基于极限随机森林的引水隧洞围岩变形预测方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及专门适用于行政、商业、金融、管理、监督或预测目的的数据处理系统或方法技术领域,具体涉及一种基于极限随机森林的引水隧洞围岩变形预测方法及系统。
背景技术
我国水资源分布极度不平衡,水利工程包括引水隧洞的建设是协调水资源的重要基础设施。引水隧洞作为复杂山区上水资源输送的重要水利工程之一,为缩短山区输水距离,提高经济效益等方面起到了关键作用。因此引水隧洞的安全关系到人民生产生活的安全保证。
引水隧洞围岩的变形伴随其开挖以及使用的全过程,是判断引水隧洞结构健康与否的重要指标。引水隧洞围岩变形可以借助具有物理意义和工程环境背景的参数作为输入进行变形点预测。传统围岩预测方法大多是基于已有的监测曲线进行点对点预测,这种方法可以提供高精度的预测数值,但很难提供关于预测结果误差的不确定性或者程度。而区间预测可以给出一个预测结果的范围或者置信区间,提供了关于预测结果的不确定性估计,可以帮助决策者更准确地评估风险,并制定相应地决策策略。
发明内容
针对现有技术存在的不足,本发明提出一种基于极限随机森林的引水隧洞围岩变形预测方法及系统,可以对引水隧洞围岩变形进行区间预测,从而提高预测结果的可靠性,具体技术方案如下:
第一方面,提供了一种基于极限随机森林模型的引水隧洞围岩变形区间预测方法,在第一方面的第一种可实现方式中,包括:
获取引水隧洞围岩变形历史数据,通过所述引水隧洞围岩变形历史数据获取完整特征数据集;
根据所述完整特征数据集,采用极限随机森林模型进行引水隧洞围岩变形区间预测。
结合第一方面的第一种可实现方式中,在第一方面的第二种可实现方式中,通过所述引水隧洞围岩变形历史数据获取完整特征数据集,包括:
根据开挖以及运行过程中引水隧洞围岩变形的影响因素,从所述引水隧洞围岩变形历史数据提取出特征数据集;
通过所述特征数据集构建缺失数据填充模型,并通过所述缺失数据填充模型对所述特征数据集中的缺失数据进行填充,得到所述完整特征数据集。
结合第一方面的第二种可实现方式中,在第一方面的第三种可实现方式中,所述特征数据集包括:开挖瞬时效应特征集、长期蠕变特征集、围岩参数特征集和掘进参数特征集。
结合第一方面的第二种可实现方式中,在第一方面的第四种可实现方式中,所述缺失数据填充模型为基于特征相关性的KNN模型。
结合第一方面的第四种可实现方式中,在第一方面的第五种可实现方式中,所述KNN模型根据不同特征之间的相关系数计算样本之间的加权距离,并根据加权距离选取最相似的样本数据估算所述缺失数据。
结合第一方面的第一种可实现方式中,在第一方面的第六种可实现方式中,采用极限随机森林模型进行引水隧洞围岩变形区间预测,包括:
通过所述完整特征数据集构建训练集和验证集;
采用极值标准化方法分别对所述训练集和验证集进行标准化处理。
结合第一方面的第一种可实现方式中,在第一方面的第七种可实现方式中,包括:根据均方根误差和平均误差对训练得到的极限随机森林模型进行验证。
结合第一方面的第一种可实现方式中,在第一方面的第八种可实现方式中,采用极限随机森林模型进行引水隧洞围岩变形区间预测,包括:
根据所述完整特征数据集,通过训练好的极限随机森林模型得到多个预测结果;
将所有预测结果按照从小到大的顺序依次排列,并根据不同分位数的预测结果预测引水隧洞围岩变形区间。
第二方面,提供了一种基于极限随机森林模型的引水隧洞围岩变形区间预测系统,在第二方面的第一种可实现方式中,包括:
数据获取模块,配置为获取引水隧洞围岩变形历史数据,通过所述引水隧洞围岩变形历史数据获取完整特征数据集;
区间预测模块,配置为根据所述完整特征数据集,采用极限随机森林模型进行引水隧洞围岩变形区间预测。
结合第二方面的第一种可实现方式中,在第二方面的第二种可实现方式中,所述数据获取模块包括:
数据提取单元,配置为根据开挖以及运行过程中引水隧洞围岩变形的影响因素,从所述引水隧洞围岩变形历史数据提取出特征数据集;
