一种识别套牌空壳企业团伙的方法及系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及大数据以及人工智能领域,具体涉及一种识别套牌空壳企业团伙的方法及系统。
背景技术
套牌公司即通常所说的“一套人马,多块牌子”现象,使用同一套身份信息注册多家空壳公司。套牌空壳企业团伙是套牌公司的“升级版”,由多个套牌公司组成的大规模空壳团伙。
金融机构面临严峻的套牌空壳企业团伙识别压力和风险。账户类业务中,犯罪案件中往往都需要通过大量的空壳公司及其在银行开立的对公账户实施资金转移,套牌空壳企业团伙是快速设立大量空壳公司常用的手段。普惠金融业务中,贷款人购买套牌空壳企业,伪造交易合同等虚假材料进行骗贷。消费金融业务中,犯罪分子利用套牌空壳企业伪造社保流水等资料向银行骗取个人信贷贷款。严重侵害消费者和金融机构的财产安全,严重扰乱了正常金融秩序。
发明内容
本发明的目的在于提供一种识别套牌空壳企业团伙的方法及系统,解决了现有技术中存在的问题。
本发明通过下述技术方案实现:
一方面,本发明提供一种识别套牌空壳企业团伙的方法,包括:
从企业信息数据库中获取多家第一目标企业对应的多种企业信息,并基于第一目标企业对应的多种企业信息,构建第一目标企业对应的企业核心特征集;
获取由人机交互输入的第一目标企业对应的空壳类型标签,并根据多家第一目标企业对应的企业核心特征集以及空壳类型标签,构建训练数据集;
采用机器学习模型构建多分类的空壳识别模型,并根据所述训练数据集对空壳识别模型进行训练,获取训练完成的空壳识别模型;
针对待识别的多家第二目标企业,采用基于编辑距离分簇的企业社团划分方法对多家第二目标企业进行社团划分,得到多个企业社团;
以训练完成的空壳识别模型为基础,获取每个企业社团对应的套牌空壳企业团伙指数,并确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙。
在一种可能的实施方式中,将确定的套牌空壳企业团伙嵌入至金融业务流程中的风险控制系统中,以使风险控制系统在处理金融业务流程中对套牌空壳企业团伙总的企业进行拦截。
在一种可能的实施方式中,多种企业信息包括企业基础信息、企业负面信息和企业加工信息。
在一种可能的实施方式中,所述空壳类型标签包括非空壳公司、异地经营类空壳公司、无实质经营类空壳公司、借壳经营类空壳公司、傀儡公司类空壳公司以及僵尸企业类空壳公司。
在一种可能的实施方式中,采用机器学习模型构建多分类的空壳识别模型,并根据所述训练数据集对空壳识别模型进行训练,获取训练完成的空壳识别模型,包括:
采用LightGBM模型构建六分类的空壳识别模型;
从训练数据集中抽取预设比例的数据作为测试数据,剩下数据作为训练数据;
根据所述训练数据对空壳识别模型的参数进行更新,得到训练完成的空壳识别模型;
根据所述测试数据对训练完成的空壳识别模型进行AUC、精确率、召回率以及F1值进行验证,若AUC、精确率、召回率以及F1值中任一项条件未满足预设条件,则重新获取训练完成的空壳识别模型,否则输出该训练完成的空壳识别模型。
在一种可能的实施方式中,针对待识别的多家第二目标企业,采用基于编辑距离分簇的企业社团划分方法对多家第二目标企业进行社团划分,得到多个企业社团,包括:
针对待识别的多家第二目标企业,获取每个第二目标企业对应的企业基础信息序列;
从所有第二目标企业中随机取出一个第三目标企业,确定第三目标企业对应的企业基础信息序列与任一一个第二目标企业对应的企业基础信息序列之间的编辑距离;
根据编辑距离,确定第三目标企业与任一一个第二目标企业之间的相似度,并取出与第三目标企业相似度大于相似度阈值的第二目标企业,得到第四目标企业;
将取出的第三目标企业以及第四目标企业构建企业社团;
