一种数据报文处理方法、装置、存储介质及电子装置
文献发布时间:2024-04-18 19:58:53
技术领域
本申请实施例涉及通信领域,具体而言,涉及一种数据报文处理方法、装置、存储介质及电子装置。
背景技术
网络技术日新月异,对通讯设备的带宽需求也急剧增加,40G、100G等超高速以太网投入使用,网络带宽需求急剧提升,通讯设备,尤其是各种负责包转
发的网络节点,如媒体包转发、防火墙等,也面临挑战;硬件方面,多核处理器不断推陈出新,集成度越来越高,X86架构下IO通道、内存速率、CPU处理能力都获得了长足的进展,不是主要瓶颈;但要通过通用处理器的软件转发挑战超高速以太网的高吞吐量,仍然面临很多困难;以前底层收发包,走的内核协议栈,在数据包的收发过程中,需多次进行内存拷贝,后来采用数据平面开发套件(Data Plane Development Kit,简称为DPDK)底层收发包,绕过内核协议栈,减少了内存拷贝,性能有大幅度提升,但应用层业务转发过程采用的run to completion(运行至完成)模型,使用的是标量数据包处理方式,是一次处理一个数据包从rx到tx整个报文的生命周期,再取下一个报文进行处理,这样处理会带来每个数据包都会导致缓存未命中和指令切换的开销,使得转发性能慢,达不到高吞吐量的要求。
针对相关技术中数据报文转发时使用标量数据包的处理方式,转发开销大且转发性能慢的问题,尚未提出解决方案。
发明内容
本申请实施例提供了一种数据报文处理方法、装置、存储介质及电子装置,以至少解决相关技术中数据报文转发时使用标量数据包的处理方式,转发开销大且转发性能慢的问题。
根据本申请的一个实施例,提供了一种数据报文处理方法,所述方法包括:
从网卡的入包队列中读取多个数据报文;
在用户空间将所述多个数据报文进行分流,得到多组数据报文,并对所述多组数据报文进行并行处理,得到处理后的多组数据报文;
将所述处理后的多组数据报文存储到所述网卡的出包队列中;
基于所述出包队列发送所述处理后的多组数据报文。
在一实施例中,在用户空间将所述多个数据报文进行分流,得到多组数据报文,并对所述多组数据报文进行并行处理包括:
基于报文处理图中的图节点,通过所述用户空间的IO线程将所述多个数据报文进行分流,得到多组数据报文;
通过所述IO线程与多个WORK线程对所述多组数据报文进行并行处理。
在一实施例中,基于所述报文处理图中的图节点,通过所述用户空间的IO线程将所述多个数据报文进行分流,得到所述多组数据报文包括:
基于报文处理图中的图节点,通过所述IO线程从所述入包队列轮询并读取所述多个数据报文,将所述多个数据报文进行分流,得到所述多组数据报文。
在一实施例中,通过所述IO线程与所述多个WORK线程对所述多组数据报文进行并行处理包括:
通过所述IO线程将所述多组数据报文存储到所述多个WORK线程对应的ringR队列中,其中,一个WORK线程处理一组数据报文,一个WORK线程对应一个ringR队列;
分别通过所述多个WORK线程从对应的所述ringR队列中读取所述多组数据报文,经过业务处理与转发之后存储到所述多个WORK线程对应的ringS队列中,一个WORK线程对应一个ringS队列。
在一实施例中,通过所述IO线程将所述多组数据报文存储到所述多个WORK线程对应的ringR队列中包括:
通过所述IO线程获取所述ringS队列中积压数据报文的数量;
在所述数量大于或等于预设阈值的情况下,将每组数据报文中小于低优先级阈值的数据报文丢弃,将所述每组数据报文中大于或等于低优先级阈值的数据报文存储到所述ringS队列中。
在一实施例中,分别通过所述多个WORK线程从对应的所述ringR队列中读取所述多组数据报文,经过业务处理与转发之后存储到所述多个WORK线程对应的ringS队列中包括:
