一种车辆数据的备份方法、电子设备及计算机存储介质
文献发布时间:2024-04-18 19:58:26
技术领域
本申请属于车辆技术领域,尤其涉及一种车辆数据的备份方法、电子设备及计算机存储介质。
背景技术
随着车辆配备的环境感知传感器等硬件逐渐增加,车辆端产生的数据量也越来越大。由于车辆端的存储能力有限,需要把车载传感器周期性采集的车辆数据传输到云端进行存储备份。Kafka是由Apache软件基金会开发的开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,其性能卓越可靠性强,支持高并发高可用,且可伸缩、可扩展、容错性好,可将周期性采集的车辆数据暂存到Kafka组件中,通过消费Kafka组件中存储的车辆数据,将车辆数据传输到云端进行存储备份。
鉴于Kafka组件的高吞吐量,如何及时可靠地消费Kafka组件里存储的车辆数据,提高车辆数据在云端的存储备份效率,并降低车辆数据在云端的存储备份成本,成了亟待解决的问题。
发明内容
针对上述技术问题,本申请提供一种车辆数据的备份方法、电子设备及计算机存储介质,能够提高车辆数据在云端的存储备份效率,并降低车辆数据在云端的存储备份成本。
本申请提供了一种车辆数据的备份方法,包括:获取车辆数据,并将所述车辆数据存储到Kafka组件的第一存储单元中;从所述Kafka组件的第一存储单元中读取所述车辆数据,并对所述车辆数据进行解析分类;将解析分类后的车辆数据通过Flume组件同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,以对所述车辆数据进行备份。
在一实施方式中,所述从所述Kafka组件的第一存储单元中读取所述车辆数据,并对所述车辆数据进行解析分类的步骤,包括:通过至少两个解析分类器从所述Kafka组件的第一存储单元中同步读取不同的第一目标车辆数据,并对所述不同的第一目标车辆数据进行解密、验证及分类,以对所述车辆数据进行解析分类。
在一实施方式中,所述Flume组件包括第一数据传输链路及第二数据传输链路;所述将解析分类后的车辆数据通过Flume组件同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,以对所述车辆数据进行备份的步骤,包括:通过所述第一数据传输链路,将所述解析分类后的车辆数据存储至所述OSS对象存储组件中,以对所述车辆数据进行冷备份;通过所述第二数据传输链路,将所述解析分类后的车辆数据存储至所述Elasticsearch搜索引擎中,以对所述车辆数据进行热备份。
在一实施方式中,在所述将解析分类后的车辆数据通过Flume组件同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,以对所述车辆数据进行备份的步骤之前,包括:将所述解析分类后的车辆数据存储到所述Kafka组件的第二存储单元中。
在一实施方式中,所述第一数据传输链路由Source组件、第一Channel组件及第一Sink组件构成;所述通过所述第一数据传输链路,将所述解析分类后的车辆数据存储至所述OSS对象存储组件中,以对所述车辆数据进行冷备份的步骤,包括:通过所述Source组件从所述Kafka组件的第二存储单元中读取所述解析分类后的车辆数据,并将所述解析分类后的车辆数据发送至所述第一Channel组件中进行缓存;通过所述第一Sink组件读取所述第一Channel组件中缓存的所述解析分类后的车辆数据,并将所述解析分类后的车辆数据存储至所述OSS对象存储组件中,以对所述车辆数据进行冷备份。
在一实施方式中,所述第二数据传输链路由Source组件、第二Channel组件及第二Sink组件构成;所述通过所述第二数据传输链路,将所述解析分类后的车辆数据存储至所述Elasticsearch搜索引擎中,以对所述车辆数据进行热备份的步骤,包括:通过所述Source组件从所述Kafka组件的第二存储单元中读取所述解析分类后的车辆数据,并将所述解析分类后的车辆数据发送至所述第二Channel组件中进行缓存;通过所述第二Sink组件读取所述第二Channel组件中缓存的所述解析分类后的车辆数据,并将所述解析分类后的车辆数据存储至所述Elasticsearch搜索引擎中,以对所述车辆数据进行热备份。
在一实施方式中,所述将所述解析分类后的车辆数据存储至所述OSS对象存储组件中,以对所述车辆数据进行冷备份,包括:将不同类型的车辆数据存储至所述OSS对象存储组件中不同的文件系统目录中,以对所述车辆数据进行冷备份。
