一种核酸合成仪数据编码处理方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及数据处理技术领域,具体涉及一种核酸合成仪数据编码处理方法。
背景技术
在核酸合成仪工作状态下,需要即时传输的数据包括实时合成进度以及合成参数和状态以及合成质量检测数据等,由于核酸合成仪的工作原理为制备反应体系,其进行互补配对后再进行循环合成,最终不停重复操作进行产物提纯,因此,数据的重复性比较高,且最终的数据表现出不同的频率分布,由此,导致重要的数据在出现频次上具有显著表现,且最终进行数据的即时传输时,需要对数据进行压缩编码,即对于出现频次高的数据采用较短的编码进行数据传输,其通常使用哈夫曼编码进行数据压缩。
现有的问题:传统的哈夫曼编码进行数据编码时,其主要针对数据的出现频率,且由底向上进行编码,并不能具备即时传输的速率要求,以及即时性要求。当核酸合成仪产生新的数据后,会导致新数据传输至数据分析处理中心的速度较慢,从而影响数据分析结果的及时性。
发明内容
本发明提供一种核酸合成仪数据编码处理方法,以解决现有的问题。
本发明的一种核酸合成仪数据编码处理方法采用如下技术方案:
本发明一个实施例提供了一种核酸合成仪数据编码处理方法,该方法包括以下步骤:
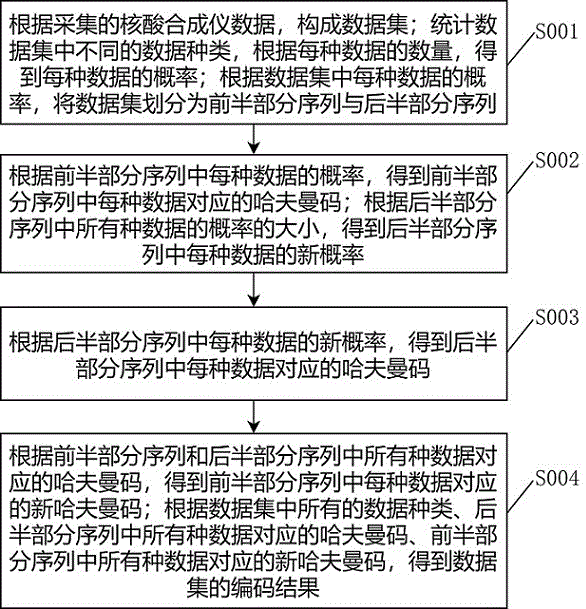
根据采集的核酸合成仪数据,构成数据集;统计数据集中不同的数据种类,根据每种数据的数量,得到每种数据的概率;根据数据集中每种数据的概率,将数据集划分为前半部分序列与后半部分序列;
根据前半部分序列中每种数据的概率,得到前半部分序列中每种数据对应的哈夫曼码;根据后半部分序列中所有种数据的概率的大小,得到后半部分序列中每种数据的新概率;
根据后半部分序列中每种数据的新概率,得到后半部分序列中每种数据对应的哈夫曼码;
根据前半部分序列和后半部分序列中所有种数据对应的哈夫曼码,得到前半部分序列中每种数据对应的新哈夫曼码;根据数据集中所有的数据种类、后半部分序列中所有种数据对应的哈夫曼码、前半部分序列中所有种数据对应的新哈夫曼码,得到数据集的编码结果。
进一步地,所述根据每种数据的数量,得到每种数据的概率,包括的具体步骤如下:
在数据集中,将每种数据的数量除以数据集中的数据数量,记为每种数据的概率。
进一步地,所述根据数据集中每种数据的概率,将数据集划分为前半部分序列与后半部分序列,包括的具体步骤如下:
在数据集中,根据每种数据的概率,由小到大对所有种数据进行排序,得到数据种类序列;
将数据种类序列划分为前半部分序列与后半部分序列。
进一步地,所述将数据种类序列划分为前半部分序列与后半部分序列,包括的具体步骤如下:
当数据种类序列中的数据数量为偶数时,依次根据数据种类序列中前
当数据种类序列中的数据数量为奇数时,依次根据数据种类序列中前
所述x为数据种类序列中的数据数量,
进一步地,所述根据前半部分序列中每种数据的概率,得到前半部分序列中每种数据对应的哈夫曼码,包括的具体步骤如下:
在前半部分序列中,根据每种数据的概率,使用哈夫曼编码算法对每种数据进行编码,得到前半部分序列中每种数据对应的哈夫曼码。
进一步地,所述根据后半部分序列中所有种数据的概率的大小,得到后半部分序列中每种数据的新概率,包括的具体步骤如下:
在后半部分序列中,将最后一种数据的概率,记为第一种数据的新概率;将倒数第二种数据的概率,记为第二种数据的新概率;以此类推,直至将第一种数据的概率,记为最后一种数据的新概率。
