一种模型应用方法及装置
文献发布时间:2024-04-18 19:58:30
技术领域
本公开涉及通信技术领域,尤其涉及一种模型应用方法及装置。
背景技术
在无线通信网络中,例如在移动通信网络中,网络支持的业务越来越多样,因此需要满足的需求越来越多样。例如,网络需要能够支持超高速率、超低时延、和/或超大连接。该特点使得网络规划、网络配置、和/或资源调度越来越复杂。此外,由于网络的功能越来越强大,例如支持的频谱越来越高、支持高阶多入多出(multiple input multiple output,MIMO)技术、支持波束赋形、和/或支持波束管理等新技术。这些新需求、新场景和新特性给网络规划、运维和高效运营带来了前所未有的挑战。为了迎接该挑战,可以将人工智能技术引入无线通信网络中,从而实现网络智能化。基于此,如何在网络中有效地实现人工智能是一个值得研究的问题。
发明内容
本公开提供一种模型应用方法及装置,以实现对参考信号端口的自适应,减少模型存储和训练开销。
第一方面,提供一种模型应用方法,该方法的执行主体为终端设备,或配置于终端设备中的部件(处理器、芯片或其它等),或者执行主体为网络设备,或配置于网络设备中的部件,该方法包括:根据接收到的参考信号,确定第一信息,所述第一信息中包含所述参考信号的m个端口的数据;根据所述m个端口和第一模型的输入维度的n个端口的对应关系,将所述m个端口的数据映射到所述第一模型的输入,得到所述第一模型的输出,所述m和n均为大于或等于1的整数,且m和n不相等。
通过上述设计,当参考信号的端口数量与第一模型的输入维度中的端口数量不同时,可根据参考信号的端口与第一模型的输入维度中的端口的对应关系,将参考信号的端口的数据,自适应的输入到第一模型中,而无需针对每种类型的参考信号的端口设计与其配置对应的模型,从而减少模型训练和存储开销。
在一种可能的设计中,所述参考信号为下行参考信号,所述第一模型的输出用于确定第二信息,所述方法还包括:向网络设备发送所述第二信息。
在一种可能的设计中,所述根据所述m个端口和所述第一模型的输入维度的n个端口的对应关系,将所述m个端口的数据映射到所述第一模型的输入,包括:根据所述m个端口和所述n个端口的对应关系,确定所述n个端口中的第一目标端口,所述第一目标端口的数量为m;将所述m个端口的数据,输入所述第一模型的第一目标端口对应的输入。
通过上述设计,当第一模型的输入维度中的n个端口的数量,大于参考信号的m个端口的数量时,在n个端口中,选择出部分端口,称为第一目标端口,该第一目标端口的数量与m的取值相同。将第一信息中包含的m个端口的数据,输入到第一目标端口中,从而实现参考信号端口数据的自适应输入到第一模型中,减少模型的存储和训练开销。
在一种可能的设计中,所述m个端口采用矩阵方式排列,包含M1列M2行,采用双极化方向,所述m个端口表示为(M1,M2,2),所述n个端口采用矩阵方式排列,包含N1列N2行,采用双极化方向,所述n个端口表示为(N1,N2,2),M1、M2、N1和N2均为大于或等于1的整数;所述m个端口和所述n个端口的对应关系,满足以下:
极化方向1:所述m个端口中的端口(i*M2至(i+1)*M2-1)对应所述n个端口中的端口(i*N2至i*N2+M2-1);
极化方向2:所述m个端口中的端口(i*M2+M1*M2至(i+1)*M2-1+M1*M2)对应所述n个端口中的端口(i*N2+N1*N2至i*N2+M2-1+N1*N2);
其中,i为大于或等于0,小于或等于M1-1的整数。
在一种可能的设计中,所述第一模型中除所述第一目标端口外的其它端口的输入为预设数据,可选地该预设数据可以为零,或者所述m个端口的数据的复制数据。
通过上述设计,当其它端口填充的数据为预设数据(例如零)时,容易实现,功耗较小。当其它端口填充的数据为第一目标端口对应的数据的复制数据时,相当于当同一份数据被传输了多次,提高了数据传输的精度。
在一种可能的设计中,所述第一目标端口中包括端口0。
该第一目标端口中包括端口0的设计,容易操作,易于实现。
在一种可能的设计中,所述n个端口中每一行的端口数量大于或者等于所述m个端口中每一行的端口数量,所述n个端口中每一列的端口数量大于或者等于所述m个端口中每一列的端口数量。
在一种可能的设计中,所述根据所述m个端口和所述第一模型的输入维度的n个端口的对应关系,将所述m个端口的数据映射到所述第一模型的输入,包括:根据所述m个端口和所述n个端口,确定Y个端口集合,所述Y为大于1的整数,所述Y个端口集合中至少一个端口集合中包含n个端口;针对所述包含n个端口的端口集合,将所述端口集中包含的n个端口对应的数据,输入所述第一模型的n个端口对应的输入。
通过上述设计,当第一模型的输入维度中的n个端口,小于参考信号的m个端口的情况,即n的取值小于m的情况,可将参考信号的m个端口,划分为Y个子面板,子面板端口的数量以及端口的排列分布与第一模型的输入维度中的n个端口相同。可选的,面板是物理概念,端口可按照一定的排列方式,分布在天线面板中,子面板可认为是一个逻辑概念,一个面板可被划分为至少一个子面板。关于将参考信号的m个端口,划分为Y个子面板的方式不作限定。将Y个子面板各对应的参考信号端口的数据,分别输入到第一模型的输入维度的n个端口时,从而实现参考信号的端口数量大于第一模型的输入的端口数量时,对参考信号端口数据的自适应,减少了模型存储和训练开销。
在一种可能的设计中,所述m个端口采用矩阵方式排列,包含M1列M2行,采用双极化方向,所述m个端口表示为(M1,M2,2),所述n个端口采用矩阵方式排列,包含N1列N2行,采用双极化方向,所述n个端口表示为(N1,N2,2),M1、M2、N1和N2均为大于或等于1的整数;针对所述Y个端口集合中的端口集合k,k为大于或等于0,小于或等于Y-1的整数,所述m个端口和所述n个端口的对应关系,满足以下:
极化方向1:所述m个端口中的端口(i*M2+k*N2至i*M2+k*N2+N2-1)对应所述n个端口中的端口(i*N2至i*N2+N2-1);
极化方向2:所述m个端口中的端口(i*M2+k*N2+M1*M2至i*M2+k*N2+N2-1+M1*M2)对应所述n个端口中的端口(i*N2+N1*N2至i*N2+N2-1+N1*N2);
其中,i为大于或等于0,小于或等于M1-1的整数。
通过上述设计,可按照行优先划分的方式,将参考信号的m个端口中,划分为Y个子面板,关于行优先划分方式的示例,可参见图15所示,该划分方式易于实现,降低功耗。
在一种可能的设计中,所述m个端口采用矩阵方式排列,包含M1列M2行,采用双极化方向,所述m个端口表示为(M1,M2,2),所述n个端口采用矩阵方式排列,包含N1列N2行,采用双极化方向,所述n个端口表示为(N1,N2,2);针对所述Y个端口集合中的端口集合k,k为大于或等于0,小于或等于Y-1的整数,所述m个端口和所述n个端口的对应关系,满足以下:
极化方向1:所述m个端口中的端口(i*M2+k*N1至i*M2+k*N1+M2-1)对应所述n个端口中的端口(i*N2至i*N2+M2-1);
极化方向2:所述m个端口中的端口(i*M2+k*N1+M1*M2至i*M2+k*N1+M2-1+M1*M2)对应所述n个端口中的端口(i*N2+N1*N2至i*N2+M2-1+N1*N2);
其中,i为大于或等于0,小于或等于M1-1的整数。
通过上述方法,可按照列优先划分的方式,将参考信号的m个端口,划分为Y个子面板,关于列优先划分方式的示例,可参见图16所示,该划分方式易于实现,降低功耗。
在一种可能的设计中,还包括:向网络设备发送端口集合的标识信息。
通过上述设计,尤其是上述将参考信号划分为Y个子面板,每个子面板对应一个端口集合,在该设计中,除了将每个子面板对应的第二信息发送给网络设备,还可以向网络设备发送发送每个第二信息对应的端口集合的标识,从而使得网络设备可以将恢复的信道信息再整合在一起。
在一种可能的设计中,所述n端口中每一行的端口数量小于或者等于所述m个端口中每一行的端口数量,所述n个端口中每一列的端口数量小于或者等于所述m个端口中每一列的端口数量。
第二方面,提供一种模型应用方法,该方法的执行主体为网络设备,或配置于网络设备中的部件,该方法包括:接收来自终端设备的第二信息;根据第二模型和所述第二信息,确定第三信息;根据下行参考信号的m个端口和所述第二模型的输出维度的x个端口的对应关系,对所述第三信息进行处理,确定第一信息,所述第一信息中包含所述m个端口的数据,所述m和x均为大于或等于1的整数,且m和x不相等。
通过上述设计,终端设备可以向网络设备发送第二信息,网络设备根据第二信息和第二模型,确定第三信息;该第三信息可以为第二模型的输出,或根据第二模型的输出确定的。该第二模型的输出维度中包括x个端口的数量,与第一模型的输入维度中的n个端口的数量可以相同,或不同,不作限定。由于在该设计中,网络设备需要恢复参考信号的m个端口的数据,当第二模型的输出维度中包含x个端口时,第三信息中也包括x个端口的数量。通过上述设备,可将第三信息中包含的x个端口的数据,恢复为发送参考信号的m个端口的数据,该m个端口的数据可认为是m个端口对应的下行信道信息,无需对每种类型的参考信号,均设置对应的恢复模型,减少模型存储和训练开销。
