一种基于AIGC的视频生成系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及电数字数据处理领域,具体涉及一种基于AIGC的视频生成系统。
背景技术
AIGC,即人工智能生成内容,是一种将人工智能技术应用于创造内容的领域。随着深度学习和生成模型的不断发展,AIGC已经在多个领域取得了显著的进展,从图像生成到音乐创作,再到文本写作和视频生成,都展现出了巨大的潜力,在AIGC技术的技术上,能够大大降低许多工作的难度,而视频制作便是其中一种工作,现需要一种系统在结合AIGC技术的基础上来提高视频制作的效率。
背景技术的前述论述仅意图便于理解本发明。此论述并不认可或承认提及的材料中的任一种公共常识的一部分。
现在已经开发出了很多视频制作系统,经过大量的检索与参考,发现现有的视频制作系统有如公开号为CN113784167B所公开的系统,这些系统方法一般包括:使用行为树编辑器基于3D场景中已有的各个对象所需的表演内容及互动内容编辑行为树,并输出对应的行为树数据,互动内容为行为树的条件节点;在预渲染主机中输入行为树数据并拆解为条件节点下的每一段完整的行为树数据来进行3D实时渲染和视频录制,得到多个视频文件;将转变为视频文件的行为树数据简化为一个“播放视频”的行为,得到简化后的行为树数据;将简化后的行为树数据和视频文件输入互动视频播放器。但该系统仍是使用传统的方式来制作3D视频,效率较低,难度较高,对制作者有技术要求。
发明内容
本发明的目的在于,针对所存在的不足,提出了一种基于AIGC的视频生成系统。
本发明采用如下技术方案:
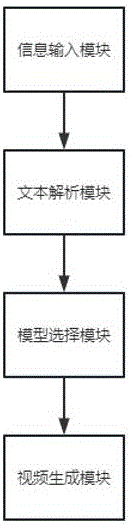
一种基于AIGC的视频生成系统,包括信息输入模块、文本解析模块、模型选择模块和视频生成模块;
所述信息输入模块用于输入用户的需求信息,所述文本解析模块用于对需求信息进行内容解析,所述模型选择模块用于选择视频的基础模型,所述视频生成模块用于对基础模型进行处理得到完整视频;
所述文本解析模块包括分类拆解单元、组合单元和转换单元,所述分类拆解单元用于将文字信息拆解成多个关键词并将关键词分类,所述组合单元基于描述性关键词的位置将分类后的关键词进行组合生成三个词包,所述转换单元用于将词包中的关键词转换成对应的编码形成编码包;
所述模型选择模块包括模型库存储单元和模型匹配单元,所述模型库存储单元用于保存背景模型和活动主体模型,所述模型匹配单元基于编码包中的编码信息匹得到对应的背景模型和活动主体模型;
所述视频生成模块包括模型放置单元、动作单元和拍摄单元,所述模型放置单元用于放置背景模型和活动主体模型,所述动作单元根据事件编码包信息使活动主体模型完成对应的动作,所述拍摄单元用于拍摄活动主体模型在背景模型中完成动作时的画面信息得到视频数据;
进一步的,所述分类拆解单元包括关键词训练处理器、关键词识别处理器和关键词记录处理器,所述关键词训练处理器用于对大量文本进行训练得到关键词的识别参数,所述识别参数被发送至所述关键词识别处理器,所述关键词识别处理器基于识别参数对文字信息中的关键词进行识别,每识别到一个关键词就将该关键词的类别和位置信息以及该关键词本身发送给所述关键词记录处理器,所述关键词记录处理器用于记录接收的关键词信息;
进一步的,所述模型匹配单元包括编码处理器、注释检索处理器和匹配计算处理器,所述编码处理器用于将接收的编码包进行处理,所述注释检索处理器根据处理结果缩小注释信息的检索范围,所述匹配计算处理器用于将注释信息与编码包进行匹配计算;
进一步的,所述匹配计算处理器根据下式计算出检索出的模型注释信息与编码包之间的匹配度Pm:
;
其中,Ic(i)表示注释信息中含有第i个主体编码的指示数,含有时指示数为1,不含时指示数为0,
所述匹配计算处理器选择匹配度最大的模型注释信息,并根据对应的存储地址从模型寄存器中获取模型并发送给模型放置单元或动作单元;
