一种融合中文词性信息和相互学习的短文本分类方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及中文短文本分类领域,尤其涉及一种融合中文词性信息和相互学习的短文本分类方法。
背景技术
在互联网飞速发展的今天,如何快速的从网上海量的信息中获取所需要的信息,变得尤为重要。在浏览海量信息时,标题信息是判别该网页与用户需求相关度的重要依据。然而,标题分类作为短文本分类的一个重要分支,存在篇幅较短,信息量偏少等问题。因此,短文本分类模型仍需要进行更深入地研究与探索。
短文本分类是一个高度复杂的计算过程,因为计算机无法识别文字信息,因此需要将文字信息转化为向量模式才能进行计算。同时,因为短文本中信息少,利用相互学习的方式,使得单个模型能够获取其他更优模型的概率分布,以此来扩大模型的信息量。本发明选择使用BERT神经网络作为相互学习中的两个学生网络,BERT是Google在2018年提出的一种预训练语言模型。该模型基于Transformer模型的encoder部分,其不仅可以作为预训练模型,同时可以用于处理文本分类等自然语言处理任务。BERT在提出之后便成功地在11项NLP任务中取得优异的成绩,由此可以看出BERT在自然语言处理领域有着较高的性能,适合于工程应用。为弥补短文本信息量偏少的缺陷,本发明使用两个学生网络交互学习,其中一个网络仅使用常规的字向量信息,另一个网络融合使用字向量信息和词性信息,并集成KL和JS两种散度构造模型的损失评价函数。
发明内容
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种融合中文词性信息和相互学习的短文本分类方法,算法包含一个仅使用字向量信息的BERT和一个融合字向量信息和词性信息的BERT,引入TF控制两个BERT间的信息传递,并集成KL和JS两种散度构造模型的损失评价函数。
本发明解决其技术问题所采用的技术方案是:
本发明提供一种融合中文词性信息和相互学习的短文本分类方法,该方法包括以下步骤:
S1、确定BERT神经网络的参数,包括:Transformer block个数,字/词性向量维度和批次数;
S2、初始化超参数,包括:学生网络Θ
S3、比较学生网络Θ
S4、将输入的中文短文本转化为向量形式,并在句向量前后添加[CLS]和[SEP]标签对应的标签向量,得到学生网络Θ
S5、对输入向量添加位置信息;
S6、使用BERT神经网络进行计算,得到输出向量Output;
S7、对输出向量Output进行平均池化,将Output从高维度转化为1维行向量的形式,得到平均池化后的句向量P_Output;
S8、对P_Output进行线性变换,线性变换后得到LP向量;
S9、使用Tanh函数对线性变换得到的LP向量中的神经元进行激活,得到最终的句向量表示Sentence_vec;
S10、对最终得到的句向量进行线性变换,将句向量从k维向量转化为与标签类别个数相同维数的Logits向量;
S11、使用softmax函数进行归一化,得到长度为l的概率分布S,以此作为分类依据;
S12、采用KL散度作为硬损失指标衡量硬标签和预测值之间的匹配度,采用JS散度作为软损失指标衡量软标签和预测值之间的匹配度,并计算完整的损失函数,
