低剂量CT投影图像生成模型建立方法及配对数据生成方法
文献发布时间:2024-04-18 19:53:33
技术领域
本发明属于图像处理技术领域,更具体地,涉及低剂量CT投影图像生成模型建立方法及配对数据生成方法。
背景技术
X射线计算机断层扫描(X-RayComputed Tomography,CT)是一种无创成像方式,广泛用于临床疾病检查与治疗过程。然而,CT扫描会使患者暴露于X射线电离辐射中,可能导致癌症、基因突变和其他疾病。因此,低剂量CT成像技术对于降低辐射诱发疾病的风险至关重要。
目前,为了降低CT扫描时的辐射剂量,主要采用降低X射线管的电流或者减少投影的个数等方法,这两种方式都会严重影响CT图像质量,干扰医生的诊断,甚至可能造成严重的医疗事故。因此,在降低X射线剂量的情况下如何保证CT图像的质量十分重要。对于低剂量CT图像的重建,优化其图像的算法主要分为两种,分别为基于迭代重建的算法和基于深度学习的算法。基于迭代重建的算法,如非局部均匀滤波,三维块匹配滤波算法等算法,其优化函数充分考虑了成像系统、统计噪声模型以及CT先验信息等因素,可以得到较好的效果,但存在计算复杂度高、速度较慢且需要人为的先验知识等缺点。相比之下,基于深度学习的方法具有更好的性能、处理速度,并具有摆脱人为先验知识的限制的潜力,因此可能实现更加优越的性能。
基于深度学习的方法通常需要大量低剂量及其对应的正常剂量的配对数据进行监督训练,采用卷积核逐步提取图像的低级和高级特征,采用损失函数评估网络输出与正常剂量图像的误差,以一种反向传播的方式来更新卷积核权重。然而在实际临床应用场景下,难以提供大量的高低剂量配对数据用来训练,因此如何在缺少配对数据的情况下实现基于深度学习的低剂量CT重建是一个十分关键且极具挑战性的课题,引起了众多研究者的关注。
目前,针对缺少配对数据的问题,已有研究团队提出了一些基于非配对学习的深度学习方法,主要分为直接策略和间接策略。直接策略直接向非配对正常剂量数据学习以去除低剂量图像中的噪声,如ISCL(Interdependent Self-Cooperative Learning)。间接策略即先从正常剂量图像模拟生成其对应的低剂量图像,再以配对学习的方式训练深度学习网络,如UIDNet(Unpaired Image Denoising with Conditional AdversarialNetworks)以及FBModel(Flow-Based Model)等。但是目前这些网络仍然存在问题,比如生成的低剂量图像可能丢失结构信息、引入原本不存在的结构,导致与正常剂量图像的内容不匹配,以及生成的图像中噪声特性与真实情况不符合等。
基于系统参数的物理方法模拟的低剂量投影图像与真实的低剂量投影图像具有较好的内容一致性,但噪声特性与真实低剂量投影图像的噪声特性并不相符。
总体而言,现有方法所生成的低剂量CT投影图像,相比于与正常剂量投影图像实际配对的低剂量投影图像仍存在一定的误差,这使得所生成的配对数据训练得到的深度学习去噪网络的性能,仍有待进一步提高。
发明内容
针对现有技术的缺陷和改进需求,本发明提供了低剂量CT投影图像生成模型建立方法及配对数据生成方法,其目的在于,生成高质量的高低剂量CT投影图像配对数据,以解决深度学习网络在训练过程中较为依赖配对数据,而配对数据在实际临床场景中极难获得的问题。
为实现上述目的,按照本发明的一个方面,提供了一种低剂量CT投影图像生成模型建立方法,包括:
获取真实的正常剂量投影图像并生成对应的低剂量投影图像,利用生成的低剂量投影图像与真实低剂量投影图像构建样本数据集;