进一步的,所述视频生成模块生成视频的过程包括如下步骤:
S31、所述模型放置单元将背景模型和活动主体模型进行初始化放置;
S32、所述动作单元根据事件编码包拆解得到多个动作指令;
S33、所述模型放置单元基于动作指令对活动主体模型进行动作处理,得到活动主体模型在每个动作指令下的结束位置,由初始位置和结束位置按序构成节点位置;
S34、所述模型放置单元根据相邻两个节点位置计算出时长帧数;
S35、所述模型放置单元根据时长帧数计算出相同数量的补帧位置;
S36、所述模型放置单元根据节点位置、若干个补帧位置的顺序对活动主体模型进行变化,每变化依次位置向所述拍摄单元发送信号,所述拍摄单元接收到信号后拍摄一帧画面数据;
S37、所述拍摄单元将所有画面数据组合形成视频数据。
本发明所取得的有益效果是:
本系统对需求信息进行智能分析,将分析结果分为模型结果和动作结果,基于模型结果在模型库中筛选出合适的模型,基于动作结果对模型实时动作指令,然后在虚拟空间中呈现模型及模型动作,并对整个动作过程进行拍摄实现视频的生成,整个过程用户仅需要输入文本信息即可,无需复杂操作,降低了视频制作的难度,提高了视频制作的效率。
为使能更进一步了解本发明的特征及技术内容,请参阅以下有关本发明的详细说明与附图,然而所提供的附图仅用于提供参考与说明,并非用来对本发明加以限制。
附图说明
图1为本发明整体结构框架示意图;
图2为本发明文本解析模块构成示意图;
图3为本发明视频生成模块构成示意图;
图4为本发明模型匹配单元构成示意图;
图5为本发明模型放置单元构成示意图。
具体实施方式
以下是通过特定的具体实施例来说明本发明的实施方式,本领域技术人员可由本说明书所公开的内容了解本发明的优点与效果。本发明可通过其他不同的具体实施例加以施行或应用,本说明书中的各项细节也可基于不同观点与应用,在不悖离本发明的精神下进行各种修饰与变更。另外,本发明的附图仅为简单示意说明,并非依实际尺寸的描绘,事先声明。以下的实施方式将进一步详细说明本发明的相关技术内容,但所公开的内容并非用以限制本发明的保护范围。
实施例一:本实施例提供了一种基于AIGC的视频生成系统,结合图1,包括信息输入模块、文本解析模块、模型选择模块和视频生成模块;
所述信息输入模块用于输入用户的需求信息,所述文本解析模块用于对需求信息进行内容解析,所述模型选择模块用于选择视频的基础模型,所述视频生成模块用于对基础模型进行处理得到完整视频;
所述文本解析模块包括分类拆解单元、组合单元和转换单元,所述分类拆解单元用于将文字信息拆解成多个关键词并将关键词分类,所述组合单元基于描述性关键词的位置将分类后的关键词进行组合生成三个词包,所述转换单元用于将词包中的关键词转换成对应的编码形成编码包;
所述模型选择模块包括模型库存储单元和模型匹配单元,所述模型库存储单元用于保存背景模型和活动主体模型,所述模型匹配单元基于编码包中的编码信息匹得到对应的背景模型和活动主体模型;
所述视频生成模块包括模型放置单元、动作单元和拍摄单元,所述模型放置单元用于放置背景模型和活动主体模型,所述动作单元根据事件编码包信息使活动主体模型完成对应的动作,所述拍摄单元用于拍摄活动主体模型在背景模型中完成动作时的画面信息得到视频数据;
所述分类拆解单元包括关键词训练处理器、关键词识别处理器和关键词记录处理器,所述关键词训练处理器用于对大量文本进行训练得到关键词的识别参数,所述识别参数被发送至所述关键词识别处理器,所述关键词识别处理器基于识别参数对文字信息中的关键词进行识别,每识别到一个关键词就将该关键词的类别和位置信息以及该关键词本身发送给所述关键词记录处理器,所述关键词记录处理器用于记录接收的关键词信息;
所述模型匹配单元包括编码处理器、注释检索处理器和匹配计算处理器,所述编码处理器用于将接收的编码包进行处理,所述注释检索处理器根据处理结果缩小注释信息的检索范围,所述匹配计算处理器用于将注释信息与编码包进行匹配计算;