重复获取企业社团,直至所有的第二目标企业均被取出,得到多个企业社团。
在一种可能的实施方式中,根据编辑距离,确定第三目标企业与任一一个第二目标企业之间的相似度=1/(编辑距离+1)。
在一种可能的实施方式中,以训练完成的空壳识别模型为基础,获取每个企业社团对应的套牌空壳企业团伙指数,并确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙,包括:
针对每个企业社团,确定企业社团中每个企业核心特征集;
以企业社团中每个企业核心特征集作为训练完成的空壳识别模型的输入数据,获取企业社团中每个企业对应的输出数据
其中,
根据企业社团中每个企业对应的输出数据
确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙。
在一种可能的实施方式中,根据企业社团中每个企业对应的输出数据
其中,Q
另一方面,本发明提供一种识别套牌空壳企业团伙的系统,包括特征获取模块、训练数据获取模块、模型构建模块、企业社团划分模块以及识别模块;
所述特征获取模块用于从企业信息数据库中获取多家第一目标企业对应的多种企业信息,并基于第一目标企业对应的多种企业信息,构建第一目标企业对应的企业核心特征集;
所述训练数据获取模块用于获取由人机交互输入的第一目标企业对应的空壳类型标签,并根据多家第一目标企业对应的企业核心特征集以及空壳类型标签,构建训练数据集;
所述模型构建模块用于采用机器学习模型构建多分类的空壳识别模型,并根据所述训练数据集对空壳识别模型进行训练,获取训练完成的空壳识别模型;
所述企业社团划分模块用于针对待识别的多家第二目标企业,采用基于编辑距离分簇的企业社团划分方法对多家第二目标企业进行社团划分,得到多个企业社团;
所述识别模块用于以训练完成的空壳识别模型为基础,获取每个企业社团对应的套牌空壳企业团伙指数,并确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙。
本发明提供的一种识别套牌空壳企业团伙的方法及系统,通过获取企业核心特征集以及企业核心特征集对应的空壳类型标签作为训练数据,采用机器学习模型构建多分类的空壳识别模型,通过企业核心特征集以及企业核心特征集对应的空壳类型标签作为训练数据对空壳识别模型进行训练,再以训练得到空壳识别模型为基础,获取已划分好的企业社团对应的套牌空壳企业团伙指数,最终通过套牌空壳企业团伙指数精准地获取套牌空壳企业团伙,具有覆盖度和准确率高的特点。
附图说明
为了更清楚地说明本发明示例性实施方式的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。在附图中:
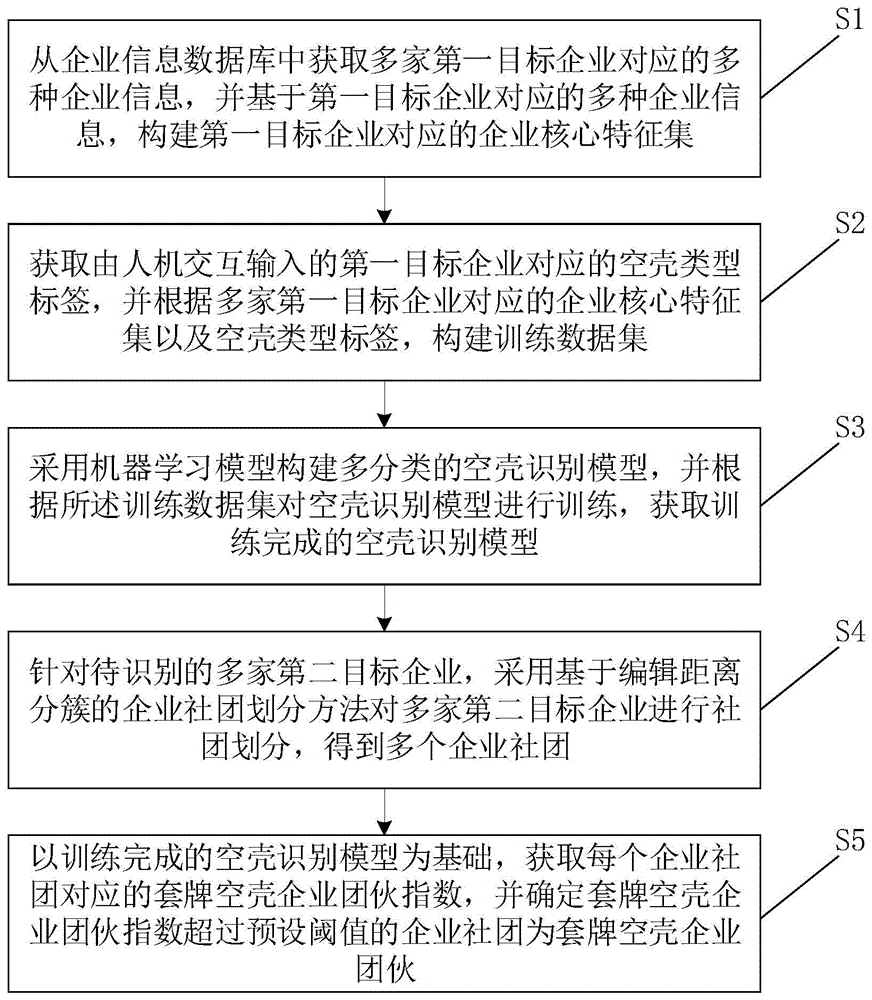
图1为本发明实施例提供的一种识别套牌空壳企业团伙的方法的流程图。
图2为本发明实施例提供的一种识别套牌空壳企业团伙的系统的结构示意图。
附图中标记及对应的零部件名称:
其中,1-特征获取模块、2-训练数据获取模块、3-模型构建模块、4-企业社团划分模块、5-识别模块。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
实施例1
如图1所示,本发明提供一种识别套牌空壳企业团伙的方法,包括:
S1、从企业信息数据库中获取多家第一目标企业对应的多种企业信息,并基于第一目标企业对应的多种企业信息,构建第一目标企业对应的企业核心特征集。
企业信息数据库可以为工商数据库,第一目标企业可以为部分,也可以为全部。
S2、获取由人机交互输入的第一目标企业对应的空壳类型标签,并根据多家第一目标企业对应的企业核心特征集以及空壳类型标签,构建训练数据集。