分别通过所述WORK线程从所述ringR中读取每组数据报文,解析所述每组数据报文,剥掉所述每组数据报文的以太头,通过查路由的方式从所述报文处理图中获取下一跳图节点;
通过所述下一跳图节点获取出接口,将所述出接口封装为所述每组数据报文的以太头,得到处理后的每组数据报文,并将所述处理后的每组数据报文通过所述出接口对应的图节点存储到所述ringS队列中。
在一实施例中,通过所述用户空间的IO线程将所述多个数据报文进行分流,得到得到多组数据报文包括:
按照报文特征,通过所述IO线程将所述多个数据报文进行分流,得到所述多组数据报文,其中,所述多个数据报文中的多个分片报文的报文特征相同。
在一实施例中,所述方法还包括:
将报文转发过程划分成为不同的多个转发处理动作;
将所述多个转发处理动作分解为先后连接的多个图节点,形成所述报文处理图,其中,一个图节点完成一个转发处理动作,每个图节点按照节点先后顺序处理所述每组数据报文。
在一实施例中,所述方法还包括:
在所述报文转发过程中,检测到绑定新的网卡,在所述报文处理图中插入出接口对应的新的图节点,得到更新的所述报文处理图。
根据本申请的另一个实施例,还提供了一种数据报文处理装置,所述装置包括:
读取模块,用于从网卡的入包队列中读取多个数据报文;
分流模块,用于在用户空间将所述多个数据报文进行分流,得到多组数据报文,并对所述多组数据报文进行并行处理,得到处理后的多组数据报文;
存储模块,用于将所述处理后的多组数据报文存储到所述网卡的出包队列中;
发送模块,用于基于所述出包队列发送所述处理后的多组数据报文。
在一实施例中,所述分流模块包括:
分流子模块,用于基于报文处理图中的图节点,通过所述用户空间的IO线程将所述多个数据报文进行分流,得到多组数据报文;
处理子模块,用于通过所述IO线程与多个WORK线程对所述多组数据报文进行并行处理。
在一实施例中,所述分流子模块,还用于基于报文处理图中的图节点,通过所述IO线程从所述入包队列轮询并读取所述多个数据报文,将所述多个数据报文进行分流,得到所述多组数据报文。
在一实施例中,所述处理子模块包括:
存储单元,用于通过所述IO线程将所述多组数据报文存储到所述多个WORK线程对应的ringR队列中,其中,一个WORK线程处理一组数据报文,一个WORK线程对应一个ringR队列;
读取单元,用于分别通过所述多个WORK线程从对应的所述ringR队列中读取所述多组数据报文,经过业务处理与转发之后存储到所述多个WORK线程对应的ringS队列中,一个WORK线程对应一个ringS队列。
在一实施例中,所述存储单元,还用于
通过所述IO线程获取所述ringS队列中积压数据报文的数量;
在所述数量大于或等于预设阈值的情况下,将每组数据报文中小于低优先级阈值的数据报文丢弃,将所述每组数据报文中大于或等于低优先级阈值的数据报文存储到所述ringS队列中。
在一实施例中,所述读取单元,还用于
分别通过所述WORK线程从所述ringR中读取每组数据报文,解析所述每组数据报文,剥掉所述每组数据报文的以太头,通过查路由的方式从所述报文处理图中获取下一跳图节点;
通过所述下一跳图节点获取出接口,将所述出接口封装为所述每组数据报文的以太头,得到处理后的每组数据报文,并将所述处理后的每组数据报文通过所述出接口对应的图节点存储到所述ringS队列中。
在一实施例中,所述分流模块,还用于按照报文特征,通过所述IO线程将所述多个数据报文进行分流,得到所述多组数据报文,其中,所述多个数据报文中的多个分片报文的报文特征相同。
在一实施例中,所述装置还包括:
划分模块,用于将报文转发过程划分成为不同的多个转发处理动作;
分解模块,用于将所述多个转发处理动作分解为先后连接的多个图节点,形成所述报文处理图,其中,一个图节点完成一个转发处理动作,每个图节点按照节点先后顺序处理所述每组数据报文。
