一种识别MAGE的T细胞受体及其应用
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于生物医药技术领域,具体涉及一种识别MAGE的T细胞受体及其应用,尤其涉及一种能够识别源自MAGE-A4抗原短肽的TCR及其编码序列、转导所述TCR获得的MAGE-A4特异性的T细胞以及在预防和/或治疗MAGE-A4相关疾病中的用途。
背景技术
MAGE蛋白家族具有与其他MAGE蛋白的序列紧密匹配的同源区,并且包含在免疫识别中展现为HLA/肽复合物的肽。一些MAGE基因家族蛋白(MAGE-A至MAGE-C家族)仅在生殖细胞和癌症中表达;其他(MAGE-D至MAGE-H)在正常组织中广泛表达。MAGE-A4是MAGE A基因家族的CTA成员。虽然认为可能在胚胎发育中起作用,但功能未知。MAGE-A4作为一种内源性肿瘤抗原,在细胞内生成后被降解成小分子多肽,并与MHC(主组织相容性复合体)分子结合形成复合物,被呈递到细胞表面。
研究显示,GVYDGREHTV是衍生自MAGE-A4的短肽。MAGE-A4蛋白在多种肿瘤类型中均有表达,包括黑色素瘤,以及其他固体肿瘤如胃癌、肺癌、食道癌、膀胱癌、头颈部鳞状细胞癌等。对于上述疾病的治疗,可以采用化疗和放射性治疗等方法,但都会对自身的正常细胞造成损害。
T细胞过继免疫治疗是将对靶细胞抗原具有特异性的反应性T细胞转入病人体内,使其针对靶细胞发挥作用。T细胞受体(TCR)是T细胞表面的一种膜蛋白,其能够识别相应的靶细胞表面的抗原短肽。在免疫系统中,通过抗原短肽特异性的TCR与短肽-主组织相容性复合体(pMHC复合物)的结合引发T细胞与抗原呈递细胞(APC)直接的物理接触,然后T细胞及APC两者的其他细胞膜表面分子就发生相互作用,引起一系列后续的细胞信号传递和其他生理反应,从而使得不同抗原特异性的T细胞对其靶细胞发挥免疫效应。
因此,本领域技术人员致力于分离出对MAGE-A4抗原短肽具有特异性的TCR,以及将所述TCR转导T细胞来获得对MAGE-A4抗原短肽具有特异性的T细胞,从而使他们在细胞免疫治疗中发挥作用。
发明内容
针对现有技术存在的不足,本发明的目的在于提供一种识别MAGE的T细胞受体及其应用。
为达到此发明目的,本发明采用以下技术方案:
本发明的第一方面,提供了一种T细胞受体(TCR),所述TCR包括TCRα链可变域和TCRβ链可变域,所述TCR能够与GVYDGREHTV-HLA A0201复合物结合。
在另一优选例中,所述TCRα链可变域的3个互补决定区(CDR)为:
αCDR1-TSDPSYGSEQ ID NO:10
αCDR2-QGSYDQQN SEQ ID NO:11
αCDR3-AMREYNFNKFYSEQ ID NO:12;和/或
所述TCRβ链可变域的3个互补决定区为:
βCDR1-LNHDASEQ ID NO:13
βCDR2-SQIVND SEQ ID NO:14
βCDR3-ASSIEGRGRTYNEQFSEQ ID NO:15。
在另一优选例中,所述TCR包括TCRα链可变域和TCRβ链可变域,所述TCRα链可变域为与SEQ ID NO:1具有至少90%(例如可以是90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%等)序列相同性的氨基酸序列;和/或所述TCRβ链可变域为与SEQID NO:5具有至少90%(例如可以是90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%等)序列相同性的氨基酸序列。
在另一优选例中,所述TCR包含α链可变域氨基酸序列SEQ ID NO:1。
在另一优选例中,所述TCR包含β链可变域氨基酸序列SEQ ID NO:5。
在另一优选例中,所述TCR为αβ异质二聚体,所述αβ异质二聚体包含TCRα链恒定区TRAC*01和TCRβ链恒定区TRBC1*01或TRBC2*01。
在另一优选例中,所述TCR的α链氨基酸序列为SEQ ID NO:3和/或所述TCR的β链氨基酸序列为SEQ ID NO:7。
在另一优选例中,所述TCR是人源的。
在另一优选例中,所述TCR是可溶的。
在另一优选例中,所述TCR是分离或纯化的。
在另一优选例中,所述TCR为单链。
在另一优选例中,所述TCR是由α链可变域与β链可变域通过肽连接序列连接而成。
在另一优选例中,所述TCR的α与β链的恒定区分别为鼠源的α与β链的恒定区。
在另一优选例中,所述TCR在α链可变区氨基酸第11、13、19、21、53、76、89、91、或第94位,和/或α链J基因短肽氨基酸倒数第3位、倒数第5位或倒数第7位中具有一个或多个突变;和/或所述TCR在β链可变区氨基酸第11、13、19、21、53、76、89、91、或第94位,和/或β链J基因短肽氨基酸倒数第2位、倒数第4位或倒数第6位中具有一个或多个突变,其中氨基酸位置编号按IMGT(国际免疫遗传学信息系统)中列出的位置编号。
在另一优选例中,所述TCR的α链可变域氨基酸序列包含SEQ ID NO:32和/或所述TCR的β链可变域氨基酸序列包含SEQ ID NO:34。
在另一优选例中,所述TCR的氨基酸序列为SEQ ID NO:30。
在另一优选例中,所述TCR包括(a)除跨膜结构域以外的全部或部分TCRα链;以及(b)除跨膜结构域以外的全部或部分TCRβ链;
并且(a)和(b)各自包含功能性可变结构域,或包含功能性可变结构域和所述TCR链恒定结构域的至少一部分。
在另一优选例中,半胱氨酸残基在所述TCR的α和β链恒定域之间形成人工二硫键。
在另一优选例中,在所述TCR中形成人工二硫键的半胱氨酸残基取代了选自下列的一组或多组位点:
TRAC*01外显子1的Thr48和TRBC1*01或TRBC2*01外显子1的Ser57;
TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Ser77;
TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Ser17;
TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Asp59;
TRAC*01外显子1的Ser15和TRBC1*01或TRBC2*01外显子1的Glu15;
TRAC*01外显子1的Arg53和TRBC1*01或TRBC2*01外显子1的Ser54;
TRAC*01外显子1的Pro89和TRBC1*01或TRBC2*01外显子1的Ala19;
或TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Glu20。
在另一优选例中,所述TCR的α链氨基酸序列为SEQ ID NO:26和/或所述TCR的β链氨基酸序列为SEQ ID NO:28。
在另一优选例中,所述TCR的α链可变区与β链恒定区之间含有人工链间二硫键。
在另一优选例中,在所述TCR中形成人工链间二硫键的半胱氨酸残基取代了选自下列的一组或多组位点:
TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸;
TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的等61位氨基酸;
TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第61位氨基酸;
或TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸。
在另一优选例中,所述TCR包含α链可变域和β链可变域以及除跨膜结构域以外的全部或部分β链恒定域,但其不包含α链恒定域,所述TCR的α链可变域与β链形成异质二聚体。
在另一优选例中,所述TCR的α链的C-或N-末端结合有偶联物,和/或所述TCR的β链的C-或N-末端结合有偶联物。
在另一优选例中,与所述T细胞受体结合的偶联物包括可检测标记物、治疗剂或PK修饰部分中任意一种或至少两种的组合。
优选地,所述治疗剂为抗-CD3抗体。
本发明的第二方面,提供了一种多价TCR复合物,所述多价TCR复合物包含至少两个TCR分子,并且其中的至少一个TCR分子为第一方面所述的TCR。
本发明的第三方面,提供了一种核酸分子,所述核酸分子包括编码本发明第一方面所述的TCR的核苷酸序列,和/或编码本发明第一方面所述的TCR的核苷酸序列的互补序列。
在另一优选例中,所述核酸分子是分离或纯化的。
在另一优选例中,所述核酸分子包括编码TCRα链可变域的核苷酸序列SEQ ID NO:2或SEQ ID NO:33。
在另一优选例中,所述的核酸分子包括编码TCRβ链可变域的核苷酸序列SEQ IDNO:6或SEQ ID NO:35。
在另一优选例中,所述核酸分子包括编码TCRα链的核苷酸序列SEQ ID NO:4和/或包含编码TCRβ链的核苷酸序列SEQ ID NO:8。
本发明的第四方面,提供了一种载体,所述载体含有本发明第三方面所述的核酸分子。
优选地,所述载体为病毒载体。
优选地,所述病毒载体为慢病毒载体。
本发明的第五方面,提供了一种分离的宿主细胞,所述分离的宿主细胞中含有本发明第四方面所述的载体,或所述分离的宿主细胞的基因组中整合有外源的本发明第三方面所述的核酸分子。
本发明的第六方面,提供了一种细胞,所述细胞转导有本发明第三方面所述的核酸分子或本发明第四方面所述的载体。
优选地,所述细胞包括T细胞、NK细胞、NKT细胞或干细胞。
本发明的第七方面,提供了一种药物组合物,所述药物组合物包括本发明第一方面所述的TCR、本发明第二方面所述的多价TCR复合物、本发明第三方面所述的核酸分子、本发明第四方面所述的载体或本发明第六方面所述的细胞中任意一种或至少两种的组合。
优选地,所述药物组合物还包括药学上可接受的载体。
本发明的第八方面,提供了本发明第一方面所述的TCR、本发明第二方面所述的多价TCR复合物或本发明第六方面所述的细胞中任意一种或至少两种的组合的用途,所述用途包括制备治疗肿瘤或自身免疫疾病的药物。
优选地,所述肿瘤包括MAGE-A4阳性肿瘤。
本发明的第九方面,提供了本发明第一方面所述的TCR、本发明第二方面所述的多价TCR复合物或本发明第六方面所述的细胞用作治疗肿瘤或自身免疫疾病的药物。
优选地,所述肿瘤包括MAGE-A4阳性肿瘤。
本发明的第十方面,提供了一种治疗疾病的方法,包括给需要治疗的对象施用适量的本发明第一方面所述的TCR、本发明第二方面所述的TCR复合物、本发明第六方面所述的细胞或本发明第七方面所述的药物组合物中任意一种或至少两种的组合。
优选地,所述的疾病包括肿瘤。
优选地,所述肿瘤包括MAGE-A4阳性肿瘤。
应理解,在本发明范围内中,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成新的或优选的技术方案。限于篇幅,在此不再一一累述。
本发明所述的数值范围不仅包括上述例举的点值,还包括没有例举出的上述数值范围之间的任意的点值,限于篇幅及出于简明的考虑,本发明不再穷尽列举所述范围包括的具体点值。
相对于现有技术,本发明具有以下有益效果:
(1)本发明的TCR能够与MAGE-A4抗原短肽复合物GVYDGREHTV-HLA A0201特异性结合,同时转导了本发明TCR的效应细胞能够被特异性激活。
附图说明
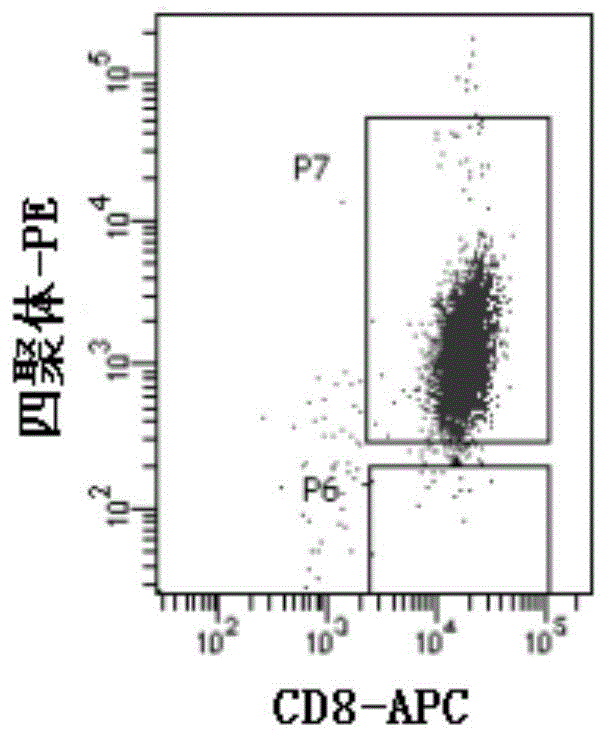
图1为单克隆细胞的CD8-APC及四聚体-PE双阳性染色结果。
图2a和图2b为纯化后得到的可溶性TCR的SDS-PAGE电泳胶图。其中,图2a和图2b的右侧泳道分别为还原胶和非还原胶,左侧泳道都为分子量标记(marker)。
图3a和图3b为纯化后得到的可溶性单链TCR的SDS-PAGE电泳胶图。其中,图3a的左侧泳道为非还原胶,右侧泳道为分子量标记(marker);图3b的左侧泳道都为分子量标记(marker),右侧泳道为还原胶。
图4为可溶性TCR与GVYDGREHTV-HLA A0201复合物结合的BIAcore动力学图谱。
图5为可溶性单链TCR与GVYDGREHTV-HLA A0201复合物结合的BIAcore动力学图谱。
图6为得到的T细胞克隆的ELISPOT激活功能验证结果。
图7为针对负载短肽的T2细胞,转染本发明TCR的效应细胞的ELISPOT激活功能验证结果。
具体实施方式
发明人经过广泛而深入的研究,找到了与MAGE-A4抗原短肽GVYDGREHTV(SEQ IDNO:9)能够特异性结合的TCR,所述抗原短肽GVYDGREHTV可与HLA A0201形成复合物并一起被呈递到细胞表面。本发明还提供了编码所述TCR的核酸分子以及包含所述核酸分子的载体。另外,本发明还提供了转导本发明TCR的细胞。
术语
MHC分子是免疫球蛋白超家族的蛋白质,可以是Ⅰ类或Ⅱ类MHC分子。因此,其对于抗原的呈递具有特异性,不同的个体有不同的MHC,能呈递一种蛋白抗原中不同的短肽到各自的APC细胞表面。人类的MHC通常称为HLA基因或HLA复合体。
T细胞受体(TCR),是呈递在主组织相容性复合体(MHC)上的特异性抗原肽的唯一受体。在免疫系统中,通过抗原特异性的TCR与pMHC复合物的结合引发T细胞与抗原呈递细胞(APC)直接的物理接触,然后T细胞及APC两者的其他细胞膜表面分子就发生相互作用,这就引起了一系列后续的细胞信号传递和其他生理反应,从而使得不同抗原特异性的T细胞对其靶细胞发挥免疫效应。
TCR是由α链/β链或者γ链/δ链以异质二聚体形式存在的细胞膜表面的糖蛋白。在95%的T细胞中TCR异质二聚体由α和β链组成,而5%的T细胞具有由γ和δ链组成的TCR。天然αβ异质二聚TCR具有α链和β链,α链和β链构成αβ异源二聚TCR的亚单位。广义上讲,α和β各链包含可变区、连接区和恒定区,β链通常还在可变区和连接区之间含有短的多变区,但该多变区常视作连接区的一部分。各可变区包含嵌合在框架结构(framework regions)中的3个CDR(互补决定区),CDR1、CDR2和CDR3。CDR区决定了TCR与pMHC复合物的结合,其中CDR3由可变区和连接区重组而成,被称为超变区。TCR的α和β链一般看作各有两个“结构域”即可变域和恒定域,可变域由连接的可变区和连接区构成。TCR恒定域的序列可以在国际免疫遗传学信息系统(IMGT)的公开数据库中找到,如TCR分子α链的恒定域序列为“TRAC*01”,TCR分子β链的恒定域序列为“TRBC1*01”或“TRBC2*01”。此外,TCR的α和β链还包含跨膜区和胞质区,胞质区很短。
在本发明中,术语“本发明多肽”、“本发明的TCR”、“本发明的T细胞受体”可互换使用。
天然链间二硫键与人工链间二硫键
在天然TCR的近膜区Cα与Cβ链间存在一组二硫键,本发明中称为“天然链间二硫键”。在本发明中,将人工引入的,位置与天然链间二硫键的位置不同的链间共价二硫键称为“人工链间二硫键”。