S3、采用机器学习模型构建多分类的空壳识别模型,并根据所述训练数据集对空壳识别模型进行训练,获取训练完成的空壳识别模型。
S4、针对待识别的多家第二目标企业,采用基于编辑距离分簇的企业社团划分方法对多家第二目标企业进行社团划分,得到多个企业社团。
S5、以训练完成的空壳识别模型为基础,获取每个企业社团对应的套牌空壳企业团伙指数,并确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙。
在一种可能的实施方式中,将确定的套牌空壳企业团伙嵌入至金融业务流程中的风险控制系统中,以使风险控制系统在处理金融业务流程中对套牌空壳企业团伙总的企业进行拦截。
在一种可能的实施方式中,多种企业信息包括企业基础信息、企业负面信息和企业加工信息。
可选的,企业基础信息包括工商基础信息、股东信息、主要人员信息、变更记录信息、企业年报信息、企业经营信息。企业负面信息包括工商经营异常信息、严重违法信息、行政处罚信息、司法诉讼信息、税务不良信息。企业加工信息包括时间间隔类指标、极值类指标和统计类指标。假设工商企业有n个,第i家企业记做A
(1)、企业基础信息。企业基础信息包括工商基础信息、股东信息、主要人员信息、变更记录信息、企业年报信息以及企业经营信息,合计6大类。
1.1)、工商基础信息包括如企业名称、企业统一社会信用代码、法人名称、企业规模、电话、邮箱、企业登记状态、注册资本、实缴资本、企业类型、营业期限、纳税人资质、人员规模、参保人数、核准日期、所属地区、登记机关、注册地址、国标行业以及经营范围等。
1.2)、股东信息是一个列表,包含多条记录,其中每一条记录包含5项信息,分别为:股东名称、持股比例、认缴出资额、认缴出资日期以及首次持股日期。
1.3)、主要人员信息是一个列表,包含多条记录,其中每一条记录包括3项信息,分别为:姓名、职务以及持股比例。
1.4)、变更记录信息是一个列表,包含多条记录,其中每一条记录包括4项信息,分别为:包括变更时间、变更项目、变更前内容以及变更后内容。
1.5)、企业年报信息是一个列表,包含多条记录,其中每一条记录包括4项信息,分别为:年份、包括企业基本信息、股东(发起人)出资信息、企业资产状况信息以及社保信息,合计4大类信息。
年报中企业基本信息包括3项,分别为本年度从业人数、本年度是否发生股东股权转让、本年度企业是否有投资信息或购买其他公司股权。
股东(发起人)出资信息是一个列表,包含多条记录,其中每一条记录包括7项信息,分别为:发起人、认缴出资额、认缴出资日期、认缴出资方式、实缴出资额、实缴出资日期以及实缴出资方式。企业资产状况信息包括资产总额、所有者权益合计、营业总收入、利润总额、净利润、营业总收入中主营业务收入、纳税总额以及负债总额,合计8项。
社保信息包括城镇职工基本养老保险人数、失业保险人数、单位缴纳基数、本期实际缴费金额以及单位累计欠缴金额,合计5项。
1.6)、企业经营信息包括股权出质信息和知识产权2类。股权出质信息是一个列表,包含多条记录,其中每一条记录包括7项信息,分别为:出质人、出质股权标的企业、质权人、出质股权数额、状态、登记日期以及登记内容。
知识产权包括专利数量、授权专利数量、商标数量、作品著作权数、软件著作权数合计5项。
(2)、企业负面信息包括工商经营异常信息、严重违法信息、行政处罚信息、司法诉讼信息以及税务不良信息,合计5大类。
2.1)、工商经营异常信息是一个列表,包含多条记录,其中每一条记录包括6项信息,分别为:列入时间、列入原因、移出时间、移出原因、列入机关名称以及移出机关名称。
2.2)、严重违法信息是一个列表,包含多条记录,其中每一条记录包括3项信息,分别为:风险提示、列入日期以及列入原因。
