基于大数据分析的锅炉的自动排程方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明属于锅炉安全性检测领域,更具体的,涉及一种基于大数据分析的锅炉的自动排程方法。
背景技术
锅炉,作为工业和商业领域的关键设备,长久以来一直是能源转换和供应系统的核心。它们将化石燃料或其他能源形式转化为蒸汽或热水,为各种工业过程、供暖和动力生成提供能源。随着工业化的进程和技术的发展,锅炉的设计和操作已经取得了很大的进步,特别是在效率、可靠性和环境友好性方面。然而,随着现代工业过程对能源需求的变化,锅炉经常面临负荷突变的挑战。负荷突变是指锅炉在短时间内需要处理的蒸汽或热水需求的急剧变化。这可能是由于生产线的突然启动或停机、设备故障、外部电网的波动或其他突发事件引起的。
在现有技术中,可以采用智能算法,例如粒子群算法可以实现对锅炉的自动排程,然而,当负荷突变的情形下,不难理解的是,算法本身输出的最优解,哪怕是局部最优解,本质上都是凸点,也就是说,最优解本身不够平滑就会导致对锅炉的排程更加极端,进而导致锅炉中的一些部件,例如蛇形管或翅冷壁在刹那间的压力剧增,从而影响其寿命。在效率最大化的前提下,如何确保锅炉的稳定和安全运行,以及如何延长锅炉部件的使用寿命,是一个亟待解决的问题。
发明内容
为解决现有技术中存在的不足,本发明的目的在于解决上述缺陷,进而提出一种基于大数据分析的锅炉的自动排程方法。
本发明采用如下的技术方案。
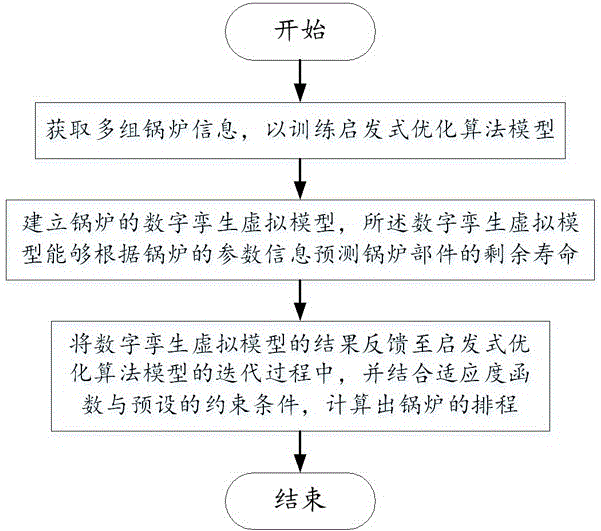
本发明第一方面公开了一种基于大数据分析的锅炉的自动排程方法,包括步骤1~步骤3;
步骤1,获取多组锅炉信息,以训练启发式优化算法模型;
步骤2,建立锅炉的数字孪生虚拟模型,所述数字孪生虚拟模型能够根据锅炉的参数信息预测锅炉部件的剩余寿命;
步骤3,将数字孪生虚拟模型的结果反馈至启发式优化算法模型的迭代过程中,并结合适应度函数与预设的约束条件,计算出锅炉的排程。
进一步的,锅炉信息包括参数信息与状态信息,参数信息包括锅炉的输出热功率、给水流量、锅炉温度、空气流量、锅炉蒸汽压力;状态信息包括蒸汽的质量流量,蒸汽的出口焓值与入口焓值,燃料的质量流量,燃料的热值。
进一步的,适应度函数
;
其中,
进一步的,步骤2具体包括步骤2.1~步骤2.4;
步骤2.1,构建锅炉的几何模型与物理模型;
步骤2.2,基于锅炉的几何模型与物理模型,构建锅炉的仿真模型;
步骤2.3,基于锅炉的几何模型、物理模型与仿真模型,构建锅炉的数字孪生虚拟模型;
步骤2.4,基于数字孪生虚拟模型,预测锅炉部件的剩余寿命。
进一步的,启发式优化算法模型为粒子群算法,粒子的位置表示锅炉的参数信息;适应度函数为锅炉的效率最大化;粒子的速度表示参数信息的变化率;个体最佳位置和全局最佳位置均表示了在迭代过程中找到的最佳锅炉操作参数。
进一步的,步骤3中,迭代过程具体包括步骤3.1~步骤3.3;
步骤3.1,在每一次迭代过程中,基于数字孪生虚拟模型,计算出粒子的位置对应的风险值;
步骤3.2,依次计算出前后2次迭代中所有粒子的风险值的耦合关联度;
步骤3.3,判断耦合关联度是否大于预设的关联度阈值;若大于,迭代结束。
进一步的,粒子
;
其中,
进一步的,耦合关联度
;
;
;
其中,
本发明第二方面公开了一种终端,包括处理器及存储介质;其特征在于:
所述存储介质用于存储指令;
所述处理器用于根据所述指令进行操作以执行第一方面所述方法的步骤。
本发明第三方面公开了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现第一方面所述方法的步骤。
本发明的有益效果在于,与现有技术相比,本发明具有以下优点:
本发明考虑到锅炉效率最大化时,其最优解不平滑的特性容易疲劳甚至损坏锅炉中的一些部件,本发明创造性的通过数字孪生虚拟模型去评估粒子群算法中每一次迭代的结果,进而控制粒子群算法的收敛速度与权重因子。
附图说明
图1是一种基于大数据分析的锅炉的自动排程方法的流程图。
具体实施方式
下面结合附图对本申请作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本申请的保护范围。
锅炉主要由如下结构组成:燃烧室、燃料供应系统、空气供应系统、烟气排放系统、热交换器、控制系统与安全装置。燃烧室,也叫炉膛,是锅炉的核心部分,其可以根据不同的功能类型而设计成一个特定的形状,用于燃烧燃料并释放热量。燃料供应系统用于将燃料,例如煤、油或天然气,输送到炉膛内进行燃烧。空气供应系统用于为燃烧提供必要的空气,通常包括风机、风道和调节阀。烟气排放系统用于将燃烧后产生的废气从锅炉中排放出去,通常包括烟囱、烟道和其他排放装置。热交换器用于从燃烧产生的热量中提取热能,将其传递给水或其他介质,产生蒸汽或热水。控制系统用于监控和调节锅炉的运行。控制系统可以实时调整燃料和空气的流量、压力和比例,以保持最佳的燃烧状态。安全装置,例如可以是压力释放阀、散热装置等,用于确保锅炉的安全运行。
在工业生产的绝大多数情形下,一个锅炉还需要同时供应多条不同的生产线,因此,锅炉中还包括蒸汽分配系统,用于将热交换器产生的蒸汽分配到各个生产线。可理解的,蒸汽分配系统可以包括:蒸汽主管、分支管、调节阀和隔离阀等。在工业生产中,常会出现如下情形,例如:某条生产线突然增加生产需求,此时需要锅炉迅速的调整排程,加大燃烧功率以满足所有生产线的蒸汽需求;多个锅炉之间协调合作,其中一个锅炉发生临时故障,此时其他锅炉也需要迅速调整排程;外部环境的影响,例如极端温度会导致锅炉的冷却系统受到影响,导致运行效率受到影响。
由于锅炉的参数信息对锅炉部件(例如翅冷壁和蛇形管)的影响是非线性的。事实上,对锅炉部件的寿命的预测方法,基本通过仿真技术,例如数字孪生技术,结合锅炉的参数信息,从而预测锅炉部件的寿命。因此,无法通过建立新的约束条件,例如:限定锅炉的参数信息的范围,以实现安全稳定的运行。
基于此,本发明公开了一种基于大数据分析的锅炉的自动排程方法,如图1所示,包括步骤1~步骤3。
步骤1,获取多组锅炉信息,以训练启发式优化算法模型。
可理解的,一组锅炉信息包括参数信息与状态信息,参数信息可以包括锅炉的输出热功率、给水流量、锅炉温度、空气流量、锅炉蒸汽压力等信息。状态信息可以包括蒸汽的质量流量,蒸汽的出口焓值与入口焓值,燃料的质量流量,燃料的热值等信息。状态信息用于计算适应度函数。
参数信息
;
其中,
在本发明的第一实施例中,该启发式优化算法模型可选择粒子群算法(ParticleSwarm Opitimation,PSO)。在粒子群算法中,粒子的位置可以表示锅炉的一组参数信息。这些参数信息的组合决定了锅炉的运行状态和效率。适应度函数可以是锅炉的效率、蒸汽产量或其他相关的性能指标,在本发明的实施例中,适应度函数即为锅炉的效率最大化,即算法的目标就是最大化这个适应度值。粒子的速度表示上述参数信息的变化率。例如,如果速度是正的,那么燃料供应率可能会增加;如果速度是负的,燃料供应率可能会减少。个体最佳位置和全局最佳位置均表示了在迭代过程中找到的最佳锅炉操作参数。个体最佳位置是每个粒子找到的最佳参数,而全局最佳位置是所有粒子中的最佳参数。权重因子决定了粒子是如何根据其个体最佳位置和全局最佳位置来调整其速度和位置的。在锅炉的优化问题中,我们可以需要根据问题的特性来调整这些权重因子。惯性权重决定了粒子是如何考虑其当前速度来调整其位置的。在锅炉的优化问题中,适当的惯性权重可以帮助算法快速收敛到最佳解。
