编解码方法及相关设备、存储介质
文献发布时间:2024-04-18 19:58:26
本公开实施例涉及但不限于编解码技术,尤其涉及一种编解码方法及相关设备、存储介质。
三维点云数据已经开始普及到各个领域,例如虚拟/增强现实、机器人、地理信息系统、医学领域等。随着三维点云数据的发展和三维点云数据扫描设备(比如激光雷达,Kinect体感相机等)的基准度和速率的不断提升,人们可以准确地获取物体表面的大量点云数据,往往一个场景下的点云数据就可以包括几十万个点。数量如此庞大的点云数据也给计算机的存储和传输带来了挑战。
点云压缩主要分为几何压缩和属性压缩,其中针对属性压缩,国际标准组织(Moving Picture Experts Group,MGEP所提供的测试平台TMC13(Test Model for Category1&3)中描述的点云属性压缩框架包括基于多细节层次LOD(Level of Detail)的升降变换(LiftingTransform)策略,以及基于LOD的预测变换(Predicting Transform)策略等。还有AVS(Audio Video coding Standard)点云压缩工作组所提供的测试平台PCEM中描述的点云属性压缩方法,等等。
但是点云属性压缩方案仍有很多可改进的余地。
发明概述
以下是对本文详细描述的主题的概述。本概述并非是为了限制权利要求的保护范围。
第一方面,本公开实施例提供了一种编码方法,包括:
确定待编码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
当所述第一参数小于阈值时,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
对量化后的所述残差值进行编码。
第二方面,本公开实施例提供了一种解码方法,包括:
确定待解码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
当所述第一参数小于阈值时,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
解析码流,获得所述当前点的第一属性的残差值;
计算所述残差值反量化后与所述预测值相加的和值,作为所述当前点的第一属性的重建值。
第三方面,本公开实施例还提供了另一种编码方法,包括:
一种编码方法,包括:
确定待编码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
当所述第一参数小于阈值时,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
对量化后的所述残差值进行编码;
将所述第一预测模式的标识信息写入码流,所述标识信息用于指示预测模式。
第四方面,本公开实施例还提供了另一种解码方法,包括:
解析码流,获得待解码点云中当前点的预测模式的标识信息;
使用所述标识信息指示的预测模式确定所述当前点的第一属性的预测值;
解析码流,获得所述当前点的第一属性的残差值;
计算所述残差值反量化后与所述预测值相加的和值,作为所述当前点的第一属性的重建值。。
在阅读并理解了附图和详细描述后,可以明白其他方面。
附图概述
附图用来提供对本公开实施例的理解,并且构成说明书的一部分,与本公开实施例一起用于解释本公开的技术方案,并不构成对本公开技术方案的限制。
图1为一种点云编码的流程示意图;
图2为一种点云解码的流程示意图;
图3为一种LOD生成过程的示意图;
图4为另一种LOD生成过程的示意图;
图5为本公开一实施例编码方法的流程示意图;
图6为本公开一示例性实施例编码方法的流程示意图;
图7为本公开实施例解码方法的流程示意图;
图8为本公开一示例性实施例解码方法的流程示意图;
图9为本公开一实施例编码方法的流程示意图;
图10为本公开一示例性实施例编码方法的流程示意图;
图11为本公开一实施例解码方法的流程示意图;
图12为本公开实施例一种编码器的框架示意图;
图13为本公开一示例编码器处理流程的示意图;
图14为本公开实施例一种解码器的框架示意图;
图15为本公开一示例解码器处理流程的示意图;
图16为一种编码设备的框架示意图。
详述
本公开描述了多个实施例,但是该描述是示例性的,而不是限制性的,在本公开所描述的实施例包含的范围内可以有更多的实施例和实现方案。
本公开中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本公开中被描述为“示例性的”或者“例如”的任何实施例不应被解释为比其他实施例更优选或更具优势。
在描述具有代表性的示例性实施例时,说明书可能已经将方法和/或过程呈现为特定的步骤序列。然而,在该方法或过程不依赖于本文所述步骤的特定顺序的程度上,该方法或过程不应限于所述的特定顺序的步骤。如本领域普通技术人员将理解的,其它的步骤顺序也是可能的。因此,说明书中阐述的步骤的特定顺序不应被解释为对权利要求的限制。此外,针对该方法和/或过程的权利要求不应限于 按照所写顺序执行它们的步骤,本领域技术人员可以容易地理解,这些顺序可以变化,并且仍然保持在本公开实施例的精神和范围内。
图1为一种点云编码的框架示意图,如图1所示的点云编码的框架,可以应用于点云编码器。针对待编码点云中每个点的几何信息和属性信息是分开进行编码的。在几何编码过程中,对几何信息进行坐标转换,使点云全都包含在一个bounding box(包围盒)中,然后再进行量化,这一步量化主要起到缩放的作用,由于量化取整,使得一部分点云的几何信息相同,于是在基于参数来决定是否移除重复点,量化和移除重复点这一过程又被称为体素化过程。接着对bounding box进行八叉树划分。在基于八叉树的几何信息编码流程中,将包围盒八等分为8个子立方体,对非空的(包含点云中的点)的子立方体继续进行八等分,直到划分得到的叶子结点为1×1×1的单位立方体时停止划分,对叶子结点中的点进行算术编码,生成二进制的几何比特流,即几何码流。在基于三角面片集(triangle soup,trisoup)的几何信息编码过程中,同样也要先进行八叉树划分,但区别于基于八叉树的几何信息编码,该trisoup不需要将点云逐级划分到边长为1x1x1的单位立方体,而是划分到block(子块)边长为W时停止划分,基于每个block中点云的分布所形成的表面,得到该表面与block的十二条边所产生的至多十二个vertex(交点),对vertex进行算术编码(基于交点进行表面拟合),生成二进制的几何比特流,即几何码流。Vertex还用于在几何重建的过程的实现,而重建的几何信息在对点云的属性编码时使用。
在属性编码过程中,几何编码完成,对几何信息进行重建后,进行颜色转换,将颜色信息(即属性信息的一种)从RGB颜色空间转换到YUV颜色空间。然后,利用重建的几何信息对点云重新着色,使得未编码的属性信息与重建的几何信息对应起来。属性编码主要针对颜色信息进行,在颜色信息编码过程中,包括三种变换方法,一是依赖于细节层次(Level of Detail,LOD)划分的基于距离的预测变换(Predictive Transform),二是同样依赖于细节层次(Level of Detail,LOD)划分的基于距离的提升变换,LOD,三是直接进行区域自适应分层变换(Regionadaptive Hierarchal Transform,RAHT)的变换,后两种方法都会将颜色信息从空间域转换到频域,通过变换得到高频系数和低频系数,最后对系数进行量化(即量化系数),最后,将量化后的系数进行算数编码,生成二进制的属性比特流,即属性码流。
图2为一种点云解码的框架示意图,如图2所示的点云解码的框架,可以应用于点云解码器。针对所获取的二进制码流,首先对二进制码流中的几何比特流和属性比特流分别进行独立解码。在对几何比特流的解码时,通过算术解码-八叉树合成-表面拟合-重建几何-逆坐标转换,得到点云的几何信息;在对属性比特流的解码时,通过算术解码-反量化-基于LOD的预测变换或提升逆变换或者基于RAHT的逆变换-逆颜色转换,得到点云的属性信息,基于几何信息和属性信息还原待编码的点云数据的三维图像模型。
在如上述图1所示的点云编码框架中,LOD划分主要用于点云属性变换中的预测变换(Predicting Transform)和提升变换(Lifting Transform)两种方式。下面将对基于距离进行LOD划分进行详细介绍。作为一种示例,LOD划分是通过一组距离阈值(用d
(1)、将点云中所有的点置于“未访问过”的点集,并且初始化“访问过”的点集(用V表示)为空集;
(2)、通过不断迭代来划分LOD层,第1次迭代所对应的细化级别LOD生成过程如下所示:
a、通过迭代遍历点云中所有的点;
b、如果当前的点已经遍历过,则忽略该点;
c、否则,分别计算该点到集合V中每个点的距离,记录其中最近的距离为D;
d、如果距离D大于或等于阈值,则将该点添加到细化级别R
e、重复a至d的过程,直至点云中的至少一个点全部被遍历过;