建立生成对抗网络;生成对抗网络包括生成器和判别器;生成器用于对输入的初始低剂量投影图像进行修正,得到目标低剂量投影图像;判别器以目标低剂量投影图像和真实低剂量投影图像为输入,用于提取输入的低剂量投影图像的噪声分布,以判断所输入的是否为真实的低剂量投影图像;
利用样本数据集对生成对抗网络进行训练;训练过程中,损失函数为
训练结束后,提取生成对抗网络中的生成器作为低剂量CT投影图像生成模型。
进一步地,判别器包括:全局判别分支和局部判别分支;
全局判别分支用于提取输入的低剂量投影图像的全局噪声分布,以判断输入的低剂量投影图像是否为真实的低剂量投影图像;
局部判别分支包括裁剪模块和局部判别器;裁剪模块用于将输入的目标低剂量投影图像和真实低剂量投影图像分别随机裁剪为相同大小的图像块后在通道维度上相连为局部图像块组;局部判别器用于提取局部图像块组的局部噪声分布,以判断输入的低剂量投影图像是否为真实的低剂量投影图像;
并且,噪声损失包括全局噪声损失和局部噪声损失。
进一步地,全局判别分支包括:高频信息提取器和全局判别器;
高频信息提取器用于对输入的低剂量投影图像提取低频信息,并从输入的低剂量投影图像中减去所提取的低频信息,得到高频信息;
全局判别器用于根据高频信息提取器提取的高频信息获取全局噪声分布,以判断输入的低剂量投影图像是否为真实的低剂量投影图像。
进一步地,高频信息提取器包括3×3平均池化层、5×5平均池化层、7×7平均池化层和11×11平均池化层,分别用于对输入的低剂量投影图像提取相应的低频信息;
高频信息提取器还包括高频信息提取模块,用于分别从输入的低剂量投影图像中减去所提取的低频信息,得到高频信息。
进一步地,全局噪声损失为:
其中,
进一步地,局部损失为:
其中,
进一步地,β=7×10
进一步地,构建样本数据集时,所获取的真实的正常剂量投影图像和低剂量投影图像均为经过预处理之后的图像;预处理包括:
将图像的像素值转化为浮点数类型后,对像素进行归一化。
按照本发明的另一个方面,提供了一种配对高低剂量投影数据生成方法,包括:
生成正常剂量投影图像对应的低剂量投影图像,作为初始低剂量投影图像;
将初始低剂量投影图像输入至由本申请提供的低剂量CT投影图像生成模型建立方法所建立的低剂量CT投影图像生成模型,得到目标低剂量投影图像,由正常剂量投影图像和目标低剂量投影图像构成配对高低剂量投影数据。
按照本发明的又一个方面,提供了一种计算机可读存储介质,包括存储的计算机程序;计算机程序被处理器执行时,控制计算机可读存储介质所在设备执行本发明提供的上述低剂量CT投影图像生成模型建立方法,和/或,本发明提供的低剂量CT投影图像生成方法。
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
(1)本发明基于生成对抗网络(Generative Adversarial Networks,GAN)建立初始的深度学习模型,其中的生成器用于对正常剂量投影图像对应的初始低剂量投影图像进行修正,获得目标低剂量投影图像,判别器用于根据噪声分布判别所输入的目标低剂量投影图像是否为真实的低剂量投影图像,生成对抗网络是深度学习领域中一种常用的生成模型,通过让两个神经网络即生成器和判别器以相互博弈的方式进行学习,其网络结构灵活、表达能力较强,可以直接向非配对的低剂量图像学习其噪声特性;由于本发明在对该生成对抗网络进行训练时,所使用的损失函数包含了两个部分的损失,即输入判别器的目标低剂量投影图像与真实低剂量投影图像之间的噪声损失,以及生成器输出的目标低剂量投影图像与输入生成器的初始低剂量投影图像之间的内容损失,本发明所设计的该损失函数,在保证生成器所生成的低剂量投影图像的噪声分布与真实低剂量投影图像的噪声分布保持一致的同时,能够以初始低剂量投影图像(可利用基于物理模拟等方式生成)为参考,解决在使用GAN网络时极易发生的图像内容改变问题,使生成器产生的低剂量投影图像内容与真实低剂量投影图像内容保持一致。