在一实施方式中,所述将所述解析分类后的车辆数据存储至所述Elasticsearch搜索引擎中,以对所述车辆数据进行热备份,包括:根据索引模板创建所述Elasticsearch搜索引擎中存储的第二目标车辆数据的索引,并配置所述索引的生命周期;根据所述索引的生命周期,删除所述Elasticsearch搜索引擎中存储的第二目标车辆数据,以对所述车辆数据进行热备份。
本申请还提供了一种电子设备,所述电子设备包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述车辆数据的备份方法的步骤。
本申请还提供了一种计算机存储介质,所述计算机存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述车辆数据的备份方法的步骤。
本申请提供的一种车辆数据的备份方法、电子设备及计算机存储介质,通过对Kafka组件中存储的车辆数据进行解析分类,并通过Flume组件将解析分类后的车辆数据同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,能够提高车辆数据在云端的存储备份效率,并降低车辆数据在云端的存储备份成本。
附图说明
图1是本申请实施例一提供的车辆数据的备份方法的流程示意图;
图2是本申请实施例一提供的车辆数据的备份方法的具体流程示意图;
图3是本申请实施例二提供的电子设备的结构示意图。
具体实施方式
以下结合说明书附图及具体实施例对本申请技术方案做进一步的详细阐述。除非另有定义,本申请所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中在本申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本申请。本文所使用的“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
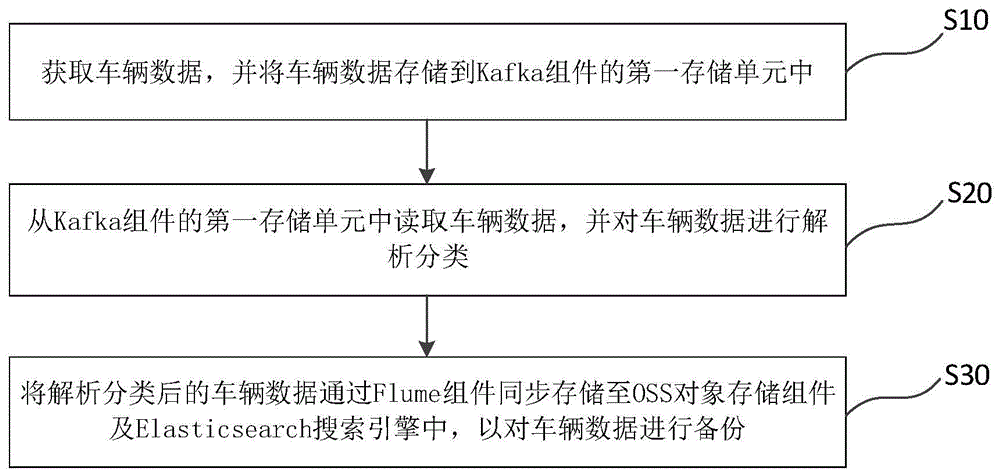
图1是本申请实施例一提供的车辆数据的备份方法的流程示意图。如图1所示,本申请的车辆数据的备份方法,可以包括如下步骤:
步骤S10:获取车辆数据,并将车辆数据存储到Kafka组件的第一存储单元中;
步骤S20:从Kafka组件的第一存储单元中读取车辆数据,并对车辆数据进行解析分类;
步骤S30:将解析分类后的车辆数据通过Flume组件同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,以对车辆数据进行备份。
本申请实施例一提供的车辆数据的备份方法,通过Flume组件将解析分类后的车辆数据同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,能够提高车辆数据在云端的存储备份效率,并降低车辆数据在云端的存储备份成本。
其中,Flume是由Cloudera提供的一种高可靠高可用的日志收集系统,用于高效收集聚合分布式的海量日志,支持定制各类数据发送方和接收方,Flume的核心角色是Flumeagent(Flume中最简单的部署单元),其包括Source组件、Channel组件及Sink组件,其中,Source为来源,用于接收数据,可处理各种类型、各种格式的日志数据,Channel为通道,是一个储存Source接收到的数据的缓存区,支持内存、硬盘或Kafka等存储设施,Sink为水槽,用于把Channel中缓存的数据发送到指定的地方,例如HDFS,Elasticsearch等。在Sink组件将Channel组件中缓存的数据成功发送出去之后,Channel组件才会将临时存放的数据删除,能够保证数据传输的可靠性与安全性。OSS是由阿里云提供的一款海量、安全、低成本、高可靠的云存储服务,提供最高可达99.995%的服务可用性,支持多种存储类型。Elasticsearch是一种由Elastic公司基于Apache Lucene构建的强大的分布式搜索引擎,能够存储数据并具有快速检索及分析数据的能力。
在一实施方式中,步骤S20:从Kafka组件的第一存储单元中读取车辆数据,并对车辆数据进行解析分类,包括:
通过至少两个解析分类器从Kafka组件的第一存储单元中同步读取不同的第一目标车辆数据,并对不同的第一目标车辆数据进行解密、验证及分类,以对车辆数据进行解析分类。