(3)、针对第l个LOD集合,即LODl是通过将细化级别R
(4)、通过重复(1)至(3)的过程进行不断地迭代,直至所有的LOD层生成或者所有的点都被遍历过。
图3为一种LOD生成过程的示意图,如图3所示,点云中包括有P0、P1、P2、P3、P4、P5、P6、P7、P8、P9等10个点,基于距离阈值进行LOD划分,如此,LOD0集合中顺序包括有P4、P5、P0、P2,LOD1集合中顺序包括有P4、P5、P0、P2、P3、P1、P6,LOD2集合中顺序包括有P4、P5、P0、P2、P3、P1、P6、P7、P8、P9。
基于莫顿码进行LOD划分的方案,与原始遍历搜索全部的点进行LOD划分的方案相比,基于莫顿码进行LOD划分的方案可以降低计算复杂度。
莫顿编码也叫z-order code,因为其编码顺序按照空间z序。首先以变量P
其中,x
其中,m
进一步地,D0(初始距离的阈值)和ρ(相邻LOD层划分时的距离阈值比)分别为初始参数,并且ρ>1。假定I表示所有点的索引,在第k次迭代时,LODk中的点会从LOD0到第LODk-1层中查找最近邻居,即距离最近的点;k=1,2,...,N-1。这里,N为LOD划分的总层数;而且当k=0时,第0次迭代时,LOD0中的点会直接在LOD0中查找最近邻居。示例性的,过程如下:
(1)、初始化划分距离阈值为D0;
(2)、在第k次迭代时,L(k)保存属于第k层LOD中的点,O(k)保存比LODk层更高细化级别的点集。其中,L(k)和O(k)的计算过程如下:
首先,O(k)和L(k)被初始化为空集;
其次,每一次迭代按照I中所保存点的索引顺序进行遍历。每一次遍历都会计算当前点到集合O(k)中一定范围内所有点的几何距离,而且基于I中当前点所对应的莫顿码,在集合O(k)中进行查找第一个大于当前点所对应莫顿码点的索引,然后在该索引的一个搜索范围SR1内进行查找(这里,SR1表示基于莫顿码的搜索范围,可以取值为8,16,64);如果在该范围内查找到与当前点的距离小于阈值的点,就将当前点加入到集合L(k)中,否则,则将当前点加入到集合O(k)中;
(3)、在每一次迭代的过程中,集合L(k)和O(k)分别进行计算,并且O(k)中的点会被用来预测集合L(k)中点。假定集合R(k)=L(k)¥L(k-1),即R(k)表示LOD(k-1)与LOD(k)集合相差部分的点集。针对位于集合R(k)中的点会在集合O(k)中进行查找最近的h个预测邻居(一般来说,h可以设置为3)。查找最近邻居的过程如下:
a、对于集合R(k)中的点Pi,该点所对应的莫顿码为Mi;
b、在集合O(k)查找第一个大于当前点Pi所对应的莫顿码Mi的点的索引j;
c、基于索引j在集合O(k)中的一个搜索范围[j-SR2,j+SR2]内查找当前点Pi的最近邻居(这里,SR2表示一个搜索范围,可以取值为8、16、32、64);
(4)、通过重复(1)至(3)的过程不断地迭代,直至I中所有的点全部被遍历。
图4为另一种LOD生成过程的示意图,如图4所示,点云中包括有P0、P1、P2、P3、P4、P5、P6、P7、P8、P9等10个点,基于莫顿码进行LOD划分,首先按照莫顿码的升序进行排列,这10个点的顺序为P4、P1、P9、P5、P0、P6、P8、P2、P7、P3;然后进行最近邻居的查找,如此,LOD0集合中仍然顺序包括有P4、P5、P0、P2,LOD1集合中仍然顺序包括有P4、P5、P0、P2、P3、P1、P6,LOD2集合中仍然顺序包括有P4、P5、P0、P2、P3、P1、P6、P7、P8、P9。
对于提升变换(Lifting Transform)模式,首先用已按照莫顿码排序的点云构建LOD,即根据预设好的LOD层数,对已经排好序的点进行下采样,每采样一次后已经得到的点构成一层LOD,采样距离由大到小,直至整个LOD构建完成。然后以LOD顺序对点云中的点寻找邻居点,以所有邻居点属性值的加权平均作为属性预测值,其中每个邻居点的权重是当前点与该当前点的邻居点的几何坐标欧氏距离平方的倒数,最后用当前点的实际属性值减去属性预测值得到属性残差值。
在一示例中,对于提升变换(Lifting Transform)模式,在构建完LOD之后,可以按照K最近邻(k-NearestNeighbor,KNN)算法为每一个点寻找最多K个最邻居点,则共有K+1种预测模式,分别是:以第一个、第二个、……、第K个最邻居点的属性值作为预测参考值,以及以K个最邻居点的属性加权平均值作为预测参考值,其中每个最邻居点的权重是当前点与该当前点的最邻居点的几何坐标欧氏距离平方的倒数,然后对此K+1个预测参考值及对应模式计算率失真优化(Rate-distortion optimization,RDO)代价值,将其中最小代价值的对应属性预测值作为当前点的属性预测值。
在一示例中,应用于点云颜色编码的预测变换Predicting Transform模式中的颜色预测技术可以通过以下流程实现:
1、基于每个点的欧式距离生成LOD,基于LOD的顺序得到当前点的3个最近邻,将其作为当前点的邻居点集;
2、根据邻居点集的颜色信息对当前点的颜色进行预测,共有4种预测模式。
在一示例中,预测模式0,即predMode=0(predMode赋值为0),以邻居点与当前点欧式距 离的倒数作为权重,对邻居点集中3个邻居点的颜色加权平均,得到当前点的颜色预测值。预测模式1,即predMode=1,直接采用第1邻居点(1st nearest point)的颜色信息作为预测值。预测模式2,即predMode=2,直接采用第2邻居点(2st nearest point)的颜色信息作为预测值。预测模式3,即predMode=3,直接采用第3邻居点(3st nearest point)的颜色信息作为预测值。预测模式及编码每种预测模式所需比特数idxBits如表1所示。
表1:
计算得到4种预测模式的颜色预测值之后,可以采用RDO技术对4种预测模式进行率失真优化选择,选择最优预测模式来预测当前点的颜色信息,采用算术编码器对最优预测模式信息进行熵编码。
在一示例中,在预测点云中的当前点时,基于生成LOD时的近邻点搜索结果创建多个预测变量候选项,即predMode可以取值0~3。如图3所示,当使用预测方式编码P2的属性值时,得到P2的3个最近邻点位点P0,P5 and P4,可以将P0,P5 and P4,的基于距离的加权平均值的预测变量索引设为0,然后,将最近邻邻居P4属性值的预测变量索引设为1,此外,将下一个近邻点P5 and P0的属性值预测变量索引分别设为2和3,如表2所示。在创建预测变量候选项之后,利用率失真优化过程(RDO)选择最佳预测变量,然后对所选的预测变量索引进行算术编码(在这里,若当前点的预测模式为0不需要编码,若是通过RDO选择后的1,2,3三种预测模式则编码到属性码流)。
表2:
在一示例中,应用于点云颜色编码的预测变换Predicting Transform模式中的颜色预测技术可以通过以下流程实现:
对当前点的邻居点集计算其属性的最大差异maxDiff,将maxDiff与设定的阈值进行比较,如果小于阈值则使用邻居点属性值加权平均的预测模式;否则对该点使用RDO技术选择最优预测模式;
RDO技术会对当前点的每种预测模式计算得到一个代价分数,然后选取代价分数最小的预测模式,即最优预测模式作为当前点的属性预测模式。
例如,基于表1所示的4种预测模式,首先,计算当前点邻居点集的属性最大差异maxDiff,过程如下:首先计算邻居点在R(红色)分量上的最大差异,即MAX(R)–MIN(R),G(绿色)、B(蓝色)分量同理,然后选择R、G、B分量中的最大差异值作为maxDiff,即maxDiff= max(max(R1,R2,R3)-min(R1,R2,R3),max(G1,G2,G3)-min(G1,G2,G3),max(B1,B2,B3)-min(B1,B2,B3));将maxDiff与阈值比较,若小于阈值则当前点的预测模式设为0,即predMode=0;若大于等于阈值,则对当前点使用RDO技术,计算出每种预测模式对应的属性预测值attrPred,令当前点的属性值attrValue与预测值attrPred相减并量化得到量化残差attrResidualQuant,RDO技术中的失真D为attrResidualQuant三个分量的和,即D=attrResidualQuant[0]+attrResidualQuant[1]+attrResidualQuant[2];计算编码每种预测模式所需的比特数idxBits作为RDO技术中的码率R,即R=idxBits,则每种预测模式的代价分数可表示为D+lambda x R,其中lambda=0.01x Qstep,选择代价分数最小的预测模式作为当前点的最优预测模式。其中,R1表示第1个邻居点在R分量上的属性值;R2表示第2个邻居点在R分量上的属性值;R3表示第3个邻居点在R分量上的属性值;G1表示第1个邻居点在G分量上的属性值;G2表示第2个邻居点在G分量上的属性值;G3表示第3个邻居点在G分量上的属性值;B1表示第1个邻居点在B分量上的属性值;B2表示第2个邻居点在B分量上的属性值;B3表示第3个邻居点在B分量上的属性值。