数据填充单元,配置为通过所述特征数据集构建缺失数据填充模型,并通过所述缺失数据填充模型对所述特征数据集中的缺失数据进行填充,得到所述完整特征数据集。
有益效果:
1.采用了基于集成算法的极限随机森林预测模型评估引水隧洞围岩变形影响因素与引水隧洞围岩变形间的非线性映射关系,实现引水隧洞围岩变形的区间预测。相较于传统的点预测方法,该方法集成多个子随机树的预测结果构建一个概率区间以获取相对稳定的评估区间预测结果,提高了引水隧洞围岩变形预测结果的可靠性。
2.通过考虑和构造引水隧洞开挖过程中的瞬时形变效应和长期蠕变效应建立具有明确物理含义的引水隧洞围岩变形因子特征集,弥补了传统引水隧洞围岩变形预测中影响因子相关性弱,缺乏对引水隧洞围岩变形时效性的问题。
3.本发明通过基于不同特征之间的相关性,计算样本间的加权距离,从而考虑到了特征相关性来估算特征集中的缺失值,克服了传统KNN填充算法中无法考虑各特征对缺失特征的影响。
附图说明
为了更清楚地说明本发明具体实施方式,下面将对具体实施方式中所需要使用的附图作简单地介绍。在所有附图中,各元件或部分并不一定按照实际的比例绘制。
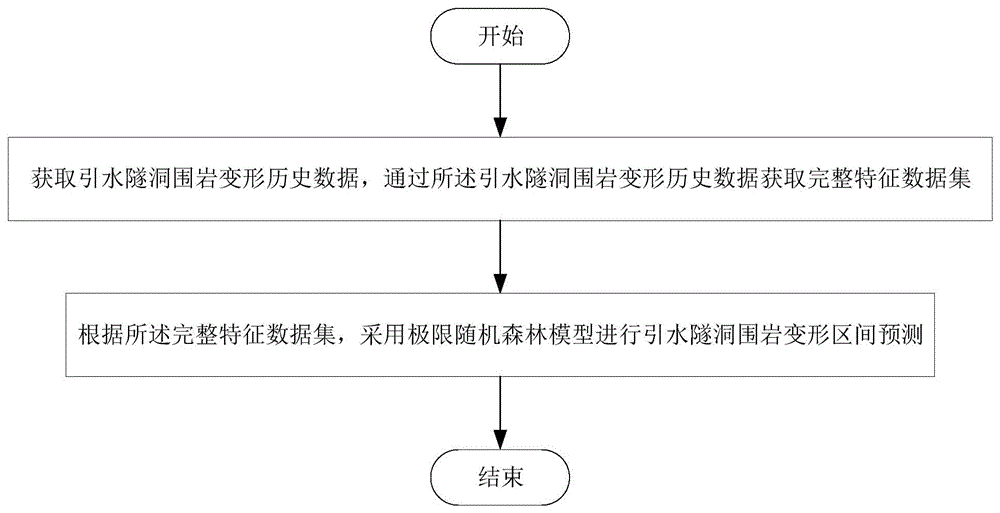
图1为本发明一实施例提供的基于极限随机森林模型的引水隧洞围岩变形区间预测方法的流程图;
图2为本发明一实施例提供的缺失数据填充方法的流程图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。
如图1所示的基于极限随机森林模型的引水隧洞围岩变形区间预测方法的流程图,该预测方法包括:
步骤1、获取引水隧洞围岩变形历史数据,通过所述引水隧洞围岩变形历史数据获取完整特征数据集;
步骤2、根据所述完整特征数据集,采用极限随机森林模型进行引水隧洞围岩变形区间预测。
具体而言,首先,可以获取引水隧洞围岩变形历史数据,并基于引水隧洞围岩变形历史数据构建起相应的完整特征数据集。然后,可以基于所述完整特征数据集构建起训练集和验证集,通过训练集对极限随机森林模型进行训练,并通过验证集对训练过程中的极限随机森林模型进行验证,最终得到最优的极限随机森林模型。
通过最优的极限随机森林模型可以评估引水隧洞围岩变形影响因素与引水隧洞围岩变形间的非线性映射关系,从而实现引水隧洞围岩变形的区间预测。相较于传统的点预测方法,该方法集成多个子随机树的预测结果构建一个概率区间以获取相对稳定的评估区间预测结果,提高了引水隧洞围岩变形预测结果的可靠性。
在本实施例中,可选的,在步骤1中,通过所述引水隧洞围岩变形历史数据获取完整特征数据集,包括:
根据开挖以及运行过程中引水隧洞围岩变形的影响因素,从所述引水隧洞围岩变形历史数据提取出特征数据集;
通过所述特征数据集构建缺失数据填充模型,并通过所述缺失数据填充模型对所述特征数据集中的缺失数据进行填充,得到所述完整特征数据集。
具体而言,首先,可以根据开挖以及运行过程中引水隧洞围岩变形的影响因素,从所述引水隧洞围岩变形历史数据提取出特征数据集。然后,可以通过特征数据集构建起缺失数据填充模型,通过数据填充模型对特征数据集中的缺失数据进行估算,从而对特征数据集中的缺失数据进行补充,得到完整特征数据。
在本实施例中,可选的所述特征数据集包括:开挖瞬时效应特征集、长期蠕变特征集、围岩参数特征集和掘进参数特征集。
具体而言,构建的特征数据集包括开挖瞬时效应特征集、长期蠕变特征集、围岩参数特征集和掘进参数特征集。
其中,开挖瞬时效应特征集为
长期蠕变特征集Y
其中,T
围岩参数特征集Y
构建特征数据集时考虑了引水隧洞开挖过程中的瞬时形变效应和长期蠕变效应,建立起特征数据集是具有明确物理含义的引水隧洞围岩变形因子特征集,弥补了传统引水隧洞围岩变形预测中影响因子相关性弱,缺乏对引水隧洞围岩变形时效性的问题。
在本实施例中,可选的,所述缺失数据填充模型为基于特征相关性的KNN模型。具体而言,可以通过KNN模型作为缺失数据填充模型对特征数据集中的缺失数据进行补充。如图2所示,具体步骤如下:
步骤S11、从所述特征数据集中筛选出仅包含完整记录的完整样本集;