所述匹配计算处理器根据下式计算出检索出的模型注释信息与编码包之间的匹配度Pm:
;
其中,Ic(i)表示注释信息中含有第i个主体编码的指示数,含有时指示数为1,不含时指示数为0,
所述匹配计算处理器选择匹配度最大的模型注释信息,并根据对应的存储地址从模型寄存器中获取模型并发送给模型放置单元或动作单元;
所述视频生成模块生成视频的过程包括如下步骤:
S31、所述模型放置单元将背景模型和活动主体模型进行初始化放置;
S32、所述动作单元根据事件编码包拆解得到多个动作指令;
S33、所述模型放置单元基于动作指令对活动主体模型进行动作处理,得到活动主体模型在每个动作指令下的结束位置,由初始位置和结束位置按序构成节点位置;
S34、所述模型放置单元根据相邻两个节点位置计算出时长帧数;
S35、所述模型放置单元根据时长帧数计算出相同数量的补帧位置;
S36、所述模型放置单元根据节点位置、若干个补帧位置的顺序对活动主体模型进行变化,每变化依次位置向所述拍摄单元发送信号,所述拍摄单元接收到信号后拍摄一帧画面数据;
S37、所述拍摄单元将所有画面数据组合形成视频数据。
实施例二:本实施例包含了实施例一中的全部内容,提供了一种基于AIGC的视频生成系统,包括信息输入模块、文本解析模块、模型选择模块和视频生成模块;
所述信息输入模块用于输入用户的需求信息,所述文本解析模块用于对需求信息进行内容解析,所述模型选择模块用于选择视频的基础模型,所述视频生成模块用于对基础模型进行处理得到完整视频;
所述信息输入模块包括交互显示单元和信息采集单元,所述交互显示单元用于显示窗口信息并通过输入设备在窗口中输入文字信息,所述信息采集单元用于采集窗口中的文字信息并发送给所述文本解析模块;
结合图2,所述文本解析模块包括分类拆解单元、组合单元和转换单元,所述分类拆解单元用于将文字信息拆解成多个关键词并将关键词分为描述性关键词、静态主体关键词、动态主体关键词和事件关键词,所述组合单元基于描述性关键词的位置将描述性关键词编码分别与静态主体关键词、动态主体关键词和事件关键词进行组合生成三个词包,所述转换单元用于将词包中的关键词转换成对应的编码形成编码包,分别称为背景编码包、活动编码包和事件编码包,所述背景编码包和活动编码包发送至所述模型选择模块,所述事件编码包发送给所述视频生成模块;
所述模型选择模块包括模型库存储单元和模型匹配单元,所述模型库存储单元用于保存背景模型和活动主体模型,所述模型匹配单元基于编码包中的编码信息匹得到对应的背景模型和活动主体模型,匹配得到的模型数据被发送至所述视频生成模块;
结合图3,所述视频生成模块包括模型放置单元、动作单元和拍摄单元,所述模型放置单元用于放置背景模型和活动主体模型,所述动作单元根据事件编码包信息使活动主体模型完成对应的动作,所述拍摄单元用于拍摄活动主体模型在背景模型中完成动作时画面信息得到视频数据;
所述分类拆解单元包括关键词训练处理器、关键词识别处理器和关键词记录处理器,所述关键词训练处理器基于AIGC技术对大量文本进行训练得到关键词的识别参数,所述识别参数被发送至所述关键词识别处理器,所述关键词识别处理器基于识别参数对文字信息中的关键词进行识别,每识别到一个关键词就将该关键词的类别和位置信息以及该关键词本身发送给所述关键词记录处理器,所述关键词记录处理器用于记录接收的关键词信息;
所述组合单元对关键词进行组合的过程包括如下步骤:
S1、将所述关键词记录处理器中的描述性关键词选择作为第一目标关键词,其余的关键词作为第二目标关键词,为每个第二目标关键词建立一个描述包;
S2、选择一个第一目标关键词,分别与其余的第二目标关键词计算出组合指数Cb:
;
其中,Np1为第一目标关键词的位置序号,Np2为第二目标关键词的位置序号,
S3、将该第一目标关键词添加进组合指数最小的第二目标关键词的描述包中;
S4、重复步骤S2和步骤S3,直至所有的第一目标关键词添加进描述包中;