为方便描述二硫键的位置,本发明中TRAC*01与TRBC1*01或TRBC2*01氨基酸序列的位置编号按从N端到C端依次的顺序进行位置编号,如TRBC1*01或TRBC2*01中,按从N端到C端依次的顺序第60个氨基酸为P(脯氨酸),则本发明中可将其描述为TRBC1*01或TRBC2*01外显子1的Pro60,也可将其表述为TRBC1*01或TRBC2*01外显子1的第60位氨基酸,又如TRBC1*01或TRBC2*01中,按从N端到C端依次的顺序第61个氨基酸为Q(谷氨酰胺),则本发明中可将其描述为TRBC1*01或TRBC2*01外显子1的Gln61,也可将其表述为TRBC1*01或TRBC2*01外显子1的第61位氨基酸,其他以此类推。本发明中,可变区TRAV与TRBV的氨基酸序列的位置编号,按照IMGT中列出的位置编号。如TRAV中的某个氨基酸,IMGT中列出的位置编号为46,则本发明中将其描述为TRAV第46位氨基酸,其他以此类推。本发明中,其他氨基酸的序列位置编号有特殊说明的,则按特殊说明。
发明详述
TCR分子
在抗原加工过程中,抗原在细胞内被降解,然后通过MHC分子携带至细胞表面。T细胞受体能够识别抗原呈递细胞表面的肽-MHC复合物。因此,本发明的第一方面提供了一种能够结合GVYDGREHTV-HLA A0201复合物的TCR分子。
优选地,所述TCR分子是分离的或纯化的。该TCR的α和β链各具有3个互补决定区(CDR)。
在本发明的一个优选地实施方式中,所述TCR的α链包含具有以下氨基酸序列的CDR:
αCDR1-TSDPSYGSEQ ID NO:10
αCDR2-QGSYDQQN SEQ ID NO:11
αCDR3-AMREYNFNKFYSEQ ID NO:12;和/或
所述TCRβ链可变域的3个互补决定区为:
βCDR1-LNHDASEQ ID NO:13
βCDR2-SQIVND SEQ ID NO:14
βCDR3-ASSIEGRGRTYNEQFSEQ ID NO:15。
可以将上述本发明的CDR区氨基酸序列嵌入到任何适合的框架结构中来制备嵌合TCR。只要框架结构与本发明的TCR的CDR区兼容,本领域技术人员根据本发明公开的CDR区就能够设计或合成出具有相应功能的TCR分子。因此,本发明TCR分子是指包含上述α和/或β链CDR区序列及任何适合的框架结构的TCR分子。
本发明TCRα链可变域为与SEQ ID NO:1具有至少90%,优选地95%,更优选地98%序列相同性的氨基酸序列;
和/或本发明TCRβ链可变域为与SEQ ID NO:5具有至少90%,优选地95%,更优选地98%序列相同性的氨基酸序列。
在本发明的一个优选例中,本发明的TCR分子是由α与β链构成的异质二聚体。具体地,一方面所述异质二聚TCR分子的α链包含可变域和恒定域,所述α链可变域氨基酸序列包含上述α链的CDR1(SEQ ID NO:10)、CDR2(SEQ ID NO:11)和CDR3(SEQ ID NO:12)。
优选地,所述TCR分子包含α链可变域氨基酸序列SEQ ID NO:1。
更优选地,所述TCR分子的α链可变域氨基酸序列为SEQ ID NO:1。
另一方面,所述异质二聚TCR分子的β链包含可变域和恒定域,所述β链可变域氨基酸序列包含上述β链的CDR1(SEQ ID NO:13)、CDR2(SEQ ID NO:14)和CDR3(SEQ ID NO:15)。
优选地,所述TCR分子包含β链可变域氨基酸序列SEQ ID NO:5。
更优选地,所述TCR分子的β链可变域氨基酸序列为SEQ ID NO:5。
在本发明的一个优选例中,本发明的TCR分子是由α链的部分或全部和/或β链的部分或全部组成的单链TCR分子。有关单链TCR分子的描述可以参考文献Chung et al(1994)Proc.Natl.Acad.Sci.USA 91,12654-12658。根据文献中所述,本领域技术人员能够容易地构建包含本发明CDRs区的单链TCR分子。具体地,所述单链TCR分子包含Vα、Vβ和Cβ,优选地按照从N端到C端的顺序连接。
所述单链TCR分子的α链可变域氨基酸序列包含上述α链的CDR1(SEQ ID NO:10)、CDR2(SEQ ID NO:11)和CDR3(SEQ ID NO:12)。
优选地,所述单链TCR分子包含α链可变域氨基酸序列SEQ ID NO:1。
更优选地,所述单链TCR分子的α链可变域氨基酸序列为SEQ ID NO:1。
所述单链TCR分子的β链可变域氨基酸序列包含上述β链的CDR1(SEQ ID NO:13)、CDR2(SEQ ID NO:14)和CDR3(SEQ ID NO:15)。
优选地,所述单链TCR分子包含β链可变域氨基酸序列SEQ ID NO:5。
更优选地,所述单链TCR分子的β链可变域氨基酸序列为SEQ ID NO:5。
在本发明的一个优选例中,本发明的TCR分子的恒定域是人的恒定域。本领域技术人员知晓或可以通过查阅相关书籍或IMGT(国际免疫遗传学信息系统)的公开数据库来获得人的恒定域氨基酸序列。例如,本发明TCR分子α链的恒定域序列可以为“TRAC*01”,TCR分子β链的恒定域序列可以为“TRBC1*01”或“TRBC2*01”。IMGT的TRAC*01中给出的氨基酸序列的第53位为Arg,在此表示为:TRAC*01外显子1的Arg53,其他以此类推。优选地,本发明TCR分子α链的氨基酸序列为SEQ ID NO:3,和/或β链的氨基酸序列为SEQ ID NO:7。
天然存在的TCR是一种膜蛋白,通过其跨膜区得以稳定。如同免疫球蛋白(抗体)作为抗原识别分子一样,TCR也可以被开发应用于诊断和治疗,这时需要获得可溶性的TCR分子。可溶性的TCR分子不包括其跨膜区。可溶性TCR有很广泛的用途,它不仅可用于研究TCR与pMHC的相互作用,也可用作检测感染的诊断工具或作为自身免疫病的标志物。类似地,可溶性TCR可以被用来将治疗剂(如细胞毒素化合物或免疫刺激性化合物)输送到呈递特异性抗原的细胞,另外,可溶性TCR还可与其他分子(如,抗-CD3抗体)结合来重新定向T细胞,从而使其靶向呈递特定抗原的细胞。本发明也获得了对MAGE-A4抗原短肽具有特异性的可溶性TCR。
为获得可溶性TCR,一方面,本发明TCR可以是在其α和β链恒定域的残基之间引入人工二硫键的TCR。半胱氨酸残基在所述TCR的α和β链恒定域间形成人工链间二硫键。半胱氨酸残基可以取代在天然TCR中合适位点的其他氨基酸残基以形成人工链间二硫键。例如,取代TRAC*01外显子1的Thr48和取代TRBC1*01或TRBC2*01外显子1的Ser57的半胱氨酸残基来形成二硫键。引入半胱氨酸残基以形成二硫键的其他位点还可以是:
TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Ser77;
TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Ser17;
TRAC*01外显子1的Thr45和TRBC1*01或TRBC2*01外显子1的Asp59;
TRAC*01外显子1的Ser15和TRBC1*01或TRBC2*01外显子1的Glu15;
TRAC*01外显子1的Arg53和TRBC1*01或TRBC2*01外显子1的Ser54;
TRAC*01外显子1的Pro89和TRBC1*01或TRBC2*01外显子1的Ala19;
或TRAC*01外显子1的Tyr10和TRBC1*01或TRBC2*01外显子1的Glu20。
即半胱氨酸残基取代了上述α与β链恒定域中任一组位点。可在本发明TCR恒定域的一个或多个C末端截短最多50个、或最多30个、或最多15个、或最多10个、或最多8个或更少的氨基酸,以使其不包括半胱氨酸残基来达到缺失天然二硫键的目的,也可通过将形成天然二硫键的半胱氨酸残基突变为另一氨基酸来达到上述目的。
如上所述,本发明的TCR可以包含在其α和β链恒定域的残基间引入的人工二硫键。应注意,恒定域间含或不含上文所述的引入的人工二硫键,本发明的TCR均可含有TRAC恒定域序列和TRBC1或TRBC2恒定域序列。TCR的TRAC恒定域序列和TRBC1或TRBC2恒定域序列可通过存在于TCR中的天然二硫键连接。
为获得可溶性TCR,另一方面,本发明TCR还包括在其疏水芯区域发生突变的TCR,这些疏水芯区域的突变优选为能够使本发明可溶性TCR的稳定性提高的突变,如在公开号为WO2014/206304的专利文献中所述。这样的TCR可在其下列可变域疏水芯位置发生突变:(α和/或β链)可变区氨基酸第11、13、19、21、53、76、89、91、94位,和/或α链J基因(TRAJ)短肽氨基酸位置倒数第3、5、7位,和/或β链J基因(TRBJ)短肽氨基酸位置倒数第2、4、6位,其中氨基酸序列的位置编号按国际免疫遗传学信息系统(IMGT)中列出的位置编号。本领域技术人员知晓上述国际免疫遗传学信息系统,并可根据该数据库得到不同TCR的氨基酸残基在IMGT中的位置编号。
本发明中疏水芯区域发生突变的TCR可以是由一柔性肽链连接TCR的α与β链的可变域而构成的稳定性可溶单链TCR。应注意,本发明中柔性肽链可以是任何适合连接TCRα与β链可变域的肽链。
另外,对于稳定性而言,专利文献201680003540.2还公开了在TCR的α链可变区与β链恒定区之间引入人工链间二硫键能够使TCR的稳定性显著提高。因此,本发明的TCR的α链可变区与β链恒定区之间还可以含有人工链间二硫键。具体地,在所述TCR的α链可变区与β链恒定区之间形成人工链间二硫键的半胱氨酸残基取代了:
TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸;
TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的61位氨基酸;
TRAV的第46位氨基酸和TRBC1*01或TRBC2*01外显子1的第61位氨基酸;
或TRAV的第47位氨基酸和TRBC1*01或TRBC2*01外显子1的第60位氨基酸。
优选地,这样的TCR可以包含(ⅰ)除其跨膜结构域以外的全部或部分TCRα链,和(ⅱ)除其跨膜结构域以外的全部或部分TCRβ链,其中(ⅰ)和(ⅱ)均包含TCR链的可变域和至少一部分恒定域,α链与β链形成异质二聚体。
更优选地,这样的TCR可以包含α链可变域和β链可变域以及除跨膜结构域以外的全部或部分β链恒定域,但其不包含α链恒定域,所述TCR的α链可变域与β链形成异质二聚体。
本发明的TCR也可以多价复合体的形式提供。本发明的多价TCR复合体包含两个、三个、四个或更多个本发明TCR相结合而形成的多聚物,如可以用p53的四聚结构域来产生四聚体,或多个本发明TCR与另一分子结合而形成的复合物。本发明的TCR复合物可用于体外或体内追踪或靶向呈递特定抗原的细胞,也可用于产生具有此类应用的其他多价TCR复合物的中间体。
本发明的TCR可以单独使用,也可与偶联物以共价或其他方式结合,优选以共价方式结合。所述偶联物包括可检测标记物(为诊断目的,其中所述TCR用于检测呈递GVYDGREHTV-HLA A0201复合物的细胞的存在)、治疗剂、PK(蛋白激酶)修饰部分或任何以上这些物质的组合结合或偶联。
用于诊断目的的可检测标记物包括但不限于:荧光或发光标记物、放射性标记物、MRI(磁共振成像)或CT(电子计算机X射线断层扫描技术)造影剂、或能够产生可检测产物的酶。
可与本发明TCR结合或偶联的治疗剂包括但不限于:
1.放射性核素(Koppe等,2005,癌转移评论(Cancer metastasis reviews)24,539);
2.生物毒(Chaudhary等,1989,自然(Nature)339,394;Epel等,2002,癌症免疫学和免疫治疗(Cancer Immunology and Immunotherapy)51,565);
3.细胞因子如IL-2等(Gillies等,1992,美国国家科学院院刊(PNAS)89,1428;Card等,2004,癌症免疫学和免疫治疗(Cancer Immunology and Immunotherapy)53,345;Halin等,2003,癌症研究(Cancer Research)63,3202);
4.抗体Fc片段(Mosquera等,2005,免疫学杂志(The Journal Of Immunology)174,4381);
5.抗体scFv片段(Zhu等,1995,癌症国际期刊(International Journal ofCancer)62,319);
6.金纳米颗粒/纳米棒(Lapotko等,2005,癌症通信(Cancer letters)239,36;Huang等,2006,美国化学学会杂志(Journal of the American Chemical Society)128,2115);
7.病毒颗粒(Peng等,2004,基因治疗(Gene therapy)11,1234);
8.脂质体(Mamot等,2005,癌症研究(Cancer research)65,11631);
9.纳米磁粒;
10.前药激活酶(例如,DT-心肌黄酶(DTD)或联苯基水解酶-样蛋白质(BPHL));
11.化疗剂(例如,顺铂)或任何形式的纳米颗粒等。
另外,本发明的TCR还可以是包含衍生自超过一种物种序列的杂合TCR。例如,有研究显示鼠科TCR在人T细胞中比人TCR能够更有效地表达。因此,本发明TCR可包含人可变域和鼠的恒定域。这一方法的缺陷是可能引发免疫应答。因此,在其用于过继性T细胞治疗时应当有调节方案来进行免疫抑制,以允许表达鼠科的T细胞的植入。
应理解,本文中氨基酸名称采用国际通用的单英文字母或三英文字母表示,氨基酸名称的单英文字母与三英文字母的对应关系如下:Ala(A)、Arg(R)、Asn(N)、Asp(D)、Cys(C)、Gln(Q)、Glu(E)、Gly(G)、His(H)、Ile(I)、Leu(L)、Lys(K)、Met(M)、Phe(F)、Pro(P)、Ser(S)、Thr(T)、Trp(W)、Tyr(Y)、Val(V)。
核酸分子
本发明的第二方面提供了编码本发明第一方面TCR分子或其部分的核酸分子,所述部分可以是一个或多个CDR,α和/或β链的可变域,以及α链和/或β链。
编码本发明第一方面TCR分子α链CDR区的核苷酸序列如下:
CDR1α-accagtgatccaagttatggt SEQ ID NO:16
CDR2α-caggggtcttatgaccagcaaaatSEQ ID NO:17
CDR3α-gcaatgagggaatacaacttcaacaaattttac SEQ ID NO:18
编码本发明第一方面TCR分子β链CDR区的核苷酸序列如下:
CDR1β-ttgaaccacgatgcc SEQ ID NO:19
CDR2β-tcacagatagtaaatgacSEQ ID NO:20
CDR3β-gccagtagtatagagggccgcgggagaacctacaatgagcagttc SEQ ID NO:21