2.3)、行政处罚信息是一个列表,包含多条记录,其中每一条记录包括4项信息,分别为:案件名称、被处罚对象、行政处罚决定书文号以及处罚日期。
2.4)、司法诉讼信息包括司法拍卖信息、破产重整信息、裁判文书信息、被执行人信息以及限制高消费信息合计5类。
司法拍卖信息是一个列表,包含多条记录,其中每一条记录包括7项信息,分别为:拍品所有人、权利来源、拍品类别、拍品名称、权证情况、成交日期、成交价格。
破产重整信息是一个列表,包含多条记录,其中每一条记录包括5项信息,分别为:破产类型、主要资产、机构名称、公开日期、案件说明。
裁判文书信息是一个列表,包含多条记录,其中每一条记录包括5项信息,分别为:案件主体、案件状态、案件类型、案由名称、判决依据。
被执行人信息是一个列表,包含多条记录,其中每一条记录包括5项信息,分别为:执行标的、被执行人名称、立案时间、案号、案由。
限制高消费信息是另一个列表,包含多条记录,其中每一条记录包括4项信息,分别为:案由、限消令对象、立案时间、案件明细。
2.5)、税务不良信息包括欠税信息和纳税人状态评级信息。欠税信息包括欠缴税种、企业名称、纳税人类型、总欠税额以及最近一年新欠金额等信息。纳税人状态评级信息包括企业名称、评级以及纳税人状态等信息。
(3)、企业加工信息包括时间间隔指标、极值类指标和统计类指标。时间间隔类指标指的是计算满足某些条件的企业关联的任意两个时间之间的间隔。极值类指标指的是计算某一段时间范围内满足某些条件的某个特征的极值。统计类指标指的是计算某一段时间范围内满足某些条件的某个维度的数量。
3.1)、时间间隔类指标。如企业注册时间距今时间间隔、企业注销时间距今时间间隔、最近一次企业变更距今时间间隔、企业核准日期距今时间间隔、最近一次涉诉时间距今时间间隔以及最近一次欠税日期距今时间间隔等。
3.2)、极值类指标。如股东最大持股比例、股东最小持股比例、股东最大实缴资本、股东最小实缴资本、最小被执行金额、最大被执行金额、最大欠税金额以及最小欠税金额等。
3.3)、统计类指标。如近1年已结案的被执行案件数量、近1年失信被执行次数、近1年终本案件数量、近1年行政处罚次数、近一年欠税次数、近一年企业作为财产保全案件被告的数量、近一年企业作为案件被告的案件数量、近一年企业作为合同纠纷案件被告的数量以及近一年企业作为特定案件被告的数量等。
在一种可能的实施方式中,所述空壳类型标签包括非空壳公司、异地经营类空壳公司、无实质经营类空壳公司、借壳经营类空壳公司、傀儡公司类空壳公司以及僵尸企业类空壳公司。
异地经营指的是使用虚假地址或非真实经营场所注册的企业。一般是使用托管、代办、自主申报等方式注册的企业,包括以下一些显著特征:一人多企、一人多户、一址多照。经营地址为“自主申报、住所申报”。法人为无有固定住所、无居住证、无社保的三无人员。首次开户的企业法人代表年纪偏大或偏小,如小于25岁或大于65岁。身份证地址为偏远农村,且与企业注册地址不一致。手机号归属地城市与企业注册地址城市不一致等。
无实际经营是指企业各类外部数据无法反映该企业具有正常的生产经营活动。即该企业没有任何能够反映其经营活动的外部数据,包括不限于企业年报、投融资、招投标、专利、商标、经营资质等,如无资金、无营业收入、无员工、无资质等。
借壳经营是指该企业近期曾发生过集中性重大变更,且于变更之前无实际经营。企业借壳经营的主要目的是获得“壳”所具有的资质和能力,例如进入某些已被限制注册的行业、避免较长的注册和认证周期,直接获得某种经营资质、获得比较长的存续时间,以便在经营中满足一些准入条件等等。
傀儡公司。傀儡公司是指疑似冒用、借用他人身份证件注册的空壳公司。主要包含同一法人名下企业过多且存在短时间内集中注册、多次注吊销、法人非实控人等特征。