在一示例中,属性编码过程可以包括:通过给定输入点云的位置信息生成细节级别LOD(Level of Detail),依据LOD的顺序,进行点云预测,对预测后计算的残差结果(也可以称为残差值)进行量化,并对残差值和预测模式进行算术编码形成属性码流。在一示例中,属性解码过程可以包括:通过解析属性码流,获取点云中点的属性信息的残差值,然后获取预测模式,继而进行点云预测,得到点云的属性预测值,然后通过对点的属性信息的残差值进行反量化,得到反量化后的点的属性信息的残差值;与上述预测值相加得到点的属性信息的重建值,以得到解码点云。
属性编码不仅包括对颜色信息的编码,还包括对反射率信息等其他属性信息的编码。在属性编码过程中,针对待编码点云中每个点的颜色信息和反射率信息是分开进行编码的。例如,先编码属性中的颜色信息(color),颜色信息编码完成后形成颜色属性码流,接着再编码反射率信息(reflectance),编码完成后形成反射率属性码流。在对反射率信息进行预测的过程中,当不使用RDO选择最优预测模式时,反射率信息的预测模式(predMode)会默认为颜色属性遗留下来的预测模式,即反射率信息会默认使用颜色信息的预测模式。但是颜色属性和反射率属性的特性不同,直接继承颜色属性的预测模式对反射率信息进行预测,会产生逻辑错误,导致预测结果也可能存在偏差,导致预测准确度不高,降低了编解码性能。
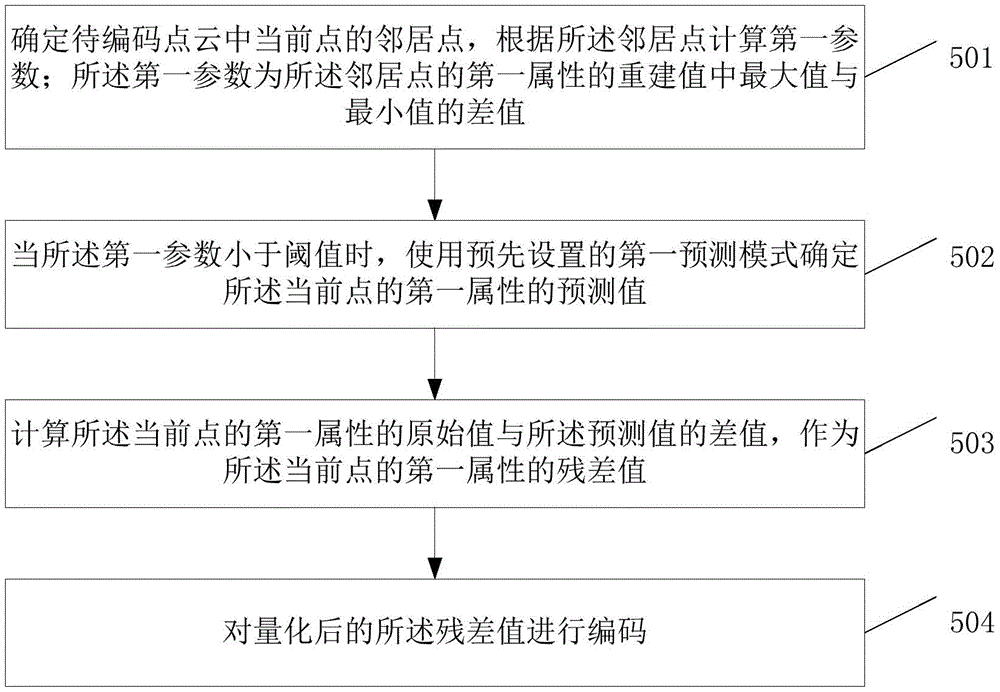
本公开实施例提供了一种解码方法,如图5所示,该方法包括:
步骤501,确定待编码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
步骤502,当所述第一参数小于阈值时,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
步骤503,计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
步骤504,对量化后的所述残差值进行编码。
在一些示例性实施例中,所述第一属性包括以下至少一种:反射率信息,颜色信息。
在一些示例性实施例中,所述第一预测模式包括以下至少一种:使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。
在一些示例性实施例中,所述使用邻居点属性加权平均值作为预测值,包括:
使用M个邻居点属性加权平均值作为预测值,M取值为大于1的正整数。
在一些示例性实施例中,使用邻居点之一的属性值作为预测值,包括:
使用当前点的第N个邻居点的属性值作为预测值,N取值为正整数。
在一些示例性实施例中,所述M个邻居点包括所述当前点的前P个邻居点中的至少部分邻居点,P≥M。
在一些示例性实施例中,所述当前点的邻居点包括R个邻居点R取值为大于1的正整数。
在一些示例性实施例中,M可以取值为3、4或者5。
在一些示例性实施例中,N可以取值为1、2或3。
在一些示例性实施例中,R可以取值为3、4或5。
在一些示例性实施例中,该方法还包括:
当所述第一参数不小于阈值时,采用率失真优化RDO选择第二预测模式;
使用所述第二预测模式确定所述当前点的第一属性的预测值;
将所述第二预测模式的标识信息写入码流,所述标识信息用于指示预测模式。
在一些示例性实施例中,所述第二预测模式包括以下至少一种:
使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。
在一些示例性实施例中,所述使用邻居点属性加权平均值作为预测值,包括:
使用S个邻居点属性加权平均值作为预测值,S取值为大于1的正整数,对应的标识信息为预设索引值且具有全局唯一性。
在一些示例性实施例中,使用邻居点之一的属性值作为预测值,包括:
使用当前点的第T个邻居点的属性值作为预测值,T取值为正整数,对应的标识信息是第T个邻居点的索引值。
在一些示例性实施例中,所述S个邻居点包括所述当前点的前U个邻居点中的至少部分邻居点,U≥S。
在一些示例性实施例中,S可以取值为3、4或5。
在一些示例性实施例中,T可以取值为1、2或3。
在一些示例性实施例中,U可以取值为3、4或5。
本公开一示例性实施例提供了一种编码方法,如图6所示,包括:
步骤601,确定待编码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
在一些示例中,待编码点云中当前点的邻居点是指待编码点云中当前点的已经编码的邻居点。
在一些示例中,当前点的邻居点可以包括R个邻居点,R取值为大于1的正整数。在一示例中,R可以取值为3、4或5。例如当前点的邻居点包括3个邻居点,该3个邻居点可以是指基于距离从近到远,距离当前点最近的3个邻居点,或者距离当前点最近的Z个邻居点中的任意3个邻居点,Z>3,Z为正整数。
在一些示例中,所述第一属性包括以下至少一种:反射率信息,颜色信息。
在一示例中,所述第一属性包括反射率信息,所述第一参数为邻居点的反射率信息的重建值中最 大值与最小值的差值。例如,该第一参数maxDiff=max(Re)-min(Re),其中,max(Re)表示邻居点的反射率信息重建值中的最大值,min(Re)表示邻居点反射率信息中的最小值。例如,当前点的邻居点包括3个邻居点,第一参数为该3个邻居点的反射率信息的重建值中最大值与最小值的差值。
在一示例中,所述第一属性包括颜色信息,所述第一参数为邻居点的颜色信息的重建值中最大值与最小值的差值。例如,可以通过以下方式计算第一参数maxDiff:
计算邻居点在R分量上的最大差异值,即max(R)-min(R);
计算邻居点在G分量上的最大差异值,即max(G)-min(G);
计算邻居点在B分量上的最大差异值,即max(B)-min(B);
选择R、G、B分量上的最大差异值中的最大值作为maxDiff;
即,maxDiff=max(max(R)-min(R),max(G)-min(G),max(B)-min(B)),其中max(R)表示邻居点在R分量上重建值中的最大值,min(R)表示邻居点在R分量上重建值中的最小值,max(G)表示邻居点在G分量上重建值中的最大值,min(G)表示邻居点在G分量上重建值中的最小值,max(B)表示邻居点在B分量上重建值中的最大值,min(B)表示邻居点在B分量上重建值中的最小值。例如,当前点的邻居点包括3个邻居点,第一参数为该3个邻居点的颜色信息的重建值中最大值与最小值的差值,也就是第一参数为该3个邻居点在R分量上的最大差异值,在G分量上的最大差异值,在B分量上的最大差异值这三者数值中的最大值。
步骤602,判断所述第一次参数是否小于阈值;
在一些示例中,该阈值可以预先设定。例如,可以预先设定颜色信息对应的阈值,当第一属性为颜色信息时,判断第一参数是否小于颜色信息的阈值。又例如,可以预先设定反射率信息对应的阈值,当第一属性为反射率信息时,判断第一参数是否小于反射率信息的阈值。
当所述第一参数小于阈值时,执行步骤603至步骤605,当所述第一参数不小于阈值时,执行步骤606至步骤608:
步骤603,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
在一些示例中,所述第一预测模式包括以下至少一种:使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。例如,可以预先将第一预测模式设置为使用邻居点属性加权平均值作为预测值。又例如,可以预先将第一预测模式设置为使用邻居点之一的属性值作为预测值。
在一些示例中,所述使用邻居点属性加权平均值作为预测值,包括:
使用M个邻居点属性加权平均值作为预测值,M取值为大于1的正整数。在一示例中,M可以取值为3、4或者5。例如可以使用3个邻居点属性加权平均值作为预测值。
在一些示例中,所述M个邻居点包括所述当前点的前P个邻居点中的至少部分邻居点,P≥M。例如,P可以取值为5,M可以取值为3,可以从当前点的前5个邻居点中选择3个邻居点。当前点的前P个邻居点是指基于距离从近到远,距离当前点的前P个邻居点,P为正整数。
在一些示例中,M个邻居点可以选取计算第一参数的当前点的邻居点。例如计算第一参数的当前点的邻居点可以选择3个邻居点,M个邻居点也可以选择该3个邻居点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的3个邻居点,也使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,M个邻居点可以选取计算第一参数的当前点的邻居点中的点或者不是计算第一参数的当前点的邻居点中的点,例如计算第一参数的当前点的邻居点可以选择5个邻居点,M个邻居点 可以选择3个邻居点。该3个邻居点可以是该5个邻居点中的3个,或者该3个邻居点可以不是该5个邻居点中的点,或者该3个邻居点的部分点可以是该5个邻居点中的点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的5个邻居点,使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,每个邻居点的权重可以是当前点与该邻居点的欧式距离平方的倒数。