粒子群算法的位置与速度的更新方程可以如下式所示:
;
;
其中,
步骤2,建立锅炉的数字孪生虚拟模型,所述数字孪生虚拟模型能够根据锅炉的参数信息预测锅炉部件的剩余寿命。
步骤2具体包括步骤2.1~步骤2.4。
步骤2.1,构建锅炉的几何模型与物理模型。
几何模型是锅炉的三维表示,它详细描述了锅炉的几何形状和尺寸,包括炉膛、燃烧器、锅筒、进气口、出气口等几何组成部分。在某些情况下,可以使用AutoCAD、CATIA等软件构建几何模型,包括定义几何形状、设定边界条件、进行网格划分,以及规定物理属性和材质参数等。
物理模型需要包含锅炉的全部物理属性,如材质特性、结构特性、流体特性等。在某些情形下,可以使用ANSYS、Simulink等软件构建物理模型。
步骤2.2,基于锅炉的几何模型与物理模型,构建锅炉的仿真模型。
仿真模型采用几何模型和物理模型作为基础输入,执行虚拟仿真实验,进而产生仿真的输出结果,这些输出可能包括部件的预期疲劳、磨损状况以及潜在的故障区域。数据模型则利用锅炉内部的实时数据,如效率、工作时长、流量、压差和温度等作为输入,经过处理和整合后,输出实时的数据信息,这些信息可能涵盖了数据趋势、异常情况的检测以及数据的汇总。仿真模型用于进行虚拟的仿真实验,包括但不限于流场分析实验、热力分析实验、结构分析实验等。在一些实施例中,可以使用仿真软件,例如COMSOL multiphysics、OpenFOAM来构建锅炉的仿真模型。
步骤2.3,基于锅炉的几何模型、物理模型与仿真模型,构建锅炉的数字孪生虚拟模型。
数字孪生虚拟模型不仅仅是上述各个模型的简单组合。实际上,它代表了这些模型的深度融合。例如,几何模型产生的数据可能会对物理模型的表现产生影响,同时,数据模型的输出(如实时数据)可能会对仿真模型的参数产生调整。也就是说,各个模型之间存在密切的融合。这种融合方式远超过了单纯的模型组合,这使得数字孪生虚拟模型成功地汇集了各个模型的优势。
步骤2.4,基于数字孪生虚拟模型,预测锅炉部件的剩余寿命。
在一些实施例中,可以借鉴仿真模型中的疲劳损伤累积模型预测锅炉部件的剩余寿命。
步骤3,将数字孪生虚拟模型的结果反馈至启发式优化算法模型的迭代过程中,并结合适应度函数与预设的约束条件,计算出锅炉的排程。
在本发明的实施例中,适应度函数
;
其中,
约束条件用于限定锅炉信息中的参数信息,例如,约束条件可以包括锅炉的最大/最小输出热功率、最大/最小给水流量、最大/最小锅炉温度、最大/最小锅炉蒸汽压力等等。约束条件定义了搜索空间的边界,也就是说,每个粒子的位置必须在这些边界内。此外,以输出热功率为例,可理解的是,约束条件中不单有最大/最小输出热功率,还应当根据生产线中蒸汽的热功率需求,确定锅炉的输出热功率的边界条件,例如:
;
其中,
在第一实施例中,步骤3中,迭代过程具体包括步骤3.1~步骤3.3。
步骤3.1,在每一次迭代过程中,基于数字孪生虚拟模型,计算出粒子的位置对应的风险值。
由于锅炉部件的数量可以是多个,粒子的位置对应的锅炉部件的风险值可以是粒子的位置对应的多个锅炉部件的剩余寿命的加权平均值。即粒子
;
其中,
步骤3.2,依次计算出前后2次迭代中所有粒子的风险值的耦合关联度。
耦合关联度
;
;
;
其中,
步骤3.3,判断耦合关联度是否大于预设的关联度阈值;若大于,迭代结束。
也就是说,若
本发明申请人结合说明书附图对本发明的实施示例做了详细的说明与描述,但是本领域技术人员应该理解,以上实施示例仅为本发明的优选实施方案,详尽的说明只是为了帮助读者更好地理解本发明精神,而并非对本发明保护范围的限制,相反,任何基于本发明的发明精神所作的任何改进或修饰都应当落在本发明的保护范围之内。
- 一种流程可变的验光检测系统与方法、装置和存储介质
- 一种基于自动规划算法的排程方法及相关装置