一种融合显示视觉中心与注意力机制的水下目标检测方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于水下目标检测领域,涉及一种融合显示视觉中心与注意力机制的水下目标检测方法。
背景技术
海洋占地球总表面积的绝大部分,包含丰富的资源。近随着计算机视觉和水下机器人的发展,基于光学图像的水下目标检测广泛应用在水下航行以及鱼类养殖等领域。早期水下目标检测主要是基于人工特征提取的机器学习方法,即通过颜色、形状、纹理等特征来刻画水下物体,但受制于硬件设备和周围环境,无法高精度检测目标物体,造成大量信息误差。而基于深度学习的目标检测算法实现了目标检测任务中端到端的检测,克服了传统目标检测算法的诸多缺点,其中YOLO系列目标检测算法在保证检测速度的同时,检测精度也呈现出不错效果。
由于水下生物受到自身习性以及海洋洋流等多种因素的影响,水下目标间存在相互遮挡和检测场景中小目标众多、细长型目标检测精度低等问题。现在常使用的深度学习目标检测算法YOLOv5在自然环境中检测性能优异,但在水下环境中并不令人满意,其模型仍有很大的改进空间。因此考虑到水下环境的复杂性,往往需要对常规的检测模型进行适当地修改,使其能够更好地在水下环境中执行各种目标检测任务。
针对上述问题,本发明提出了一种新的水下目标检测方法,该方法能提升模型在复杂水环境下的目标检测性能。
发明内容
有鉴于此,本发明需要解决的技术问题是提供一种基于YOLOv5改进的水下目标检测方法,该方法能在复杂的水下环境中,提高YOLOv5模型对多种特定目标的检测精度。
本发明解决技术问题所采用的技术方案如下:
一种融合显示视觉中心与注意力机制的水下目标检测方法,其中包括:
步骤1)获取水下特定目标的初始数据集,并对数据集中图像进行预处理;
步骤2)将经预处理后的图像输入到主干特征提取网络,提取图像不同尺度特征,得到不同尺度的特征图像;
步骤3)将不同尺度的特征图像输入特征融合网络。特征融合网络以加权的方式对特征图进行融合,对不同尺度的特征信息进行充分融合,得到用于预测的特征图;
步骤4)预测网络中的基于无锚盒的检测框对输入融合后的特征图进行处理,将检测到的目标的种类、位置和置信度在输入图片中标识出来。
进一步,所述步骤1)具体包括以下步骤:
步骤11)对初始数据集利用标记软件进行水下图像标记,将图像中的各种目标用特定的方框标记出来,生成对应的标注文件,与水下图像文件一同作为训练数据集;
步骤12)数据预处理。采用与数据无关的增强方法,即Mixup方法,构建虚拟样本,对图像进行增强处理。
进一步,所述步骤2)具体包括以下步骤:
步骤21)将预处理后的数据集送入主干特征提取网络进行特征提取。采用融合注意力机制与可变形卷积的CSP模块进行特征提取,并用不同采样率的空洞卷积提取多尺度上下文信息。每个模块经下采样后输出不同分辨率的特征图,其大小分别为原始特征图的1/4、1/8、1/16、1/32,通道维度上分别是经Focus操作后的2、4、8、16倍。
进一步,所述步骤3)具体包括以下步骤:
步骤31)将特征提取后的四种不同尺度特征图作为特征融合网络的输入,其中大小为原始图片1/4的特征图经过协调注意力模块后送入特征融合网络。对于输入的特征图,首先将1/32大小的特征图输入EVC模块,并进行自底向上的融合,其中分别以带权重的方式融合大小为原始图片1/4、1/8、1/16、1/32的输入特征图,这样能充分融合浅层位置信息,为目标定位提供有效信息。自底向上的融合结构由EVC模块、卷积层、上采样层以及Concat层组成;
步骤32)将经过自底向上融合后的特征图再进行自顶向下的特征融合。其中分别以带权重的方式融合自底向上中特征图大小为原始图片1/4、1/8、1/16、1/32的输出特征图,这样能充分融合浅层位置信息与深层语义信息,为目标定位与分类提供有效信息。自顶向下的融合结构由卷积层、下采样层以及Concat层组成。
进一步,所述步骤4)具体包括以下步骤:
步骤41)将经过特征融合网络后的特征图送入预测网络,该网络包含四个检测头,较原有模型增加了一个小目标检测头。预测网络能同时进行类别与位置的预测,主要由卷积层、批归一化层以及非线性层组成。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
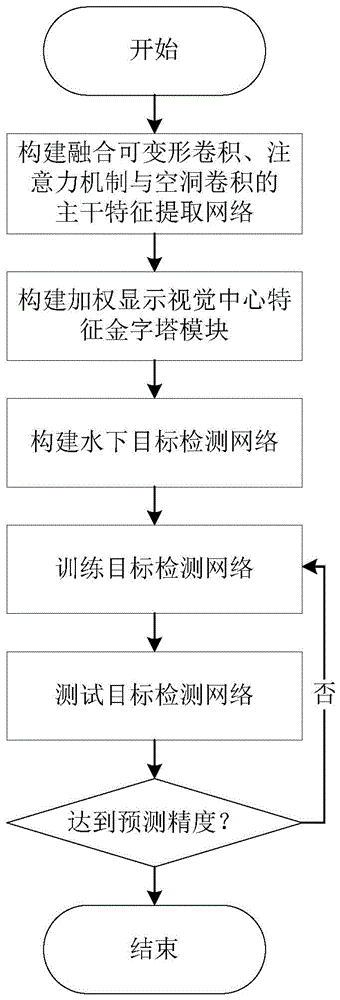
图1为本方法流程图;
图2为本方法的总体模型框架图;