在一种可能的设计中,所述根据下行参考信号的m个端口和所述第二模型的输出维度的x个端口的对应关系,对所述第三信息进行处理,确定第一信息,包括:根据所述m个端口和所述x个端口的对应关系,确定所述x个端口中的第二目标端口;根据所述第三信息中所述第二目标端口对应的数据,确定所述第一信息。
通过上述设计,由于对于发送端,当参考信号的m个端口,小于第一模型的n个端口时,在n个端口中选择m个端口,输入参考信号m个端口的数据,所选择的m个端口称为第一目标端口。对于接收端,即网设备在进行下行信道信息恢复时,也可以在第二模型的输出对应的第三信息中,该第三信息中包括x个端口的数据,再选择m个端口的数据,该再次选择的m个端口可称为第二目标端口,可将在第三信息中选择的m个端口的数据,或该选择的m个端口的数据处理后的信息称为第一信息,从而实现对下行信道信息的恢复。
在一种可能的设计中,所述第二目标端口中包括端口0。
在一种可能的设计中,所x个端口中每一行的端口数量大于或者等于所述m个端口中每一行的端口数量,所述x个端口中每一列的端口数量大于或者等于所述m个端口中每一列的端口数量。
在一种可能的设计中,从所述终端设备接收Y个第二信息,确定Y个第三信息,所述根据下行参考信号的m个端口和所述第二模型的输出维度的x个端口的对应关系,对所述第三信息进行处理,确定第一信息,包括:根据所述m个端口和所述x个端口的对应关系,对所述Y个第三信息进行拼接,确定所述第一信息。
通过上述设计,由于在发送端,将参考信号的m个端口,划分为Y个子面板,每个子板可称为一个端口集合。将每个端口集合对应的数据,分别输入到第一模型中。对于接收端,即网络设备,将确定Y个端口集合的信息,拼接到一起,作为恢复的第一信息,实现对下行信道数据的恢复。
在一种可能的设计中,还包括:接收来自所述终端设备的所述第二信息对应的端口信息集合的标识信息。
在一种可能的设计中,所述x个端口中每一行的端口数量小于或者等于所述m个端口中每一行的端口数量,所述x个端口中每一列的端口数量小于或者等于所述m个端口中每一列的端口数量。
第三方面,提供一种装置,该装置可以是终端设备,或配置于终端设备中的部件,或者,该装置是网络设备,或配置于网络设备中的部件。
示例地,该装置包括执行第一方面中所描述的方法/操作/步骤/动作一一对应的单元,该单元可以是硬件电路,也可以是软件,也可以是硬件电路结合软件实现
例如,该装置包括处理单元和通信单元,且处理单元和通信单元可以执行上述第一方面任一种设计中的相应功能,具体的:
通信单元,用于接收来参考信号;处理单元,用于根据接收到的参考信号,确定第一信息,所述第一信息中包含所述参考信号的m个端口的数据;以及根据所述m个端口和第一模型的输入维度的n个端口的对应关系,将所述m个端口的数据映射到所述第一模型的输入,得到所述第一模型的输出,所述m和n均为大于或等于1的整数,且m和n不相等。
关于处理单元和通信单元的具体执行过程可以参考第一方面,这里不再赘述。
或者,该装置包括处理器,用于实现上述第一方面描述的方法。所述装置还可以包括存储器,用于存储指令和/或数据。所述处理器与所述存储器耦合,所述处理器执行所述存储器中存储的程序指令,实现上述第一方面的方法。所述装置还可以包括通信接口,所述通信接口用于该装置和其它设备进行通信。通信接口可以是收发器、电路、总线、模块、管脚或其它类型的通信接口。在一种可能的设计中,该装置包括:
存储器,用于存储程序指令;
通信接口,用于接收参考信号;
处理器,用于根据接收到的参考信号,确定第一信息,所述第一信息中包含所述参考信号的m个端口的数据;以及根据所述m个端口和第一模型的输入维度的n个端口的对应关系,将所述m个端口的数据映射到所述第一模型的输入,得到所述第一模型的输出,所述m和n均为大于或等于1的整数,且m和n不相等。
关于通信接口和处理器的具体执行过程,可参考第一方面,这里不再赘述。
第四方面,提供一种装置,该装置可以是网络设备,或配置于网络设备中的部件。
示例地,该装置包括执行第二方面中所描述的方法/操作/步骤/动作一一对应的单元,该单元可以是硬件电路,也可以是软件,也可以是硬件电路结合软件实现
例如,该装置包括处理单元和通信单元,且处理单元和通信单元可以执行上述第二方面任一种设计中的相应功能,具体的:
通信单元,用于接收来自终端设备的第二信息;
处理单元,用于根据第二模型和所述第二信息,确定第三信息,以及根据下行参考信号的m个端口和所述第二模型的输出维度的x个端口的对应关系,对所述第三信息进行处理,确定第一信息,所述第一信息中包含所述m个端口的数据,所述m和x均为大于或等于1的整数,且m和x不相等。
关于处理单元和通信单元的具体执行过程可以参考第二方面,这里不再赘述。
或者,该装置包括处理器,用于实现上述第二方面描述的方法。所述装置还可以包括存储器,用于存储指令和/或数据。所述处理器与所述存储器耦合,所述处理器执行所述存储器中存储的程序指令,实现上述第二方面的方法。所述装置还可以包括通信接口,所述通信接口用于该装置和其它设备进行通信。通信接口可以是收发器、电路、总线、模块、管脚或其它类型的通信接口,其它设备可以为终端设备等。在一种可能的设计中,该装置包括:
存储器,用于存储程序指令;
通信接口,用于接收来自终端设备的第二信息;
处理器,用于根据第二模型和所述第二信息,确定第三信息,以及根据下行参考信号的m个端口和所述第二模型的输出维度的x个端口的对应关系,对所述第三信息进行处理,确定第一信息,所述第一信息中包含所述m个端口的数据,所述m和x均为大于或等于1的整数,且m和x不相等。
关于通信接口和处理器的具体执行过程,可参考第二方面,这里不再赘述。
第五方面,提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行第一方面或第二方面中任一方面的方法。
第六方面,提供一种芯片系统,该芯片系统包括处理器,还可以包括存储器,用于实现第一方面或第二方面中任一方面的方法。该芯片系统可以由芯片构成,也可以包含芯片和其他分立器件。
第七方面,提供一种计算机程序产品,包括指令,当其在计算机上运行时,使得计算机执行第一方面或第二方面任一方面的方法。
第八方面,本申请还提供一种系统,该系统中包括第三方面的装置和第四方面的装置。
附图说明
图1是本公开提供的通信系统的示意图;
图2和图3是本公开提供的通信架构示意图;
图4是本公开提供的AI模型的架构示意图;
图5和图6是本公开提供的神经元的示意图;
图7和图18是本公开提供的流程示意图;
图8为本公开提供的(8,2,2)端口的示意图;
图9为本公开提供的(2,2,2)端口的示意图;
图10为本公开提供的(2,2,2)端口与(8,2,2)端口的匹配示意图;
图11为本公开提供的(4,2,2)端口的示意图;
图12为本公开提供的(4,2,2)端口与(8,2,2)端口的匹配示意图;
图13和图14分别为本公开提供的8端口和16端口,各自与32端口的匹配示意图;
图15和图16分别为本公开提供的优先行划分子面板和优先列划分子面板的示意图;
图17为本公开提供的64端口与32端口的匹配和恢复信道信息的示意图;
图19为本公开提供的CSI反馈和恢复信道信息的示意图;
图20和图21为本公开提供的装置示意图。
具体实施方式
图1是本公开能够应用的通信系统1000的架构示意图。如图1所示,该通信系统包括无线接入网100和核心网200,可选的,通信系统1000还可以包括互联网300。其中,无线接入网100可以包括至少一个接入网设备(如图1中的110a和110b),还可以包括至少一个终端设备(如图1中的120a-120j)。终端设备通过无线的方式与接入网设备相连,接入网设备通过无线或有线方式与核心网连接。核心网设备与接入网设备可以是独立的不同的物理设备,或者可以是将核心网设备的功能与接入网设备的逻辑功能集成在同一个物理设备上,或者可以是一个物理设备上集成了部分核心网设备的功能和部分的接入网设备的功能。终端设备和终端设备之间以及接入网设备和接入网设备之间可以通过有线或无线的方式相互连接。图1只是示意图,该通信系统中还可以包括其它网络设备,如还可以包括无线中继设备和无线回传设备等,在图1中未画出。
接入网设备可以是基站(base station)、演进型基站(evolved NodeB,eNodeB)、发送接收点(transmission reception point,TRP)、第五代(5th generation,5G)移动通信系统中的下一代基站(next generation NodeB,gNB)、开放无线接入网(open radioaccess network,O-RAN)中的接入网设备、第六代(6th generation,6G)移动通信系统中的下一代基站、未来移动通信系统中的基站或无线保真(wireless fidelity,WiFi)系统中的接入节点等。或者,接入网设备可以是完成基站部分功能的模块或单元,例如,可以是集中式单元(central unit,CU)、分布式单元(distributed unit,DU)、集中单元控制面(CUcontrol plane,CU-CP)模块、或集中单元用户面(CU user plane,CU-UP)模块。接入网设备可以是宏基站(如图1中的110a),也可以是微基站或室内站(如图1中的110b),还可以是中继节点或施主节点等。本公开中对接入网设备所采用的具体技术和具体设备形态不做限定。