S13、依照获得MAF1分数作为评价指标;
S14、使用MAF1分数的公式计算本轮次训练集train_score和测试集结果test_socre;
S15、使用AdamW优化器对Θ
S16、更新学生网络Θ
S17、比较学生网络Θ
S18、将输入的中文短文本将转化为向量形式,得到学生网络Θ
S19、将输入向量Input作为输入,重复步骤S4到S14的工作;并使用AdamW优化器对Θ
S20、更新学生网络Θ
S21、轮次t=t+1,若没到停止轮次,返回S3继续;若到停止轮次,则停止循环,输出分类结果。
进一步地,本发明的所述步骤S4的方法包括:
得到学生网络Θ
Input=Input_BERT
其中,s_len表示句子长度,w
进一步地,本发明的所述步骤S5的方法包括:
首先根据位置公式初始化位置信息:
其中,wp表示字向量所在的位置,k表示字向量的维度,n表示当前所在维度;将字向量所在的位置代入位置信息公式,得到位置变量为:
T_Input=Input+Positionals
其中,pos
进一步地,本发明的所述步骤S6的方法包括:
使用BERT神经网络进行计算,得到输出向量Output:
o
其中,s_len表示句子长度,o
所述步骤S7的方法包括:
平均池化后的句向量P_Output表示为:
P_Output=MeanPool(Output),
P_Output∈R
所述步骤S8的方法包括:
对P_Output进行线性变换,线性变换后得到的LP向量表示为:
LP=P_Output·W
LP∈R
其中,W
进一步地,本发明的所述步骤S9的方法包括:
Tanh函数计算方法如下:
Sentence_vec表示为:
Sentence_vec=[Tanh(x
Sentence_vec∈R
其中,x
所述步骤S10的方法包括:
将句向量从k维向量转化为与标签类别个数相同维数的Logits向量,Logits表示为:
Logits=Sentence_vec·W
Logits∈R
其中l表示标签类别个数,k表示字向量维度;
所述步骤S11的方法包括:
某一类别概率的softmax激活函数计算方法为:
则,经过模型运算得到的概率分布为:
S=[s
其中,S表示得到的概率分布,s
进一步地,本发明的所述步骤S12的方法包括:
采用KL散度作为硬损失指标衡量硬标签和预测值之间的匹配度,KL散度表示为
其中,P代表标签实际概率分布,Q为模型预测的概率分布;设HardL为标签实际概率分布,即hard label;S为经过模型计算得到概率分布,S
采用JS散度作为软损失指标衡量软标签和预测值之间的匹配度,JS散度表示为:
其中,P代表标签实际概率分布,Q为模型预测的概率分布;设
因此,完整的损失函数表示为:
其中,n代表对应的学生网络Θ
进一步地,本发明的所述步骤S13的方法包括:
MAF1分数的计算方法为:
其中,TP表示把正例预测为正例的样本,TN表示把负例预测为负例的样本,FN表示把正例预测为负例的样本,FP表示把负例预测为正例的样本。
进一步地,本发明的所述步骤S15的方法包括:
使用AdamW优化器对Θ
Θ