图3为本方法所提出的DC-BoT结构图;
图4为本方法所提出的FP-ASPP结构图;
图5为本方法所提出的WEVC-FPN结构图。
具体实施方式
下面将结合附图,对本发明的优选实例进行详细的描述。
本发明提供的一种融合显示视觉中心与注意力机制的水下目标检测方法,方法流程图如图1所示,本方法所提的总体模型框架图如图2所示,该方法包括以下步骤:
步骤1)构建水下目标检测数据集;
步骤2)构建融合注意力机制与可变形卷积的DC-BoT模块;
步骤3)构建由不同膨胀系数的空洞卷积组成的FP-ASPP模块;
步骤4)构建主干特征提取网络;
步骤5)构建加权显示视觉中心特征金字塔模块;
步骤6)构建融合显示视觉中心与注意力机制的水下目标检测网络;
步骤7)训练目标检测网络;
步骤8)测试目标检测网络。
进一步,步骤1)具体内容包括以下几个步骤:
步骤11)获取开源水下目标检测数据集,该数据集包含4类,分别为:海胆、海星、扇贝以及海参,通过标注软件对每张图片中的目标进行标注,生成标注文件;
步骤12)将所得数据集进行划分,以7:2:1的比例分别划分为训练集、测试集以及验证集。
进一步,步骤2)具体内容包括以下几个步骤:
步骤21)如图3所示,DC-BoT模块由一个残差结构组成,包含结合可变形卷积的瓶颈模块、结合注意力机制的瓶颈模块,以及顺序连接卷积层、批归一化层、激活函数层的卷积模块,其中,可变形卷积能增强主干网络对细长型物体特征的提取能力,多头自注意力机制能够学习到图像中不同位置之间的特征关系。二者结合,能更准确地表示水下细长型目标以及遮挡目标的形状、大小和位置等信息。DC-BoT模块将输入特征图按通道维度分成三个部分,并将其分别通过三个模块,最后再按通道方向进行拼接。
进一步,步骤3)具体内容包括以下步骤:
步骤31)如图4所示,FP-ASPP模块由膨胀系数分别为5、9、13的空洞卷积以及堆叠的最大池化模块(SPPF)组成。该模块采用SPPF保留重要特征信息,并采用3个不同膨胀系数的空洞卷积来增强感受野,有效避免下采样操作带来的特征信息损失。最后将各分支的特征在通道维度上进行拼接,从而增加模型对不同物体的感知能力。
进一步,步骤4)具体内容包括以下步骤:
步骤41)利用步骤2与步骤3构建的模块结合由卷积层、批归一化层、激活函数层构成的卷积模块搭建主干特征提取网络,如图2中Backbone所示。每个DC-BoT模块之间通过卷积模块连接,负责模块之间的尺度缩放,最后连接FP-ASPP模块。
进一步,步骤5)具体内容包括以下步骤:
步骤51)如图5所示,WEVC-FPN模块将显示视觉中心模块的输出分别上采样1倍、2倍、4倍、8倍,并将上采样后的特征加权融合到相应的输出层中,这样可以使网络更有效地融合多尺度特征。本发明使用的加权方式为快速归一加权,公式为:
其中I
WEVC-FPN结构每层的输出特征式可表示为:
其中,R是对输入进行上采样或下采样操作,P
进一步,步骤6)具体内容包括以下步骤:
步骤61)利用以上步骤构成的主干网络、特征融合网络并结合前文所述的预测网络,组成水下目标检测网络;
步骤62)在预测网络的设计上,增加融合协调注意力机制的小目标检测头,如图2所示。
进一步,步骤7)具体内容包括以下步骤:
步骤71)配置相应配置,设置训练参数,开展训练任务;
步骤72)配置的训练环境为:Ubuntu20.04 LTS、Python3.8和Pytorch2.0.0等平台实现。硬件设备包括CPU:Intel(R)Xeon(R)CPU E5-2680 v4@2.40GHz,内存为32GB;GPU:NVIDIARTX 3090,内存为24GB。
步骤73)训练参数的配置为:目标类别数为4,输入图像尺寸为736×416,批量大小设置为25,学习率为0.001,训练轮次为100。
进一步,步骤8)具体内容包括以下步骤:
将训练好的权重文件加载到水下目标检测网络中,从测试数据集中随机选择图片进行检测,返回带有待测目标位置及类别信息的已标注图片。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管通过上述实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其做出各种各样的改变,但不偏离本发明权利要求书所限定的范围。
- 一种基于注意力机制的毫米波雷达与视觉融合的三维目标检测方法
- 一种基于注意力机制的毫米波雷达与视觉融合的三维目标检测方法