在一些示例中,使用邻居点之一的属性值作为预测值,包括:使用当前点的第N个邻居点的属性值作为预测值,N取值为正整数。在一示例中,N可以取值为1、2或3。第N个邻居点是指距离从近到远,距离当前点最近的的第N个邻居点,例如可以使用距离当前点最近的第1个邻居点的属性值作为预测值,该属性值可以是重建值。又例如,可以使用距离当前点最近的第2个邻居点的属性值作为预测值。又例如,可以使用距离当前点最近的第3个邻居点的属性值作为预测值。
在一些示例中,用户可以预先设置编解码的第一预测模式,例如用户可以预先设置编码端的第一预测模式为使用M个邻居点属性加权平均值作为预测值。又例如用户可以预先设置编码端的第一预测模式为使用当前点的第N个邻居点的属性值作为预测值。在一示例中,编解码端预先设置的第一模式相同。在另一示例中,编解码端预先设置的第一模式不同。
在一些示例中,所述第一预测模式还可以包括:使用邻居点的平均值作为预测值。例如,将选取的3个邻居点的属性值的平均值作为当前点的预测值。
在一些示例中,所述第一预测模式还可以包括:将对邻居点的属性值进行数学运算后得到的值作为预测值。该数学运算是指除了加权平均和平均之外的其他任意一种数学运算方法。
在一些示例中,可以预先从多种预测模式中选择一种设置为编码端的第一预测模式。例如,该多种预测模式可以根据计算第一参数的当前点的邻居点确定,
比如,当前点的邻居点为3个,则该多种预测模式可以包括:使用该3个邻居点属性加权平均值作为预测值的预测模式,以及分别将第1个、第2个、第3个邻居点的属性值作为预测值的预测模式,例如表1中所示,包括预测模式0,即predMode=0(predMode赋值为0),以邻居点与当前点欧式距离平房的倒数作为权重,对3个邻居点的属性值加权平均,作为当前点的预测值;预测模式1,即predMode=1,直接采用第1个邻居点(1st nearest point)的属性值作为预测值;预测模式2,即predMode=2,直接采用第2个邻居点(2st nearest point)的属性值作为预测值;预测模式3,即predMode=3,直接采用第3个邻居点(3st nearest point)的属性值作为预测值。例如,以图3中点P2为例,选择点P2的3个邻居点P0,P5 and P4,可以从4种预测模式中选择一种设置为第一预测模式,该4种预测模式包括:预测模式0,即predMode=0(predMode赋值为0),即以邻居点与当前点欧式距离平方的倒数作为权重,对P0,P5 and P4的属性加权平均,得到值作为当前点的预测值;预测模式1,即predMode=1,直接采用第1个邻居点(1st nearest point)即P4的属性值作为预测值;预测模式2,即predMode=2,直接采用第2个邻居点(2st nearest point)即P5的属性值作为预测值;预测模式3,即predMode=3,直接采用第3个邻居点(3st nearest point)即P0的属性值作为预测值。每一种预测模式可以对应一种标识(可以是索引号),本示例中,4种预测模式的索引号,如表1所示,分别为0,1,2,3。
又比如,当前点的邻居点为3个,则该多种预测模式可以包括:分别将第1个、第2个、第3个邻居点的属性值作为预测值的预测模式,例如表3中所示,包括预测模式1,即predMode=1,直接采用第1个邻居点(1st nearest point)的属性值作为预测值;预测模式2,即predMode=2,直接采用第2个邻居点(2st nearest point)的属性值作为预测值;预测模式3,即predMode=3, 直接采用第3个邻居点(3st nearest point)的属性值作为预测值。例如,以图3中点P2为例,选择点P2的3个邻居点为点P0,P5 and P4,从3种预测模式中选择一种设置为第一预测模式,该三种预测模式包括:预测模式1,即predMode=1,直接采用第1个邻居点(1st nearest point)即P4的属性值作为预测值;预测模式2,即predMode=2,直接采用第2个邻居点(2st nearest point)即P5的属性值作为预测值;预测模式3,即predMode=3,直接采用第3个邻居点(3st nearest point)即P0的属性值作为预测值。
表3:
在一示例中,可以在编码端和解码端预先设置第一预测模式,例如将编解码两端预测模式默认初始化值设置为第一预测模式对应的标识。例如,当将表3中的预测模式1设定为第一预测模式时,可以将编解码两端默认初始化值设置为1。在一示例中,编码端和解码端可以设置相同的第一预测模式。在另一示例中,编码端和解码端可以设置不同的第一预测模式。
步骤604,计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
步骤605,对量化后的所述残差值进行编码;
步骤606,采用率失真优化RDO选择第二预测模式;使用所述第二预测模式确定所述当前点的第一属性的预测值;
在一些示例中,可以从多种备选的预测模式中,采用率失真优化RDO选择第二预测模式。例如该多种备选的预测模式可以包括:邻居点属性加权平均值作为预测值的预测模式,以及D种预测模式,D为正整数。该D种预测模式包括以下一种或者多种:基于距离由近到远,分别将以当前点的第1个、第2个、……、第E个邻居点的属性值作为预测值的预测模式作为第1种至第E种预测模式,E为正整数。例如,该多种预测模式可以包括:邻居点属性加权平均值作为预测值的预测模式,距离当前点最近的第1个的邻居点的属性值作为预测值的预测模式,距离当前点最近的第2个的邻居点的属性值作为预测值的预测模式,距离当前点最近的第3个的邻居点的属性值作为预测值的预测模式。又例如,该多种备选的预测模式可以包括:F种预测模式,F为正整数。该F种预测模式包括以下一种或者多种:基于距离由近到远,分别将以当前点的第1个、第2个、……、第G个邻居点的属性值作为预测值的预测模式作为第1种至第G种预测模式,G为正整数。例如,该多种备选的预测模式可以包括:距离当前点最近的第1个的邻居点的属性值作为预测值的预测模式,距离当前点最近的第2个的邻居点的属性值作为预测值的预测模式,距离当前点最近的第3个的邻居点的属性值作为预测值的预测模式。
在一些示例中,采用RDO从多种备选的预测模式中选择第二预测模式,包括:
针对多种备选的预测模式中的每一种预测模式分别执行:
计算出该种预测模式对应的预测值attrPred,将当前点的反射率值attrValue与预测值attrPred相减并量化得到量化残差attrResidualQuant,将该量化残差attrResidualQuant作为RDO技术中的失真D,即D=attrResidualQuant;
计算编码该种预测模式所需的比特数idxBits,将该比特数idxBits作为RDO技术中的码率R,即R=idxBits;
计算该种预测模式的代价分数,其中,代价分数=D+lambda x R,lambda=0.01 x Qstep,Qstep为量化步长;
选择代价分数最小的预测模式作为第二预测模式。
在一些示例中,所述第二预测模式包括以下至少一种:
使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。
在一些示例中,所述使用邻居点属性加权平均值作为预测值,包括:使用S个邻居点属性加权平均值作为预测值,S取值为大于1的正整数。
在一示例中,S可以取值为3、4或者5。例如可以使用3个邻居点属性加权平均值作为预测值。
在一些示例中,所述S个邻居点包括所述当前点的前U个邻居点中的至少部分邻居点,U≥S。例如,U可以取值为5,S可以取值为3,可以从当前点的前5个邻居点中选择3个邻居点。当前点的前U个邻居点是指基于距离从近到远,距离当前点的前U个邻居点,U为正整数。
在一些示例中,S个邻居点可以选取计算第一参数的当前点的邻居点。例如计算第一参数的当前点的邻居点可以选择3个邻居点,S个邻居点也可以选择该3个邻居点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的3个邻居点,也使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,S个邻居点可以选取计算第一参数的当前点的邻居点中的点或者不是计算第一参数的当前点的邻居点中的点,例如计算第一参数的当前点的邻居点可以选择5个邻居点,S个邻居点可以选择3个邻居点。该3个邻居点可以是该5个邻居点中的3个,或者该3个邻居点可以不是该5个邻居点中的点,或者该3个邻居点的部分点可以是该5个邻居点中的点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的5个邻居点,使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,每个邻居点的权重可以是当前点与该邻居点的欧式距离平方的倒数。