所述步骤S16的方法包括:
更新学生网络Θ
S
x
y
进一步地,本发明的所述步骤S18的方法包括:
将输入的中文短文本将转化为向量形式,得到学生网络Θ
Input=Input_word+Input_pos,
w
进一步地,本发明的所述步骤S19的方法包括:
将Input作为输入,重复步骤S4到S14的工作,并使用AdamW优化器对Θ
Θ
所述步骤S20的方法包括:
更新学生网络Θ
S
x
y
本发明产生的有益效果是:
本发明的方法包含一个使用字向量信息的BERT,保证了BERT模型的基础优势,增加了一个融合字向量信息和词性信息的BERT,引入TF控制两个BERT间的信息传递,增加了额外的信息,一定程度上弥补了短文本信息量偏少的不足,并集成KL和JS两种散度构造模型的损失评价函数,既考虑了JS散度的对称性特点,也考虑了KL散度的非对称性特点。本发明方法具有模型精度高、可拓展性强的特点,在短文本分类研究中将是一种切实可行的方法。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
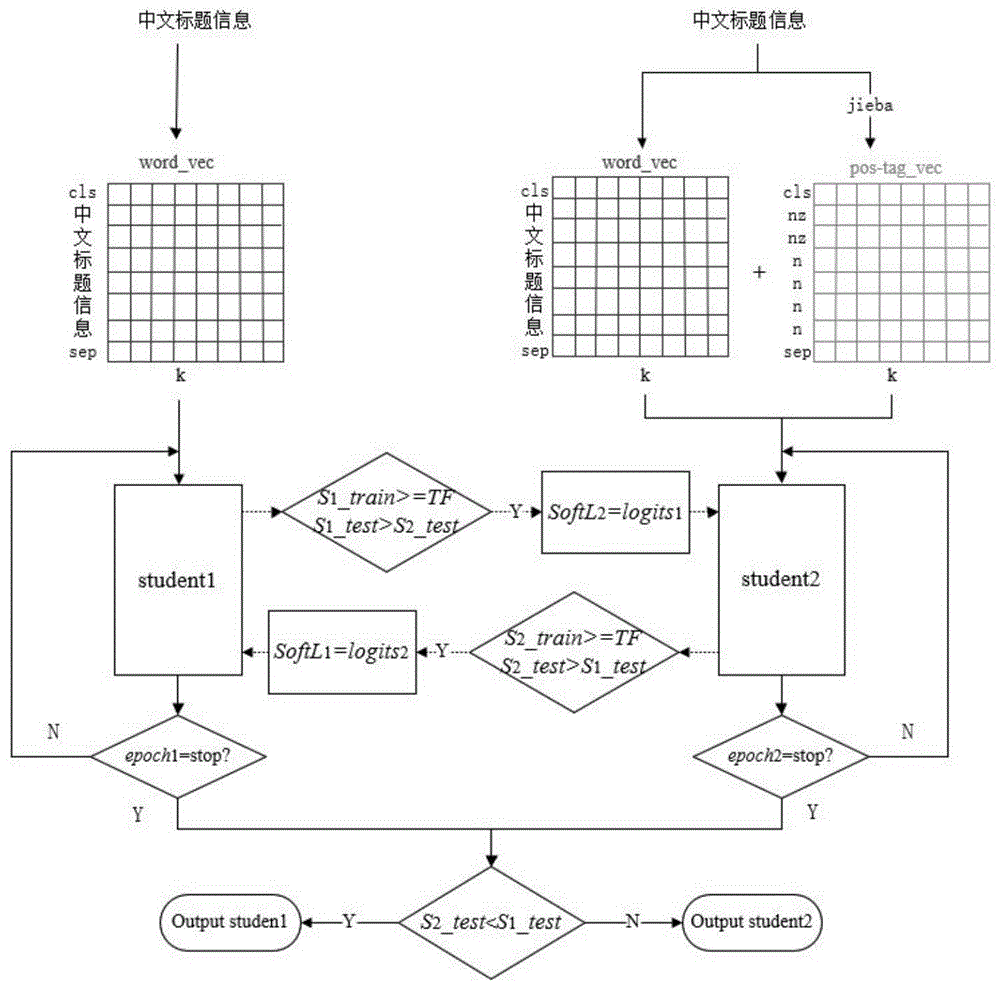
图1是本发明实施例的算法结构流程图。
图2是本发明实施例的算法在THUCNews数据集的各个类别上的分类性能对比。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
实施例1
本发明涉及一种融合中文词性信息和相互学习的短文本分类算法ML-BERT(Mutual Learning Bidirectional Encoder Representations from Transformers)。该算法由一个仅使用字向量信息的BERT和一个融合字向量信息和词性信息的BERT组成,引入TF控制两个BERT间的信息传递,并集成KL(Kullback-Leibler divergence)和JS(Jensen-Shannon)两种散度构造模型的损失评价函数,采用相互学习的方法进行交叉计算。
本发明实施例的融合中文词性信息和相互学习的短文本分类方法,在BERT模型中嵌入相互学习方法,并融合词性信息,挖掘出了等多的短文本信息量。
为验证本发明的有效性,使用公开的THUCNews数据集进行实验。
THUCNews是清华大学自然语言处理实验室(THUNLP)创建的一个用于文本分类的中文标题数据集。本实验从该数据集中筛选出10万条新闻数据,涵盖Finance、Property、Stocks、Education、Science、Society、Sports、Game和Entertainment共十个类别。每个类别随机选择1万条数据,并以8:2的比例划分训练集与测试集。进行如下操作:
步骤S1、确定BERT神经网络的Transformer block个数,字(词性)向量维度和批次数等。
步骤S2、根据表1中的参数初始化学生网络Θ
表1公开数据集测试参数设置
步骤S3、比较学生网络Θ
if x
步骤S4、将输入的中文短文本将转化为向量形式,并在句向量前后添加[CLS]和[SEP]标签对应的标签向量,得到学生网络Θ
Input=Input_BERT.
