一种基于生成式人工智能的在线课程观点摘要生成方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明属于人工智能领域,涉及教育信息智能化,尤其涉及一种基于生成式人工智能的在线课程观点摘要生成方法。
背景技术
观点摘要生成涉及到生成式人工智能技术与自然语言处理技术,具体是指从评论、博客、新闻等文本中提取观点信息生成摘要的过程。根据生成方式可以分为抽取式文本摘要与生成式文本摘要两方面。
抽取式摘要生成是直接选取输入文本中的句子,并将其拼接形成摘要的生成方式,该方式思路简单,是摘要生成研究初期时的主要方向。抽取式摘要生成主要采用基于机器学习的技术与基于深度学习的模型。基于机器学习的摘要生成方法,如Erkan G等(ErkanG,Radev D R.Lexrank:Graph-based lexical centrality as salience in textsummarization[J].Journal of artificial intelligence research,2004,22:457-479.)设计了一种基于PageRank算法的生成式模型LexRank,通过计算句子与句子之间的相似度,根据句子评分选择分数高的句子作为文字的摘要。基于机器学习的摘要生成方法只能提取出低准确率的语义特征,这会导致生成摘要的流畅度差效果不好。而基于深度学习的摘要生成方法,如ZHENG H等(ZHENG H,LAPATA M.Sentence Centrality Revisited forUnsupervised Summarization[C].Annual Meeting of the Association forComputational Linguistics,Florence,Italy,2019:6236-6247.)提出的一种基于Textrank的抽取式生成模型,引进BERT模型对句子编码有利于捕捉到句子中更深层次的语意,继而通过位置信息获取句与句彼此之间的指向关系,最后通过选取句子形成文本摘要。
生成式摘要是通过对提取到的信息进行分析、重构进而生成文字构成摘要,并非从输入中选取句子构成,这种技术难度大,不易实现,因此早期以生成式研究较少。生成式摘要正式兴起是在SUTSKEVER I等(SUTSKEVER I,Vinyals O,Le Q V.Sequence tosequence learning with neural networks[J].Advances in neural informationprocessing systems.2014:2302-3104.)提出一种序列到序列的模型框架后,该模型用于解决机器翻译问题,后来才用到生成式摘要研究中。朱永清等(朱永清,赵鹏,赵菲菲等.基于深度学习的生成式文本摘要技术综述[J].计算机工程,2021,47(11):11-21+28)总结出利用深度学习技术去解决生成式文本摘要的任务,模型可能会存在如未登录词问题、与生成内容重复、长期依赖性等问题,这些会导致模型性能一直不理想。对此,SEE A等(SEE A,LIU P J,MANNING C D.Get to the point:summarization with pointer-generatornetworks[C].Annual Meeting of the Association for Computational Linguistics:Association for Computational Linguistics,Vancouver,Canada,2017:1073-1083.)提出了基于序列到序列框架的指针生成器网络,该网络中利用复制机制缓解未登录词问题,即在生成时可以选择从源文档中复制单词生成。LI W等(LI W,XIAO X,LIU J,etal.Leveraging graph to improve abstractive multi-document summarization[C].Annual Meeting of the Association for Computational Linguistics,Online,2020:6232-6243.)