步骤S12、根据所述完整样本集计算不同特征之间的皮尔逊相关系数,计算方法如下:
其中r
步骤S13、对于所述特征数据集中某个样本i其缺失特征为p,样本i与所述完整样本集中第a个样本间的加权距离按如下公式计算:
其中,n
如此,可以基于不同特征之间的相关性,计算得到样本间的加权距离,从而考虑到了特征相关性来估算特征集中的缺失值,克服了传统KNN填充算法中无法考虑各特征对缺失特征的影响。
步骤S14、对于所述特征集中某个样本i缺失特征p,x
步骤S15、通过估算数据集估算缺失数据x
在本实施例中,可根据特征数据集中缺失数据量来决定选取的样本数量k。
在本实施例中,可选的,在步骤2中,采用极限随机森林模型进行引水隧洞围岩变形区间预测,包括:
通过所述完整特征数据集构建训练集和验证集;
采用极值标准化方法分别对所述训练集和验证集进行标准化处理。
具体而言,在构建起完整特征数据集后,首先,可以按照8:2的比例从完整特征数据集中随机抽取出特征数据样本分别构建起训练集和验证集。然后,可以采用极值标准化方法分别对训练集和验证集中的样本进行线性变换,从而将样本数据标准化映射到设定的极值区间中,用于消除不同量纲的变量对于参数学习的影响。
在本实施例中,可选的,在训练极限随机森林模型的过程中,可以根据均方根误差和平均误差对训练得到的极限随机森林模型进行验证。具体计算式如下:
其中,m为极限随机森林模型中子随机树的个数,
在本实施例中,可选的,在根据均方根误差和平均误差确定最优极限随机森林模型后,可以根据所述完整特征数据集,通过训练好的极限随机森林模型得到多个预测结果。然后,将所有预测结果按照从小到大的顺序依次排列,并根据不同分位数的预测结果预测引水隧洞围岩变形区间,从而集成多个子随机树的预测结果构建一个概率区间获取相对稳定的评估区间预测结果,提高引水隧洞围岩变形区间预测结果的可靠性。在本实施例中,可以将95%和5%分位数的预测结果确定为引水隧洞围岩变形区间的上下限。
一种基于极限随机森林模型的引水隧洞围岩变形区间预测系统,包括:
数据获取模块,配置为获取引水隧洞围岩变形历史数据,通过所述引水隧洞围岩变形历史数据获取完整特征数据集;
区间预测模块,配置为根据所述完整特征数据集,采用极限随机森林模型进行引水隧洞围岩变形区间预测。
具体而言,该预测系统包括数据获取模块和区间预测模块,其中,数据获取模块可以获取引水隧洞围岩变形历史数据,并基于引水隧洞围岩变形历史数据构建起相应的完整特征数据集。区间预测模块可以基于所述完整特征数据集构建起训练集和验证集,通过训练集对极限随机森林模型进行训练,并通过验证集对训练过程中的极限随机森林模型进行验证,最终得到最优的极限随机森林模型。通过最优的极限随机森林模型可以评估引水隧洞围岩变形影响因素与引水隧洞围岩变形间的非线性映射关系,从而实现引水隧洞围岩变形的区间预测。相较于传统的点预测方法,该方法集成多个子随机树的预测结果构建一个概率区间以获取相对稳定的评估区间预测结果,提高了引水隧洞围岩变形区间预测结果的可靠性。
在本实施例中,可选的,所述数据获取模块包括:
数据提取单元,配置为根据开挖以及运行过程中引水隧洞围岩变形的影响因素,从所述引水隧洞围岩变形历史数据提取出特征数据集;
数据填充单元,配置为通过所述特征数据集构建缺失数据填充模型,并通过所述缺失数据填充模型对所述特征数据集中的缺失数据进行填充,得到所述完整特征数据集。
具体而言,数据获取模块是由数据提取单元和数据填充单元组成。其中,数据提取单元可以根据开挖以及运行过程中引水隧洞围岩变形的影响因素,从所述引水隧洞围岩变形历史数据提取出特征数据集。数据填充单元可以通过特征数据集构建起缺失数据填充模型,并通过数据填充模型对特征数据集中的缺失数据进行估算,从而对特征数据集中的缺失数据进行补充,得到完整特征数据。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 大埋深隧洞挤压型围岩大变形预测方法
- 一种长距离隧洞膨胀性围岩变形超前预测预报方法