非受限环境下人脸表情识别的特征提取和增强方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及计算机人工智能领域,尤其涉及一种自然环境下多级特征提取与融合的人脸表情识别方法。
背景技术
人类的情感和情绪状态可以通过面部表情来外在体现,这在日常社会活动中扮演着重要的角色。随着科技的发展,人脸表情识别(FER)技术已经被应用于心理健康评估和人机交互系统等多个领域。作为计算机视觉领域的热点之一,人脸表情识别已经引起研究人员的广泛关注。
然而,人脸表情识别面临着很多挑战。在图像获取方面,角度、比例、遮挡等因素都会对最终的识别结果产生影响。此外,在实际应用中,人脸表情图像往往存在不均匀的照明和低质量等干扰因素,这也会对识别结果产生负面影响。因此,如何设计出性能更好、泛化能力更强的人脸表情识别模型,成为人脸表情识别研究的重点。
近年来,随着深度学习方法在计算机视觉任务上的广泛应用,基于深度学习的人脸表情识别方法也逐渐得到了发展。这些方法利用深度学习模型自动从原始数据中学习特征,代替了传统的手动特征提取方法,可以在不同任务和数据集上实现更好的性能。虽然基于深度学习的方法已经在实验室收集的数据集中取得了显著成功,但在野外环境下识别无约束面部表情时仍然面临许多挑战,因为面部表情图像容易受到诸如弱光条件和模糊图像等干扰因素的影响。
由于基于常规卷积神经网络(CNN)的模型在表情识别的竞争中逐渐表现出弱势,一些研究人员打算研究其他方法来进行人脸表情识别。大多方法基于数据增强、类内公有特征(intra-category common feature)、注意力机制、标签噪声、不确定性等方向进行人脸表情识别。[Farzaneh A H,Qi X.Facial expression recognition in the wild viadeep attentive center loss,in Proceedings of the IEEE/CVF winter conferenceon applications of computer vision.2021:2402-2411.]提出了一种深度注意力中心损失(DACL)方法,它可以估计与特征重要性相关的注意力权重,并实现类内紧凑和类间分离。[Shome D,Kar T.FedAffect:Few-shot federated learning for facial expressionrecognition,in Proceedings of the IEEE/CVF International Conference onComputer Vision.2021:4168-4175.]提出了一种基于自我监督的联合学习方法,以实现稳健和多样化的人脸表征。[Zheng Z,Rasmussen C,Peng X.Student-Teacher Oneness:AStorage-efficient approach that improves facial expression recognition.InProceedings of the IEEE/CVF International Conference on Computer Vision.2021:4077-4086.]提出了一种基于在线蒸馏的人脸表情识别的学生-教师一体性(STO)方法,与现有的方法不同,这种方法设计了随机子网络来代替多分支结构成分。[Wang Z,Zeng F,Liu S,et al.OAENet:Oriented attention ensemble for accurate facial expressionrecognition,Pattern Recognition,2021,112:107694.]提出了一种定向注意伪模拟网络,通过融合全局和局部面部信息来实现高精度的人脸表情识别。
然而以上方法忽略了不同的特征提取方法对最终人脸表情识别的影响,在特征提取阶段,很多底层特征信息被丢失,纯粹的高层抽象特征不足以识别具有挑战性的面部表情,例如,当面部表情过于相似时。此外,这些方法很少探讨从不同卷积核大小的卷积中提取的特征对最终人脸表情识别的影响。
发明内容
为了解决上述问题,本发明实施例提供一种自然环境下多级特征提取与融合的人脸表情识别方法。
本发明实施例提供一种自然非受限环境下的人脸表情识别的特征提取模块、特征增强模块和优化策略,包括:
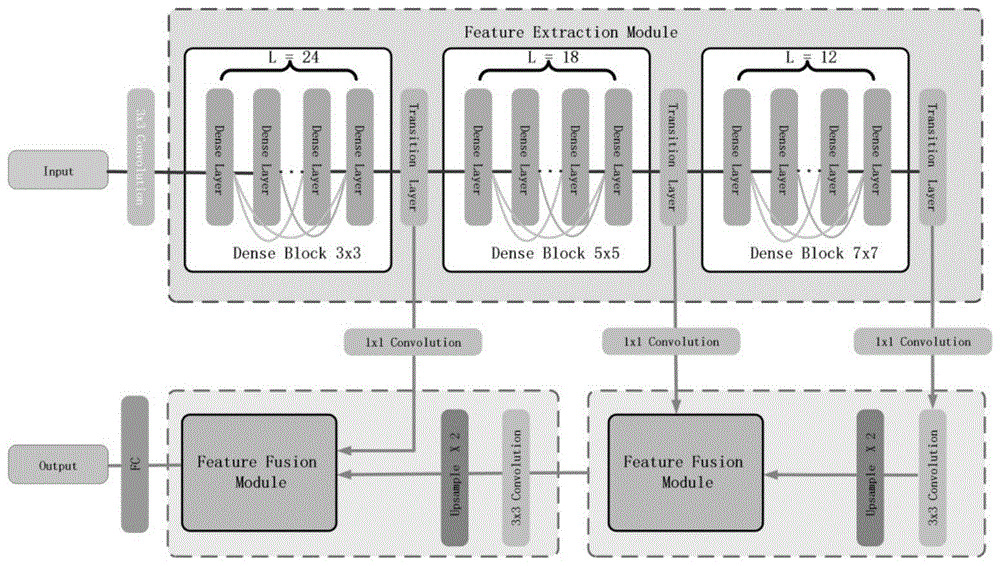
特征提取模块主要由3个不同卷积核尺度(3x3、5x5、7x7)的DenseNet密集块构成,目的是尽可能多地提取多层次的面部表情特征(低级到高级的特征),每一个子块之间由过度层连接用于减少特征维度。