僵尸企业是指尚未注销但已无人经营、管理的企业。企业因列入经营异常名录,满3年未履行义务而被移入严重违法企业名单,可作为僵尸企业识别的重要依据。
基于专家规则对全量企业进行规则跑批,输出目标变量,即空壳类型标签。假设第i家企业A
在一种可能的实施方式中,采用机器学习模型构建多分类的空壳识别模型,并根据所述训练数据集对空壳识别模型进行训练,获取训练完成的空壳识别模型,包括:
采用LightGBM模型构建六分类的空壳识别模型。LightGBM(Light GradientBoosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。其中GBDT(Gradient Boosting Decision Tree)是机器学习中一个长盛不衰的模型,其主要思想是利用决策树等弱分类器不断迭代训练以得到最优模型,具有训练效果好、不易过拟合等优点,有很多实践的应用。
由于空壳识别模型的主要作用是对输入数据进行分类,因此还可以采用其他分类模型作为空壳识别模型,而输入空壳识别模型的数据都需要经过预处理。如:将数据转换为空壳识别模型的输入形式、固定输入数据的维度等等,以保证空壳识别模型能够正常运行。
对于第i家企业A
从训练数据集中抽取预设比例的数据作为测试数据,剩下数据作为训练数据。
例如:对样本集{X
根据所述训练数据对空壳识别模型的参数进行更新,得到训练完成的空壳识别模型。例如:基于python软件,调用lightgbm包,在训练样本集上构建LightGBM模型。有5个模型参数需要特调整,其他采用默认设置,其中调参参数设置如下:“objective”表示模型的目标函数,设置为“multiclass”。“num_class”表示目标变量类别数量,设置为6。“max_depth”表示树模型的最大深度,设置为6。“lambda_l1”表示L1正则项的惩罚因子,设置为0.1。“lambda_l2”表示L2正则项的惩罚因子,设置为0.2。
根据所述测试数据对训练完成的空壳识别模型进行AUC、精确率、召回率以及F1值进行验证,若AUC(Area under curve,曲线下面积)、精确率、召回率以及F1值中任一项条件未满足预设条件,则重新获取训练完成的空壳识别模型,否则输出该训练完成的空壳识别模型。
在一种可能的实施方式中,针对待识别的多家第二目标企业,采用基于编辑距离分簇的企业社团划分方法对多家第二目标企业进行社团划分,得到多个企业社团,包括:
针对待识别的多家第二目标企业,获取每个第二目标企业对应的企业基础信息序列。
从所有第二目标企业中随机取出一个第三目标企业,确定第三目标企业对应的企业基础信息序列与任一一个第二目标企业对应的企业基础信息序列之间的编辑距离。
根据编辑距离,确定第三目标企业与任一一个第二目标企业之间的相似度,并取出与第三目标企业相似度大于相似度阈值的第二目标企业,得到第四目标企业。
将取出的第三目标企业以及第四目标企业构建企业社团。
重复获取企业社团,直至所有的第二目标企业均被取出,得到多个企业社团。
在本实施例中,提供一种获取企业社团的举例,具体为:
S4、构建企业基础信息序列,基于编辑距离分簇划分企业社团。假设最终形成了r个企业社团,第k个社团包含w
S4.1、构建企业基础信息序列。对于任意一个企业A
S4.2、基于编辑距离分簇划分企业社团。通过不断更新种子企业,基于编辑距离算法构建该种子企业的企业社团,最终将n个企业划分为r个企业社团。
编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
S4.2.1、生成种子企业。生成待划分企业的ID序列,初始为自然数序列1,2,…,n,随机从中选择一个数作为种子企业id,假设为α,则种子企业为A