S5、将所有静态主体关键词以及描述包整合成一个词包,将所有动态主体关键词以及描述包整合成一个词包,将所有事件关键词以及描述包整合成一个词包;
所述转换单元包括编码映射寄存器和转换处理器,所述编码映射寄存器用于保存关键词与编码的映射关系,一个编码能够映射多个关键词,所述转换处理器根据映射关系将词包中的关键词转换成对应的编码;
所述模型库存储单元包括模型寄存器和模型注释寄存器,所述模型寄存器将模型分为背景模型和活动主体模型,以单个模型为单位进行保存,所述模型注释寄存器用于记录每个模型的注释信息以及对应模型的类型以及在模型寄存器中的存储地址;
结合图4,所述模型匹配单元包括编码处理器、注释检索处理器和匹配计算处理器,所述编码处理器用于将接收的编码包进行处理,所述注释检索处理器根据处理结果缩小注释信息的检索范围,所述匹配计算处理器用于将注释信息与编码包进行匹配计算;
编码包中的编码分为主体编码和描述编码,所述主体编码指非描述包中的关键词转换成的编码,所述描述编码指描述包中的关键词转换成的编码,所述主体编码从首位到末位能够依次体现分类的细致程度;
所述编码处理器对编码包中主体编码进行处理的过程包括如下步骤:
S21、获取编码包中的主体编码;
S22、选择差值最小的两个主体编码,将这两个主体编码分别记为Cd(1)和Cd(2),其均值记为Cd’;
S23、将剩余的主体编码根据与Cd’差值的绝对值从小到大排序,分别记为Cd(3)、Cd(4)、...、Cd(m),m为编码包中主体编码的数量;
S24、根据Cd(1)和Cd(2)确定检索编码集,所述检索编码集中包含检索编码,所述检索编码与主体编码具有相同的位数且末位是连续的多个0;所述检索编码Sc满足下述关系式:
;
其中,n为检索编码末位连续0的个数,Ys为检索阈值;
S25、根据下式计算出每个检索编码的检索指数Ps:
;
其中,
S26、将检索指数最小的检索编码发送给所述注释检索处理器;
所述匹配计算处理器根据下式计算出检索出的模型注释信息与编码包之间的匹配度Pm:
;
其中,Ic(i)表示注释信息中含有第i个主体编码的指示数,含有时指示数为1,不含时指示数为0,
所述匹配计算处理器选择匹配度最大的模型注释信息,并根据对应的存储地址从模型寄存器中获取模型并发送给模型放置单元或动作单元;
所述视频生成模块生成视频的过程包括如下步骤:
S31、所述模型放置单元将背景模型和活动主体模型进行初始化放置;
S32、所述动作单元根据事件编码包拆解得到多个动作指令;
S33、所述模型放置单元基于动作指令对活动主体模型进行动作处理,得到活动主体模型在每个动作指令下的结束位置,由初始位置和结束位置按序构成节点位置;
S34、所述模型放置单元根据相邻两个节点位置计算出时长帧数;
S35、所述模型放置单元根据时长帧数计算出相同数量的补帧位置;
S36、所述模型放置单元根据节点位置、若干个补帧位置的顺序对活动主体模型进行变化,每变化依次位置向所述拍摄单元发送信号,所述拍摄单元接收到信号后拍摄一帧画面数据;
S37、所述拍摄单元将所有画面数据组合形成视频数据;
结合图5,所述模型放置单元包括模型展示处理器、动作处理器和位置处理器,所述模型展示处理器用于提供一个虚拟空间放置模型,所述动作处理器用于执行动作指令使模型产生动作,所述位置处理器用于记录模型的位置信息以及根据位置信息进行计算处理;
所述位置处理器根据下式计算出时长帧数T:
;
其中,L为模型在两个节点位置的最大移动距离,v为动作指令的单帧移动速度;
所述位置处理器根据下式计算出补帧位置
;
;
;
其中,
以上所公开的内容仅为本发明的优选可行实施例,并非因此局限本发明的保护范围,所以凡是运用本发明说明书及附图内容所做的等效技术变化,均包含于本发明的保护范围内,此外,随着技术发展其中的元素可以更新的。
- 一种视频在线生成系统及其生成方法
- 一种基于AIGC技术的人物艺术形象生成系统
- 一种基于AIGC技术的人物艺术形象生成系统