密集块的DenseNet骨干网络包括:批量归一化(Batch Normalization)、ReLu激活和1x1卷积操作。
此外,一个密集块包含不同数量的密集连接层,每层的特征图大小相同,层与层之间采用密集连接的方式。对于每一个密集连接层,其输出包含了之前的所有层,它可以用一个数学公式表示如下:
其中C为连接操作;
过渡器(Transition)包括:批量归一化(Batch Normalization)、ReLu激活、1x1卷积和2x2池化。
特征融合模块有全局注意(Global Attention)和局部注意(Local Attention)操作,高级特征图通过3x3卷积(Convolution)、2倍尺度的上采样(Up Sample)和低级特征图进行元素相加计算后的数据矩阵作为特征融合模块的输入,在全局注意(GlobalAttention)和局部注意(Local Attention)处理后与输入分别进行元素相乘计算,输出的两个数据矩阵进行元素相加计算,以产生所述融合后的面部表情特征图。
特征融合模块的输入可以用一个数学公式表示如下:
F=U
其中H
F
其中,GA(F)和LA(F)表示全局融合和局部融合权值。F
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中网络框架的架构图;
图2为本发明实施例中特征融合模块的概述图;
图3为本发明实施例中密集层的概述图;
图4为本发明实施例中过渡层的概述图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
对于特征提取模块,采用3个不同卷积核尺度(3x3、5x5、7x7)并以DenseNet为骨干网络的密集块。
图-1为网络框架图。该框架有两个顺序的子模块:特征提取模块FEM(FeatureExtraction Module)和特征融合模块FFM(Feature Fusion Module),FEM由3层密集块组成,L表示每个密集块的层量,分别为24、18和12,FC为全连通层,所有提取的特征都被FFM模块融合。
图-2为特征融合模块,它包括两种注意力操作:全局注意力操作和局部注意力操作。
图3所示密集层由两层卷积组成,并带有批量归一化(BN)和ReLu操作。K是每个密集层中卷积核的大小,这取决于不同的密集块,K分别为3、5和7。
图4所示过渡层由1×1卷积和2×2池化操作组成。
特征融合模块的输入,如公式5所示H
全局注意力(Global Attention)包括:卷积核大小3x3的2层卷积层、卷积核大小3x3的4层卷积层、平均池化层(Average Pooling)和Sigmoid激活函数。
局部注意力(Local Attention)包括:卷积核大小3x3的2层卷积层、卷积核大小3x3的4层卷积层、卷积核大小1x1的1层卷积层和Sigmoid激活函数。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
参考文献
[1]Farzaneh A H,Qi X.Facial expression recognition in the wild viadeep attentive center loss[C]//Proceedings of the IEEE/CVF winter conferenceon applications of computer vision.2021:2402-2411.
[2]Shome D,Kar T.FedAffect:Few-shot federated learning for facialexpression recognition[C]//Proceedings of the IEEE/CVF InternationalConference on Computer Vision.2021:4168-4175.
[3]Zheng Z,Rasmussen C,Peng X.Student-Teacher Oneness:A Storage-efficient approach that improves facial expression recognition[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.2021:4077-4086.
[4]Wang Z,Zeng F,Liu S,et al.OAENet:Oriented attention ensemble foraccurate facial expression recognition[J].Pattern Recognition,2021,112:107694.
- 非约束环境下的有效人脸特征提取方法
- 非约束环境下的有效人脸特征提取方法