在层次Transformer模型的基础上,提出了一种端到端的基于Transformer的模型GraphSum。在图编码层中,GraphSum将自注意机制扩展到基于图的自注意机制,该机制将图表示纳入Transformer编码过程,以缓解生成重复的问题。Laban P等(Laban P,Schnabel T,Bennett P N,et al.SummaC:Re-visiting NLI-based models forinconsistency detection in summarization[J].Transactions of the Associationfor Computational Linguistics,2022,10:163-177.)认为,摘要生成研究的关键是生成的摘要内容与输入文档中描述事实保持一致,部分研究采用自然语言推理技术来确保内容一致性,但表现不佳,原因是两者数据细粒度不匹配,自然语言推理是句子级数据,一致性检验任务是文档级数据,这是产生长期依赖性问题的原因。
因此在面对观点摘要生成任务中与生成内容重复、长期依赖性问题时,结合在线教育发展累积了海量的课程评论数据的教育场景下,通过生成式人工智能中的摘要生成技术有效利用在线课程评论数据是亟待解决的问题。而现有对课程评论的研究主要集中在情感倾向或方面词提取等局部信息,缺乏对课程全局信息的反馈,导致生成的课程评论信息存在片面化等问题。
发明内容
有鉴于此,本发明的目的在于提供一种基于生成式人工智能的在线课程观点摘要生成方法,从而弥补教育场景中因缺乏对课程全局信息的反馈,导致生成的课程评论信息存在片面化等问题,从大量课程中自动化生成课程评论的观点摘要。
为达到上述目的,本发明提供如下技术方案:
一种基于生成式人工智能的在线课程观点摘要生成方法,其包括以下步骤:
S1、采集文本评论数据并进行清理、分词和去停用词操作;
S2、采用预训练过的BERT语言模型将文本评论数据进行词嵌入,映射为高维向量表示形式,然后输入到Bi-GRU网络得到评论的隐藏状态信息;
S3、随机选择一个评论作为伪摘要,以该伪摘要为参考对象,计算其余评论在方面、情感、语义和综合信息层面与伪摘要的距离,从而对伪摘要进行内容调整生成初级数据集,再对伪摘要进行内容调整提高数据集质量以生成综合数据集;
S4、使用生成网络对综合数据集进行训练生成课程观点摘要,以验证综合数据集的实效性;同时设计课程类型预测子任务以提高生成网络的编码器和解码器性能,通过多任务的方式提高摘要生成的准确性。
进一步地,步骤S2中,获取隐藏状态信息的方式包括:采用Bi-GRU网络对文本评论数据的嵌入矩阵进行双向训练,获取包含上下文记忆信息的文本评论向量,具体地,采用自左向右的GRU网络获取记忆信息
H={h
进一步地,步骤S3中,通过内容质量计算得到其余评论在方面、情感、语义以及综合信息层面与伪摘要的距离。其中内容质量计算表示为:
f
式中,α
f
式中,
f
式中,
f
式中,Sem
f
式中,W
步骤S3中,所述内容调整包括改写、插入和删除操作;各调整操作的接受概率表示为:
π(y,c)=p(y)·ψ(y,c)
式中,
最后需要通过ψ(y,c)决定是否采用编辑后的
进一步地,步骤S4中,课程类型预测子任务的损失函数表示为:
式中,
多任务观点摘要生成层的损失函数表示为:
L
式中,λ表示控制课程类型预测子任务影响大小的参数,L
本发明的有益效果在于:
(1)本发明在课程观点摘要生成任务中,除了提取在线课程评论数据的隐藏特征外,还根据输入的评论数据设计综合数据集,通过对伪摘要进行内容调整来提高数据集质量,此外还设计多任务观点摘要生成以增强数据集的质量和模型的效果。
(2)本发明为获取到输入数据的隐藏状态信息,使用Bi-GRU网络对嵌入矩阵进行双向训练。对比其他模型如RNN和GRU,Bi-GRU能更好地捕捉潜在语义信息,且同时具有学习长期依赖信息能力,所以能更好地提取隐藏状态信息的特征。
(3)本发明使用Bi-GRU网络替代LSTM网络,相对于LSTM,GRU内部结构较简单,少一个门控单元,且可以实现与LSTM相当的功能。此外,GRU的训练参数减少,模型拟合速度更快。