在本公开中,用于实现接入网设备的功能的装置可以是接入网设备;也可以是能够支持接入网设备实现该功能的装置,例如芯片系统、硬件电路、软件模块、或硬件电路加软件模块,该装置可以被安装在接入网设备中或可以与接入网设备匹配使用。在本公开中,芯片系统可以由芯片构成,也可以包括芯片和其他分立器件。为了便于描述,下文以用于实现接入网设备的功能的装置是接入网设备,接入网设备为基站为例,描述本公开提供的技术方案。
(1)协议层结构。
接入网设备和终端设备之间的通信遵循一定的协议层结构。该协议层结构可以包括控制面协议层结构和用户面协议层结构。例如,控制面协议层结构可以包括无线资源控制(radio resource control,RRC)层、分组数据汇聚层协议(packet data convergenceprotocol,PDCP)层、无线链路控制(radio link control,RLC)层、媒体接入控制(mediaaccess control,MAC)层和物理层等协议层的功能。例如,用户面协议层结构可以包括PDCP层、RLC层、MAC层和物理层等协议层的功能,在一种可能的实现中,PDCP层之上还可以包括业务数据适配协议(service data adaptation protocol,SDAP)层。
可选的,接入网设备和终端设备之间的协议层结构还可以包括人工智能(artificial intelligence,AI)层,用于传输AI功能相关的数据。
(2)集中单元(central unit,CU)和分布单元(distributed unit,DU)。
接入设备可以包括CU和DU。多个DU可以由一个CU集中控制。作为示例,CU和DU之间的接口可以称为F1接口。其中,控制面(control panel,CP)接口可以为F1-C,用户面(userpanel,UP)接口可以为F1-U。本公开不限制各接口的具体名称。CU和DU可以根据无线网络的协议层划分:比如,PDCP层及以上协议层的功能设置在CU,PDCP层以下协议层(例如RLC层和MAC层等)的功能设置在DU;又比如,PDCP层以上协议层的功能设置在CU,PDCP层及以下协议层的功能设置在DU,不予限制。
上述对CU和DU的处理功能按照协议层的划分仅仅是一种举例,也可以按照其他的方式进行划分。例如可以将CU或者DU划分为具有更多协议层的功能,又例如将CU或DU还可以划分为具有协议层的部分处理功能。在一种设计中,将RLC层的部分功能和RLC层以上的协议层的功能设置在CU,将RLC层的剩余功能和RLC层以下的协议层的功能设置在DU。在另一种设计中,还可以按照业务类型或者其他系统需求对CU或者DU的功能进行划分,例如按时延划分,将处理时间需要满足时延要求的功能设置在DU,不需要满足该时延要求的功能设置在CU。在另一种设计中,CU也可以具有核心网的一个或多个功能。示例性的,CU可以设置在网络侧方便集中管理。在另一种设计中,将DU的无线单元(radio unit,RU)拉远设置。可选的,RU可以具有射频功能。
可选的,DU和RU可以在物理层(physical layer,PHY)进行划分。例如,DU可以实现PHY层中的高层功能,RU可以实现PHY层中的低层功能。其中,用于发送时,PHY层的功能可以包括以下至少一项:添加循环冗余校验(cyclic redundancy check,CRC)码、信道编码、速率匹配、加扰、调制、层映射、预编码、资源映射、物理天线映射、或射频发送功能。用于接收时,PHY层的功能可以包括以下至少一项:CRC校验、信道解码、解速率匹配、解扰、解调、解层映射、信道检测、资源解映射、物理天线解映射、或射频接收功能。其中,PHY层中的高层功能可以包括PHY层的一部分功能,例如该部分功能更加靠近MAC层,PHY层中的低层功能可以包括PHY层的另一部分功能,例如该部分功能更加靠近射频功能。例如,PHY层中的高层功能可以包括添加CRC码、信道编码、速率匹配、加扰、调制、和层映射,PHY层中的低层功能可以包括预编码、资源映射、物理天线映射、和射频发送功能;或者,PHY层中的高层功能可以包括添加CRC码、信道编码、速率匹配、加扰、调制、层映射和预编码,PHY层中的低层功能可以包括资源映射、物理天线映射、和射频发送功能。例如,PHY层中的高层功能可以包括CRC校验、信道解码、解速率匹配、解码、解调、和解层映射,PHY层中的低层功能可以包括信道检测、资源解映射、物理天线解映射、和射频接收功能;或者,PHY层中的高层功能可以包括CRC校验、信道解码、解速率匹配、解码、解调、解层映射、和信道检测,PHY层中的低层功能可以包括资源解映射、物理天线解映射、和射频接收功能。
示例性的,CU的功能可以由一个实体来实现,或者也可以由不同的实体来实现。例如,可以对CU的功能进行进一步划分,即将控制面和用户面分离并通过不同实体来实现,分别为控制面CU实体(即CU-CP实体)和用户面CU实体(即CU-UP实体)。该CU-CP实体和CU-UP实体可以与DU相耦合,共同完成接入网设备的功能。
可选的,上述DU、CU、CU-CP、CU-UP和RU中的任一个可以是软件模块、硬件结构、或者软件模块+硬件结构,不予限制。其中,不同实体的存在形式可以是不同的,不予限制。例如DU、CU、CU-CP、CU-UP是软件模块,RU是硬件结构。这些模块及其执行的方法也在本公开的保护范围内。
一种可能的实现中,接入网设备包括CU-CP、CU-UP、DU和RU。例如,本公开的执行主体包括DU,或者包括DU和RU,或者包括CU-CP、DU和RU,或者包括CU-UP、DU和RU,不予限制。各模块所执行的方法也在本公开的保护范围内。
终端设备也可以称为终端、用户设备(user equipment,UE)、移动台、移动终端设备等。终端设备可以广泛应用于各种场景中的通信,例如包括但不限于以下至少一个场景:设备到设备(device-to-device,D2D)、车物(vehicle to everything,V2X)、机器类通信(machine-type communication,MTC)、物联网(internet of things,IOT)、虚拟现实、增强现实、工业控制、自动驾驶、远程医疗、智能电网、智能家具、智能办公、智能穿戴、智能交通、或智慧城市等。终端设备可以是手机、平板电脑、带无线收发功能的电脑、可穿戴设备、车辆、无人机、直升机、飞机、轮船、机器人、机械臂、或智能家居设备等。本公开对终端设备所采用的具体技术和具体设备形态不做限定。
在本公开中,用于实现终端设备的功能的装置可以是终端设备;也可以是能够支持终端设备实现该功能的装置,例如芯片系统、硬件电路、软件模块、或硬件电路加软件模块,该装置可以被安装在终端设备中或可以与终端设备匹配使用。为了便于描述,下文以用于实现终端设备的功能的装置是终端设备,终端设备为UE为例,描述本公开提供的技术方案。
基站和UE可以是固定位置的,也可以是可移动的。基站和/或UE可以部署在陆地上,包括室内或室外、手持或车载;也可以部署在水面上;还可以部署在空中的飞机、气球和人造卫星上。本公开对基站和UE的应用场景不做限定。基站和UE可以部署在相同的场景或不同的场景,例如,基站和UE同时部署在陆地上;或者,基站部署在陆地上,UE部署在水面上等,不再一一举例。
基站和UE的角色可以是相对的,例如,图1中的直升机或无人机120i可以被配置成移动基站,对于那些通过120i接入到无线接入网100的UE120j来说,UE120i是基站;但对于基站110a来说,120i是UE,即110a与120i之间是通过无线空口协议进行通信的。110a与120i之间也可以是通过基站与基站之间的接口协议进行通信的,此时,相对于110a来说,120i也是基站。因此,基站和UE都可以统一称为通信装置,图1中的110a和110b可以称为具有基站功能的通信装置,图1中的120a-120j可以称为具有UE功能的通信装置。
在本公开中,可在前述图1所示的通信系统中引入独立的网元如称为AI网元、或AI节点等)来实现AI相关的操作,AI网元可以和通信系统中的接入网设备之间直接连接,或者可以通过第三方网元和接入网设备实现间接连接。其中,第三方网元可以是认证管理功能(authentication management function,AMF)、或用户面功能(user plane function,UPF)等核心网网元;或者,可以在通信系统中的其他网元内配置AI功能、AI模块或AI实体来实现AI相关的操作,例如该其他网元可以是接入网设备(如gNB)、核心网设备、或网管(operation,administration and maintenance,OAM)等,在这种情况下,执行AI相关的操作的网元为内置AI功能的网元。其中,上述OAM用于对接入网设备和/或核心网设备等进行操作、管理和维护等。
可选的,图2为本公开提供的一种通信系统的架构。如图2所示,在第一种设计中,接入网设备中包括近实时接入网智能控制(RAN intelligent controller,RIC)模块,用于进行模型训练和推理。例如,近实时RIC可以用于训练AI模型,利用该AI模型进行推理。例如,近实时RIC可以从CU、DU或RU中的至少一项获得网络侧和/或终端侧的信息,该信息可以作为训练数据或者推理数据。可选的,近实时RIC可以将推理结果递交至CU、DU、RU或终端设备中的至少一项。可选的,CU和DU之间可以交互推理结果。可选的,DU和RU之间可以交互推理结果,例如近实时RIC将推理结果递交至DU,由DU转发给RU。
