联的第一流,并且在用户到第二其他场景的转换的情况下,提供与所述第一场景相关联的流和与所述第二场景相关联的第二流两者。
示例实施例11,根据前述示例实施例中的任一项所述的系统,其中,针对第一和第二视觉环境来定义多个场景(150A、150B),第一和第二环境是邻近和/或相邻环境,
其中,在用户的位置或虚拟位置处于与所述第一场景相关联的第一环境中的情况下,从所述服务器提供与所述第一场景相关联的第一流,以再现所述第一场景,
在用户的位置或虚拟位置处于与所述第二场景相关联的第二环境中的情况下,从所述服务器提供与所述第二场景相关联的第二流,以再现所述第二场景,以及
在所述用户的位置或虚拟位置处于所述第一场景和所述第二场景之间的转换位置中的情况下,提供与所述第一场景相关联的第一流和与所述第二场景相关联的第二流两者。
示例实施例12,根据前述示例实施例中的任一项所述的系统,其中,针对第一和第二视觉环境来定义多个场景(150A、150B),所述第一和第二视觉环境是邻近和/或相邻环境,
其中,所述系统被配置为:在用户的虚拟位置处于所述第一环境中的情况下,请求和/或接收与关联到所述第一环境的第一场景(150A)相关联的第一流,以用于再现所述第一场景,
其中,所述系统被配置为:在所述用户的虚拟位置处于所述第二环境中的情况下,请求和/或接收与关联到所述第二环境的第二场景(150B)相关联的第二流,以再现所述第二场景,以及
其中,所述系统被配置为:在所述用户的虚拟位置处于所述第一环境与所述第二环境之间的转换位置(150AB)中的情况下,请求和/或接收与所述第一场景相关联的第一流和与所述第二场景相关联的第二流两者。
示例实施例13,根据示例实施例10至12中的任一项所述的系统,其中:
当所述用户处于与所述第一场景相关联的所述第一环境中时,以较高的比特率和/或质量来获得与所述第一场景相关联的所述第一流,
当所述用户处于从所述第一场景到所述第二场景的转换位置的开始时,以较低的比特率和/或质量来获得与关联到所述第二环境的所述第二场景相关联的所述第二流,以及
当所述用户处于从所述第一场景到所述第二场景的转换位置的未端时,以较低的比特率和/或质量来获得与所述第一场景相关联的所述第一流,并且以较高的比特率和/或质量获得与所述第二场景相关联的所述第二流,
其中,所述较低的比特率和/或质量低于所述较高的比特率和/或质量。
示例实施例14,根据前述示例实施例中的任一项所述的系统,其中,针对多个环境来定义多个场景(150A、150B),所述多个环境例如是邻近和/或相邻环境,
使得所述系统被配置为获得与关联到第一当前环境的第一当前场景相关联的流,以及
在所述用户的位置或虚拟位置距所述场景的边界的距离低于预定阈值的情况下,所述系统还获得与关联到所述第二场景的第二邻近和/或相邻环境相关联的音频流。
示例实施例15,根据前述示例实施例中的任一项所述的系统,其中,针对多个视觉环境来定义多个场景(150A、150B),
使得所述系统以较高的比特率和/或质量来请求和/或获得与所述当前场景相关联的流,以及以较低的比特率和/或质量来请求和/或获得与所述第二场景相关联的流,
其中,所述较低的比特率和/或质量低于所述较高的比特率和/或质量。
示例实施例16,根据前述示例实施例中的任一项所述的系统,其中,定义了多个N个音频元素,并且在用户到这些音频元素的位置或区域的距离大于预定阈值的情况下,处理N个音频元素以获得与靠近所述N个音频元素的位置或区域的位置或区域相关联的较少数量M个音频元素(M<N),以:
在所述用户到所述N个音频元素的位置或区域的距离小于预定阈值的情况下,向所述系统提供与所述N个音频元素相关联的至少一个音频流,或者
在所述用户到所述N个音频元素的位置或区域的距离大于预定阈值的情况下,向所述系统提供与所述M个音频元素相关联的至少一个音频流。
示例实施例17,根据前述示例实施例中的任一项所述的系统,其中,至少一个视觉环境场景与至少一个多个N个音频元素(N>=2)相关联,每个音频元素与所述视觉环境中的位置和/或区域相关联,
其中,以高比特率和/或质量水平以至少一个表示来提供至少所述至少一个多个N个音频元素,以及
