一种可适应不同混响环境的深度优化麦克风阵列增强方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于语音增强技术领域,具体涉及一种可适应不同混响环境的深度优化麦克风阵列增强方法。
背景技术
随着万物互联时代的到来,语音成为智能设备的重要交互入口。麦克风阵列技术可充分利用阵列语音输入从时域、频域、空域等三个方面对语音信号进行优化,提高语音质量,为实时通信、语音交互等应用提供语音质量保障,近年来得到广泛的研究和应用。
在不同场景下麦克风阵列语音增强实际应用中,实际室内环境由于空间尺寸、材质、环境噪声和墙壁等障碍物的存在,语音会受到不同程度的干扰,因此麦克风阵列接收到的语音信号常常含有噪声和混响,其中,噪声包含外界环境噪声和其他说话人的干扰声;混响是由于声源发出的语音信号向四周扩散,经过墙壁等障碍物反射引起的多径效应,最终在阵列接收端叠加产生。包含噪声和混响的语音信号会大大影响语音的质量。传统麦克风阵列算法更多的是基于阵列的物理结构来进行设计,在理想环境中表现得较好,在实际表现中,良好环境下能够使用,但是在复杂环境下算法性能急剧下降,因此这类传统算法非常受限于环境。
Khalil F等公开的滤波累加波束形成(Filter-and-Sum Beamforming,FSB)算法就是将麦克风接收的多通道信号通过FIR滤波器组后加权求和输出来进行语音增强,FIR滤波器组可以通过最优逼近思想来训练出来,其中最小二乘(Least-Squares,LS)就是最经典的最优化方法。固定波束形成算法原理简单,计算复杂度低,易于硬件实时实现,但是其不具备自适应环境变化的能力。
Parchami M等提出一种线性加权预测语音去混响方法(Weighted PredictionError,WPE)。通过使用多个先前帧信号进行加权来预测当前帧信号中的混响分量,其核心问题是确定加权系数。然而,受限于相对巨大的计算负担,WPE在硬件端的效果比服务器端的效果更差
Kinoshita等提出一种基于神经网络频谱估计的去混响算法(DNN),对多通道的带噪语音进行语音特征提取后作为神经网络的输入,并以当前帧的混响幅度谱与估计的当前帧幅度谱的差作为神经网络输出,当前帧纯净语音的幅度谱为参考目标特征。
然而,尽管传统基于学习的去混响方法能够在网络经过充分训练之后达到较满意的性能,但是在多样化应用场景下不可避免遇到与训练数据环境不同的失配环境,此时由于其混响相关信息不包含在训练数据中,麦克风阵列语音增强性能趋于恶化。这个问题的直接解决方案是扩大数据样本,以覆盖尽可能多的环境,然而这对于实际应用来说可能是非常困难、或者说几乎不可能的。
发明内容
针对上述影响麦克风阵列语音增强实际场景应用的瓶颈问题,本发明第一方面提供一种可适应不同混响环境的深度优化麦克风阵列增强方法,包括步骤:获取麦克风阵列的输入信号,获取波束形成信号,并提取环境混响特征;将环境混响特征输入训练好的混响感知模型,获得混响适配向量;基于混响适配向量,对波束形成信号进行反混响处理,获得增强信号。
优选地,基于混响适配向量,对波束形成信号进行反混响处理包括步骤:将混响适配向量与环境混响特征进行卷积处理,获得后置滤波器系数;将后置滤波器系数于波束形成信号进行卷积处理,获得增强信号。
优选地,方法还包括:将波束形成信号与环境混响特征同时输入训练好的混响感知模型。
优选地,混响感知模型基于LSTM结构构建。
优选地,混响感知模型包括单层LSTM结构和两层全连接层结构。
优选地,混响感知模型的训练过程中,结合加权向量构建损失函数,加权向量用于补偿后置滤波处理的高频损失。
优选地,提取环境混响特征具体包括:将输入信号和波束形成信号进行互相关运算,获得环境混响特征。
本发明第二方面提供一种可适应不同混响环境的深度优化麦克风阵列增强装置,包括:语音输入模块,配置用于获取麦克风阵列的输入信号,获取波束形成信号,并提取环境混响特征;混响感知模块,配置用于将环境混响特征输入训练好的混响感知模型,获得混响适配向量;反混响模块,配置用于基于混响适配向量,对波束形成信号进行反混响处理,获得增强信号。
优选地,反混响模块包括:后置滤波器,配置用于将混响适配向量与环境混响特征进行卷积处理,获得后置滤波器系数;信号增强单元,配置用于将后置滤波器系数于波束形成信号进行卷积处理,获得增强信号。