因此,编码本发明TCRα链的核酸分子的核苷酸序列包括SEQ ID NO:16、SEQ IDNO:17和SEQ ID NO:18,和/或编码本发明TCRβ链的核酸分子的核苷酸序列包括SEQ ID NO:19、SEQ ID NO:20和SEQ ID NO:21。
本发明核酸分子的核苷酸序列可以是单链或双链的,所述核酸分子可以是RNA或DNA,并且可以包含或不包含内含子。
优选地,本发明核酸分子的核苷酸序列不包含内含子但能够编码本发明多肽,例如编码本发明TCRα链可变域的核酸分子的核苷酸序列包括SEQ ID NO:2,和/或编码本发明TCRβ链可变域的核酸分子的核苷酸序列包括SEQ ID NO:6。或者,编码本发明TCRα链可变域的核酸分子的核苷酸序列包括SEG ID NO:33,和/或编码本发明TCRβ链可变域的核酸分子的核苷酸序列包括SEG ID NO:35。
更优选地,本发明核酸分子的核苷酸序列包含SEQ ID NO:4和/或SEQ ID NO:8。或者,本发明核酸分子的核苷酸序列为SEQ ID NO:31。
应理解,由于遗传密码的简并,不同的核苷酸序列可以编码相同的多肽。因此,编码本发明TCR的核酸序列可以与本发明中所示的核酸序列相同或是简并的变异体。以本发明中的其中一个例子来说明,“简并的变异体”是指编码具有SEQ ID NO:1的蛋白序列,但与SEQ ID NO:2的核苷酸序列有差别的核酸序列。
核苷酸序列可以是经密码子优化的。不同的细胞在具体密码子的利用上是不同的,可以根据细胞的类型,改变序列中的密码子来增加表达量。哺乳动物细胞以及多种其他生物的密码子选择表是本领域技术人员公知的。
本发明的核酸分子全长序列或其片段通常可以用但不限于PCR扩增法、重组法或人工合成的方法获得。目前,已经可以完全通过化学合成来得到编码本发明TCR(或其片段,或其衍生物)的DNA序列。然后可将该DNA序列引入本领域中已知的各种现有的DNA分子(或如载体)和细胞中。DNA可以是编码链或非编码链。
载体
本发明还涉及包含本发明的核酸分子的载体,包括表达载体,即能够在体内或体外表达的构建体。常用的载体包括细菌质粒、噬菌体和动植物病毒。
病毒递送系统包括但不限于腺病毒载体、腺相关病毒(AAV)载体、疱疹病毒载体、逆转录病毒载体、慢病毒载体、杆状病毒载体。
优选地,载体可以将本发明的核苷酸转移至细胞中,例如T细胞中,使得所述细胞表达MAGE-A4抗原特异性的TCR。理想的情况下,载体应当能够在T细胞中持续高水平地表达。
细胞
本发明还涉及用本发明的载体或编码序列经基因工程产生的宿主细胞。所述宿主细胞中含有本发明的载体或染色体中整合有本发明的核酸分子。宿主细胞选自:原核细胞和真核细胞,例如大肠杆菌、酵母细胞或CHO细胞等。
另外,本发明还包括表达本发明的TCR的分离的细胞,可以但不仅限为T细胞、NK细胞、NKT细胞、干细胞,特别是T细胞。所述T细胞可衍生自从受试者分离的T细胞,或者可以是从受试者中分离的混合细胞群,诸如外周血淋巴细胞(PBL)群的一部分。例如,所述细胞可以分离自外周血单核细胞(PBMC),可以是CD4
备选地,本发明的细胞还可以是或衍生自干细胞,如造血干细胞(HSC)。将基因转移至HSC不会导致在细胞表面表达TCR,因为干细胞表面不表达CD3分子。然而,当干细胞分化为迁移至胸腺的淋巴前体(lymphoid precursor)时,CD3分子的表达将启动在胸腺细胞的表面表达所述引入的TCR分子。
有许多方法适合于用编码本发明TCR的DNA或RNA进行T细胞转染(如,Robbins等.,(2008)J.Immunol.180:6116-6131)。表达本发明TCR的T细胞可以用于过继免疫治疗。本领域技术人员能够知晓进行过继性治疗的许多合适方法(如,Rosenberg等.,(2008)Nat RevCancer8(4):299-308)。
MAGE-A4抗原相关疾病
本发明还涉及在受试者中治疗和/或预防与MAGE-A4相关疾病的方法,其包括过继性转移MAGE-A4特异性T细胞至受试者的步骤。所述MAGE-A4特异性T细胞可识别GVYDGREHTV-HLA A0201复合物。
本发明的MAGE特异性的T细胞可用于治疗任何呈递MAGE-A4抗原短肽GVYDGREHTV-HLA A0201复合物的MAGE-A4相关疾病,包括但不限于肿瘤,如黑色素瘤,以及其他固体肿瘤如胃癌、肺癌、食道癌、膀胱癌或头颈部鳞状细胞癌等。
治疗方法
可以通过分离患有与MAGE-A4抗原相关疾病的病人或志愿者的T细胞,并将本发明的TCR导入上述T细胞中,随后将这些基因工程修饰的细胞回输到病人体内来进行治疗。因此,本发明提供了一种治疗MAGE-A4相关疾病的方法,包括将分离的表达本发明TCR的T细胞,优选地,所述T细胞来源于病人本身,输入到病人体内。一般地,包括(1)分离病人的T细胞,(2)用本发明核酸分子或能够编码本发明TCR分子的核酸分子体外转导T细胞,(3)将基因工程修饰的T细胞输入到病人体内。分离、转染及回输的细胞的数量可以由医师决定。
本发明的主要优点在于:
本发明的TCR能够与MAGE-A4抗原短肽复合物GVYDGREHTV-HLA A0201特异性结合,同时转导了本发明TCR的效应细胞能够被特异性激活。
下面的具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件,例如(Sambrook和Russell等人,分子克隆:实验室手册(Molecular Cloning-A LaboratoryManual)(第三版)(2001)CSHL出版社)中所述的条件,或按照制造厂商所建议的条件。除非另外说明,否则百分比和份数按重量计算。除非另外说明,否则百分比和份数按重量计算。以下实施例中所用的实验材料和试剂如无特别说明均可从市售渠道获得。
实施例1克隆MAGE-A4抗原短肽特异性T细胞
利用合成短肽GVYDGREHTV(SEQ ID NO:9,由江苏金斯瑞生物科技有限公司合成)刺激来自于基因型为HLA-A0201的健康志愿者的外周血淋巴细胞(PBL)。将GVYDGREHTV短肽与带有生物素标记的HLA-A0201复性,制备pMHC单倍体。这些单倍体与用PE标记的链霉亲和素(BD公司)组合成PE标记的四聚体,分选所述四聚体及抗-CD8-APC双阳性细胞。扩增分选的细胞,并按上述方法进行二次分选,随后用有限稀释法进行单克隆。单克隆细胞用四聚体染色,筛选到的双阳性克隆如图1所示,图1为单克隆细胞的CD8-APC及四聚体-PE双阳性染色结果。经过层层筛选得到的双阳性克隆,还需要满足进一步的功能测试。
IFN-γ是活化T淋巴细胞产生的一种强有力的免疫调节因子,因此本实施例通过本领域技术人员熟知的ELISPOT实验检测IFN-γ数以验证转染本发明TCR的细胞的激活功能及抗原特异性。通过ELISPOT实验进一步检测所述T细胞克隆的功能及特异性。本实施例IFN-γELISPOT实验中所用的效应细胞为本发明中获得的T细胞克隆,靶细胞为负载了GVYDGREHTV短肽的T2细胞、NCI-H1299-A2(指转染HLA-A0201的NCI-H1299细胞),对照组为负载了其他抗原短肽的T2细胞和MCF-7。其中,T2细胞和MCF-7均购自ATCC,NCI-H1299细胞购自中国科学院细胞库。
首先准备ELISPOT平板,ELISPOT实验步骤如下:按以下顺序将试验的各个组分加入ELISPOT平板:靶细胞20000个/孔、效应细胞2000个/孔后,在实验组和对照组加入20μL相应的短肽,T2负载的短肽终浓度为10-5M,空白组加入20μL培养基(试验培养基),并设置2复孔。然后温育过夜(37℃,5%CO
实施例2获取MAGE-A4抗原短肽特异性T细胞克隆的TCR基因
用Quick-RNA
经测序,双阳性克隆表达的TCR中:
TCRα链可变域氨基酸序列如SEQ ID NO:1所示,TCRα链可变域核苷酸序列SEQ IDNO:2所示,TCRα链氨基酸序列如SEQ ID NO:3所示,TCRα链核苷酸序列如SEQ ID NO:4所示,具有前导序列的TCRα链氨基酸序列如SEQ ID NO:22所示,具有前导序列的TCRα链核苷酸序列如SEQ ID NO:23所示;
TCRβ链可变域氨基酸序列如SEQ ID NO:5所示,TCRβ链可变域核苷酸序列如SEQID NO:6所示,TCRβ链氨基酸序列如SEQ ID NO:7所示,TCRβ链核苷酸序列如SEQ ID NO:8所示,具有前导序列的TCRβ链氨基酸序列如SEQ ID NO:24所示,具有前导序列的TCRβ链核苷酸序列如SEQ ID NO:25所示。
SEQ ID NO:1:
AQKITQTQPGMFVQEKEAVTLDCTYDTSDPSYGLFWYKQPSSGEMIFLIYQGSYDQQNATEGRYSLNFQKARKSANLVISASQLGDSAMYFCAMREYNFNKFYFGSGTKLNVKP。
SEQ ID NO:2:
gcccagaagataactcaaacccaaccaggaatgttcgtgcaggaaaaggaggctgtgactctggactgcacatatgacaccagtgatccaagttatggtctattctggtacaagcagcccagcagtggggaaatgatttttcttatttatcaggggtcttatgaccagcaaaatgcaacagaaggtcgctactcattgaatttccagaaggcaagaaaatccgccaaccttgtcatctccgcttcacaactgggggactcagcaatgtatttctgtgcaatgagggaatacaacttcaacaaattttactttggatctgggaccaaactcaatgtaaaacca。
SEQ ID NO:3:
AQKITQTQPGMFVQEKEAVTLDCTYDTSDPSYGLFWYKQPSSGEMIFLIYQGSYDQQNATEGRYSLNFQKARKSANLVISASQLGDSAMYFCAMREYNFNKFYFGSGTKLNVKPNIQNPDPAVYQLRDSKSSDKSVCLFTDFDSQTNVSQSKDSDVYITDKTVLDMRSMDFKSNSAVAWSNKSDFACANAFNNSIIPEDTFFPSPESSCDVKLVEKSFETDTNLNFQNLSVIGFRILLLKVAGFNLLMTLRLWSS。
SEQ ID NO:4:
gcccagaagataactcaaacccaaccaggaatgttcgtgcaggaaaaggaggctgtgactctggactgcacatatgacaccagtgatccaagttatggtctattctggtacaagcagcccagcagtggggaaatgatttttcttatttatcaggggtcttatgaccagcaaaatgcaacagaaggtcgctactcattgaatttccagaaggcaagaaaatccgccaaccttgtcatctccgcttcacaactgggggactcagcaatgtatttctgtgcaatgagggaatacaacttcaacaaattttactttggatctgggaccaaactcaatgtaaaaccaaatAtccagaaccctgaccctgccgtgtaccagctgagagactctaaatccagtgacaagtctgtctgcctattcaccgattttgattctcaaacaaatgtgtcacaaagtaaggattctgatgtgtatatcacagacaaaactgtgctagacatgaggtctatggacttcaagagcaacagtgctgtggcctggagcaacaaatctgactttgcatgtgcaaacgccttcaacaacagcattattccagaagacaccttcttccccagcccagaaagttcctgtgatgtcaagctggtcgagaaaagctttgaaacagatacgaacctaaactttcaaaacctgtcagtgattgggttccgaatcctcctcctgaaagtggccgggtttaatctgctcatgacgctgcggctgtggtccagc。
SEQ ID NO:22:
SLSSLLKVVTASLWLGPGIAQKITQTQPGMFVQEKEAVTLDCTYDTSDPSYGLFWYKQPSSGEMIFLIYQGSYDQQNATEGRYSLNFQKARKSANLVISASQLGDSAMYFCAMREYNFNKFYFGSGTKLNVKPNIQNPDPAVYQLRDSKSSDKSVCLFTDFDSQTNVSQSKDSDVYITDKTVLDMRSMDFKSNSAVAWSNKSDFACANAFNNSIIPEDTFFPSPESSCDVKLVEKSFETDTNLNFQNLSVIGFRILLLKVAGFNLLMTLRLWSS。
SEQ ID NO:23:
tcactttctagcctgctgaaggtggtcacagcttcactgtggctaggacctggcattgcccagaagataactcaaacccaaccaggaatgttcgtgcaggaaaaggaggctgtgactctggactgcacatatgacaccagtgatccaagttatggtctattctggtacaagcagcccagcagtggggaaatgatttttcttatttatcaggggtcttatgaccagcaaaatgcaacagaaggtcgctactcattgaatttccagaaggcaagaaaatccgccaaccttgtcatctccgcttcacaactgggggactcagcaatgtatttctgtgcaatgagggaatacaacttcaacaaattttactttggatctgggaccaaactcaatgtaaaaccaaatAtccagaaccctgaccctgccgtgtaccagctgagagactctaaatccagtgacaagtctgtctgcctattcaccgattttgattctcaaacaaatgtgtcacaaagtaaggattctgatgtgtatatcacagacaaaactgtgctagacatgaggtctatggacttcaagagcaacagtgctgtggcctggagcaacaaatctgactttgcatgtgcaaacgccttcaacaacagcattattccagaagacaccttcttccccagcccagaaagttcctgtgatgtcaagctggtcgagaaaagctttgaaacagatacgaacctaaactttcaaaacctgtcagtgattgggttccgaatcctcctcctgaaagtggccgggtttaatctgctcatgacgctgcggctgtggtccagc。
SEQ ID NO:5:
DGGITQSPKYLFRKEGQNVTLSCEQNLNHDAMYWYRQDPGQGLRLIYYSQIVNDFQKGDIAEGYSVSREKKESFPLTVTSAQKNPTAFYLCASSIEGRGRTYNEQFFGPGTRLTVL。
