一种自监督学习的DTCO标准单元库版图布局方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及芯片研发的标准单元库版图自动布局改进的技术领域,一种自监督学习的DTCO标准单元库版图布局方法。
背景技术
随着半导体工艺进入深亚微米和纳米节点,及对新工艺节点下高性能高效芯片的需求,DTCO(Design Technology Co-Optimization)策略应运而生。DTCO的核心理念是将工艺技术和芯片设计进行协同优化,使得工艺技术和芯片设计得以深度融合,从而在新工艺节点下创造出性能更强、功耗更低、成本更优的芯片产品,是半导体行业进一步发展的重要途径。
标准单元库(Standard Cell Library)是DTCO集成电路设计流程中的重要模块。其是指预先设计和字符化的逻辑门、触发器、IO口等基本功能单元的集合。标准单元具有固定的布局设计和尺寸,可以像积木一样组合成复杂的数字或模拟电路。目前流程中对于标准单元库的版图布局布线生成的需求高,但是目前标准单元库的版图布局布线的生成仍以大量人工绘制和调试为主,传统手工布局的低效已难以满足DTCO流程中芯片迭代的需求。此背景下,学术界和工业界尝试了多种算法来实现布局自动化,但各有局限。
早期使用预定义模板和设计经验进行标准单元布局,但随着新工艺新材料的发展,预定义模板和经验难以满足日益复杂的设计规则约束,实现自动化变得更为困难。退火算法等空间搜索算法曾用于布局优化,相较于预定义模板技术,退火算法可以搜索更大解空间,但容易陷入局部最优,流程往往需要大量的手工调优,且难以迁移到不同工艺。
近年来,强化学习被应用于标准单元的自动布局生成。采用强化学习方法进行布局生成,可以逐步修复布局违规。但是强化学习需要设计大量奖惩机制,并依赖生成-修复范式,导致训练样本利用效率低下。强化学习难以明确告知学习者复杂环境下的期望行为,只能靠反馈进行试错,因此很难自动学习满足复杂约束条件的优质布局。总体来说,现有强化学习方法过于依赖专家进行监督和优化,训练时间长而效果难以控制,也不适合不同工艺下的全自动标准单元库版图布局生成。
发明内容
本发明目的在于提供一种自监督学习的DTCO标准单元库版图布局方法,以解决上述现有技术存在的问题。
本发明中所述一种自监督学习的DTCO标准单元库版图布局方法,包括如下步骤:
S1.收集学习文件;
S2.建立自监督学习深度学习模型,自监督学习方案采用无监督预训练结合监督微调的深度框架,无监督预训练直接将经清洗但未经标定的文本文件输入深度学习模型,监督微调为对深度学习模型投入经过清洗且标定的文本文件;
S3.训练过程自适应动态调整深度学习模型的参数权重和超参数,直到生成内容满足指定工艺节点设计规则的版图布局要求。
所述学习文件包括语义文件、标准单元库的Spice网表文件、设计规则文件以及相对应的标准单元库版图布局信息的数据文件。
所述深度学习模型基于深度神经网络架构,所述深度神经网络架构是卷积神经网络,或循环神经网络,或变换器。
在所述步骤S2的无监督预训练:所述深度学习模型被训练至具备理解未经标定的文本文件的状态。
在所述步骤S2的监督微调:在无监督预训练之后,所述深度学习模型进入监督微调阶段;使用已经清洗和标定的文本文件对深度学习模型进行进一步训练,以提高性能;已经清洗和标定的文本文件包括使用人工标签的数据。
在所述步骤S3中,训练过程根据深度学习模型的性能和生成结果来自动进行调整;训练过程需要多轮迭代,其中每一轮训练都会生成一组版图布局,并评估其与设计规则的符合程度,根据评估结果自适应地调整深度学习模型参数权重和超参数;如果生成的版图布局不符合设计规则,深度学习模型将进行相应的调整,以改进生成的结果,直到能够生成满足特定工艺节点设计规则的版图布局,并且在性能和质量方面达到设定的水平。
本发明中所述一种自监督学习的DTCO标准单元库版图布局方法,其优点在于:
1.自动化程度提高:与传统手工布局方法相比,本发明提供了一种全自动的标准单元库版图布局方法。这将大大减少人工干预和调整的需要,提高了设计效率,尤其在新工艺和新材料下,可以显著减少布局迭代的时间和成本。
2.适用性广泛:本发明的方法不仅适用于数字电路,还适用于混合信号、模拟电路和其他领域的设计。这种广泛的适用性有助于满足不同类型芯片的布局需求,从而推动半导体行业的发展。
3.自监督学习优势:采用自监督学习的方法,深度学习模型可以从大量未标定的文本数据中学习,这有助于提高深度学习模型的泛化能力和对复杂语义信息的理解。与需要大量标注数据的传统监督学习方法相比,这降低了数据标注的成本和复杂性。
4.自适应训练:本发明中的自适应动态调整深度学习模型参数权重和超参数的策略可以确保深度学习模型在训练过程中不断改进,以生成满足特定工艺规则的版图布局。这意味着深度学习模型的性能逐步提高,最终达到满意的水平。
5.提高快速迭代和优化:在新材料和新工艺下,芯片的快速迭代和优化对于半导体行业至关重要。本发明的方法有助于缩短设计周期,提高设计质量,支持更快的芯片开发和制造。
6.减少人为错误:自动化布局生成减少了人工干预,从而降低了因人为错误而导致的问题。这有助于改善版图的准确性和可制造性。
附图说明
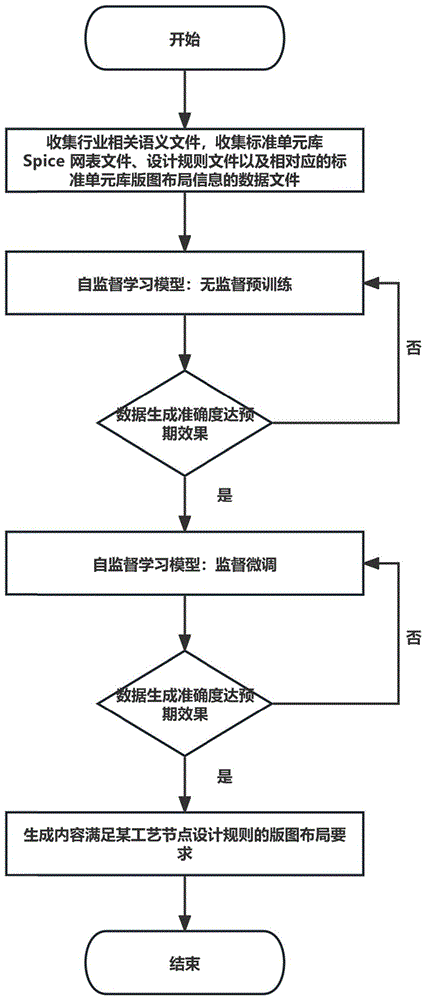
图1是本发明中所述一种自监督学习的DTCO标准单元库版图布局方法的流程示意图。
图2是基于Spice网表文件自动生成的标准单元库版图布局示意图。
具体实施方式
如图1所示,本发明中所述一种自监督学习的DTCO标准单元库版图布局方法包括以下步骤:
S1.本发明实施例采用了40nm、28nm CMOS器件的行业相关语义文件,标准单元库Spice网表文件、设计规则文件以及相对应的标准单元库版图布局信息的JSON数据文件。其中行业相关语义文件为现有技术文件。
40nm、28nm CMOS器件行业相关语义文件:这些语义文件包括与电路设计和制造相关的文档和知识。包括设计规范、技术白皮书、行业标准文件、研究论文以及其他关于电子设计和半导体制造的信息。这些文件可以提供关于电路版图设计的理论、最佳实践、新技术和行业趋势的重要语境。
技术白皮书:技术白皮书通常包含了关于最新制造技术、工艺流程和工具的详细信息。它们可以介绍特定工艺节点下的创新方法和解决方案,以满足不断增长的性能和功耗需求。
行业标准文件:这些文件是半导体行业的标准化组织发布的,包括半导体设备和材料国际协会SEMI等。它们规定了工艺制造中的规则和约束,以确保电路的可制造性和一致性。
40nm、28nm CMOS器件标准单元库的Spice网表文件:Spice网表文件是用于电路仿真的关键输入文件,它们通常包含了电路元件,如晶体管、电阻、电容之间的连接、特性和参数信息。这些文件提供了电路元件的电学行为描述:
电路元件连接:Spice网表文件指定了标准单元库中各个电路元件,如晶体管、电阻、电容等之间的连接方式,包括输入和输出端口以及相互之间的关系。
特性描述:这些文件包含了各个电路元件的特性参数,如晶体管的阈值电压、电流增益、电容值等。这些参数对于电路的性能和行为至关重要。
40nm、28nm CMOS器件设计规则文件:设计规则文件包含了工艺制造中的规则和约束。这些规则定义了元件的尺寸、间距、层次结构等,以确保电路在芯片制造过程中的正确性和性能。设计规则文件对于确保电路可制造性非常重要。这些文件包括以下内容:
元件尺寸规则:40nm、28nm CMOS器件设计规则文件规定了电路元件的尺寸,包括晶体管的门长、源漏区域等。这确保了元件的准确性和一致性,以满足特定工艺节点的要求。
间距规则:40nm、28nm CMOS器件设计规则文件定义了元件之间的最小间距,以防止不同元件之间的电学干扰或相互干扰。这有助于确保电路的可靠性和性能。