进一步地,所述根据后半部分序列中每种数据的新概率,得到后半部分序列中每种数据对应的哈夫曼码,包括的具体步骤如下:
在后半部分序列中,根据每种数据的新概率,使用哈夫曼编码算法对每种数据进行编码,得到后半部分序列中每种数据对应的哈夫曼码。
进一步地,所述根据前半部分序列和后半部分序列中所有种数据对应的哈夫曼码,得到前半部分序列中每种数据对应的新哈夫曼码,包括的具体步骤如下:
将前半部分序列中任意一种数据,记为目标数据;将目标数据对应的哈夫曼码,记为目标码;
将后半部分序列中每种数据对应的哈夫曼码,记为参考码;
根据目标码与所有参考码之间的差异,得到目标数据对应的新哈夫曼码。
进一步地,所述根据目标码与所有参考码之间的差异,得到目标数据对应的新哈夫曼码,包括的具体步骤如下:
在所有参考码中,若存在与目标码相同的参考码时,在目标码前添加预设的标识符,得到目标数据对应的新哈夫曼码;
若不存在与目标码相同的参考码时,将目标码,记为目标数据对应的新哈夫曼码。
进一步地,所述根据数据集中所有的数据种类、后半部分序列中所有种数据对应的哈夫曼码、前半部分序列中所有种数据对应的新哈夫曼码,得到数据集的编码结果,包括的具体步骤如下:
根据数据集中所有的数据种类、后半部分序列中所有种数据对应的哈夫曼码、前半部分序列中所有种数据对应的新哈夫曼码,构成数据集的新哈夫曼编码表;
根据新哈夫曼编码表对数据集进行编码,得到数据集的编码结果。
本发明的技术方案的有益效果是:
本发明实施例中,采集核酸合成仪数据,得到数据集,并统计数据集中不同的数据种类,将每种数据的数量除以数据集中的数据数量,记为每种数据的概率。根据数据集中所有种数据的概率的大小,得到数据种类序列,并将数据种类序列划分为前半部分序列与后半部分序列。根据后半部分序列中所有种数据的概率的大小,得到后半部分序列中每种数据的新概率,分别根据前半部分序列中每种数据的概率、后半部分序列中每种数据的新概率,使用哈夫曼编码,得到前半部分序列与后半部分序列中每种数据对应的哈夫曼码,从而得到前半部分序列中每种数据对应的新哈夫曼码,其将重复的哈夫曼码通过添加标识符进行区别,保证核酸合成仪数据的传输过程中,数据的编码结果和解码结果唯一。由此获取数据集的新哈夫曼编码表。本发明通过从中间向两边编码的方式,使得在采集的数据量较大时,提高编码速率,并令数据编码过程中,更加灵活,可以降低原有数据的耦合性,以及在新的数据加入时,只需要对部分数据进行重新排列编码,提高编码效率和数据传输速率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种核酸合成仪数据编码处理方法的步骤流程图。
图2为本实施例所提供的一个哈夫曼树对比示意图。
图3为本实施例所提供的一个下半部分哈夫曼树示意图。
图4为本实施例所提供的一个上半部分哈夫曼树示意图。
图5为本实施例所提供的一个概率颠倒示意图。
图6为本实施例所提供的一个新哈夫曼树示意图。
具体实施方式
为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种核酸合成仪数据编码处理方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
下面结合附图具体的说明本发明所提供的一种核酸合成仪数据编码处理方法的具体方案。
请参阅图1,其示出了本发明一个实施例提供的一种核酸合成仪数据编码处理方法的步骤流程图,该方法包括以下步骤:
步骤S001:根据采集的核酸合成仪数据,构成数据集;统计数据集中不同的数据种类,根据每种数据的数量,得到每种数据的概率;根据数据集中每种数据的概率,将数据集划分为前半部分序列与后半部分序列。
哈夫曼编码是一种用于数据压缩的编码方法,它通过分配较短的编码给出现次数较多的数据块,从而实现数据压缩。哈夫曼编码对数据进行编码之前,会根据数据出现概率进行排序,最终完成自底向上的哈夫曼树的构造,压缩率较高,但哈夫曼编码的压缩和解压缩过程相对复杂,需要较多的时间。
对于哈夫曼编码来说,在数据的出现概率波动越大时,压缩率相对于现有的很多压缩算法都要高,例如游程编码、LZ77编码等,但美中不足的是,数据的编码过程较为复杂,也意味着数据编码过程比较慢,这样就导致哈夫曼编码很难应用到即时数据传输中,所以本实施例将针对数据编码速度提升,进行改进,从而达到在哈夫曼编码的时候,速率大幅提升。
对于核酸合成仪数据而言,由于其数据的量较大,且如果直接进行数据编码的话,最终的编码速率并未提升,因此需要对数据编码方式做出改变。
所需说明的是:哈夫曼树的构造是叶子节点向根节点走,本实施例采用从中间向两边的编码方式,并解决编码过程的前缀重复问题,其将根节点变为虚根节点,但总体还是一个哈夫曼树,确定新的编码顺序和逻辑。哈夫曼编码是自底向上编码,最终产生的哈夫曼树为一个三角形形状,而从中间向两边编码最终产生的哈夫曼树则是一个漏斗形状的哈夫曼树。图2为本实施例所提供的一个哈夫曼树对比示意图。图2中左侧三角形,表示传统哈夫曼算法构成的哈夫曼树,右侧漏斗形状,表示本实施例改进的哈夫曼算法构成的哈夫曼树。图2中的子节点、根节点、虚根节点都为哈夫曼树上的节点,将图2中的虚根节点,记为节点A。节点A既是图2中右侧哈夫曼树中的上半部哈夫曼树的根节点,也是下半部哈夫曼树的根节点,但是由于节点A对于上半部分是结束节点,而对下半部分来说是开始节点,因此并非真正意义上的根节点,所以本实施例中称其为虚根节点。节点A是全部数据经概率从小到大排序后的中间概率,根据节点A划分的上下两部分的概率不同,所以需要根据哈夫曼编码的编码规则:自底向上编码,由概率低向概率高编码,对节点A上下两部分数据进行一个重新的排序。
从中间向两边编码是新的编码顺序,但最基本的编码逻辑还是采用哈夫曼编码的逻辑,因此需要将哈夫曼树的构造优先进行考虑,由原始哈夫曼编码构造的哈夫曼树可以知道,哈夫曼树对于每一个数据最终的编码都是唯一的,且避免了前缀相同导致的解码困难,本实施例的哈夫曼树构造的新哈夫曼树为漏斗型,由编码过程可以得出,上下两棵树中,编码结束会产生的相同编码较多,因此对编码进行一个匹配,将相同编码表示的两个数据中,出现概率较小的数据的编码前面加一个符号位,用于区分概率较大数据的编码。而将节点A转化为概率较小数据哈夫曼树的子节点,这样可以直接进行编码。
对于核酸合成仪数据,如果出现编码或解码过程的错误,则会导致数据的错乱,以至于实验结果出现误差,实验数据作废,浪费大量的时间以及人力资源进行重新的实验,因此在提升数据编码速度的同时,则需要进行数据的编码准确率提升,而对于霍夫曼编码而言,在不发生计算错误的前提下,从两边进行编码最终的编码错误只能出现在编码的前缀相同,导致最终的解码出错,进一步使得所有的实验数据出错。
因此首先根据采集的核酸合成仪数据,构成数据集。统计数据集中不同的数据种类,将每种数据的数量除以数据集中的数据数量,记为每种数据的概率。
在数据集合中,根据每种数据的概率,由小到大对所有种数据进行排序,得到数据种类序列。
