一种基于运渣车土石方运输特征的扬尘点位类型判别方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及交通大数据技术领域,具体涉及一种基于运渣车土石方运输特征的扬尘点位类型判别方法。
背景技术
随着经济社会的发展,颗粒物污染已成为降低城市生态环境质量的主要大气污染源,不仅对城市空气质量和城市景观产生较大影响,还危害着周边居民甚至公众的身体健康。城市扬尘是大气颗粒物的主要来源之一,城市建设施工、改建拆迁、市政设施建设进程不断加快,不可避免地导致了施工扬尘的大量排放。针对不同类型扬尘源的污染途径及特点,及时给出合理的管控方法和措施,极为重要。目前土方点位的类型确定主要依靠人工线下排查,不仅人力成本耗费巨大且时效性不佳。
渣土车作为城市建设的运输主体,其行为包括建渣装载、道路运输与土场倾倒等,它们不断往返于建筑工地、重型停车场、倾倒场以及砂石厂,形成了覆盖辖区内主要土石方点位的运输网络。分析运渣车的运输特征可以有效识别扬尘点位的类型,进而深入了解扬尘的来源和特点,为环保监管部门实施更详细、更具针对性的扬尘管控措施提供现实依据。
发明内容
针对现有技术中的上述不足,本发明提供的一种基于运渣车土石方运输特征的扬尘点位类型判别方法解决了现有技术确定扬尘点位的类型需耗费大量人力,并耗时长且时效性不佳的问题。
为了达到上述发明目的,本发明采用的技术方案为:
提供了一种基于运渣车土石方运输特征的扬尘点位类型判别方法,其包括以下步骤:
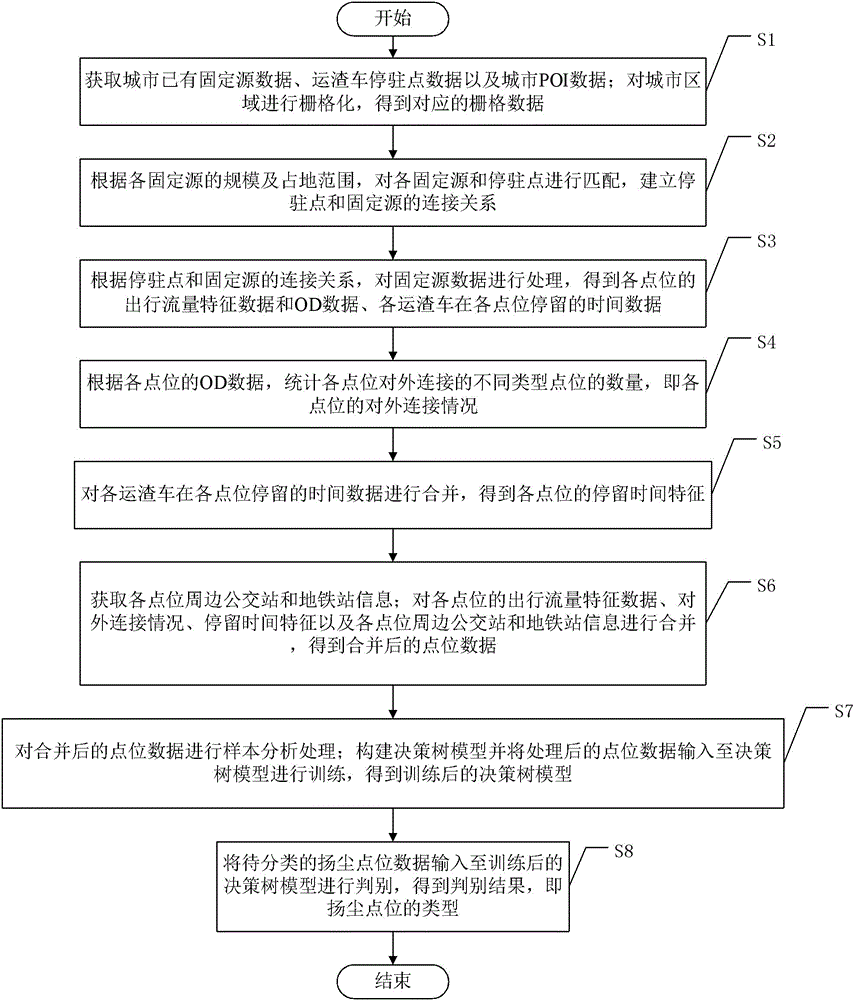
S1、获取城市已有固定源数据、运渣车停驻点数据以及城市POI数据;对城市区域进行栅格化,得到对应的栅格数据;
S2、根据各固定源的规模及占地范围,对各固定源和停驻点进行匹配,建立停驻点和固定源的连接关系;
S3、根据停驻点和固定源的连接关系,对固定源数据进行处理,得到各点位的出行流量特征数据和OD数据、各运渣车在各点位停留的时间数据;
S4、根据各点位的OD数据,统计各点位对外连接的不同类型点位的数量,即各点位的对外连接情况;
S5、对各运渣车在各点位停留的时间数据进行合并,得到各点位的停留时间特征;
S6、获取各点位周边公交站和地铁站信息;对各点位的出行流量特征数据、对外连接情况、停留时间特征以及各点位周边公交站和地铁站信息进行合并,得到合并后的点位数据;
S7、对合并后的点位数据进行样本分析处理;构建决策树模型并将处理后的点位数据输入至决策树模型进行训练,得到训练后的决策树模型;
S8、将待分类的扬尘点位数据输入至训练后的决策树模型进行判别,得到判别结果,即扬尘点位的类型。
进一步地,城市已有固定源数据包括施工工地、重型停车场、倾倒场、砂石场的点位名称、类型、占地范围及经纬度信息;城市POI数据包括城市的公交站、地铁站的基础信息。
进一步地,步骤S2进一步包括:
S2-1、根据各固定源的规模及占地范围,将各固定源与网格进行匹配和Label标记,建立网格和固定源的关系;
S2-2、对每一辆运渣车的停驻点进行处理并与网格进行匹配,得到对应的停驻点的位置信息;
S2-3、基于网格和固定源的关系、停驻点的位置信息,建立停驻点和固定源的连接关系。
进一步地,步骤S2-2的具体过程如下:按照时间顺序,对每一辆运渣车的停驻点进行排序,得到对应的排序后的停驻点信息;将排序后的停驻点信息与网格进行匹配,并删除始终处于同一网格内活动的车辆数据,得到对应的停驻点的位置信息;其中,车辆数据为运渣车轨迹数据。
进一步地,步骤S3进一步包括:
S3-1、按照时间顺序查看同一辆运渣车的停驻网格是否属于同一个固定源;若是则保留该固定源点位的第一条数据和最后一条数据,并记录该运渣车在此点位的停留时间;反之则得到该运渣车的OD数据;