或者,在第二种设计中,如图2所示,接入网设备之外包括非实时RIC(可选的,非实时RIC可以位于OAM中或者核心网设备中),用于进行模型训练和推理。例如,非实时RIC用于训练AI模型,利用该模型进行推理。例如,非实时RIC可以从CU、DU或RU中的至少一项获得网络侧和/或终端侧的信息,该信息可以作为训练数据或者推理数据,该推理结果可以被递交至CU、DU、RU或终端设备中的至少一项。可选的,CU和DU之间可以交互推理结果。可选的,DU和RU之间可以交互推理结果,例如非实时RIC将推理结果递交至DU,由DU转发给RU。
或者,在第三种设计中,如图2所示,接入网设备中包括近实时RIC,接入网设备之外包括非实时RIC(可选的,非实时RIC可以位于OAM中或者核心网设备中)。同上述第二种设计,非实时RIC可以用于进行模型训练和推理。和/或,同上述第一种设计,近实时RIC可以用于进行模型训练和推理。和/或,非实时RIC进行模型训练,近实时RIC可以从非实时RIC获得AI模型信息,并从CU、DU或RU中的至少一项获得网络侧和/或终端侧的信息,利用该信息和该AI模型信息得到推理结果。可选的,近实时RIC可以将推理结果递交至CU、DU、RU或终端设备中的至少一项。可选的,CU和DU之间可以交互推理结果。可选的,DU和RU之间可以交互推理结果,例如近实时RIC将推理结果递交至DU,由DU转发给RU。例如,近实时RIC用于训练模型A,利用模型A进行推理。例如,非实时RIC用于训练模型B,利用模型B进行推理。例如,非实时RIC用于训练模型C,将模型C的信息发送给近实时RIC,近实时RIC利用模型C进行推理。
图3为本公开提供的另一种通信系统的架构。相对图2,图3中将CU分离成为了CU-CP和CU-UP等。
AI模型是AI功能的具体实现,AI模型表征了模型的输入和输出之间的映射关系。AI模型可以是神经网络、线性回归模型、决策树模型、支持向量机(support vectormachine,SVM)、贝叶斯网络、Q学习模型或者其他机器学习模型等。本公开中,AI功能可以包括以下至少一项:数据收集(收集训练数据和/或推理数据)、数据预处理、模型训练(或称为,模型学习)、模型信息发布(配置模型信息)、模型校验、模型推理、或推理结果发布。其中,推理又可以称为预测。本公开中,可以将AI模型简称为模型。
如图4所示为AI模型的一种应用架构示意图。数据源(data source)用于存储训练数据和推理数据。模型训练节点(model trainning host)通过对数据源提供的训练数据(training data)进行分析或训练,得到AI模型,且将AI模型部署在模型推理节点(modelinference host)中。可选的,模型训练节点还可以对已部署在模型推理节点的AI模型进行更新。模型推理节点还可以向模型训练节点反馈已部署模型的相关信息,以使得模型训练节点对已部署的AI模型进行优化或更新等。
其中,通过模型训练节点学习得到AI模型,相当于由模型训练节点利用训练数据学习得到模型的输入和输出之间的映射关系。模型推理节点使用AI模型,基于数据源提供的推理数据进行推理,得到推理结果。该方法还可以描述为:模型推理节点将推理数据输入到AI模型,通过AI模型得到输出,该输出即为推理结果。该推理结果可以指示:由执行对象使用(执行)的配置参数、和/或由执行对象执行的操作。推理结果可以由执行(actor)实体统一规划,并发送给一个或多个执行对象(例如,网络实体)去执行。可选的,执行实体或者执行对象可以将其收集到的参数或测量量反馈给数据源,该过程可以称为表现反馈,所反馈的参数可以作为训练数据或推理数据。可选的,还可以根据模型推理节点所输出的推理结果,确定模型性能相关的反馈信息,且将该反馈信息反馈给模型推理节点,模型推理节点可根据该反馈信息,向模型训练节点反馈该模型的性能信息等,以使得模型训练节点对已部署的AI模型进行优化或更新等,该过程可称为模型反馈。
AI模型可以是神经网络或其它机器学习模型。以神经网络为例,神经网络是机器学习技术的一种具体实现形式。根据通用近似定理,神经网络在理论上可以逼近任意连续函数,从而使得神经网络具备学习任意映射的能力。因此神经网络可以对复杂的高维度问题进行准确的抽像建模。
神经网络的思想来源于大脑组织的神经元结构。每个神经元都对其输入值做加权求和运算,将加权求和结果通过一个激活函数产生输出。如图5所示,为神经元结构示意图。假设神经元的输入为x=[x
神经网络一般包括多层结构,每层可包括一个或多个神经元。增加神经网络的深度和/或宽度可以提高该神经网络的表达能力,为复杂系统提供更强大的信息提取和抽象建模能力。其中,神经网络的深度可以指神经网络包括的层数,每层包括的神经元个数可以称为该层的宽度。如图6所示,为神经网络的层关系示意图。一种实现中,神经网络包括输入层和输出层。神经网络的输入层将接收到的输入经过神经元处理后,将结果传递给输出层,由输出层得到神经网络的输出结果。另一种实现中,神经网络包括输入层、隐藏层和输出层。神经网络的输入层将接收到的输入经过神经元处理后,将结果传递给中间的隐藏层,隐藏层再将计算结果传递给输出层或者相邻的隐藏层,最后由输出层得到神经网络的输出结果。一个神经网络可以包括一层或多层依次连接的隐藏层,不予限制。神经网络的训练过程中,可以定义损失函数。损失函数描述了神经网络的输出值和理想目标值之间的差距或差异,本公开不限制损失函数的具体形式。神经网络的训练过程就是通过调整神经网络参数,如神经网络的层数、宽度、神经元的权值、和/或神经元的激活函数中的参数等,使得损失函数的值小于阈值门限值或者满足目标需求的过程。
AI技术,是一种通过模拟人脑进行复杂计算的技术。随着数据存储和能力的提升,AI在很多领域得到了越来越多的应用,在通信系统中也越来越多的受到重视。在无线网络中,使用AI模型,需要解决的一个问题是无线网络中灵活可变的信号格式与AI模型固定的输入格式和/或输出格式之间的矛盾。例如,在多天线(例如高阶多入多出(multiple inputmultiple output,MIMO))系统中,支持的天线端口主要有4端口、8端口、16端口、24端口和32端口等。随着技术的发展,后续还会扩展到64端口、128端口或更多的端口等。端口的不同,可能会带来对AI模型的输入维度要求不同。例如,发送端采用32个端口发送参考信号,该参考信号可称为32端口的参考信号。接收端对该32端口的参考信号处理,可获得参考信号的32端口的数据。如果采用AI方式,对32端口的数据进行压缩等处理,接收端中部署的AI模型的输入维度需要满足32端口的要求。在基于AI的系统中,如何降低设备的存储开销是一个值得研究的技术问题。为了降低设备的存储开销,从而降低设备成本,可以利用有限个数的AI模型,支持多种端口的参考信号。如何利用有限个数的AI模型,支持多种端口的参考信号的处理,实现参考信号端口的自适应,是本公开待解决的技术问题。
本公开提供一种模型应用方法,该方法既适用于上行参考信号的处理,也适用于下行参考信号的处理。在该方法中,接收到参考信号的接收端,根据参考信号的m个端口与接收端的第一模型的输入维度中的n个端口的对应关系,将参考信号的m个端口的数据,映射到第一模型中。例如,当参考信号的m个端口小于第一模型的输入维度中的n个端口时,即m小于n时,可在n个端口中选择第一目标端口,第一目标端口的数量与m相等。将参考信号的m个端口对应的数据,映射到第一模型输入维度的第一目标端口中。或者,当m大于n时,一种设计中,m是n的整数倍,可将m个端口划分为Y个端口集合,每个端口集合中包括n个端口。针对每个端口集合,将n个端口的数据映射到第一模型的输入维度中的n个端口中等。或者,另一种设计中,m是n的非整数倍。在该设计中,同样可将m个端口划分为Y个端口集口,其中,Y等于
本公开的方法,既适用于上行参考信号的处理,也适用于下行参考信号的处理。只要处理的数据,是与端口相关的,都可适用本公开的方法。采用本公开的方法,参考信号的接收端,可利用一个AI模型,对多种端口类型的参考信号进行处理。相对于针对每种端口类型的参考信号均需要训练和存储一个AI模型,节省了训练和存储开销。
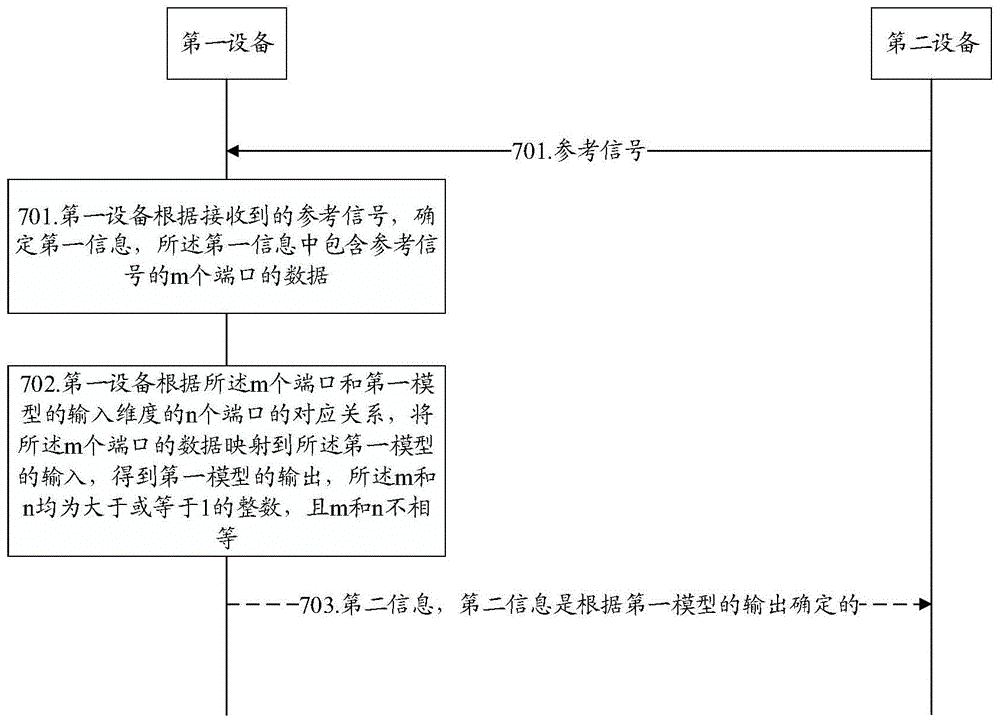
如图7所示,以下行参考信号的处理为例,提供模型应用方法的流程,至少包括:
步骤701:第一设备根据接收到的参考信号,确定第一信息,所述第一信息中包含参考信号的m个端口的数据。
可选的,第一设备接收来自第二设备的参考信号。在上行传输中,第一设备为基站,第二设备为UE,参考信号可称为上行参考信号。在下行传输中,第一设备为UE,第二设备为基站,参考信号可称为下行参考信号。参考信号的m个端口指第二设备发送参考信号的m个端口,在下行传输中,参考信号的m个端口指基站发送下行参考信号的m个端口,在上传输中,参考信号的m个端口指UE发送上行参考信号的m个端口。可选的,端口还可称为天线端口。在本公开的描述中,端口与天线端口不作区分。