当数据种类序列中的数据数量为偶数时,依次根据数据种类序列中前
当数据种类序列中的数据数量为奇数时,依次根据数据种类序列中前
其中x为数据种类序列中的数据数量,
步骤S002:根据前半部分序列中每种数据的概率,得到前半部分序列中每种数据对应的哈夫曼码;根据后半部分序列中所有种数据的概率的大小,得到后半部分序列中每种数据的新概率。
在前半部分序列中,根据每种数据的概率,使用哈夫曼编码算法对每种数据进行编码,得到前半部分序列中每种数据对应的哈夫曼码。其中,哈夫曼编码算法为公知技术,具体方法在此不做介绍。
所需说明的是:对于节点A,上部分是出现概率较大的数据节点,下半部分是概率较小的数据节点,因此对于图2中右侧的哈夫曼树中的下半部哈夫曼树来说,是没有影响的。图3为本实施例所提供的一个下半部分哈夫曼树示意图。图3中节点A、a、b、c、d、e分别为图2中右侧的哈夫曼树上的节点,并且本实施例以a、b、c、d对应的概率为0.05,e对应的概率为0.1为例进行叙述,其它实施方式中可设置为其它值,本实施例不进行限定。但对于图2中右侧的哈夫曼树中的上半部哈夫曼树来说,概率排序顺序是反的,因此变为了大概率向小概率编码。图4为本实施例所提供的一个上半部分哈夫曼树示意图。图4中节点A、f、g、h、i分别为图2中右侧的哈夫曼树上的节点,并且本实施例以f、g对应的概率为0.15,h、i对应的概率为0.2为例进行叙述,其它实施方式中可设置为其它值,本实施例不进行限定。
故图4中的哈夫曼树的子节点的概率大,而根节点的概率小,需要采用概率颠倒方式进行转换,如图5曲线箭头部分。图5为本实施例所提供的一个概率颠倒示意图。图5中m、n、p、q分别为图2中右侧的哈夫曼树上的节点。图5直线箭头部分,表示q、p、n、m对应的概率由小到大的顺序。将概率小的节点概率值赋给概率大的节点,在图5中,将概率大的节点m的概率值赋给概率小的节点q,n和p也同样,这样就是节点顺序不变的情况下,概率值发生变化,符合哈夫曼编码的由概率小的节点向概率大的节点编码。已知核酸合成仪数据中概率较大的数据为重要数据,哈夫曼编码会赋予其较短的编码,在数据传送中,较短的编码易造成数据丢失,难以复原,因此本实施例令概率较大的后半部分序列中,赋予较大概的数据相对较长的编码,用以保护重要数据的安全性。若对数据集中的数据概率进行颠倒,易导致概率较大的数据对应的编码过长,影响压缩效率。
因此在后半部分序列中,将最后一种数据的概率,记为第一种数据的新概率;将倒数第二种数据的概率,记为第二种数据的新概率;以此类推,直至将第一种数据的概率,记为最后一种数据的新概率。
由此得到后半部分序列中每种数据的新概率。
步骤S003:根据后半部分序列中每种数据的新概率,得到后半部分序列中每种数据对应的哈夫曼码。
在后半部分序列中,根据每种数据的新概率,使用哈夫曼编码算法对每种数据进行编码,得到后半部分序列中每种数据对应的哈夫曼码。
所需说明的是:在根据新的哈夫曼树进行编码时,前半部分序列与后半部分序列中每种数据对应的哈夫曼码中,会出现编码重复的问题。图6为本实施例所提供的一个新哈夫曼树示意图。图6中q、w、e、r、t、y、u、i分别为图2中右侧的哈夫曼树上的节点,并且本实施例设定的图6中节点q和i的哈夫曼码为00;节点w和u的哈夫曼码为01;节点e和y的哈夫曼码为10;节点r和t的哈夫曼码为11,以此为例进行叙述,其它实施方式中可设置为其它值,本实施例不进行限定。