优选地,混响感知模块还配置用于将波束形成信号与环境混响特征同时输入训练好的混响感知模型。
本发明公开了一种可适应不同混响环境的深度优化麦克风阵列语音增强(reverberation aware network,RAN)方法,该方法可通过实时获取混响环境特征,在深度学习神经网络框架下进行混响适配处理,并通过网络训练输出的适配向量与实时获取的混响环境特性组合后进行抗混响处理;同时,与传统深度学习优化网络方法采用网络本身进行抗混响处理不同,本发明所公开的方法采用以网络输出抗混响滤波器系数的方式进行抗混响处理,在具备不同混响环境适应能力的同时,显著降低了硬件侧信号运算的复杂度,方便了实际应用场景中的硬件工程实现。
附图说明
为了便于描述,附图中仅示出了与有关发明相关的部分。
图1为本发明一具体实施例中麦克风阵列语音信号增强方法步骤示意图;
图2为本发明一具体实施例中环境的近似混响特征提取过程示意图;
图3为本发明一具体实施例中RAN模型RGV的输出特征示意图;
图4为本发明另一具体实施例中麦克风阵列语音增强方法的处理流程图;
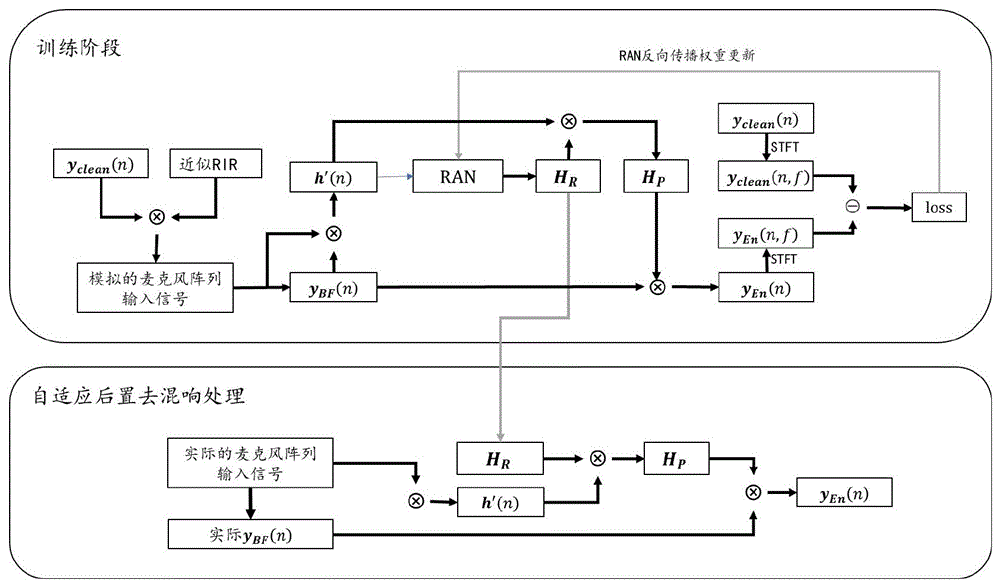
图5为本发明另一具体实施例中RAN模型的结构和训练方法示意图;
图6为本发明另一具体实施例中RAN模型的LSTM单元的内部结构;
图7为本发明另一具体实施例中RAN网络的训练和测试过程示意图;
图8为本发明另一具体实施例中麦克风阵列语音信号增强装置的结构示意图;
图9为本发明另一具体实施例中不同算法的PESQ得分对比图;
图10为本发明另一具体实施例中原始语音的时频图以及使用不同算法获得的去混响结果对比图(RT
图11为本发明另一具体实施例中原始语音的时频图以及使用不同算法获得的去混响结果对比图(RT
具体实施方式
下面结合附图和实施例对本申请作进一步的详细说明。此处所描述的具体实施例仅用于解释相关发明,而非对该发明的限定。在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
图1为本发明一具体实施例中麦克风阵列语音信号增强方法步骤示意图,具体包括步骤:
S1,获取麦克风阵列的输入信号,获取波束形成信号,并提取环境混响特征。
具体地,所提取的环境混响特征为以近似房间冲激响应(Approximate RoomImpulse Response,ARIR)的形式提取的环境的近似混响特征。图2为本实施例中环境的近似混响特征提取过程示意图,通过将不同混响环境下原始麦克风阵列输入信号(originalsignal)与经麦克风阵列波束形成输出的增强信号(beamformed signal)进行互相关运算,ARIR可以表示为:
其中,y
S2,将环境混响特征输入训练好的混响感知模型(Reverberation awarenetwork,RAN),获得混响适配向量。
考虑到语音是一种随机信号,虽然ARIR是通过混响信号与其波束形成输出之间的互相关来计算的,但它无法包含实际房间冲激响应的全面信息。为了在模型训练中通过泛化处理同时补偿语音不可控性和环境多样性缺陷,本实施例定义房间冲激响应泛化向量(RIR generalization vector,RGV)H
S3,基于混响适配向量,对波束形成信号进行反混响处理,获得增强信号。
在优选实施例中,与直接采用数据进行DNN模型训练后进行去混响处理的传统DNN方法不同,本实施例直接利用训练模型输出的H
H
并将该后置滤波器H
y
图4为本实施例中麦克风阵列语音增强方法的处理流程图。从图4可见,本实施例中RAN方法分为两个步骤,即RAN网络训练(RAN network training)和自适应后置去混响处理(post de-reverberation processing)。在训练阶段,通过输入实时获得的混响特征ARIR和波束形成信号训练RAN模型,从而获得房间冲激响应泛化向量H
图5为另一具体实施例中RAN模型的结构和训练方法示意图。本实施例中,RAN模型在网络模型上采用本领域公知的单向LSTM神经网络模型,LSTM不仅可以处理某些短期依赖,还可以处理长期依赖。对于LSTM网络,除了单层LSTM层,还有两层全连接层共同组合成神经网络的主要结构。