以下行参考信号为例,UE可对接收的下行参考号进行信道估计,得到下行信道信息H,该估计得到的信道信息H还可称为信道估计矩阵H。估计得到的信道信息H的维度为(nTx,nRx,nsuband)。可选的,可对信道信息H进行预处理,预处理后的信道信息的维度为(nTx,nsuband)。nTx表示发送端用于发送参考信号的端口,即基站的端口,nTx为正整数;由于基站采用端口发送参考信号,因此nTx还可称为参考信号的端口;nRx表示接收端的端口,即UE的端口,nRx为正整数;nsubband表示频域中频域单元的数量,nsubband为正整数。在本公开中,重点考虑如何将参考信号的端口nTx,与第一模型的输入维度中的端口相匹配。可选的,步骤701中的第一信息可指下行信道信息H,或者预处理后的信道信息,即第一信息的维度可以为(nTx,nRx,nsuband),或(nTx,nsuband),或者步骤701中的第一信息的维度仅包括nTx,不作限定。例如,设定第二设备采用m个端口向第一设备发送下行参考信号,第一设备通过对下行参考信号进行处理,获得的第一信息在nTx维度中包括m个端口中每个端口对应的数据。对第一信息处理的第一模型的输入维度中包含n个端口,当m个端口与n个端口的数量不同时,如何实现m个端口的数据的自适应,是重点关注的问题。
步骤702:第一设备根据所述m个端口和第一模型的输入维度的n个端口的对应关系,将所述m个端口的数据映射到所述第一模型的输入,得到第一模型的输出,所述m和n均为大于或等于1的整数,且m和n不相等。
前已述,第一信息中包括参考信号的m个端口中每个端口对应的数据。假设第一模型的输入维度中包括n个端口,且m与n不相等。重点讨论如何将m个端口的数据,映射到第一模型的输入维度中的n个端口中。可选的,第一模型的输入维度中除包括n个端口外,还可以包括其它维度,不作限定。第一模型用于对第一信息处理,所述处理包括但不限于压缩、量化、调制、或编码等,第一模型还可称为AI模型,或编码模型等。
在一种设计中,主要考虑第一模型的输入维度中的n个端口的数量,大于参考信号的m个端口的情况,即n的取值大于m的情况。例如,协议上支持的参考信号的最大端口数量为32端口。可选的,m个端口与n个端口均采用矩阵方式排列,所述n个端口中每一行的端口数量大于或等于所述m个端口中每一行的端口数量,所述n个端口中每一列的端口数量大于或等于所述m个端口中每一列的端口数量。例如,系统中,例如基于第三代合作伙伴计划(3
在本公开中,当第一模型的输入维度中的n个端口的数量,大于参考信号的m个端口的数量时,采用以下解决方案:在n个端口中,选择出部分端口,称为第一目标端口,该第一目标端口的数量与m的取值相同。将第一信息中包含的m个端口的数据,输入到第一模型的第一目标端口对应的输入。该过程可描述为:根据所述m个端口和所述n个端口的对应关系,确定所述n个端口中的第一目标端口,第一目标端口的数量等于m。可选的,第一目标端口中包含的m个端口的排列方式与参考信号的m个端口的排列方式相同。将所述m个端口的数据,输入到所述第一模型的第一目标端口对应的输入。可选的,m个端口与n个端口的对应关系可以是协议规定的,或者基站预先通知UE的,不作限定。也就是说,在本公开中,UE可以基于某规则,从m个端口中,选择第一目标端口。该某规则可以是上述m个端口与n个端口的对应关系,该对应关系可表示参考信号的m个端口中的端口i,与第一模型的n个端口中的端口j的对应关系,i为大于或等于1,小于或等于m的整数,j为大于或等于1,小于或等于n的整数。本公开中,以i和j从1开始计数为例,可选地,i和j也可以从0开始计数,例如,i为大于或等于0且小于或等于m-1的整数,j为大于或等于0且小于或等于n-1的整数。其他参数的计数方式类似,不再赘述。
如图9和图10所示,以m的取值为8,参考信号的8个端口表示为(2,2,2),n的取值为32,第一模型的输入维度中的n个端口表示为(8,2,2)为例。该8个端口与32个端口的对应关系,可参见图10所示。在虚线对应的第一极化方向中,参考信号的4个端口的序号分别为0至3,对应于第一模型中的端口序号分别为0至3。在实线对应的第二极化方向中,参考信号的4个端口的序号分别为4至7,对应于第一模型中的端口序号分别为16至19。或者,如图11所示,以m的取值为16,参考信号的16个端口可表示(4,2,2)为例,第一模型的输入维度中的32个天端口,与参考信号的16个端口的对应关系,可参见图12。在图12中,在虚线对应的第一极化方向中,参考信号的8个端口的序号分别为0至7,对应于第一模型中的端口序号分别为0至7。在实线对应的第二极化方向中,参考信号的8个端口的序号分别为8至15,对应于第一模型中的端口序号分别为16至23。
在一种设计中,所述m个端口采用矩阵方式排列,包含M1列M2行,双极化方向,所述m个端口表示为(M1,M2,2),所述n个端口采用矩阵方式排列,包含N1列N2行,采用双极化方向,所述n个端口表示为(N1,N2,2),M1、M2、N1和N2均为大于或等于1的整数;所述m个端口和所述n个端口的对应关系,满足以下:
极化方向1:所述m个端口中的端口(i*M2至(i+1)*M2-1)对应所述n个端口中的端口(i*N2至i*N2+M2-1);
极化方向2:所述m个端口中的端口(i*M2+M1*M2至(i+1)*M2-1+M1*M2)对应所述n个端口中的端口(i*N2+N1*N2至i*N2+M2-1+N1*N2);其中,i为大于或等于0,小于或等于M1-1的整数。
举例来说,当m的取值为8,参考信号的8个端口表示为(2,2,2),n的取值为32,第一模型的32个端口表示为(8,2,2)。在极化方向1中,参考信号中的4个端口(0至3),分别对应于第一模型的端口(0至3)。在极化方向2中,参考信号中的4个端口(4至7),分别对应于第一模型的端口(16至19),可参考前述图9和图10所示。或者,当m的取值为16时,参考信号的16个端口表示为(4,2,2),n的取值为32,第一模型的32个端口表示为(8,2,2)。在极化方向1中,参考信号的8个端口(0至7),分别对应于第一模型的端口(0至7)。在极化方向2中,参考信号的8个端口(8至15),分别对应于第一模型的端口(16至23),可参考前述图11和图12所示。
或者,在第一模型的n个端口中,选择m个端口的方式,除根据上述m个端口与n个端口的对应关系外,还可以基于其它的规则:例如,该规则可以为:所选择的第一目标端口中,至少包括某个端口,该端口可以为端口0等。该规则简单,容易操作和实现。可选的,对于上述在第一模型的n个端口,选择m个端口的过程,可描述为:在第一模型中,确定子模型,该子模型的输入维度中包含m个端口,且该m个端口的排列方式,与参考信号的m个端口的排列方式相同。
可选的,对于第一模型的n个端口中,除第一目标端口中外的其它端口,可以填充预设数据,预设数据可以为0或其他约定的值,或者,可对第一信息中的m个端口的数据进行复制,将复制后的数据,填充至第一模型的其它端口等。即第一模型中除所述第一目标端口外的其它端口的输入为预设数据,或者所述m个端口的数据的复制数据等。对于UE对上述其它端口的填充数据的处理方式,可以在协议上预设具体的处理方式,或者基站侧通过信令通知UE其处理方式,或者是UE向基站上报其处理方式等,不作限制。
举例来说,如图13所示,m的取值为8,n的取值为32,图13中的每个矩形代表4个端口。在极化方向1中,将参考信号的4个端口(该4个端口的序号可为0至3)的数据,输入到第一模型的4个端口(该4个端口的序号可为0至3)对应的输入,对于极化方向1中的剩余12个端口,填充预设数据,或者重复的数据。在极化方向2中,将参考信号的4个端口(该4个端口的序号可为4至7),输入到第一模型的4个端口(该4个端口的序号可为16至19)对应的输入,极化方向2中的剩余12个端口,填充预设数据,或者重复的数据。或者,如图14所示,m的取值为16,n的取值为32,图14中的每个矩形代表8个端口,在极化方向1和极化方向2中,将参考信号的8个端口的数据,分别填充到第一模型对应的8个端口对应的输入,对于第一模型的剩余8个端口中填充预设数据,或者重复的数据,不作赘述。
通过上述设计,在第一模型中除第一目标端口外的其它端口的填充预设数据(例如补零)的方法,非常简单,易于实现,功耗较小。可选的,为提高第一模型的性能,在训练第一模型时,设计损失函数时,可以将输入数据有可能为填充预设数据的场景考虑进去。在第一模型中除第一目标端口外的其它端口的补重复数据的方法,在将第一模型的输出发送给接收端的场景中,该方法相当于同一份数据被传输了多次,提高了数据传输的精度,而对于接收端的计算复杂度没有改变,可达到性能更优的效果。可选的,为提高第一模型的性能,在训练第一模型时,设计损失函数时,可以将输入数据有可能为重复数据的场景考虑进去。
在另一种设计中,主要考虑第一模型的输入维度中的n个端口,小于参考信号的m个端口的情况,即n的取值小于m的情况。可选的,m个端口与n个端口可均采用矩阵方式排列,所述n端口中每一行的端口数量小于或等于所述m个端口中每一行的端口数量,所述n个端口中每一列的端口数量小于或等于所述m个端口中每一列的端口数量。例如,将参考信号的m个端口,划分为Y个端口集合,至少一个端口集合中包括的端口数量等于n,且端口集合所包括n个端口的排列分布,与第一模型的输入维度中的n个端口的排列分布相同。将端口集合对应的n个端口的数据,分别输入到第一模型的n个端口对应的输入。一种情况,m可以整除n,可以将m个端口划分为Y个端口集合,每个端口集合中包括n个端口,将每个端口集合中包括的n个端口对应的数据,分别映射到第一模型的n个端口对应的输入。另一种情况,可能存在m不能整除n的情况,同样将m个端口划分为Y个端口集合。其中,Y等于