SEQ ID NO:6:
gatggtggaatcactcagtccccgaagtacctgttcagaaaggaaggacagaatgtgaccctgagttgtgaacagaatttgaaccacgatgccatgtactggtaccgacaggacccagggcaagggctgagattgatctactactcacagatagtaaatgactttcagaaaggagatatagctgaagggtacagcgtctctcgggagaagaaggaatcctttcctctcactgtgacatcggcccaaaagaacccgacagctttctatctctgtgccagtagtatagagggccgcgggagaacctacaatgagcagttcttcgggccagggacacggctcaccgtgcta。
SEQ ID NO:7:
DGGITQSPKYLFRKEGQNVTLSCEQNLNHDAMYWYRQDPGQGLRLIYYSQIVNDFQKGDIAEGYSVSREKKESFPLTVTSAQKNPTAFYLCASSIEGRGRTYNEQFFGPGTRLTVLEDLKNVFPPEVAVFEPSEAEISHTQKATLVCLATGFYPDHVELSWWVNGKEVHSGVSTDPQPLKEQPALNDSRYCLSSRLRVSATFWQNPRNHFRCQVQFYGLSENDEWTQDRAKPVTQIVSAEAWGRADCGFTSESYQQGVLSATILYEILLGKATLYAVLVSALVLMAMVKRKDSRG。
SEQ ID NO:8:
gatggtggaatcactcagtccccgaagtacctgttcagaaaggaaggacagaatgtgaccctgagttgtgaacagaatttgaaccacgatgccatgtactggtaccgacaggacccagggcaagggctgagattgatctactactcacagatagtaaatgactttcagaaaggagatatagctgaagggtacagcgtctctcgggagaagaaggaatcctttcctctcactgtgacatcggcccaaaagaacccgacagctttctatctctgtgccagtagtatagagggccgcgggagaacctacaatgagcagttcttcgggccagggacacggctcaccgtgctaGaggacctgaaaaacgtgttcccacccgaggtcgctgtgtttgagccatcagaagcagagatctcccacacccaaaaggccacactggtgtgcctggccacaggcttctaccccgaccacgtggagctgagctggtgggtgaatgggaaggaggtgcacagtggggtcagcacagacccgcagcccctcaaggagcagcccgccctcaatgactccagatactgcctgagcagccgcctgagggtctcggccaccttctggcagaacccccgcaaccacttccgctgtcaagtccagttctacgggctctcggagaatgacgagtggacccaggatagggccaaacctgtcacccagatcgtcagcgccgaggcctggggtagagcagactgtggcttcacctccgagtcttaccagcaaggggtcctgtctgccaccatcctctatgagatcttgctagggaaggccaccttgtatgccgtgctggtcagtgccctcgtgctgatggccatggtcaagagaaaggattccagaggc。
SEQ ID NO:24:
SNQVLCCVVLCLLGANTVDGGITQSPKYLFRKEGQNVTLSCEQNLNHDAMYWYRQDPGQGLRLIYYSQIVNDFQKGDIAEGYSVSREKKESFPLTVTSAQKNPTAFYLCASSIEGRGRTYNEQFFGPGTRLTVLEDLKNVFPPEVAVFEPSEAEISHTQKATLVCLATGFYPDHVELSWWVNGKEVHSGVSTDPQPLKEQPALNDSRYCLSSRLRVSATFWQNPRNHFRCQVQFYGLSENDEWTQDRAKPVTQIVSAEAWGRADCGFTSESYQQGVLSATILYEILLGKATLYAVLVSALVLMAMVKRKDSRG。
SEQ ID NO:25:
agcaaccaggtgctctgctgtgtggtcctttgtctcctgggagcaaacaccgtggatggtggaatcactcagtccccgaagtacctgttcagaaaggaaggacagaatgtgaccctgagttgtgaacagaatttgaaccacgatgccatgtactggtaccgacaggacccagggcaagggctgagattgatctactactcacagatagtaaatgactttcagaaaggagatatagctgaagggtacagcgtctctcgggagaagaaggaatcctttcctctcactgtgacatcggcccaaaagaacccgacagctttctatctctgtgccagtagtatagagggccgcgggagaacctacaatgagcagttcttcgggccagggacacggctcaccgtgctaGaggacctgaaaaacgtgttcccacccgaggtcgctgtgtttgagccatcagaagcagagatctcccacacccaaaaggccacactggtgtgcctggccacaggcttctaccccgaccacgtggagctgagctggtgggtgaatgggaaggaggtgcacagtggggtcagcacagacccgcagcccctcaaggagcagcccgccctcaatgactccagatactgcctgagcagccgcctgagggtctcggccaccttctggcagaacccccgcaaccacttccgctgtcaagtccagttctacgggctctcggagaatgacgagtggacccaggatagggccaaacctgtcacccagatcgtcagcgccgaggcctggggtagagcagactgtggcttcacctccgagtcttaccagcaaggggtcctgtctgccaccatcctctatgagatcttgctagggaaggccaccttgtatgccgtgctggtcagtgccctcgtgctgatggccatggtcaagagaaaggattccagaggc。
SEQ ID NO:9:GVYDGREHTV。
经鉴定,α链包含具有以下氨基酸序列的CDR:
αCDR1-TSDPSYG SEQ ID NO:10
αCDR2-QGSYDQQNSEQ ID NO:11
αCDR3-AMREYNFNKFY SEQ ID NO:12
β链包含具有以下氨基酸序列的CDR:
βCDR1-LNHDA SEQ ID NO:13
βCDR2-SQIVNDSEQ ID NO:14
βCDR3-ASSIEGRGRTYNEQF SEQ ID NO:15。
实施例3 MAGE-A4抗原短肽特异性可溶TCR的表达、重折叠和纯化
为获得可溶的TCR分子,本发明的TCR分子的α和β链可以分别只包含其可变域及部分恒定域,并且α和β链的恒定域中分别引入了一个半胱氨酸残基以形成人工链间二硫键,其α链的氨基酸序列如SEQ ID NO:26所示,α链的核苷酸序列如SEQ ID NO:27所示;其β链的氨基酸序列如SEQ ID NO:28所示,β链的核苷酸序列如SEQ ID NO:29所示。通过《分子克隆实验室手册》(Molecular Cloning a Laboratory Manual)(第三版,Sambrook和Russell)中描述的标准方法将上述TCRα链和TCRβ链的目的基因序列经合成后分别插入到表达载体pET28a+(Novagene),上下游的克隆位点分别是Nco I和Not I。插入片段经过测序确认无误。
SEQ ID NO:26:
AQKITQTQPGMFVQEKEAVTLDCTYDTSDPSYGLFWYKQPSSGEMIFLIYQGSYDQQNATEGRYSLNFQKARKSANLVISASQLGDSAMYFCAMREYNFNKFYFGSGTKLNVKPNIQNPDPAVYQLRDSKSSDKSVCLFTDFDSQTNVSQSKDSDVYITDKTVLDMRSMDFKSNSAVAWSNKSDFACANAFNNSIIPEDTFFCSPESS。
SEQ ID NO:27:
gcgcagaaaattacccaaacccaaccaggaatgttcgtgcaggaaaaggaggctgtgactctggactgcacatatgacaccagtgatccaagttatggtctattctggtacaagcagcccagcagtggggaaatgatttttcttatttatcaggggtcttatgaccagcaaaatgcaacagaaggtcgctactcattgaatttccagaaggcaagaaaatccgccaaccttgtcatctccgcttcacaactgggggactcagcaatgtatttctgtgcaatgagggaatacaacttcaacaaattttactttggatctgggaccaaactcaatgtaaaaccaaatatccagaaccctgaccctgccgtttatcagctgcgtgatagcaaaagcagcgataaaagcgtgtgcctgttcaccgattttgatagccagaccaacgtgagccagagcaaagatagcgatgtgtacatcaccgataaaaccgtgctggatatgcgcagcatggatttcaaaagcaatagcgcggttgcgtggagcaacaaaagcgattttgcgtgcgcgaacgcgtttaacaacagcatcatcccggaagatacgttcttctgcagcccagaaagttcc。
SEQ ID NO:28:
DGGITQSPKYLFRKEGQNVTLSCEQNLNHDAMYWYRQDPGQGLRLIYYSQIVNDFQKGDIAEGYSVSREKKESFPLTVTSAQKNPTAFYLCASSIEGRGRTYNEQFFGPGTRLTVLEDLKNVFPPEVAVFEPSECEISHTQKATLVCLATGFYPDHVELSWWVNGKEVHSGVSTDPQPLKEQPALNDSRYALSSRLRVSATFWQNPRNHFRCQVQFYGLSENDEWTQDRAKPVTQIVSAEAWGRAD。
SEQ ID NO:29:
gatggcggcattacccagtccccgaagtacctgttcagaaaggaaggacagaatgtgaccctgagttgtgaacagaatttgaaccacgatgccatgtactggtaccgacaggacccagggcaagggctgagattgatctactactcacagatagtaaatgactttcagaaaggagatatagctgaagggtacagcgtctctcgggagaagaaggaatcctttcctctcactgtgacatcggcccaaaagaacccgacagctttctatctctgtgccagtagtatagagggccgcgggagaacctacaatgagcagttcttcgggccagggacacggctcaccgtgctagaggacctgaaaaacgtgttcccacccgaggtcgctgtgtttgagccatcagaatgcgaaattagccatacccagaaagcgaccctggtttgtctggcgaccggtttttatccggatcatgtggaactgtcttggtgggtgaacggcaaagaagtgcatagcggtgtttctaccgatccgcagccgctgaaagaacagccggcgctgaatgatagccgttatgcgctgtctagccgtctgcgtgttagcgcgaccttttggcaaaatccgcgtaaccattttcgttgccaggtgcagttttatggcctgagcgaaaacgatgaatggacccaggatcgtgcgaagccggttacccagattgttagcgcggaagcctggggccgcgcagat。
将TCRα链和TCRβ链的表达载体分别通过化学转化法转化进入表达细菌BL21(DE3),细菌用LB培养液生长,于OD
溶解后的TCRα链和TCRβ链以1:1的质量比快速混合于含有5M尿素、0.4M精氨酸、20mM Tris(pH 8.1)、3.7mM cystamine、6.6mMβ-mercapoethylamine(4℃)的溶液中,终浓度为60mg/mL。混合后将溶液置于10倍体积的去离子水中透析(4℃),12h后将去离子水换成缓冲液(20mM Tris,pH 8.0)继续于4℃透析12h。透析完成后的溶液经0.45μM的滤膜过滤后,通过阴离子交换柱(HiTrap Q HP,5ml,GE Healthcare)纯化。洗脱峰含有复性成功的α和β二聚体的TCR通过SDS-PAGE胶确认。TCR随后通过凝胶过滤层析(HiPrep 16/60,Sephacryl S-100HR,GE Healthcare)进一步纯化。纯化后的TCR纯度经过SDS-PAGE测定大于90%,浓度由BCA法确定。本发明纯化后得到的可溶性TCR的SDS-PAGE电泳胶图如图2a和图2b所示,其中,图2a和图2b的右侧泳道分别为还原胶和非还原胶,左侧泳道都为分子量标记(marker)。
实施例4 MAGE-A4抗原短肽特异性的可溶性单链TCR的产生
根据专利文献WO2014/206304中所述,利用定点突变的方法将实施例2中TCRα链与TCRβ链的可变域构建成了一个以柔性短肽(linker)连接的稳定的可溶性单链TCR分子。所述单链TCR分子的氨基酸序列如SEQ ID NO:30所示,所述单链TCR分子的核苷酸序列如SEQID NO:31所示;其linker的氨基酸序列及核苷酸序列以单下划线标出。其α链可变域的氨基酸序列如SEQ ID NO:32所示,α链可变域的核苷酸序列如SEQ ID NO:33所示;其β链可变域的氨基酸序列如SEQ ID NO:34所示,β链可变域的核苷酸序列如SEQ ID NO:35所示。
将目的基因经Nco I和Not I双酶切,与经过Nco I和Not I双酶切的pET28a载体连接。连接产物转化至E.coli DH5α,涂布含卡那霉素的LB平板,37℃倒置培养过夜,挑取阳性克隆进行PCR筛选,对阳性重组子进行测序,确定序列正确后抽提重组质粒转化至E.coliBL21(DE3),用于表达。
SEQ ID NO:30:
AQKITQTQPGLNVQEGENVTIDCTYDTSDPSYGLFWYKQPSSGEMIFLIYQGSYDQQNATEGRYSLNFQKARKSANLVISASQPGDSAMYFCAMREYNFNKFYFGCGTKLNVKP
SEQ ID NO:31:
gcacaaaaaattactcagacccagccgggtctgaatgtgcaggaaggcgaaaatgttaccattgattgcacctatgataccagtgatccgagttatggtctgttttggtataaacagccgagcagcggtgaaatgattttcctgatctatcagggcagttatgatcagcagaatgccaccgaaggtcgctatagtctgaattttcagaaagcccgtaaaagcgccaatctggttattagtgcaagtcagccgggcgatagcgccatgtatttctgtgcaatgcgcgaatataattttaataagttctacttcggttgtggcaccaaactgaatgtgaaaccg
SEQ ID NO:32:
AQKITQTQPGLNVQEGENVTIDCTYDTSDPSYGLFWYKQPSSGEMIFLIYQGSYDQQNATEGRYSLNFQKARKSANLVISASQPGDSAMYFCAMREYNFNKFYFGCGTKLNVKP。
SEQ ID NO:33:
gcacaaaaaattactcagacccagccgggtctgaatgtgcaggaaggcgaaaatgttaccattgattgcacctatgataccagtgatccgagttatggtctgttttggtataaacagccgagcagcggtgaaatgattttcctgatctatcagggcagttatgatcagcagaatgccaccgaaggtcgctatagtctgaattttcagaaagcccgtaaaagcgccaatctggttattagtgcaagtcagccgggcgatagcgccatgtatttctgtgcaatgcgcgaatataattttaataagttctacttcggttgtggcaccaaactgaatgtgaaaccg。
SEQ ID NO:34:
DGGITQSPKYLSVKEGQNVTLSCEQNLNHDAMYWYRQDPGQCLRLIYYSQIVNDFQKGDIAERYSVSREKKESFPLTITSVQPNDTAFYLCASSIEGRGRTYNEQFFGPGTRLTVD。
SEQ ID NO:35:
gatggtggtattacccagagtccgaaatatctgagcgttaaagaaggccagaatgtgaccctgagctgcgaacagaatctgaatcatgatgccatgtattggtatcgccaggaccctggccagtgtctgcgcttaatctattatagccagattgttaatgacttccagaaaggtgacattgcagaacgttatagtgtgagtcgtgaaaagaaagaaagttttccgctgaccattaccagcgtgcagccgaatgataccgccttttatctctgtgcgagtagtattgaaggtcgtggccgcacctataatgaacagttctttggtccgggtacccgcctgaccgttgat。
实施例5 MAGE-A4抗原短肽特异性的可溶性单链TCR的表达、复性和纯化
将实施例4中制备的含有重组质粒pET28a-模板链的BL21(DE3)菌落全部接种于含有卡那霉素的LB培养基中,37℃培养至OD
向5mg溶解的单链TCR包涵体蛋白中,加入2.5mL缓冲液(6M Gua-HCl、50mM Tris-HCl pH 8.1、100mM NaCl、10mM EDTA),再加入DTT至终浓度为10mM,37℃处理30min。用注射器向125mL复性缓冲液(100mM Tris-HCl pH 8.1、0.4M L-精氨酸、5M尿素、2mM EDTA、6.5mMEDTA、6.5mMβ-mercapthoethylamine、1.87mM Cystamine)中滴加上述处理后的单链TCR,4℃搅拌10min,然后将复性液装入截留量为4kDa的纤维素膜透析袋,透析袋置于1L预冷的水中,4℃缓慢搅拌过夜。17h后,将透析液换成1L预冷的缓冲液(20mM Tris-HCl pH 8.0),4℃继续透析8h,然后将透析液换成相同的新鲜缓冲液继续透析过夜。17h后,样品经0.45μm滤膜过滤,真空脱气后通过阴离子交换柱(HiTrap Q HP,GE Healthcare),用20mM Tris-HClpH 8.0配制的0-1M NaCl线性梯度洗脱液纯化蛋白,收集的洗脱组分进行SDS-PAGE分析,包含单链TCR的组分浓缩后进一步用凝胶过滤柱(Superdex 7510/300,GE Healthcare)进行纯化,目标组分也进行SDS-PAGE分析。
用于BIAcore分析的洗脱组分进一步采用凝胶过滤法测试其纯度。条件为:色谱柱Agilent Bio SEC-3(300A,Ф7.8×300mm),流动相为150mM磷酸盐缓冲液,流速0.5mL/min,柱温25℃,紫外检测波长214nm。
本实施例纯化后得到的可溶性单链TCR的SDS-PAGE电泳胶图如图3a和图3b所示,其中,图3a的左侧泳道为非还原胶,右侧泳道为分子量标记(marker);图3b的左侧泳道都为分子量标记(marker),右侧泳道为还原胶。
实施例6结合表征
本实施例通过BIAcore分析证明了可溶性的TCR分子能够与GVYDGREHTV-HLAA0201复合物特异性结合。
使用BIAcore T200实时分析系统检测实施例3得到的TCR分子与GVYDGREHTV-HLAA0201复合物的结合活性。将抗链霉亲和素的抗体(GenScript)加入偶联缓冲液(10mM醋酸钠缓冲液,pH 4.77),然后将抗体流过预先用EDC和NHS活化过的CM5芯片,使抗体固定在芯片表面,最后用乙醇胺的盐酸溶液封闭未反应的活化表面,完成偶联过程,偶联水平约为15000RU。
使低浓度的链霉亲和素流过已包被抗体的芯片表面,然后将GVYDGREHTV-HLAA0201复合物流过检测通道,另一通道作为参比通道,再将0.05mM的生物素以10μL/min的流速流过芯片2min,封闭链霉亲和素剩余的结合位点。
上述GVYDGREHTV-HLA A0201复合物的制备过程如下:
(a)纯化
收集100mL诱导表达重链或轻链的E.coli菌液,于4℃、8000g离心10min后用10mLPBS洗涤菌体一次,之后用5mL BugBuster Master Mix Extraction Reagents(Merck)剧烈震荡重悬菌体,并于室温旋转孵育20min,之后于4℃、6000g离心15min,弃去上清,收集包涵体。
将上述包涵体重悬于5mL BugBuster Master Mix中,室温旋转孵育5min;加30mL稀释10倍的BugBuster,混匀,4℃、6000g离心15min;弃去上清,加30mL稀释10倍的BugBuster重悬包涵体,混匀,4℃、6000g离心15min,重复两次,加30mL 20mM Tris-HCl pH8.0重悬包涵体,混匀,4℃、6000g离心15min,最后用20mM Tris-HCl 8M尿素溶解包涵体,SDS-PAGE检测包涵体纯度,BCA试剂盒测浓度。
(b)复性
将合成的短肽GVYDGREHTV溶解于DMSO至20mg/mL的浓度。轻链和重链的包涵体用含有8M尿素、20mM Tris pH 8.0、10mM DTT的溶液来溶解,复性前加入3M盐酸胍、10mM醋酸钠、10mM EDTA进一步变性。将GVYDGREHTV肽以25mg/L(终浓度)加入复性缓冲液(0.4M L-精氨酸、100mM Tris pH 8.3、2mM EDTA、0.5mM氧化性谷胱甘肽、5mM还原型谷胱甘肽、0.2mMPMSF,冷却至4℃),然后依次加入20mg/L的轻链和90mg/L的重链(终浓度,重链分三次加入,8h/次),复性在4℃进行至少3天至完成,SDS-PAGE检测能否复性成功。
(c)复性后纯化
用10体积的20mM Tris pH 8.0作透析来更换复性缓冲液,至少更换缓冲液两次来充分降低溶液的离子强度。透析后用0.45μm醋酸纤维素滤膜过滤蛋白质溶液,然后加载到HiTrap Q HP(GE通用电气公司)阴离子交换柱上(5mL床体积)。利用Akta纯化仪(GE通用电气公司),20mM Tris pH 8.0配制的0-400mM NaCl线性梯度液洗脱蛋白,pMHC约在250mMNaCl处洗脱,收集诸峰组分,SDS-PAGE检测纯度。
(d)生物素化
用Millipore超滤管将纯化的pMHC分子浓缩,同时将缓冲液置换为20mM Tris pH8.0,然后加入生物素化试剂0.05M Bicine pH 8.3、10mM ATP、10mM MgOAc、50μM D-Biotin、100μg/mL BirA酶(GST-BirA),室温孵育混合物过夜,SDS-PAGE检测生物素化是否完全。
(e)纯化生物素化后的复合物
用Millipore超滤管将生物素化标记后的pMHC分子浓缩至1mL,采用凝胶过滤层析纯化生物素化的pMHC,利用Akta纯化仪(GE通用电气公司),用过滤过的PBS预平衡HiPrep
利用BIAcore Evaluation软件计算动力学参数,得到与GVYDGREHTV-HLA A0201复合物结合的动力学图谱,其中,图4为可溶性TCR与GVYDGREHTV-HLA A0201复合物结合的BIAcore动力学图谱,图5为可溶性单链TCR与GVYDGREHTV-HLA A0201复合物结合的BIAcore动力学图谱。图谱显示,本发明得到的可溶性TCR分子能够与GVYDGREHTV-HLA A0201复合物结合。同时,还利用上述方法检测了本发明可溶性的TCR分子与其他几种无关抗原短肽与HLA复合物的结合活性,结果显示本发明TCR分子与其他无关抗原均无结合。
实施例7针对负载短肽的T2细胞,转染本发明TCR的效应细胞激活实验
本实实施例中所用的效应细胞是转染本发明TCR的CD3
ELISPOT平板乙醇活化包被,4℃过夜。实验第1天,去掉包被液,洗涤封闭,室温下孵育两个小时,去除封闭液,将试验的各个组分加入ELISPOT平板:靶细胞为1×10
图7为针对负载短肽的T2细胞,转染本发明TCR的效应细胞的ELISPOT激活功能验证结果,从图7可知,对负载GVYDGREHTV短肽的T2细胞,转染本发明TCR的T细胞有明显的激活效应,而负载其他短肽或空载的T2细胞,转染本发明TCR的T细胞基本无激活效应。
在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
申请人声明,以上所述仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,所属技术领域的技术人员应该明了,任何属于本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,均落在本发明的保护范围和公开范围之内。
序列表
<110> 香雪生命科学技术(广东)有限公司
<120> 一种识别MAGE的T细胞受体及其应用
<130> 2022
<160> 35
<170> PatentIn version 3.3
<210> 1
<211> 114
<212> PRT
<213> 人工序列
<400> 1
Ala Gln Lys Ile Thr Gln Thr Gln Pro Gly Met Phe Val Gln Glu Lys
1 5 1015
Glu Ala Val Thr Leu Asp Cys Thr Tyr Asp Thr Ser Asp Pro Ser Tyr
202530
Gly Leu Phe Trp Tyr Lys Gln Pro Ser Ser Gly Glu Met Ile Phe Leu
354045
Ile Tyr Gln Gly Ser Tyr Asp Gln Gln Asn Ala Thr Glu Gly Arg Tyr
505560
Ser Leu Asn Phe Gln Lys Ala Arg Lys Ser Ala Asn Leu Val Ile Ser
65707580
Ala Ser Gln Leu Gly Asp Ser Ala Met Tyr Phe Cys Ala Met Arg Glu
859095
Tyr Asn Phe Asn Lys Phe Tyr Phe Gly Ser Gly Thr Lys Leu Asn Val
100 105 110
Lys Pro
<210> 2
<211> 342
<212> DNA
<213> 人工序列
<400> 2
gcccagaaga taactcaaac ccaaccagga atgttcgtgc aggaaaagga ggctgtgact 60
ctggactgca catatgacac cagtgatcca agttatggtc tattctggta caagcagccc 120
agcagtgggg aaatgatttt tcttatttat caggggtctt atgaccagca aaatgcaaca 180
gaaggtcgct actcattgaa tttccagaag gcaagaaaat ccgccaacct tgtcatctcc 240
gcttcacaac tgggggactc agcaatgtat ttctgtgcaa tgagggaata caacttcaac 300
aaattttact ttggatctgg gaccaaactc aatgtaaaac ca 342
<210> 3
<211> 255
<212> PRT
<213> 人工序列
<400> 3
Ala Gln Lys Ile Thr Gln Thr Gln Pro Gly Met Phe Val Gln Glu Lys
1 5 1015
Glu Ala Val Thr Leu Asp Cys Thr Tyr Asp Thr Ser Asp Pro Ser Tyr
202530
Gly Leu Phe Trp Tyr Lys Gln Pro Ser Ser Gly Glu Met Ile Phe Leu
354045
Ile Tyr Gln Gly Ser Tyr Asp Gln Gln Asn Ala Thr Glu Gly Arg Tyr
505560
Ser Leu Asn Phe Gln Lys Ala Arg Lys Ser Ala Asn Leu Val Ile Ser
65707580
Ala Ser Gln Leu Gly Asp Ser Ala Met Tyr Phe Cys Ala Met Arg Glu
859095
Tyr Asn Phe Asn Lys Phe Tyr Phe Gly Ser Gly Thr Lys Leu Asn Val
100 105 110