在一些示例中,每个邻居点的权重还可以是其他值,例如可以是预先设置的系数等。
在一示例中,S个邻居点与M个邻居点可以选取相同的邻居点,例如可以都选择距离当前点最近的3个邻居点的属性加权平均作为当前点的预测值。
在一示例中,S个邻居点与M个邻居点也可以选取不相同的邻居点,例如M个邻居点选择距离当前点最近的3个邻居点的属性加权平均作为当前点的预测值,S个邻居点选择距离当前点最近的第5个至第7个邻居点的属性加权平均作为当前点的预测值。
在一示例中,S个邻居点与M个邻居点中的点可以部分相同。例如M个邻居点选择距离当前点最近的3个邻居点的属性加权平均作为当前点的预测值,S个邻居点选择距离当前点最近的第2个至第4个邻居点的属性加权平均作为当前点的预测值。
在一些示例中,使用邻居点之一的属性值作为预测值,包括:使用当前点的第T个邻居点的属性值作为预测值,T取值为正整数。在一示例中,T可以取值为1、2或3。第T个邻居点是指距离从近到远,距离当前点最近的的第T个邻居点,例如可以使用距离当前点最近的第1个邻居点的属性值作为预测值,该属性值可以是重建值。又例如,可以使用距离当前点最近的第2个邻居点的属性值作 为预测值。又例如,可以使用距离当前点最近的第3个邻居点的属性值作为预测值。
在一些示例中,可以从多种备选的预测模式中,采用率失真优化RDO选择第二预测模式。例如,该多种备选预测模式可以根据计算第一参数的当前点的邻居点确定,
比如,当前点的邻居点为3个,则该多种备选预测模式可以包括:使用该3个邻居点属性加权平均值作为预测值的预测模式,以及分别将第1个、第2个、第3个邻居点的属性值作为预测值的预测模式,例如表1中所示,包括预测模式0,即predMode=0(predMode赋值为0),以邻居点与当前点欧式距离平房的倒数作为权重,对3个邻居点的属性值加权平均,作为当前点的预测值;预测模式1,即predMode=1,直接采用第1个邻居点(1st nearest point)的属性值作为预测值;预测模式2,即predMode=2,直接采用第2个邻居点(2st nearest point)的属性值作为预测值;预测模式3,即predMode=3,直接采用第3个邻居点(3st nearest point)的属性值作为预测值。例如,以图3中点P2为例,选择点P2的3个邻居点P0,P5 and P4,可以从4种预测模式中选择第二预测模式,该4种预测模式包括:预测模式0,即predMode=0(predMode赋值为0),即以邻居点与当前点欧式距离平方的倒数作为权重,对P0,P5 and P4的属性加权平均,得到值作为当前点的预测值;预测模式1,即predMode=1,直接采用第1个邻居点(1st nearest point)即P4的属性值作为预测值;预测模式2,即predMode=2,直接采用第2个邻居点(2st nearest point)即P5的属性值作为预测值;预测模式3,即predMode=3,直接采用第3个邻居点(3st nearest point)即P0的属性值作为预测值。每一种预测模式可以对应一种标识(该标识信息可以是索引号),本示例中,4种预测模式的索引号,如表1所示,分别为0,1,2,3。
又比如,当前点的邻居点为3个,则该多种备选的预测模式可以包括:分别将第1个、第2个、第3个邻居点的属性值作为预测值的预测模式,例如表3中所示,包括预测模式1,即predMode=1,直接采用第1个邻居点(1st nearest point)的属性值作为预测值;预测模式2,即predMode=2,直接采用第2个邻居点(2st nearest point)的属性值作为预测值;预测模式3,即predMode=3,直接采用第3个邻居点(3st nearest point)的属性值作为预测值。
步骤607,计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
在一些示例中,可以通过以下方式计算当前点的第一属性的残差值attrResidualQuant:
其中,attrPredValue为属性预测值,attrValue为当前点的属性值(原始值),量化步长Qstep由量化参数Qp计算得到。
步骤608,对量化后的所述残差值进行编码,以及将所述第二预测模式的标识信息写入码流,所述标识信息用于指示预测模式。
在一些示例中,每一种预测模式可以对应一种标识。在一示例中,可以预先将使用邻居点属性加权平均值作为预测值的预测模式的标识设置为预设索引值且具有全局唯一性,例如该预测索引值可以为0。在另一示例中,可以预先将使用当前点的第T个邻居点的属性值作为预测值的预测模式的标识设置为该第T个邻居点的索引值。例如,将使用当前点的第T个邻居点的属性值作为预测值的预测模式的标识设置为T。又例如,将使用当前点的第T个邻居点的属性值作为预测值的预测模式的标识设置为1,将使用当前点的第2个邻居点的属性值作为预测值的预测模式的标识设置为2,将使用当前 点的第3个邻居点的属性值作为预测值的预测模式的标识设置为3。当前点的第T个邻居点是指基于距离由近到远,距离当前点最近的第T个邻居点。
在一些示例中,该标识信息可以是一个标识位,用于指示预测模式的信息,例如预测模式的索引号。
本公开实施例提供了一种解码方法,如图7所示,包括:
步骤701,确定待解码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
步骤702,当所述第一参数小于阈值时,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
步骤703,解析码流,获得所述当前点的第一属性的残差值;
步骤704,计算所述残差值反量化后与所述预测值相加的和值,作为所述当前点的第一属性的重建值。
在一些示例性实施例中,所述第一属性包括以下至少一种:反射率信息,颜色信息。
在一些示例性实施例中,所述第一预测模式包括以下至少一种:使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。
在一些示例性实施例中,所述使用邻居点属性加权平均值作为预测值,包括:
使用M个邻居点属性加权平均值作为预测值,M取值为大于1的正整数。
在一些示例性实施例中,使用邻居点之一的属性值作为预测值,包括:
使用当前点的第N个邻居点的属性值作为预测值,N取值为正整数。
在一些示例性实施例中,所述当前点的邻居点包括R个邻居点,R取值为大于1的正整数。
在一些示例性实施例中,M可以取值为3、4或者5。
在一些示例性实施例中,N可以取值为1、2或3。
在一些示例性实施例中,R可以取值为3、4或5。
在一些示例性实施例中,该方法还包括:
当所述第一参数不小于阈值时,解析码流,获得预测模式的标识信息;
使用所述标识信息指示的预测模式确定所述当前点的第一属性的预测值。
在一些示例性实施例中,当所述标识信息为预设索引值时,将邻居点属性加权平均值作为所述当前点的预测值;
当所述标识信息为所述预设索引值之外的其他索引值时,使用邻居点之一的属性值作为所述当前点的预测值,
在一些示例性实施例中,使用邻居点属性加权平均值作为所述当前点的预测值,包括:
使用S个邻居点属性加权平均值作为预测值,S取值为大于1的正整数。
在一些示例性实施例中,使用邻居点之一的属性值作为所述当前点的预测值,包括:
使用第T个邻居点的属性值作为所述当前点的预测值,T为所述标识信息对应的索引值。
本公开一示例性实施例提供了一种解码方法,如图8所示,该方法包括:
步骤801,确定待解码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
在一些示例中,待解码点云中当前点的邻居点是指待解码点云中当前点的已经解码的邻居点。
在一些示例中,当前点的邻居点可以包括R个邻居点,R取值为大于1的正整数。在一示例中,R可以取值为3、4或5。例如当前点的邻居点包括3个邻居点,该3个邻居点可以是指基于距离从近到远,距离当前点最近的3个邻居点,或者距离当前点最近的Z个邻居点中的任意3个邻居点,Z>3。
在一些示例中,所述第一属性包括以下至少一种:反射率信息,颜色信息。
在一示例中,所述第一属性包括反射率信息,所述第一参数为邻居点的反射率信息的重建值中最大值与最小值的差值。例如,该第一参数maxDiff=max(Re)-min(Re),其中,max(Re)表示邻居点的反射率信息重建值中的最大值,min(Re)表示邻居点反射率信息中的最小值。例如,当前点的邻居点包括3个邻居点,第一参数为该3个邻居点的反射率信息的重建值中最大值与最小值的差值。