例如,可以按照行优先划分子面板,或者描述为按照行优先划分端口集合。示例的,所述m个端口采用矩阵方式排列,包含M1列M2行,采用双极化方向,所述m个端口表示为(M1,M2,2),所述n个端口采用矩阵方式排列,包含N1列N2行,采用双极化方向,所述n个端口表示为(N1,N2,2),M1、M2、N1和N2均为大于或等于1的整数;针对所述Y个端口集合中的端口集合k,k为大于或等于0,小于或等于Y-1的整数,所述m个端口和所述n个端口的对应关系,满足以下:
极化方向1:所述m个端口中的端口(i*M2+k*N2至i*M2+k*N2+N2-1)对应所述n个端口中的端口(i*N2至i*N2+N2-1);
极化方向2:所述m个端口中的端口(i*M2+k*N2+M1*M2至i*M2+k*N2+N2-1+M1*M2)对应所述n个端口中的端口(i*N2+N1*N2至i*N2+N2-1+N1*N2);其中,i为大于或等于0,小于或等于M1-1的整数。
举例来说,m的取值为64,参考信号的端口数量为64,参考信号的端口的排列分布为(8,4,2)。n的取值为32,第一模型的输入维度的端口数量为32,第一模型的输入维度的端口的排列分布为(8,2,2)。如图15所示,可将参考信号的64个端口,按照行划分为2个子面板,分别为子面板1和子面板2。子面板1和子面板2中分别包含的端口的序号可参见图15所示,不再赘述。子面板1中或子面板2中各自包含32个端口,且所包含的32个端口的排列分布与第一模型的输入维度中包含的32个端口的排列分布相同。其中,排列分布相同可以理解为行数和列数相同。将子面板1和子面板2所包含的端口对应的数据,分别映射到第一模型的输入中。关于子面板1或子面板2中包含的端口的序号,与第一模型的输入维度中的32个端口的序号的对应关系,可参见前述公式中的描述,不再赘述。
或者,可按照列优先划分子面板,或者描述为按照列优先划分端口集合。示例的,所述m个端口采用矩阵方式排列,包含M1列M2行,采用双极化方向,所述m个端口表示为(M1,M2,2),所述n个端口采用矩阵方式排列,包含N1列N2行,采用双极化方向,所述n个端口表示为(N1,N2,2);针对所述Y个端口集合中的端口集合k,k为大于或等于0,小于或等于Y-1的整数,所述m个端口和所述n个端口的对应关系,满足以下:
极化方向1:所述m个端口中的端口(i*M2+k*N1至i*M2+k*N1+M2-1)对应所述n个端口中的端口(i*N2至i*N2+M2-1);
极化方向2:所述m个端口中的端口(i*M2+k*N1+M1*M2至i*M2+k*N1+M2-1+M1*M2)对应所述n个端口中的端口(i*N2+N1*N2至i*N2+M2-1+N1*N2);其中,i为大于或等于0,小于或等于M1-1的整数。
沿用前述举例,如图16所示,可将参考信号的64个端口,按照列优先划分为2个子面板,分别称为子面板1和子面板2。该子面板1和子面板2分别包含的端口的序号可参见图16所示。子面板1或子面板2所包含的32个端口的排列分布与第一模型中包含的32个端口的排列分布相同。关于子面板1或子面板2中包含的参考信号端口的序号与第一模型的输入维度中的32个端口的序号的对应关系,可参见前述公式中的描述。
可选的,步骤703:第一设备向第二设备发送第二信息,该第二信息是根据第一模型的输出所确定的。
以第一设备为UE,第二设备为基站,参考信号为信道状态信息-参考信号(channelstate information-reference signal,CSI-RS)为例。第二信息可以为信道状态信息(channel state information,CSI)。例如,第一模型的输出可以为CSI,则UE向基站反馈CSI。或者,第一模型的输出为下行信道信息H,UE可以根据H,确定CSI,且向基站反馈CSI等。某些场景下,UE在接收到下行参考信号时,可能不需要向基站反馈对应的信道信息,因此上述步骤703是可选的。例如,下行参考信号可以为解调参考信号(demodulation referencesignal,DMRS)。UE可将DMRS的端口与第一模型的输入进行匹配,第一模型的输出可以为估计的下行信道信息H,UE根据该估计的下行信道信息H,对后续的下行数据进行解码,无需再向基站反馈下行信道的情况。
可选的,基站在接收到第二信息时,可根据第二信息,恢复第一信息。基站恢复第一信息的方式不限于AI方式。以AI方式为例,基站可根据第二模型和第二信息,确定第三信息。可选的,第二模型用于对第二信息进行处理,所述处理包括但不限于解压缩、去量化、解调、或解码等,第二模型还可称为AI模型,或解码模型等。根据下行参考信号的m个端口和第二模型的输出维度的x个端口的对应关系,对第三信息进行处理,确定第一信息,第一信息中包含m个端口的数据,m和x均为大于或等于1的整数,且m和x不相等。该第一信息是基站恢复的第一信息,与UE发送的第一信息可以相同,或不同,不作限制。例如UE发送的第一信息与基站恢复的第一信息两者间可能存在误差等。
在一种设计中,考虑参考信号的m个端口小于第二模型的输出维度的x个端口,即x大于m。可选的,当端口采用矩阵方式排列,所述x个端口中每一行的端口数量大于或等于所述m个端口中每一行的端口数量,所述x个端口中每一列的端口数量大于或等于所述m个端口中每一列的端口数量。
在该设计中,基站可根据所述m个端口和所述x个端口的对应关系,确定所述x个端口中的第二目标端口;根据所述第三信息中所述第二目标端口对应的数据,确定所述第一信息。可选的,该设计可对应于前述对于发送侧即UE侧,当第一模型的输入维度中的n个端口,大于参考信号的m个端口时,UE在n个端口中,选择第一目标端口,该第一目标端口的数量等于m。将参考信号的m个端口对应的数据,映射到第一模型的输入中。对于第一模型的其它端口,采取填充预设数据,或m个端口对应数据的复制数据的操作。在该设计中,针对其它端口填充预设数据的操作,基站可根据m个端口与x个端口的对应关系,在x个端口中选择第二目标端口。该第二目标端口对应于实际传输的信道信息对应的端口。根据第二目标端口对应的数据,恢复第一信息。可选的,x的取值可以与n的取值相同,m个端口与x个端口的对应关系,可参见发送侧m个端口与n个端口的对应关系。或者,针对其它端口填充m个端口对应数据的复制数据的操作。可以采取与前述相同的方法,在x个端口中选择第二目标端口,根据第二目标端口对应的数据,恢复第一信息。或者,可以根据第二模型的x个端口对应的数据,恢复第一信息,不作限定。可选的,第二目标端口中可以包括端口0。
在另一种设计中,考虑参考信号的m个端口大于第二模型的输出维度的x个端口,即x小于m的情况。可选的,当端口采用矩阵方式排列,所述x个端口中每一行的端口数量小于或等于所述m个端口中每一行的端口数量,所述x个端口中每一列的端口数量小于或等于所述m个端口中每一列的端口数量。
在该设计中,基站可以从UE接收Y个第二信息;根据第二模型和Y个第二信息,确定Y个第三信息。基站可以根据所述m个端口和所述x个端口的对应关系,对所述Y个第三信息进行拼接,确定所述第一信息。该设计对应于前述UE侧设计中的m大于x的情况,将m个端口拆分为Y个端口集合,将每个端口集合对应的数据分别映射到第一模型,且将根据第一模型的输出确定的第二信息发送到基站,Y个端口集合可对应于Y个第二信息,UE向基站发送Y个第二信息。而基站在接收到Y个第二信息时,将每个第二信息或第二信息处理后的数据,作为第二模型的输入,第二模型的输出为第三信息或者根据第二模型的输出确定第三信息,基站可获取Y个第三信息。根据m个端口与x个端口的对应关系,将Y个第三信息拼接在一起,组成第一信息。可选的,x与n可相等。关于m个端口与x个端口的对应关系,可参见发送侧m个端口与n个端口的对应关系。举例来说,以前述图15所示的按照行优先,划分子面板为例,基站可按照行优先的方式,将2个第三信息进行拼接,得到第一信息。各第二信息对应的端口集合可以是隐含的,例如按照其对应的混合自动重传请求(hybrid automatic repeatrequest,HARQ)进程号的先后顺序进行排列。或者,各第二信息对应的端口集合可以是信令指示的。可选的,UE除向基站发送第二信息外,还可以向基站发送第二信息对应的端口集合的标识信息。基站可按照端口集合的标识,对第三信息进行拼接。仍沿用前述举例,基站在按照行优先的方式,对2个第三信息进行拼接时,可能还需要知道每个第三信息对应的端口集合的标识,所述端口集合的标识即为图15中的子面板的标识。
如图17所示,设定UE中的编码模型的输入维度中包含32个端口,参考信号的端口为64,UE将参考信号的64端口划分为2个子面板,将每个子面板对应的数据映射到编码模型后,分别发送到基站。基站将2个子面板对应的数据按照端口进行逆变换,恢复最终的信道信息。可选的,可将2个子面板对应的数据按照端口间的位置关系进行相位调整,从而提高整体系统性能。例如,基站根据子面板1对应的反馈信息,恢复的信道信息为X1,根据子面板2对应的反馈信息,恢复的信道信息为X2,X1与X2间的相位差为α。示例的,所述相位差a可以是X1与X2中对应的第一个元素相除的相位。基站可根据波长、子面板1与子面板2之间的相对距离等,计算出期望的X1和X2之间的相对相位角度
以第一设备为UE,第二设备为基站,对下行参考信号进行处理为例,描述本公开的方案。