在一实施例中,所述装置还包括:
更新模块,用于在所述报文转发过程中,检测到绑定新的网卡,在所述报文处理图中插入出接口对应的新的图节点,得到更新的所述报文处理图。
根据本申请的又一个实施例,还提供了一种计算机可读的存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
根据本申请的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
本申请实施例,从网卡的入包队列中读取多个数据报文;在用户空间将所述多个数据报文进行分流,得到多组数据报文,并对所述多组数据报文进行并行处理,得到处理后的多组数据报文;将所述处理后的多组数据报文存储到所述网卡的出包队列中;基于所述出包队列发送所述处理后的多组数据报文,可以解决相关技术中数据报文转发时使用标量数据包的处理方式,转发开销大且转发性能慢的问题,从网卡的入包队列中读取多个数据报文,采用矢量数据报文进行转发,减少读取延迟和cache miss,提升大流量转发性能。
附图说明
图1是本申请实施例的数据报文处理方法的移动终端的硬件结构框图;
图2是根据本申请实施例的数据报文处理方法的流程图;
图3是根据本申可选请实施例的数据报文处理方法的流程图;
图4是根据本实施例的硬件运行实现层级的示意图;
图5是根据本实施例的矢量报文处理的流程图;
图6是根据本实施例的绑定新网卡时node插入的示意图;
图7是根据本申请实施例的数据报文处理装置的框图。
具体实施方式
下文中将参考附图并结合实施例来详细说明本申请的实施例。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
本申请实施例中所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。以运行在移动终端上为例,图1是本申请实施例的数据报文处理方法的移动终端的硬件结构框图,如图1所示,移动终端可以包括一个或多个(图1中仅示出一个)处理器102(处理器102可以包括但不限于微处理器MCU或可编程逻辑器件FPGA等的处理装置)和用于存储数据的存储器104,其中,上述移动终端还可以包括用于通信功能的传输设备106以及输入输出设备108。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述移动终端的结构造成限定。例如,移动终端还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
存储器104可用于存储计算机程序,例如,应用软件的软件程序以及模块,如本申请实施例中的数据报文处理方法对应的计算机程序,处理器102通过运行存储在存储器104内的计算机程序,从而执行各种功能应用以及业务链地址池切片处理,即实现上述的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至移动终端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
传输装置106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括移动终端的通信供应商提供的无线网络。在一个实例中,传输装置106包括一个网络适配器(Network Interface Controller,简称为NIC),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置106可以为射频(Radio Frequency,简称为RF)模块,其用于通过无线方式与互联网进行通讯。