S3-2、重复步骤S3-1,直至检查完所有运渣车,获得所有运渣车的OD数据以及各运渣车在各点位停留的时间数据;
S3-3、对所有运渣车的OD数据进行合并,得到各固定源的出行线路;统计各点位分别作为O点、D点时的车辆出行流量、车辆入行流量,得到各固定源的总出行流量;
S3-4、根据所有运渣车的OD数据,统计各点位作为O点时对外连接的固定源的数量、各点位作为D点时外部进来的固定源数据的数量,并分别作为出度和入度,获得各固定源的总出行度;
S3-5、对各固定源的总出行流量和总出行度进行合并,得到各点位的出行流量特征数据。
进一步地,步骤S5进一步包括:
S5-1、遍历每一个点位,将所有运渣车在该点位停留的时长进行计算,得到各点位的平均停留时长数据;
S5-2、遍历每一个点位,将所有运渣车在该点位停留的行程时长进行排序,得到各点位停留时长的25分位数、50分位数、75分位数;
S5-3、将各点位的平均停留时长数据以及各点位停留时长的25分位数、50分位数、75分位数进行合并,得到各点位的停留时间特征。
进一步地,步骤S7处理合并后的固定源数据的具体过程为:
对合并后的固定源数据进行样本分析;若出现样本不均衡问题,则通过SMOTE采样方式对出现不均衡的样本进行插值处理,使合并后的固定源数据的数据量相同。
本发明的有益效果为:本方法基于运渣车轨迹数据获取土石方运输特征,利用决策树算法建模判断扬尘点位类型,能及时、准确且快速地判定扬尘源特点及污染风险;无需依赖于职能部门源清单即可为环保监管人员及时排查问题、实施源头管控提供有力数据支撑,提升辖区污染防控工作水平。
附图说明
图1为本发明的具体流程图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种基于运渣车土石方运输特征的扬尘点位类型判别方法包括以下步骤:
S1、获取城市已有固定源数据、运渣车停驻点数据以及城市POI数据;对城市区域进行栅格化,得到对应的栅格数据;
城市已有固定源数据包括施工工地、重型停车场、倾倒场、砂石场的点位名称、类型、占地范围及经纬度信息;城市POI数据包括城市的公交站、地铁站的基础信息。
运渣车停驻点数据是依据运渣车实时轨迹数据筛选出来的轨迹点,表示车辆在某位置处于停留或者徘徊状态且维持一段时间的一簇点。
对城市区域格式化为200m*200m的正方形,并给出每个网格的中心坐标以及上下左右4个顶点坐标。
S2、根据各固定源的规模及占地范围,对各固定源和停驻点进行匹配,建立停驻点和固定源的连接关系;
步骤S2进一步包括:
S2-1、根据各固定源的规模及占地范围,将各固定源与网格进行匹配和Label标记,建立网格和固定源的关系;
S2-2、对每一辆运渣车的停驻点进行处理并与网格进行匹配,得到对应的停驻点的位置信息;其中,
步骤S2-2的具体过程如下:按照时间顺序,对每一辆运渣车的停驻点进行排序,得到对应的排序后的停驻点信息;将排序后的停驻点信息与网格进行匹配,并删除始终处于同一网格内活动的车辆数据,得到对应的停驻点的位置信息;其中,车辆数据为运渣车轨迹数据。
S2-3、基于网格和固定源的关系、停驻点的位置信息,建立停驻点和固定源的连接关系;其中,停驻点和固定源的连接关系的形式为
S3、根据停驻点和固定源的连接关系,对固定源数据进行处理,得到各点位的出行流量特征数据和OD数据、各运渣车在各点位停留的时间数据;
步骤S3进一步包括:
S3-1、按照时间顺序查看同一辆运渣车的停驻网格是否属于同一个固定源;若是则保留该固定源点位的第一条数据和最后一条数据,并记录该运渣车在此点位的停留时间;
反之则得到该运渣车的OD数据;即反之则得到该运渣车的OD数据,表明运渣车离开上一个点位区域进入下一个点位区域,一条OD形成,其中上个点位的last记录代表O点,下个点位的first记录代表D点。下个点位的last记录则又是一条新OD线的O点。以此类推,形成车辆的完整OD流程。