在一示例中,所述第一属性包括颜色信息,所述第一参数为邻居点的颜色信息的重建值中最大值与最小值的差值。例如,可以通过以下方式计算第一参数maxDiff:
计算邻居点在R分量上的最大差异值,即max(R)-min(R);
计算邻居点在G分量上的最大差异值,即max(G)-min(G);
计算邻居点在B分量上的最大差异值,即max(B)-min(B);
选择R、G、B分量上的最大差异值中的最大值作为maxDiff;
即,maxDiff=max(max(R)-min(R),max(G)-min(G),max(B)-min(B)),其中max(R)表示邻居点在R分量上重建值中的最大值,min(R)表示邻居点在R分量上重建值中的最小值,max(G)表示邻居点在G分量上重建值中的最大值,min(G)表示邻居点在G分量上重建值中的最小值,max(B)表示邻居点在B分量上重建值中的最大值,min(B)表示邻居点在B分量上重建值中的最小值。例如,当前点的邻居点包括3个邻居点,第一参数为该3个邻居点的颜色信息的重建值中最大值与最小值的差值,也就是第一参数为该3个邻居点在R分量上的最大差异值,在G分量上的最大差异值,在B分量上的最大差异值这三者数值中的最大值。
步骤802,判断所述第一次参数是否小于阈值;
在一些示例中,该阈值可以预先设定。例如,可以预先设定颜色信息对应的阈值,当第一属性为颜色信息时,判断第一参数是否小于颜色信息的阈值。又例如,可以预先设定反射率信息对应的阈值,当第一属性为反射率信息时,判断第一参数是否小于反射率信息的阈值。
当所述第一参数小于阈值时,执行步骤803,当所述第一参数不小于阈值时,执行步骤804:
步骤803,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
在一些示例中,所述第一预测模式包括以下至少一种:使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。例如,可以预先将第一预测模式设置为使用邻居点属性加权平均值作为预测值。又例如,可以预先将第一预测模式设置为使用邻居点之一的属性值作为预测值。
在一些示例中,所述使用邻居点属性加权平均值作为预测值,包括:
使用M个邻居点属性加权平均值作为预测值,M取值为大于1的正整数。在一示例中,M可以取值为3、4或者5。例如可以使用3个邻居点属性加权平均值作为预测值。
在一些示例中,所述M个邻居点包括所述当前点的前P个邻居点中的至少部分邻居点,P≥M。例如,P可以取值为5,M可以取值为3,可以从当前点的前5个邻居点中选择3个邻居点。当前点的前P个邻居点是指基于距离从近到远,距离当前点的前P个邻居点。
在一些示例中,M个邻居点可以选取计算第一参数的当前点的邻居点。例如计算第一参数的当前点的邻居点可以选择3个邻居点,M个邻居点也可以选择该3个邻居点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的3个邻居点,也使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,M个邻居点可以选取计算第一参数的当前点的邻居点中的点或者不是计算第一参数的当前点的邻居点中的点,例如计算第一参数的当前点的邻居点可以选择5个邻居点,M个邻居点可以选择3个邻居点。该3个邻居点可以是该5个邻居点中的3个,或者该3个邻居点可以不是该5个邻居点中的点,或者该3个邻居点的部分点可以是该5个邻居点中的点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的5个邻居点,使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,每个邻居点的权重可以是当前点与该邻居点的欧式距离平方的倒数。
在一些示例中,每个邻居点的权重还可以是其他值,例如可以是预先设置的系数等。
在一些示例中,使用邻居点之一的属性值作为预测值,包括:使用当前点的第N个邻居点的属性值作为预测值,N取值为正整数。在一示例中,N可以取值为1、2或3。第N个邻居点是指距离从近到远,距离当前点最近的的第N个邻居点,例如可以使用距离当前点最近的第1个邻居点的属性值作为预测值,该属性值可以是重建值。又例如,可以使用距离当前点最近的第2个邻居点的属性值作为预测值。又例如,可以使用距离当前点最近的第3个邻居点的属性值作为预测值。
在一些示例中,用户可以预先设置编解码的第一预测模式,例如用户可以预先设置解码端的第一预测模式为使用M个邻居点属性加权平均值作为预测值。又例如用户可以预先设置编码端的第一预测模式为使用当前点的第N个邻居点的属性值作为预测值。在一示例中,编解码端预先设置的第一模式相同。在另一示例中,编解码端预先设置的第一模式不同。
在一些示例中,所述第一预测模式还可以包括:使用邻居点的平均值作为预测值。例如,将选取的3个邻居点的属性值的平均值作为当前点的预测值。
在一些示例中,所述第一预测模式还可以包括:将对邻居点的属性值进行数学运算后得到的值作为预测值。该数学运算是指除了加权平均和平均之外的其他任意一种数学运算方法。
步骤804,解析码流,获得预测模式的标识信息;使用所述标识信息指示的预测模式确定所述当前点的第一属性的预测值;
在一些示例中,当所述标识信息为预设索引值时,将邻居点属性加权平均值作为所述当前点的预测值。例如,预先将邻居点属性加权平均值作为预测值的预测模式的标识设置为索引值0,则当解析获得的预测模式的标识信息为0时,使用该标识信息0指示的预测模式即将邻居点属性加权平均值作为预测值的预测模式确定当前点的预测值。
在一些示例中,该标识信息指示的使用邻居点属性加权平均值作为所述当前点的预测值的预测模式,包括:
使用S个邻居点属性加权平均值作为预测值,S取值为大于1的正整数。
在一示例中,S可以取值为3、4或者5。例如可以使用3个邻居点属性加权平均值作为预测值。
在一些示例中,所述S个邻居点包括所述当前点的前U个邻居点中的至少部分邻居点,U≥S。 例如,U可以取值为5,S可以取值为3,可以从当前点的前5个邻居点中选择3个邻居点。当前点的前U个邻居点是指基于距离从近到远,距离当前点的前U个邻居点。
在一些示例中,S个邻居点可以选取计算第一参数的当前点的邻居点。例如计算第一参数的当前点的邻居点可以选择3个邻居点,S个邻居点也可以选择该3个邻居点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的3个邻居点,也使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,S个邻居点可以选取计算第一参数的当前点的邻居点中的点或者不是计算第一参数的当前点的邻居点中的点,例如计算第一参数的当前点的邻居点可以选择5个邻居点,S个邻居点可以选择3个邻居点。该3个邻居点可以是该5个邻居点中的3个,或者该3个邻居点可以不是该5个邻居点中的点,或者该3个邻居点的部分点可以是该5个邻居点中的点。比如,计算第一参数的当前点的邻居点选择距离当前点最近的5个邻居点,使用距离当前点最近的3个邻居点属性加权平均值作为预测值。
在一些示例中,每个邻居点的权重可以是当前点与该邻居点的欧式距离平方的倒数。
在一些示例中,每个邻居点的权重还可以是其他值,例如可以是预先设置的系数等。
在一示例中,S个邻居点与M个邻居点可以选取相同的邻居点,例如可以都选择距离当前点最近的3个邻居点的属性加权平均作为当前点的预测值。
在一示例中,S个邻居点与M个邻居点也可以选取不相同的邻居点,例如M个邻居点选择距离当前点最近的3个邻居点的属性加权平均作为当前点的预测值,S个邻居点选择距离当前点最近的第5个至第7个邻居点的属性加权平均作为当前点的预测值。
在一示例中,S个邻居点与M个邻居点中的点可以部分相同。例如M个邻居点选择距离当前点最近的3个邻居点的属性加权平均作为当前点的预测值,S个邻居点选择距离当前点最近的第2个至第4个邻居点的属性加权平均作为当前点的预测值。
在一些示例中,当所述标识信息为所述预设索引值之外的其他索引值时,使用邻居点之一的属性值作为所述当前点的预测值。在一示例中,使用邻居点之一的属性值作为预测值,包括:使用当前点的第T个邻居点的属性值作为预测值,T取值为正整数。在一示例中,T可以取值为1、2或3。第T个邻居点是指距离从近到远,距离当前点最近的的第T个邻居点,例如,可以预先设置的索引值1指示使用当前点的第1个邻居点的属性值作为预测值,索引值2指示使用当前点的第2个邻居点的属性值作为预测值,索引值1指示使用当前点的第3个邻居点的属性值作为预测值,当解析获得的标识信息为1,则使用当前点的第1个邻居点的属性值作为当前点的预测值,当解析获得的标识信息为2,则使用当前点的第2个邻居点的属性值作为当前点的预测值,当解析获得的标识信息为3,则使用当前点的第3个邻居点的属性值作为当前点的预测值。第1,2,3个邻居点是指基于距离由近到远,距离当前点最近的第1,2,3个邻居点。