如图2所示,采用多个解析分类应用程序(如解析分类app1、解析分类app2、解析分类app3),从Kafka组件的第一存储单元(Kafka Topic1)中同步读取不同的第一目标车辆数据,并对各自读取的第一目标车辆数据进行解密、验证及分类,能够提高对车辆数据进行解析分类的效率,进一步提高车辆数据在云端的存储备份效率。
以解析分类app1为例对解密、验证及分类的过程进行说明,解析分类app1消费Kafka Topic1中存储的第一目标车辆数据,然后对第一目标车辆数据进行解密,若解密成功,则对第一目标车辆数据进行验证(如验证第一目标车辆数据的数据时间是否正确、是否有必要的字段等),若验证通过,则将第一目标车辆数据分类为解析成功的车辆数据,若解密失败和/或验证不通过,则将第一目标车辆数据分类为解析失败的车辆数据。
可选地,Flume组件包括第一数据传输链路及第二数据传输链路。
在一实施方式中,步骤S30:将解析分类后的车辆数据通过Flume组件同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,以对车辆数据进行备份,包括:
通过第一数据传输链路,将解析分类后的车辆数据存储至OSS对象存储组件中,以对车辆数据进行冷备份;
通过第二数据传输链路,将解析分类后的车辆数据存储至Elasticsearch搜索引擎中,以对车辆数据进行热备份。
其中,第一数据传输链路与第二数据传输链路传输的数据是完全一样的,通过第一数据传输链路传输到OSS对象存储组件中的数据可永久保存,即对车辆数据进行冷备份,可用于后续的审计及数据分析、问题排查等。通过第二数据传输链路传输到Elasticsearch搜索引擎中的数据,基于Elasticsearch计算存储扩容成本的考虑,可定期删除其存储的数据,只保留最新的部分数据,即对车辆数据进行热备份,可用于运营人员针对时效性数据的查询及搜索。
在一实施方式中,在将解析分类后的车辆数据通过Flume组件同步存储至OSS对象存储组件及Elasticsearch搜索引擎中,以对车辆数据进行备份的步骤之前,包括:
将解析分类后的车辆数据存储到Kafka组件的第二存储单元中。
继续参考图2,解析分类app1、解析分类app2、解析分类app3对各自读取的第一目标车辆数据进行解密、验证及分类后,将解析分类后的第一目标车辆数据发送到Kafka组件的第二存储单元(Kafka Topic2)中进行存储,以将解析分类后的车辆数据存储到KafkaTopic2中。
值得一提的是,通过Kafka Topic2暂存解析分类后的第一目标车辆数据,可充分利用Kafka的特性,提高通过Flume组件将解析后的车辆数据同步存储至OSS对象存储组件及Elasticsearch搜索引擎的可靠性及效率。
可选地,第一数据传输链路由Source组件、第一Channel组件及第一Sink组件构成,第二数据传输链路由Source组件、第二Channel组件及第二Sink组件构成。
在一实施方式中,通过第一数据传输链路,将解析分类后的车辆数据存储至OSS对象存储组件中,以对车辆数据进行冷备份,包括:
通过Source组件从Kafka组件的第二存储单元中读取解析分类后的车辆数据,并将解析分类后的车辆数据发送至第一Channel组件中进行缓存;
通过第一Sink组件读取第一Channel组件中缓存的解析分类后的车辆数据,并将解析分类后的车辆数据存储至OSS对象存储组件中,以对车辆数据进行冷备份。
继续参考图2,Source组件消费Kafka Topic 2中存储的解析分类后的车辆数据,以Event事件的形式发送至第一Channel组件(Channel1),第一Channel组件通过文件系统缓存Source组件发送的Event事件数据,等待第一Sink组件将其消费,第一Sink组件(Sink1)以事务的形式消费第一Channel组件中缓存的Event事件数据,并将Event事件数据发送至OSS对象存储组件(Aliyun OSS)中进行存储,以对车辆数据进行冷备份。
在一实施方式中,通过第二数据传输链路,将解析分类后的车辆数据存储至Elasticsearch搜索引擎中,以对车辆数据进行热备份,包括:
通过Source组件从Kafka组件的第二存储单元中读取解析分类后的车辆数据,并将解析分类后的车辆数据发送至第二Channel组件中进行缓存;
通过第二Sink组件读取第二Channel组件中缓存的解析分类后的车辆数据,并将解析分类后的车辆数据存储至Elasticsearch搜索引擎中,以对车辆数据进行热备份。
