一种基于问答任务模型进行问题扩充的方法及存储介质
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及问答任务领域,特别是涉及一种基于问答任务模型进行问题扩充的方法及存储介质。
背景技术
随着ChatGPT的发展,使用模型进行AI问答越来越普遍,在我们对任一模型进行训练时,往往需要大量的训练样本,因此,常常基于样本问题使用AI问答进行问题扩充,然而,AI扩充的问题往往简单、重复、量大,对模型的后续训练帮助并不大,因此,在进行问题扩充时,如何设置扩充规则,并对模型输入满足合适的规则使得模型能够输出高质量的问题至关重要。
发明内容
针对上述技术问题,本发明采用的技术方案为:
一种基于问答任务模型进行问题扩充的方法,所述方法包括如下步骤:
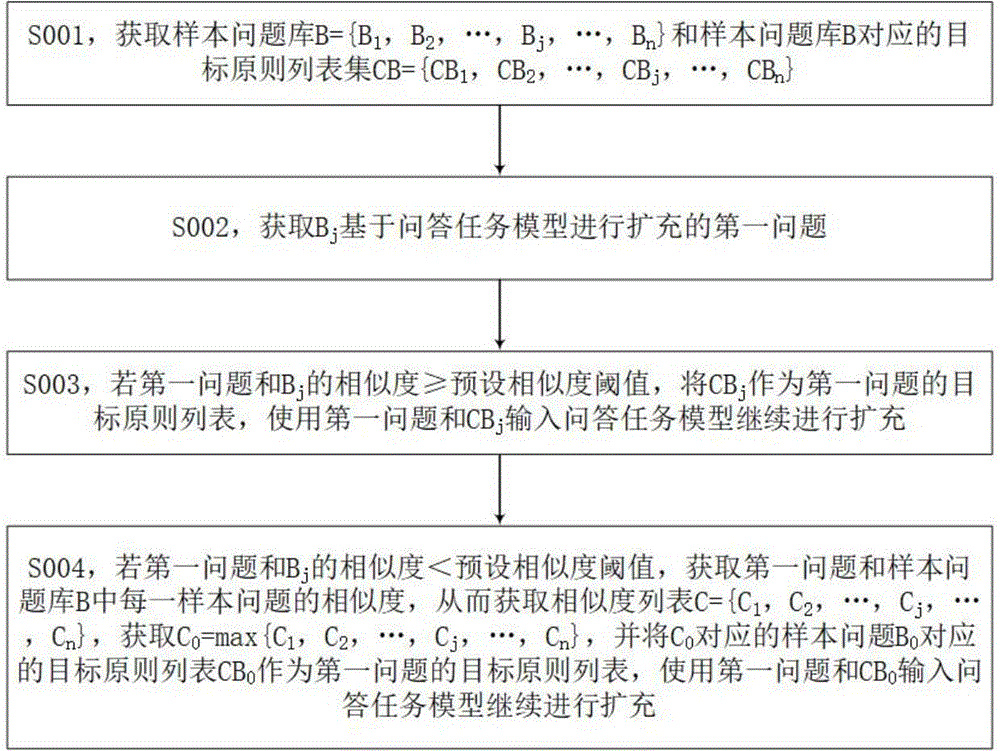
S001,获取样本问题库B={B
S002,获取B
S003,若第一问题和B
S004,若第一问题和B
一种非瞬时性计算机可读存储介质,所述存储介质中存储有至少一条指令或至少一段程序,所述至少一条指令或所述至少一段程序由处理器加载并执行以实现如上述的基于问答任务模型进行问题扩充的方法。
本发明至少具有以下有益效果:
综上,获取样本问题库和每一样本问题对应的目标原则列表,基于任一样本问题和问答任务模型进行扩充,获取扩充的第一问题,若第一问题和该样本问题的相似度不小于预设相似度阈值,将该样本问题对应的目标原则列表作为第一问题对应的目标原则列表,并使用第一问题和第一问题对应的目标原则列表输入问答任务模型继续进行扩充;若第一问题和该样本问题的相似度小于预设相似度阈值,计算第一问题和样本问题库中所有样本问题的相似度,将最大的相似度对应的样本问题对应的目标原则列表作为第一问题对应的目标原则列表,通过获取样本问题的目标原则列表的对应关系,并获取基于样本问题进行扩充的第一问题,通过相似度判断,扩充出的第一问题可以继承该样本问题或其它样本问题的目标原则列表,使得扩充出的第一问题继续进行扩充时有合理的扩充规则,使得问答任务模型能够输出相对高质量的扩充问题。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的基于问答任务模型进行问题扩充的方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种基于问答任务模型进行问题扩充的方法,如图1所示,所述方法包括如下步骤:
S001,获取样本问题库B={B
具体的,任一样本问题B
S002,获取B
具体的,S002,获取B
S021,基于样本问题B
S022,将第五指令输入问答任务模型,获取第一问题。
具体的,在本发明一个示例中,所述第五指令为:根据样本问题B
S003,若第一问题和B
具体的,本领域人员知晓,现有技术中任何一种计算两个语句的相似度的方法均属于本发明保护范围,此处不再赘述。
可选的,所述预设相似度阈值F
具体的,在S003中,使用第一问题和CB
S031,基于样本问题B
S032,将第四指令输入问答任务模型,获取新问题。
进一步的,S003还包括:
S005,若第一问题和B
具体的,可以从CB
S004,若第一问题和B
具体的,S004中,使用第一问题和CB
S041,基于样本问题B
S042,将第六指令输入问答任务模型,获取扩充问题。
综上,获取样本问题库和每一样本问题对应的目标原则列表,基于任一样本问题和问答任务模型进行扩充,获取扩充的第一问题,若第一问题和该样本问题的相似度不小于预设相似度阈值,将该样本问题对应的目标原则列表作为第一问题对应的目标原则列表,并使用第一问题和第一问题对应的目标原则列表输入问答任务模型继续进行扩充;若第一问题和该样本问题的相似度小于预设相似度阈值,计算第一问题和样本问题库中所有样本问题的相似度,将最大的相似度对应的样本问题对应的目标原则列表作为第一问题对应的目标原则列表,通过获取样本问题的目标原则列表的对应关系,并获取基于样本问题进行扩充的第一问题,通过相似度判断,扩充出的第一问题可以继承该样本问题或其它样本问题的目标原则列表,使得扩充出的第一问题继续进行扩充时有合理的扩充规则,使得问答任务模型能够输出相对高质量的扩充问题。