随着无线通信技术的发展,通信系统中所支持的业务不断增多,在系统容量、通信时延等指标上均对通信系统提出了更高的要求。其中,MIMO技术,尤其是大规模MIMO,通过在收发端配置大规模天线阵列,可实现空域的分集增益进而显著地增加系统容量,此外系统容量的增加又可以降低通信时延,因此大规模MIMO技术已经成为通信系统演进中一个关键的方向。在大规模MIMO技术中,基站可以利用相同的时频资源向多个UE同时发送数据,即多用户MIMO(multi-user MIMO,MU-MIMO),或者向同一个UE同时发送多个数据流,即单用户MIMO(single-user MIMO,SU-MIMO),该多个UE的数据或者该同一个UE的多个数据流之间是空分复用的。
在大规模MIMO系统中,基站需要对UE的下行发送数据进行预编码。基站使用预编码技术可实现空分复用(spatial multiplexing),即使得不同UE间的数据或同一个UE的不同数据流间的数据在空间进行隔离,从而可以降低不同UE间或不同数据流间的干扰,并提升UE端的接收信干噪比,提高下行数据传输的速率。基站在进行预编码时,需要使用预编码矩阵对下行数据进行预编码。为了获得预编码矩阵,基站需要获得下行信道的CSI,根据CSI确定预编码矩阵。但是,在目前广泛应用的基于频分双工(frequency division duplex,FDD)的通信系统中,上下行信道具备互异性,基站需要通过由UE进行上行反馈的方式获取下行CSI。例如,UE接收来自基站的下行参考信号。由于UE已知下行参考信号的发送序列,UE基于接收到的下行参考信号可以估计(或称为测量)该下行参考信号所经历的下行信道的CSI,并将测量得到的CSI反馈给基站。UE所反馈的CSI精度越高,反馈的信道信息越完整。基站根据CSI确定的预编码矩阵越准确,下行空分复用性能越好,后续UE接收信号的信干噪比越高,系统容量越高。在现实的布网环境中,往往会根据许多客观因素,例如预算、城区密集程度等,来规划基站。如何在不同的环境下对CSI进行高精度的压缩反馈是一个重要的研究课题。目前的研究主要集中在希望通过AI技术,即通过学习的方法获得CSI的特征,对信道信息进行压缩量化,并反馈给基站。在本公开中,提供以下解决方案:
在一种方案中,设置单边模型,在一种设计中,UE维护第一模型,该第一模型用于对确定的下行信道信息进行压缩,以第一模型为编码模型为例。基站侧不维护第二模型,该第二模型可用于恢复压缩的下行信道信息,在后续描述中以第二模型为解码模型为例描述。例如,在一种实现方式中:UE根据接收的下行参考信号,确定下行信道的特征矩阵H;对下行信道的特征矩阵H进行预处理,将预处理后的数据,作为编码模型的输入,编码模型的输出为压缩的下行信道信息。可选的,对压缩的下行信道信息进行量化。将量化后的信息发送给基站。上述压缩的下行信道信息可以认为是码本中与原始信道信息最相关的码字,且将码字的标识发送给基站。基站可根据量化后的信息,利用码本恢复下行信道信息。示例的,UE发送给基站的信息可称为CSI反馈。
在另一种设计中,基站维护解码模型,UE不维护编码模型。UE可以按照非AI模型(例如3GPP协议)的方法发送CSI信息,可选地,UE可采用非AI的算法,对下行信道信息进行压缩等。基站将反馈的CSI信息通过解码模型,恢复下行信道信息。
在另一种方案中,设置多边模型。UE维护编码模型,基站维护解码模型。UE根据编码模型,向基站反馈CSI信息。基站根据解码模型,恢复下行信道信息。
可选的,UE可以根据UE的能力,维护A个编码模型。基站可以根据网络能力,维护B个解码模型。A和B均为大于或等于1的正整数。编码模型和解码模型可以是通过AI训练得到的,不限于离线训练或在线训练。可以在训练的时候已经确定好了其输入维度。编码模型和解码模型可以联合训练,也可以分别训练得到,训练的过程可以将最小化输入数据和输出数据的均方误差(mean square error,MSE)作为损失函数进行训练,也可以将输入数据和输出数据的相关性作为损失函数进行训练。编码模型确定了其输入维度,编码模型输出的信息经过解码模型后,确定了其输出维度。由于输入的数据是信道信息,输出的数据是恢复的信道信息,因此编码模型和解码模型需要匹配使用。
编码模型的输入维度中包含了端口数、以及各端口的排列方式,端口的排列方式与端口的面板结构是有关的,端口的面板结构包含N1列N2行,极化是双极化,因此端口的排列方式为(N1,N2,2),端口数是N1*N2*2。当编码模型和解码模型需要匹配使用时,例如编码模型的输入维度中对应的端口排列方式是(N1,N2,2)时,则相应的选择的解码模型输出维度中对应的端口排列方式也需要满足(N1,N2,2)。例如,UE维护3个编码模型,该3个编码模型的输入维度中对应的端口排列方式分别为(16,1,2)、(4,4,2)和(8,2,2)。基站维护2个解码模型,2个解码模型的输出维度中的端口排列方式分别为(4,4,2)和(8,2,2),则只能采用(8,2,2)的编码模型和(8,2,2)的解码模型配对使用。如何选择配对的编码模型和解码模型,本公开提供以下解决方案:
UE向基站上报编码模型能力,基站根据UE上报的编码模型能力进行判断:例如,当UE仅支持或维护一个编码模型时,则基站可根据UE上报的一个编码模型,匹配相应的解码模型。若基站则没有成功匹配到解码模型,则基站向UE发送一信令,用于通知模型匹配失败。或者,若基站则成功匹配到解码模型,则基站可向UE发送一信令,用于通知模型匹配成功。该过程是可选的,例如,UE可以在未收到匹配失败的信令时,默认匹配成功。或者,当UE支持或维护多个编码模型时,则基站根据UE上报的多个编码模型,均未匹配到解码模型时,可向UE发送一信令,用于通知模型匹配失败。或者,基站模型匹配成功,则基站向UE下发一信令用于通知成功匹配的编码模型。可选的,基站可根据计算能力、参考信号的端口排列等因素,来决策匹配的编码模型。
一种可能的实现中,系统支持的参考信号的端口的最大数量为32端口。为了适配其他可能的参考信号端口,UE可维护三个编码模型,该3个编码模型的输入维度的端口排列方式可以分别为(16,1,2)、(4,4,2)或(8,2,2)。关于UE具体使用该3个编码模型中的哪一个编码模型进行下行信道信息的压缩,主要取决于基站的决策。关于基站决策的过程,可参见上述基站选择配对的编码模型和解码模型中的说明。实质上,无论UE选择该3个编码模型中的哪一个编码模型,该3个编码模型中的输入维度中包括的端口数量均为32,该32个端口的编号可为0至31。后续通过对下行参考信号进行信道估计,确定的m个端口的数据,会按照某种映射规则,将m个端口的数据,分别输入到编码模型的32个端口对应的输入中。也就是说,无论UE选择何种端口排列方式的编码模型,只要该编码模型的输入维度中包括32个端口,将参考信号的m个端口对应的数据映射到该32个端口的过程都相似。因此,在后续重点考虑32与m的大小关系。
在一种设计中,UE可对接收的下行参考信号进行信道估计,获得下行信道信息H,H中包含的参考信号的m个端口的数据,当m的取值小于32时,可根据前述的方式,在第一编码模型(该第一编码模型可是UE在所支持的3个编码模型中,所选择的用于信道信息压缩的模型)的输入维度中的32个端口中,选择m个端口进行输入,其它端口输入预设数据,或者对m个端口的数据复制的数据等,不作限定。上述过程也可以描述为,在第一编码模型中划分出一个子模型,该子模型的输入中包括的端口数量为m。可选的,该子模型的输入端口的排列分布可以与参考信号的m个端口的排列分布相同。
或者,在另一种可能的实现中,随着技术的发展,参考信号端口的数量可能不限于32,可能会出现64和128等。对于UE侧的编码模型不宜随着参考信号端口的数量无限制扩大,因为编码模型的输入端口数量越多,编码模型的参数也越多,UE侧的计算复杂度越大,对UE和基站很不友好,因此主要考虑在协议支持的编码模型上进行扩展,以适配参考信号的高数量端口需求。例如,设计编码模型的输入维度中包含32个端口。后续对于参考信号的64个端口,或128个端口等,可划分为多个子面板,每个子面板中包含32个端口。可选的,每个子面板包含的32个端口的排列分布与编码模型的输入维度中的32个端口的排列分布相同。将每个子面板中包含的数据,分别输入到编码模型的32个端口中。对编码模型的输出,或者输出处理后的数据,分别发送到基站。基站将接收到的数据,按照一定的规则整合在一起。
在无线网络中,UE不是一直静止不动的,在移动的过程中会发生小区切换等,此时会使得UE进入一个新的小区,给UE服务的基站的端口数以及端口排布都会发生变化。或者,UE在不同的位置初始接入到的基站是不同的,这样也会导致给该UE服务的基站的端口数以及端口排列都是不同的。为UE服务的基站的端口数以及端口排布发生变化或不同,会导致参考信号端口的端口数及端口排布都不同。而在本公开中,不需要针对每种参考信号的端口形态都设置一个编码模型,使能了最小化编码模型存储,通过有限个数的编码模型,甚至单个编码模型,几乎可以完全满足协议以及后续扩展设计中所有的参考信号的处理,减少了模型的训练和存储开销。
以图7流程中的第一设备为UE,第二设备为基站,第一模型为编码模型,第二模型为解码模型,参考信号为CSI-RS,第二信息为CSI反馈为例。如图18所示,提供一种流程,可以包括:
步骤1800:UE支持或维护A套编码模型,基站支持或维护B套解码模型,A与B均为自然数,且A与B不同时为零。