总体而言,本发明所建立的低剂量CT投影图像生成模型,所生成的低剂量投影图像在噪声分布和内容方面均能与真实低剂量投影图像保持一致,质量较高,且不依赖于真实配对数据,对于生成的配对数据在深度学习去噪网络中的应用至关重要。
(2)在本发明的优选方案中,本发明基于生成对抗网络所建立初始的深度学习模型中,判别器为双路径判别器,其中的两个判别器分别学习低剂量投影图像中的全局噪声分布和与结构相关的局部噪声分布,使得生成器生成的低剂量投影图像的噪声特性与真实低剂量投影图像更加相符。
(3)在本发明的优选方案中,本发明基于生成对抗网络所建立初始的深度学习模型中,用于学习低剂量投影图像中的全局噪声分布的路径中,包含了高频信息提取器和全局判别器,该高频信息提取器能够有效提取低剂量投影图像中全局噪声分布,使得全局判别器能够更好地学习真实低剂量投影图像的全局噪声分布,使得生成器生成的低剂量投影图像的噪声特性与真实低剂量投影图像更加相符。
(4)在本发明的优选方案中,用于学习低剂量投影图像中的全局噪声分布的路径中所包含的高频信息提取器具体包括3×3平均池化层、5×5平均池化层、7×7平均池化层和11×11平均池化层,分别用于对输入的低剂量投影图像提取相应的低频信息,该高频信息提取器还包括高频信息提取模块,用于分别从输入的低剂量投影图像中减去所提取的低频信息,得到高频信息;基于该结构,本发明中,高频信息提取器能够准确提取图像中的高频信息,有利于全局判别器准确获取全局噪声分布信息。
(5)在本发明的优选方案中,全局噪声损失和局部噪声损失均基于Wasserstein距离和梯度惩罚构造,能够在保证训练所得模型的性能的基础上,有效提高模型的训练效率。
(6)在本发明的优选方案中,设置损失函数中,内容损失
(7)在本发明的优选方案中,在构建样本数据集时,会对图像进行相应的预处理,便于后续模型的处理。
附图说明
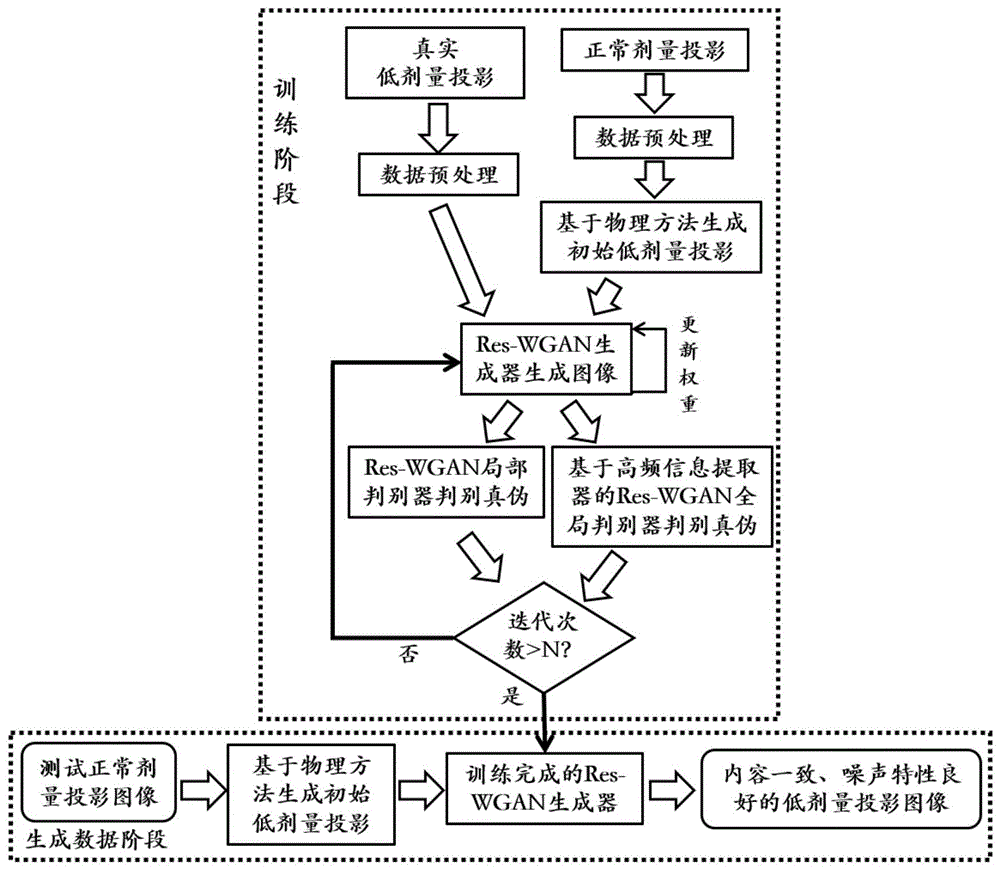
图1为本发明实施例提供的低剂量CT投影图像生成模型建立方法及配对数据生成方法示意图;
图2为本发明实施例提供的生成对抗网络中生成器的结构示意图;
图3为本发明实施例提供的生成对抗网络中全局判别器和局部判别器的结构示意图;
图4为本发明实施例提供的生成对抗网络中高频信息提取器的结构示意图;
图5为本发明实施例提供的配对数据生成方法与其他配对数据生成方法的结果对比图;其中,(a)为正常剂量投影,(b)为真实低剂量投影,(c)为UIDNet生成的投影,(d)为ISCL生成的投影,(e)为FBModel生成的投影,(f)为实施例提供的配对高低剂量投影数据生成方法生成的投影;
图6为本发明实施例提供的配对数据生成方法与其他配对数据生成方法在感兴趣区域的对比图;其中,(a)为正常剂量投影,(b)为真实低剂量投影,(c)为UIDNet生成的投影,(d)为ISCL生成的投影,(e)为FBModel生成的投影,(f)为实施例提供的配对高低剂量投影数据生成方法生成的投影;