继续参考图2,Source组件消费Kafka Topic 2中存储的解析分类后的车辆数据,以Event事件的形式发送至第二Channel组件(Channel2),第二Channel组件通过文件系统缓存Source组件发送的Event事件数据,等待第二Sink组件将其消费,第二Sink组件(Sink2)以事务的形式消费第二Channel组件中缓存的Event事件数据,并将Event事件数据发送至Elasticsearch搜索引擎中进行存储,以对车辆数据进行热备份。
在一实施方式中,将解析分类后的车辆数据存储至OSS对象存储组件中,以对车辆数据进行冷备份,包括:
将不同类型的车辆数据存储至OSS对象存储组件中不同的文件系统目录中,以对车辆数据进行冷备份。
值得一提的是,OSS对象存储组件可以选择低频访问、同城冗余类型,不仅能够大幅降低对车辆数据进行存储备份的成本,还能够提高对车辆数据进行存储备份的可靠性及容灾能力。
在一实施方式中,将解析分类后的车辆数据存储至Elasticsearch搜索引擎中,以对车辆数据进行热备份,包括:
根据索引模板创建Elasticsearch搜索引擎中存储的第二目标车辆数据的索引,并配置索引的生命周期;
根据索引的生命周期,删除Elasticsearch搜索引擎中存储的第二目标车辆数据,以对车辆数据进行热备份。
其中,索引的生命周期用于指定索引创建后,索引及通过该索引能够搜索到的车辆数据多长时间从Elasticsearch搜索引擎中删除。实际删除时,可先将待删除数据移入删除阶段,然后等待自动删除。
本申请实施例一提供的车辆数据的备份方法,通过Flume组件,无需编码仅通过配置即可实现复杂的数据流转,能够降低将车辆数据传输至云端存储组件进行存储备份的复杂度,提高车辆数据在云端的存储备份效率。利用Elasticsearch搜索引擎能够提高对车辆数据进行查询搜索的便利性,另外,基于OSS对象存储组件的安全、低成本的存储特性,可到期删除Elasticsearch搜索引擎中存储的时效性数据,大幅减少Elasticsearch搜索引擎中存储的数据量,能够降低车辆数据在云端的存储备份成本,实现车辆数据的在云端的冷备份与热备份。
图3是本申请实施例二提供的电子设备的结构示意图。可选地,本申请提供的电子设备为云端服务器,包括:处理器110、存储器111以及存储在存储器111中并可在处理器110上运行的计算机程序112。处理器110执行计算机程序112时实现上述车辆数据的备份方法实施例中的步骤。
电子设备可包括,但不仅限于,处理器110、存储器111。本领域技术人员可以理解,图3仅仅是电子设备的示例,并不构成对电子设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件,例如电子设备还可以包括输入输出设备、网络接入设备、总线等。
处理器110可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
存储器111可以是电子设备的内部存储单元,例如电子设备的硬盘或内存。存储器111也可以是电子设备的外部存储设备,例如电子设备上配备的插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)等。进一步地,存储器111还可以既包括电子设备的内部存储单元也包括外部存储设备。存储器111用于存储计算机程序以及电子设备所需的其他程序和数据。存储器111还可以用于暂时地存储已经输出或者将要输出的数据。
本申请还提供一种计算机存储介质,计算机存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述车辆数据的备份方法的步骤。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,除了包含所列的那些要素,而且还可包含没有明确列出的其他要素。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 一种车辆行驶风险预警方法、装置、存储介质及电子设备
- 一种车辆预警方法、装置、电子设备及存储介质
- 一种车位确定方法、装置、电子设备、车辆及存储介质
- 一种车辆定位方法、装置、电子设备及存储介质
- 一种鉴权方法、电子设备及计算机可读存储介质
- 数据备份方法、装置、电子设备及计算机可读存储介质
- 数据备份方法及装置、电子设备和计算机可读存储介质