S4.2.2、计算种子企业与剩余企业列表两两之间的相似度。首先计算种子企业与剩余企业列表两两之间的编辑距离,定义相似度=1/(编辑距离+1),生成种子企业与剩余企业列表两两之间的相似度列表。
S4.2.3、生成种子企业的社区划分。筛选与种子企业相似度大于0.9的企业列表,与种子企业A
S4.2.4、更新待划分企业的ID序列。剔除已形成的企业社团中的企业ID,生成新的待划分企业的ID序列。
S4.2.5、重复S4.2.1-4.2.4,不断划分生成新的企业社团,直至所有的企业都已划分到不同的社区。
在一种可能的实施方式中,根据编辑距离,确定第三目标企业与任一一个第二目标企业之间的相似度=1/(编辑距离+1)。
在一种可能的实施方式中,以训练完成的空壳识别模型为基础,获取每个企业社团对应的套牌空壳企业团伙指数,并确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙,包括:
针对每个企业社团,确定企业社团中每个企业核心特征集。
以企业社团中每个企业核心特征集作为训练完成的空壳识别模型的输入数据,获取企业社团中每个企业对应的输出数据
其中,
根据企业社团中每个企业对应的输出数据
确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙。
在一种可能的实施方式中,根据企业社团中每个企业对应的输出数据
其中,Q
可选的,β
对于生成的r个企业社团,当套牌空壳企业团伙指数大于0.9时,标记该企业社团为套牌空壳企业团伙。即对于第k个社团,若Q
本实施例提供的一种识别套牌空壳企业团伙的方法,通过获取企业核心特征集以及企业核心特征集对应的空壳类型标签作为训练数据,采用机器学习模型构建多分类的空壳识别模型,通过企业核心特征集以及企业核心特征集对应的空壳类型标签作为训练数据对空壳识别模型进行训练,再以训练得到空壳识别模型为基础,获取已划分好的企业社团对应的套牌空壳企业团伙指数,最终通过套牌空壳企业团伙指数精准地获取套牌空壳企业团伙,具有覆盖度和准确率高的特点。
实施例2
如图2所示,本发明提供一种识别套牌空壳企业团伙的系统,包括特征获取模块1、训练数据获取模块2、模型构建模块3、企业社团划分模块4以及识别模块5。
所述特征获取模块1用于从企业信息数据库中获取多家第一目标企业对应的多种企业信息,并基于第一目标企业对应的多种企业信息,构建第一目标企业对应的企业核心特征集。
所述训练数据获取模块2用于获取由人机交互输入的第一目标企业对应的空壳类型标签,并根据多家第一目标企业对应的企业核心特征集以及空壳类型标签,构建训练数据集。
所述模型构建模块3用于采用机器学习模型构建多分类的空壳识别模型,并根据所述训练数据集对空壳识别模型进行训练,获取训练完成的空壳识别模型。
所述企业社团划分模块4用于针对待识别的多家第二目标企业,采用基于编辑距离分簇的企业社团划分方法对多家第二目标企业进行社团划分,得到多个企业社团。
所述识别模块5用于以训练完成的空壳识别模型为基础,获取每个企业社团对应的套牌空壳企业团伙指数,并确定套牌空壳企业团伙指数超过预设阈值的企业社团为套牌空壳企业团伙。
本实施例提供的一种识别套牌空壳企业团伙的系统,其原理及有益效果与实施例1中所述技术方案类似,此处不再赘述。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于重量与颜色处理麻将机乱牌少牌控制系统及其控制方法
- 一种扑克牌游戏方法及系统、设备和存储介质
- 一种无牌车辆停车计费方法及停车计费系统
- 一种空壳企业确定方法及装置、空壳企业监测方法及装置
- 一种空壳企业精准识别方法、系统、设备及存储介质