图7为基于本发明实施例提供的配对数据生成方法与基于其他配对数据生成方法生成的配对训练数据,双域降噪网络训练完成后,测试时提升真实低剂量锥束CT图像质量的视觉结果对比图;其中,(a)为正常剂量CT图像,(b)为真实低剂量CT图像,(c)为基于真实数据训练网络的测试结果,(d)为基于UIDNet生成数据训练网络的测试结果,(e)为基于ISCL生成数据训练网络的测试结果,(f)为基于FBModel生成数据训练网络的测试结果,(g)为基于实施例生成数据训练网络的测试结果;
图8为基于本发明实施例提供的配对数据生成方法与基于其他配对数据生成方法生成的配对训练数据,双域降噪网络训练完成后,测试时提升真实低剂量锥束CT图像质量在感兴趣区域的视觉结果对比图;(a)为正常剂量CT图像,(b)为真实低剂量CT图像,(c)为基于真实数据训练网络的测试结果,(d)为基于UIDNet生成数据训练网络的测试结果,(e)为基于ISCL生成数据训练网络的测试结果,(f)为基于FBModel生成数据训练网络的测试结果,(g)为基于实施例生成数据训练网络的测试结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
在本发明中,本发明及附图中的术语“第一”、“第二”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
为了解决深度学习网络在训练过程中较为依赖配对数据,而配对数据在实际临床场景中极难获得的问题,本发明提供了低剂量CT投影图像生成模型建立方法及配对数据生成方法,其整体思路在于:基于生成对抗网络建立初始的模型,通过让其中的生成器和判别器以相互博弈的方式进行学习,可以直接向非配对的低剂量投影图像学习其噪声特性,并通过对损失函数进行改进,使得可以从非配对的正常剂量投影图像和低剂量投影图像中模拟产生配对数据,较好地保留图像内容信息的同时其噪声特性也更符合真实低剂量投影图像的噪声分布,从而满足深度学习架构的配对训练的需求。在此基础上,进一步对模型结构进行改进,使得生成器生成的低剂量投影图像的噪声特性与真实低剂量投影图像更加相符。
以下为实施例。
实施例1:
一种低剂量CT投影图像生成模型建立方法,如图1所示,包括:
获取真实的正常剂量投影图像并生成对应的低剂量投影图像,利用生成的低剂量投影图像与真实低剂量投影图像构建样本数据集。
为了便于对数据的处理,本实施例中,构建样本数据集时,所获取的真实的正常剂量投影图像和低剂量投影图像均为经过预处理之后的图像;预处理包括:
将图像的像素值转化为浮点数类型,以符合神经网络对输入数据类型的要求;之后,对像素进行归一化,可选地,本实施例中,归一化方法如下:
其中P
可选地,本实施例基于物理模拟方法生成正常剂量投影图像对应的初始低剂量投影图像,且具体为向正常剂量投影图像添加泊松噪声,将该方法记为f
其中,
参阅图1,本实施例还包括:建立生成对抗网络;该生成对抗网络包括生成器和判别器;生成器用于对输入的初始低剂量投影图像进行修正,得到目标低剂量投影图像;判别器以目标低剂量投影图像和真实低剂量投影图像为输入,用于提取输入的低剂量投影图像的噪声分布,以判断所输入的是否为真实的低剂量投影图像。
可选地,如图1所示,本实施例中,所建立的生成对抗网络具体为Res-WGAN网络,其中的生成器结构如图2所示,将初始低剂量投影图像输入该生成器后,首先使用2个卷积单元(卷积层+ReLU激活函数)提取特征,之后用最大池化层(MaxPooling)来学习图像的边缘和纹理结构,同时降低信息冗余;再使用2个卷积单元和一个最大池化层提取图像特征和纹理结构;之后再次使用两个卷积单元进一步提取高维信息;之后经过一个Dropout层,随机丢掉一些卷积(比例为50%),目的在于提高网络泛化能力;此时已经得到丰富的图像高维特征,将这些特征通过上采样(Upsample)和卷积层结合(即反卷积)的方式进行处理,最后再经过一个1×1的卷积层将其还原为原始图像的尺寸,重建出低剂量投影图像的结构信息,得到修正后的生成结果,即目标低剂量投影图像