Lys Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp
115 120 125
Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser
130 135 140
Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp
145 150 155 160
Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala
165 170 175
Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn
180 185 190
Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser
195 200 205
Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu
210 215 220
Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys
225 230 235 240
Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
245 250 255
<210> 4
<211> 765
<212> DNA
<213> 人工序列
<400> 4
gcccagaaga taactcaaac ccaaccagga atgttcgtgc aggaaaagga ggctgtgact 60
ctggactgca catatgacac cagtgatcca agttatggtc tattctggta caagcagccc 120
agcagtgggg aaatgatttt tcttatttat caggggtctt atgaccagca aaatgcaaca 180
gaaggtcgct actcattgaa tttccagaag gcaagaaaat ccgccaacct tgtcatctcc 240
gcttcacaac tgggggactc agcaatgtat ttctgtgcaa tgagggaata caacttcaac 300
aaattttact ttggatctgg gaccaaactc aatgtaaaac caaatatcca gaaccctgac 360
cctgccgtgt accagctgag agactctaaa tccagtgaca agtctgtctg cctattcacc 420
gattttgatt ctcaaacaaa tgtgtcacaa agtaaggatt ctgatgtgta tatcacagac 480
aaaactgtgc tagacatgag gtctatggac ttcaagagca acagtgctgt ggcctggagc 540
aacaaatctg actttgcatg tgcaaacgcc ttcaacaaca gcattattcc agaagacacc 600
ttcttcccca gcccagaaag ttcctgtgat gtcaagctgg tcgagaaaag ctttgaaaca 660
gatacgaacc taaactttca aaacctgtca gtgattgggt tccgaatcct cctcctgaaa 720
gtggccgggt ttaatctgct catgacgctg cggctgtggt ccagc 765
<210> 5
<211> 116
<212> PRT
<213> 人工序列
<400> 5
Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg Lys Glu Gly
1 5 1015
Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp Ala Met
202530
Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu Ile Tyr Tyr
354045
Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu Gly Tyr
505560
Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Val Thr Ser
65707580
Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser Ser Ile Glu
859095
Gly Arg Gly Arg Thr Tyr Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg
100 105 110
Leu Thr Val Leu
115
<210> 6
<211> 348
<212> DNA
<213> 人工序列
<400> 6
gatggtggaa tcactcagtc cccgaagtac ctgttcagaa aggaaggaca gaatgtgacc 60
ctgagttgtg aacagaattt gaaccacgat gccatgtact ggtaccgaca ggacccaggg 120
caagggctga gattgatcta ctactcacag atagtaaatg actttcagaa aggagatata 180
gctgaagggt acagcgtctc tcgggagaag aaggaatcct ttcctctcac tgtgacatcg 240
gcccaaaaga acccgacagc tttctatctc tgtgccagta gtatagaggg ccgcgggaga 300
acctacaatg agcagttctt cgggccaggg acacggctca ccgtgcta 348
<210> 7
<211> 295
<212> PRT
<213> 人工序列
<400> 7
Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg Lys Glu Gly
1 5 1015
Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp Ala Met
202530
Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu Ile Tyr Tyr
354045
Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu Gly Tyr
505560
Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Val Thr Ser
65707580
Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser Ser Ile Glu
859095
Gly Arg Gly Arg Thr Tyr Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg
100 105 110
Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
115 120 125
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
130 135 140
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
145 150 155 160
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
165 170 175
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
180 185 190
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
195 200 205
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
210 215 220
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
225 230 235 240
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln
245 250 255
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
260 265 270
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
275 280 285
Lys Arg Lys Asp Ser Arg Gly
290 295
<210> 8
<211> 885
<212> DNA
<213> 人工序列
<400> 8
gatggtggaa tcactcagtc cccgaagtac ctgttcagaa aggaaggaca gaatgtgacc 60
ctgagttgtg aacagaattt gaaccacgat gccatgtact ggtaccgaca ggacccaggg 120
caagggctga gattgatcta ctactcacag atagtaaatg actttcagaa aggagatata 180
gctgaagggt acagcgtctc tcgggagaag aaggaatcct ttcctctcac tgtgacatcg 240
gcccaaaaga acccgacagc tttctatctc tgtgccagta gtatagaggg ccgcgggaga 300
acctacaatg agcagttctt cgggccaggg acacggctca ccgtgctaga ggacctgaaa 360
aacgtgttcc cacccgaggt cgctgtgttt gagccatcag aagcagagat ctcccacacc 420
caaaaggcca cactggtgtg cctggccaca ggcttctacc ccgaccacgt ggagctgagc 480
tggtgggtga atgggaagga ggtgcacagt ggggtcagca cagacccgca gcccctcaag 540
gagcagcccg ccctcaatga ctccagatac tgcctgagca gccgcctgag ggtctcggcc 600
accttctggc agaacccccg caaccacttc cgctgtcaag tccagttcta cgggctctcg 660
gagaatgacg agtggaccca ggatagggcc aaacctgtca cccagatcgt cagcgccgag 720
gcctggggta gagcagactg tggcttcacc tccgagtctt accagcaagg ggtcctgtct 780
gccaccatcc tctatgagat cttgctaggg aaggccacct tgtatgccgt gctggtcagt 840
gccctcgtgc tgatggccat ggtcaagaga aaggattcca gaggc 885
<210> 9
<211> 10
<212> PRT
<213> 人工序列
<400> 9
Gly Val Tyr Asp Gly Arg Glu His Thr Val
1 5 10
<210> 10
<211> 7
<212> PRT
<213> 人工序列
<400> 10
Thr Ser Asp Pro Ser Tyr Gly
1 5
<210> 11
<211> 8
<212> PRT
<213> 人工序列
<400> 11
Gln Gly Ser Tyr Asp Gln Gln Asn
1 5
<210> 12
<211> 11
<212> PRT
<213> 人工序列
<400> 12
Ala Met Arg Glu Tyr Asn Phe Asn Lys Phe Tyr
1 5 10
<210> 13
<211> 5
<212> PRT
<213> 人工序列
<400> 13
Leu Asn His Asp Ala
1 5
<210> 14
<211> 6
<212> PRT
<213> 人工序列
<400> 14
Ser Gln Ile Val Asn Asp
1 5
<210> 15
<211> 15
<212> PRT
<213> 人工序列
<400> 15
Ala Ser Ser Ile Glu Gly Arg Gly Arg Thr Tyr Asn Glu Gln Phe
1 5 1015
<210> 16
<211> 21
<212> DNA
<213> 人工序列
<400> 16
accagtgatc caagttatgg t 21
<210> 17
<211> 24
<212> DNA
<213> 人工序列
<400> 17
caggggtctt atgaccagca aaat 24
<210> 18
<211> 33
<212> DNA
<213> 人工序列
<400> 18
gcaatgaggg aatacaactt caacaaattt tac 33
<210> 19
<211> 15
<212> DNA
<213> 人工序列
<400> 19
ttgaaccacg atgcc 15
<210> 20
<211> 18
<212> DNA
<213> 人工序列
<400> 20
tcacagatag taaatgac 18
<210> 21
<211> 45
<212> DNA
<213> 人工序列
<400> 21
gccagtagta tagagggccg cgggagaacc tacaatgagc agttc 45
<210> 22
<211> 274
<212> PRT
<213> 人工序列
<400> 22
Ser Leu Ser Ser Leu Leu Lys Val Val Thr Ala Ser Leu Trp Leu Gly
1 5 1015
Pro Gly Ile Ala Gln Lys Ile Thr Gln Thr Gln Pro Gly Met Phe Val
202530
Gln Glu Lys Glu Ala Val Thr Leu Asp Cys Thr Tyr Asp Thr Ser Asp
354045
Pro Ser Tyr Gly Leu Phe Trp Tyr Lys Gln Pro Ser Ser Gly Glu Met