层次结构规则:这些40nm、28nm CMOS器件规则规定了不同电路层之间的联系和叠放方式,以确保正确的信号传输和互连。这对于多层CMOS电路设计至关重要。
材料和工艺规则:这些40nm、28nm CMOS器件规则包括关于使用特定材料和工艺步骤的约束,以确保电路的可制造性和质量。
特殊约束规则:这些40nm、28nm CMOS器件设计规则文件可能包括特殊约束,例如关于电源电压、时序要求、抗干扰性等方面的规定。
40nm、28nm CMOS器件相对应的标准单元库版图布局信息的数据文件:这些数据文件包括了实际电路版图的布局信息。
器件的位置:这些文件记录了40nm、28nm CMOS器件标准单元库中各个电路元件,如晶体管、电容、电阻等在电路版图中的精确的位置或器件的相对位置。
器件的属性:数据文件包含了关于40nm、28nm CMOS器件标准单元库中每个电路元件的属性信息,如元件类型、尺寸、电性能参数等。这些属性信息有助于深度学习模型理解电路元件的特性。
器件的连接关系:文件中还包括了40nm、28nm CMOS器件标准单元库中元件之间的连接关系,包括输入和输出端口的连接方式以及信号传输路径。这有助于深度学习模型理解电路的拓扑结构和功能。
这些文件为自监督学习深度学习模型提供了真实的版图布局数据,这些符合设计规则的布局信息文件用于训练深度学习模型。
S2.建立自监督学习深度学习模型,自监督学习方案采用无监督预训练结合监督微调的深度框架,无监督预训练直接将经清洗但未经标定的文本文件输入深度学习模型,监督微调为对深度学习模型投入经过清洗且标定的文本文件。
建立深度学习模型:在这一步骤中,建立一个深度学习模型,该深度学习模型用于执行自监督学习任务。通常,这个深度学习模型可以基于深度神经网络架构,如卷积神经网络CNN、循环神经网络RNN或变换器Transformer等。这个深度学习模型的设计能够有效地处理文本数据和理解版图布局信息。
Deep Learning Model=Modeling(X)
其中,X代表输入数据,可能包括语义文件、Spice网表文件、设计规则文件以及版图布局信息。
采用自监督学习方案:这个方法采用自监督学习,其中深度学习模型通过自己进行训练,而不是通过外部标签。具体而言,该方法采用两个阶段的自监督学习方案,包括无监督预训练和监督微调。
采用了现有技术中GPT网络深度学习模型的自监督学习方案,GPT的网络结构只包含Transformer结构的Decoder模块,相当于一个编码器-解码器深度学习模型中的解码器部分。Position Embedding加入位置信息,以表示每个token的位置,输入信息表示为:
Input_embed=Token_embed+Pos_embed
而Decoder模块包含Masked Self-Attention层和Feed Forward层的堆叠,前馈全连接层可表示为:
FFN(X)=max(0,XW
Decoder的层级连接表示为:
Decoder(X)=FFN(Att(X))+X
堆叠了L层Decoder表示为:
GPT(X)=Decoder_L(......Decoder_2(Decoder_1(X)))
Masked Self-Attention层的掩码多头自注意力机制Masked Multi-Head Self-Attention是自注意力机制的一个变种,现有技术中常用于处理序列数据,具体而言:首先,将输入序列进行多头分割,得到多个子空间的表示。每个头部注意力机制可以关注输入序列的不同方面。其次,在注意力计算时,对输入序列进行掩码操作,使得预测时不能看到未来的信息。具体来说,就是在注意力权重矩阵中,将非法的注意力项设置为一个很小的值(-inf)或者0。最后,多头注意力得到的输出再Concat拼接在一起,并进行线性变换作为最终的序列表示。公式流程为:设输入序列为a=(a