为保证网络在训练中不出现梯度消失以及输出更多的图像细节,本发明中采用残差结构,即将下采样过程中的第二、四个卷积单元的输出通过跳跃连接分别与上采样过程中的第七、第十个卷积层的输出以扩增通道的方式连接在一起,同时将输入层与倒数第二层的输出相加连接。本实施例中,生成器网络的卷积层以及反卷积层(除最后一层采用1×1卷积核外)均采用3×3的卷积核,卷积核个数分别为32,32,64,64,128,128,64,64,64,32,32,32,1,其中两个下采样层和两个上采样层均采用2×2的卷积核,步长为2,dropout层的比率为0.5。
为了增强生成器学习真实噪声特性的能力,作为一种优选的实施方式,本实施例中,生成对抗网络中的判别器为一种双路径判别器,具体包括全局判别分支和局部判别分支,分别用于学习真实低剂量投影图像的全局噪声分布和局部噪声分布;
为了更好地提取图像的高频信息,本实施例中,全局判别分支具体包括:高频信息提取器和全局判别器;
高频信息提取器用于对输入的低剂量投影图像提取低频信息,并从输入的低剂量投影图像中减去所提取的低频信息,得到高频信息;其结构如图3所示,包括3×3平均池化层、5×5平均池化层、7×7平均池化层和11×11平均池化层,分别用于对输入的低剂量投影图像提取相应的低频信息;将生成器生成的目标低剂量投影图像以及真实低剂量投影图像输入该高频信息提取器的平均池化层后,会提取到图像的低频信息,之后再从输入的低剂量投影图像中减去所提取的低频信息,即得到高频信息,将目标低剂量投影图像与真实低剂量投影图像的高频信息共同输入全局判别器中,从而更有利于全局判别器判断高频信息即全局噪声分布的真假。
全局判别器用于根据高频信息提取器提取的高频信息获取全局噪声分布,以判断输入的低剂量投影图像是否为真实的低剂量投影图像,全局判别器的结构如图4所示,由4个卷积单元和一个全连接层组成,每个卷积单元采用大小为5×5,步长为2的卷积核,并采用Leaky-ReLU激活函数来提取图像特征,最后采用一个全连接层输出一个实数,判别器输出为1表示判别为真,即判别器认为生成器生成的图像与真实低剂量投影图像十分接近,0表示判别为假,即判别器认为生成器生成的图像与真实低剂量投影图像存在较大差异。
基于Wasserstein距离和梯度惩罚,生成器G与全局判别器D
其中,
局部判别分支包括裁剪模块和局部判别器;裁剪模块用于将输入的低剂量投影图像随机裁剪为相同大小的图像块后在通道维度上相连为局部图像块组;可选地,本实施例中,对于低剂量投影图像,会将其随机裁剪为9个图像块,并将这些图像块在通道维度上相连接,得到局部图像块组,其大小为32×32×9;
局部判别器用于提取局部图像块组的局部噪声分布,以判断输入的低剂量投影图像是否为真实的低剂量投影图像;本实施例中,局部判别器的结构与全局判别器的结构相同。
基于Wasserstein距离和梯度惩罚,生成器G与局部判别器D
其中,
以上全局噪声损失和局部噪声损失将共同参与构成生成对抗网络的损失函数。只使用全局判别器将会忽略细微结构附近的噪声特性,本实施例在全局判别器的基础上进一步引入局部判别器,能够使得生成器生成的低剂量投影图像与真实低剂量投影图像的噪声分布更为相符。