505560
Ile Phe Leu Ile Tyr Gln Gly Ser Tyr Asp Gln Gln Asn Ala Thr Glu
65707580
Gly Arg Tyr Ser Leu Asn Phe Gln Lys Ala Arg Lys Ser Ala Asn Leu
859095
Val Ile Ser Ala Ser Gln Leu Gly Asp Ser Ala Met Tyr Phe Cys Ala
100 105 110
Met Arg Glu Tyr Asn Phe Asn Lys Phe Tyr Phe Gly Ser Gly Thr Lys
115 120 125
Leu Asn Val Lys Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
130 135 140
Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
145 150 155 160
Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr
165 170 175
Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190
Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn
195 200 205
Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220
Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
225 230 235 240
Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
245 250 255
Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
260 265 270
Ser Ser
<210> 23
<211> 822
<212> DNA
<213> 人工序列
<400> 23
tcactttcta gcctgctgaa ggtggtcaca gcttcactgt ggctaggacc tggcattgcc 60
cagaagataa ctcaaaccca accaggaatg ttcgtgcagg aaaaggaggc tgtgactctg 120
gactgcacat atgacaccag tgatccaagt tatggtctat tctggtacaa gcagcccagc 180
agtggggaaa tgatttttct tatttatcag gggtcttatg accagcaaaa tgcaacagaa 240
ggtcgctact cattgaattt ccagaaggca agaaaatccg ccaaccttgt catctccgct 300
tcacaactgg gggactcagc aatgtatttc tgtgcaatga gggaatacaa cttcaacaaa 360
ttttactttg gatctgggac caaactcaat gtaaaaccaa atatccagaa ccctgaccct 420
gccgtgtacc agctgagaga ctctaaatcc agtgacaagt ctgtctgcct attcaccgat 480
tttgattctc aaacaaatgt gtcacaaagt aaggattctg atgtgtatat cacagacaaa 540
actgtgctag acatgaggtc tatggacttc aagagcaaca gtgctgtggc ctggagcaac 600
aaatctgact ttgcatgtgc aaacgccttc aacaacagca ttattccaga agacaccttc 660
ttccccagcc cagaaagttc ctgtgatgtc aagctggtcg agaaaagctt tgaaacagat 720
acgaacctaa actttcaaaa cctgtcagtg attgggttcc gaatcctcct cctgaaagtg 780
gccgggttta atctgctcat gacgctgcgg ctgtggtcca gc 822
<210> 24
<211> 313
<212> PRT
<213> 人工序列
<400> 24
Ser Asn Gln Val Leu Cys Cys Val Val Leu Cys Leu Leu Gly Ala Asn
1 5 1015
Thr Val Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg Lys
202530
Glu Gly Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp
354045
Ala Met Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu Ile
505560
Tyr Tyr Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu
65707580
Gly Tyr Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Val
859095
Thr Ser Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser Ser
100 105 110
Ile Glu Gly Arg Gly Arg Thr Tyr Asn Glu Gln Phe Phe Gly Pro Gly
115 120 125
Thr Arg Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu
130 135 140
Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys
145 150 155 160
Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu
165 170 175
Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr
180 185 190
Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr
195 200 205
Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro
210 215 220
Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn
225 230 235 240
Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser
245 250 255
Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr
260 265 270
Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly
275 280 285
Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala
290 295 300
Met Val Lys Arg Lys Asp Ser Arg Gly
305 310
<210> 25
<211> 939
<212> DNA
<213> 人工序列
<400> 25
agcaaccagg tgctctgctg tgtggtcctt tgtctcctgg gagcaaacac cgtggatggt 60
ggaatcactc agtccccgaa gtacctgttc agaaaggaag gacagaatgt gaccctgagt 120
tgtgaacaga atttgaacca cgatgccatg tactggtacc gacaggaccc agggcaaggg 180
ctgagattga tctactactc acagatagta aatgactttc agaaaggaga tatagctgaa 240
gggtacagcg tctctcggga gaagaaggaa tcctttcctc tcactgtgac atcggcccaa 300
aagaacccga cagctttcta tctctgtgcc agtagtatag agggccgcgg gagaacctac 360
aatgagcagt tcttcgggcc agggacacgg ctcaccgtgc tagaggacct gaaaaacgtg 420
ttcccacccg aggtcgctgt gtttgagcca tcagaagcag agatctccca cacccaaaag 480
gccacactgg tgtgcctggc cacaggcttc taccccgacc acgtggagct gagctggtgg 540
gtgaatggga aggaggtgca cagtggggtc agcacagacc cgcagcccct caaggagcag 600
cccgccctca atgactccag atactgcctg agcagccgcc tgagggtctc ggccaccttc 660
tggcagaacc cccgcaacca cttccgctgt caagtccagt tctacgggct ctcggagaat 720
gacgagtgga cccaggatag ggccaaacct gtcacccaga tcgtcagcgc cgaggcctgg 780
ggtagagcag actgtggctt cacctccgag tcttaccagc aaggggtcct gtctgccacc 840
atcctctatg agatcttgct agggaaggcc accttgtatg ccgtgctggt cagtgccctc 900
gtgctgatgg ccatggtcaa gagaaaggat tccagaggc 939
<210> 26
<211> 208
<212> PRT
<213> 人工序列
<400> 26
Ala Gln Lys Ile Thr Gln Thr Gln Pro Gly Met Phe Val Gln Glu Lys
1 5 1015
Glu Ala Val Thr Leu Asp Cys Thr Tyr Asp Thr Ser Asp Pro Ser Tyr
202530
Gly Leu Phe Trp Tyr Lys Gln Pro Ser Ser Gly Glu Met Ile Phe Leu
354045
Ile Tyr Gln Gly Ser Tyr Asp Gln Gln Asn Ala Thr Glu Gly Arg Tyr
505560
Ser Leu Asn Phe Gln Lys Ala Arg Lys Ser Ala Asn Leu Val Ile Ser
65707580
Ala Ser Gln Leu Gly Asp Ser Ala Met Tyr Phe Cys Ala Met Arg Glu
859095
Tyr Asn Phe Asn Lys Phe Tyr Phe Gly Ser Gly Thr Lys Leu Asn Val
100 105 110
Lys Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp
115 120 125
Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser
130 135 140
Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp
145 150 155 160
Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala
165 170 175
Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn
180 185 190
Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Cys Ser Pro Glu Ser Ser
195 200 205
<210> 27
<211> 624
<212> DNA
<213> 人工序列
<400> 27
gcgcagaaaa ttacccaaac ccaaccagga atgttcgtgc aggaaaagga ggctgtgact 60
ctggactgca catatgacac cagtgatcca agttatggtc tattctggta caagcagccc 120
agcagtgggg aaatgatttt tcttatttat caggggtctt atgaccagca aaatgcaaca 180
gaaggtcgct actcattgaa tttccagaag gcaagaaaat ccgccaacct tgtcatctcc 240
gcttcacaac tgggggactc agcaatgtat ttctgtgcaa tgagggaata caacttcaac 300
aaattttact ttggatctgg gaccaaactc aatgtaaaac caaatatcca gaaccctgac 360
cctgccgttt atcagctgcg tgatagcaaa agcagcgata aaagcgtgtg cctgttcacc 420
gattttgata gccagaccaa cgtgagccag agcaaagata gcgatgtgta catcaccgat 480
aaaaccgtgc tggatatgcg cagcatggat ttcaaaagca atagcgcggt tgcgtggagc 540
aacaaaagcg attttgcgtg cgcgaacgcg tttaacaaca gcatcatccc ggaagatacg 600
ttcttctgca gcccagaaag ttcc 624
<210> 28
<211> 246
<212> PRT
<213> 人工序列
<400> 28
Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg Lys Glu Gly
1 5 1015
Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp Ala Met
202530
Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu Ile Tyr Tyr
354045
Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu Gly Tyr
505560
Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Val Thr Ser
65707580
Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser Ser Ile Glu
859095
Gly Arg Gly Arg Thr Tyr Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg
100 105 110
Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
115 120 125
Val Phe Glu Pro Ser Glu Cys Glu Ile Ser His Thr Gln Lys Ala Thr
130 135 140
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
145 150 155 160
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
165 170 175
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Ala Leu
180 185 190
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
195 200 205
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
210 215 220
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
225 230 235 240
Ala Trp Gly Arg Ala Asp
245
<210> 29
<211> 738
<212> DNA
<213> 人工序列
<400> 29
gatggcggca ttacccagtc cccgaagtac ctgttcagaa aggaaggaca gaatgtgacc 60
ctgagttgtg aacagaattt gaaccacgat gccatgtact ggtaccgaca ggacccaggg 120
caagggctga gattgatcta ctactcacag atagtaaatg actttcagaa aggagatata 180
gctgaagggt acagcgtctc tcgggagaag aaggaatcct ttcctctcac tgtgacatcg 240
gcccaaaaga acccgacagc tttctatctc tgtgccagta gtatagaggg ccgcgggaga 300
acctacaatg agcagttctt cgggccaggg acacggctca ccgtgctaga ggacctgaaa 360
aacgtgttcc cacccgaggt cgctgtgttt gagccatcag aatgcgaaat tagccatacc 420
cagaaagcga ccctggtttg tctggcgacc ggtttttatc cggatcatgt ggaactgtct 480
tggtgggtga acggcaaaga agtgcatagc ggtgtttcta ccgatccgca gccgctgaaa 540
gaacagccgg cgctgaatga tagccgttat gcgctgtcta gccgtctgcg tgttagcgcg 600
accttttggc aaaatccgcg taaccatttt cgttgccagg tgcagtttta tggcctgagc 660
gaaaacgatg aatggaccca ggatcgtgcg aagccggtta cccagattgt tagcgcggaa 720
gcctggggcc gcgcagat 738
<210> 30
<211> 254
<212> PRT
<213> 人工序列
<400> 30
Ala Gln Lys Ile Thr Gln Thr Gln Pro Gly Leu Asn Val Gln Glu Gly
1 5 1015
Glu Asn Val Thr Ile Asp Cys Thr Tyr Asp Thr Ser Asp Pro Ser Tyr
202530
Gly Leu Phe Trp Tyr Lys Gln Pro Ser Ser Gly Glu Met Ile Phe Leu
354045
Ile Tyr Gln Gly Ser Tyr Asp Gln Gln Asn Ala Thr Glu Gly Arg Tyr
505560
Ser Leu Asn Phe Gln Lys Ala Arg Lys Ser Ala Asn Leu Val Ile Ser
65707580
Ala Ser Gln Pro Gly Asp Ser Ala Met Tyr Phe Cys Ala Met Arg Glu
859095
Tyr Asn Phe Asn Lys Phe Tyr Phe Gly Cys Gly Thr Lys Leu Asn Val
100 105 110
Lys Pro Gly Gly Gly Ser Glu Gly Gly Gly Ser Glu Gly Gly Gly Ser
115 120 125
Glu Gly Gly Gly Ser Glu Gly Gly Thr Gly Asp Gly Gly Ile Thr Gln
130 135 140
Ser Pro Lys Tyr Leu Ser Val Lys Glu Gly Gln Asn Val Thr Leu Ser
145 150 155 160
Cys Glu Gln Asn Leu Asn His Asp Ala Met Tyr Trp Tyr Arg Gln Asp
165 170 175
Pro Gly Gln Cys Leu Arg Leu Ile Tyr Tyr Ser Gln Ile Val Asn Asp
180 185 190
Phe Gln Lys Gly Asp Ile Ala Glu Arg Tyr Ser Val Ser Arg Glu Lys
195 200 205
Lys Glu Ser Phe Pro Leu Thr Ile Thr Ser Val Gln Pro Asn Asp Thr
210 215 220
Ala Phe Tyr Leu Cys Ala Ser Ser Ile Glu Gly Arg Gly Arg Thr Tyr
225 230 235 240
Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg Leu Thr Val Asp
245 250
<210> 31
<211> 762
<212> DNA
<213> 人工序列
<400> 31
gcacaaaaaa ttactcagac ccagccgggt ctgaatgtgc aggaaggcga aaatgttacc 60
attgattgca cctatgatac cagtgatccg agttatggtc tgttttggta taaacagccg 120
agcagcggtg aaatgatttt cctgatctat cagggcagtt atgatcagca gaatgccacc 180
gaaggtcgct atagtctgaa ttttcagaaa gcccgtaaaa gcgccaatct ggttattagt 240
gcaagtcagc cgggcgatag cgccatgtat ttctgtgcaa tgcgcgaata taattttaat 300
aagttctact tcggttgtgg caccaaactg aatgtgaaac cgggcggcgg tagtgaaggc 360
ggcggcagcg aaggcggcgg ttcagaaggc ggcggaagcg aaggcggtac cggcgatggt 420
ggtattaccc agagtccgaa atatctgagc gttaaagaag gccagaatgt gaccctgagc 480
tgcgaacaga atctgaatca tgatgccatg tattggtatc gccaggaccc tggccagtgt 540
ctgcgcttaa tctattatag ccagattgtt aatgacttcc agaaaggtga cattgcagaa 600
cgttatagtg tgagtcgtga aaagaaagaa agttttccgc tgaccattac cagcgtgcag 660
ccgaatgata ccgcctttta tctctgtgcg agtagtattg aaggtcgtgg ccgcacctat 720
aatgaacagt tctttggtcc gggtacccgc ctgaccgttg at 762
<210> 32
<211> 114
<212> PRT
<213> 人工序列
<400> 32
Ala Gln Lys Ile Thr Gln Thr Gln Pro Gly Leu Asn Val Gln Glu Gly
1 5 1015
Glu Asn Val Thr Ile Asp Cys Thr Tyr Asp Thr Ser Asp Pro Ser Tyr
202530
Gly Leu Phe Trp Tyr Lys Gln Pro Ser Ser Gly Glu Met Ile Phe Leu
354045
Ile Tyr Gln Gly Ser Tyr Asp Gln Gln Asn Ala Thr Glu Gly Arg Tyr
505560
Ser Leu Asn Phe Gln Lys Ala Arg Lys Ser Ala Asn Leu Val Ile Ser
65707580
Ala Ser Gln Pro Gly Asp Ser Ala Met Tyr Phe Cys Ala Met Arg Glu
859095
Tyr Asn Phe Asn Lys Phe Tyr Phe Gly Cys Gly Thr Lys Leu Asn Val
100 105 110
Lys Pro
<210> 33
<211> 342
<212> DNA
<213> 人工序列
<400> 33
gcacaaaaaa ttactcagac ccagccgggt ctgaatgtgc aggaaggcga aaatgttacc 60
attgattgca cctatgatac cagtgatccg agttatggtc tgttttggta taaacagccg 120
agcagcggtg aaatgatttt cctgatctat cagggcagtt atgatcagca gaatgccacc 180
gaaggtcgct atagtctgaa ttttcagaaa gcccgtaaaa gcgccaatct ggttattagt 240
gcaagtcagc cgggcgatag cgccatgtat ttctgtgcaa tgcgcgaata taattttaat 300
aagttctact tcggttgtgg caccaaactg aatgtgaaac cg 342
<210> 34
<211> 116
<212> PRT
<213> 人工序列
<400> 34
Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Ser Val Lys Glu Gly
1 5 1015
Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp Ala Met
202530
Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Cys Leu Arg Leu Ile Tyr Tyr
354045
Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu Arg Tyr
505560
Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Ile Thr Ser
65707580
Val Gln Pro Asn Asp Thr Ala Phe Tyr Leu Cys Ala Ser Ser Ile Glu
859095
Gly Arg Gly Arg Thr Tyr Asn Glu Gln Phe Phe Gly Pro Gly Thr Arg
100 105 110
Leu Thr Val Asp
115
<210> 35
<211> 348
<212> DNA
<213> 人工序列
<400> 35
gatggtggta ttacccagag tccgaaatat ctgagcgtta aagaaggcca gaatgtgacc 60
ctgagctgcg aacagaatct gaatcatgat gccatgtatt ggtatcgcca ggaccctggc 120
cagtgtctgc gcttaatcta ttatagccag attgttaatg acttccagaa aggtgacatt 180
gcagaacgtt atagtgtgag tcgtgaaaag aaagaaagtt ttccgctgac cattaccagc 240
gtgcagccga atgataccgc cttttatctc tgtgcgagta gtattgaagg tcgtggccgc 300
acctataatg aacagttctt tggtccgggt acccgcctga ccgttgat 348
- 识别HLA-A1-或HLA-CW7-限制的MAGE的T细胞受体
- 一种增强型的靶向识别受体酪氨酸激酶的荧光传感器及细胞膜荧光成像的应用
- 一种靶向CD19的嵌合抗原受体T细胞的制备方法及应用
- 一种基于CD19和PSMA的双重嵌合抗原受体基因修饰的免疫细胞及其应用
- 一种新型可调控的双嵌合抗原受体T细胞及其构建方法和应用
- 一种靶向MAGE-A3的T细胞受体、T细胞受体基因修饰T细胞及其制备方法和应用
- 一种识别MAGE-A4的T细胞受体及其编码序列和应用