S3-2、重复步骤S3-1,直至检查完所有运渣车,获得所有运渣车的OD数据以及各运渣车在各点位停留的时间数据;所有运渣车的OD数据亦为各点位的OD数据;
S3-3、对所有运渣车的OD数据进行合并,得到各固定源的出行线路;统计各点位分别作为O点、D点时的车辆出行流量、车辆入行流量,得到各固定源的总出行流量;
步骤S3-3涉及的公式为:
其中,
S3-4、根据所有运渣车的OD数据,统计各点位作为O点时对外连接的固定源的数量、各点位作为D点时外部进来的固定源数据的数量,并分别作为出度和入度,获得各固定源的总出行度;
步骤S3-4涉及的公式为:
其中,
S3-5、对各固定源的总出行流量和总出行度进行合并,得到各点位的出行流量特征数据。
其中,各运渣车在各点位停留的时间数据的数据格式为
S4、根据各点位的OD数据,统计各点位对外连接的不同类型点位的数量,即各点位的对外连接情况;即遍历每一个固定源点位,根据各点位OD数据,统计其对外连接的不同类型点位的数量,例如固定源
S5、对各运渣车在各点位停留的时间数据进行合并,得到各点位的停留时间特征;
步骤S5进一步包括:
S5-1、遍历每一个点位,将所有运渣车在该点位停留的时长进行计算,得到各点位的平均停留时长数据;
S5-2、遍历每一个点位,将所有运渣车在该点位停留的行程时长进行排序,得到各点位停留时长的25分位数、50分位数、75分位数;
S5-3、将各点位的平均停留时长数据以及各点位停留时长的25分位数、50分位数、75分位数进行合并,得到各点位的停留时间特征。
其中,
S6、获取各点位周边公交站和地铁站信息,即基于各固定源的经纬度信息,借助于地图服务商API获取点位周边500米的公交站个数、公交路线数、地铁站个数以及地铁线路数
对各点位的出行流量特征数据、对外连接情况、停留时间特征以及各点位周边公交站和地铁站信息进行合并,得到合并后的点位数据;
S7、对合并后的点位数据进行样本分析处理;构建决策树模型并将处理后的点位数据输入至决策树模型进行训练,得到训练后的决策树模型;
步骤S7处理合并后的固定源数据的具体过程为:
对合并后的固定源数据进行样本分析;若出现样本不均衡问题,则通过SMOTE采样方式对出现不均衡的样本进行插值处理,使合并后的固定源数据的数据量相同。
其中,处理后的点位数据的数据格式为:
其中,/>
S8、将待分类的扬尘点位数据输入至训练后的决策树模型进行判别,得到判别结果,即扬尘点位的类型。
在本发明的一个实施例中,SMOTE过采样方法是基于样本的特征空间,通过对少数类样本进行插值来生成合成样本。其主要步骤如下:
1.对于每一个少数类样本,计算其与所有其他少数类样本之间的距离,并找到其K个最近邻居。
2.从这K个最近邻居中随机选择一个样本,并计算该样本与当前样本的差异。
3.根据差异比例,生成一个新的合成样本,该样本位于两个样本之间的连线上。
4.重复上述步骤,生成指定数量的合成样本。
待样本均衡之后,确定合理的运行参数进行决策树建模,并使用决策树的特征重要度信息对预测结果进行解释,说明预测的依据,增强分类结果的可信度。
待样本均衡之后,确定合理的运行参数进行决策树建模,并使用决策树的特征重要度信息对预测结果进行解释,说明预测的依据,增强分类结果的可信度。
综上所述,本发明基于运渣车轨迹数据获取土石方运输特征,利用决策树算法建模判断扬尘点位类型,能及时、准确且快速地判定扬尘源特点及污染风险;无需依赖于职能部门源清单即可为环保监管人员及时排查问题、实施源头管控提供有力数据支撑,提升辖区污染防控工作水平。
- 文件解析方法及网络设备
- JSON文件解析方法及装置
- 一种JSON文件解析方法、装置及电子设备