参阅图1,样本数据集和生成对抗网络建立完成后,本实施例进一步包括:利用样本数据集对生成对抗网络进行训练;GAN网络生成图像往往会改变图像内容,为了解决该问题,本实施例在损失函数中引入了内容保真损失(Physics-based Content-fidelityloss,PCLoss),用于表示生成器输出的目标低剂量投影图像与输入生成器的初始低剂量投影图像之间的内容损失,其定义如下:
/>
其中W和H分别代表图像的宽度和高度,
综上,本实施在对生成对抗网络进行训练过程中,损失函数具体为:
即
其中,
在训练过程中,会更新网络参数,达到训练次数后训练结束,输出训练好的生成对抗网络,提取其中的生成器作为低剂量CT投影图像生成模型。
需要说明的是,本实施例中,在构建用于模型训练和测试的样本数据集时,所使用的真实低剂量投影图像用于提供噪声分布的先验信息,无论是否与正常剂量的投影图像配对,均可用于本实施例,因此,本实施例不依赖于配对的CT投影图像。
总体来说,本实施例提供的低剂量CT投影图像生成模型建立方法,存在以下特点:
(1)基于Res-WGAN的生成器,并对生成对抗网络的训练损失函数进行改进,在其中引入了内容保真损失PCLoss,该损失函数以基于物理模拟生成的初始低剂量投影图像为参考,解决了在使用GAN网络时极易发生的图像内容改变问题,使生成器产生的低剂量投影图像内容与真实低剂量投影图像内容保持一致,这对于生成的配对数据在深度学习去噪网络中的应用至关重要。
(2)使用双路径判别器分别学习低剂量投影图像中的全局噪声分布和与结构相关的局部噪声分布,使得生成器生成的低剂量投影图像的噪声特性与真实低剂量投影图像更加相符。
(3)在生成对抗网络中引入高频信息提取器,并将其与全局判别器结合起来,这种结合方式可以让全局判别器更好地学习真实低剂量投影图像的全局噪声分布。
实施例2:
一种配对高低剂量投影数据生成方法,如图1所示,包括:
生成正常剂量投影图像对应的低剂量投影图像,作为初始低剂量投影图像;同上述实施例1,本实施例通过向正常剂量投影图像添加泊松噪声的方式生成初始低剂量投影图像,具体生成方式可参考上述实施例1中的描述;
将初始低剂量投影图像输入至由上述实施例体提供的低剂量CT投影图像生成模型建立方法所建立的低剂量CT投影图像生成模型(即训练完成的Res-WGAN生成器),得到目标低剂量投影图像,该目标低剂量投影图像与正常剂量投影图像内容一致且噪声特性良好;最终由正常剂量投影图像和目标低剂量投影图像构成配对高低剂量投影数据。
实施例3:
一种计算机可读存储介质,包括存储的计算机程序;计算机程序被处理器执行时,控制计算机可读存储介质所在设备执行上述实施例1提供的低剂量CT投影图像生成模型建立方法,和/或,上述实施例2提供的低剂量CT投影图像生成方法。
为了进一步证明本发明所能取得的有益效果,在真实的核桃低剂量锥束CT投影数据集上进行了实验验证,并与其他方法进行对比。此外,将上述实施例2生成的配对数据用于训练双域降噪深度学习网络Dual-AGNet(Dual-domainattention-guided Network),对真实低剂量锥束CT图像进行去噪,与现有的配对数据生成方法进行对比,进一步说明了本发明模拟生成的配对数据的有效性和优越性。
图5是几种配对数据生成方法生成的低剂量投影图像与真实低剂量投影图像的对比,图6是对应于图5中几种数据生成方法生成结果的感兴趣区域。图5和图6中,(a)和(b)分别表示正常剂量投影图像和真实低剂量投影图像,(c)、(d)、(e)、(f)分别表示UIDNet、ISCL、FBModel以及本实施例生成的低剂量投影数据;