(4)本发明可有效帮助学生快捷选取所需课程,辅助教师快速掌握学生的课程体验反馈,为学生自主学习、教师教学反思提供有力支撑。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1为本发明实施例提供的在线课程观点摘要生成方法的原理示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
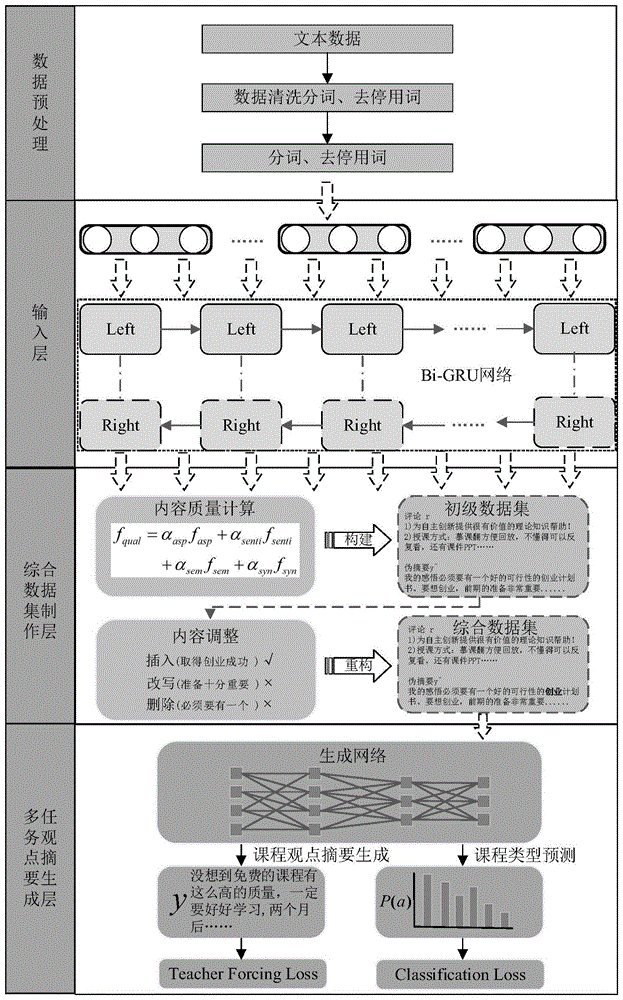
如图1所示,为一种基于生成式人工智能的在线课程观点摘要生成方法,该方法主要用于教育场景下在线课程观点摘要生成的任务,可迅速从大量课程中自动化地生成观点摘要信息,其内容包括:
步骤一、数据预处理阶段
在智慧教育平台上采集文本评论数据,再使用预过滤对收集到的评论文本数据进行清理、分词、去停用词操作,为文本数据转换为结构化数据做准备。其中,评论总数量为8314条,通过文本预处理技术对评论进行清洗、分词以及去停用词等,剔除无效评论后,剩余6357条有效评论,根据文本数量长度,将有效评论分为210组,通过人工阅读评论撰写对应参考摘要,作为实验对比文本。将80%的样本数据作为模型的训练数据,其余样本作为模型的测试数据。训练数据集共包括5085条评论数据,构成168组评论组,测试集包含1272条评论数据,构成42组评论组。
步骤二、特征提取阶段
采用预训练过的BERT语言模型,将输入的文本评论信息表征为高维词向量形式,即文本评论向量,嵌入矩阵表示为
H={h
步骤三、以随机选择的评论作为伪摘要,计算其余评论在方面、情感、语义以及综合信息层面与伪摘要的距离,对伪摘要进行内容调整生成初级数据集,在对伪摘要进行内容调整来提高数据集质量生成综合数据集。
(1)内容质量计算。设计内容质量计算函数,根据该函数计算选出的伪摘要应该传达评论的重要信息,包括方面、情感、语义以及综合信息,综合信息包括信息内容、显著度以及新颖度。
具体地,以第i条评论与伪摘要为例,根据评论文本的嵌入向量矩阵
评论的方面信息距离计算公式如下:
式中,“||”表示拼接操作。
同理得到评论的情感信息。情感信息提取主要是通过字典学习,获取评论文本中最根本的情感信息s
利用Bi-GRU网络对隐藏状态信息进行情感信息获取,评论的情感信息距离计算公式如下:
同样以第i条评论为例,采用池化BERT的头部特征Head
式中,
则评论的语义信息距离表示为:
式中,Sem
评论的综合信息将从信息内容、显著度以及新颖度三个方面进行评估。以第i条评论为例,信息内容表示的是第i条评论中所包含的信息;第i句话的状态信息
其中W
最终的内容质量计算函数计算如下:
其中α
(2)内容调整。为让伪摘要与真实摘要的形式更相似,需要对所选伪摘要进行内容调整。内容调整的方式包括插入、改写与删除。计算公式如下:
π(y,c)=p(y)·ψ(y,c)
定义联合概率分布函数以及约束,其中,p(y)表示生成摘要y时BERT的概率;c为采样约束;ψ(y,c)为约束函数。据Metropolis-Hasting采样过程定义接受概率
式中,
改写(replace)操作、插入(insert)操作、删除(delete)操作的概率分别记为
其中,
本实施例只展示了改写操作的概率计算公式,插入和删除操作的计算改变相应的下标即可。同理,删除、插入编辑操作的概率分别用q
最后,通过ψ(y,c)决定是否采用编辑后的
步骤四、利用生成网络即基于Transformer的原始框架对综合数据集进行训练,使用生成课程观点摘要来验证综合数据集的实效性;再结合T5网络,实现嵌入相对位。
利用课程类型预测子任务,提高生成网络编码器解码器提取信息的能力,课程类型预测子任务损失函数如式下:
多任务观点摘要生成层最终的损失函数如下:
L
其中,
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 一种废弃铝灰渣综合利用的方法及铝灰渣成型块
- 一种在线旁路轻质物风选分离装置
- 一种轴承钢球研磨液铁屑分离装置
- 一种铝灰渣研磨风选分离一体机装置
- 一种铝灰渣研磨风选分离一体机装置