其中,训练编码模型与解码模型的实体可以是基站、UE、或其它第三方设备等,不作限制。例如,由基站训练编码模型和解码模型,则基站可将训练的编码模型发送给UE,UE可以直接使用基站发送的编码模型,或者可以对该编码模型的参数调整后再使用。或者,由UE训练编码模型和解码模型,则UE将训练好的解码模型上传给基站,或者,由第三方设备训练编码模型和解码模型,则UE和基站可以从第三方设备分别下载编码模型和解码模型。可选的,编码模型与解码模型需要配对使用,UE与基站可协商使用的编码模型和解码模型的过程,可参见前述,不再赘述。
步骤1801:基站向UE发送CSI-RS配置信息和CSI-RS。
UE接收到CSI-RS配置信息时,可根据该配置信息的配置,接收来自基站的CSI-RS。
步骤1802:UE根据CSI-RS,确定信道信息H,信道信息H经过预处理、编码、量化等后,确定量化后的信息。
如图19所示,UE对CSI-RS进行信道估计。可选的,对信道估计的信息进行预处理,该预处理的过程可包括奇异值分解(singular value decomposition,SVD)分解和离散傅里叶变换(discrete fourier transform,DFT)转换等。预处理前的信道信息的维度包括(nTx,nRx,nSubband),预处理后的信道信息的维度包括(nTx,nSubband)。本公开重点考虑基站的端口nTx,又称为参考信号的端口,与编码模型的输入维度中包含的端口的自适应。在前述描设计中,设定参考号的端口数量为m,称为参考信号的m个端口。编码模型的输入维度中包含n个端口,称为编码模型的n个端口。在前述设计中,具体分为x大于n,与x小于n两种情况为例,分别给出相应的解决方案。无论采用上述何种解决方案,可将参考信号m个端口的数据映射到编码模型中,编码模型的输出可以是浮点矩阵。经过量化,将浮点矩阵转换为二进制比特。
步骤1803:UE向基站发送量化后的信息,该量化后的信息可称为CSI反馈。
步骤1804:基站对量化后的信息经过反量化、解码等处理,恢复估计的信道信息P。
如图19所示,基站可对接收后的量化信息进行反量化和解码。例如,基站将量化后的信息,输入反量化器,得到对应的浮点矩阵。将浮点矩阵映射到解码器,解码器的输出中包含x个端口的信息。根据前述将x个端口与参考信号的m个端口作匹配,恢复出信道数据P。该恢复的信息数据P与前述UE估计的信息数据H可相同,或略有差异。
在本公开中,通过自适应的方法,将参考信号的端口上的数据映射到编码模型上,使能了最小化存储模型,通过有限个数的模型便几乎可以满参考信号端口的所有场景的需求。
可以理解的是,为了实现上述方法中的功能,UE和基站包括了执行各个功能相应的硬件结构和/或软件模块。本领域技术人员应该很容易意识到,结合本公开描述的各示例的单元及方法步骤,本公开能够以硬件或硬件和计算机软件相结合的形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用场景和设计约束条件。
图20和图21为本公开提供的可能的装置的结构示意图。这些通信装置可以用于实现上述方法中UE或基站的功能,因此也能实现上述方法所具备的有益效果。
如图20所示,通信装置2000包括处理单元2010和收发单元2020。通信装置2000用于实现上述方法中基站或UE的功能。
当通信装置2000用于实现上述方法中UE或基站的功能时:收发单元2020用于接收参考信号;处理单元2010用于根据接收到的参考信号,确定第一信息,所述第一信息中包含所述参考信号的m个端口的数据,以及,根据所述m个端口和第一模型的输入维度的n个端口的对应关系,将所述m个端口的数据映射到所述第一模型的输入,得到所述第一模型的输出,所述m和n均为大于或等于1的整数,且m和n不相等。
当通信装置2000用于实现上述方法中的基站的功能时:收发单元2020,用于接收来自终端设备的第二信息;处理单元2010,用于根据第二模型和所述第二信息,确定第三信息;根据下行参考信号的m个端口和所述第二模型的输出维度的x个端口的对应关系,对所述第三信息进行处理,确定第一信息,所述第一信息中包含所述m个端口的数据,所述m和x均为大于或等于1的整数,且m和x不相等。
有关上述处理单元2010和收发单元2020更详细的描述可以直接参考上述方法中相关描述直接得到,这里不加赘述。
如图21所示,通信装置2100包括处理器2110和接口电路2120。处理器2110和接口电路2120之间相互耦合。可以理解的是,接口电路2120可以为收发器、输入输出接口、或管脚等。可选的,通信装置2100还可以包括存储器2130,用于存储处理器2110执行的指令或存储处理器2110运行指令所需要的输入数据或存储处理器2110运行指令后产生的数据。
当通信装置2100用于实现上述方法时,处理器2110用于实现上述处理单元2010的功能,接口电路2120用于实现上述收发单元2020的功能。
当上述通信装置为应用于终端的芯片时,该终端芯片实现上述方法实施例中终端的功能。该终端芯片从终端中的其它模块(如射频模块或天线)接收信息,该信息是基站发送给终端的;或者,该终端芯片向终端中的其它模块(如射频模块或天线)发送信息,该信息是终端发送给基站的。
当上述通信装置为应用于基站的模块时,该基站模块实现上述方法实施例中基站的功能。该基站模块从基站中的其它模块(如射频模块或天线)接收信息,该信息是终端发送给基站的;或者,该基站模块向基站中的其它模块(如射频模块或天线)发送信息,该信息是基站发送给终端的。这里的基站模块可以是基站的基带芯片,也可以是DU或其他模块,这里的DU可以是开放式无线接入网(open radio access network,O-RAN)架构下的DU。
可以理解的是,本公开中的处理器可以是中央处理单元(central processingunit,CPU),还可以是其它通用处理器、数字信号处理器(digital signal processor,DSP)、专用集成电路(application specific integrated circuit,ASIC)、现场可编程门阵列(field programmable gate array,FPGA)或者其它可编程逻辑器件、晶体管逻辑器件,硬件部件或者其任意组合。通用处理器可以是微处理器,也可以是任何常规的处理器。
本公开中的存储器可以是随机存取存储器、闪存、只读存储器、可编程只读存储器、可擦除可编程只读存储器、电可擦除可编程只读存储器、寄存器、硬盘、移动硬盘、CD-ROM或者本领域熟知的任何其它形式的存储介质。
一种示例性的存储介质耦合至处理器,从而使处理器能够从该存储介质读取信息,且可向该存储介质写入信息。存储介质也可以是处理器的组成部分。处理器和存储介质可以位于ASIC中。另外,该ASIC可以位于基站或终端中。当然,处理器和存储介质也可以作为分立组件存在于基站或终端中。
本公开中的方法可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机程序或指令。在计算机上加载和执行所述计算机程序或指令时,全部或部分地执行本公开所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、网络设备、用户设备、核心网设备、OAM或者其它可编程装置。所述计算机程序或指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机程序或指令可以从一个网站站点、计算机、服务器或数据中心通过有线或无线方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是集成一个或多个可用介质的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,例如,软盘、硬盘、磁带;也可以是光介质,例如,数字视频光盘;还可以是半导体介质,例如,固态硬盘。该计算机可读存储介质可以是易失性或非易失性存储介质,或可包括易失性和非易失性两种类型的存储介质。
在本公开中,如果没有特殊说明以及逻辑冲突,不同的实施例之间的术语和/或描述具有一致性、且可以相互引用,不同的实施例中的技术特征根据其内在的逻辑关系可以组合形成新的实施例。
本公开中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B的情况,其中A,B可以是单数或者复数。在本公开的文字描述中,字符“/”,一般表示前后关联对象是一种“或”的关系;在本公开的公式中,字符“/”,表示前后关联对象是一种“相除”的关系。“包括A,B或C中的至少一个”可以表示:包括A;包括B;包括C;包括A和B;包括A和C;包括B和C;包括A、B和C。
可以理解的是,在本公开中涉及的各种数字编号仅为描述方便进行的区分,并不用来限制本公开的范围。上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定。
- 一种口语测评方法、装置及一种生成口语测评模型的装置
- 一种欺诈检测模型训练方法和装置及欺诈检测方法和装置
- 一种神经网络模型训练方法及装置、文本标签确定方法及装置
- 一种绿光估计模型训练方法及装置、影像合成方法及装置
- 一种去除抗药抗体检测样品中游离药物的装置和方法、该装置的制备方法及应用
- 一种用于2型糖尿病动物模型或肥胖动物模型建立的诱导饲料及其应用和应用方法
- 一种用于抑郁症动物模型构建的夹尾装置、表情图像采集系统及模型构建方法和应用