图5中,(c)、(d)中的箭头表明,UIDNet和ISCL生成的图像都会发生内容的改变;(e)中的箭头表明,FBModel虽然噪声特性较好,但是其无法模拟复杂结构信息处的噪声分布。
图6中,(c)中的箭头表明,UIDNet生成的低剂量投影图像会发生内容改变,(d)、(e)中的箭头表明ISCL和FBModel无法模拟真实低剂量投影图像中复杂的结构信息。
图5和图6所示结果充分说明本发明可以生成与真实低剂量投影图像内容最为一致的模拟低剂量投影图像,并且能够保持最真实的噪声特性。其主要原因在于本发明设计了PCLoss,将基于物理模拟生成的初始低剂量投影图像作为参考以保证内容不发生变化,且基于高频信息提取器的全局判别器和局部判别器使得生成器可以充分学习真实低剂量投影图像中噪声的全局分布与局部特性。
使用基于本发明生成的配对高低剂量投影图像训练双域去噪网络,用以提升真实低剂量锥束CT图像质量,并与其他方法对比可以进一步证明本发明的有益效果。具体采用了三种量化指标即均方根误差(Root Mean Square Error,RMSE),峰值信噪比(PeakSignal to Noise Ratio,PSNR)以及结构相似性(Structural Similarity,SSIM)进行对比。三个量化指标的定义分别为:
其中C代表图像像素个数,z
量化指标对比结果如表1所示,其中真实低剂量投影不经去噪直接重建所得结果最差,基于本发明生成的配对训练数据,双域去噪网络提升真实低剂量锥束CT图像质量得到的结果,其三种量化指标均优于现有的其他配对数据生成方法。值得注意的是,本发明还使用了真实配对数据训练的网络结果作为参考,可以看到,基于本发明生成的配对训练数据,双域网络去噪的量化结果与基于真实的配对训练数据得到的量化结果十分接近且相差极小,更进一步说明了本发明生成模拟配对数据的有效性和优越性。
表1双域降噪网络提升真实低剂量锥束CT图像质量的量化结果
图7所示为基于不同方法生成的配对训练数据,双域网络训练完成后,测试时提升真实低剂量锥束CT图像质量的视觉结果,图8是图7中感兴趣区域的视觉结果对比图。图7和图8中,(a)为正常剂量CT图像,(b)为真实低剂量CT图像,(c)为基于真实数据训练网络的测试结果,(d)为基于UIDNet生成数据训练网络的测试结果,(e)为基于ISCL生成数据训练网络的测试结果,(f)为基于FBModel生成数据训练网络的测试结果,(g)为基于实施例生成数据训练网络的测试结果。
根据图7可以看出,在几种数据生成方法中,基于UIDNet生成数据训练的网络结果最差,ISCL次之,FBModel较好,而基于本发明生成的配对训练数据,双域网络提升真实低剂量锥束CT图像质量的效果最好。
图8则更进一步证明了上述结论,即基于本发明生成的配对训练数据,双域去噪网络提升真实低剂量锥束CT图像质量的结果,无论从量化值还是从视觉结果来看,都比现有的数据生成方法更好。
综上,与其他方法相比,本发明生成的模拟低剂量投影图像,其内容与真实低剂量投影图像最为一致,且具有最为真实的噪声特性,同时,基于本发明生成的配对训练数据,双域网络提升真实低剂量锥束CT图像质量得到的结果从量化指标和视觉结果两个方面来看都优于其他配对数据生成方法,充分证明了本发明生成配对数据的有效性和优越性。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于低剂量投影数据滤波的X射线CT图像重建方法
- 一种基于低剂量投影数据滤波的X射线CT图像重建方法