一种基于springbatch对于大量数据进行分片处理的算法
文献发布时间:2024-04-18 19:53:33
技术领域
本发明属于数据通信技术领域,具体的说是一种基于springbatch对于大量数据进行分片处理的算法。
背景技术
在我们常用的金融系统交易处理中,常常需要对大量的数据进行更新、删除、插入数据的操作。
现有技术中金融系统交易数据处理的方式主要分为四个步骤,首先需要对数据进行整理收集,然后将其存储到指定的数据库中,之后在对这些存储的数据进行加工,加工完成后,在将加工完成后的数据传输至指定位置,从而即可完成对数据的处理。
但是现有技术中在对数据进行操作的过程中发现,需要花费大量的时间才能完成这些数据的处理,但同时在金融交易系统中我们对于账务的处理又有时限的要求,需要更快的处理完这些数据,为此,本发明提供一种基于springbatch对于大量数据进行分片处理的算法。
发明内容
为了弥补现有技术的不足,解决背景技术中所提出的至少一个技术问题。
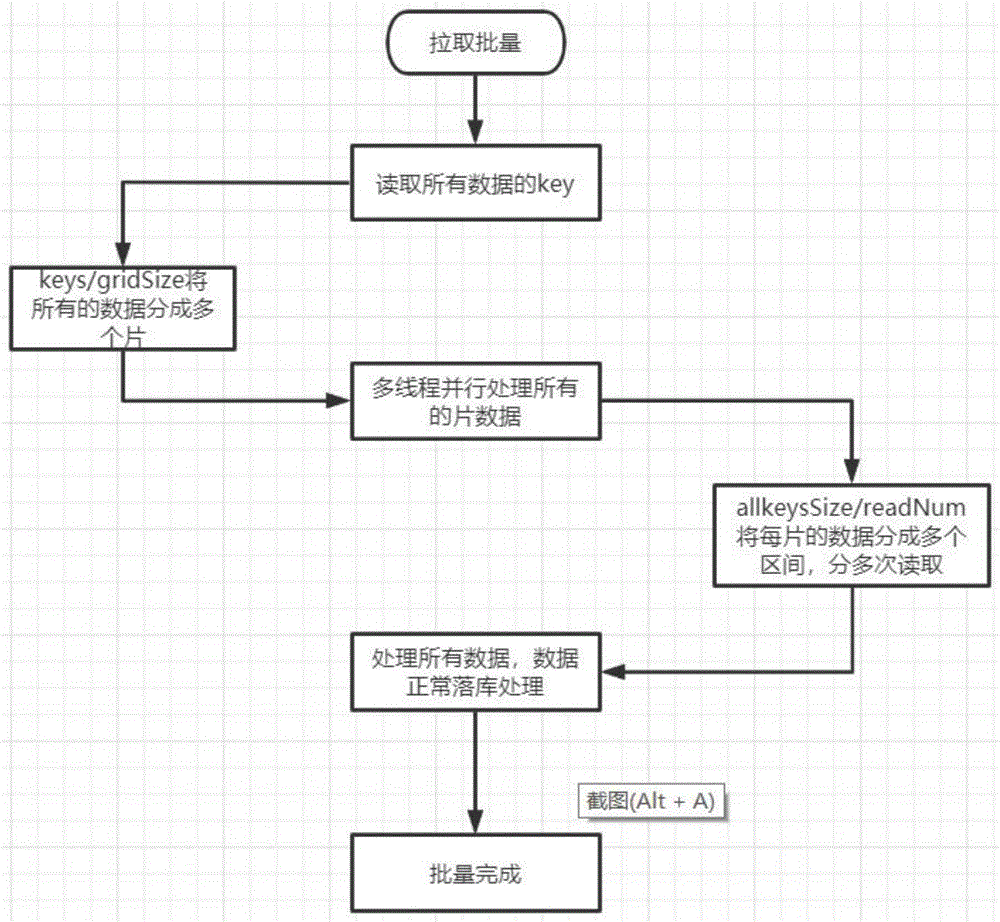
本发明解决其技术问题所采用的技术方案是:本发明所述的一种基于springbatch对于大量数据进行分片处理的算法,该数据分片处理的算法具体步骤如下:
S1:定义我们用到的所有变量;
S2:读取需要操作表的所有主键;
S3:从数据库进行数据读取,每次读取readNum条数据;
S4:数据处理,使用springbatch的多线程分片处理,将所有的数据分成多个片,使用多线程进行分片的处理操作;
S5:数据处理完成。
优选的,根据S1中所提出的定义我们用到的所有变量是指,start每次缓存读取的起始位置、allKeysSize每个分片要处理的allkey的大小、readNum每次读入缓存的数量、firstFlag第一次读取标识,默认为true,读取完以后修改为false;避免数据处理失败时,重新拉起批量处理数据时,数据的重复处理、currentitemCount当前处理到的第几条数据,每处理完一条数据加1。
优选的,根据S2中所提出的操作表的所有主键是指,根据数据库主键获取所有的key值allKeys、定义分片变量、firstFlag为true,表示第一次读取数据、设置allKeysSize的值为allKeys/gridsize作为每个分片要处理的数据量、第一次读取完,firstFlag置为false、start设置为0,表示从第一条数据开始。
优选的,根据S3所提出的数据读取是指,currentitemCount-1%readNum=0、Remain(剩余的总条数)=allKeysSize(总条数)-start(读取的起始位置)、localReadNum(本次需要读取的条数)=remain(剩余的条数)>=readNum(每次读入缓存的数量)readNum:remain、根据start和localReadNum来读取allKeys中的主键、根据allKeys中的主键读取出需要处理的数据、每次读取完数据,start=start+localReadNum作为下次需要截取的数据的起始位置。