其中以低比特率和/或质量水平以至少一个表示来提供至少所述至少一个多个N个音频元素,其中通过处理所述N个音频元素以获得与靠近所述N个音频元素的位置或区域的位置或区域相关联的较少数量M个音频元素(M<N),来获得至少一个表示,
其中,所述系统被配置为在所述音频元素在所述当前用户在所述场景中的虚拟位置处更相关和/或更能够听见的情况下,针对所述音频元素以较高的比特率和/或质量水平来请求所述表示,
其中,所述系统被配置为在所述音频元素在所述当前用户在所述场景中的虚拟位置处更不相关和/或更不能够听见的情况下,针对所述音频元素以较低比特率和/或质量水平来请求表示。
示例实施例18,根据示例实施例16和17所述的系统,其中,在所述用户的距离和/或相关性和/或可听性水平和/或角度取向低于预定阈值的情况下,针对不同的音频元素来获得不同的流。
示例实施例19,根据前述示例实施例中的任一项所述的系统,其中,所述系统被配置为基于所述场景中所述用户的取向和/或用户的移动方向和/或用户交互来请求和/或获得所述流。
示例实施例20,根据前述示例实施例中的任一项所述的系统,其中,所述视口与所述位置和/或虚拟位置和/或移动数据和/或头部相关联。
示例实施例21,根据前述示例实施例中的任一项所述的系统,其中,在不同的视口处提供不同的音频元素,其中,所述系统被配置为:在一个第一音频元素(S1)落入视口(160-1)内的情况下,相比未落入所述视口的第二音频元素(S2),以更高比特率请求和/或接收第一音频元素。
示例实施例22,根据前述示例实施例中的任一项所述的系统,被配置为请求和/或接收第一音频流和第二音频流,其中,所述第一音频流中的所述第一音频元素比所述第二个音频流中的所述第二音频元素更相关和/或更能够听见,
其中,以比所述第二音频流的比特率和/或质量高的比特率和/或质量来请求和/或接收所述第一音频流。
示例实施例23,根据前述示例实施例中的任一项所述的系统,其中,定义至少两个视觉环境场景,其中,至少一个第一和第二音频元素与关联到所述第一视觉环境的第一场景相关联,并且至少一个第三音频元素与关联到第二视觉环境的第二场景相关联,
其中,所述系统被配置为获得描述所述至少一个第二音频元素另外地与所述第二视觉环境场景相关联的元数据,以及
其中,所述系统被配置为在所述用户的虚拟位置处于所述第一视觉环境中的情况下,请求和/或接收所述至少第一和第二音频元素,以及
其中,所述系统被配置为在所述用户的虚拟位置处于所述第二视觉环境场景中的情况下,请求和/或接收所述至少第二和第三音频元素,以及
其中,所述系统被配置为在所述用户的虚拟位置处于所述第一视觉环境场景与所述第二视觉环境场景之间的转换的情况下,请求和/或接收所述至少第一、第二和第三音频元素。
示例实施例24,根据示例实施例23所述的系统,其中,在至少一个音频流和/或适应集中提供所述至少一个第一音频元素,并且在至少一个第二音频流和/或适应集中提供所述至少一个第二音频元素,并且在至少一个第三音频流和/或适应集中提供所述至少一个第三音频元素,并且其中,所述至少第一视觉环境场景由元数据描述为需要所述至少第一和第二音频流和/或适应集的完整场景,并且其中,所述第二视觉环境场景由元数据描述为需要所述至少第三音频流和/或适应集以及与所述至少第一视觉环境场景相关联的所述至少第二音频流和/或适应集的不完整场景,
其中,所述系统包括元数据处理器,所述元数据处理器被配置为操控元数据,以允许在所述用户的虚拟位置处于所述第二视觉环境的情况下,将属于所述第一视觉环境的所述第二音频流和与所述第二视觉环境相关联的所述第三音频流合并为新的单个流。
示例实施例25,根据前述示例实施例中的任一项所述的系统,其中,所述系统包括元数据处理器,所述元数据处理器被配置为基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,在所述至少一个音频解码器之前操控至少一个音频流中的元数据。
示例实施例26,根据示例实施例25所述的系统,其中,所述元数据处理器被配置为:基于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,在所述至少一个音频解码器之前启用和/或禁用至少一个音频流中的至少一个音频元素,其中