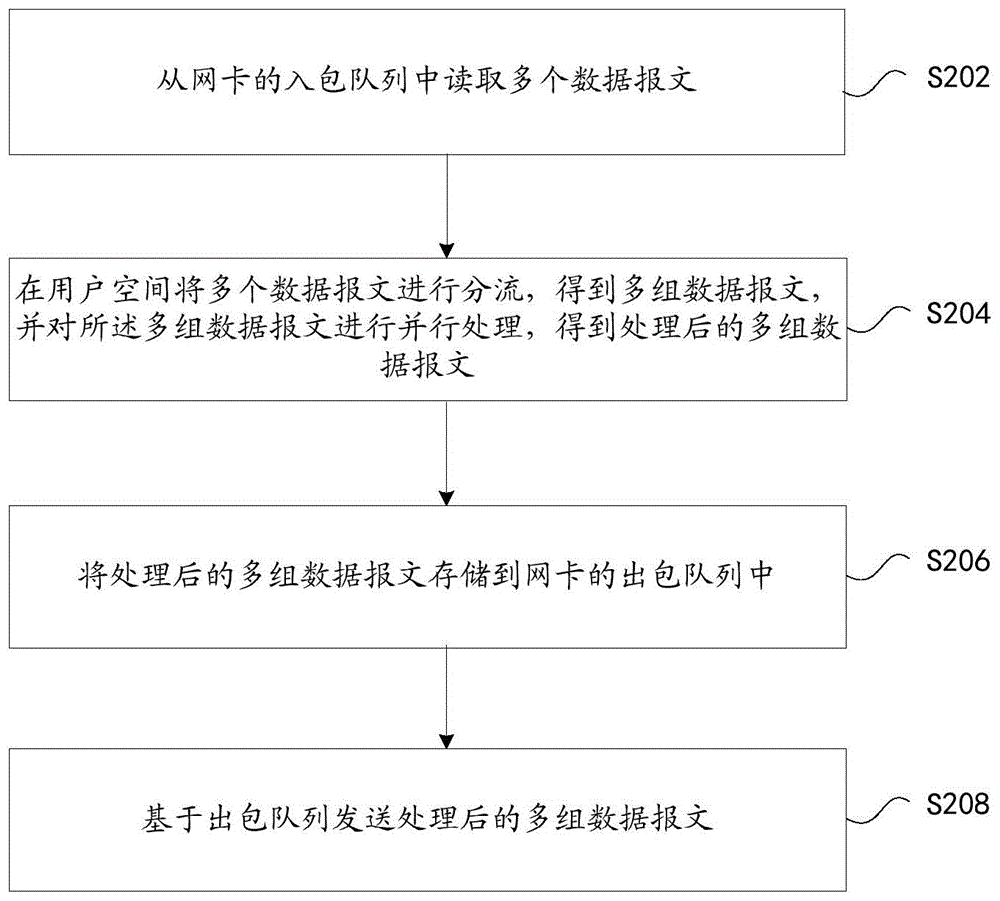
在本实施例中提供了一种运行于上述移动终端或网络架构的数据报文处理方法,图2是根据本申请实施例的数据报文处理方法的流程图,如图2所示,该流程包括如下步骤:
步骤S202,从网卡的入包队列中读取多个数据报文;
步骤S204,在用户空间将多个数据报文进行分流,得到多组数据报文,并对所述多组数据报文进行并行处理,得到处理后的多组数据报文;
上述步骤S204中,可以通过以下方式进行分流:按照报文特征,通过所述IO线程将所述多个数据报文进行分流,得到多组数据报文,多个数据报文中的多个分片报文的报文特征相同,使得多个分片报文分配到一组数据报文中。
步骤S206,将处理后的多组数据报文存储到网卡的出包队列中;
步骤S208,基于出包队列发送处理后的多组数据报文。
通过上述步骤S202至S208,可以解决相关技术中数据报文转发时使用标量数据包的处理方式,转发开销大且转发性能慢的问题,从网卡的入包队列中读取多个数据报文,采用矢量数据报文进行转发,减少读取延迟和cache miss,提升大流量转发性能。
图3是根据本申可选请实施例的数据报文处理方法的流程图,如图3所示,上述步骤S204具体可以包括:
S302,基于报文处理图中的图节点,通过用户空间的IO线程将多个数据报文进行分流,得到多组数据报文;
上述步骤S302具体是基于报文处理图中的图节点,通过所述IO线程从入包队列轮询并读取多个数据报文,将多个数据报文进行分流,得到多组数据报文。
本实施例中的报文处理图,可以给予报文转发过程中的动作来设置,具体的,将报文转发过程划分成为不同的多个转发处理动作;将多个转发处理动作分解为先后连接的多个图节点,形成报文处理图,其中,一个图节点完成一个转发处理动作,每个图节点按照节点先后顺序处理每组数据报文。
进一步的,还可以更新报文处理图,具体的,在所述报文转发过程中,若检测到绑定新的网卡,在所述报文处理图中插入出接口对应的新的图节点,得到更新的所述报文处理图。
S304,通过IO线程与多个WORK线程对多组数据报文进行并行处理。
本实施例中,上述步骤S304具体可以包括:
S3041,通过所述IO线程将所述多组数据报文存储到所述多个WORK线程对应的ringR队列(无锁队列)中,其中,一个WORK线程处理一组数据报文,一个WORK线程对应一个ringR队列;
进一步的,通过所述IO线程获取所述ringS队列中积压数据报文的数量;,在所述数量大于或等于预设阈值的情况下,将每组数据报文中小于低优先级阈值的数据报文丢弃,将所述每组数据报文中大于或等于低优先级阈值的数据报文存储到所述ringS队列中。
S3042,分别通过所述多个WORK线程从对应的所述ringR队列中读取所述多组数据报文,经过业务处理与转发之后存储到所述多个WORK线程对应的ringS队列中,一个WORK线程对应一个ringS队列。
进一步的,分别通过所述WORK线程从所述ringR中读取每组数据报文,解析所述每组数据报文,剥掉所述每组数据报文的以太头,通过查路由的方式从所述报文处理图中获取下一跳图节点;通过所述下一跳图节点获取出接口,将所述出接口封装为所述每组数据报文的以太头,得到处理后的每组数据报文,并将所述处理后的每组数据报文通过所述出接口对应的图节点存储到所述ringS队列中。
本实施例在报文转发过程中采用矢量转发,将整个转发过程分成不同具体转发动作,找出转发动作的分叉点,根据分叉点设计node处理,相同处理动作的报文作为一帧,每帧可最多批量处理256个数据包,每个node处理批量数据包时提前进行包的预取,减少读取延迟和cache miss,提升大流量转发性能;并且支持运行过程中插入新node节点,支持分片报文不乱序重组和高低优先级报文转发。
