一种基于毫米波感知振动信号的抗噪声声纹识别方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及无线智能感知领域,尤其涉及一种基于毫米波感知振动信号的抗噪声声纹识别方法。
背景技术
随着声控设备和语音交互服务的快速增长,将基于声纹的生物识别技术用于用户认证、语音助理的研究越来越多。声纹是一种生理和行为相结合的生物特征,具有生物识别的普遍性、唯一性、持久性和可操作性等特点,因此可以通过提取说话人独特的声纹特征进行说话人的识别。现有的声纹感知主要通过特殊的硬件设备如麦克风、加速度计等实现,存在声音被截获或者模仿等识别的安全风险。
声带是一个非常重要的发声器官,其振动通过声腔发出具有独特特征的声音。通过毫米波感知方式,实现非接触式直接采集声带振动信号,可以实现便捷、安全的声纹识别,然而通过毫米波感知采集的声带振动信号非常微弱,容易被环境噪声淹没,从而导致无法提取能够正确识别说话人声纹的特征。
发明内容
针对现有技术的不足,本发明提出一种基于毫米波感知振动信号的抗噪声声纹识别方法,利用了由声带振动引起的目标人喉咙附近皮肤反射射频信号的独特干扰,通过毫米波感知接收反射射频信号,采用一系列信号智能分析方法,提取声纹特征,实现抗噪声声纹识别,从而区分说话人的身份。
具体技术方案如下:
一种基于毫米波感知振动信号的抗噪声声纹识别方法,包括以下步骤:
S1:使用毫米波雷达向目标人发射射频信号,并接收目标人说话时对发射信号调制后的回波信号,将回波信号与发射信号混合后的中频信号作为毫米波雷达的接收信号;
S2:通过波束成形算法提高接收信号的信噪比;通过波束成形后的接收信号表达式为:
x
式中,θ为目标人相对毫米波雷达的方位角,
S3:对接收信号进行预处理:对毫米波雷达感知区域按单元进行划分,得到存在感知目标的候选单元集,去除其中判断为静态反射物和随机身体运动的候选单元,定位喉咙部位以获得声带振动的数据;
S4:对所述声带振动的数据进行特征提取:取喉咙部位单元中的采集的平均信号作为声带振动的射频接收信号
S5:对声带振动的轨迹进行基于深度神经网络AlexNet的声纹识别。
进一步地,所述S1具体为:
毫米波雷达发射调频连续波信号,通过目标人调制后反射回波信号,所述调频连续波信号和回波信号通过混频器混频得到中频信号,其表达式如下:
式中,j为虚数单位,λ
R(t)=R
式中,R
得到通过i次采样的第k个啁啾信号发射后,接收信号的表达式如下:
进一步地,所述S2具体为:
对于M×N的多天线毫米波雷达,相当于M×N元素的虚拟天线阵列,第l信道(l=1,2,…,M×N)的接收信号表达式为:
式中,d
第m个发射天线的导向矢量
式中,R
式中,
进一步地,所述S3具体通过如下子步骤实现:
S3.1:对雷达感知信号空间按单元进行划分,根据毫米波雷达的距离分辨率,将雷达感知的区域划分为多个长方体单元,以距离分辨率为长方体单元的一个边长,每个长方体单元的长为Δr,宽为
S3.2:形成感知目标的候选单元集。为了定位目标人的喉咙部位位置,通过二维自适应CFAR算法判断每个长方体单元内是否存在感知目标,将存在感知目标的单元作为目标候选单元,每个长方体单元接收到的信号通过如下表达式表示:
式中,d()表示假设检验,H
若
S3.3:进行静态反射物检测,计算每个候选单元相位的方差统计值
式中,
如果
S3.4:进行随机身体运动检测,设定门限η
若
式中,x(t)表示候选单元中接收信号的值
因此,当