步骤S5、对输入向量添加位置信息。首先根据位置公式初始化位置信息
其中wp表示字向量所在的位置,k表示字向量的维度,n表示当前所在维度(奇数维度和偶数维度计算方法不同)。
根据位置信息公式,将字向量所在的位置代入位置信息公式,可得到位置变量为
T_Input=Input+Positionals.
其中pos
步骤S6、使用BERT神经网络进行计算,得到输出向量Output:
o
步骤S7、对Output进行平均池化,将Output_BERT从高维度转化为1维行向量的形式,得到平均池化后的句向量P_Output。P_Output可以表示为
P_Output=MeanPool(Output),
P_Output∈R
步骤S8、对P_Output进行线性变换,线性变换后得到的LP向量表示为
LP=P_Output·W
LP∈R
其中W
步骤S9、使用Tanh函数对线性变换得到的LP向量中的神经元进行激活,便可得到最终的句向量表示Sentence_vec,Tanh函数计算方法如下
根据上述公式Sentence_vec可以表示为
Sentence_vec=[Tanh(x
Sentence_vec∈R
其中,x
步骤S10、为获得最终模型预测的概率分布,需要对最终得到的句向量进行线性变换,将句向量从k维向量转化为与标签类别个数相同维数的Logits向量,Logits表示为
Logits=Sentence_vec·W
Logits∈R
其中l表示标签类别个数,k表示字向量维度。
步骤S11、在得到逻辑分布Logits后,通常选择使用softmax函数进行归一化,后便可得到长度为l的概率分布S,以此作为分类依据。某一类别概率的softmax激活函数计算方法为
则,经过模型运算得到的概率分布为
S=[s
其中S表示得到的概率分布,s
步骤S12、采用KL散度作为硬损失计算时衡量硬标签和预测值之间的匹配度的方法,KL散度表示为
其中P代表标签实际概率分布,Q为模型预测的概率分布。设HardL为标签实际概率分布,即hard label;S为经过的经过模型计算得到概率分布,S
采用JS散度作为软损失计算时衡量软标签和预测值之间的匹配度的方法,JS散度表示为
其中P代表标签实际概率分布,Q为模型预测的概率分布。设
因此,完整的损失函数可以表示为
Loss
其中n代表对应的学生模型为student1或student2。两个学生网络为同一数据集,因此同一数据的HardL一致。通过上述方法每个模型既可以通过KL散度使用预测值与真实标签来计算监督损失,又可以通过JS散度使用预测值与软标签来计算等量的概率估计。
步骤S13、依照获得MAF1分数作为评价指标,MAF1分数的计算方法为
其中TP表示把正例预测为正例的样本,TN表示把负例预测为负例的样本,FN表示把正例预测为负例的样本,FP表示把负例预测为正例的样本。
步骤S14、根据MAF1的计算方法计算本轮次训练集train_score和测试集结果test_socre。
步骤S15、使用AdamW优化器对Θ
Θ
步骤S16、更新学生网络Θ
S
x
y
步骤S17、比较学生网络Θ
if x
步骤S18、将输入的中文短文本将转化为向量形式,得到学生网络Θ
Input=Input_word+Input_pos,
w
步骤S19、将Input作为输入,重复步骤S4到S14的工作。并使用AdamW优化器对Θ
Θ
步骤S20、更新学生网络Θ
S
x
y
步骤S21、轮次t=t+1,如若没到停止伦次,返回S3继续。
实施例2
经过所有轮次的训练后,选用Text-CNN、Text-RNN和BERT模型进行对比结果对比,对比结果如表2所示。从表2可以看出,本发明取得了最优的分类性能。
表2各模型文本分类结果
表2中的实验结果表明,本文所构建的ML-BERT模型在THUCNews数据集上的分类实验中都取得了最优异的结果,其MAA,MAP,MAR,MAF1分别为93.80%、93.79%、93.80%和93.79%。
为更直观的为更直观的对比模型在每一类上的分类效果,本文使用折线图的方法进行展示,如图2所示。从图2中可以看出,本发明在除了Stocks类别外的其他类别上的F1source均处在最高的位置。
应当理解的是,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 一种融合上下文信息图卷积的中文短文本分类方法
- 一种基于提示学习的中文短文本分类方法