Q=aWq,K=aWk,V=aWv
对多头自注意的每个头h,计算注意力权重:
其中
进行掩码操作:
Mask=[[0,0,...,-inf],[0,0,...,0],...,[0,0,...,0]]
最后对各个头部的注意力输出拼接:
b=MultiHead(Q,K,V)=Concat(Attention
其中Concat为各注意力的拼接操作,W
通过这种方式,掩码自注意力既考虑了多头注意力表示的多样性,也解决了普通自注意力无法进行顺序生成的问题,让深度学习模型在进行预测时只依赖于已生成的token。
无监督预训练阶段:在这一阶段,深度学习模型被训练到可以理解未经标定的文本文件。这意味着深度学习模型将学习文本数据的内部表示,包括语义和结构,而不需要外部标签或注释。这一阶段的目标是为深度学习模型提供关于语义信息的理解。
Model
其中,X
监督微调阶段:在无监督预训练之后,深度学习模型进入监督微调阶段。在这一阶段,使用已经清洗和标定的文本文件对深度学习模型进行进一步训练,以提高性能。这可以包括使用人工标签的数据来指导深度学习模型进行特定任务,以满足特定的设计规则和要求。
Model
其中,X
S3.训练过程自适应动态调整深度学习模型的参数权重和超参数,直到生成内容满足某工艺节点设计规则的版图布局要求。
深度学习模型的训练过程采用自适应动态调整深度学习模型参数权重和超参数的策略。这意味着训练过程不是静态的,而是根据深度学习模型的性能和生成结果来自动进行调整。训练深度学习模型以逐渐生成满足某工艺节点设计规则的版图布局要求的内容,这是自监督学习任务的关键目标。训练过程可能需要多轮迭代,其中每一轮训练都会生成一组版图布局,并评估其与设计规则的符合程度。根据评估结果,自适应地调整深度学习模型参数权重和超参数。如果生成的版图布局不符合设计规则,深度学习模型将进行相应的调整,以改进生成的结果。这个训练过程将持续进行,直到深度学习模型能够生成满足特定工艺节点设计规则的版图布局,并且在性能和质量方面达到满意的水平。
Adaptive Training(Model,X)=Training(Model,X,Valuation(X))
其中,Model代表深度学习模型,X代表输入数据,包括版图布局信息和设计规则,Valuation(X)代表对生成的版图布局进行性能评估,包括与设计规则的符合程度。
经监督微调后,输入无监督预训练和监督微调流程中未训练到的28nm的Spice网表文件,如图2所示,深度学习模型生成的描述版图布局的JSON格式文件包含了器件各模块的相对位置坐标、各端连接关系以及图形的几何尺寸信息,其器件布局方式已蕴含了设计规则条件,满足该模块的版图布局的设计要求。
本发明的一种自监督学习的DTCO标准单元库版图布局方法,通过收集行业相关语义文件、Spice网表文件、设计规则文件和标准单元库版图布局数据,建立深度学习模型,自适应训练该深度学习模型以生成符合特定工艺规则的版图布局。与传统手工布局方法相比,本发明实现了全自动化,提高了设计效率,适用于不同电路类型,降低了成本;与模拟退火算法相比,本发明的自监督学习方法具有更高的自适应性、更有效的数据利用和更好的泛化能力,减少了手动调整和提高训练效率;相较于强化学习,它需要更少的数据、训练更快,并具有较低的控制难度。本方法支持DTCO流程的快速芯片迭代和优化需求,具有广泛的应用前景。
对于本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 光掩模的修正方法、光掩模的制造方法、光掩模和显示装置的制造方法
- 光掩模坯料及其制造方法、光掩模的制造方法、以及显示装置的制造方法
- 芯片上阀门的制造方法、微流控芯片与液体流动控制方法
- 无线通信芯片及其制造方法、无线通信芯片用内置型天线
- 光感应芯片及其制造方法、激光雷达及电子设备
- 光感应芯片的制造方法