S3.5:在候选单元中将判断为静态反射物反射的信号的候选单元、判断为随机身体运动反射的信号的候选单元剔除后,剩余的候选单元组成目标位置,即感知声带振动的喉咙部位。
进一步地,所述S4具体通过如下子步骤实现:
S4.1:将射频接收信号
S4.2:对每个Mel频率下的数据进行对数压缩,并对其进行离散余弦变化,获得M个Mel频率倒谱系数;
S4.3:对M个Mel频率倒谱系数分别取一阶导数和二阶导数,从而获得M×3个Mel频率倒谱特征值,即得到声带振动的轨迹。
进一步地,所述S5中,深度神经网络AlexNet的配置依次为:
一个输入层,用于从M×3的Mel频率倒谱系数特征值矩阵中读取数据;
两个卷积层,具有3×3的64通道滤波器;每个卷积层后面依次包括一个归一化层,用于归一化数据;一个线性整流函数层,用于激活函数,使准确率更高;
三个完全连接层,每个完全连接层具有1024个神经元;
一个具有2个神经元的完全连接层;一个1×2的softmax激活函数层,用于进行二分类,一类是通过说话人声纹识别的正确用户,另一个类是其他。
本发明的有益效果是:
(1)本发明提出基于距离分辨率的单元划分方法,联合静态反射物检测和随机身体运动检测抑制杂波影响,定位声带振动喉咙部位,提高声纹识别的抗噪性、准确性和鲁棒性。
(2)传统的声纹识别主要采用扬声器采集语言信号,容易受到伪造或重放攻击,本发明所用的方法通过毫米波雷达直接感知声带振动,减少识别的安全风险。
附图说明
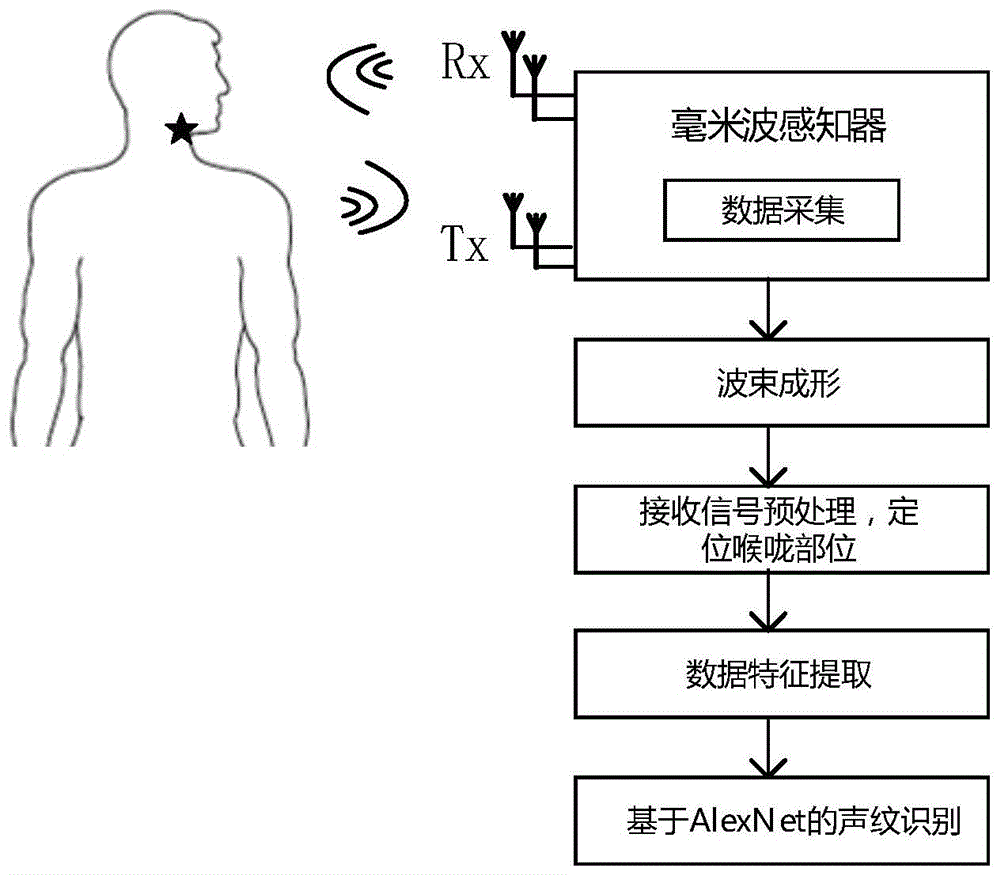
图1是本发明基于毫米波感知振动信号的抗噪声声纹识别方法的流程图。
图2是本发明步骤S2的预处理流程图。
图3是本发明步骤S2中将雷达感知区域按单元进行划分的示意图。
图4是本发明步骤S4中深度神经网络AlexNet的网络结构图。
具体实施方式
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,一种基于毫米波感知振动信号的抗噪声声纹识别方法,具体包括以下步骤:
S1:数据采集:使用毫米波雷达向目标人发射射频信号,并接收目标人说话时对发射信号调制后的回波信号,并以回波信号与发射信号混合后的中频信号作为毫米波雷达的接收信号,具体如下:
毫米波雷达发射调频连续波(Frequency Modulated Continuous Wave,以下简称FMCW)信号,通过目标人调制后反射回波信号,FMCW信号和回波信号通过混频器混频得到中频信号,其表达式如下:
式中,j为虚数单位,t为采样时间,λ
R(t)=R
式中,R
由此得到,通过i次采样的第k个啁啾信号发射后,接收信号可以表示为:
S2:通过波束成形算法提高接收信号的信噪比,具体为:
对于M×N的多天线毫米波雷达,相当于M×N元素的虚拟天线阵列,M、N分别为毫米波雷达虚拟天线阵列的行数、列数,第l信道(l=1,2,…,M×N)的接收信号表达式为:
式中,d
为进一步确定目标振动物体的方位并提高接收信号的信噪比,增强喉咙皮肤位移信号的采集功率,通过波束成形算法使得毫米波雷达发射和接收天线指向目标所在的方位,此时毫米波雷达发射和接收天线的方位角为θ,俯仰角为
式中,R
式中,
S3:对接收信号进行预处理,如图2所示,预处理包括:感知区域单元划分、形成目标候选单元、静态反射物检测、随机身体运动检测步骤,以此定位喉咙部位以获得声带振动的数据。根据步骤S2,通过波束成形后的接收信号可以表示为:
式中,