因此图6中为了避免哈夫曼码的重复,需要对相同两个节点的其中一个加一个标识符,经过分析,对于新构建的哈夫曼树有,树的下半部分为出现概率较小的节点,因此需要对其采用较长的哈夫曼编码,所以对于下半部分的节点加标识符,对于压缩率的影响是小于对上半部分的节点加标识符的,可以实现压缩率的提升。
步骤S004:根据前半部分序列和后半部分序列中所有种数据对应的哈夫曼码,得到前半部分序列中每种数据对应的新哈夫曼码;根据数据集中所有的数据种类、后半部分序列中所有种数据对应的哈夫曼码、前半部分序列中所有种数据对应的新哈夫曼码,得到数据集的编码结果。
已知哈夫曼编码过程中,由于相同概率节点相加顺序是随机的,所以前半部分序列与后半部分序列中每种数据对应的哈夫曼码并不一定会全重复,所以需要首先确定有重复的哈夫曼码。
将前半部分序列中任意一种数据,记为目标数据;将目标数据对应的哈夫曼码,记为目标码。
将后半部分序列中每种数据对应的哈夫曼码,记为参考码。
本实施例设定的标识符为“-”,以此为例进行叙述,其它实施方式中可设置为其它标识符,本实施例不进行限定。
在所有参考码中,若存在与目标码相同的参考码时,在目标码前添加标识符,得到目标数据对应的新哈夫曼码。
若不存在与目标码相同的参考码时,将目标码,记为目标数据对应的新哈夫曼码。
按照上述方式,得到前半部分序列中每种数据对应的新哈夫曼码。
所需说明的是:例如目标码为00110,则在目标码前添加标识符后的新哈夫曼码为-00110。由此解决了新构建的哈夫曼树中的哈夫曼编码重复问题。
根据数据种类序列中所有数据种类、后半部分序列中所有种数据对应的哈夫曼码、前半部分序列中所有种数据对应的新哈夫曼码,构成数据集的新哈夫曼编码表。即数据集中每种数据对应唯一的一个哈夫曼编码。根据新哈夫曼编码表对数据集进行编码,得到数据集的编码结果。
至此,完成核酸合成仪数据的编码处理。
所需说明的是:在核酸合成仪数据中,则需要考虑数据的即时性要求,例如实验结果的即时性传输优先级高于实验的效率等实验数据,基团耗尽程度和其余参数的即时传输优先级则高于实验次数以及实验报告等数据。本实施例中将数据集划分为两部分,分别进行哈夫曼编码,再进行重组,获取新哈夫曼编码表。因此可以利用多线程或者多台电脑同步对划分的两部分进行编码,提升压缩速率。并且当新的数据加入时,只需要改变图2中节点A上或者下半部分的哈夫曼树结构就可以,也就是说只需要对一半的数据进行重新排列编码。
至此,本发明完成。
综上所述,在本发明实施例中,采集核酸合成仪数据,得到数据集,并统计数据集中不同的数据种类,将每种数据的数量除以数据集中的数据数量,记为每种数据的概率。根据数据集中所有种数据的概率的大小,得到数据种类序列,并将数据种类序列划分为前半部分序列与后半部分序列。根据后半部分序列中所有种数据的概率的大小,得到后半部分序列中每种数据的新概率,分别根据前半部分序列中每种数据的概率、后半部分序列中每种数据的新概率,使用哈夫曼编码,得到前半部分序列与后半部分序列中每种数据对应的哈夫曼码,从而得到前半部分序列中每种数据对应的新哈夫曼码,由此获取数据集的新哈夫曼编码表。本发明通过从中间向两边编码的方式,保证核酸合成仪数据的传输过程中,不仅提升数据的即时传输速率,并且保障数据的编码结果和解码结果唯一,提升正确率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种HPV分型核酸检测血样标本处理方法
- 一种核糖核酸提取时的前处理方法
- 一种用于提高核酸合成一致性的辅助装置及核酸合成仪
- 一种便于与核酸合成仪拆卸的合成柱