具体的,样本问题B
S100,获取原则库A={A
具体的,所述原则是对样本问题进行问题扩充时的所遵循的预设准则。
S200,对样本问题B
S300,基于样本问题B
S400,基于第二问题,生成第二指令,将第二指令输入问答任务模型,获取回答语句,其中,所述第二指令为:根据第二问题生成回答语句。
S500,基于第二问题和回答语句,生成第三指令,将第三指令输入问答任务模型,获取第一得分,若第一得分小于预设准确度阈值,执行S300,更新第二问题;否则,执行S600;
其中,所述第三指令为:对于第二问题和回答语句,评估回答语句和第二问题是否匹配,用以下5分制进行评分:{分值g:分值g对应的描述语句;},g=1,2,3,4,5。
具体的,本领域技术人员知晓,可以使用5分制进行评分,也可以使用6分制等进行评分,在本发明一个示例性说明中,所述第三指令为:
对于第二问题和回答语句,评估回答语句是否和第二问题是否匹配,用以下5分制进行评分:
{1:这意味着回答是不完整的,模糊的,或者不是用户要求的,例如,一些内容缺失,或者看起来像来自论坛的回答,或者包含其它不相关的信息;
2:这意味着转换程序能够解决用户提出的大部分问题。它并不直接解决用户的问题。例如,它只提供了一个高层次的方法论,而不是用户问题的精确解答办法;
3:它解决了用户的所有基本要求。它是完整和独立的缺点是,响应不是从一个人工智能助理的角度写的,而是从其他人的角度写的;
4:它为用户的问题或指令提供了完整、清晰和全面的答复它组织得很好,自成体系,而且写得很有帮助.它有很小的改进余地,例如更简洁和更有重点;
5:答案提供了高质量的内容,展示了该领域的专家知识,写得很好,逻辑性强,易于遵循,引人入胜,富有洞察力;}。
基于S100-S500,对样本问题B
S600,获取样本问题B
S700,将样本问题B
其中,所述分类模型用于判断问答任务模型对样本问题B
具体的,可以理解为,所述第三得分代表了第二问题相对于样本问题的难易程度,希望问答任务模型能够输出更加困难、少见的样本。
具体的,所述预设扩充阈值>1.5。
综上,获取原则库,对样本问题B
进一步的,S200中,对样本问题B
S210,获取样本问题B
具体的,可以人工基于样本问题的领域词语、样本问题的关键词和原则的关键词对样本问题和原则之间的关联度进行打分,作为关联度分值。可以理解为,样本问题包含的领域词语越多,对应的关联度分值越高;符合第一预设词表的样本问题的关键词越多,对应的关联度分值越高;符合第二预设词表的原则的关键词越多,对应的关联度分值越高;所述第一预设词表和第二预设词表根据实际需求确定。例如,本发明想要生成困难、少见的扩充问题,所述第二预设词表包括:困难。
具体的,本领域技术人员知晓,现有技术中任何一种确定文本关键词的方法均属于本发明保护范围,此处不再赘述。
S220,若E
综上,获取样本问题B
本发明的实施例还提供了一种非瞬时性计算机可读存储介质,该存储介质可设置于电子设备之中以保存用于实现方法实施例中一种方法相关的至少一条指令或至少一段程序,该至少一条指令或该至少一段程序由该处理器加载并执行以实现上述实施例提供的方法。
本发明的实施例还提供了一种电子设备,包括处理器和前述的非瞬时性计算机可读存储介质。
本发明的实施例还提供一种计算机程序产品,其包括程序代码,当所述程序产品在电子设备上运行时,所述程序代码用于使该电子设备执行本说明书上述描述的根据本发明各种示例性实施方式的方法中的步骤。
虽然已经通过示例对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员还应理解,可以对实施例进行多种修改而不脱离本发明的范围和精神。本发明公开的范围由所附权利要求来限定。
- 一种基于存储介质的固件自动升级方法及其存储介质
- 一种对话问答方法、装置、设备及存储介质
- 一种问答方法、装置、电子设备及存储介质
- 一种防御病毒对文件进行操作的方法、装置和存储介质
- 一种基于NAND FLASH的数据存储方法、终端设备及存储介质
- 一种基于多任务模型进行文本处理的方法、装置、计算机装置及计算机可读取存储介质
- 一种基于关联问题对用户问答进行引导的方法及系统