S3.1:对雷达感知信号空间按单元进行划分。如图3所示,以雷达为原点,坐标轴方向遵循世界坐标系的规则,目标人的喉部与x轴形成方位角θ,与z轴形成俯仰角
S3.2:形成感知目标的候选单元集。为了定位目标人的喉咙部位位置,通过二维自适应恒虚警检测(Constant False Alarm Rate,以下简称CFAR)算法判断每个长方体单元内是否存在感知目标,将存在感知目标的单元作为目标候选单元,每个长方体单元接收到的信号通过如下表达式表示:
式中,d()表示假设检验,H
根据决策阈值Γ筛选,若
由于候选单元中还包含了检测目标范围内的静态反射物、随机身体运动反射的信号,需要对候选单元做进一步处理以提高声纹识别的精度。
S3.3:进行静态反射物检测。在雷达感知的区域内能反射信号的物质有可能是人也有可能是静止的物体,为了区别候选单元中人和静止的物体,计算每个候选单元相位的方差统计值
式中,
如果是静止的物体,相位变化非常小,因此方差统计值
S3.4:进行随机身体运动检测。根据检测目标随机身体运动的幅度通常会比声带振动大的原理,设定一个门限η
同时,如果随机身体运动的幅度偏小(即
式中,x(t)表示候选单元中接收信号的值
因此候选单元是否存在随机身体运动可以通过如下条件进行判断:
式中,Γ
S3.5:在候选单元中将S3.3得到的记为静态反射物反射的信号的候选单元、S3.4得到的记为随机身体运动反射的信号的候选单元剔除后,剩余的候选单元则可以组成目标位置,即感知声带振动的喉咙部位。
S4:对S3得到的喉咙部位包含声带振动的数据进行特征提取。取目标位置单元(即喉咙部位单元)中采集的平均信号作为声带振动的射频接收信号
S4.1:将射频接收信号
S4.2:对每个Mel频率下的数据进行对数压缩,并对其进行DCT变换(离散余弦变化),获得M个MFCC系数。在本实施例中,M的值取20。
S4.3:对M个MFCC系数分别取一阶导数和二阶导数,从而获得M×3个MFCC特征值,即得到声带振动的轨迹。
S5:对声带振动的轨迹进行基于深度神经网络AlexNet网络的声纹识别。为实现基于毫米波雷达感知的声纹识别验证,设计一个深度卷积网络AlexNet,该网络的配置如图4所示。深度卷积网络AlexNet从输入到输出的配置依次为:
一个输入层,用于从M×3的MFCC特征值矩阵中读取数据。
两个卷积层(Conv),具有3×3的64通道滤波器;每个卷积层后面依次包括一个归一化层(BN),用于归一化数据;一个线性整流函数(ReLU)层,用于激活函数,使准确率更高。
三个完全连接层(Fully Connected layers,以下简称FC),每个完全连接层具有1024个神经元。
一个具有2个神经元的完全连接层;一个1×2的softmax激活函数层,即为输出层,用于进行二分类,一类是通过说话人声纹识别的正确用户,另一个类是其他。
本发明提出基于毫米波感知振动信号的抗噪声声纹识别方法,通过距离分辨率的单元划分,联合静态反射物检测和随机身体运动检测抑制杂波影响,准确定位声带振动喉咙部位,提高声纹识别的抗噪性、准确性和鲁棒性,具有较高的精度和稳定性。此外,本发明可以应用于生物认证、人机交互、健康或情绪估计等领域,具有较好的实用性和广泛的应用前景。
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
- 一种基于3D卷积神经网络的声纹识别方法
- 一种基于毫米波感知的非接触式声纹生物认证方法
- 一种基于环境感知的声纹识别方法及系统