基于X86架构体系,部署在虚拟机中,运用于单个虚拟路由器节点,基于Linux的宿主机创建KVM虚拟机并将宿主机物理网卡以通过直通、SR-IOV(Single Root I/OVirtualization)方式将pci透传到虚拟机,能够从网卡注入流量。
使用数据平面开发套件(Data Plane Development Kit,简称为DPDK)进行底层收发包,DPDK是一个用来进行包数据处理加速的软件库。具有以下优点:通过UIO技术将报文拷贝到应用空间处理,规避不必要的内存拷贝和系统调用;通过大页内存HUGEPAGE,降低cache miss(访存开销);通过无锁队列,减少资源竞争;
矢量报文处理(Vector Packet Processing简称为VPP),一款可拓展的开源框架,提供容易使用的、高质量的交换、路由功能,VPP构建基于“包处理图”,意味着可以“插入”新的结点,变得容易拓展,可以自定义一些特定的功能。
本实施例需要运用的硬件包括X86多核服务器,网卡,光模块等硬件设备,需要KVM虚拟机镜像,libvirt,DPDK,VPP等软件,图4是根据本实施例的硬件运行实现层级的示意图,如图4所示,node1是X86服务器计算节点,部署KVM虚拟机,虚拟机内再部署主控处理单元(Main Control Processing Unit,简称为MP)单板,eth0连接到TIPC网络,组成一个虚拟转发路由器设备;每块单板内部部署控制面进程和转发面进程,转发面进程内包括主job线程、检测线程、转发线程、轮询分发线程等;主job线程负责初始化网卡,将网卡从linux驱动解绑到用户空间的I/O技术(Userspace I/O,简称为UIO),使DPDK接管网卡;work转发线程主要负责业务报文的路由转发;io轮询分发线程主要是轮询网卡队列收包,分发报文到work线程,并将wrok线程处理的报文转发到网卡队列。
报文转发过程采用矢量转发。首先,将转发过程中多个转发处理动作分解为一个个先后连接的服务node节点,每个node节点都是完成一个转发动作,中间node节点都有一个或多个前驱node和后继node,像链表一样从头node节点到尾node节点,整个串成一条或多条转发路径;其次,向量包处理采用了“分类”,将同一个node处理的一批报文作为一类,称为帧,这一组报文帧被第一个node节点的任务处理,然后依次被第二个node节点的任务处理,依次类推,每个node处理过程中如果cache命中,则这一批报文都命中,否则,一批都未命中,未命中时,由传统的n个包未命中n次变为n个包未命中1次,每帧可最多批量处理256个的数据包,批处理数据包时进行包的预取,减少读取延迟和cache miss,可以减少开销,提高转发性能;最后,根据当前node处理结果,转发到后继的不同node中处理,转到相同后继node的一批报文又构成一类帧报文进行处理。
网卡收包会有速率大小,会有到大量包和不满256个包的情况。io轮询分发线程会循环轮询网卡队列,如果每次轮询,网卡队列一直有包,那么就读满256个包才进行压栈入node处理;如果有一次轮询没有收到包,不管是否达到256个包,都进行压栈入node处理。
开放式虚拟转发(Open Virtual Forwarding,简称为OVF)转发整个过程都在io轮询分发线程和work线程中完成,如果将整个过程划分的node个数过多,则会增加报文帧压栈出栈的次数,如果过少则每个node处理的动作过多,又起不到预取和批处理的目的,以最简单的ipv4报文转发为例来讲述如何比较好的划分node,这里划分的主要原则是报文某个处理动作后有分叉点的时候就需要考虑拆成node。