步骤805,解析码流,获得所述当前点的第一属性的残差值;计算所述残差值反量化后与所述预测值相加的和值,作为所述当前点的第一属性的重建值。
本公开实施例提供了一种编码方法,如图9所示,包括:
步骤901,确定待编码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
步骤902,当所述第一参数小于阈值时,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
步骤903,计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
步骤904,对量化后的所述残差值进行编码,将所述第一预测模式的标识信息写入码流,所述标识信息用于指示预测模式。
在一些示例性实施例中,所述第一属性包括以下至少一种:反射率信息,颜色信息。
在一些示例性实施例中,所述第一预测模式包括以下至少一种:使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。
在一些示例性实施例中,所述使用邻居点属性加权平均值作为预测值,包括:
使用M个邻居点属性加权平均值作为预测值,M取值为大于1的正整数。
在一些示例性实施例中,使用邻居点之一的属性值作为预测值,包括:
使用当前点的第N个邻居点的属性值作为预测值,N取值为正整数。
在一些示例性实施例中,所述M个邻居点包括所述当前点的前P个邻居点中的至少部分邻居点,P≥M。
在一些示例性实施例中,所述当前点的邻居点包括R个邻居点,R取值为大于1的正整数。
在一些示例性实施例中,M可以取值为3、4或者5。
在一些示例性实施例中,N可以取值为1、2或3。
在一些示例性实施例中,R可以取值为3、4或5。
在一些示例性实施例中,该方法还包括:
当所述第一参数不小于阈值时,采用率失真优化RDO选择第二预测模式;
使用所述第二预测模式确定所述当前点的第一属性的预测值;
将所述第二预测模式的标识信息写入码流,所述标识信息用于指示预测模式。
在一些示例性实施例中,所述第二预测模式包括以下至少一种:
使用邻居点属性加权平均值作为预测值;使用邻居点之一的属性值作为预测值。
在一些示例性实施例中,所述使用邻居点属性加权平均值作为预测值,包括:
使用S个邻居点属性加权平均值作为预测值,S取值为大于1的正整数,对应的标识信息为预设索引值且具有全局唯一性。
在一些示例性实施例中,使用邻居点之一的属性值作为预测值,包括:
使用当前点的第T个邻居点的属性值作为预测值,T取值为正整数,对应的标识信息是第T个邻居点的索引值。
在一些示例性实施例中,所述S个邻居点包括所述当前点的前U个邻居点中的至少部分邻居点,U≥S。
在一些示例性实施例中,S可以为3、4或5。
在一些示例性实施例中,T可以取值为1、2或3。
在一些示例性实施例中,U可以取值为3、4或5。
本公开一示例性实施例提供了一种编码方法,如图10所示,包括:
步骤1001,确定待编码点云中当前点的邻居点,根据所述邻居点计算第一参数;所述第一参数为所述邻居点的第一属性的重建值中最大值与最小值的差值;
其中,针对当前点的邻居点以及第一参数的相关内容,与上述实施例相同,在此不再赘述。
步骤1002,判断所述第一参数是否小于阈值;
在一些示例中,该阈值可以预先设定。例如,可以预先设定颜色信息对应的阈值,当第一属性为颜色信息时,判断第一参数是否小于颜色信息的阈值。又例如,可以预先设定反射率信息对应的阈值,当第一属性为反射率信息时,判断第一参数是否小于反射率信息的阈值。
当所述第一参数小于阈值时,执行步骤1003至步骤1005,当所述第一参数不小于阈值时,执行步骤1006至步骤1008:
步骤1003,使用预先设置的第一预测模式确定所述当前点的第一属性的预测值;
其中,针对第一预测模式的相关内容,与上述实施例相同,在此不再赘述。
其中,针对第二预测模式的相关内容,与上述实施例相同,在此不再赘述。
步骤1004,计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
步骤1005,对量化后的所述残差值进行编码;将所述第一预测模式的标识信息写入码流,所述标识信息用于指示预测模式;
其中,针对标识信息的相关内容,与上述实施例相同,在此不再赘述。
步骤1006,采用率失真优化RDO选择第二预测模式;使用所述第二预测模式确定所述当前点的第一属性的预测值;
步骤1007,计算所述当前点的第一属性的原始值与所述预测值的差值,作为所述当前点的第一属性的残差值;
步骤1008,对量化后的所述残差值进行编码;将所述第二预测模式的标识信息写入码流,所述标识信息用于指示预测模式。
其中,针对标识信息的相关内容,与上述实施例相同,在此不再赘述。
本公开实施例提供了一种解码方法,如图11所示,该方法包括:
步骤1101,解析码流,获得待解码点云中当前点的预测模式的标识信息;
步骤1102,使用所述标识信息指示的预测模式确定所述当前点的第一属性的预测值;
步骤1103,解析码流,获得所述当前点的第一属性的残差值;
步骤1104,计算所述残差值反量化后与所述预测值相加的和值,作为所述当前点的第一属性的重建值。
在一些示例性实施例中,所述第一属性包括以下至少一种:反射率信息,颜色信息。
在一些示例性实施例中,当所述标识信息为预设索引值时,将邻居点属性加权平均值作为所述当前点的预测值;
当所述标识信息为所述预设索引值之外的其他索引值时,使用邻居点之一的属性值作为所述当前点的预测值。
在一些示例性实施例中,使用邻居点属性加权平均值作为所述当前点的预测值,包括:
使用X个邻居点属性加权平均值作为预测值,X取值为大于1的正整数。
其中,针对将邻居点属性加权平均值作为的预测值的相关内容,与上述实施例相同,在此不再赘述。
在一些示例性实施例中,使用邻居点之一的属性值作为所述当前点的预测值,包括:
使用第Y个邻居点的属性值作为所述当前点的预测值,Y为所述标识信息对应的索引值。Y取值为正整数。
其中,针对使用邻居点之一的属性值作为的预测值的相关内容,与上述实施例相同,在此不再赘述。
本公开一示例性实施例提供了一种编码方法,包括:
步骤1,确定当前点的相邻点,根据相邻点计算maxDiff;
步骤2,当maxDiff<阈值时,使用“邻居点属性值加权平均的预测模式”确定当前点的预测值,编码器将该模式序号写入码流(即对应于表1中的Predictor index等于0的模式索引序号);反之,当maxDiff>=阈值时,使用RDO的方法,从相邻候选点中选择之一,将该选择的点的值作为当前点的预测值,编码器将指示该相邻点的模式索引序号写入码流(即对应于表1中的Predictor index不等于0的模式索引序号1、2、3)。
在一些示例中,用于计算maxDiff的相邻点(“相邻点集合A”)、用于计算“maxDiff<阈值”时的加权平均值使用的相邻点(“相邻点集合B”)、用于“maxDiff>=阈值”时RDO确定当前点预测值过程中使用的相邻候选点(“相邻点集合C”),三个集合可以是由不同数量的点组成的。例如:按照与当前点之间的距离,选择前5个最近邻点来作为集合A和B,但在C时,可以使用前3个最近邻来构造3种“maxDiff>=阈值”下的预测模式。
本公开一示例性实施例提供了一种解码方法,包括:
步骤1,确定当前点的相邻点;
步骤2,解析码流,得到当前点的模式索引序号;
其中,该模式索引序号是指预测模式的标识信息。
步骤3,当模式索引序号指示使用“邻居点属性值加权平均的预测模式”时,使用相邻点计算当前点的预测值;反之,当模式索引序号指示使用“邻居点的属性值确定当前点的预测值”时,解码器将当前点的预测值设置为等于所述模式索引序号指示的相邻点的属性值。(例如:模式索引序号index指示的是按欧氏距离,相邻点中第index个与当前点最临近的点)。
本公开一示例性实施例提供了一种解码方法,包括:
步骤1,解析码流,得到当前点的模式索引序号;
步骤2,当模式索引序号指示使用“邻居点属性值加权平均的预测模式”时,确定当前点的相邻点,使用相邻点计算当前点的预测值;反之,
步骤3,当模式索引序号指示使用“邻居点的属性值确定当前点的预测值”时,确定当前点的相 邻点,解码器将当前点的预测值设置为等于所述模式索引序号指示的相邻点的属性值。(例如:模式索引序号index指示的是按欧氏距离,相邻点中第index个与当前点最临近的点)。
在本示例性实施例中,先确定预测模式,再根据预测模式获取相邻点,避免获取的相邻点是用不上的,从而避免了浪费资源。
本公开一示例性实施例提供了一种编码方法,包括:
步骤1,确定当前点的相邻点,根据相邻点计算maxDiff;
步骤2,当maxDiff<阈值时,使用“邻居点属性值加权平均的预测模式”确定当前点的预测值,这种情况下,编码器不需要将该模式序号写入码流(即对应于表1中的Predictor index等于0的模式索引序号);反之,当maxDiff>=阈值时,使用RDO的方法,从相邻候选点中选择之一,将该选择的点的值作为当前点的预测值,编码器将指示该相邻点的模式索引序号写入码流(即对应于表1中的Predictor index不等于0的模式索引序号1、2、3)。