图6为本实施例中LSTM单元的内部结构。如图6所示,LSTM神经网络由三个门组成,即输入门、遗忘门和输出门。对于输出门i
i
遗忘门f
f
添加定义概要信息
可以得到输出门o
o
最后的LSTM传输链包含长期记忆c
h
用h
图7为另一优选实施例中RAN网络的训练和测试过程示意图。本实施例中,结合加权向量构建损失函数,模型训练的损失函数l可表示为:
其中N
图8为另一具体实施例中麦克风阵列语音信号增强装置800的结构示意图,装置包括:
语音输入模块801,配置用于获取麦克风阵列的输入信号,获取波束形成信号,并提取环境混响特征;
混响感知模块802,配置用于将环境混响特征输入训练好的混响感知模型,获得混响适配向量;
反混响模块803,配置用于基于混响适配向量,对波束形成信号进行反混响处理,获得增强信号。
上述实施例中描述的各种组件、模块或单元是为了强调经配置以执行所揭示的技术的装置的功能方面,并不限制于需要通过不同硬件单元实现。
在一具体实施例中,混响感知模型的训练过程通常通过服务器或计算机设备执行;在实际应用中,通过服务器、计算机设备或嵌入式系统等形式实现环境中语音信号的增强。
另一具体实施例中,基于混响场景对本发明提供的麦克风阵列语音信号增强方法进行实验分析。本实施例中,原始纯净语料库采用清华大学语音与语言技术中心开放式中文语音数据库THCHS-30(Wang D,Zhang X.THCHS-30:A Free Chinese Speech Corpus[J].Computer Science,2015),该数据集于安静室内环境下录制,为采样率16kHz单通道信号,总语音数达13388句,总语音时长超过30小时,数据集分类如下表1所示:
表1 THCHS-30数据集
基于IMAGE混响模型方法,使用RIR_generator工具来构造不同混响程度的房间脉冲响应,通过将上述原始纯净语料库中的语音通过与房间脉冲响应进行卷积可以得到不同混响程度的语音信号来模拟麦克风阵列多通道原始接收信号。将空间分为24个子空间,以0°方向为例,生成混响时间为0.6s、0.8s和1s的三种房间脉冲响应,训练集大小为30,000,累计时长75h。
进一步地,h'(n),H
在具体的实施例中,仿真设置采用直径为0.07m的六元均匀圆形麦克风阵列,采样率为16kHz。在模拟生成的房间中央放置一个六元麦克风阵列,扬声器随机放置在房间的多个位置,以模拟声源在不同方向的入射。
为了进行混响抑制性能比较和评估,选择FSB、WPE算法和DNN-WPE(以下简写为DNN)作为对比方法,选择语音PESQ评估得分以及语音识别率来作为去混响后语音质量的评估指标。语音识别率采用Wang D等人在文献中所应用的识别软件。
本实施例的性能评估对比中,对于需要模型学习的DNN-WPE及本发明RAN算法,在环境匹配的情况下,模型训练和测试的数据集来自同一个房间,而在环境不匹配的情况下,模型训练与测试的数据集中来自不同的房间。即,在实施例性能分析比较中,算法后加match的表示模型训练集与当前测试集混响匹配,加mismatch的表示不匹配。
图9为本实施例中不同算法的PESQ得分。虽然FSB和WPE这两种传统算法都产生了明显的PESQ增强,但在环境匹配的条件下,DNN、RAN这两种深度学习优化类算法在所有三个混响级别上都表现出更好的性能。然而,在环境不匹配的情况下,算法的性能都会下降。具体来说,DNN表现出显著的PESQ分数损失,本发明所公开的RAN方法相对于环境匹配场景的PESQ下降小得多。
图10和图11为原始语音的时频图以及使用不同算法获得的去混响结果,其中混响时间分别为RT
从本实施例不同算法评估与比较结果可看出,本发明所公开的RAN方法无论在强弱混响条件下效果均比较稳定,可改善不同混响环境下的麦克风阵列语音增强性能。
尽管结合优选实施方案具体展示和介绍了本申请的内容,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本申请的精神和范围内,没有做出创造性劳动的情况下,在形式上和细节上对本申请做出的各种变化,均为本申请的保护范围。
- 一种自适应抗混响的麦克风阵列语音增强方法及其系统
- 基于混响环境下麦克风阵列波束形成方法