首先,需要梳理出在处理ipv4转发整个过程的动作,找出分叉点,大致梳理出的动作有io轮询线程从网卡读包,根据报文特征计算分流目的work收包ring id进行分流(分叉点:不同ring id),当work收包ring队列中积压个数达到阈值,需要丢弃低优先级报文,高优先级报文继续入ring(分叉点:高低优先级报文);work处理动作主要有从work收包ring中读包,解析报文,剥掉以太头,查路由获取下一跳(分叉点:本地路由与非本地路由),根据下一跳,查arp表获取出接口并且封装以太头(分叉点:出接口不同),将报文放入对应出接口的work发包ring;io轮询线程再将报文读取出放入网卡发包队列。
图5是根据本实施例的矢量报文处理的流程图,如图5所示,每个圆代表node节点,流程步骤包括:
步骤1,轮询网卡收包队列,从网卡队列批量读出包,每次从网卡队列最多读32个;
步骤2,循环读取报文,最多读256个,压入port-rss node;
步骤3,在port-rss node中根据报文特征进行分流,压入不同io2ring node;
步骤4,ringR积压包个数超出高低优先级阈值时,高优先级进入io2qos node处理,低优先级报文丢弃;
步骤5,io线程enqueue ringR队列进行入包;
步骤6,work线程dequeueringR队列进行出包;
步骤7,根据报文类型进入下一个node处理,ipv4包进入ipv4-fwd查路由处理;
步骤8,查的路由是本地路由,进入上送lpp-upsend node;
步骤9,将批量路由非本地包,查出接口,根据出接口选择不同下游node;
步骤10,同一出接口的批量包进入对应出接口nic-tx node;
步骤11,work线程enqueue ringS队列进行入包;
步骤12,io线程dequeue ringS队列进行出包;
步骤13,io线程轮询网卡发包队列,将包放入发包队列,由网卡DMA将报文发送出去。
本实施例支持运行过程中插入新node。图6是根据本实施例的绑定新网卡时node插入的示意图,如图6所示,在转发过程当前,创建新的接口,绑定新网卡,则会在原有node基础上插入新的接口node,图中nic-tx-2node是新插入的node,查的路由出接口为2口的报文则会转到该node中进行处理。
本实施例支持一条流的多分片报文保证走同一条转发路径。在图5步骤(3)中,特征不同的报文可能会流入不同的work处理,此时报文需要进行分流,但对于一条流的ipv4多个分片报文,则要求保证流入相同work才能进行重组,所以在port-rss node中计算分流索引值时将一条流的多片包设置成一样。
本实施例支持性能达到转发瓶颈时,丢弃低优先级报文保证高优先级报文优先转发。通过设置图5的io2qos node,在ringS积压报文达到一定阈值(设置为ring深的2/3),将低优先级报文进入drop node进行丢弃,保证高优先级报文继续能入队列,对于有大量背景流量时的关键协议报文不断链的场景非常适用。
根据本申请的另一个实施例,还提供了一种数据报文处理装置,图7是根据本申请实施例的数据报文处理装置的框图,如图7所示,所述装置包括:
读取模块72,用于从网卡的入包队列中读取多个数据报文;
分流模块74,用于在用户空间将所述多个数据报文进行分流,得到多组数据报文,并对所述多组数据报文进行并行处理,得到处理后的多组数据报文;
存储模块76,用于将所述处理后的多组数据报文存储到所述网卡的出包队列中;
发送模块78,用于基于所述出包队列发送所述处理后的多组数据报文。
在一实施例中,分流模块74包括:
分流子模块,用于基于报文处理图中的图节点,通过所述用户空间的IO线程将所述多个数据报文进行分流,得到多组数据报文;
处理子模块,用于通过所述IO线程与多个WORK线程对所述多组数据报文进行并行处理。