本公开一示例性实施例提供了一种解码方法,包括:
步骤1,确定当前点的相邻点,计算第一参数(即maxDiff)的取值;
步骤2,当maxDiff的Y取值为正整数。小于阈值时,则使用“邻居点属性值加权平均的预测模式”计算当前点的预测值(即对应于表1中的Predictor index等于0的模式索引序号);这里,解码器根据已有解码信息来推导当前点的模式信息,不需要解析码流来获得模式信息;反之;
步骤3,当maxDiff的取值大于阈值时,解码器解析码流,获得模式索引序号;解码器将当前点的预测值设置为等于所述模式索引序号指示的相邻点的属性值。
本公开实施例还提供了一种编码器,如图12所示,包括:处理器以及存储有可在所述处理器上运行的计算机程序的存储器,其中,所述处理器执行所述计算机程序时实现上述任一项所述的编码方法。
在一些示例中,如图13所示,编码器的处理流程包括:对当前点的邻居点集计算其属性值的最大差异maxDiff(即第一参数),判断maxDiff是否<阈值,当maxDiff<阈值时,选择预先设置的第一预测模式preMode计算点云属性预测值,否则执行RDO选择第二预测模式计算点云属性预测值,计算点云属性残差,当没有选择RDO选择的预测模式时,编码残差写入属性码流,当选择RDO选择的预测模式时,编码预测模式(即将预测模式的标识信息写入码流,例如选择的第二预测模式为预测模式1时,将preMode1写入码流)以及编码残差,将编码的码字写入属性码流。在一示例中,第一预测模式preMode可以为表1所示的预测模式0、1、2、3中的一种,RDO可以从预测模式1、2、3中选择一种作为第二预测模式。
本公开实施例还提供了一种解码器,如图14所示,包括:处理器以及存储有可在所述处理器上运行的计算机程序的存储器,其中,所述处理器执行所述计算机程序时实现上述任一项所述的解码方法。
在一示例中,如图15所示,解码器的处理流程包括:获得属性码流,解码残差,对当前点的邻居点集计算其属性值的最大差异maxDiff(即第一参数),判断maxDiff是否<阈值,当maxDiff< 阈值时,选择预先设置的第一预测模式preMode计算点云属性预测值,否则解码预测模式(即解析获得预测模式的标识信息),采用解码获得的预测模式preMode(即标识信息指示的预测模式)计算点云属性预测值,根据残差和预测值计算点云重建属性值,以重建点云。在一示例中,第一预测模式preMode可以为表1所示的预测模式0、1、2、3中的一种。
本公开实施例还提供了一种终端,包括:点云编解码器,所述点云编解码器包括上述的编码器,和/或上述的解码器。
本公开实施例还提供了一种编解码系统,包括:点云编解码器,所述点云编解码器包括上述的编码器,和/或上述的解码器。
本公开实施例提供的技术方案,避免了编解码的过程中产生逻辑错误,导致预测结果也可能存在偏差导致编解码性能不高的问题。例如采用本公开实施例在G-PCC参考软件TMC13 V12.0上实现后,在CTC CY测试条件下对MPEG要求的cat3-fused测试集中测试序列进行测试得到的测试结果为端到端速率百分比(End to End BD-AttrRate%)为-0.1%,表明采用本公开实施例提供的技术方案可以有效提高编解码性能。
图16为一种编码设备的框架示意图,如图16所示,编码设备1可以包括处理器101、存储器103和总线系统104。处理器101和存储器103通过总线系统104相连,该存储器103用于存储指令,该处理器101用以执行本公开描述的任一项预测方法、编码方法或者解码方法。
该处理器101可以是中央处理单元(central processing unit,CPU),该处理器101还可以是其他通用处理器、DSP、ASIC、FPGA或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
该存储器103可以包括ROM设备或者RAM设备。任何其他适宜类型的存储设备也可以用作存储器103。存储器103可以包括由处理器101使用总线104访问的代码和数据。
该总线系统104除包括数据总线之外,还可以包括电源总线、控制总线和状态信号总线等。在图中可以将各种总线都标为总线系统104。
编码设备1还可以包括一个或多个输出设备,例如显示器102。该显示器102可以是触感显示器,其将显示器与可操作地感测触摸输入的触感合并。显示器102可以经由总线104连接到处理器101。
在一或多个示例性实施例中,所描述的功能可以硬件、软件、固件或其任一组合来实施。如果以软件实施,那么功能可作为一个或多个指令或代码存储在计算机可读介质上或经由计算机可读介质传输,且由基于硬件的处理单元执行。计算机可读介质可包含对应于例如数据存储介质等有形介质的计算机可读存储介质,或包含促进计算机程序例如根据通信协议从一处传送到另一处的任何介质的通信介质。以此方式,计算机可读介质通常可对应于非暂时性的有形计算机可读存储介质或例如信号或载波等通信介质。数据存储介质可为可由一或多个计算机或者一或多个处理器存取以检索用于实施本发明中描述的技术的指令、代码和/或数据结构的任何可用介质。计算机程序产品可包含计算机可读介质。
举例来说且并非限制,此类计算机可读存储介质可包括RAM、ROM、EEPROM、CD-ROM或其它光盘存储装置、磁盘存储装置或其它磁性存储装置、快闪存储器或可用来以指令或数据结构的形式存储所要程序代码且可由计算机存取的任何其它介质。而且,还可以将任何连接称作计算机可读介质举例来说,如果使用同轴电缆、光纤电缆、双绞线、数字订户线(DSL)或例如红外线、无线电及微波等无线技术从网站、服务器或其它远程源传输指令,则同轴电缆、光纤电缆、双纹线、DSL或例如红外线、无线电及微波等无线技术包含于介质的定义中。然而应了解,计算机可读存储介质和数据存储介质不包含连接、载波、信号或其它瞬时(瞬态)介质,而是针对非瞬时有形存储介质。如本文中 所使用,磁盘及光盘包含压缩光盘(CD)、激光光盘、光学光盘、数字多功能光盘(DVD)、软磁盘或蓝光光盘等,其中磁盘通常以磁性方式再生数据,而光盘使用激光以光学方式再生数据。上文的组合也应包含在计算机可读介质的范围内。
可由例如一或多个数字信号理器(DSP)、通用微处理器、专用集成电路(ASIC)现场可编程逻辑阵列(FPGA)或其它等效集成或离散逻辑电路等一或多个处理器来执行指令。因此,如本文中所使用的术语“处理器”可指上述结构或适合于实施本文中所描述的技术的任一其它结构中的任一者。另外,在一些方面中,本文描述的功能性可提供于经配置以用于编码和解码的专用硬件和/或软件模块内,或并入在组合式编解码器中。并且,可将所述技术完全实施于一个或多个电路或逻辑元件中。
本公开实施例的技术方案可在广泛多种装置或设备中实施,包含无线手机、集成电路(IC)或一组IC(例如,芯片组)。本公开实施例中描各种组件、模块或单元以强调经配置以执行所描述的技术的装置的功能方面,但不一定需要通过不同硬件单元来实现。而是,如上所述,各种单元可在编解码器硬件单元中组合或由互操作硬件单元(包含如上所述的一个或多个处理器)的集合结合合适软件和/或固件来提供。
本领域普通技术人员可以理解,上文中所公开方法中的全部或某些步骤、系统、装置中的功能模块/单元可以被实施为软件、固件、硬件及其适当的组合。在硬件实施方式中,在以上描述中提及的功能模块/单元之间的划分不一定对应于物理组件的划分;例如,一个物理组件可以具有多个功能,或者一个功能或步骤可以由若干物理组件合作执行。某些组件或所有组件可以被实施为由处理器,如数字信号处理器或微处理器执行的软件,或者被实施为硬件,或者被实施为集成电路,如专用集成电路。这样的软件可以分布在计算机可读介质上,计算机可读介质可以包括计算机存储介质(或非暂时性介质)和通信介质(或暂时性介质)。如本领域普通技术人员公知的,术语计算机存储介质包括在用于存储信息(诸如计算机可读指令、数据结构、程序模块或其他数据)的任何方法或技术中实施的易失性和非易失性、可移除和不可移除介质。计算机存储介质包括但不限于RAM、ROM、EEPROM、闪存或其他存储器技术、CD-ROM、数字多功能盘(DVD)或其他光盘存储、磁盒、磁带、磁盘存储或其他磁存储装置、或者可以用于存储期望的信息并且可以被计算机访问的任何其他的介质。此外,本领域普通技术人员公知的是,通信介质通常包含计算机可读指令、数据结构、程序模块或者诸如载波或其他传输机制之类的调制数据信号中的其他数据,并且可包括任何信息递送介质。
- 存储设备测试方法、存储设备测试系统及存储介质
- 异构虚拟计算资源的管理方法、相关设备及存储介质
- 数据处理方法、相关设备及计算机存储介质
- 光效显示方法、相关设备及存储介质
- 信息传输方法、装置、相关设备及计算机可读存储介质
- 视频编解码方法、相关编解码器和计算机可读存储介质
- 帧内帧间联合预测方法、编解码方法及相关设备、存储介质