所述元数据处理器被配置为:在由于当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,所述系统决定不再再现所述音频元素的情况下,在所述至少一个音频解码器之前禁用至少一个音频流中的至少一个音频元素,并且其中
所述元数据处理器被配置为:在由于用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据,所述系统决定将再现所述音频元素的情况下,在所述至少一个音频解码器之前启用至少一个音频流中的至少一个音频元素。
示例实施例27,根据前述示例实施例中的任一项所述的系统,被配置为禁用对基于所述用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置而选择的音频元素的解码。
示例实施例28,根据前述示例实施例中的任一项所述的系统,被配置为将与所述当前音频场景相关联的至少一个第一音频流合并到与相邻、邻近和/或未来音频场景相关联的至少一个流。
示例实施例29,根据前述示例实施例中的任一项所述的系统,被配置为获取和/或收集关于所述用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据的统计或聚合数据,以向所述服务器发送与所述统计或聚合数据相关联的请求。
示例实施例30,根据前述示例实施例中的任一项所述的系统,被配置为基于与至少一个流相关联的元数据并且基于所述用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据,不激活所述至少一个流的解码和/或再现。
示例实施例31,根据前述示例实施例中的任一项所述的系统,还被配置为:
至少基于所述用户的当前或估计的视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据,操控与选择的音频流的组相关联的元数据,以:
选择和/或启用和/或激活合成要再现的所述音频场景的音频元素;和/或
使得能够将所有选择的音频流合并到单个音频流。
示例实施例32,根据前述示例实施例中的任一项所述的系统,被配置为基于所述用户的位置距与不同场景相关联的相邻和/或邻近环境的边界的距离或与用户在所述当前环境中的位置相关联的其他度量或对未来环境的预测,来控制向所述服务器对所述至少一个流的所述请求。
示例实施例33,根据前述示例实施例中的任一项所述的系统,其中,针对每个音频元素或音频对象,从所述服务器系统(120)提供信息,其中,所述信息包括与其中所述声音场景或所述音频元素是活动的位置有关的描述性信息。
示例实施例34,根据前述示例实施例中的任一项所述的系统,被配置为基于当前或未来或视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置和/或用户的选择,在再现一个场景与合成或混合或复用或叠加或组合至少两个场景之间进行选择,所述两个场景与不同的相邻和/或邻近环境相关联。
示例实施例35,根据前述示例实施例中的任一项所述的系统,被配置为至少创建或使用所述适应集,使得:
多个适应集与一个音频场景相关联;和/或
提供了将每个适应集与一个视点或一个音频场景相关联的附加信息;和/或
提供可以包括以下项的附加信息:
-关于一个音频场景的边界的信息和/或
-关于一个适应集与一个音频场景之间的关系的信息(例如,音频场景被编码在三个流中,所述三个流被封装在三个适应集中)和/或
-关于所述音频场景的边界与所述多个适应集之间的连接的信息。
示例实施例36,根据前述示例实施例中的任一项所述的系统,被配置为:
接收与相邻或邻近环境相关联的场景的流;
在检测到两个环境之间的边界的转换时,开始解码和/或再现用于所述相邻或邻近环境的所述流。
示例实施例37,一种系统,包括前述示例实施例中的任一项所述的系统,所述系统被配置为作为客户端和服务器进行操作,所述服务器被配置为传递要在媒体消费设备中再现的视频和/音频流。
示例实施例38,根据前述示例实施例中的任一项所述的系统,其中,所述系统还被配置为:
请求和/或接收至少一个第一适应集,所述第一适应集包括与至少一个第一音频场景相关联的至少一个音频流;
请求和/或接收至少一个第二适应集,所述第二适应集包括与至少两个音频场景相关联的至少一个第二音频流,所述至少两个音频场景包括至少一个第一音频场景;以及
基于与以下项有关的能够使用的元数据,使所述至少一个第一音频流能够和所述至少一个第二音频流合并为要解码的新的音频流:用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据和/或描述所述至少一个第一适应集与所述至少一个第一音频场景的关联和/或所述至少一个第二适应集与所述至少一个第一音频场景的关联的信息。
示例实施例39,根据前述示例实施例中的任一项所述的系统,被配置为:
接收关于用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据和/或表征由所述用户的动作触发的变化的任何信息的信息;以及
接收关于适应集的可用性的信息以及描述至少一个适应集与至少一个场景和/或视点和/或视口和/或位置和/或虚拟位置和/或移动数据和/或取向的关联的信息。
示例实施例40,根据前述示例实施例中的任一项所述的系统,被配置为:
决定是否要再现嵌入在至少一个流中的来自至少一个音频场景的至少一个音频元素和嵌入在至少一个附加流中的来自至少一个附加音频场景的至少一个附加音频元素;以及
在肯定的决定的情况下,引起将附加音频场景的所述至少一个附加流合并或合成或复用或叠加或组合到所述至少一个音频场景的所述至少一个流的操作。
示例实施例41,根据前述示例实施例中的任一项所述的系统,被配置为:
至少基于所述用户的当前视口和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据,操控与选择的音频流相关联的音频元数据,以:
选择和/或启用和/或激活合成决定要再现的所述音频场景的所述音频元素;以及
使得能够将所有选择的音频流合并到单个音频流。
示例实施例42,一种服务器(120),用于将音频和视频流传递给用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的客户端,所述视频和音频流将在媒体消费设备中再现,
其中,所述服务器(120)包括用于编码的编码器和/或存储器,所述存储器用于存储描述视觉环境的视频流,所述视觉环境与音频场景相关联;
其中,所述服务器还包括用于编码的编码器和/或存储器,所述存储器用于存储要传递给所述客户端的多个流和/或音频元素和/或适应集,所述流和/或音频元素和/或适应集与至少一个音频场景相关联,
其中,所述服务器被配置为:
基于来自客户端的请求来选择并传递视频流,所述视频流与环境相关联;
基于来自所述客户端的请求,选择音频流和/或音频元素和/或适应集,所述请求至少与所述用户的当前视口和/或头部取向和/或移动数据和/或交互元数据和/或虚拟位置数据相关联以及与关
联到所述环境的音频场景相关联;以及
向所述客户端传递所述音频流。
示例实施例43,根据示例实施例42所述的服务器,其中,所述流被封装到适应集中,每个适应集包括与相同音频内容的具有不同比特率和/或质量的不同表示相关联的多个流,
其中,基于来自所述客户端的请求来选择所选择的适应集。
示例实施例44,一种系统,包括作为客户端和服务器进行操作的示例实施例1-41中的任一项所述的系统。
示例实施例45,根据示例实施例44所述的系统,包括示例实施例42或43所述的服务器。
示例实施例46,一种用于虚拟现实VR、增强现实AR、混合现实MR或360度视频环境的方法,所述方法被配置为接收要在媒体消费设备中再现的视频和/或音频流,包括:
从视频流中解码视频信号,以向用户表示VR、AR、MR或360度视频环境场景,以及
从音频流中解码音频信号,
基于用户的当前视口和/或位置数据和/或头部取向和/或移动数据和/或元数据和/或虚拟位置数据和/或元数据,向服务器请求和/或从服务器获取至少一个音频流。
示例实施例47,一种计算机程序,包括指令,所述指令当由处理器执行时使所述处理器执行示例实施例46所述的方法。
- 用于虚拟现实应用的音频传递优化
- 用于虚拟现实应用的音频传递优化