优选的,根据S4所提出的数据处理是指,定义并发批量线程poolsize,假设有10个线程,10个线程同时各处理一个片的数据,可以显著提升数据的处理效率、定义支持并发批量的线程池jobs.xml配置、定义支持分片处理的分片jobs.xml配置、定义基于数据处理的processor任务,用于具体的数据更新,删除,插入等操作和writer写文件任务。
本发明的有益效果如下:
1.本发明所述的一种基于springbatch对于大量数据进行分片处理的算法,通过分片处理的算法,从而可提高处理数据时的速度,降低处理数据时所花费的时间。
附图说明
下面结合附图对本发明作进一步说明。
图1是本发明中的数据分片处理算法流程图;
图2是本发明中的数据分片处理算法具体步骤图;
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
如图2所示,本发明实施例所述的一种基于springbatch对于大量数据进行分片处理的算法,该数据分片处理的算法具体步骤如下:
S1:定义我们用到的所有变量;
S2:读取需要操作表的所有主键;
S3:从数据库进行数据读取,每次读取readNum条数据;
S4:数据处理,使用springbatch的多线程分片处理,将所有的数据分成多个片,使用多线程进行分片的处理操作;
S5:数据处理完成。
如图2所示,根据S1中所提出的定义我们用到的所有变量是指,start每次缓存读取的起始位置、allKeysSize每个分片要处理的allkey的大小、readNum每次读入缓存的数量、firstFlag第一次读取标识,默认为true,读取完以后修改为false;避免数据处理失败时,重新拉起批量处理数据时,数据的重复处理、currentitemCount当前处理到的第几条数据,每处理完一条数据加1。
如图2所示,根据S2中所提出的操作表的所有主键是指,根据数据库主键获取所有的key值allKeys、定义分片变量、firstFlag为true,表示第一次读取数据、设置allKeysSize的值为allKeys/gridsize作为每个分片要处理的数据量、第一次读取完,firstFlag置为false、start设置为0,表示从第一条数据开始。
如图2所示,根据S3所提出的数据读取是指,currentitemCount-1%readNum=0、Remain(剩余的总条数)=allKeysSize(总条数)-start(读取的起始位置)、localReadNum(本次需要读取的条数)=remain(剩余的条数)>=readNum(每次读入缓存的数量)readNum:remain、根据start和localReadNum来读取allKeys中的主键、根据allKeys中的主键读取出需要处理的数据、每次读取完数据,start=start+localReadNum作为下次需要截取的数据的起始位置。
如图2所示,根据S4所提出的数据处理是指,定义并发批量线程poolsize,假设有10个线程,10个线程同时各处理一个片的数据,可以显著提升数据的处理效率、定义支持并发批量的线程池jobs.xml配置、定义支持分片处理的分片jobs.xml配置、定义基于数据处理的processor任务,用于具体的数据更新,删除,插入等操作和writer写文件任务。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 一种变电运维用视频辅助装置
- 一种变电运维视频辅助装置