在一实施例中,所述分流子模块,还用于基于报文处理图中的图节点,通过所述IO线程从所述入包队列轮询并读取所述多个数据报文,将所述多个数据报文进行分流,得到所述多组数据报文。
在一实施例中,所述处理子模块包括:
存储单元,用于通过所述IO线程将所述多组数据报文存储到所述多个WORK线程对应的ringR队列中,其中,一个WORK线程处理一组数据报文,一个WORK线程对应一个ringR队列;
读取单元,用于分别通过所述多个WORK线程从对应的所述ringR队列中读取所述多组数据报文,经过业务处理与转发之后存储到所述多个WORK线程对应的ringS队列中,一个WORK线程对应一个ringS队列。
在一实施例中,所述存储单元,还用于
通过所述IO线程获取所述ringS队列中积压数据报文的数量;
在所述数量大于或等于预设阈值的情况下,将每组数据报文中小于低优先级阈值的数据报文丢弃,将所述每组数据报文中大于或等于低优先级阈值的数据报文存储到所述ringS队列中。
在一实施例中,所述读取单元,还用于
分别通过所述WORK线程从所述ringR中读取每组数据报文,解析所述每组数据报文,剥掉所述每组数据报文的以太头,通过查路由的方式从所述报文处理图中获取下一跳图节点;
通过所述下一跳图节点获取出接口,将所述出接口封装为所述每组数据报文的以太头,得到处理后的每组数据报文,并将所述处理后的每组数据报文通过所述出接口对应的图节点存储到所述ringS队列中。
在一实施例中,分流模块74,还用于按照报文特征,通过所述IO线程将所述多个数据报文进行分流,得到所述多组数据报文,其中,所述多个数据报文中的多个分片报文的报文特征相同。
在一实施例中,所述装置还包括:
划分模块,用于将报文转发过程划分成为不同的多个转发处理动作;
分解模块,用于将所述多个转发处理动作分解为先后连接的多个图节点,形成所述报文处理图,其中,一个图节点完成一个转发处理动作,每个图节点按照节点先后顺序处理所述每组数据报文。
在一实施例中,所述装置还包括:
更新模块,用于在所述报文转发过程中,检测到绑定新的网卡,在所述报文处理图中插入出接口对应的新的图节点,得到更新的所述报文处理图。
本申请的实施例还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
在一个示例性实施例中,上述计算机可读存储介质可以包括但不限于:U盘、只读存储器(Read-Only Memory,简称为ROM)、随机存取存储器(Random Access Memory,简称为RAM)、移动硬盘、磁碟或者光盘等各种可以存储计算机程序的介质。
本申请的实施例还提供了一种电子装置,包括存储器和处理器,该存储器中存储有计算机程序,该处理器被设置为运行计算机程序以执行上述任一项方法实施例中的步骤。
在一个示例性实施例中,上述电子装置还可以包括传输设备以及输入输出设备,其中,该传输设备和上述处理器连接,该输入输出设备和上述处理器连接。
本实施例中的具体示例可以参考上述实施例及示例性实施方式中所描述的示例,本实施例在此不再赘述。
显然,本领域的技术人员应该明白,上述的本申请的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本申请不限制于任何特定的硬件和软件结合。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 一种方控数据处理方法、装置、电子设备及存储介质
- 一种材质的数据处理方法、装置、电子设备及存储介质
- 一种数据处理方法、装置、电子设备及存储介质
- 音频数据的处理方法及装置、存储介质、电子装置
- 数据处理方法、装置、存储介质和电子装置
- 数据报文的处理方法及装置、存储介质、电子装置
- 一种数据报文的处理方法、装置、电子设备及存储介质